
Leveraging Tekton for Cloud Native CI/CD
Tekton is a newer entry in the continuous integration and continuous delivery (CI/CD) tooling space. It is open source and part of the Continuous Delivery Foundation set of projects. It stands out in the set of CI/CD tools that are cloud native and work with Kubernetes because, once installed, it runs natively on Kubernetes rather than reaching out to manage Kubernetes from a separate application. This means it includes many of the advantages and challenges that come with using Kubernetes itself.
Since it runs natively on Kubernetes, Tekton provides the most direct option for implementing CI/CD there. If you know how to work with Kubernetes, you will have a more direct path to leveraging and learning Tekton. Tekton also offers a potential path for common implementations of your CI/CD workflows via Kuberentes objects, so you don’t have to leverage yet another CI/CD application with a different architecture and interface.
Within Kubernetes, Tekton gets installed as an extension and creates Kubernetes resources to do its work. Its resulting objects are available via the Kubernetes API and the Kubernetes command line. Kubernetes, at its core, manages workloads via containers (implemented via Pods). Similarly, Tekton, at its lowest level, leverages containers to perform the actual steps of a workflow. (This is not unique to Tekton, but it usefully illustrates the different concerns involved in defining the workflow and how it is actually implemented.)
Since Tekton runs on the Kubernetes infrastructure, the capacity for running CI/CD workloads can be scaled in the same way, such as by adding nodes to the cluster.
There are downsides of using Tekton. For example, it’s complex to set up and maintain. It requires a lot of YAML to be written to implement a pipeline. Operations that can be done in other CI/CD applications with a few simple clicks or a few lines of code or configuration now have to be implemented via an extensive Kubernetes syntax and semantics.
Also, out of the box, the component known as Tekton Pipelines supplies only the CD portion of CI/CD. To add the CI functionality and make it truly CI/CD, you will need to leverage another component known as Tekton Triggers (discussed in “Tekton Triggers”).
This approach of being tied so closely to Kubernetes and leveraging its objects to implement any kind of desired pipeline raises an interesting question for anyone looking at CI/CD solutions: “Does Tekton have the potential to standardize tooling and processes for CI/CD?”
In some ways, it could be easy to dismiss this notion. After all, one only has to look at the plethora of CI/CD tools and services that are available throughout the industry today. Only a few years ago, there were a number of platforms battling to help you manage your container orchestration, including Docker Swarm, Mesos, and Kubernetes. Today, it is apparent to everyone that one platform, Kubernetes, has won that war. It is ubiquitous—and companies that need its functionality but don’t embrace it are falling behind.
Whether Tekton is the best tool for solving CI/CD problems remains to be seen. But two key elements of success for software development are the platform and the practices you choose. Tekton is associated with an industry-standard platform (Kubernetes) and an industry-standard practice for delivering software (CI/CD). These characteristics further validate that we should be aware of what it is, what it fundamentally does, how it can be leveraged, and where it fits among similar tools. This report will provide you with that knowledge.
Tekton and Kubernetes
Let’s start at the basics. I’ll assume that since you are reading this report, you already have a basic working knowledge of Kubernetes and CI/CD.
A traditional knowledge model of Kubernetes usually focuses on how it manages continuous workloads, rather than driving a terminal workflow like a pipeline. This is one of the first challenges that can come up with Tekton: understanding how we cross the bridge from Kubernetes managing objects (creating, deleting, scaling, etc.) to Kubernetes implementing a CI/CD workflow.
We may traditionally think of CI/CD workflows as more imperative (step-by-step) processes than a declarative model (tell me what you want, and I’ll figure out how to make it happen) as used in Kubernetes. But if a workflow can be defined via a series of starting and ending states and needed resources, an API implementation can take care of the rest.
Declarative Versus Imperative Models
To crystallize the difference between imperative and declarative models, I’ll often use the following example. Consider the task of providing dinner for your family or friends. If you prepare and cook the meal (gathering the ingredients, following the steps in a recipe, etc.), you are using an imperative approach—following a step-by-step process to achieve the end result.
On the other hand, if you go out to a restaurant and place your order from the menu (choosing what you want, how much you want, how it’s cooked, etc.), you are using a declarative approach. You just “declare” what you want, how much, and how it should be prepared to the server. Then your part is done. The server takes your order back to the kitchen. The kitchen staff then prepare what you’ve asked for, it is instantiated as you requested, and it’s returned to you. Aside from stating what you wanted, you didn’t lift a finger.
The declarative model in Kubernetes is usually sourced from formatted text files for items like Pods, Services, Deployments, etc. These objects serve the core purposes that we use Kubernetes for, such as encapsulating and managing containers, providing a single point of connection to backend pieces, and ensuring we have a given number of instances always available. Instances of these types can be spun up in Kubernetes because there is a core API available that understands how to create and work with these “built-in” types based on specifications.
Adding Tekton into your Kubernetes system adds another set of objects and functionality that is available to implement a different “domain”—objects for Pipelines, Tasks, and related pieces. These just need to be combined in a way that represents the desired workflow for a pipeline. To better understand this domain, let’s see how a Tekton Pipeline comes together, from the bottom up.
Tekton Pipelines
Figure 1 shows an overview of Tekton Pipeline objects.
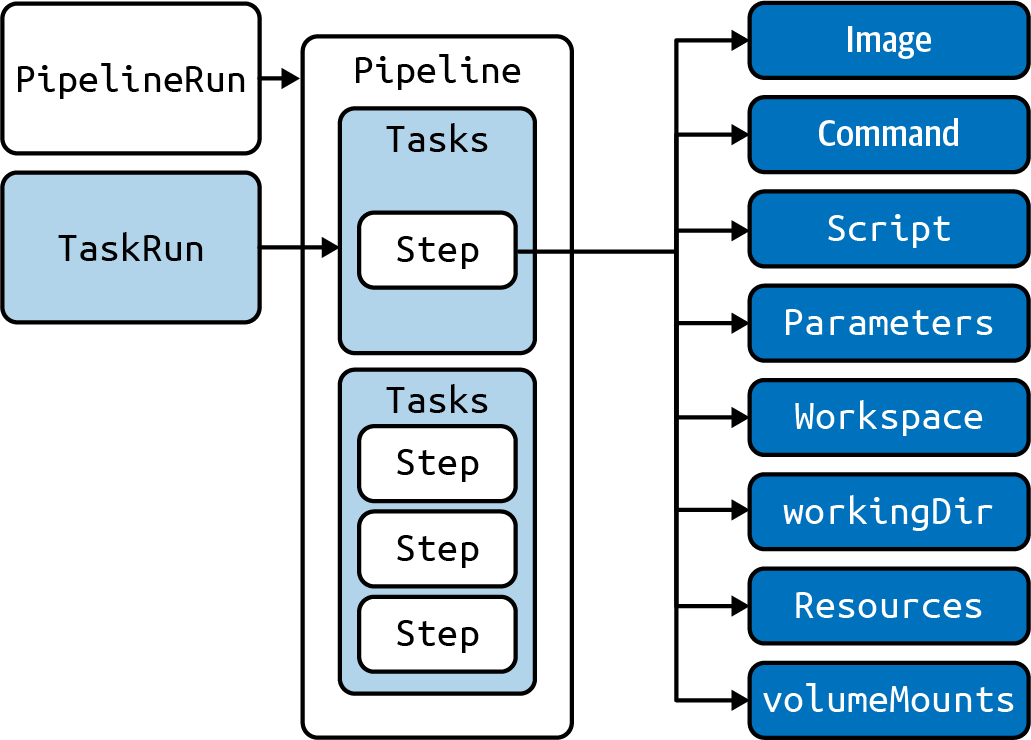
Figure 1. Basic elements of a Tekton Pipeline
You can see here an assortment of different objects: Pipeline, Task, TaskRun, PipelineRun, Steps, etc. All of these are available as Kubernetes objects—specifically custom resources—when you install Tekton. It’s not necessary that you understand these in detail, but as with targeting any new domain, knowing the basic terminology and having at least a high-level awareness of the concepts is crucial for engagement and understanding.
With those goals in mind for our Tekton journey, we’ll examine the primary concepts you need to know about. Along the way, we will help you understand what they do, why each is important, and how they work together. The first piece we’ll look at is the Step.
Step
At the lowest level, Tekton implements a Step resource. A Tekton Step defines an atomic operation in a pipeline, such as cloning down a Git repository, kicking off a build, and so forth.
While you may be used to the idea of a “step” being a single, explicit command in many CI/CD tools, in Tekton, Steps invoke a container to execute a function. The use of containers in this way is not unique to Tekton, but unlike most other CI/CD tools, Tekton requires this approach.
Leveraging containers to execute the individual commands or scripts that invoke the applications used in your pipeline provides a separate standalone environment in which to run the command or script. This means that your pipeline setup doesn’t need to specify details or make available external applications that are needed for doing builds, compiles, tests, and the like in your pipeline. Bundling, configuring, and running those applications is all handled within the container. Further, if you need to update to a new version of a tool or switch to a different tool, you create an updated image and tell the Step to use the updated image.
Examples of two simple Tekton Steps are shown in Example 1-1. In the first Step, we use a command to execute the action, and in the second, we execute a script to do a similar action. In both cases, the action is executed inside the container.
Example 1-1. Two simple Tekton Steps
steps:-name:hello-world1image:ubuntucommand:["/bin/bash"]args:["-c","echoHelloWorld1!>$(workspaces.output.path)/message1.txt"]-name:hello-world2image:ubuntuscript:|#!/usr/bin/env bashset -xeecho Hello World 2! > $(workspaces.output.path)/message2.txt
Steps themselves cannot be executed in Tekton. To be usable, Steps need to be encapsulated in a higher-level object that can include declarations of inputs, outputs, resources, etc. In Tekton, that higher-level object is called a Task.
Task
Just as a Pod is considered the most basic unit that Kubernetes manages for workloads, a Tekton Task is the most basic unit of execution in Tekton. And both mechanisms rely on a specified container image to do the underlying work.
A Task can be executed standalone in Tekton, separate from a Pipeline, if its unique function makes sense to execute separately or for testing. But more commonly, the Task with its Steps will be designed to perform some core function of the pipeline. Such functions might include pulling code, building modules, testing functionality, packaging, etc. Tasks are usually written to be independent of the data they operate on. Tekton Parameters can be used to customize the resources and behavior associated with a Task.
Running Tasks at the Cluster Level
If a Task needs to be able to run in any namespace in the cluster, a ClusterTask can be used instead.
Figure 2 shows the high-level model of a Task. When Tekton is installed on a cluster, it runs the Tekton Controller. When a user applies the manifest (YAML spec) for a Task, it creates the Task object encapsulating the Steps with their image definitions.

Figure 2. High-level model of a Task
An actual specification of a Task around our previous Steps might look like Example 1-2.
Example 1-2. Task specification
apiVersion:tekton.dev/v1beta1kind:Taskmetadata:name:example-taskspec:workspaces:-name:outputdescription:Folder where output goessteps:-name:hello-world1image:ubuntucommand:["/bin/bash"]args:["-c","echoHelloWorld1!>$(workspaces.output.path)/message1.txt"]-name:hello-world2image:ubuntuscript:|#!/usr/bin/env bashset -xeecho Hello World 2! > $(workspaces.output.path)/message2.txt
Even though we have declared a Task with Steps to execute, this does not cause anything to happen. Within Tekton, you need separate objects to execute and drive any CD processes.
Driving Tasks
Many of the “built-in” Kubernetes types of objects (Pods, Deployments, Services, etc.) are intended to be instantiated, started up, and then persist until terminated. Tekton Task objects, on the other hand, are instantiated and then do nothing until they are “signaled.” Once signaled, they execute their Steps to complete their function and then stop. In this sense, they are more like standard Kubernetes Jobs.
What provides that “signal” to kick off execution of a Task? Tekton requires the definition and creation of another separate object type—the TaskRun—to actually invoke and execute a Task. The TaskRun contains a reference to (or in some cases may directly include) the specification for the Task. As well, it can define parameters and resources such as specific workspaces that the Task may need to execute.
The high-level model view of using a Tekton TaskRun to initiate execution of a Task is shown in Figure 3. Applying the specification for a TaskRun causes the object to be created, which then runs the Steps defined in the Task. Each Task results in a Pod, with each Step being a container in that Pod.

Figure 3. High-level model of a Tekton TaskRun
An example of a simple TaskRun for the Task from Example 1-2 is shown in Example 1-3.
Example 1-3. Simple TaskRun
apiVersion:tekton.dev/v1beta1kind:TaskRunmetadata:name:example-taskrunnamespace:defaultspec:workspaces:-name:outputpersistentVolumeClaim:claimName:output-pvcsubPath:messagestaskRef:name:example-task
You can see here that the TaskRun has a reference (taskRef) to our example task as well as a mapping for the workspace that the Task will use to a persistentVolumeClaim (PVC). This information is sufficient to execute the Task to completion once the manifest for the TaskRun and Task are applied to the cluster (assuming access to the image and the PVC).
A Tekton Task launched by a Tekton TaskRun can be a useful way to accomplish one directed work function. For example, it might execute a set of tests against local code, run a tool to transform inputs into outputs, generate reports, or whatever task needs doing. However, the real business value comes from combining functions to do end-to-end processing via pipelines, particularly CD pipelines.
Pipelines
Along with Tasks, Tekton supports the definition and use of Pipeline objects. A Tekton Pipeline is an object of larger scope that encapsulates the Tasks to define the desired workflow. Once you decide what major functions you need to have done in your pipeline (builds, testing, managing artifacts, etc.), you can define a Task to handle each one and then define a Pipeline to include all of those and orchestrate the functions.
For CI/CD, the Pipeline object will contain all of the Tasks needed to take the inputs (typically source code), process it, and produce the desired output (typically product deliverables). By default, the Tasks in a Pipeline all run in parallel, although there are ways to force them to run in sequence if needed.
Figure 4 shows the high-level object model for a Tekton Pipeline. Note the Pipeline encapsulates/references one or more Tasks.
And, as with Tasks, an additional object is needed to cause the Pipeline to execute. It probably won’t surprise you that these objects are called PipelineRuns.
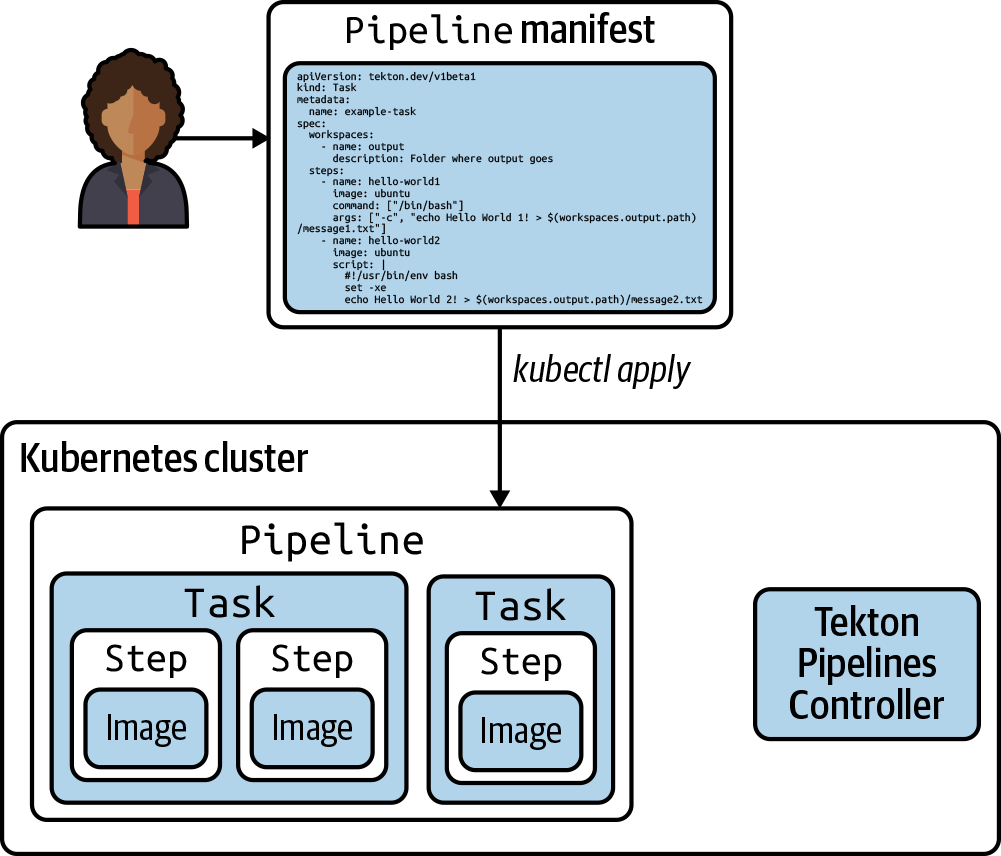
Figure 4. High-level object model of a Tekton Pipeline
Driving Pipelines
The Tekton Pipeline drives the individual tasks in the Pipeline by creating a TaskRun object for each Task to cause it to execute. For the overall Pipeline itself, there is also a PipelineRun object that needs to be declared and instantiated to identify how to execute the Pipeline.
Since Tekton objects are defined by Kubernetes manifests, a Kubernetes admin can simply apply the manifest to a cluster in the same way as for any other Kubernetes object. By applying the PipelineRun manifest into Kubernetes, we can cause the Tekton Pipeline to start executing. This in turn will generate TaskRuns for the Task objects. As the various Task objects execute, they will perform the Steps needed to execute the functions for our CD workflow.
Figure 5 illustrates the high-level object model for a Pipeline being executed via a PipelineRun object. Applying the manifest for a PipelineRun object causes that object to be created via the Tekton Pipelines Controller. In turn, the process creates TaskRun objects to initiate execution of the various Tasks in the order needed for the workflow (parallel by default). As with the TaskRun, Pods are spun up for Tasks and containers are run for the Steps.
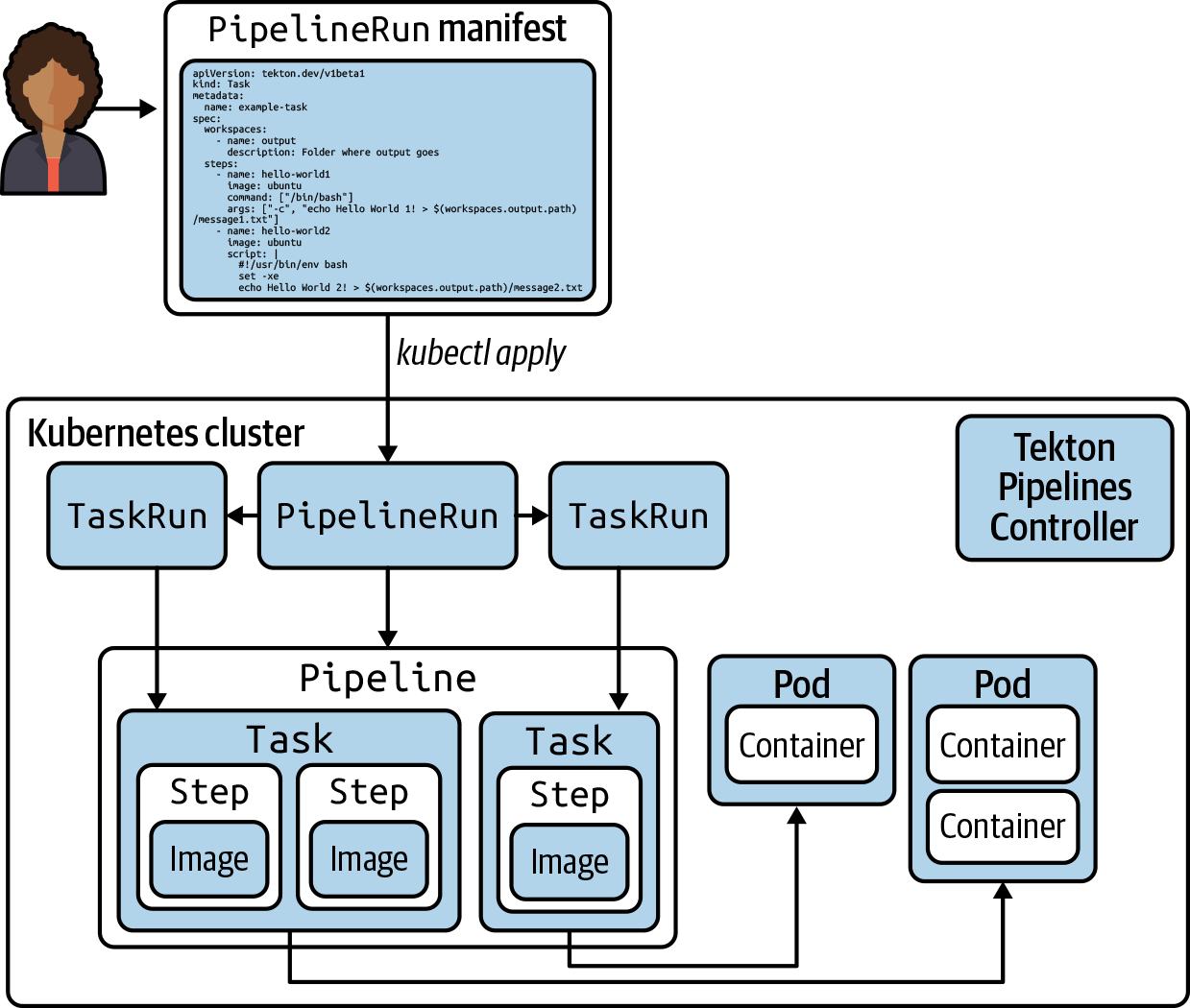
Figure 5. Initiating execution of a Pipeline via a PipelineRun
You may have noticed a seeming contradiction between CI/CD principles and how we have discussed working with Tekton so far. Specifically, we are initiating our Tekton Pipeline “manually” by instantiating a PipelineRun object. We are not triggering it automatically based on a change. In short, we’ve been able to implement continuous delivery but not continuous integration.
As mentioned earlier, the original Tekton objects were only designed to handle CD. In fact, the product itself is formally named “TektonCD.” So how, then, do we add CI into the mix? The answer is that we need to install additional types of objects designed to “trigger” our Pipeline based on an event occurring. These sets of objects are referred to by the umbrella term Tekton Triggers.
Tekton Triggers
Tekton Triggers is an extension to Tekton (a Tekton “component”) that must be installed separately. Once installed, it provides the missing CI piece by allowing events to automatically instantiate Tekton PipelineRuns or TaskRuns. As an example use case, consider a Tekton Trigger that is activated when a pull request happens in GitHub. In response to the initiation of the pull request, the Trigger causes a Tekton Pipeline to do a test build of the code associated with the pull request.
Triggers Controller
To provide the necessary continuous functionality, the Triggers component runs as a Kubernetes controller in the cluster. In Kubernetes terminology, a controller is a loop process that continuously executes and ensures that, for a given object type, the requested state matches what is instantiated and running (the observed state) in the cluster. If something changes in either state, the controller is responsible for doing what needs to be done to make sure the balance is restored (the observed state is made to match the requested state).
Another key aspect of any continuous integration functionality is the ability to automatically respond when a qualifying event occurs. A common example is pulling a set of source code to be built and processed through the continuous delivery portion of the pipeline when a change is pushed to a source repository.
In the example use case mentioned above, when someone created a pull request in GitHub, GitHub would send data about what changed (the payload) over the network to a web address. The payload would be sent from GitHub by a mechanism called a webhook. Once the Trigger process identified incoming information from the webhook, it would extract desired data values from it. For example, if the data were due to source code changes in a project, the Trigger process could extract the project path and revision of the code changes.
Within the Trigger structure, a template for a PipelineRun or a TaskRun is defined with parameters to be filled in. To create an actual object from the template, the Trigger would take the values extracted from the payload from GitHub, fill in the parameters with them, and instantiate an actual PipelineRun or TaskRun object to kick off the Pipeline or Task, respectively.
Figure 6 shows a high-level overview of the Tekton Trigger process.
When the Tekton Triggers piece is installed, it starts a special Controller for Triggers. The various objects that you define for a Trigger include the EventListener, the TriggerBinding, and the TriggerTemplate. These components are described in more detail in “Triggers Details” if you are interested. The TriggerTemplate object contains a template for a PipelineRun (or alternatively a TaskRun).

Figure 6. High-level overview of the Tekton Trigger process
A Kubernetes Service is also spun up listening on a port. As an example event generator, a GitHub project can be set up to send information (the payload) about an event via a webhook. When an event happens (such as a pull request), the webhook is triggered. It sends the payload with the relevant information. The event data comes in via an ingress/service. It is then processed to extract the needed data and bind it to parameters. Those parameters are then plugged into the template for the PipelineRun (or TaskRun), and that instantiates the PipelineRun object to start execution.
So, to summarize, with the functionality enabled by the Trigger pieces, we now have continuous integration. Combined with the existing continuous delivery functionality of standard Tekton, we have the intended CI/CD workflow.
One final question that may come to mind is why Tekton didn’t already have functionality built in to automatically kick off the Pipeline. As we noted before, like other Kubernetes objects, Tekton Pipelines and Tasks are declarative. This means they have no information about under what conditions they will be started, or what the state of resources will be that they operate on. Pipelines are ultimately only an instance of a specification and not a program.
The Triggers functionality provides the missing means to declaratively create the PipelineRun or TaskRun objects in response to external events. Since the Triggers construct the PipelineRun, they don’t need to know anything about what’s in the Pipeline declaration itself. This design makes for a nice separation of concerns between the two areas. This separation promotes reusability and configurability.
Advantages and Challenges
From the previous sections, you can see that there is a core set of basic building blocks available with Tekton that can be configured to do almost any needed functionality for CI/CD. The overall function of a Task or a Pipeline is nothing we couldn’t have done in some other CI/CD system, but Tekton does offer several advantages:
- We are able to declare it like any other Kubernetes objects, without needing to learn another application.
- It is cloud native by default since it runs in Kubernetes.
- It is scalable for workloads simply by scaling the Kubernetes infrastructure.
- It leverages pods, running containers to do any of the actual operations. So once the container is set up, we don’t need to incur that cost and overhead each time we run it.
- We can leverage existing containers in our pipeline to simplify accomplishing tasks.
- We can also create our own custom containers with specific versions of software and environments as needed.
- We can declaratively define the parameters and operations we want to run.
Any challenges here would likely reflect how much familiarity and experience you have with Kubernetes and containers. While you don’t have to learn a new application, you are learning a new Kubernetes API and declarative model. And a switch from thinking about Pipelines as an imperative process to a declarative one is a mental shift. In short, without a solid foundation in the Kubernetes model, there can be a nontrivial learning curve for something you might be able to do with significantly less effort in another application.
Likewise, while Steps in Tekton essentially treat containers like a “black box,” at some point there will be a need to “open the box” and work with its contents to learn about the functionality. You may even want to produce an updated image for additional functionality.
And, because the flow is not always evident from the Kubernetes specifications and the purpose of a container is not always self-evident, good comments and supporting documentation are essential for maintainability when using Tekton.
Without this foundational knowledge, or the willingness to devote the time needed to obtain it, there is a danger that users new to Tekton will find trying to use it for substantial work a confusing and frustrating experience; other CI/CD tools may be easier to use.
However, as we have discussed, the main distinction between other tools and Tekton is that no other pipeline engine was built to be a natural extension to Kubernetes. Most CI/CD applications can take advantage of Kubernetes in ways similar to how we might make system calls to the OS to handle something for us and return back, or they may even run in Kubernetes as a containerized workload. But that is very different from a complete integration at the level of the APIs available from a platform. In brief, Tekton checks the boxes for an ephemeral, cloud native, Kubernetes-native solution because, once installed, it is part of Kubernetes. And there are no other applications or abstracted layers to get in the way.
Interestingly, some CI/CD tools, such as Jenkins X, take the approach of supplying their own interfaces, structured input files, etc., and then ultimately produce Tekton code to do the actual workflow. Part of the motivation here is that putting other interfaces on top of Tekton can simplify the experience for the user who is less familiar with working in Kubernetes at that level.
If you find that using a frontend to the CI/CD tool provides worthwhile benefits, then by all means use one. In my experience, the additional complexity that this kind of translation layer introduces is difficult to get right, manage, and keep up-to-date. For example, if there is an error in the translation to Tekton, you will be less able to debug the resulting Pipeline yourself. In short, while well-intentioned, these approaches can actually steepen the learning curve and make dealing with bugs more complicated than if you had just learned and used Tekton directly.
None of this should imply that the Tekton community is unconcerned about Tekton’s ease of use and integration. On the contrary, the Tekton community has been (and is) working on a collection of interfaces and integrations to make it easier to leverage Tekton without adding more layers of complexity. I’ll discuss several of those in the next section.
Additional Tekton Integration and Tooling
There is an active community working to move Tekton forward and position it as a valuable and adaptable tool for CI/CD. As with any application, a key to wider adoption is the ability to work with it easily through multiple interfaces and the ability to integrate it with other widely used applications.
For Tekton, user community efforts have resulted in the following additional functionality:
- Integrations for developer tooling
- Interfaces, such as the Tekton command-line interface and the Tekton Dashboard
- Ways to enable reuse and sharing of components via catalogs
- Products that integrate with Tekton
Each of these is worth touching on briefly. We’ll start with the integrations for developer tooling.
Integrations for Developer Tooling
The Tekton community has created a number of extensions for common development needs. These include:
- The Tekton Pipelines Extension for VSCode (available from Visual Studio)
- The Tekton Pipelines Extension for IntelliJ (available from JetBrains)
There is also a Tekton Client Plugin for Jenkins. This plugin allows Jenkins to interact with Tekton Pipelines on a Kubernetes cluster.
Interfaces
As alternatives to initiating actions and operations via the Kubernetes command line, Tekton provides its own command-line interface. There is also a dashboard to graphically navigate and interact with Tekton objects.
Command line
The optional CLI functionality for Tekton is done via the tkn application. The CLI simplifies reporting and debugging and supports managing the typical sets of Tekton objects, as shown in this output:
$ tkn Available Commands: clustertask Manage ClusterTasks clustertriggerbinding Manage ClusterTriggerBindings condition Manage Conditions eventlistener Manage EventListeners hub Interact with Tekton Hub pipeline Manage Pipelines pipelinerun Manage PipelineRuns resource Manage PipelineResources task Manage Tasks taskrun Manage TaskRuns triggerbinding Manage TriggerBindings triggertemplate Manage TriggerTemplates Other Commands: completion Prints shell completion scripts version Prints version information Flags: -h, --help help for tkn
Objects will have a set of available actions that can be done on them as well from the CLI:
$ tkn task Manage Tasks Usage: tkn task [flags] tkn task [command] Aliases: task, t, tasks Available Commands: delete Delete Tasks in a namespace describe Describe a Task in a namespace list Lists Tasks in a namespace logs Show Task logs start Start Tasks
Dashboard
Tekton also has a separately available web UI for use with Pipelines and Triggers. Users can interact with it to do operations such as:
- Create Tekton resources
- Execute Tekton resources
- Manage and observe Tekton resources
- Import Tekton resources from Git
- Add extensions for more functionality
An example of the Tekton Dashboard interface is shown in Figure 7.
Figure 7. Tekton Dashboard
Tekton Catalogs
Tekton users have provided catalogs of reusable Tasks. At some point, these catalogs may start to contain other resource types such as Pipelines. The catalogs and their corresponding Tasks are usually stored in GitHub, with Tasks organized by subdirectories. The Task subdirectories will also have a README file and a Kubernetes manifest to make them readily usable. Table 1 summarizes the set of catalogs available as of this writing.
| Name | Purpose | Location |
|---|---|---|
| Community Catalog | main catalog | |
| OpenShift Pipelines Catalog | OpenShift-specific |
The main branch of the Community Catalog repository usually corresponds to the latest API version. At the time of this writing, it is v1beta1.
Tekton Hub
The Tekton Hub is a resource designed to help Tekton users share Tasks and Pipelines. It was created by RedHat working with the Tekton community. Its stated mission is “to facilitate search and discovery of Tekton Tasks, Pipelines, and all things Tekton.”1 If you’re wondering about the difference between the Hub and catalogs, the Hub serves as a registry for catalogs, including the Community Catalog.
The Hub also provides an API service that integrates with the Hub to search, get, and install Tasks within other development tools such as VSCode and IntelliJ (see “Integrations for Developer Tooling”).
Figure 8 shows a screenshot of the Tekton Hub.

Figure 8. Tekton Hub
Offerings That Include Tekton
A number of applications have included Tekton as part of their functionality. By this, I mean that they either leverage Tekton as the way to create content, or they produce Tekton code from other input. In either situation, Tekton is used in some capacity to execute pipelines. I’ll just briefly list a few examples in this section, but I’ve included links in case you want to explore any in more depth.
Jenkins X
Jenkins X attempts to provide cloud-ready CI/CD pipelines leveraging many of the current DevOps best practices such as GitOps and preview environments. While you do not need to know Tekton to use it, it ultimately renders its pipelines and executes them in Tekton.
IBM Cloud DevOps/Kabanero
IBM Cloud DevOps attempts to provide an end-to-end set of tools (toolchain) for doing CD in cloud environments. It uses Tekton for its pipeline and related pieces.
Kabanero is included with some of the IBM Cloud pieces. It seeks to integrate open source projects with the ideas around modern microservice development. And it strives to help developers create cloud native apps faster via toolchains, prebuilt deployments, frameworks, etc.
OpenShift pipelines
This is a CI/CD solution based on Tekton. It is installed easily on OpenShift via an operator and includes multiple OpenShift interfaces and a Visual Studio Code editor plugin.
Conclusion
Success in the software development world today requires excellence in two primary areas: platforms and practices. In terms of platforms, Kubernetes has won the war for being able to orchestrate and manage the containerized workloads that make up today’s cloud-friendly applications.
And, in terms of practices, CI/CD, implemented through pipelines, has become the expected method to transform source code, data, configuration, and all other inputs into an end product that is reliably and automatically produced—and proven to be ready for customers to use.
Tekton provides a unique partnership between platform and practice. It provides a way for users to create CI/CD pipelines natively on Kubernetes, as Kubernetes native objects. In this way, the practice of CI/CD leverages the key platform of Kubernetes, reducing the need to have other “middle-ware.”
As a technology, Tekton can still be considered the “new kid on the block” for creating pipelines. It holds a unique position in that space as being directly compatible with Kubernetes (because it is implemented with Kubernetes objects). But it also suffers from the complexity and learning curve often involved in working directly with Kubernetes. This complexity can be mitigated to some extent by use of the graphical and/or command-line interfaces and the existence of a catalog with ready-made components that developers can choose from.
Ultimately, to be able to work effectively with Tekton pipelines, developers must be familiar and comfortable with creating and using native Kubernetes objects. Since most cloud-focused developers these days will already be somewhat familiar with Kubernetes, this is not an undue expectation. Adoption of Tekton will likely help further develop Kubernetes proficiency. If leveraged fully, it can offset the need to invest in other pipeline technologies and dedicated infrastructure.
1 CD Foundation, “Introducing Tekton Hub”, blog post, August 10, 2020.