


Core technologies
This chapter addresses N series core technologies such as the WAFL file system, disk structures, and NVRAM access methods.
This chapter includes the following sections:
11.1 Write Anywhere File Layout (WALF)
Write Anywhere File Layout (WAFL) is the N series file system. At the core of Data ONTAP is WAFL, N series proprietary software that manages the placement and protection of storage data. Integrated with WAFL is N series RAID technology, which includes both single and double parity disk protection. N series RAID is proprietary and fully integrated with the data management and placement layers, allowing efficient data placement and high-performance data paths.
WAFL has these core features:
•WAFL is highly data aware, and enables the storage system to determine the most efficient data placement on disk, as shown in Figure 11-1.
•Data is intelligently written in batches to available free space in the aggregate without changing existing blocks.
•The aggregate can reclaim free blocks from one flexible volume (FlexVol volume) for allocation to another.
•Data objects can be accessed through NFS, CIFS, FC, FCoE, or iSCSI protocols.
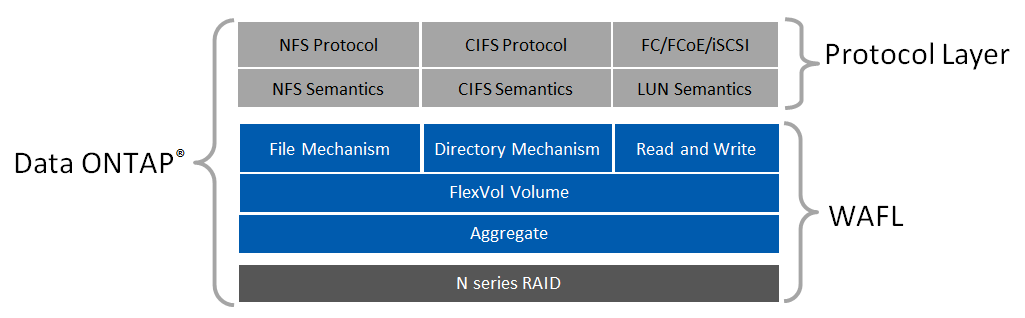
Figure 11-1 WAFL
WAFL also includes the necessary file and directory mechanisms to support file-based storage, and the read and write mechanisms to support block storage or LUNs.
Notice that the protocol access layer is above the data placement layer of WAFL. This layer allows all of the data to be effectively managed on disk independently of how it is accessed by the host. This level of storage virtualization offers significant advantages over other architectures that have tight association between the network protocol and data.
To improve performance, WAFL attempts to avoid the disk head writing data and then moving to a special portion of the disk to update the inodes. The inodes contain the metadata. This movement across the physical disk medium increases the write time. Head seeks happen quickly, but on server-class systems you have thousands of disk accesses going on per second. This additional time adds up quickly, and greatly affects the performance of the system, particularly on write operations. WAFL does not have that handicap, and writes the metadata in line with the rest of the data. Write anywhere refers to the file system’s capability to write any class of data at any location on the disk.
The basic goal of WAFL is to write to the first best available location. “First” is the closest available block. “Best” is the same address block on all disks, that is, a complete stripe. The first best available is always going to be a complete stripe across an entire RAID group that uses the least amount of head movement to access. That is arguably the most important criterion for choosing where WAFL is going to locate data on a disk.
Data ONTAP has control over where everything goes on the disks, so it can decide on the optimal location for data and metadata. This fact has significant ramifications for the way Data ONTAP does everything, but particularly in the operation of RAID and the operation of Snapshot technology.
11.2 Disk structure
Closely integrated with N series RAID is the aggregate, which forms a storage pool by concatenating RAID groups. The aggregate controls data placement and space management activities.
The FlexVol volume is logically assigned to an aggregate, but is not statically mapped to it. This dynamic mapping relationship between the aggregate layer and the FlexVol layer is integral to the innovative storage features of Data ONTAP.
An abstract layout is shown in Figure 11-2.

Figure 11-2 Dynamic disk structure
To write new data into a RAID stripe that already contains data (and parity), you must read the parity block. You then calculate a new parity value for the stripe, and write the data block plus the new parity block. This process adds a significant amount of extra work for each block to be written.
The N series reduces this penalty by buffering NVRAM-protected writes in memory, and then writing full RAID stripes plus parity whenever possible. This process makes reading parity data before writing unnecessary, and requires only a single parity calculation for a full stripe of data blocks. WAFL does not overwrite existing blocks when they are modified, and it can write data and metadata to any location. In other data layouts, modified data blocks are usually overwritten, and metadata is often required to be at fixed locations.
This approach offers much better write performance, even for double-parity RAID (RAID 6). Unlike other RAID 6 implementations, RAID-DP performs so well that it is the default option for N series storage systems. Tests show that random write performance declines only 2% versus the N series RAID 4 implementation. By comparison, another major storage vendor’s RAID 6 random write performance decreases by 33% relative to RAID 5 on the same system. RAID 4 and RAID 5 are both single-parity RAID implementations. RAID 4 uses a designated parity disk. RAID 5 distributes parity information across all disks in a RAID group.
11.3 NVRAM and system memory
Caching technologies provide a way to decouple storage performance from the number of disks in the underlying disk array to substantially improve cost. The N series platform has been a pioneer in the development of innovative read and write caching technologies. The N series storage systems use NVRAM to journal incoming write requests. This configuration allows it to commit write requests to nonvolatile memory and respond back to writing hosts without delay. Caching writes early in the stack allows the N series to optimize writes to disk, even when writing to double-parity RAID. Most other storage vendors cache writes at the device driver level.
The N series uses a multilevel approach to read caching. The first-level read cache is provided by the system buffer cache. Special algorithms decide which data to retain in memory and which data to prefetch to optimize this function. The N series Flash Cache provides an optional second-level cache. It accepts blocks as they are ejected from the buffer cache to create a large, low-latency block pool to satisfy read requests. Flash Cache can reduce your storage costs by 50% or more. It does so by reducing the number of spindles needed for a specific level of performance. Therefore, it allows you to replace high-performance disks with more economical options.
Both buffer cache and Flash Cache benefit from a cache amplification effect that occurs when N series deduplication or FlexClone technologies are used. Behavior can be further tuned and priorities can be set by using N series FlexShare to create different classes of service.
Traditionally, storage performance has been closely tied to spindle count. The primary means of boosting storage performance was to add more or higher performance disks. However, the intelligent use of caching can dramatically improve storage performance for a wide variety of applications.
From the beginning, the N series platform has pioneered innovative approaches to both read and write caching. These approaches allow you to do more with less hardware and at less cost. N series caching technologies can help you in these ways:
•Increases I/O throughput while decreasing I/O latency (the time needed to satisfy an I/O request)
•Decreases storage capital and operating costs for a specific level of performance
•Eliminates much of the manual performance tuning that is necessary in traditional storage environments
11.4 Intelligent caching of write requests
Caching writes have been used as a means of accelerating write performance since the earliest days of storage. The N series uses a highly optimized approach to write caching that integrates closely with the Data ONTAP operating environment. This approach eliminates the need for the huge and expensive write caches seen on some storage arrays. It enables the N series to achieve exceptional write performance, even with RAID 6 (double-parity RAID).
11.4.1 Journaling write requests
When any storage system receives a write request, it must commit the data to permanent storage before the request can be confirmed to the writer. Otherwise, if the storage system experiences a failure while the data is only in volatile memory, that data would be lost. This data loss can cause the underlying file structures to become corrupted.
Storage system vendors commonly use battery-backed, nonvolatile RAM (NVRAM) to cache writes and accelerate write performance while providing permanence. This process is used because writing to memory is much faster than writing to disk. The N series provides NVRAM in all of its current storage systems. However, the Data ONTAP operating environment uses NVRAM in a much different manner than typical storage arrays.
Every few seconds, Data ONTAP creates a special Snapshot copy called a consistency point, which is a consistent image of the on-disk file system. A consistency point remains unchanged even as new blocks are being written to disk because Data ONTAP does not overwrite existing disk blocks. The NVRAM is used as a journal of the write requests that Data ONTAP has received since creation of the last consistency point. With this approach, if a failure occurs, Data ONTAP reverts to the latest consistency point. It then replays the journal of write requests from NVRAM to bring the system up to date and make sure the data and metadata on disk are current.
This is a much different use of NVRAM than that of traditional storage arrays, which cache writes requests at the disk driver layer. This use offers several advantages:
•Requires less NVRAM. Processing a write request and caching the resulting disk writes generally take much more space in NVRAM than journaling the information required to replay the request. Consider a simple 8 KB NFS write request. Caching the disk blocks that must be written to satisfy the request requires the following memory:
– 8 KB for the data
– 8 KB for the inode
– For large files, another 8 KB for the indirect block
Data ONTAP merely has to log the 8 KB of data along with about 120 bytes of header information. Therefore, it uses half or a third as much space.
It is common for other vendors to point out that N series storage systems often have far less NVRAM than competing models. This is because N series storage systems actually need less NVRAM to do the same job because of their unique use of NVRAM.
•Decreases the criticality of NVRAM. When NVRAM is used as a cache of unwritten disk blocks, it becomes part of the disk subsystem. A failure can cause significant data corruption. If something goes wrong with the NVRAM in an N series storage system, a few write requests might be lost. However, the on-disk image of the file system remains completely self-consistent.
•Improves response times. Both block-oriented SAN protocols (Fibre Channel protocol, iSCSI, FCoE) and file-oriented NAS storage protocols (CIFS, NFS) require an acknowledgement from the storage system that a write has been completed. To reply to a write request, a storage system without any NVRAM must run these steps:
a. Update its in-memory data structures
b. Allocate disk space for new data
c. Wait for all modified data to reach disk
A storage system with an NVRAM write cache runs the same steps, but copies modified data into NVRAM instead of waiting for disk writes. Data ONTAP can reply to a write request much more quickly because it need update only its in-memory data structures and log the request. It does not have to allocate disk space for new data or copy modified data and metadata to NVRAM.
•Optimizes disk writes. Journaling all write data immediately and acknowledging the client or host not only improve response times, but also gives Data ONTAP more time to schedule and optimize disk writes. Storage systems that cache writes in the disk driver layer must accelerate processing in all the intervening layers to provide a quick response to host or client. This requirement gives them less time to optimize.
For more information about how Data ONTAP benefits from NVRAM, see the following document:
11.4.2 NVRAM operation
No matter how large a write cache is or how it is used, eventually data must be written to disk. Data ONTAP divides its NVRAM into two separate buffers. When one buffer is full, that triggers disk write activity to flush all the cached writes to disk and create a consistency point. Meanwhile, the second buffer continues to collect incoming writes until it is full, and then the process reverts to the first buffer. This approach to caching writes in combination with WAFL is closely integrated with N series RAID 4 and RAID-DP. It allows the N series to schedule writes such that disk write performance is optimized for the underlying RAID array. The combination of N series NVRAM and WAFL in effect turns a set of random writes into sequential writes.
The controller contains a special chunk of RAM called NVRAM. It is nonvolatile because it has a battery. Therefore, if a sudden disaster that interrupts the power supply strikes the system, the data stored in NVRAM is not lost.
After data gets to an N series storage system, it is treated in the same way whether it came through a SAN or NAS connection. As I/O requests come into the system, they first go to RAM. The RAM on an N series system is used as in any other system: It is where Data ONTAP does active processing. As the write requests come in, the operating system also logs them in to NVRAM.
NVRAM is logically divided into two halves so that as one half is emptying out, the incoming requests fill up the other half. As soon as WAFL fills up one half of NVRAM, WAFL forces a consistency point, or CP, to happen. It then writes the contents of that half of NVRAM to the storage media. A fully loaded system does back-to-back CPs, so it is filling and refilling both halves of the NVRAM.
Upon receipt from the host, WAFL logs writes in NVRAM and immediately sends an ACK (acknowledgment) back to the host. At that point from the host’s perspective, the data has been written to storage. But in fact, the data might be temporarily held in NVRAM. The goal of WAFL is to write data in full stripes across the storage media. To write the data, it holds write requests in NVRAM while it chooses the best location for the data. It then does RAID calculations, parity calculations, and gathers enough data to write a full stripe across the entire RAID group. A sample client request is displayed in Figure 11-3.

Figure 11-3 High performance NVRAM virtualization
WAFL never holds data longer than 10 seconds before it establishes a CP. At least every 10 seconds, WAFL takes the contents of NVRAM and commits it to disk. As soon as a write request is committed to a block on disk, WAFL clears it from the journal. On a system that is lightly loaded, an administrator can actually see the 10 second CPs happen: Every 10 seconds the lights cascade across the system. Most systems run with a heavier load than that, and CPs happen at smaller intervals depending on the system load.
NVRAM does not cause a performance bottleneck. The response time of RAM and NVRAM is measured in microseconds. Disk response times are always in milliseconds and it takes a few milliseconds for a disk to respond to an I/O. Disks therefore are always the performance bottleneck of any storage system. They are the bottleneck because disks are radically slower than any other component on the system. When a system starts committing back-to-back CPs, the disks are taking writes as fast as they possibly can. That is a platform limit for that system. To improve performance when the platform limit is reached, you can spread the traffic across more heads or upgrade the head to a system with greater capacity. NVRAM can function faster if the disks can keep up.
For more information about technical details of N series RAID-DP, see this document:
11.5 N series read caching techniques
The random read performance of a storage system is dependent on both drive count (total number of drives in the storage system) and drive rotational speed. Unfortunately, adding more drives to boost storage performance also means using more power, more cooling, and more space. With single disk capacity growing much more quickly than performance, many applications require additional disk spindles to achieve optimum performance even when the additional capacity is not needed.
11.5.1 Introduction of read caching
Read caching is the process of deciding which data to either keep or prefetch into storage system memory to satisfy read requests more rapidly. The N series uses a multilevel approach to read caching to break the link between random read performance and spindle count. This configuration provides you with multiple options to deliver low read latency and high read throughput while minimizing the number of disk spindles you need:
•Read caching in system memory (the system buffer cache) provides the first-level read cache, and is used in all current N series storage systems.
•Flash Cache (PAM II) provides an optional second-level read cache to supplement system memory.
•FlexCache creates a separate caching tier within your storage infrastructure to satisfy read throughput requirements in the most data-intensive environments.
The system buffer cache and Flash Cache increase read performance within a storage system. FlexCache scales read performance beyond the boundaries of any single system’s performance capabilities.
N series deduplication and other storage efficiency technologies eliminate duplicate blocks from disk storage. These functions make sure that valuable cache space is not wasted storing multiple copies of the same data blocks. Both the system buffer cache and Flash Cache benefit from this “cache amplification” effect. The percentage of cache hits increases and average latency improves as more shared blocks are cached. N series FlexShare software can also be used to prioritize some workloads over others and modify caching behavior to meet specific objectives.
11.5.2 Read caching in system memory
There are two distinct aspects to read caching:
•Keeping “valuable” data in system memory
•Prefetching data into system memory before it is requested
Deciding which data to keep in system memory
The simplest means of accelerating read performance is to cache data in system memory after it arrives there. If another request for the same data is received, that request can then be satisfied from memory rather than having to reread it from disk. However, for each block in the system buffer cache, Data ONTAP must determine the potential “value” of the block. The questions that must be addressed for each data block include:
•Is the data likely to be reused?
•How long should the data stay in memory?
•Will the data change before it can be reused?
Answers to these questions can be determined in large part based on the type of data and how it got into memory in the first place.
•Write data: Write workloads tend not to be read back after writing. They are often already cached locally on the system that ran the write. Therefore, they are generally not good candidates for caching. In addition, recently written data is normally not a high priority for retention in the system buffer cache. The overall write workload can be high enough that writes overflow the cache and cause other, more valuable data to be ejected. However, some read-modify-write type workloads benefit from caching recent writes. Examples include stock market simulations and some engineering applications.
•Sequential reads: Sequential reads can often be satisfied by reading a large amount of contiguous data from disk at one time. In addition, as with writes, caching large sequential reads can cause more valuable data to be ejected from system cache. Therefore, it is preferable to read such data from disk and preserve available read cache for data that is more likely to be read again. The N series provides algorithms to recognize sequential read activity and read data ahead, making it unnecessary to retain this type of data in cache with a high priority.
•Metadata: Metadata describes where and how data is stored on disk (name, size, block locations, and so on). Because metadata is needed to access user data, it is normally cached with high priority to avoid the need to read metadata from disk before every read and write.
•Small, random reads: Small, random reads are the most expensive disk operation because they require a higher number of head seeks per kilobyte than sequential reads. Head seeks are a major source of the read latency associated with reading from disk. Therefore, data that is randomly read is a high priority for caching in system memory.
The default caching behavior for the Data ONTAP buffer cache is to prioritize small, random reads and metadata over writes and sequential reads.
Deciding which data to prefetch into system memory
The N series read ahead algorithms are designed to anticipate what data will be requested and read it into memory before the read request arrives. Because of the importance of effective read ahead algorithms, IBM has done a significant amount of research in this area. Data ONTAP uses an adaptive read history logging system based on “read sets”, which provides much better performance than traditional and fixed read-ahead schemes.
In fact, multiple read sets can support caching for individual files or LUNs, which means that multiple read streams can be prefetched simultaneously. The number of read sets per file or LUN object is related to the frequency of access and the size of the object.
The system adaptively selects an optimized read-ahead size for each read stream based on these historical factors:
•The number of read requests processed in the read stream
•The amount of host-requested data in the read stream
•A read access style associated with the read stream
•Forward and backward reading
•Identifying coalesced and fuzzy sequences of arbitrary read access patterns
Cache management is significantly improved by these algorithms, which determine when to run read-ahead operations and how long each read stream's data is retained in cache.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.