


Introduction and overview of IBM PowerAI
This chapter provides introductory information about IBM PowerAI.
This chapter contains the following topics:
2.1 What is IBM PowerAI
IBM PowerAI is a package of software distributions for many of the major deep learning (DL) software frameworks for model training, such as TensorFlow, Caffe, Chainer, Torch, and Theano, and their associated libraries, such as CUDA Deep Neural Network (cuDNN), and nvCaffe. They are extensions that take advantage of accelerators, for example, nvCaffe is NVIDIA extension to Caffe so that it can work on graphical processing units (GPU). As with nvCaffe, IBM has an own extension to Caffe, which is called IBM Caffe. Furthermore, the IBM PowerAI solution is optimized for performance by using the NVLink-based IBM POWER8® server, the IBM Power S822LC for High Performance Computing server, and its successor, the IBM Power System AC922 for High Performance Computing server. The stack also comes with supporting libraries, such as Deep Learning GPU Training System (DIGITS), OpenBLAS, Bazel, and NVIDIA Collective Communications Library (NCCL).
2.1.1 Contents of IBM PowerAI (IBM PowerAI Release 4)
The IBM PowerAI package is released with all of the upgraded versions of each framework and libraries. However, under special circumstances, such as with an increase in demand, targets for the next release vary. Table 2-1 shows the IBM PowerAI software stack.
Table 2-1 IBM PowerAI software stack
|
IBM PowerAI software stack (basic)
|
||
|
Deep learning frameworks
|
||
|
Core
|
TensorFlow
|
IBM Caffe
|
|
Other frameworks
|
BLVC Caffe
|
nvCaffe
|
|
|
Chainer
|
Torch
|
|
Theano
|
N/A
|
|
|
Libraries and other components
|
||
|
Major components
|
DIGITS
|
NCCL
|
|
OpenBLAS
|
Bazel
|
|
|
Distributed DL
|
IBM Distributed Deep Learning (DDL) Library for IBM Caffe
|
|
|
TensorFlow Operator for IBM DDL Library
|
||
2.1.2 Minimum hardware requirement for IBM PowerAI
IBM PowerAI can be run on POWER8 and IBM POWER9™ servers. However, to run the DL platform, IBM recommends the following configuration in those servers:
•Two POWER8 CPUs
•128 GB of memory
•NVIDIA Tesla P100 or V100 with NVLink GPUs
•NVIDIA NVLink interface to Tesla GPUs
You can download at no cost the current version of IBM PowerAI from Index of /software/server/POWER/Linux/mldl/ubuntun.
|
Note: The instruction guide for IBM PowerAI can be found in the readme file.
|
Additionally, if you want to download specific versions of frameworks from previous releases, you can download them from Index of software/server/POWER/Linux/mldl/ubuntu/archive. This website provides a readme file and direct download links for the following releases:
•Release 3.0
•Release 3.1
•Release 3.2
•Release 3.3
•Release 3.4
•Release 4.0
|
Tip: You can confirm the contents of each release to specify the versions of the frameworks within each release package in 3.2, “IBM PowerAI compatibility matrix” on page 58.
|
2.2 Why IBM PowerAI simplifies adoption of deep learning
Today, organizations are using DL to develop powerful new analytic capabilities spanning multiple usage patterns, from computer vision and object detection, to improved human computer interaction through natural language processing (NLP), to sophisticated anomaly detection capabilities. At the heart of any use case that is associated with DL are sophisticated pattern recognition and classification capabilities that serve as the birthplace for revolutionary applications and insights of the future. However, in situations where organizations try to expand their area for DL or to start working on the development of DL, there are enormous difficulties, especially the performance issues that are caused by hardware limitations, and time-consuming process in each framework regarding setup, tuning, upgrades, and others.
In the fourth quarter of 2016, IBM announced a significant revamp of IBM PowerAI, seeking to address some of the bigger challenges facing developers and data scientists. The goals were to cut down the time that is required for artificial intelligence (AI) system training, making and running a snap with an enterprise-ready software distribution for DL and AI, and simplifying the development experience. The idea behind IBM PowerAI is to embrace and extend the open source community, embrace and extend the capability and creativity that is happening there, and add IBM unique capabilities. This situation manifests itself in a number of value differentiators for AI applications that IBM Power Systems brings to the table.
IBM PowerAI provides the following benefits:
•Fast time to deploy a DL environment so that clients can get to work immediately:
– Simplified installation in usually less than 1 hour
– Precompiled DL libraries, including all required files
•Optimized performance so users can capture value sooner:
– Built for IBM Power Systems servers with NVLink CPUs and NVIDIA GPUs, delivering performance unattainable elsewhere
– Distributed DL, taking advantage of parallel processing
•Designed for enterprise deployments:
– Multitenancy supporting multiple users and lines of business (LOBs)
– Centralized management and monitoring by integrations with other software
•IBM service and support for the entire solution, including the open source DL frameworks
2.3 IBM unique capabilities
This section highlights the unique capabilities of IBM products and solutions that you can take advantage with IBM PowerAI, which includes the following items:
•NVLink and NVLink 2.0
•Distributed Deep Learning (DDL)
•Large Model Support (LMS)
2.3.1 NVLink and NVLink 2.0
Announced in 2014, NVLink is the NVIDIA proprietary high-speed, low-latency physical interconnect. NVLink improves on the traditional communication bottleneck between multiple GPUs, enabling efficient and performance communication between GPUs and system memory. Additionally, NVLink provides more performant and efficient communication between system CPUs and GPUs.
The initial generation of NVLink was implemented with the NVIDIA GPU based on their Pascal-microarchitecture. It provides higher bandwidth than the third generation of the industry-standard Peripheral Component Interconnect Express (PCIe) interface. NVLink was first made commercially available in September 2016 with the launch of the IBM Power System S822LC for High Performance Computing server. This model is available in configurations with either 2 or 4 NVIDIA Tesla P100 GPUs.
The implementation of NVLink in this IBM POWER8 system provides a bidirectional path between GPUs of up to 180 GBps and a bidirectional path between the GPUs and CPUs of up to 80 GBps.
In systems that are configured with more than one GPU, the benefits that are provided by NVLink increase and scale. Each extra GPU adds a separate interconnect between itself and neighboring GPUs and between itself and the nearest CPU.
In 2017, NVIDIA announced the second generation of NVLink with the introduction of its Volta-microarchitecture. It provides improved data rates of up to 300 GBps. The POWER9 processor-based IBM Power System AC922 for High Performance Computing server launched in December 2017 with the second generation of NVLink, supporting configurations of up to six NVIDIA GPUs.
|
Note: For more information about the implementation and architecture of NVLink, including performance metrics, see the NVDIA NVLink website.
|
2.3.2 Power AI Distributed Deep Learning
IBM PowerAI DDL is a software/hardware co-optimized distributed DL system that can achieve near-linear scaling up to 256 GPUs. This algorithm is encapsulated as a communication library that is called DDL that provides communication APIs for implementing DL communication patterns across multiple DL frameworks.
The inherent challenge with distributed DL systems is that as the number of learners increases, the amount of computation decreases at the same time the amount of communication remains constant. This intuitively results in unwanted communication ratios.
To mitigate the impact of this scaling problem, IBM PowerAI DDL uses an innovative multi-ring communication algorithm that balances the communication latency and communication impact. This algorithm adapts to the hierarchy of communication bandwidths, including intranode, internode, and interrack, within any system. This implementation allows for adaptation, which enables IBM PowerAI DDL to deliver to the optimal distributed DL solution for an environment.
The current implementation of IBM PowerAI DDL is based on IBM Spectrum MPI because IBM Spectrum MPI provides many of the required functions, such as scheduling processes and communication primitives in a portable, efficient, and mature software infrastructure. IBM Spectrum MPI specifically provides functions and optimizations to IBM Power Systems and InfiniBand network technology.
IBM PowerAI DDL objects() are the foundation of IBM PowerAI DDL. Each object() instance combines both the data and relevant metadata. The data structure component itself can contain various payloads, such as a tensor of gradients. The metadata provides a definition of the host, type of device (GPU along others), device identifier, and the type of memory where the data structure is. All of the functions within IBM PowerAI DDL operate on these objects, which are in effect synonymous with variables.
In a 256 GPU environment, about 90 GB of data must be transmitted to perform a simple reduction operation, and the same amount of data must be transmitted to copy the result to all the GPUs. Even a fast network connection with a 10 GBps transfer rate bringing this data to a single Parameter Server (PS) can take 9 seconds. IBM PowerAI DDL performs the entire reduction and distribution of 350 MB in less than 100 ms by using a communication scheme that is optimized for the specific network topology.
A key differentiator for IBM PowerAI DDL is its ability to optimize the communication scheme based on the bandwidth of each available link, topology, and latency for each segment. In a heterogeneous environment, with multiple link speeds, IBM PowerAI DDL adjusts its dimensions to use the fastest available link, thus preventing the slowest link from dominating the run time.
Using IBM PowerAI DDL on cluster of 64 IBM S822LC for High Performance Computing servers, we demonstrated a validation accuracy of 33.8% for Resnet-101 on Imagenet 22k in ~7 hours (Figure 2-1). For comparison, Microsoft ADAM1 and Google DistBelief2 were not able to reach 30% validation accuracy for this data set.

Figure 2-1 Resnet-101 for 22k classes using up to 256 GPUs
2.3.3 Large Model Support
When defining and training large neural networks that are prevalent in the DL space for tasks such as high definition image recognition, large batch size tasks, and highly deep neural networks, the amount of GPU memory that is available can be a significant limitation. To overcome this challenge in IBM PowerAI V1.4, IBM provides LMS, which uses main system memory with the GPU memory to train these large-scale neural networks.
LMS enables you to process and train larger models that do not fit within the GPU memory space that is available currently. LMS uses the GPU memory and a fast interconnect (NVLink) to accommodate such large models and fetch only the working set in each instance to ensure the fastest computation possible while operating with a larger batch size outside the GPU memory address space.
To accommodate such models that occupy both system and GPU memory, LMS performs many CPU to GPU copy operations. There is regular transfer of data from system to GPU memory during the training phase. To perform this operation without inducing delays that impact computation time, the system requires a high-bandwidth interconnect between the CPU and the GPU. On IBM Power Systems servers, LMS can take advantage of the higher bandwidth interconnect that is provided by NVLink, which is described in 2.3.1, “NVLink and NVLink 2.0” on page 24.
Figure 2-2 shows the connections between the layers of a deep neural network and demonstrates the challenge and inherent complexity that is derived when trying to train a system at this scale, which LMS seeks to alleviate.

Figure 2-2 Neural networks diagram
To use LMS within IBM Caffe, add the following flag during the run time:
-lms <size in KB>
This flag sets the threshold size for determining which memory allocations must happen on the CPU memory, and which must be on the GPU memory. For example:
-lms 1028
When you use this parameter, any memory chunk larger than 1028 KB is processed on the main system memory address space by the CPU, and only fetched to GPU memory when required for computation. So, smaller values result in a more aggressive use of LMS and a greater amount of main system memory is used. However, large values, such as 100,000,000, essentially disable the LMS feature and ensure that all chunks are allocated to GPU memory.
This parameter can be used to control the performance tradeoff because more data being brought in from the CPU during the run time results in a runtime impact.
An alternative way to use LMS within your environment is by using the lms_frac flag:
-lms_frac <x> [0 < x < 1.0]
In this instance, LMS does not use system memory for allocating chunks of data until a certain threshold of GPU memory is allocated. For example:
-lms_frac 0.75
Until more than 75% of the GPU memory that is available is allocated, the system continues to assign chunks of any size to the GPU. The advantage to this method is that you can essentially disable the LMS function for faster training of smaller networks, or have more efficient utilization of GPU memory for larger networks.
2.4 Extra integrations that are available for IBM PowerAI
This section highlights the availability of extra integrations with other IBM products, which gives you more benefits for using IBM PowerAI. This section includes the following products:
•IBM Data Science Experience (IBM DSX)
•IBM PowerAI Vision (technology preview)
•Spectrum Conductor Deep Learning Impact (DLI)
2.4.1 IBM Data Science Experience
IBM DSX is a infrastructure of open source-based frameworks, libraries, and tools for scientists to develop algorithms and validate, deploy, and collaborate with communities of scientists and developers. IBM DSX enables data scientists to develop algorithms in their most preferred language, integrated developer environment (IDE), and libraries.
In September 2017, IBM announced that IBM DSX can be used on IBM Power Systems servers, which enables data scientists to take advantage of IBM PowerAI to deliver performance advantages for DL workloads, as shown in Figure 2-3 on page 29. IBM PowerAI is also integrated with Jupyter notebook, which supports R, Python, and Scala Spark APIs, and no separate installation or configuration is required to use libraries in IBM PowerAI.

Figure 2-3 IBM Data Science Experience on Power Systems layers
Even though IBM DSX is a software product that can be integrated with IBM PowerAI, the installation method is different from the other two software products that are introduced in this section. In fact, IBM DSX is a package software that contains IBM PowerAI. Therefore, after IBM DSX is installed in the environment, IBM PowerAI is also already in the system and ready to use.
System requirements
There are two default installation options that an IBM DSX local customer can choose to install: a three-server cluster or a nine-server cluster. The two common requirements regardless of the number of servers are the following ones:
•IBM DSX local requires dedicated servers (virtual machines (VMs) or baremetal).
•IBM DSX local runs on RHEL7.3.3
Three-node cluster hardware recommendations
Each server runs control, storage, and compute operations. A minimum of three servers is required, each with a minimum of 32 cores, 64 GB memory, and 500 GB of attached storage, plus an extra 2 TB of auxiliary storage.
Nine-node cluster hardware recommendations
Here are the hardware recommendations for the nine node cluster:
•A minimum of three servers are required to run control operations.
•Each must have a minimum of 8 cores, 16 GB memory, and 500 GB of attached storage.
•A minimum of three servers are required to run storage operations.
•Each must have a minimum of 16 cores, 32 GB memory, and 500 GB of attached storage.
•A minimum of three servers are required to run compute operations.
•Each must have a minimum of 32 cores, 64 GB memory, and 500 GB of attached storage.
The three- and nine-node cluster installations are starting points. After they are installed, you can add and move nodes as required.
Installation details are documented at Install Data Science Experience Local.
2.4.2 IBM PowerAI Vision (technology preview)
IBM PowerAI Vision provides a complete platform for image analytics to create data sets, label them, train a model, and validate and deploy them. The tool makes the journey from raw data to a deployed model faster, and does not impose a need for data scientists. IBM PowerAI Vision realizes rapid data labeling from images, creating labeled data sets from videos, and semi-auto labeling of video streams for enhancing data sets that are required for training, as shown in Figure 2-4.
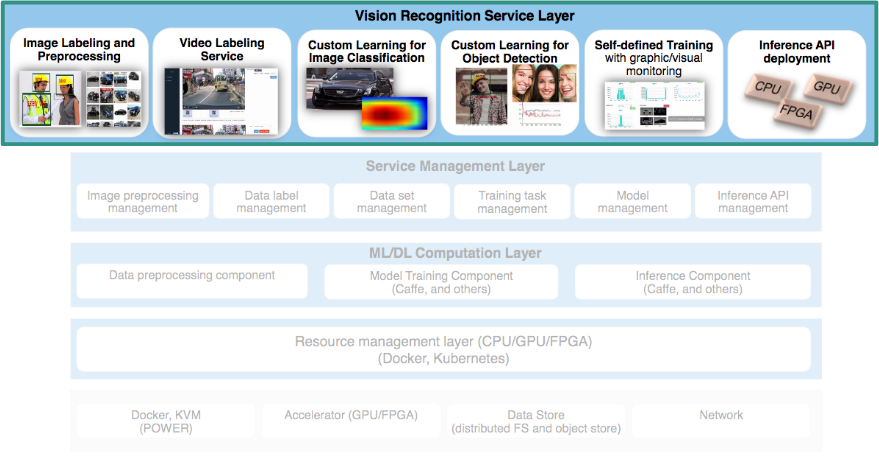
Figure 2-4 IBM PowerAI Vision layer
Hardware prerequisites
Here are the minimum hardware prerequisites for IBM PowerAI Vision:
•CPU: POWER8 or OpenPOWER infrastructure with a minimum of eight hardware cores
•Memory: 128 GB or larger
•GPU:
– At least one NVIDIA Tesla GPU
– GPU memory of one GPU core greater than 4 GB
•Disk: Greater than 20 GB available disk space
•Network: At least one Ethernet interface
Software prerequisites
Here are the software prerequisites for IBM PowerAI Vision:
•Operating system:
– Ubuntu 16.04 LTS for IBM PowerAI V1.4
– Red Hat Enterprise Linux 7.4 for V1.5 (architecture ppc64le)
•Docker.io 1.12.0 or newer.
•NVIDIA driver version 384.59 or higher is required.
•NVIDIA CUDA version 8.0.44 or higher is required.
•NVIDIA cuDNN 6.0 or higher is required.
For more information about IBM PowerAI Vision, see Deep Learning and PowerAI Development.
2.4.3 IBM Spectrum Conductor Deep Learning Impact
IBM Spectrum Conductor™ DLI is an add-on to IBM Spectrum Conductor with Spark that provides DL capabilities. DLI supports both IBM Power Systems servers and x86 servers.
Figure 2-5 shows the relationship between DLI and IBM PowerAI on IBM Power Systems servers.

Figure 2-5 Relationship between DLI and IBM PowerAI on the IBM Power platform
DLI provides a GUI to take advantage of frameworks of IBM PowerAI to perform DL activities, such as data set importing, model training, model validation, and tuning, and supports transforming a trained model to inference mode and providing service for customer to-do prediction. In addition, DLI uses IBM Spectrum Conductor with Spark to provide a multitenant solution and manage GPU resources flexibly in the DL cluster environment. DLI is an end-to-end DL lifecycle management product.
There are some environment requirements for DLI Version 1.1.0 to run in an IBM Power platform:
•IBM PowerAI V1.5
•IBM Conductor with Spark V2.2.1
•NVIDIA GPU device in the compute node
For more information about the hardware and software requirements for IBM Spectrum Conductor DLI V1.1.0, see IBM Knowledge Center.
Chapter 6, “Introduction to IBM Spectrum Conductor Deep Learning Impact” on page 143 provides more content about DLI, including DLI benefits, deployment, how to use it, and case scenarios.
1 Trishul Chilimbi, et al. “Project Adam: building an efficient and scalable Deep Learning training system”, OSDI’14 Proceedings of the 11th USENIX conference on Operating Systems Design and Implementation.
2 Dean, et al. “Large-Scale Distributed Deep Networks. Advances in Neural Information Processing Systems (NIPS)”, Neural Information Processing Systems Foundation, Inc., 2012.
3 As of December 2017
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.