
CHAPTER 1: Introducing Julia

There are dozens of programming languages out there: some generic, some focused on specific niches, each claiming to be better than the rest. The most powerful languages–the ones capable of rapidly performing complex calculations–tend to be difficult to learn (and even more difficult to master). Their audience is thus limited to those “hardcore” programmers who usually have some innate talent for this kind of work. The aspiring data scientists are faced with the prospect of devoting considerable time and energy to learning a language that will ultimately serve them poorly, requiring line after line of complex code to implement any useful algorithm.
On the other side of the spectrum are the “plug-and-play” languages, where all the complexities of programming have been carefully encapsulated. The most tedious (and often most widely-utilized) algorithms have been pre-packaged and handed over to the user; there’s very little to actually learn. The problem with these languages is that they tend to be slow, with severe limitations in memory and capability. The data scientist here faces the opposite dilemma: take advantage of a language without a steep learning curve, but be stuck with a fairly weak tool for the job.
Julia is one of the languages that lies somewhere between these two extremes, offering the best of both worlds. In essence, it is a programming language designed for technical computing, offering speed, ease of use, and a variety of tools for data processing. Even though it’s still in its infancy (version 1.0 is still pending and is expected to be released summer 2017), those who have toyed with it enough to recognize its potential are already convinced of its utility in technical computing and data science applications.
Some of the features that make Julia stand out from other programming languages include:
- • Julia exhibits incredible performance in a variety of data analyses and other programming ventures. Its performance is comparable to that of C, which is often used as a benchmark for speed.
- • Julia has a strong base library, allowing for all kinds of linear algebra operations that are often essential components of data analytics modules–without the need to employ other platforms.
- • Julia utilizes a multiple dispatch style, giving it the ability to link different processes to the same function. This makes it easy to extend existing functions and reuse them for different types of inputs.
- • Julia is easy to pick up, especially if you are migrating to it from Python, R, or Matlab/Octave.
- • Julia has a variety of user-friendly interfaces–both locally and on the cloud–that make it an enjoyable interactive tool for all kinds of processes. It features a handy help for all functions and types.
- • Julia seamlessly connects with other languages, including (but not limited to) R, Python, and C. This makes it easy to use with your existing code-base, without the need for a full migration.
- • Julia and all of its documentation and tutorials are open-source, easily accessible, detailed, and comprehensible.
- • Julia’s creators are committed to enhancing it and helping its users. They give a variety of talks, organize an annual conference, and provide consulting services.
- • Julia’s custom functions are as fast and compact as those built into the base Julia code.
- • Julia has excellent parallelization capabilities, making it easy to deploy over various cores of your computer or a whole cluster of computers.
- • Julia is exceptionally flexible for developing new programs, accommodating both novice and expert users with a wide range of coding levels. This feature is rare in other languages.
As you learn and practice with Julia, you’ll certainly uncover many more advantages particular to the data science environment.
How Julia Improves Data Science
“Data science” is a rather ambiguous term that has come to mean a lot of different things since its introduction as a scientific field. In this book we will define it as: the field of science dealing with the transformation of data into useful information (or “insights”) by means of a variety of statistical and machine learning techniques.
Since reaching critical mass, data science has employed all kinds of tools to harness the power and overcome the challenges of big data. Since a big part of the data science process involves running scripts on large and complex datasets (usually referred to as “data streams”), a high performance programming language is not just a luxury but a necessity.
Consider a certain data-processing algorithm that takes several hours to run with a conventional language: even a moderate increase in performance will have a substantial impact on the overall speed of the process. As a language, Julia does exactly that. This makes it an ideal tool for data science applications, both for the experienced and the beginner data scientist.
Data science workflow
People view data science as a process comprising various parts, each intimately connected to the data at hand and the objective of the analysis involved. More often than not, this objective involves the development of a dashboard or some clever visual (oftentimes interactive), which is usually referred to as a “data product.”
Data science involves acquiring data from the world (from data streams stored in HDFS, datasets in CSV files, or data organized in relational databases), processing it in a way that renders useful information, and returning this information to the world in a refined and actionable form. The final product usually takes the form of a data product, but this is not essential. For instance, you may be asked to perform data science functions on a company’s internal data and keep the results limited to visuals that you share with your manager.
Take for example a small company that is opting for data-driven market research, through the use of questionnaires for the subscribers to their blog. Data science involves these five steps:
- 1. Acquisition of the data from the marketing team
- 2. Preparation of the data into a form that can be usable for predictive analytics
- 3. Exploratory analysis of the data to decipher whether certain people are more inclined to buy certain products
- 4. Formatting of work to make the whole process resource-efficient and error-free
- 5. Development of models that provide useful insights about what products the company’s clients are most interested in, and how much they are expected to pay for them.
We will go into more detail about this process in Chapter 5.
Figure 1.1 introduces the “big picture” of data science processes and how the Julia language fits in. The three stacked circles have come to represent Julia in general; in the figure, this symbol indicates a practical place to utilize Julia. It is clear that apart from the development of the data product and the acquisition of the data, Julia can be used in almost every phase of the data science process.
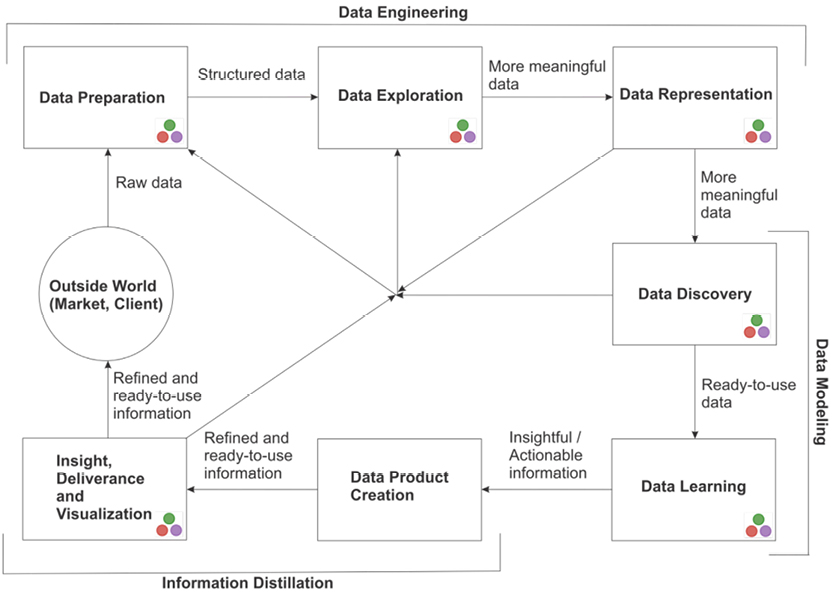
Figure 1.1 The data science process overview. The symbol with three stacked circles indicates steps where Julia fits in.
Consider how much this will simplify your workflow. No need to stitch code from other platforms into your pipeline, creating troublesome bottlenecks. Furthermore, once you have written and tested your code in Julia there is no need to translate it into a low-level language like C++ or Java, since there is no performance benefit from doing this. That’s particularly important considering that this is an essential step when prototyping in languages like R and Matlab.
Julia’s adoption by the data science community
You might be asking yourself: “If Julia is such a great language, why hasn’t it yet been widely adopted by the data science community?” It would be expected that such a versatile language as Julia would have started to shine, like R and Python, claiming its place in the data scientist’s toolbox.
Although Julia is an excellent choice for any kind of data processing project, it still lacks the variety of add-on packages that other, more established languages have to offer (even though the number of available packages is steadily growing, along with the number of Julia users). That’s primarily because of its young age, and is bound to change as time goes by.
What’s more, data science practitioners and learners are still not convinced that they can master it with the same ease as Python and R. These languages boast large user communities poised to make programming not only easy, but fun. Consider the Python Challenge: a series of programming tasks that make learning Python an adventure.
Although there is little doubt that Julia will one day experience comparable levels of fandom, it is not quite there yet–especially among data science practitioners. Despite its great potential, many people still find it challenging to write clean code and debug their first drafts in Julia. This may make the whole development process seem a bit daunting for newer users, leading to discontinuation.
Pre-made programs usually come in collections called libraries or packages. Although there are sufficient packages in Julia to perform all data science tasks, some algorithms may be missing, making some coding necessary. The early adopters of HTML and CSS faced similar difficulties during the first years of the web, but when their esoteric skill became more mainstream they found themselves in a good situation. It is likely that the same thing can happen to Julia practitioners as well. Even if you don’t actively participate in the Julia coding community, you are bound to see great benefits from becoming familiar with the language. Besides, as the community grows, things are only going to get easier for its users—particularly the early adopters.
Julia Extensions
Although Julia currently has a relatively small set of libraries (usually referred to as “packages”) that expand its functionality, Julia’s resources are continually expanding. Between early 2015 and mid-2016 the packages doubled in quantity; this doesn’t seem to be slowing. As Julia is used primarily by people who deal with advanced computing applications, the packages being developed are designed to meet that need. They are also updated relatively frequently, making them robust additions to the language. Finally, since the Julia community is small and well-connected, there are rarely duplicate packages.
Package quality
“What about the quality of the existing packages?” you may wonder. As the users developing these packages are generally experienced, they try to generate high-quality code, often reflected by the “stars” GitHub users award. It is worth noting that across the various packages, the number of stars these packages have received by the users has grown by about 50% between late 2015 and the time of this writing. Evidently there is a growing appreciation of the Julia code that is uploaded in this well-known repository.
An interesting attribute of many GitHub packages out there (across different languages) is that they are tested for build integrity, coverage, etc. so that you have a good idea of their reliability before you start using them. For the current version of Julia (0.4) the tests are impressive: out of 610 packages, 63% of the packages pass all the tests while only 11% of all packages fail the tests (the remaining packages have not been tested yet or are not testable).
Finding new packages
For more up-to-date information on how the Julia packages fare, you can visit http://pkg.julialang.org/pulse.html. In addition, at the end of this book there is a reference list of the most useful packages for data science applications. It’s also worth noting that even though Julia may not have the breadth of packages of other languages, it does have a great depth of packages relevant to data analytics. Throughout this book we will be exploring how these packages work and how they can help you tackle challenging data science problems.
About the Book
If you are reading this book (and plan to follow the examples and exercises in it), you must be at least somewhat committed to the field of data science. We assume that you have basic programming experience, and have some understanding of data structures, GitHub repositories, and data analysis processes. If you have implemented an algorithm yourself, created any program from scratch, or adapted an existing program from GitHub to solve a problem—even a simple one—you are off to a great start.
Most importantly, we hope that you have a hands-on attitude and are comfortable using various technical documents and forums when you are stuck. Finally, you must have a genuine interest in learning this tool and making it a part of your workflow in data analytics projects.
If you’re still reading at this point, you should be able to get the most out of this book, making considerable progress toward mastery of Julia for data science applications. You may not become an expert Julia developer, but you will be knowledgeable enough to understand a new script, and competent enough to get Julia to do some interesting data analytics for you. This includes some data engineering, which is generally an irksome process in most programming languages.
This book will present you with a series of hands-on problems representative of those commonly encountered throughout the data science pipeline, and guide you in the use of Julia to solve them. You won’t have to reinvent the wheel, as the majority of these problems make use of existing packages and built-in functions. What’s more, you will have the opportunity to practice on a couple of real datasets and let experience be your teacher, without having to go through the trial-and-error loops that arise in the absence of guidance.
The topics we are going to cover include:
- 1. The various options for IDEs that exist for Julia, as well as the use of a text editor for creating and editing Julia scripts.
- 2. Language specifics (main programming structures and functions), along with how they apply in a few relatively simple examples.
- 3. The different ways Julia can help you accomplish data engineering tasks, such as importing, cleaning, formatting and storing data, as well as performing data preprocessing.
- 4. Data visualization and some simple yet powerful statistics for data exploration purposes.
- 5. Dimensionality reduction through a variety of techniques designed to eliminate the unnecessary variables. In this section we’ll also cover feature evaluation.
- 6. Machine learning methods, ranging from unsupervised (different types of clustering) to supervised (decision trees, random forests, basic neural networks, regression trees, and Extreme Learning Machines).
- 7. Graph analysis, from examining how the most popular algorithms can be applied to the data at hand, to pinpointing the connections among the various entities.
In addition to all this we will revisit some data science essentials, so that you have the data science pipeline fresh in your mind before delving into its various components. Furthermore, all of the material is accompanied by supplementary information that will be particularly useful to the novice users of Julia, including a number of resources for learning the particulars of the language as well as installing it on your machine.
Throughout the book, you will be exposed to examples and questions that will reinforce the material covered in each chapter. Once you are confident that you have internalized at least most of the information presented here, you will be able to write your own wrapper programs, and make good use of this extraordinary programming language.
You will be given directions on how you could extend all this to a parallelized setting (even on a single computer if you don’t have access to a cluster). For those of you who are bold enough, in the last chapter of the book you will have an opportunity to create a data science application from scratch using Julia, making use of all the stuff you’ll have learned in this book. Are you ready to begin?