


Creating Microservices in Java
The prospect of creating an application composed of microservices raises some questions in any language:
•How large should a microservice be?
•What does the notion of focused services that do one thing mean for traditional centralized governance?
•What does it do to traditional ways of modeling data?
Some of these topics are covered in more depth in later chapters. This chapter focuses on how you identify and create the microservices that compose your app, with specific emphasis on how identified candidates are converted into RESTful APIs, and then implemented in Java.
This chapter covers the following topics:
2.1 Java platforms and programming models
New Java applications should minimally use Java 8, and should embrace new language features like lambdas, parallel operations, and streams. Using annotations can simplify the codebase by eliminating boilerplate, but can reach a subjective point where there is “too much magic”. Try to establish a balance between code cleanliness and maintainability.
You can create perfectly functional microservices using nothing but low-level Java libraries. However, it is generally recommended to have something provide a reasonable base level of support for common, cross-cutting concerns. It allows the codebase for a service to focus on satisfying functional requirements.
2.1.1 Spring Boot
Spring Boot provides mechanisms for creating microservices based on an opinionated view of what technologies should be used. Spring Boot applications are Spring applications, and use a programming model unique to that ecosystem.
Spring Boot applications can be packaged to run as an application hosted by an application server, or run as a runnable .jar file containing the composition of dependencies and some type of embedded server (usually Tomcat). Spring Boot emphasizes convention over configuration, and uses a combination of annotations and classpath discovery to enable additional functions.
Spring Cloud is a collection of integrations between third-party cloud technologies and the Spring programming model. Some are integrations between the spring programming model and third-party technologies. In fewer cases, Spring Cloud technologies are usable outside of the Spring programming model, like Spring Cloud Connectors Core.
For more information about Spring Cloud Connectors, see the following website:
2.1.2 Dropwizard
Dropwizard is another technology for creating microservices in Java. It also has an opinionated approach, with a preselected stack that enhances an embedded Jetty servlet container with additional capabilities. The set of technologies that Dropwizard supports is comparatively narrow, although third party or community provided plug-ins are available to fill the gaps. Some of their capabilities, specifically their support for application metrics, are quite good.
2.1.3 Java Platform, Enterprise Edition
Java Platform, Enterprise Edition (Java EE) is an open, community driven standard for building enterprise applications.
Java EE technologies are suited for creating microservices, especially Java API for RESTful Web Services (JAX-RS), and Contexts and Dependency Injection (CDI) for Java EE. Annotations are used for both specifications, with support for dependency injection, lightweight protocols, and asynchronous interaction patterns. Concurrency utilities in Java EE7 further provide a straightforward mechanism for using reactive libraries like RxJava in a container friendly way.
For more information about RxJava, see:
Modern Java EE application servers (WebSphere Liberty, Wildfly, TomEE, Payara) undercut claims of painful dealings with application servers. All of these servers can produce immutable, self-contained, lightweight artifacts in an automated build without requiring extra deployment steps. Further, composable servers like WebSphere Liberty allow for explicit declaration of spec-level dependencies, allowing the run time to be upgraded without creating compatibility issues with the application.
Applications use a reduced set of Java EE technologies and are packaged with application servers like WebSphere Liberty that tailor the run time to the needs of the application. This process results in clean applications that can move between environments without requiring code changes, mock services, or custom test harnesses.
The examples in this book primarily use Java EE technologies like JAX-RS, CDI, and Java Persistence API (JPA). These specifications are easy to use, and are broadly supported without relying on vendor-specific approaches.
2.2 Versioned dependencies
The twelve factor application methodology was introduced in Chapter 1, “Overview” on page 1. In keeping with the second factor, use explicit versions for external dependencies. The build artifact that is deployed to an environment must not make assumptions about what is provided.
Build tools like Apache Maven1 or Gradle2 provide easy mechanisms for defining and managing dependency versions. Explicitly declaring the version ensures that the artifact runs the same in production as it did in the testing environment.
Tools are available to make creating Java applications that use Maven and Gradle easier. These tools accept as inputs a selection of technologies, and output project structures complete with the Maven or Gradle build artifacts that are required to build and either publish or deploy the final artifact:
•WebSphere Liberty App Accelerator
•Spring Initializr
•Wildfly Swarm Project Generator
2.3 Identifying services
As mentioned in Chapter 1, “Overview” on page 1, microservices are described as being “small.” The size of a service should be reflected in its scope, rather than in the size of its codebase. A microservice should have a small, focused scope: It should do one thing, and do that thing well. Eric Evans’ book, Domain-Driven Design, describes many concepts that are helpful when deciding how to build an application as a composition of independent pieces. Both the online retail store and Game On! are referenced in the next few sections to explain why these concepts are useful for developing and maintaining microservice architectures in the long term.
2.3.1 Applying domain-driven design principles
In domain-driven design, a domain is a particular area of knowledge or activity. A model is an abstraction of important aspects of the domain that emerges over time, as the understanding of the domain changes. This model is then used to build the solution, for cross-team communications.
With monolithic systems, a single unified domain model exists for the entire application. This concept works if the application remains fairly simple. Using a single unified model falls apart when different parts of your application use common elements in different ways.
For example, the Catalog service in the Online Retail Store sample is focused on the items for sale, including descriptions, part numbers, product information, pictures, and so on. The Order service, by contrast, is focused on the invoice, with items represented minimally, perhaps only the part number, summary, and calculated price.
Bounded contexts allow a domain to be subdivided into independent subsystems. Each bounded context can then have its own models for domain concepts. Continuing the above example, both the Catalog and Order services can each have independent representations of items that best fit the needs of their service. This system usually works great, but how do the two services share information with other services, given they have different representations for the same concept?
Context mapping, including the development and use of ubiquitous language, can help ensure that disparate teams working on individual services understand how the big picture should fit together. In the case of modeling a domain for a microservices application, it is important not to get down to the class or interface level when identifying the pieces that comprise the system. For the first pass, keep things at a high, coarse level. Allow individual teams working on the individual services work within their bounded contexts to expand on the details.
Ubiquitous language in Game On!
To give a concrete example of the importance of language, we take a small detour into how Game On! was developed. The game was built to make it easier for developers to experiment with microservices concepts first hand, combining the instant gratification of a quick hello world example with different ways to think about the more complex aspects of microservices architectures. It is a text-based adventure game in which developers add their own individual services (rooms) to extend the game.
The original metaphor for the game was akin to a hotel, with three basic elements:
•A Player service to deal with all things relating to game players
•An initial Room service as a placeholder for what developers will build
•An additional service called the Concierge, the original purpose of which was to help facilitate the transition of a player from room to room
After letting these three pieces of the system evolve over time, it was discovered that different people working on the game had different interpretations of what the Concierge was supposed to do. The Concierge did not work as a metaphor because it was too ambiguous. The Concierge was replaced with a new Map service. The Map is the ultimate source of truth for where a room is located in the game, which is clearly understood from the name alone.
2.3.2 Translating domain elements into services
Domain models contain a few well-defined types:
•An Entity is an object with a fixed identity and a well-defined “thread of continuity” or lifecycle. An frequently cited example is a Person (an Entity). Most systems need to track a Person uniquely, regardless of name, address, or other attribute changes.
•Value Objects do not have a well-defined identity, but are instead defined only by their attributes. They are typically immutable so that two equal value objects remain equal over time. An address could be a value object that is associated with a Person.
•An Aggregate is a cluster of related objects that are treated as a unit. It has a specific entity as its root, and defines a clear boundary for encapsulation. It is not just a list.
•Services are used to represent operations or activities that are not natural parts of entities or value objects.
Domain elements in Game On!
As mentioned in 1.3.1, “The meaning of “small”” on page 4, the game was built around the notion of a Player, an obvious Entity. Players have a fixed ID, and exist for as long as the player’s account does. The player entity has a simple set of value objects, including the player’s user name, favorite color, and location.
The other significant element of the game, rooms, do not map so obviously to an Entity. For one thing, room attributes can change in various ways over time. These changeable attributes are represented by a Value Object containing attributes like the room’s name, descriptions of its entrances, and its public endpoint. Further, the placement of rooms in the map can change over time. If you consider each possible room location as a Site, you end up with the notion of a Map as an Aggregate of unique Site entities, where each Site is associated with changeable room attributes.
Mapping domain elements into services
Converting domain elements into microservices can be done by following a few general guidelines:
•Convert Aggregates and Entities into independent microservices, by using representations of Value Objects as parameters and return values.
•Align Domain services (those not attached to an Aggregate or Entity) with independent microservices.
•Each microservice should handle a single complete business function.
This section explores this process by applying these guidelines to the domain elements listed above for Game On!, as shown in Figure 2-1.
The Player service provides the resource APIs3 to work with Player entities. In addition to standard create, read, update, and delete operations, the Player API provides additional operations for generating user names and favorite colors, and for updating the player’s location.
The Map service provides the resource APIs4 to work with Site entities, allowing developers to manage the registration of room services with the game. The Map provides create, retrieve, update, and delete operations for individual Sites within a bounded context. Data representations inside the Map service differ from those shared outside the service, as some values are calculated based on the site’s position in the map.
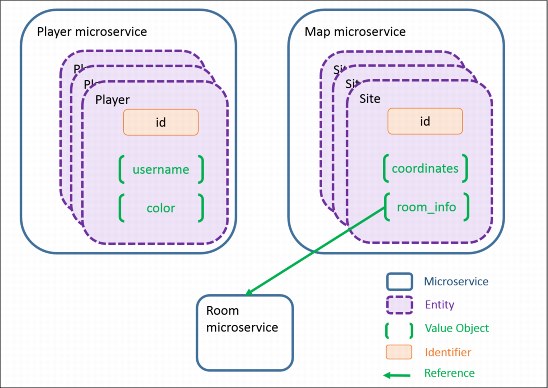
Figure 2-1 The Player and Map services
Some additional services from the game have not been discussed:
•Mediator: The Mediator is a service that splintered out of the first implementation of the Player service. Its sole responsibility is mediating between these WebSocket connections:
– One long running connection between the client device and the Mediator.
– Another connection between the Mediator and the target independent room service.
From a domain modeling point of view, the Mediator is a domain service.
•Rooms: What about individual room services? Developers stand up their own instances of rooms. For modeling purposes, treat rooms, even your own, as outside actors.
2.3.3 Application and service structure
Monolithic Java EE applications are typically structured and deployed in tiers (client, web, business, and data), with long lived application servers hosting web archives (WAR files), enterprise archives (EAR files), or both for disparate parts of an application, as shown in the left side of Figure 2-2. Naming and packaging conventions become important as JSPs, JSFs, servlets, and EJBs for different parts of the application are deployed to the same application server. Common data stores provide consistency for data representation, but also introduce constraints in how data can be represented and stored.

Figure 2-2 Order and Catalog Services as part of monolithic or microservices application
A microservices architecture will likely still have these application tiers, but the elements of each tier will likely be provided by independent services that run in independent processes, as shown in the right side of Figure 2-2. Note these details:
•The backend-for-frontend pattern is commonly used to support specialized behavior for 17
•specific front ends, like optimizations for specific devices or providing additional capabilities in a web application.
•Although each service owns and maintains its own data store, remember that the data store is itself an independent service.
Not all microservice applications will have all of these elements. For example, web applications that use JSPs or JSF, or interpreted scripts like PHP run in the backend. They could be considered as “backend-for-frontend”, especially if they have a close relationship with JavaScript running in the browser. Game On! however, does not use the backend-for-frontend pattern (at the time of this writing). The JavaScript single page web application is served as a set of static resources from an independent service. The application then runs in the browser, and calls backend APIs directly.
Internal structure
Structure your code inside a service so that you have a clear separation of concerns to facilitate testing. Calls to external services should be separate from the domain logic, which should also be separate from logic specific to marshalling data to/from a backing data service.
Figure 2-3 shows a simplified version of a microservice architecture. This architecture separates the domain logic from any code that interacts with or understands external services. The architecture is similar to the Ports and Adapters (Hexagonal) architecture5, and to Toby Clemson’s approach in “Testing Strategies in a Microservice Architecture”6.

Figure 2-3 The internal structure of a microservice
The example internal structure considers the following elements:
•Resources expose JAX-RS resources to external clients. This layer handles basic validation of requests and then passes the information into the domain logic layer.
•Domain logic, as a general concept, takes many forms. In Boundary-Entity-Control patterns, domain logic represents the entity itself, with parameter validation, state change logic, and so on.
•Repositories are optional, but can provide a useful abstraction between the core application domain logic and the data store when present. This configuration allows the backing data store to be changed or replaced without extensive changes to the domain logic.
•Service connectors are similar to the Repository abstraction, encapsulating communications with other services. This layer functions as either a façade or an “anti-corruption” layer to protect domain logic from changes to external resource APIs, or to convert between API wire formats and internal domain model constructs.
This architecture does require you to follow a few rules when creating classes. For example, each class that you use to implement your service should perform one of these tasks:
•Perform domain logic
•Expose resources
•Make external calls to other services
•Make external calls to a data store
These are general recommendations for code structure that do not have to be followed strictly. The important characteristic is to reduce the risk of making changes. For example, if you want to change the data store, you only need to update the repository layer. You do not have to search through every class looking for the methods that call the data store. If there are API changes to external services, these changes can similarly be contained within the service connector. This separation further simplifies testing, as described in Chapter 7, “Testing” on page 77.
2.3.4 Shared library or new service?
A common principle in both Agile and Object Oriented methodologies is “don’t repeat yourself” (DRY). Repeating the same code multiple times generally indicates that code should be turned into a reusable “thing.” In traditional OO, this thing is an object, or perhaps a utility class. However, especially in the case of ubiquitous utility classes, strict application of DRY principles is the end of neatly decoupled modules.
Microservices development makes this backsliding into code spaghetti more difficult. Hard process boundaries make oversharing of implementation details much harder, but sadly not impossible. So, what do you do with common code?
•Accept that there might be some redundancy
•Wrap common code in a shared, versioned library
•Create an independent service
Depending on the nature of the code, it might be best to accept redundant code and move on. Given that each service can and should evolve independently, the needs of the service over time might change the shape of that initially common code.
It is especially tempting to create shared libraries for Data Transfer Objects, which are thin classes that serve as vehicles to change to and from the wire transfer format (usually JSON). This technique can eliminate a lot of boiler plate code, but it can leak implementation details and introduce coupling.
Client libraries are often recommended to reduce duplication and make it easier to consume APIs. This technique has long been the norm for data stores, including new NoSQL data stores that provide REST-based APIs. Client libraries can be useful for other services as well, especially those using binary protocols. However, client libraries do introduce coupling between the service consumer and provider. The service may also be harder to consume for platforms or languages that do not have well-maintained libraries.
Shared libraries can also be used to ensure consistent processing for potentially complex algorithms. For Game On!, for example, a shared library is used to encapsulate request signing and signature verification, which is described in more detail in Chapter 6, “Application Security” on page 67. This configuration allows you to simplify services within the system and ensure that values are computed consistently. However, we do not provide a library for all languages, so some services still must do it the hard way.
When should a shared library really be an independent service? An independent service is independent of the language used, can scale separately, and can allow updates to take effect immediately without requiring coordinated updates to consumers. An independent service also adds extra processing, and is subject to all of the concerns with inter-service communication that are mentioned in Chapter 4, “Microservice communication” on page 33. It is a judgment call when to make the trade off, although if a library starts requiring backing services, that is generally a clue that it is a service in its own right.
2.4 Creating REST APIs
So, what does a good microservices API look like? Designing and documenting your APIs is important to ensure that it is useful and usable. Following conventions and using good versioning policies can make the API easier to understand and evolve over time.
2.4.1 Top down or bottom up?
When creating a service from scratch, you can either define the APIs that you need first and write your code to fulfill the APIs, or write the code for the service first and derive your APIs from the implementation.
In principle, the first option is always better. A microservice does not operate in isolation. Either it is calling something, or something is calling it. The interactions between services in a microservices architecture should be well defined and well documented. Concerning domain driven design, APIs are the known intersection points between bounded contexts.
As Alan Perlis says, “Everything should be built from the top down, except the first time7.” When doing a proof of concept, you might be unclear about what APIs you are providing. In those early days, write something that works to help refine ideas about what it is that you are trying to build. However, after you have a better understanding of what your service needs to do, you should go back and refine the domain model and define the external APIs to match.
2.4.2 Documenting APIs
Using tools to document your APIs can make it easier to ensure accuracy and correctness of the published documentation, which can then be used in discussions with API consumers. This documentation can also be used for your consumer driven contract tests (see Chapter 7, “Testing” on page 77).
The Open API Initiative (OAI)8 is a consortium focused on standardizing how RESTful APIs are described. The OpenAPI specification9 is based on Swagger10, which defines the structure and format of metadata used to create a Swagger representation of a RESTful API. This definition is usually expressed in a single, portable file (swagger.json by convention, though YAML is supported by using swagger.yaml). The swagger definition can be created by using visual editors or generated based on scanning annotations in the application. It can further be used to generate client or server stubs.
The apiDiscovery feature11 in WebSphere Application Server Liberty integrates support for Swagger definitions into the run time. It automatically detects and scans JAX-RS applications for annotations that it uses to generate a Swagger definition dynamically. If Swagger annotations are present, information from those annotations is included to create informative documentation that can be maintained inline with the code. This generated documentation is made available by using a system provided endpoint, as shown in Figure 2-4.

Figure 2-4 The user interface provided by the apiDisovery-1.0 feature to document APIs
The Swagger API definition, especially as rendered in a web interface, is useful for visualizing the external, consumer view of the API. Developing or designing the API from this external view helps ensure consistency. This external view aligns with Consumer Driven Contracts12, a pattern that advocates designing APIs with a focus on consumer expectations.
2.4.3 Use the correct HTTP verb
REST APIs should use standard HTTP verbs for create, retrieve, update, and delete operations, with special attention paid to whether the operation is idempotent (safe to repeat multiple times).
POST operations may be used to Create(C) resources. The distinguishing characteristic of a POST operation is that it is not idempotent. For example, if a POST request is used to create resources, and it is started multiple times, a new, unique resource should be created as a result of each invocation.
GET operations must be both idempotent and nullipotent. They should cause no side effects, and should only be used to Retrieve(R) information. To be specific, GET requests with query parameters should not be used to change or update information (use POST, PUT, or PATCH instead).
PUT operations can be used to Update(U) resources. PUT operations usually include a complete copy of the resource to be updated, making the operation idempotent.
PATCH operations allow partial Update(U) of resources. They might or might not be idempotent depending on how the delta is specified and then applied to the resource. For example, if a PATCH operation indicates that a value should be changed from A to B, it becomes idempotent. It has no effect if it is started multiple times and the value is already B. Support for PATCH operations is still inconsistent. For example, there is no @PATCH annotation in JAX-RS in Java EE7.
DELETE operations are not surprisingly used to Delete(D) resources. Delete operations are idempotent, as a resource can only be deleted once. However, the return code varies, as the first operation succeeds (200), while subsequent invocations do not find the resource (204).
2.4.4 Create machine-friendly, descriptive results
An expressive REST API should include careful consideration of what is returned from started operations. Given that APIs are started by software instead of by users, care should be taken to communicate information to the caller in the most effective and efficient way possible.
As an example, it used to be common practice to return a 200 (OK) status code along with HTML explaining the error message. Although this technique might work for users viewing web pages (for whom the HTTP status code is hidden anyway), it is terrible for machines determining whether their request succeeded.
The HTTP status code should be relevant and useful. Use a 200 (OK) when everything is fine. When there is no response data, use a 204 (NO CONTENT) instead. Beyond that technique, a 201 (CREATED) should be used for POST requests that result in the creation of a resource, whether there is a response body or not. Use a 409 (CONFLICT) when concurrent changes conflict, or a 400 (BAD REQUEST) when parameters are malformed. The set of HTTP status codes is robust, and should be used to express the result of a request as specifically as possible. For more information, see the following website:
You should also consider what data is being returned in your responses to make communication efficient. For example, when a resource is created with a POST request, the response should include the location of the newly created resource in a Location header. Yo do not need to return additional information about the resource in the response body. However, in practice the created resource is usually included in the response because it eliminates the need for the caller to make an extra GET request to fetch the created resource. The same applies for PUT and PATCH requests.
2.4.5 Resource URIs and versioning
There are varying opinions about some aspects of RESTful resource URIs. In general, resources should be nouns, not verbs, and endpoints should be plural. This technique results in a clear structure for create, retrieve, update, and delete operations:
POST /accounts Create a new item
GET /accounts Retrieve a list of items
GET /accounts/16 Retrieve a specific item
PUT /accounts/16 Update a specific item
PATCH /accounts/16 Update a specific item
DELETE /accounts/16 Delete a specific item
The general consensus is to keep things simple with URIs. If you create an application that tracks a specific kind of rodent, the URI would be /mouses/ and not /mice/, even if it makes you wince.
Relationships are modeled by nesting URIs, for example, something like /accounts/16/credentials for managing credentials associated with an account.
Where there is less agreement is with what should happen with operations that are associated with the resource, but that do not fit within this usual structure. There is no single correct way to manage these operations. Do what works best for the consumer of the API.
For example, with Game On!, the Player service provides operations that assist with generating user names and favorite colors. It is also possible to retrieve, in bulk, the location of every player within the game. The structure that was chosen reflects operations that span all players, while still allowing you to work with specific players. This techniques has its limitations, but illustrates the point:
GET /players/accounts Retrieve a list of all players
POST /players/accounts Create a new player
GET /players/accounts/{id} Retrieve a specific player
GET /players/accounts/{id}/location Retrieve a specific player’s location
PUT /players/accounts/{id}/location Update a specific player’s location
GET /players/color Return 10 generated colors
GET /players/name Return 10 generated names
GET /players/locations Retrieve the location of all players
Versioning
One of the major benefits of microservices is the ability to allow services to evolve independently. Given that microservices call other services, that independence comes with a giant caveat. You cannot cause breaking changes in your API.
The easiest approach to accommodating change is to never break the API. If the robustness principle is followed, and both sides are conservative in what they send and liberal in what they receive, it can take a long time before a breaking change is required. When that breaking change finally comes, you can opt to build a different service entirely and retire the original over time, perhaps because the domain model has evolved and a better abstraction makes more sense.
If you do need to make breaking API changes for an existing service, decide how to manage those changes:
•Will the service handle all versions of the API?
•Will you maintain independent versions of the service to support each version of the API?
•Will your service support only the newest version of the API and rely on other adaptive layers to convert to and from the older API?
After you decide on the hard part, the much easier problem to solve is how to reflect the version in your API. There are generally three ways to handled versioning a REST resource:
•Put the version in the URI
•Use a custom request header
•Put the version in the HTTP Accept header and rely on content negotiation
Put the version in the URI
Adding the version into the URI is the easiest method for specifying a version. This approach has these advantages:
•It is easy to understand.
•It is easy to achieve when building the services in your application.
•It is compatible with API browsing tools like Swagger and command-line tools like curl.
If you’re going to put the version in the URI, the version should apply to your application as a whole, so use, for example, /api/v1/accounts instead of /api/accounts/v1. Hypermedia as the Engine of Application State (HATEOAS) is one way of providing URIs to API consumers so they are not responsible for constructing URIs themselves. GitHub, for example, provides hypermedia URLs in their responses for this reason.13 HATEOAS becomes difficult if not impossible to achieve if different backend services can have independently varying versions in their URIs.
If you decide to place the version in your URI, you can manage it in a few different ways, partly determined by how requests are routed in your system. However, assume for a moment that your gateway proxy coverts the external /api/v1/accounts URI to /accounts/v1, which maps to the JAX-RS endpoint provided by your service. In this case, /accounts is a natural context root. After that you can either include the version in the @ApplicationPath annotation, as shown in Example 2-1, which works well when the application is supporting only one version of the API.
Example 2-1 Using the @ApplicationPath annotation to add the version to the URI
package retail_store.accounts.api;
@ApplicationPath("/v1")
public class ApplicationClass extends Application {}
Alternately, if the service should support more than one version of the application, you can push the version to @Path annotations, as shown in Example 2-2.
Example 2-2 The @ApplicationPath defines a rest endpoint without changing the URI
package retail_store.accounts.api.v1;
@ApplicationPath("/")
public class ApplicationClass extends Application {}
Example 2-3 shows the version added to the annotation.
Example 2-3 The version is added to the API using the @Path annotation
package retail_store.accounts.api.v1;
@Path("v1/accounts")
public class AccountsAPI {
@GET
@Path("{id}")
@Produces(MediaType.APPLICATION_JSON)
public Response getAccounts(@PathParam("id") String id) {
getId(id);
…
}
}
One of the arguments against including the version in the URL is a strict interpretation of the HTML standard that a URL should represent the entity and if the entity being represented didn’t change, the URL should not change.
Another concern is that putting versions in the URI requires consumers to update their URI references. This concern can be partly resolved by allowing requests to be made without a version, and then mapping those requests to the latest version. However, this approach is prone to unexpected behavior when the latest version changes.
Add a custom request header
You can add a custom request header to indicate the API version. Custom headers can be taken into consideration by routers and other infrastructure to route traffic to specific backend instances. However, this mechanism is not as easy to use for all of the same reasons that Accept headers are not easy to use. In addition, it is a custom header that only applies to your application, which means consumers need to learn how to use it.
Modify the Accept header to include the version
The Accept header is an obvious place to define a version, but is one of the most difficult to test. URIs are easy to specify and replace, but specifying HTTP headers requires more detailed API and command-line invocations.
Plenty of articles describe the advantages and disadvantages of all three methods. This blog post by Troy Hunt is a good place to start:
The following are the most important things to take away from this chapter:
•Design your APIs from the consumer point of view.
•Have a strategy for dealing with API changes.
•Use a consistent versioning technique across all of the services in your application.
3 https://game-on.org/swagger/#!/players Game On! Player API
4 https://game-on.org/swagger/#!/map Game On! Map API
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.