
3.1. Introduction to Distributed Data Structures
Space-based applications are typically designed around distributed data structures. Conceptually a distributed data structure is a data structure that can be accessed and manipulated by multiple processes at the same time. In most distributed computing models, distributed data structures are hard to achieve. Message passing and remote method invocation systems provide a good example of the difficulty. As Figure 3.1 illustrates, these systems tend to barricade data structures behind one central manager process, and processes that want to perform work on the data structure must “wait in line” to ask the manager process to access or alter a piece of data on their behalf. Attempts to parallelize or distribute a computation across more than one machine face a bottleneck: Since the data are so tightly controlled by the one manager process, multiple processes can't truly access the data structure concurrently.
Figure 3.1. Most computing environments hide data behind a centralized manager process, whereas JavaSpaces technology easily supports distributed data structures.
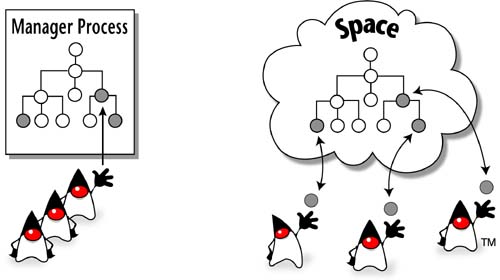
Distributed data structures provide an entirely different approach where we uncouple the data from any particular process. Instead of hiding data structures behind a manager process, we represent data structures as collections of objects that can be independently accessed and altered by remote processes in a concurrent manner. With distributed data structures, processes no longer wait in line—they can work at the same time on independent pieces of the data structure as long as they don't step on each other's toes. This last point is important—it is the “stepping on toes” that has always been difficult to avoid when building distributed systems with conventional network tools. However, as we will see over the next several chapters, this is the area where JavaSpaces technology really shines.
There are two fundamental pieces needed for any distributed data structure: a representation of the data structure, along with a protocol that processes follow when accessing and altering the data structure. The protocol typically ensures that operations on the data structure occur in a safe and fair manner in the presence of other processes accessing the structure. Let's see how we can represent distributed data structures with entries, and how we can implement distributed protocols using space operations.
3.1.1. Building Distributed Data Structures with Entries
Let's say we want to store an array of values in a space so that multiple processes can access and alter it concurrently. This array might hold the scores of the members of a distributed game, the values of a matrix that is being multiplied, or the pixels of an image that is being ray traced.
The simplest and most obvious approach is to create an entry that holds an array (let's say scores from an online game), like this:
public class Scores implements Entry {
public Integer[] values;
public Scores() {
}
}
To read or alter values in the array, we need to read or remove the entire array from the space. If many processes are trying to access the array at the same time, then the entry itself becomes a point of contention—just as in a manager process model, we've created a bottleneck.
Since it isn't possible for multiple processes to access and alter the values array within the entry concurrently, our space-based Scores entry isn't a truly distributed array. Let's try again and create a distributed version this time, by breaking the array up into a collection of entries, each of which represents one array element. We can represent an element of an array like this:
public class Score implements Entry {
public Integer index;
public Integer value;
public Score() {
}
public Score(int index, int value) {
this.index = new Integer(index);
this.value = new Integer(value);
}
}
Each Score entry holds an index (the element's position in the array) and a value (the value of that array element). To initialize an array of length ten we can do the following (see the complete source code for error checking):
for (int i = 0; i < 10 ; i++) {
Score score = new Score(i, 0);
space.write(score, null, Lease.FOREVER);
}
Iterating through this loop, we add ten Score entries to the space, each of which is initialized with an index and the value zero. To access a score, say the fourth one, we use a read operation like this:
// create a template to retrieve the element Score template = new Score(); template.index = new Integer(3); // read it from the space Score score = (Score) space.read(template, null, Long.MAX_VALUE);
To update the value of a score, we use take (with the template we created above) and then a write as follows:
// remove the element so we can alter its value Score score = null; score = (Score) space.take(template, null, Long.MAX_VALUE); // alter the value score.value = new Integer(1000); // return the element to the space space.write(score, null, Lease.FOREVER);
There you have the basics of creating a simple distributed data structure. We've take a common data structure (an array) and created a distributed version by using multiple entries to represent it in a space. Once we've “distributed” the data structure into multiple entries it becomes concurrently available for remote processes to read and alter. If a process wants to update element five of the array, it can do so without holding up another process reading element three. This kind of concurrent access to the structure wasn't supported by our first naive attempt at a space-based array, nor by manager process computing models. Granted, this particular data structure leaves a lot to be desired—we have no way of knowing the length of the distributed array, for instance—but this simple example is a good start to get you thinking about how to turn ordinary data structures into their distributed representations.
Along with designing a distributed data structure, we've developed a simple protocol that processes must follow when dealing with the distributed array. To read an array value, we just read its current value from the space. To alter an array value, we first remove the entry with take, update the value field, and then return the entry to the space with write. This is about as simple as space-based protocols get, but you could easily extend the protocol to store the size of the array, to copy a value from one array element to another, to delete an element, or to perhaps sort the array.
Now that we've seen a simple example that provides the two key pieces needed for any distributed data structure—a space-based representation and a protocol—let's get on with our exploration of the most basic and common distributed data structures. Some of these distributed data structures (like the array example) have analogs in the sequential programming world and will be familiar to you (although their representation in the space will be new), while others have no analog in the sequential world and will be brand-new.