
Chapter 29. Designing with Exceptions
This chapter rounds out this part of the book with a collection of exception design topics and common use case examples, followed by this part’s gotchas and exercises. Because this chapter also closes out the book at large, it includes a brief overview of development tools as well to help you as you make the migration from Python beginner to Python application developer.
Nesting Exception Handlers
Our examples so far have used only a single try to catch exceptions, but what happens if one try is physically nested inside another? For that matter, what does it mean if a try calls a function that runs another try? Technically, try statements can nest in terms of syntax and the runtime control flow through your code.
Both of these cases can be understood if you realize that Python stacks try statements at runtime. When an exception is raised, Python returns to the most recently entered try statement with a matching except clause. Because each try statement leaves a marker, Python can jump back to earlier trys by inspecting the stacked markers. This nesting of active handlers is what we mean when we talk about propagating exceptions up to “higher” handlers—such handlers are simply try statements entered earlier in the program’s execution flow.
Figure 29-1 illustrates what occurs when try/except statements nest at runtime. The amount of code that goes into a try block can be substantial (e.g., it can contain function calls), and it often invokes other code that may be watching for the same exceptions. When an exception is eventually raised, Python jumps back to the most recently entered try statement that names that exception, runs that statement’s except clause, and then resumes after that try.
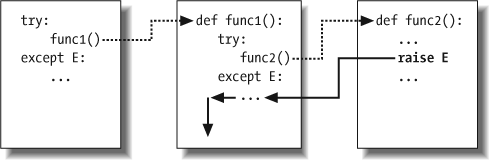
Once the exception is caught, its life is over—control does not jump back to all matching trys that name the exception; only the first one is given the opportunity to handle it. In Figure 29-1, for instance, the raise statement in the function func2 sends control back to the handler in func1, and then the program continues within func1.
By contrast, when try/finally statements are nested, each finally block is run in turn when an exception occurs—Python continues propagating the exception up to other trys, and eventually perhaps to the top-level default handler (the standard error message printer). As Figure 29-2 illustrates, the finally clauses do not kill the exception—they just specify code to be run on the way out of each try during the exception propagation process. If there are many try/finally clauses active when an exception occurs, they will all be run, unless a try/except catches the exception somewhere along the way.
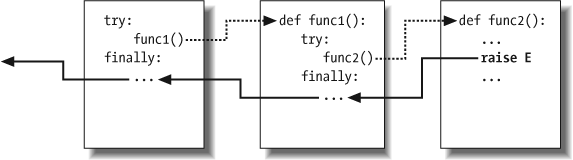
In other words, where the program goes when an exception is raised depends entirely upon where it has been—it’s a function of the runtime flow of control through the script, not just its syntax. The propagation of an exception essentially proceeds backward through time to try statements entered but not yet exited. This propagation stops as soon as control is unwound to a matching except clause, but not as it passes through finally clauses on the way.
Example: Control-Flow Nesting
Let’s turn to an example to make this nesting concept more concrete. The following module file, nestexc.py, defines two functions. action2 is coded to trigger an exception (you can’t add numbers and sequences), and action1 wraps a call to action2 in a try handler, to catch the exception:
def action2( ): print 1 + [ ] # Generate TypeError def action1( ): try: action2( ) except TypeError: # Most recent matching try print 'inner try' try: action1( ) except TypeError: # Here, only if action1 re-raises print 'outer try' %
python nestexc.pyinner try
Notice, though, that the top-level module code at the bottom of the file wraps a call to action1 in a try handler, too. When action2 triggers the TypeError exception, there will be two active try statements—the one in action1, and the one at the top level of the module file. Python picks and runs just the most recent try with a matching except, which in this case is the try inside action1.
As I’ve mentioned, the place where an exception winds up jumping to depends on the control flow through the program at runtime. Because of this, to know where you will go, you need to know where you’ve been. In this case, where exceptions are handled is more a function of control flow than of statement syntax. However, we can also nest exception handlers syntactically—an equivalent case we’ll look at next.
Example: Syntactic Nesting
As I mentioned when we looked at the new unified try/except/finally statement in Chapter 27, it is possible to nest try statements syntactically by their position in your source code:
Really, this code just sets up the same handler-nesting structure as (and behaves identically to) the prior example. In fact, syntactic nesting works just like the cases sketched in Figure 29-1 and Figure 29-2; the only difference is that the nested handlers are physically embedded in a try block, not coded in functions called elsewhere. For example, nested finally handlers all fire on an exception, whether they are nested syntactically, or by means of the runtime flow through physically separated parts of your code:
try:...try:...raise IndexError...finally:...print 'spam'...finally:...print 'SPAM'... spam SPAM Traceback (most recent call last): File "<stdin>", line 3, in ? IndexError
See Figure 29-2 for a graphic illustration of this code’s operation; the effect is the same, but the function logic has been inlined as nested statements here. For a more useful example of syntactic nesting at work, consider the following file, except-finally.py:
This code catches an exception if one is raised, and performs a finally termination-time action regardless of whether an exception occurred. This may take a few moments to digest, but the effect is much like combining an except and a finally clause in a single try statement today (recall that such combinations were syntactically illegal until Python 2.5):
python except-finally.py<function raise1 at 0x00BA2770> caught IndexError finally run <function noraise at 0x00BB47F0> finally run <function raise2 at 0x00BB4830> finally run Traceback (most recent call last): File "C:/Python25/except-finally.py", line 9, in <module> func( ) File "C:/Python25/except-finally.py", line 3, in raise2 def raise2( ): raise SyntaxError SyntaxError: None
As we saw in Chapter 27, as of Python 2.5, except and finally clauses can be mixed in the same try statement. This makes some of the syntactic nesting described in this section unnecessary, though it still works, may appear in code written prior to Python 2.5, and can be used as a technique for implementing alternative exception-handling behaviors.
Exception Idioms
We’ve seen the mechanics behind exceptions. Now, let’s take a look at some of the other ways they are typically used.
Exceptions Aren’t Always Errors
In Python, all errors are exceptions, but not all exceptions are errors. For instance, we saw in Chapter 9 that file object read methods return an empty string at the end of a file. In contrast, the built-in raw_input function (which we first met in Chapter 3, and deployed in an interactive loop in Chapter 10) reads a line of text from the standard input stream, sys.stdin, at each call, and raises the built-in EOFError at end-of-file. Unlike file methods, this function does not return an empty string—an empty string from raw_input means an empty line. Despite its name, the EOFError exception is just a signal in this context, not an error. Because of this behavior, unless end-of-file should terminate a script, raw_input often appears wrapped in a try handler and nested in a loop, as in the following code:
process next line here...
Other built-in exceptions are similarly signals, not errors. Python also has a set of built-in exceptions that represent warnings rather than errors. Some of these are used to signal use of deprecated (phased out) language features. See the standard library manual’s description of built-in exceptions, and the warnings module for more on warnings.
Functions Signal Conditions with raise
User-defined exceptions can also signal nonerror conditions. For instance, a search routine can be coded to raise an exception when a match is found, instead of returning a status flag for the caller to interpret. In the following, the try/except/else exception handler does the work of an if/else return-value tester:
success...: raise Found( ) else: return try: searcher( ) except Found: # Exception if item was found ...success... else: # else returned: not found ...failure...
More generally, such a coding structure may also be useful for any function that cannot return a sentinel value to designate success or failure. For instance, if all objects are potentially valid return values, it’s impossible for any return value to signal unusual conditions. Exceptions provide a way to signal results without a return value:
success...: return ...founditem... else: raise Failure( ) try: item = searcher( ) except Failure: ...report... else: ...use item here...
Because Python is dynamically typed and polymorphic to the core, exceptions, rather than sentinel return values, are the generally preferred way to signal such conditions.
Debugging with Outer try Statements
You can also make use of exception handlers to replace Python’s default top-level exception-handling behavior. By wrapping an entire program (or a call to it) in an outer try in your top-level code, you can catch any exception that may occur while your program runs, thereby subverting the default program termination.
In the following, the empty except clause catches any uncaught exception raised while the program runs. To get hold of the actual exception that occurred, fetch the sys.exc_info function call result from the built-in sys module; it returns a tuple, whose first two items automatically contain the current exception’s name, and its associated extra data (if any). For class-based exceptions, these two items are the exception class and the raised instance of the class, respectively (more on sys.exc_info in a moment):
run program... except: # All uncaught exceptions come here import sys print 'uncaught!', sys.exc_info( )[0], sys.exc_info( )[1]
This structure is commonly used during development, to keep programs active even after errors occur—it allows you to run additional tests without having to restart. It’s also used when testing other program code, as described in the next section.
Running In-Process Tests
You might combine some of the coding patterns we’ve just looked at in a test-driver application, which tests other code within the same process:
The testdriver function here cycles through a series of test calls (the module testapi is left abstract in this example). Because an uncaught exception in a test case would normally kill this test driver, you need to wrap test case calls in a try if you want to continue the testing process after a test fails. As usual, the empty except catches any uncaught exception generated by a test case, and it uses sys.exc_info to log the exception to a file. The else clause is run when no exception occurs—the test success case.
Such boilerplate code is typical of systems that test functions, modules, and classes by running them in the same process as the test driver. In practice, however, testing can be much more sophisticated than this. For instance, to test external programs, you could instead check status codes or outputs generated by program-launching tools such as os.system and os.popen, covered in the standard library manual (such tools do not generally raise exceptions for errors in the external programs—in fact, the test cases may run in parallel with the test driver).
At the end of this chapter, we’ll also meet some more complete testing frameworks provided by Python, such as Doctest and PyUnit, which provide tools for comparing expected outputs with actual results.
More on sys.exc_info
The sys.exc_info result used in the last two sections is the preferred way to gain access to the most recently raised exception generically. If no exception is being handled, it returns a tuple containing three None values; otherwise, the values returned are (type, value, traceback), where:
typeis the exception type of the exception being handled (a class object for class-based exceptions).valueis the exception parameter (its associated value or the second argument toraise, which is always a class instance if the exception type is a class object).tracebackis a traceback object that represents the call stack at the point where the exception originally occurred (see the standardtracebackmodule’s documentation for tools that may be used in conjunction with this object to generate error messages manually).
The older tools sys.exc_type and sys.exc_value still work to fetch the most recent exception type and value, but they can manage only a single, global exception for the entire process. The preferred sys.exc_info instead keeps track of each thread’s exception information, and so is thread-specific. Of course, this distinction matters only when using multiple threads in Python programs (a subject beyond this book’s scope). See the Python library manual or follow-up texts for more details.
Exception Design Tips
By and large, exceptions are easy to use in Python. The real art behind them is in deciding how specific or general your except clauses should be, and how much code to wrap up in try statements. Let’s address the second of these concerns first.
What Should Be Wrapped
In principle, you could wrap every statement in your script in its own try, but that would just be silly (the try statements would then need to be wrapped in try statements!). This is really a design issue that goes beyond the language itself, and becomes more apparent with use. But here are a few rules of thumb:
Operations that commonly fail should generally be wrapped in
trystatements. For example, operations that interface with system state (file opens, socket calls, and the like) are prime candidates fortrys.However, there are exceptions to the prior rule—in a simple script, you may want failures of such operations to kill your program instead of being caught and ignored. This is especially true if the failure is a showstopper. Failures in Python result in useful error messages (not hard crashes), and this is often the best outcome you could hope for.
You should implement termination actions in
try/finallystatements to guarantee their execution. This statement form allows you to run code whether exceptions occur or not.It is sometimes more convenient to wrap the call to a large function in a single
trystatement, rather than littering the function itself with manytrystatements. That way, all exceptions in the function percolate up to thetryaround the call, and you reduce the amount of code within the function.
The types of programs you write will probably influence the amount of exception handling you code as well. Servers, for instance, must generally keep running persistently, and so will likely require try statements to catch and recover from exceptions. In-process testing programs of the kind we saw in this chapter will probably handle exceptions as well. Simpler one-shot scripts, though, will often ignore exception handling completely because failure at any step requires script shutdown.
Catching Too Much: Avoid Empty excepts
On to the issue of handler generality. Python lets you pick and choose which exceptions to catch, but you sometimes have to be careful to not be too inclusive. For example, you’ve seen that an empty except clause catches every exception that might be raised while the code in the try block runs.
That’s easy to code, and sometimes desirable, but you may also wind up intercepting an error that’s expected by a try handler higher up in the exception nesting structure. For example, an exception handler such as the following catches and stops every exception that reaches it, regardless of whether another handler is waiting for it:
Perhaps worse, such code might also catch unrelated system exceptions. Even things like memory errors, genuine programming mistakes, iteration stops, and system exits raise exceptions in Python. Such exceptions should not usually be intercepted.
For example, scripts normally exit when control falls off the end of the top-level file. However, Python also provides a built-in sys.exit(statuscode) call to allow early terminations. This actually works by raising a built-in SystemExit exception to end the program, so that try/finally handlers run on the way out, and special types of programs can intercept the event.[80] Because of this, a try with an empty except might unknowingly prevent a crucial exit, as in the following file (exiter.py):
python exiter.pygot it continuing...
You simply might not expect all the kinds of exceptions that could occur during an operation.
Probably worst of all, an empty except will also catch genuine programming errors, which should be allowed to pass most of the time. In fact, empty except clauses can effectively turn off Python’s error-reporting machinery, making it difficult to notice mistakes in your code. Consider this code, for example:
continue here with x...
The coder here assumes that the only sort of error that can happen when indexing a dictionary is a missing key error. But because the name myditctionary is misspelled (it should say mydictionary), Python raises a NameError instead for the undefined name reference, which the handler will silently catch and ignore. The event handler will incorrectly fill in a default for the dictionary access, masking the program error. If this happens in code that is far removed from the place where the fetched values are used, it might make for a very interesting debugging task!
As a rule of thumb, be as specific in your handlers as you can be—empty except clauses are handy, but potentially error-prone. In the last example, for instance, you would be better off saying except KeyError: to make your intentions explicit and avoid intercepting unrelated events. In simpler scripts, the potential for problems might not be significant enough to outweigh the convenience of a catchall, but in general, general handlers are generally trouble.
Catching Too Little: Use Class-Based Categories
On the other hand, neither should handlers be too specific. When you list specific exceptions in a try, you catch only what you actually list. This isn’t necessarily a bad thing, but if a system evolves to raise other exceptions in the future, you may need to go back and add them to exception lists elsewhere in your code.
For instance, the following handler is written to treat myerror1 and myerror2 as normal cases, and treat everything else as an error. If a myerror3 is added in the future, it is processed as an error, unless you update the exception list:
Luckily, careful use of the class-based exceptions we discussed in Chapter 28 can make this trap go away completely. As we saw, if you catch a general superclass, you can add and raise more specific subclasses in the future without having to extend except clause lists manually—the superclass becomes an extendible exceptions category:
Whether you use class-based exception category hierarchies, a little design goes a long way. The moral of the story is to be careful to not be too general or too specific in exception handlers, and to pick the granularity of your try statement wrappings wisely. Especially in larger systems, exception policies should be a part of the overall design.
Exception Gotchas
There isn’t much to trip over with exceptions, but here are two general usage pointers (one of which summarizes concepts we’ve already met).
String Exceptions Match by Identity, Not by Value
Now that exceptions are supposed to be identified with classes instead of strings, this gotcha is something of a legacy issue; however, as you’re likely to encounter string-based exceptions in existing code, it’s worth knowing about. When an exception is raised (by you or by Python itself), Python searches for the most recently entered try statement with a matching except clause—i.e., an except clause that names the same string object (for string-based exceptions), or the same class or a superclass of it (for class-based exceptions). For string exceptions, it’s important to be aware that matching is performed by identity, not equality.
For instance, suppose we define two string objects we want to raise as exceptions:
ex1 = 'The Spanish Inquisition'>>>ex2 = 'The Spanish Inquisition'>>>ex1 == ex2, ex1 is ex2(True, False)
Applying the == test returns True because they have equal values, but is returns False because they are two distinct string objects in memory (assuming they are long enough to defeat the internal caching mechanism for Python strings, described in Chapter 6). Thus, an except clause that names the same string object will always match:
try:...raise ex1...except ex1:...print 'got it'... got it
but one that lists an equal-value but not identical object will fail:
try:...raise ex1...except ex2:...print 'Got it'... Traceback (most recent call last): File "<pyshell#43>", line 2, in <module> raise ex1 The Spanish Inquisition
Here, the exception isn’t caught because there is no match on object identity, so Python climbs to the top level of the process, and prints a stack trace and the exception’s text automatically. As I’ve hinted, however, some different string objects that happen to have the same values will in fact match because Python caches and reuses small strings (as described in Chapter 6):
try:...raise 'spam'...except 'spam':...print 'got it'... got it
This works because the two strings are mapped to the same object by caching. In contrast, the strings in the following example are long enough to be outside the cache’s scope:
try:...raise 'spam' * 8...except 'spam' * 8:...print 'got it'... Traceback (most recent call last): File "<pyshell#58>", line 2, in <module> raise 'spam' * 8 spamspamspamspamspamspamspamspam
If this seems obscure, all you need to remember is this: for strings, be sure to use the same object in the raise and the try, not the same value.
For class exceptions (the preferred technique today), the overall behavior is similar, but Python generalizes the notion of exception matching to include superclass relationships, so this gotcha doesn’t apply—yet another reason to use class-based exceptions today!
Catching the Wrong Thing
Perhaps the most common gotchas related to exceptions involve the design guidelines discussed in the prior section. Remember, try to avoid empty except clauses (or you may catch things like system exits) and overly specific except clauses (use superclass categories instead to avoid maintenance issues in the future as new exceptions are added).
Core Language Summary
Congratulations! This concludes your look at the core Python programming language. If you’ve gotten this far, you may consider yourself an Official Python Programmer (and should feel free to add Python to your résumé the next time you dig it out). You’ve already seen just about everything there is to see in the language itself, and all in much more depth than many practicing Python programmers initially do. You’ve studied built-in types, statements, and exceptions, as well as tools used to build up larger program units (functions, modules, and classes); you’ve even explored important design issues, OOP, program architecture, and more.
The Python Toolset
From this point forward, your future Python career will largely consist of becoming proficient with the toolset available for application-level Python programming. You’ll find this to be an ongoing task. The standard library, for example, contains hundreds of modules, and the public domain offers still more tools. It’s possible to spend a decade or more seeking proficiency with all these tools, especially as new ones are constantly appearing (trust me on this!).
Speaking generally, Python provides a hierarchy of toolsets:
- Built-ins
Built-in types like strings, lists, and dictionaries make it easy to write simple programs fast.
- Python extensions
For more demanding tasks, you can extend Python by writing your own functions, modules, and classes.
- Compiled extensions
Although we didn’t cover this topic in this book, Python can also be extended with modules written in an external language like C or C++.
Because Python layers its toolsets, you can decide how deeply your programs need to delve into this hierarchy for any given task—you can use built-ins for simple scripts, add Python-coded extensions for larger systems, and code compiled extensions for advanced work. We’ve covered the first two of these categories in this book, and that’s plenty to get you started doing substantial programming in Python.
Table 29-1 summarizes some of the sources of built-in or existing functionality available to Python programmers, and some topics you’ll probably be busy exploring for the remainder of your Python career. Up until now, most of our examples have been very small and self-contained. They were written that way on purpose, to help you master the basics. But now that you know all about the core language, it’s time to start learning how to use Python’s built-in interfaces to do real work. You’ll find that with a simple language like Python, common tasks are often much easier than you might expect.
|
Category |
Examples |
|
Object types |
Lists, dictionaries, files, strings |
|
Functions |
|
|
Exceptions |
|
|
Modules |
|
|
Attributes |
|
|
Peripheral tools |
NumPy, SWIG, Jython, IronPython, etc. |
Development Tools for Larger Projects
Once you’ve mastered the basics, you’ll find your Python programs becoming substantially larger than the examples you’ve experimented with so far. For developing larger systems, a set of development tools is available in Python and the public domain. You’ve seen some of these in action, and I’ve mentioned a few others. To help you on your way, here is a summary of some of the most commonly used tools in this domain:
- PyDoc and docstrings
PyDoc’s
helpfunction and HTML interfaces were introduced in Chapter 14. PyDoc provides a documentation system for your modules and objects, and integrates with Python’s docstrings feature. It is a standard part of the Python system—see the library manual for more details. Be sure to also refer back to the documentation source hints listed in Chapter 4 for information on other Python information resources.- PyChecker
Because Python is such a dynamic language, some programming errors are not reported until your program runs (e.g., syntax errors are caught when a file is run or imported). This isn’t a big drawback—as with most languages, it just means that you have to test your Python code before shipping it. Furthermore, Python’s dynamic nature, automatic error messages, and exception model make it easier and quicker to find and fix errors in Python than it is in some other languages (unlike C, for example, Python does not crash on errors).
The PyChecker system provides support for catching a large set of common errors ahead of time, before your script runs. It serves similar roles to the “lint” program in C development. Some Python groups run their code through PyChecker prior to testing or delivery, to catch any lurking potential problems. In fact, the Python standard library is regularly run through PyChecker before release. PyChecker is a third-party open source package; you can find it at either http://www.python.org, or the Vaults of Parnassus web site.
- PyUnit (a.k.a.
unittest) In Part V, we saw how to add self-test code to a Python file by using the
_ _name_ _ =='_ _main_ _'trick at the bottom of the file. For more advanced testing purposes, Python comes with two testing support tools. The first, PyUnit (calledunittestin the library manual), provides an object-oriented class framework for specifying and customizing test cases and expected results. It mimics the JUnit framework for Java. This is a sophisticated class-based system; see the Python library manual for details.- Doctest
The
docteststandard library module provides a second and simpler approach to regression testing. It is based upon Python’s docstrings feature. Roughly, to usedoctest, you cut and paste a log of an interactive testing session into the docstrings of your source files. Doctest then extracts your docstrings, parses out test cases and results, and reruns the tests to verify the expected results. Doctest’s operation can be tailored in a variety of ways; see the library manual for more details.- IDEs
We discussed IDEs for Python in Chapter 3. IDEs such as IDLE provide a graphical environment for editing, running, debugging, and browsing your Python programs. Some advanced IDEs, such as Eclipse and Komodo, support additional development tasks, including source control integration, interactive GUI builders, project files, and more. See Chapter 3, the text editors page at http://www.python.org, and the Vaults of Parnassus web site for more on available IDEs and GUI builders for Python.
- Profilers
Because Python is so high-level and dynamic, intuitions about performance gleaned from experience with other languages usually don’t apply to Python code. To truly isolate performance bottlenecks in your code, you need to add timing logic with clock tools in the
timeortimeitmodules, or run your code under theprofilemodule. We saw an example of the time modules at work when comparing iteration tools’ speed in Chapter 17.profileis a standard library module that implements a source code profiler for Python; it runs a string of code you provide (e.g., a script file import, or a call to a function), and then, by default, prints a report to the standard output stream that gives performance statistics—number of calls to each function, time spent in each function, and more. Theprofilemodule can be customized in various ways; for example, it can save run statistics to a file to be analyzed later with thepstatsmodule.- Debuggers
The Python standard library also includes a command-line source code debugger module called
pdb. This module works much like a command-line C language debugger (e.g., dbx, gdb): you import the module, start running code by calling apdbfunction (e.g.,pdb.run("main( )")), and then type debugging commands from an interactive prompt.pdbalso includes a useful postmortem analysis call,pdb.pm, which starts the debugger after an exception has been encountered. Because IDEs such as IDLE include point-and-click debugging interfaces,pdbis relatively infrequently used today; see Chapter 3 for tips on using IDLE’s debugging GUI interfaces.[81]- Shipping options
In Chapter 2, we introduced common tools for packaging Python programs. py2exe, PyInstaller, and freeze can package byte code and the Python Virtual Machine into “frozen binary” standalone executables, which don’t require that Python be installed on the target machine and fully hide your system’s code. In addition, we learned in Chapter 2 and Part V that Python programs may be shipped in their source (.py) or byte code (.pyc) forms, and import hooks support special packaging techniques, such as automatic extraction of .zip files and byte code encryption. We also briefly met the standard library’s
distutilsmodules, which provide packaging options for Python modules and packages, and C-coded extensions; see the Python manuals for more details. The emerging Python “eggs” packaging system provides another alternative that also accounts for dependencies; search the Web for more details.- Optimization options
For optimizing your programs, the Psyco system described in Chapter 2 provides a just-in-time compiler for translating Python byte code to binary machine code, and Shedskin offers a Python-to-C++ translater. You may also occasionally see .pyo optimized byte code files, generated and run with the
-OPython command-line flag (discussed in Chapter 18); because this provides a very modest performance boost, however, it is not commonly used. As a last resort, you can also move parts of your program to a compiled language such as C to boost performance; see the book Programming Python and the Python standard manuals for more on C extensions. In general, Python’s speed also improves over time, so be sure to upgrade to the most recent release when possible (version 2.3 was clocked at 15–20 percent faster than 2.2, for example).- Other hints for larger projects
Finally, we’ve also met a variety of language features in this text that tend to become more useful once you start coding larger projects. Among these are: module packages (Chapter 20); class-based exceptions (Chapter 28); class pseudoprivate attributes (Chapter 25); documentation strings (Chapter 14); module path configuration files (Chapter 18); hiding names from
from *with_ _all_ _lists and_X-style names (Chapter 21); adding self-test code with the_ _name__ =='_ _main_ _'trick (Chapter 21); using common design rules for functions and modules (Chapter 16, Chapter 17, and Chapter 21); and so on.
To learn about other large-scale Python development tools available in the public domain, be sure to also browse the pages at the Vaults of Parnassus web site.
Chapter Summary
This chapter wrapped up the exceptions part of the book (and the book as a whole) with a look at common exception use cases, and a brief summary of commonly used development tools. As this is the end of the book, you get a break on the chapter quiz—just one question this time. As always, be sure to work through this part’s closing exercises to cement what you’ve learned in the past few chapters. The appendixes that follow give installation hints and the answers to the end-of-part exercises.
For pointers on where to turn after this book, see the list of recommended follow-up texts in the Preface. You’ve now reached the point where Python starts to become truly fun, but this is also where this book’s story ends. You now have a good grounding to tackle some of the other books and resources that are available to help you do real applications-level work, like building GUIs, web sites, database interfaces, and more. Good luck with your journey—and of course, “Always look on the bright side of Life!”
BRAIN BUILDER
1. Chapter Quiz | |
Q: | (This question is a repeat from your first quiz in Chapter 1—see, I told you this would be easy :-)). Why did spam appear in so many examples in this book? |
2. Quiz Answers | |
Q: | |
A: | Because Python is named after the British comedy group Monty Python (based on surveys I’ve conducted in classes, this is a much-too-well-kept secret in the Python world!). The spam reference comes from a Monty Python skit, where a couple who are trying to order food in a cafeteria keep getting drowned out by a chorus of Vikings singing a song about spam. And if I could insert an audio clip of that song here as the theme song for this book’s closing credits, I would . . . . |
BRAIN BUILDER
Part VII Exercises
As we’ve reached the end of this part of the book, it’s time for a few exception exercises to give you a chance to practice the basics. Exceptions really are simple tools; if you get these, you’ve got them mastered.
See "Part VII, Exceptions and Tools" in Appendix B for the solutions.
try/except. Write a function calledoopsthat explicitly raises anIndexErrorexception when called. Then, write another function that callsoopsinside atry/exceptstatement to catch the error. What happens if you changeoopsto raise aKeyErrorinstead of anIndexError? Where do the namesKeyErrorandIndexErrorcome from? (Hint: recall that all unqualified names come from one of four scopes, by the LEGB rule.)Exception objects and lists. Change the
oopsfunction you just wrote to raise an exception you define yourself, calledMyError, and pass an extra data item along with the exception. You may identify your exception with a string or a class. Then, extend thetrystatement in the catcher function to catch this exception, and its data in addition toIndexError, and print the extra data item. Finally, if you used a string for your exception, go back and change it to a class instance; what now comes back as the extra data to the handler?Error handling. Write a function called
safe(func, *args)that runs any function usingapply(or the newer*namecall syntax), catches any exception raised while the function runs, and prints the exception using theexc_typeandexc_valueattributes in thesysmodule (or the newersys.exc_infocall result). Then, use yoursafefunction to run youroopsfunction from exercise 1 or 2. Putsafein a module file called tools.py, and pass it theoopsfunction interactively. What sort of error messages do you get? Finally, expandsafeto also print a Python stack trace when an error occurs by calling the built-inprint_excfunction in the standardtracebackmodule (see the Python library reference manual for details).Self-study examples. At the end of Appendix B, I’ve included a handful of example scripts developed as group exercises in live Python classes for you to study and run on your own in conjunction with Python’s standard manual set. These are not described, and they use tools in the Python standard library that you’ll have to look up. But, for many readers, it helps to see how the concepts we’ve discussed in this book come together in real programs. If these whet your appetite for more, you can find a wealth of larger and more realistic application-level Python program examples in follow-up books like Programming Python, and on the Web in your favorite browser.
[80] * A related call, os._exit, also ends a program, but via an immediate termination—it skips cleanup actions, and cannot be intercepted with try/except or try/finally blocks. It is usually only used in spawned child processes, a topic beyond this book’s scope. See the library manual or follow-up texts for details.
[81] * To be honest, IDLE’s debugger is not used very often, either. Most practicing Python programmers end up debugging their code by inserting strategic print statements and running it. Because turnaround from change to execution is so quick in Python, adding prints is usually faster than either typing pdb debugger commands, or starting a GUI debugging session. Another valid debugging technique is to do nothing at all—because Python prints useful error messages instead of crashing on program errors, you usually get enough information to analyze and repair errors.