
SQL Query Tuning
The data in your database is stored on your disk. Retrieving and updating the data is ultimately a series of disk input/output operations (I/Os). The goal of SQL query tuning is to minimize the number of I/Os. Your main weapon for tuning your queries is the index.
In the absence of indexes on your database tables, each retrieval would require that all the data in all of the involved tables be scanned. To illustrate this problem, consider the following example:
SELECT name FROM Employee WHERE ssnum = 999999999
In this example, we select the name of an employee from the
Employee table for the employee with 999-99-9999
as a social security number (ssnum). We know the
social security number should be unique. In other words, for each
record in the table, ssnum will have a unique
value. We thus expect a single row from the above query since only
one row can have the social security number of 999-99-9999.
Because the Employee table in our example has no
indexes, MySQL does not know that the query will return a single
record. When it executes the query, it has to scan the entire table
to find all the records that match the WHERE
clause—a scan of the entire table for the one record with a
social security number of 999-99-9999. If the
Employee table has a thousand rows, MySQL will
read each and every one of those rows to compare the
ssnum value to the constant 999999999. This
operation is linear with the number of rows in the table.
An index is a tool for telling MySQL critical information about the
table. If, for example, we add an index on the
ssnum column of the Employee
table, MySQL can consult the index first to find matching
ssnum values. In this case, the index sorts rows
by ssnum and organizes them into a tree structure
that helps MySQL find the records quickly. After it finds the
matching records, it simply has to read the name
data for each match. This operation is logarithmic with respect to
the number of rows in the table—a significant improvement over
the linear performance of an unindexed table.
Just as in this example, most MySQL query tuning boils down to a process of ensuring that you have the right indexes on your tables and that they are being used correctly by MySQL.
Index guidelines
We have established that the proper indexing of your tables is crucial to the performance of your application. The knee-jerk reaction might be to index every column in each table of your database. After all, indexing improves performance, right?
Unfortunately, indexes also have costs associated with them. Each
time you write to a table—i.e., INSERT,
UPDATE, or DELETE—with
one or more indexes, MySQL also has to update each index. Each index
thus adds overhead to all write operations on that table. In
addition, each index adds to the size of your database. You will gain
a performance benefit from an index only if its columns are
referenced in a WHERE clause. If an index is never
used, it is not worth incurring the cost of maintaining it.
If an index is used infrequently, it may or may not be worth maintaining. If, for example, you have a query that is run monthly that takes two minutes to complete without indexes, you may decide that, because the query is run so infrequently, it is not worth the index maintenance costs. On the other hand, if the monthly query takes several hours to complete, you would probably decide that maintaining the indexes is worth it. These kinds of decisions have to be made to balance the needs of your application.
With these trade-offs in mind, here are some guidelines for index creation:
- Try to index all columns referenced in a WHERE clause
As a general goal, you want any column that is referenced in a
WHEREclause to be indexed. There are, however, exceptions. If columns are compared or joined using the<,<=,=,>=,>, andBETWEENoperators, the index is used. But use of a function on a column in aWHEREclause defeats an index on that column. So, for example:SELECT * FROM Employee WHERE LEFT(name, 6) = 'FOOBAR'
would not take advantage of an index on the
namecolumn.The
LIKEoperator, on the other hand, will use an index if there is a literal prefix in the pattern. For example:SELECT * FROM Employee WHERE name LIKE 'FOOBAR%'
would use an index, but the following would not:
SELECT * FROM Employee WHERE name LIKE '%FOOBAR'
Also, as discussed earlier, it is important to note that you should not blindly index every column that is referenced in a
WHEREclause. The cost of maintaining the index should be balanced by the performance benefits.- Use unique indexes where possible
If you know the data in an index is unique, such as a primary key or an alternate key, use a unique index. Unique indexes are even more beneficial for performance than regular indexes. MySQL is able to leverage its knowledge that the value is unique to make more optimization assumptions.
- Take advantage of multicolumn indexes
Well-designed multicolumn indexes can reduce the total number of indexes needed. MySQL will use a left prefix of a multicolumn index if applicable. Say, for example, you have an
Employeetable with the columnsfirst_nameandlast_name. If you know thatlast_nameis always used in queries whilefirst_nameis used only occasionally, you can create a multicolumn index withlast_nameas the first column andfirst_nameas the second column. With this index design, all queries withlast_nameor queries withlast_nameandfirst_namein theWHEREclause will use the index.Poorly designed multicolumn indexes may end up either not being used at all or being used infrequently. From the example above, queries with only
first_namein theWHEREclause will not use the index.Having a strong understanding of your application and probable query scenarios is invaluable in determining the right set of multicolumn indexes. Always verify your results with the
EXPLAIN SELECTtool (described later in the chapter).- Consider not indexing some columns
Sometimes performing a full table scan is faster than having to read the index and the data table. This is especially true for cases in which the indexed column contains a small set of evenly distributed data. The classic example of this is gender, which has two values (male and female) that are evenly split. Selecting by gender requires you to read roughly half of the rows. It might be faster to do a full table scan in this case. As always, test your application to see what works best for you.
EXPLAIN SELECT
MySQL
provides a critical
performance-tuning tool in
the form of the EXPLAIN SELECT command. As a
general rule, you should never deploy an application without running
its queries through this utility to verify that they are executing as
expected. This tool specifically tells you:
How queries are using (or are failing to use) indexes
The order in which tables are being joined
It shows you exactly how MySQL is executing your query and gives you clues about how the query performance can be improved.
Before going into the details of EXPLAIN SELECT,
it is important to understand how MySQL compiles and executes SQL queries. The
processing of a query can be broken up into several phases, as
described in Figure 5-1.
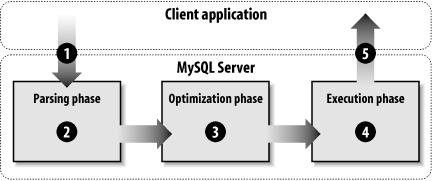
This model is a simplification of what really goes on in the MySQL server when it processes a query. Nonetheless, it is useful when discussing the process of query optimization to understand at a high level what is happening. Now, on to the phases:
The query is sent to the server. All query processing is initiated by the client sending a query to the server.
The parsing phase. During this phase, MySQL parses the SQL query for syntax correctness. In addition, it ensures that all referenced tables and columns are valid.
The optimization phase. During this phase, MySQL takes the information gathered during the parsing phase and generates an execution plan to satisfy the query. It considers all the information it knows about the relevant tables and columns and applies its internal optimization rules to generate an execution plan that should satisfy the query the fastest. Note that none of the tables or indexes are actually accessed here. Phases 2 and 3 are commonly called compilation.
The execution phase. In the execution phase, MySQL takes the query plan generated in the optimization phase and executes it. An important thing to note is that during the execution phase, MySQL will not adjust the query plan. So even if the optimization phase produces a flawed plan, it will be executed anyway.
The results are sent to the client. After the query has completed, the results are sent back to the client.
The execution of any query therefore hinges on the plan generated during the optimization phase. The key to improving the performance of any query is to understand the query plan that MySQL is using to satisfy that query. The query optimization is performed by a piece of very sophisticated software. Like any other software, it uses internal rules and assumptions to do its job. Usually it does a great job, but sometimes the plans it generates can be improved.
EXPLAIN SELECT helps us see the query plan so that
we can improve it. It gives us a way to see the query plan so that we
can see where the plan might be flawed.
For example, consider a database with a State
table and a query to retrieve the state_name based
on the code, state_cd.
mysql> SELECT state_name FROM State WHERE state_cd = 'CA';
+------------+
| state_name |
+------------+
| California |
+------------+
1 row in set (0.00 sec)To use EXPLAIN SELECT, we simply prepend the
EXPLAIN keyword to the query. MySQL
won’t execute the query; instead, it will produce
output describing the plan for executing the query. For example:
mysql> EXPLAIN SELECT state_name FROM State WHERE state_cd = 'CA';
+-------+------+---------------+------+---------+------+------+------------+
| table | type | possible_keys | key | key_len | ref | rows | Extra |
+-------+------+---------------+------+---------+------+------+------------+
| State | ALL | NULL | NULL | NULL | NULL | 50 | where used |
+-------+------+---------------+------+---------+------+------+------------+
1 row in set (0.00 sec)This output is simply a set of steps to be performed in order during
the execution phase. In our simple example, there is only one step.
We will look at some more complicated query plans later. First, we
should look at the columns returned by EXPLAIN
SELECT and what they mean:
-
table The table to which the row of output refers. In queries with multiple tables,
EXPLAIN SELECTwill return a row for each table.-
type The join type. Possible join types are listed below, ranked fastest to slowest:
-
system The table is a system table with only one row. This is a special case of the
constjoin type.-
const The table has at most one matching row, can be read once, and is treated as a constant for the remainder of query optimization. A
constquery is fast because the table is read only once.-
eq_ref No more than one row will be read from this table for each combination of rows from previous tables. This type is used when all columns of an index are used in the query, and the index is
UNIQUEor aPRIMARY KEY.-
ref All matching rows will be read from this table for each combination of rows from previous tables. This is used when an index is neither
UNIQUEnor aPRIMARY KEY, or if a left subset of index columns is used in the query.-
range Only rows in a given range will be retrieved from this table, using an index to select the rows.
-
index A full scan of the index will be performed for each combination of rows from previous tables. This is the same as an
ALLjoin type except only the index is scanned.-
ALL A full scan of the table will be performed for each combination of rows from previous tables.
ALLjoins should be avoided by adding an index.
-
-
possible_keys possible_keyslists which indexes MySQL could use to find the rows in this table. When there are no relevant indexes,possible_keysisNULL. This indicates that you can improve the performance of your query by adding an index.-
key keylists the actual index that MySQL chose. It isNULLif no index was chosen.-
key_len key_lenlists the length, in bytes, of the index that MySQL chose. This can be used to determine how many parts of a multicolumn index MySQL chose to use.-
ref reflists which columns or constants are used to select rows from this table.-
rows rowslists the number of rows that MySQL thinks it will have to examine from this table to execute the query.-
Extra Extralists more information about how a query is resolved. Possible values are:-
distinct After MySQL has found the first matching row, it will stop searching in this table.
-
not exists MySQL was able to do a left join optimization of the query.
-
range checked for each record (index map: #) MySQL was not able to identify a suitable index to use. For each combination of rows from the previous tables, it will look for an index to use. This is not ideal, but should be faster than using no index at all.
-
using filesort MySQL has to sort the rows before retrieving the data.
-
using index All needed information is available in the index, so MySQL doesn’t need to read any data from the table.
-
using temporary MySQL has to create a temporary table to resolve the query. This occurs if you use
ORDER BYandGROUP BYon different sets of columns.-
where used The
WHEREclause will be used to restrict the rows returned from this table.
-
A detailed example will help illustrate how to use EXPLAIN
SELECT to optimize a query. Even though
SELECT queries are referred to in this section,
these guidelines apply to UPDATE
and DELETE statements
as well. INSERT statements do not need to be
optimized unless they are INSERT...SELECT
statements. Even in the case of INSERT...SELECT
statements, it is still the SELECT statement that
you are optimizing.
For this example, we use a State table, which
includes data about all 50 U.S. states.
mysql> DESCRIBE State;
+------------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+----------+------+-----+---------+-------+
| state_id | int(11) | | | 0 | |
| state_cd | char(2) | | | | |
| state_name | char(30) | | | | |
+------------+----------+------+-----+---------+-------+
3 rows in set (0.00 sec)To get the name for the state of California (the state matching the
code CA):
SELECT state_name FROM State WHERE state_cd = 'CA';
Running EXPLAIN SELECT, we can discover how the
query will be executed:
mysql> EXPLAIN SELECT state_name FROM State where state_cd = 'CA';
+-------+------+---------------+------+---------+------+------+------------+
| table | type | possible_keys | key | key_len | ref | rows | Extra |
+-------+------+---------------+------+---------+------+------+------------+
| State | ALL | NULL | NULL | NULL | NULL | 50 | where used |
+-------+------+---------------+------+---------+------+------+------------+
1 row in set (0.00 sec)The join type ALL tells us that MySQL will scan
all rows in the State table to satisfy the query.
In other words, MySQL will read each of the rows in the table and
compare it to the WHERE clause criteria
(state_cd
=
'CA'). The rows column tells us
that MySQL estimates it will have to read 50 rows to satisfy the
query, which is what we would expect since there are 50 states.
We can definitely improve on this performance. Because
state_cd is being used in a
WHERE clause, we can put an index on it and rerun the
EXPLAIN
SELECT to check its
impact on performance:
mysql> CREATE INDEX st_idx ON State ( state_cd ); . . mysql> EXPLAIN SELECT state_name FROM State WHERE state_cd = 'CA'; +-------+------+---------------+--------+---------+-------+------+------------+ | table | type | possible_keys | key | key_len | ref | rows | Extra | +-------+------+---------------+--------+---------+-------+------+------------+ | State | ref | st_idx | st_idx | 2 | const | 1 | where used | +-------+------+---------------+--------+---------+-------+------+------------+
The
key column indicates
that MySQL has decided to use the new index. Consequently, the
processing of our query has been reduced from 50 rows to one.
The index on the state_cd column provided MySQL
some more information to be used during the optimization phase. MySQL
uses the st_idx index to find the rows that match
the WHERE clause criteria. Because the index is
sorted, MySQL can quickly locate the matching row. Each row in the
index provides a pointer back to its corresponding row in the table.
Once MySQL locates the rows in the index, it knows exactly which rows
to read from the table to satisfy the query.
In the first (non-indexed) case, MySQL had to read each row in the table and compare it to the criteria to find the matching row. In the second (indexed) case, MySQL exploits the sorted index to locate the matching records, then read the matching row from the table—a much faster operation.
For a more complex operation, suppose we have the following
City table:
mysql> DESCRIBE City;
+-----------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+----------+------+-----+---------+-------+
| city_id | int(11) | | | 0 | |
| city_name | char(30) | | | | |
| state_cd | char(2) | | | | |
+-----------+----------+------+-----+---------+-------+For the sake of this example, our database is populated with 50
cities for each state for a total of 2,500. We will also go back to
the original State table with no indexes. The
following query looks for the state in which San Francisco is
located:
mysql> SELECT state_name FROM State, City -> WHERE city_name = "San Francisco" -> AND State.state_cd = City.state_cd;
The EXPLAIN SELECT command tells us about this
query:
mysql> EXPLAIN SELECT state_name FROM State, City WHERE city_name = -> "San Francisco" AND State.state_cd = City.state_cd; +-------+------+---------------+------+---------+------+------+------------+ | table | type | possible_keys | key | key_len | ref | rows | Extra | +-------+------+---------------+------+---------+------+------+------------+ | State | ALL | NULL | NULL | NULL | NULL | 50 | | | City | ALL | NULL | NULL | NULL | NULL | 2500 | where used | +-------+------+---------------+------+---------+------+------+------------+
This query plan now has two steps. The first step indicates that
MySQL will read each row in the State table. This
is indicated by the query type of ALL. It also
tells us that MySQL estimates that it will read 50 rows. The second
step indicates that for each of those 50 rows, MySQL will then read
each of the 2,500 rows in the City table and look
for a city named “San Francisco.”
This means that it will read a total of 125,000 (50 x
2,500) rows and compare each of them to the criteria before it can
satisfy the query. This situation is obviously not ideal! Because we
have some columns in the WHERE clause that are not
indexed, we should be able to improve it. The first index is, of
course, the original state code index we created earlier in the
chapter:
mysql> CREATE UNIQUE INDEX st_cd ON State (state_cd);The query now has a better query plan:
mysql> EXPLAIN SELECT state_name FROM State, City WHERE city_name = -> "San Francisco" AND State.state_cd = City.state_cd; +-------+--------+---------------+-------+---------+--------------+------+----- | table | type | possible_keys | key | key_len | ref | rows | Extr +-------+--------+---------------+-------+---------+--------------+------+----- | City | ALL | NULL | NULL | NULL | NULL | 2500 | wher | State | eq_ref | st_idx | st_idx| 2 | city.state_cd| 1 | wher +-------+--------+---------------+-------+---------+--------------+------+-----
We still have two steps, but now MySQL is reading each row in the
City table and comparing it to the
WHERE clause criteria. Once it finds the matching
rows, it performs step two to join it with the
State table based on the state code.
This one index has greatly improved the situation. MySQL will now
read only one state for each city. If we add an index on the
city_name column, that should do away with the
ALL join type for the City
table.
mysql> CREATE INDEX city_idx ON City ( city_name ); . . mysql> EXPLAIN SELECT state_name FROM State, City WHERE city_name = -> "San Francisco" AND State.state_cd = City.state_cd; +-------+------+---------------+----------+---------+--------------+----+------ | table | type | possible_keys | key | key_len | ref |rows| Extra +-------+------+---------------+----------+---------+--------------+----+------ | City | ref | city_idx | city_idx | 30 | const | 1 | where | State | ref | st_idx | st_idx | 2 | City.state_cd| 1 | where +-------+------+---------------+----------+---------+--------------+----+------
By adding two indexes, we have gone from 125,000 rows read to two. This example illustrates the dramatic difference that indexes can make.
A query for all the cities in California shows extra complexity:
mysql> EXPLAIN SELECT city_name FROM City, State WHERE City.state_cd -> = State.state_cd and State.state_cd = 'CA'; +-------+------+---------------+--------+---------+-------+------+------------- | table | type | possible_keys | key | key_len | ref | rows | Extra +-------+------+---------------+--------+---------+-------+------+------------- | state | ref | st_idx | st_idx | 2 | const | 1 | where used; | | | | | | | | Using index | city | ALL | NULL | NULL | NULL | NULL | 2500 | where used +-------+------+---------------+--------+---------+-------+------+-------------
We have a new problem because MySQL plans to scan all 2,500 cities.
It takes this action because it cannot properly join on the
state_cd column without an index in the
City table. So let’s add it.
mysql> CREATE INDEX city_st_idx ON City (state_cd); . . mysql> EXPLAIN SELECT city_name FROM City, State where City.state_cd -> = State.state_cd and State.state_cd = 'CA'; +-------+------+---------------+-------------+---------+-------+------+-------- | table | type | possible_keys | key | key_len | ref | rows | Extra +-------+------+---------------+-------------+---------+-------+------+-------- | State | ref | st_idx | st_idx | 2 | const | 1 | where u | | | | | | | | Using i | City | ref | city_st_idx | city_st_idx | 2 | const | 49 | where u +-------+------+---------------+-------------+---------+-------+------+--------
With that index, MySQL has to read only roughly 50 rows to satisfy the query. Remember that the numbers reported here are estimates. As you analyze the query plan, you should check these estimates against what you know about the database. In this case, roughly 50 rows are exactly what we would expect, since California has 50 cities in this database.
Other options
MySQL is not always perfect when optimizing a query. Sometimes it just will not choose the index that it should. The isamchk/myisamchk tools can help in this situation. MySQL assumes that values in an index are distributed evenly. isamchk --analyze or myisamchk --analyze reads a table and generates a histogram of data distribution for each column. This data provides some information that MySQL can use during the query optimization phase to make a more intelligent query plan. Note that --analyze is an independent operation that must be executed prior to execution of the query.
Another option is to use USE
INDEX
/IGNORE INDEX in your
query. This trick will give MySQL specific instructions about which
indexes to use or not use. Chapter 15 contains more
information about
this option.