
12
Effective Methodologies in Pharmacovigilance for Identifying Adverse Drug Reactions Using IoT
Latha Parthiban1*, Maithili Devi Reddy2 and A. Kumaravel3
1Bharath Institute of Higher Education and Research, Tamilnadu, India
2Department of Computer Science and Engineering, Bharath Institute of Higher Education and Research, Tamilnadu, India
3School of Computing, Bharath Institute of Higher Education and Research, Tamilnadu, India
Abstract
Nowadays, every recommended drug has some side effects based on the health of the patient. This negative impact leads to Adverse Drug Event (ADE) and the time of ADE association to the specified drug is called as Adverse Drug Reaction (ADR). With each and every day, more and more devices are getting connected to internet and IoT is becoming an evolving area. Since ADR results in fatality of humans, the primary analysis of any disease is a most significant process. As a result, the protection of a novel drug has been determined from its entire manufacturing. Unexpectedly, the potential of analyzing a drug’s toxins has been restricted by several medicinal tools. At the time of modeling any kind of drug, it has been sampled on animals in order to test the function of drug applied, but the capability of inferring ADRs is minimized by the impotence of animal sampling which has to be completely understandable for human impacts. While a drug provides primary toxicity investigation, it is applied for testing on humans at the time of increased population. In this work, a novel neural predictive classifier for improving the prediction rate of ADR is proposed.
Keywords: ADR, IoT, Pharmacovigilance, feature selection, data mining, neural predictive classifier
12.1 Introduction
Generally, data is assumed to be the major source for several trading process and commercial applications. By identifying the information about medicinal fields is an optimal process from where data mining (DM) task has been considered as more crucial operation. Some of the database refers a collection of data that is correlated with certain structure as well as requirements. The process of developing different data is named as “Data Base Management System” (DBMS). Here, a new computation of Knowledge Discovery is applied for the complete database. DM can be determined by obtaining hidden data which is represented by massive number of data repositories. Knowledge Discovery in Databases (KDD) that is said to be non-trivial operation to find effective, novel, probably suitable, as well as readable patterns of data. According to the above definition, different types of data like numerical value, alphabets are determined by applying this method. The association among all data provides information and it is altered into knowledge about historical facts and future plans. In addition, there are some other parameters such as data pre-processing, selection, cleaning, and visualizing which are considered to be portions engaged in KDD operation.
Here, DM is connected with the study of database, Machine Learning (ML) and visualization. It is used to discover efficient remedy for many types of ailments and focus in exploring the required information from numerous set of data. DM is the crucial part of KDD which is applicable to derive the significant patterns from data that can be perceived in a simple manner and to orient the data. It is a model applied to find huge amount of data and to offer adaptable data. Also, KDD process involves in forming new information. Data warehouse is considered to be the major source to obtain data and pre-processing is an essential procedure to analyze various types of dataset. The final stage of KDD is to verify the pattern that has been generated with the help of DM methods which appears in huge database. Hence, the predefined data is composed with set of patterns that describe about features of data, patterns that are presented consecutively, and object that has been identified inside the clusters present in database which is described in Figure 12.1.
12.2 Literature Review
DM is used to find essential association, patterns, and movements between massive data that has been recorded in repositories, by using the pattern recognition techniques as well as statistical models. The above method is assumed to be an evolving portion of scientific development, in educational sector and firms. Mining is one of the promising issues in clinical field. Medicinal DM deals with maximum capability to identify the hidden patterns from medical application.

Figure 12.1 Knowledge discovery in databases.
DM is a logical task used to search maximum number of applicable data. By using the DM method, huge amount of information is capable of transforming essential as well as required data. Also, DM is more suitable for physicians to develop and improvise the disease prediction in a rapid manner, thus risk in detecting the ailments are minimized. Diverse models are assessable for every domain. DM is one of the mandatory factors in medical application which offers automatic prediction data that is obtained from huge dataset. In [1], the authors developed new ML technique that incorporates simulated annealing (SA) and support vector machine (SVM).
In [2], the authors discussed many feature selection algorithms. They also proposed a variant of the approach seeing the significance of each feature and verified the presentation of the proposed methods by experiments with various real-world datasets. Their feature collection methods based on the biologically inspired algorithms produced better presentation than other methods in terms of the classification accuracy and the feature significance. In particular, the modified method considering feature meaning demonstrated even more enhanced performance.
In [3], it was concluded that real-life data groups are often spread with noise. In [4], the authors presented supervised learning classification techniques. The results show that SVM with Data Gain and Wrapper method has the best results as related to others who tested. In [5], the authors presented medical diagnostic system. In [6–10], the authors discuss the ML algorithms using evolutionary computing for classification. In [11–14], the authors describe the various classification approaches for Pharmacovigilance. In [15], security requirement for medical diagnostic system was discussed.
12.3 Data Mining Tasks
The main objective of computer invention is to give assistance for humans by implementing difficult and prolonged task in an automated manner. The major advantage in discovering computer is that massive amount of digital information has been saved in the storage space provided by machines. Such data volumes could be applied to learn the facts, behaviors, and default aspects as well as to make decisions according to the human requirements. Several models are proposed for suggesting machines to read information. Specifically, ML is one of the scientific domains which have been treated as implementation of frameworks, rules, and techniques which may be obtained from data. These models are capable of constructing a detective method according to input data that is applied in decision making process. In recent times, DM is referred to be the region of computer science from where ML models are applied to identify the past unreliable features from numerous dataset. In addition, DM is used in examining the data-sets which helps in discovering provocative, and essential patterns, and tendency. The DM process is comprised with models at interchanging AI, ML, statistics, arithmetic, database systems, and so on. The main objective of DM process is to obtain data from a dataset as well as to convert in a readable format that can be applied for future application. It is assumed to be the intermediary procedure of KDD process which concentrates in finding more reliable patterns and techniques that helps in predicting the data type. Also, few steps in KDD are data preparation, data selection, data cleaning, combination of essential data, and interpreting results obtained from mining process. Diverse DM techniques are developed as well as executed in various research fields like statistics, ML, mathematics, AI, and pattern recognition that applies particular models. There are commonly used DM processes, which are explained in the upcoming sections. Data mining procedure in Pharmacovigilance is shown in Figure 12.2.
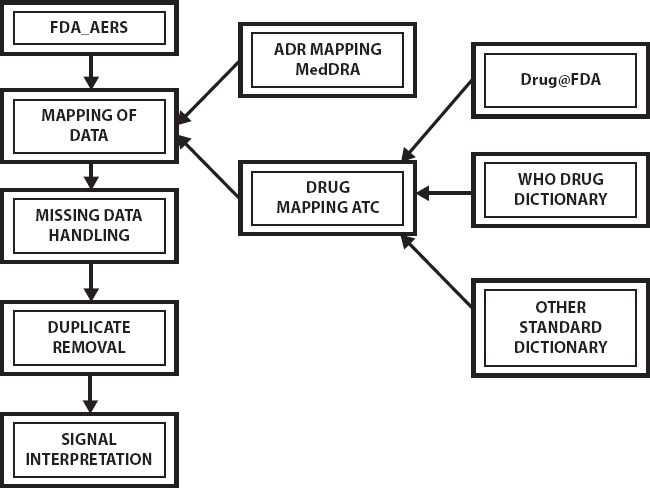
Figure 12.2 Data mining in Pharmacovigilance.
12.3.1 Classification
The key objective of this model is to categorize a dataset into more than one predetermined classes. It can be achieved by implementing the mapping which is derived from a vector of values toward a classified parameter. From this classification, the membership of a data instance can be detected for provided predetermined classes. For example, collection of outlet can save customer information into three classes, namely, maximum spending, moderate spending, as well as minimum spending users. The classifying operation is applied for several other domains like economic sectors, bioinformatics, classification of document, multimedia, textual computation, social networks, and so on.
12.3.2 Regression
This method is considered as forecasting model which connect the dataset to quantitative features as well as computes the variable measure. Regression has various applications like using the likelihood where a patient acquires illness on the basis of analysis report and detection of spontaneous team according to the technical information of existing matches. It is generally applied in financial, ecological studies, market tendency, meteorology, as well as epidemiology.
12.3.3 Clustering
The DM operation is applied to find a group of clusters to define the data. Mostly, clustering techniques have been applied in the absence of class which has to be forecasted in an available input data and classified into set of identical instances. There are few applications of clustering which is applicable to find the similar subsets of customers present in database of business groups of objects including the same attributes. It is utilized for several applications like gene computing, intrusion of network, clinical imaging, analyzing the violation, and text mining. In contrary, the classification has predefined classes that should be obtained from data, and seeking for cluster which depends upon the measures of homogeneous data with no help of clients.
12.3.4 Summarization
It is one among the DM process which offers an accurate definition of subset of data. The summarization models are often applied to unstructured data such as classifying text and combine the document by distributing identical behavior. It also uses several tedious functions that have summary criteria as well as identifying the functional associations among variables. Hence, it is mostly employed in the communicative analysis of data and automated production of reports.
12.3.5 Dependency Modeling
It is employed for identifying the methods which explains the important base among variables. This method mainly concentrates in finding the dependencies of each data values. The dependency models can be divided into two phases. Initially, structural level of a method that is based on local variables, whereas quantitative level denotes the efficiency of dependency in a numeric scale. These modeling techniques are applied in retailing, commercial purpose, process management, software designing, and assembly line optimizing process.
12.3.6 Association Rule Discovery
This technique aims in finding the set of items that has been collected from records of a database as well as the correlation between this information is more useful to obtain maximum association which satisfy particular thresholds. It is mainly employed to discover robust patterns from huge datasets under the application of diverse values. Various domains apply this model to understand the intersection massive dataset. At this point, the association rule is named as market basket analysis. Also, there is alternate mandatory application from where the association discovery has been employed such that accessing web page, interacting network application, credit card facilities, medical analysis, bioinformatics, and so on.
12.3.7 Outlier Detection
Here, the outlier is said to be an observation which is more inconsistent by deviating from alternate items of dataset from where it has been originated. Even though the outlier is assumed to be fault or error, it carries more essential data. These models are presented for various domains like environmental analysis, credit card malfunctioning, medicinal trials, network intrusion detection, system process investigation, as well as alternate data analyzing issues.
12.3.8 Prediction
This operation seeks for association among temporary series of actions. The data instances looks like sequences of actions, from where all functions are composed with time of event. There is major problem in detecting the event sequences which is to discover the sequential segments, and set of events that happens frequently. For instance, identifying that a predefined event E1 happens, within a time interval t, also event E2 with maximum probability p. Instances of applications to apply for all alarm detection used in telecommunications, web log designing, client action series, error detection while developing plants, and environmental conditions.
12.4 Feature Selection Techniques in Data Mining
Feature selection is an important procedure in DM using different techniques as given below.
12.4.1 GAs for Feature Selection
In [4], the authors presented a integrative co-evolutionary technique for FS-based GA including three populations, where it mainly aims on FS process and on instance selection, as well as to concentrate on FS and instance selection. Here, the introduced model reports the FS and instance selection in a unique performance that minimizes the processing duration. These types of models undergo further investigations for the provided datasets with thousands of features that contributes unwanted features and noisy data. In addition, they established massive populations dependent GA for the purpose of FS technique, which is comprised with two adjacent populations distributed for interchanging data to improvise the searching potential. Here, local search has been computed on optimal individual for all population that tends to enhance the computation. This presented technique undergo testing with diverse filter as well as wrapper values, that showcased a powerful FS process, also sampled using datasets along with more number of features.
The authors in [5] projected a model to report the FS-based issue by using GAs for feature clustering, and GA has been applied to make optimized cluster middle values in clustering model which is essential to cluster the features as diverse clusters. Features present in every cluster undergoes ranking on the basis of distance measures to the intermediate cluster. The FS process could be attained by selecting top most features as a representative from every cluster. The deployed model shows an effective datasets including more amounts of features. They established a GA-relied FS technique by considering the domain knowledge about economical distress forecasting so that features are divided as various groups as well as GA have been employed for feature subsets that contains best candidate features from every cluster. The above process might consist of identical issue with respect to avoid feature communications. Subsequently, GA is applied in two-stage method, which uses a filter value for ranking the features and selects a first ranked feature which is then employed for GA based FS.
Bio-encoding method in GA which comprises of every chromosome along with pair of strings is applies in [6]. The primary string is a binary-encoded, which denotes the FS process while secondary string is encoded in the form of real-numbers by implying the feature weight. By integrating with Adaboost learning technique, the bio-encoding approach reaches a best performance when compared with conventional binary encoding. A novel representation, which includes FS as well as parameter optimization of assertive classifying method like SVM, was used by the authors. The length is defined as total count of features as well as parameters. They designed a three-level representation in GA and Multilayer Perceptron (MLP) which is useful in FS operation that signifies the election of features, also pruning of neurons, and the structure of MLP. The above mentioned instances recommend that combination of FS as well as optimizing the classification technique is very efficient to enhance the classifying operation as data and classification models has to be optimized.
12.4.2 GP for Feature Selection
Several works have been applied genetic programming (GP) for identifying optimized feature subset and concurrently equipped in the form of classifier. In this, a wrapper FS method which depends upon the multi-tree GP that selects optimal feature subset at the same time as well as a trained classification under the application of chosen features was modeled. Additionally, two novel crossover processes are established to improve the GP performance in selecting features. According to the two crossover operations developed in [7], it deployed an alternate crossover tool that operates in random selection of sub-tree from the primary parent and to search for effective location from alternate parent. It displayed a successful capability of GP to perform as simultaneous FS and in training a classifier. It has the same work that applies GAs in concurrent FS and to produce optimized classification process; however, it has the major variations of GP that applied for searching process to select features and in the form of classifier for classification technique (embedded FS) as GA is employed only for exploring purpose.
The authors also presented a mutual data metric technique for ranking single features as well as to eliminate the vulnerable unwanted features in a primary stage, where GP have been used for selecting a subset of residual features. In order to acquire various merits of diverse values, various filter values has been employed in ranking features and group of features have been selected on the basis of individual metric. By concatenating the above features, it might be applied as input for GP to improve the FS operation. Unfortunately, there is a potential shortcoming is that to eliminate the essential features with no consideration of communication with alternate features. In [7], the authors developed alternate type of single feature ranging technology, that consist of frequency embedded feature which has a unique score and ranked accordingly. Consequently, FS has been accomplished by applying most top ranged features which is induced for classification. It is the path of estimating the unique features to consider the adjacent ones that is capable of removing the shortcoming of individuals to rank features, respectively.
A GP relied multi-objective filter FS model has been presented here for binary classification issues. In contrast, many of the filter approaches can estimate the relation of individual feature of class labels, and the presented technique is capable of finding the correlation among hidden association from feature subset as well as the target classes, also to attain effective classification process. GP consists of minimum number of process in selecting features for multi-objective condition. It is more attractive to examine the upcoming process as GP shows a potential reporting of FS as well as multi-objective issues.
12.4.3 PSO for Feature Selection
Here, continuous PSO as well as binary PSO have been applied for filter and wrapper techniques with unique objective and multi-objective FS. The presentation of every particle within PSO has been applied in selecting features which is a typical operation where the dimension is same as total count of features present in the dataset. A bit-string could be a binary value where binary PSO in continuous PSO. While applying the binary representation, “1” refers the FS, whereas “0” symbolizes no selection. In case of employing the continuous representation, a threshold θ can be applied to compute the selection of specified feature, which has the value greater than θ, and then, adjacent features are selected. Else non-selected features are available. In [8], the authors presented the application of PSO and statistical clustering that helps to cluster the identical features into similar cluster for FS that has novel representation to combine the statistical feature clustering data at the time searching operation is carried out in PSO. The novel representation reveals that the features derived from similar cluster that has been organized together as well as individual feature have been chosen from all clusters. The projected technique shows the potential of minimizing the count of features. The technique was enhanced by enabling the selection process for many features from the identical cluster which helps to improvise the classifying operation.
By acquiring the knowledge from neighbors’ experience, by interacting under the application of gbest, as well as by learning from every individual’s self-experience by pbest are assumed to be the main suggestions of PSO. In [8], the authors deployed a gbest resetting model by adding zero features to suggest the swarm for searching tiny feature subsets. They assumed the count of features while upgrading pbest as well as gbest at the time of exploring PSO, that tends to decrease the amount of features than the conventional update of pbest and gbest techniques with no alleviation in classifying operation. All estimation present in local search has been improved by measuring the fitness relied on features which is often modified from required to non-required and vice versa. Therefore, the presented model again reduces the feature count and enhances the classifying performance than existing models as well as a reputed PSO. Any PSO with more number of swarms helps to share the experience which can be used in FS operation but tends in greater computation expense.
12.4.4 ACO for Feature Selection
In previous models, ACO as well as SVM have been employed for wrapper FS that is useful in face recognition, which consist of actual features that are obtained by applying the strategy of PCA from the images which is present in pre-processing phase. In [8], the authors projected the application of restricted pheromone measures in ACO that is applied for FS process as well as the deployed technique has been upgraded with pheromone trails of edges by linking diverse features of best-so-far solution. The final outcome displayed that the newly deployed technique attains good performance when compared with SA, a GA, and TS dependent models with respect to classification process and amount of features. Techniques applied in [8] use a ACO to select features concurrently as well as to parameter optimization of SVM, that consist of weighting model used in computing the probability of ant choosing specific feature. They also integrated ACO with DE for FS, and DE has been applied in searching the optimized feature subset on the basis of solutions derived by ACO. A classical FS technique has been presented for ACO, so that ACO starts with minimal number of core features. In [9], the authors referred an applicable ACO model including two colonies for FS task, where the initial feature allocated the feature value which is more essential and secondary colony is useful to choose unique features. They related the process of ACO along with GA-relied FS model that initiates ensemble classification. Hence, the simulation outcome depicts that ACO performs better in case of single classifiers are tiny at the time of GA performing optimal process while having maximum values.
Several ACO-based wrapper techniques are applied as fitness evaluation criteria and the fitness of ants have been measured with the help of entire classification process, as the operation of single features consider the further enhancing operation. Also, the fitness functions have been added for classifying process as well as count of features. Then, by expanding the process on individual objective ACO as well as a fuzzy classification that is applied for FS process, they deployed a multiobjective wrapper technique where the ACO focuses in reducing classification error as well as count of features. In [9], the authors introduced a novel multi-objective ACO which can be applied for filter FS operation that obtains elitism principle to improve the converging process that applied non-dominated solutions to include pheromone which results in reinforcing the exploitation, as well as to be used in a crowding relational operator to balance the diversity of solutions. The derived final outcome shows a better performance when compared with individual objective methodologies, since it is more attractive to analyze the application of multi-objective ACO in FS process.
12.5 Classification With Neural Predictive Classifier
The Semi-Convergent Matrix is constructed in SCM-NPC technique for discovering similarity information based on cloud user request on cloud big data with higher search accuracy. The SCM-NPC method employs Semi-Convergent Matrix techniques in parallel which maximize the flow of computation at the time of data extraction. Let us consider that there are numerous CNij Cloud nodes dispersed in Cloud platform. The cloud nodes which contain the similar user requested data in Cloud platform are arranged in Semi-Convergent Matrix to improve the rate of computation during data extraction. Therefore, Semi-Convergent Matrix structure M is represented as follows:
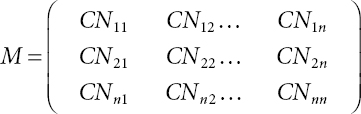
From Equation (12.1), CNij indicates the cloud nodes that consisting of resemblance user requested data. In Semi-Convergent Matrix, cloud nodes are arranged in row and column respectively. With the ever increasing size in big data, the issues that limit the applications are time complexity and space complexity. The Semi-Convergent Matrix in SCM-NPC technique significantly reduces the time complexity and space complexity through building the matrix with cloud nodes that includes similarity user requested data. The matrix M is a Semi-Convergent Matrix if the limit stratifies following conditions:
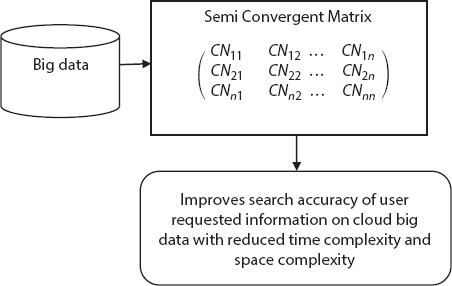
Figure 12.3 Semi-Convergent Matrix construction for improving search accuracy.
The following diagram shows the Semi-Convergent Matrix construction process in SCM-NPC technique.
As shown in Figure 12.3, SCM-NPC technique efficiently identifies similarity information of cloud user requested data by creating the Semi-Convergent Matrix. This, in turn, helps for SCM-NPC technique to improve search accuracy on big data with minimum time complexity and space complexity.
12.5.1 Neural Predictive Classifier
The neural predictive classifier exploits the human neuron on a system. Billions of neurons are interconnected in human brain for conveying the information’s with other layer using electric and chemical signals. A multilayer network called neural predictive classifier which is made up of input layer neurons, hidden neuron, and output neurons.
Back propagation neural network is a supervised learning that is used to classify the medical data conditions on big data. The main aim of using neural predictive classifier is to reduce error rate during the classification. Back propagation is performed with the aid of three different layers. The construction of the neural network for classification of medical data on big data is shown in Figure 12.4.
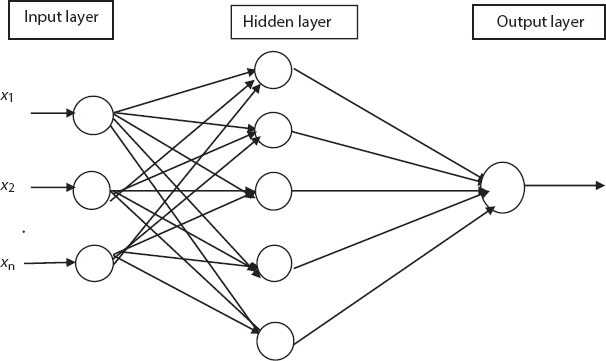
Figure 12.4 Structure of neural predictive classifier for classification.
Figure 12.5 demonstrates the processing diagram of activation function. The hidden layer is a processed layer that includes two functions, i.e., sum function and activation function. The activation function utilized sigmoid function since it unites nearly linear performance, curved behavior and nearly constant behaviors based on the input value. A sigmoid function is a statistical function that contains an “S” shaped curve as a sigmoid curve. A sigmoid function lies within the finite ranges at negative infinity and positive infinity, while the output can only be a number between −1 and 1. The sigmoid function is mathematically formulated as follows:
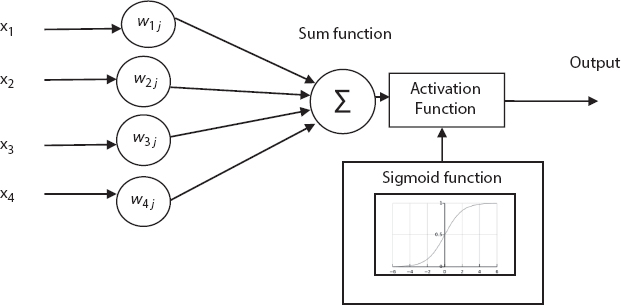
Figure 12.5 Processing diagram of activation function for classification.
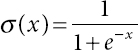
From Equation (12.3), sigmoid function σ (x) is formulated. In hidden layer, product of the input similarity data from the input layer with the weight between input layer and hidden layer is summed with the aid of SUM function. The SUM is set of the output nodes from hidden layer which multiplied with the weights consigned to the each input value to get a single number and process through sigmoid function (activation function). Subsequently, a new weight among the hidden layer and the output layer transmitted from hidden layer output to the output layer. The output layer is the processing unit that contains summation function and activation function. In output layer, the multiplication of the activated output of hidden layer and the synaptic weight among the hidden layer and output layer is summed up with the support summation function. Then, it is transmitted to the activation function for choosing final output using threshold value of the activation function.
The resultant output of neural network is compared with the target for computing the error rate which is expressed as follows:
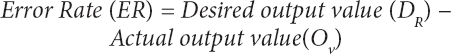
The measured error value then passed backward to the input from the output by means of updating the synaptic weight. This process is repeatedly performed until the error is reduced during the classification of climate data on cloud big data. Thus, the learning rate and momentum rate are initiated for gradient fall to discover the weight that lessens the error. The error rate between the output layer and hidden layer are determined by using following mathematical formula:
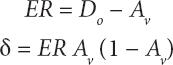
From Equations (12.5) and (12.6), error rate is determined and then compared with target value, whereas Do is represents desired output neuron value and Av signifies the activation value using sigmoid function. Here, Av (1 − Av) indicates the derivative of the sigmoid function in hidden layer. Therefore, the synaptic weight is computed is represented as follows:
From Equation (12.7), ΔSWty,z demotes the updated synaptic weight between the output layer and the hidden layer, whereas η represents the learning factor that characterizes the relative variations in synaptic weights and input (X). As a result, the updated synaptic weight is described as the error multiplied with the input. Thus, the new weight is characterized as follows:
The above waiting function is utilized for computing the weight value. Hence, the new weight is formulated by using the following:
From Equation (12.9), the new weight is formulated depends on original weight is assigned with updated synaptic weight. Therefore, the SCM-NPC technique used neural predictive classifier to improve the classification accuracy of climate data on big data. The number of neurons (i.e., attributes) in the hidden layer is to find out the optimal number of neurons which supports to provide the better classification of climate data on cloud big data. There are two functions exploited in the hidden neurons, i.e., summation of the synaptic weight and the activation function. The activation function utilized in neural predictive classifier as sigmoid transfer function to handle complex problems during the classification of climate data on cloud big data. At last, the output layer generates the target output value for predicting climate data information on cloud big data.
The algorithmic process of neural predictive classifier for classification of medical data on cloud big data is shown in the following.
As shown in Algorithm 12.1, at first, the neural network is created with random weights. For similarity data obtained from Semi-Convergent Matrix, the error rate is determined for updating the new weight in back propagation of classifier in order to get the activation output. The output of the activation is concluded, and the climate data is present in cloud big data. In SCM-NPC technique, the sigmoid function is used as an activation function. This produces the required output. If the activation produces the output as −1, then the data is classified as the Adverse Drug Reaction (ADR). Otherwise, the data is no ADR. The neural predictive classifier algorithm classifies the climate data from cloud big data through the activation function which resulting in improved classification accuracy.
12.5.2 MapReduce Function on Neural Class
The SCM-NPC technique employs MapReduce function on neural class to perform prediction analytics of ADR. The MapReduce function in SCM-NPC technique process huge volumes of data in a parallel fashion. The SCM-NPC technique employs map-reduce function on neural class to perform predictive analytics of ADC as in Figure 12.6. In map reduce function, the input is taken by map task and revamps the content into Key-Value pair where the key has class, attributes, and value acquired from neural class which mathematically represented as follows:
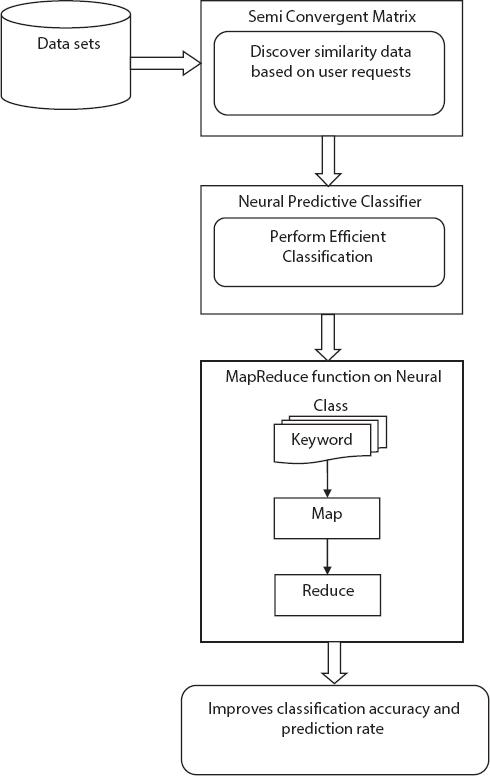
Figure 12.6 Neural predictive classifier.
12.6 Conclusions
In this paper, different computational techniques for feature selection in literature for pharmacovigilance is reviewed and discussed. Also various DM tasks for effective Pharmacovigilance are presented. The classification method proposed can find the presence of ADR and the proposed algorithm provides less computation time when compared to up-to-date works. With all medical devices slowly getting connected to internet, it has become more easy to get patient details and update ADRs.
References
1. Parthiban, L. and Subramanian, R., Intelligent heart disease prediction system using CANFIS and genetic algorithm. Int. J. Biol., Biomed. Med. Sci., 3, 3, 157–160 2008.
2. Xue, B., Zhang, M., Browne, W.N., Particle swarm optimisation for feature selection in classification: Novel initialisation and updating mechanisms. Appl. Soft Comput., 18, 261–276, 2014.
3. Venkatesan, A.S. and Parthiban, L., A novel nature inspired fuzzy tsallis entropy segmentation of magnetic resonance images. Neuroquantology, 12, 2, 221–229, 2014.
4. George, G., and Parthiban, L., Multi objective fractional cuckoo search for data clustering and its application to medical field. J. Med. Imaging Health Inform., 5, 3, 423–434, 2015.
5. Nikfarjam, A., Sarker, A., O’Connor, K., Ginn, R., Gonzalez, G., Pharmacovigilance from social media: Mining adverse drug reaction mentions using sequence labeling with word embedding cluster features. J. Am. Med. Inform. Assoc., 22, 3, 671–681, 2015.
6. Venkatesan, A. and Parthiban, L., Medical Image Segmentation With Fuzzy C-Means and Kernelized Fuzzy C-Means Hybridized on PSO and QPSO. Int. Arab J. Inf. Technol. (IAJIT), 14, 1, 53–59, 2017.
7. Deborah, J.J. and Parthiban, L., Performance Evaluation of classification algorithms on Lymph disease prediction. 2018 International Conference on Smart Systems and Inventive Technology.
8. George, G. and Parthiban, L., Multi objective hybridized firefly algorithm with group search optimization for data clustering. 2015 IEEE International Conference on Research in Computational Intelligence.
9. Vaithinathan, K. and Parthiban, L., A novel texture extraction technique with T1 weighted MRI for the classification of Alzheimer’s disease. J. Neurosci. Methods, 318, 84–99, 2019.
10. Latchoumi, T.P. and Parthiban, L., Abnormality detection using weighed particle swarm optimization and smooth support vector machine. Biomed. Res., 28, 11, 4749–4751, 2017.
11. Thomas, S.C., Parthiban, L., Sriramakrishnan, G.V., Investigation of drug induced adverse effects and Disproportionality Analysis of Acetaminophen and Ibuprofen. Int. J. Pure Appl. Math., 118, 7, 667–674, 2018.
12. Sriramakrishnan, G.V., Parthiban, L., Sankar, K., Thomas, S.C., Identifying the Safety Profile of Amiodarone and Dronedarone using Openvigil 2. Int. J. Pure Appl. Math., 118, 18, 2779–2784, 2018.
13. Sankar, K. and Parthiban, L., Effective ways of finding Adverse Drug Reactions in Pharmacovigilance. Int. J. Recent Technol. Eng. (IJRTE), 8, 2S4, 284–287, July 2019.
14. Balakrishnan, T.S. and Parthiban, L., Effective Pharmacovigilance using Natural Language Processing and Neural Network. Int. J. Pure Appl. Math., 119, 15, 1825–1831, 2018.
15. Al Alkeem, E., Shehada, D., Yeun, C.Y., Zemerly, M.J., Hu, J., New secure healthcare system using cloud of things. Clust. Comput., 20, 2211–2229, 1–19, 2017.
- *Corresponding author: [email protected]