
Imagine you are in the middle of a stock transaction on the Internet and then the application hangs for more than half an hour. Or, it is Friday morning and you are running your quarter-end financial report, which is due Monday, and your system crashes and stays down for 96 hours. Or, you are doing a business transaction on a well-known web site and the server supporting it crashes, rendering the site unavailable for a prolonged time. Scenarios such as these are far more frequent than desirable and are incurring costs and decreasing productivity.
The following was from a financial news posted on the Netscape Web site not long ago:
Nasdaq will extend trading for one hour today, to 5 P.M. EDT, after a network problem forced the electronic stock market to temporarily suspend trading through the SelectNet and Small Order Execution System, or SOES.
Today marked the second day in a row and the third time this month that the Nasdaq has had problems with its execution system.
In this Internet age of network computing, one of the most critical quality attributes is system and network availability, along with reliability and security. Requirements for high availability by mission-critical operations have existed since society became reliant on computer technologies. In the Internet age, software code is distributed across networks and businesses increasingly share data, a lack of system availability is significantly increasing adverse impacts. In this chapter we discuss the definition and measurements of system availability, possible approaches to collecting customer’s outage data, and the ways to use customer’s data and availability metrics to drive improvement of the product.
Intuitively, system availability means the system is operational when you have work to do. The system is not down due to problems or other unplanned interruptions. In measurement terms, system availability means that the system is available for use as a percentage of scheduled uptime. The key elements of this definition include:
The frequency of system outages within the time frame for the calculation
The duration of outages
Scheduled uptime
The frequency of outages is a direct reliability statement. The duration of outages reflects the severity of the outages. It is also related to the recovery strategies, service responsiveness, and maintainability of the system. Scheduled uptime is a statement of the customer’s business requirements of system availability. It could range from 5 x 8 (5 days a weeks, 8 hours a day) to 7 x 24 (7 days a week, 24 hours a day) or 365 x 24 (365 days a year, 24 hours a day). Excluding scheduled maintenance, the 7 x 24 shops require continuous system availability. In today’s business computing environments, many businesses are 7 x 24 shops as far as system availability is concerned.
The inverse measurement of system availability is the amount of down time per system per time period (for example, per year). If scheduled up-time is known or is a constant (for example, for the 7 x 24 businesses), given the value of one measurement, the other can be derived. Table 1 shows some examples of system availability and hours in down time per system per year.
The 99.999% availability, also referred to as the “five 9s” availability, is the ultimate industry goal and is often used in marketing materials by server vendors. With regard to measurement data, a study of customer installations by the consulting firm Gartner Group (1998) reported that a server platform actually achieved availability of 99.998% (10 minutes downtime per year) via clustering solutions. For a single system, availability of that same server platform was at 99.90%. There were servers at 99.98% and 99.94% availability also. At the low end, there was a PC server platform with availability below 97.5%, which is a poor level in availability measurements. These are all known server platforms in the industry.
Table 13.1. Examples of System Availability and Downtime per System per Year
|
System Availability (%) (24 x 365 basis) |
Downtime per System per Year |
|---|---|
|
99.999 |
5.3 minutes |
|
99.99 |
52.6 minutes |
|
99.95 |
4.4 hours |
|
99.90 |
8.8 hours |
|
99.8 |
17.5 hours |
|
99.7 |
26.3 hours |
|
99.5 |
43.8 hours |
|
99.0 |
87.6 hours |
|
98.5 |
131.4 hours |
|
98.0 |
175.2 hours |
|
97.5 |
219.0 hours |
Business applications at major corporations require high levels of software quality and overall system availability. Servers with system availability less than 99.9%, which is the threshold value for high availability, may not be adequate to support critical operations. As reported in Business Week (“Software Hell,” 1999), at the New York Clearing House (NYCH), about $1.2 trillion in electronic interbank payments are cleared each day by two Unisys Corporation mainframe computer systems. The software was developed for operations that must not fail and the code is virtually bug-free. For the seven years prior to the Business Week report, NYCH had clocked just 0.01% downtime. In other words, its system availability was 99.99%. This kind of high-level availability is a necessity because if one of these systems is down for a day, its ramifications are enormous and banks consider it a major international incident. The same report indicated NYCH also has some PC servers that it uses mostly for simple communications programs. These systems were another story with regard to reliability and availability in that they crashed regularly and there was a paucity of tools for diagnosing and fixing problems.
In a study of cost of server ownership in enterprise relations management (ERM) customer sites, the consulting firm IDC (2001) compared the availability of three server platforms, which we relabeled as platforms A, B, and C for this discussion. The availability of these three categories of servers for ERM solutions are 99.98%, 99.67%, and 99.90%, respectively. Since system availability has a direct impact on user productivity, IDC called the availability-related metrics productivity metrics. Table 13.2 shows a summary of these metrics. For details, see the original IDC report.
Table 13.2. Availability-Related Productivity Metrics for Three Server Platforms for ERM Solutions
|
User Productivity |
Platform A Solution |
Platform B Solution |
Platform C Solution |
|---|---|---|---|
|
From IDC white paper, “Server Cost of Ownership in ERM Customer Sites: A Total Cost of Ownership Study,” by Jean S. Bozman and Randy Perry. Copyright © 2001, IDC, a market intelligence research firm. Reprinted with permission. | |||
|
Unplanned Downtime Hours per Month |
0.24 |
2.7 |
1 |
|
Percent of Internal Users Affected |
42 |
63 |
53 |
|
Unplanned User Downtime (Hours per Year/100 Users) |
1,235 |
20,250 |
6,344 |
|
Availability (%) |
99.98 |
99.67 |
99.9 |
System availability or platform availability is a combination of hardware and software. The relationship between system availability and component availability is an “AND” relationship, not an “OR” relationship. To achieve a certain level of system availability, the availability of the components has to be higher. For example, if the availability of a system’s software is 99.95% and that of the hardware is 99.99%, then the system availability is 99.94% (99.99% x 99.95%).
In Chapter 1 we discussed software quality attributes such as capability, usability, performance, reliability, install, maintainability, documentation, and availability (CUPRIMDA) and their interrelations. Reliability and availability certainly support each other. Indeed, among the pair-relationships of quality attributes, this pair is much more strongly related than others. Without a reliable product, high availability cannot be achieved.
The operational definition of reliability is mean time to failure (MTTF). For the exponential distribution, the failure rate (or better called the instantaneous failure rate) (λ) is constant and MTTF is an inverse of it. As an example, suppose a company manufactures resistors that are known to have an exponential failure rate of 0.15% per 1,000 hours. The MTTF for these resistors is thus the inverse of .15%/1000 hours (or 0.0000015), which is 666,667 hours.
The F in MTTF for reliability evaluation refers to all failures. For availability measurement of computer systems, the more severe forms of failure (i.e., the crashes and hangs that cause outages) are the events of interest. Mean time to system outage, a reliability concept and similar to MTTF calculation-wise, is a common availability measurement. As an example, if a set of systems has an average of 1.6 outages per system per year, the mean time to outage will be the inverse of 1.6 system-year, which is 0.625 years.
As discussed earlier, in addition to the frequency of outages, the duration of outage is a key element of measuring availability. This element is related to the mean time to repair (MTTR) or mean time to recovery (average downtime) measurement. To complete the example in the last paragraph, suppose the average downtime per outage for a set of customers was 1.5 hours, the average downtime per system per year was 2.3 hours, and the total scheduled uptime for the systems was 445,870 hours, the system availability would be 99.98%.
Because of the element of outage duration, the concept of availability is different from reliability in several aspects. First, availability is more customer-oriented. With the same frequencies of failures or outages, the longer the system is down, the more pain the customer will experience. Second, to reduce outage duration, other factors such as diagnostic and debugging tools, service and fix responsiveness, and system backup/recovery strategies play important roles. Third, high reliability and excellent intrinsic product quality are necessary for high availability, but may not be sufficient. To achieve high availability and to neutralize the impact of outages often requires broader strategies such as clustering solutions and predictive warning services. Indeed, to achieve high availability at the 99.99% (52.6 minutes of downtime per year) or 99.999% level (5.2 minutes of downtime per year), it would be impossible without clustering or heavy redundancy and support by a premium service agreement. Predictive warning service is a comprehensive set of services that locally and electronically monitor an array of system events. It is designed to notify the customer and the vendor (service provider) of possible system failures before they occur. In recent years several vendors began offering this kind of premium service as a result of the paramount importance of system availability to critical business operations.
Over the years, many technologies in hardware and software have been and are being developed and implemented to improve product reliability and system availability. Some of these technologies are:
□ Redundant array of inexpensive disks (RAID)
□ Mirroring
□ Battery backup
□ Redundant write cache
□ Continuously powered main storage
□ Concurrent maintenance
□ Concurrent release upgrade
□ Concurrent apply of fix package
□ Save/restore parallelism
□ Reboot/IPL (initial program load) speed
□ Independent auxiliary storage pools (I-ASP)
□ Logical partitioning
□ Clustering
□ Remote cluster nodes
□ Remote maintenance
Where data breakout is available, of the outages affecting system availability, software normally accounts for a larger proportion than hardware. As the Business Week report (1999) indicates, a number of infamous Web site and server outages were due to software problems. Software development is also labor intensive and there is no commonly recognized software reliability standard in the industry.
Both reliability (MTTF) and defect rate are measures of intrinsic product quality. But they are not related in terms of operational definitions; that is, MTTF and defects per KLOC or function point are not mathematically related. In the software engineering literature, the two subjects are decoupled. The only relationship between defect levels and ranges of MTTF values reported in the literature (that we are aware of) are by Jones (1991) based on his empirical study several decades ago. Table 13.3 shows the corresponding values for the two parameters.
Jones’s data was gathered from various testing phases, from unit test to system test runs, of a systems software project. Size of the project is a key variable because it could provide crude links between defects per KLOC and total number of defects, and therefore possibly to the volume of defects and frequency of failures. But this information was not reported. However, this relationship is very useful because it is based on empirical data on systems software. This area clearly needs more research with a large amount of empirical studies.
Table 13.3. Association Between Defect Levels and MTTF Values
|
Defects per KLOC |
MTTF |
|---|---|
|
Source: From Applied Software Measurement: Assuring Productivity and Quality, by Capers Jones (Table on MTTF Values, p. 282). Copyright © 1991. Reprinted by permission of The McGraw-Hill Companies, Inc., New York. | |
|
More than 30 |
Less than 2 minutes |
|
20–30 |
4–15 minutes |
|
10–20 |
5–60 minutes |
|
5–10 |
1–4 hours |
|
2–5 |
4–24 hours |
|
1–2 |
24–160 hours |
|
Less than 1 |
Indefinite |
The same Business Week report (“Software Hell,” 1999) indicates that according to the U.S. Defense Department and the Software Engineering Institute (SEI) at Carnegie Mellon University, there are typically 5 to 15 flaws per KLOC in typical commercial software. About a decade ago, based on a sample study of U.S. and Japanese software projects by noted software developers in both countries, Cusumano (1991) estimated that the failure rate per KLOC during the first 12 months after delivery was 4.44 in the United States and 1.96 in Japan. Cusumano’s sample included projects in the areas of data processing, scientific, systems software, telecommunications, and embedded/real time systems. Based on extensive project assessments and benchmark studies, Jones (2001) estimates the typical defect rate of software organizations at SEI CMM level 1 to be 7.38 defects per KLOC (0.92 defects per function point), and those at SEI CMM level 3 to be 1.30 defects per KLOC (0.16 defects per function point). For the defect rates per function point for all CMM levels, see Jones (2000) or Chapter 6 in which we discuss Jones’s findings. Per IBM customers in Canada, this writer was told that the average defect rate of software in Canada a few years ago, based on a survey, was 3.7 defects per KLOC. Without detailed operational definitions, it is difficult to draw meaningful conclusions on the level of defect rate or failure rate in the software industry with a certain degree of confidence. The combination of these estimates and Jones’s relation between defect level and reliability, however, explains why there are so many infamous software crashes in the news. Even though we take these estimates as “order of magnitude” estimates and allow large error margins, it is crystal clear that the level of quality for typical software is far from adequate to meet the availability requirements of businesses and safety-critical operations. Of course, this view is shared by many and has been expressed in various publications and media (e.g., “State of Software Quality,” Information Week, 2001).
Based on our experience and assessment of available industry data, for system platforms to have high availability (99.9+%), the defect rate for large operating systems has to be at or below 0.01 defect per KLOC per year in the field. In other words, the defect rate has to be at or beyond the 5.5 sigma level. For new function development, the defect rate has to be substantially below 1 defect per thousand new and changed source instructions (KCSI). This last statistic seems to correlate with Jones’s finding (last row in Table 13.3). To achieve good product quality and high system availability, it is highly recommended that in-process reliability or outage metrics be used, and internal targets be set and achieved during the development of software. Before the product is shipped, its field quality performance (defect rate or frequency of failures) should be estimated based on the in-process metrics. For examples of such in-process metrics, refer to the discussions in Chapters 9 and 10; for defect removal effectiveness during the development process, refer to Chapter 6; for projection and estimation of field quality performance, refer to Chapters 7 and 8.
In addition to reducing the defect rate, any improvements that can lead to a reduction in the duration of downtime (or MTTR) contribute to availability. In software, such improvements include, but are not limited to, the following features:
Product configuration
Ease of install and uninstall
Performance, especially the speed of IPL (initial program load) or reboot
Error logs
Internal trace features
Clear and unique messages
Other problem determination capabilities of the software
How does one collect customer outage data to determine the availability level of one’s product (be it software, hardware, or a server computer system including hardware and software) and use the data to drive quality improvement? There are at least three approaches: collect the data directly from a small core set of customers, collect the data via your normal service process, and conduct special customer surveys.
Collecting outage data directly from customers is recommended only for a small number of customers. Otherwise, it would not be cost-effective and the chance of success would be low. Such customers normally are key customers and system availability is particularly important to them. The customers’ willingness to track outage data accurately is a critical factor because this is a joint effort. Examples of data collection forms are shown in Figures 13.1 and 13.2. The forms gather two types of information: the demographics of each system (Figure 13.1) and the detailed information and action of each outage (Figure 13.2). These forms and data collection can also be implemented in a Web site.

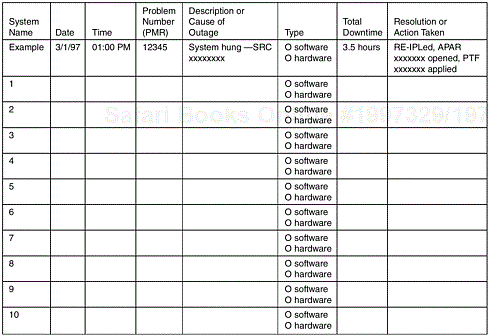
The raw data gathered via the two forms is sufficient to derive the following indicators:
Scheduled hours of operations (uptime)
Equivalent system years of operations
Total hours of downtime
System availability
Average outages per system per year
Average downtime (hours) per system per year
Average time (hours) per outage
The value of these metrics can be estimated every month or every quarter, depending on the amount of data available (i.e., sufficient number of equivalent system years of operations for each period). Trends of these metrics can be formed and monitored, and correlated with the timing of new releases of the product, or special improvement actions.
With more data, one can analyze the causes of outages, identify the problem components of the system, and take systematic improvement actions. Note that in the form in Figure 13.2, the problem management record (PMR) number should be used to link the outage incident to the customer problem record in the normal service process. Therefore, in-depth data analysis can be performed to yield insights for continual improvement.
Figure 13.3 shows a hypothetical example of the contribution of software components to the unavailability of a software system. In this case, component X of the system accounted for the most outages and downtime. This is likely an indication of poor intrinsic product quality. On the other hand, component Y accounts for only two incidents but the total downtime caused by these two outages are significant. This may be due to issues related to problem determination or inefficiencies involved in developing and delivering fixes. Effective improvement actions should be guided by these metrics and results from causal analyses.

The second way to obtain customer outage data is via the normal service process. When a customer experiences a problem and calls the support center, a call record or problem management record (PMR) is created. A simple screening procedure (e.g., via a couple of standard questions) can be established with the call record process to identify the outage-related customer calls. The total number of licenses of the product in a given time period can be used as a denominator. The rate of outage-related customer problem calls normalized to the number of license data can then be used to form some indicator of product outage rate in the field. Because this data is from the service problem management records, all information gathered via the service process is available for in-depth analysis.
Figure 13.4 shows an example of the outage incidence rate (per 1000 systems per year) for several releases of a software system over time, expressed as months after the delivery of the releases. None of the releases has complete data over the 48-month time span. Collectively, the incidence curves show a well-known pattern of the exponential distribution. Due to the fluctuations related to small numbers in the first several months after delivery, initially we wondered whether the pattern would follow a Rayleigh model or an exponential model. But with more data points from the last three releases, the exponential model became more convincing and was confirmed by a statistical goodness-of-fit test.
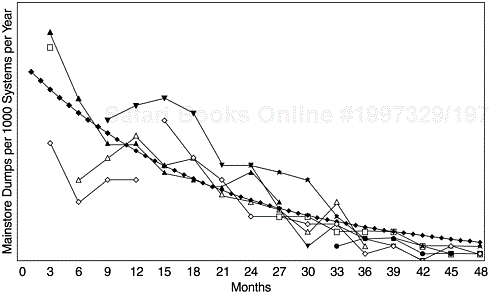
We note that outage data from the service process is related to the frequencies of outages and their causes. However, the outage duration data is usually not available because it would require a two-pass process that is expensive to implement— following up with the customers and requesting duration data when the problem is resolved. Because of this, the metric derived from this data (such as the example in Figure 13.4) pertains more to the reliability concept instead of the system availability. Nonetheless, it is also an availability measurement because the numerator data is outages. The delineation between reliability and availability in this case becomes blurred.
The third approach to collecting customer outage information is through special customer surveys, which have several advantages. First, through sampling designs, one can get a representative and sufficiently large sample of one’s entire customer set. Second, the survey can cover related topics in addition to outage information per se, such as customers’ maintenance practices, scheduled downtime, scheduled uptime, satisfaction with system availability, and specific elements that contribute to system availability. Responses from these related topics can provide useful information for the product vendor with regard to its improvement strategies and customer relationship management. Third, surveys are cost-effective. On the other hand, a major drawback of the survey approach is that the accuracy of the quantitative outage data is not likely as good as that of the previous approaches. If the customers didn’t have regular outage tracking in place, their responses might be based on recollection and approximation. Another limitation is that survey data is not adequate for root cause analysis because it is not meant to provide in-depth information of specific outage incidents.
Our experience is that special customer surveys can provide useful information for the overall big picture and this approach is complementary to the other approaches. For example, a representative survey showed that the customers’ profile of scheduled uptime (number of hours per week) for a software system is as follows:
40 hours: 11%
41–80 hours: 17%
81–120 hours: 8%
121–160 hours: 11%
168 hours (24 x 7): 53%
It is obvious from this profile that the customers of this software would demand high availability. When this data is analyzed together with other variables such as satisfaction with system availability, maintenance strategy, type of business, types of operations the software is used for, and potential of future purchases, the information will be tremendously useful for the product vendor’s improvement plans.
To improve product reliability and availability, sound architecture and good designs are key. Root causes and lessons learned from customer outages in the field can be used to improve the design points for the next release of the product. In terms of in-process metrics when the product is under development, however, we don’t recommend premature tracking of outages and availability during the early phases of testing. Such tracking should be done during the product-level testing or during the final system test phase in a customerlike environment. During early phases of testing, the defect arrival volume is high and the objective is to flush out the functional defects before the system stabilizes. Tracking and focus at these phases should be on testing progress, defect arrivals, and defect backlog. When the system is achieving good stability, normally during the final phase of testing, metrics for tracking system availability become meaningful. In Chapter 10, we discuss and recommend several metrics that measure outages and availability: number and trend of system crashes and hangs, CPU utilization, and Mean Time to unplanned IPL (initial program load, or reboot). While some metrics may require tools, resources, and a well-established tracking system, tracking the system crashes and hangs can be done by paper and pencil, and can be implemented easily by small teams.
For projects that have a beta program, we recommend tracking customer outages in beta, especially those customers who migrated their production runs to the new release. The same focus as the field outages should be applied to these outages during the beta program. Outages during the beta program can also be used as a predictive indicator of the system outages and availability in the field after the product is shipped. The difference is that during beta, there are still chances to take improvement actions before the product is made available to the entire customer population. We have experience in tracking system crashes during customer beta for several years. Due to small numbers, we haven’t established a parametric correlation be-tween beta outages and field outages yet. But using nonparametric (rank-order) correlation methods and comparing releases, we did see a positive correlation between the two—the more crashes during beta, the more outages and less system availability in the field.
In this chapter we discuss the definition and measurements of system availability. System availability is perhaps one of the most important quality attributes in the modern era of Internet and network computing. We reference a couple of industry studies to show the status of system availability. We explore the relationships among reliability, availability, and the traditional defect level measurement in software development. The concept and measurement of availability is broader than reliability and defect level. It encompasses intrinsic product quality (reliability or defect level), customer impact, and recovery and maintenance strategies. System availability is a customer-oriented concept and measure.
It is clear that the current quality of typical software is far from adequate in meeting the requirements of high availability by businesses and the society.
There are several ways to collect customer outage data for quality improvement: direct customer input, data from the service process, and special customer surveys. Root cause analyses of customers’ outages and a process similar to the defect prevention process (discussed in Chapter 2), are highly recommended as key elements of an outage reduction plan. Quality improvement from this process should include both corrective actions for the current problems and preventive actions for long-term outage reduction.
Finally, to complete the closed-loop process in our discussions, we cite several in-process metrics that are pertinent to outage and availability. We highly recommend that the tracking of system crashes and hangs during the final test phase be adopted by all projects. This is a simple and critical metric and can be implemented in different ways, ranging from complicated automated tracking to paper and pencil, by large as well as small teams.