


Performance
This chapter describes the DB2 12 enhancements that provide many types of improvements in reducing elapsed and CPU time. These added values improve processing and render better use of resources. An important aspect to mention is that this chapter discusses the results of IBM early observations and feedback from the Early Support Program (ESP).
This chapter covers the following topics:
13.1 Performance expectations
This topic describes the performance expectations based in the measurement evaluations for the DB2 12 performance enhancements.
Online transaction processing (OLTP) achieved a CPU utilization reduction without an index memory feature and also by exploiting an index in-memory feature. Further reduction is possible with contiguous buffer pools, the RELEASE(DEALLOCATE) bind option, or both.
The insert improvements for non-clustered data achieved CPU reduction with throughput improvement if the current bottleneck is from space, search, or page contentions.
Query performance has a wide range of improvement, achieving CPU reduction for query workloads and improving efficiency by reducing other resource consumption.
13.2 In-memory buffer pool
Up to DB2 11, when the buffer pool was not large enough to contain the object, page-stealing might have occurred, so pages that did not fit within the size of the buffer pool were managed by the first-in, first-out (FIFO) algorithm.
In DB2 12, the updated PGSTEAL(NONE) option of the ALTER BUFFERPOOL command (which makes possible the assigning of objects to in-memory buffer pools, in which the overflow area size is automatically determined by DB2), generally 10% of the VPSIZE value in the range of 50 - 6400 buffers and the creation of overflow happens at the time that the buffer pool is allocated. If the buffer pool is not large enough to support the objects, the pages that do not fit in the main part of the buffer pool are placed in the overflow area, where in page stealing occurs. Figure 13-1 shows a syntax diagram for the ALTER BUFFERPOOL command using the PGSTEAL(NONE) option.

Figure 13-1 Syntax diagram for ALTER BUFFERPOOL command using PGSSTEAL(NONE) option
This new feature gets direct row access, avoiding getpage overhead and providing CPU reduction measured for OLTP.
13.3 In-memory index optimization
DB2 12 introduces index Fast Traverse Block (FTB) with the Index Manager to optimize the memory structure for fast index lookups and improving random index access.
Up to DB2 11, Index Manager maintained transversal information in index lookaside, which keeps track of pages visited on the way to access the required index leaf page and then this information was kept from one access to the next. So, this method is good for sequential access of an index, but thinking about random access of the index, several getpages are required if the look aside does not get a parent of the leaf. Therefore, FTB is a complement for index lookaside.
The use of FTBs is supported only on UNIQUE, PADDED, and NOT PADDED indexes with a key size of 64 bytes or less. The best candidates for using FTB are indexes that support heavy read access, indexes on tables with a random insert or delete pattern, and indexes with high PCTFREE.
A new storage group (acomidxmgrcl20) is assigned to maintain the FTBs that are created. The storage group characteristics for FTB are as follows:
•Minimum of 10 MB
•Upper limit of 200 GB
•Default value of 20% of currently allocated buffer pool storage or 10 MB
In addition, FTB storage is not part of buffer pool allocation.
A daemon process monitors index usage and allocates FTB storage to the indexes that can benefit from this feature. FTB allocation is not permanent, so if the daemon determines that FTB storage is not being used, FTB storage can be removed.
Figure 13-2 exemplifies the usage of random keyed access.

Figure 13-2 Random keyed access usage
To accommodate the fast transverse feature, a catalog table (SYSIBM.SYSINDEXCONTROL) was created, SYSINDEXCONTROL, which specifies time windows to control the use of memory allocated for an index.
Table 13-1 demonstrates how the data is stored in SYSIBM.SYSINDEXCONTROL.
Table 13-1 SYSIBM.SYSINDEXCONTROL example
|
SSID
|
Partition
|
IX Name
|
IX Creator
|
TYPE
|
ACTION
|
MONTH_WEEK
|
MONTH
|
DAY
|
FROM_
TIME |
TO_
TIME |
|
DB2A
|
12
|
IXABC
|
DBDA
|
F
|
D
|
W
|
|
7
|
|
|
|
DB2B
|
|
IXZ12
|
DBDA
|
F
|
D
|
M
|
|
1
|
0000
|
1200
|
|
|
23
|
IXDEF
|
DBDA
|
F
|
F
|
M
|
|
|
|
|
Table 13-1 on page 233 shows the following information:
•On member DB2A, disable FTB on partition 12 of index IXABC every Sunday.
•On member DB2B, disable FTB on all partitions of index IXZ12 until noon on the first day of every month.
•On all members, force FTB on Partition 23 of index IXDEF at all times.
Figure 13-3 illustrates a syntax diagram to display for index memory usage.

Figure 13-3 Display syntax diagram for index memory usage
13.4 Improved insert performance for non-clustered data
DB2 12 introduces an insert algorithm that eliminates page contention and false leads. This algorithm is called fast insert, which brings the concept of multiple algorithms for insert. The fast insert algorithm is the default algorithm for MEMBER CLUSTER universal table spaces (UTS) because universal table spaces are strategic and MEMBER CLUSTER addresses cross member space map contention. Tables defined as APPEND and NON-APPEND can use fast insert too.
Fast insert is available on DB2 12 after activation of new function because new log records are introduced. For information about activating new function, see Chapter 2, “Continuous delivery” on page 7.
A new subsystem parameter (ZPARM) is provided to define system-wide default. It is used if a need exists to change the DB2 default insert algorithm level. DDL keywords are provided and can be used when a specific insert algorithm level is needed.
Figure 13-4 shows that DB2 achieved three times the response time improvement of CPU reduction using new DB2 12 insert algorithm.

Figure 13-4 Fast insert algorithm CPU reduction representation
The required external controls for fast insert algorithm enhancement are described next.
13.4.1 DDL clause on CREATE TABLESPACE and ALTER TABLESPACE
DB2 users are able to set the insert algorithm for inserts through a new optional clause, INSERT ALGORITHM, on the CREATE TABLESPACE and ALTER TABLESPACE statements.
Example 13-1 shows the INSERT ALGORITHM syntax diagram:
Example 13-1 INSERT ALGORITH syntax diagram
>>--CREATE TABLESPACE ------table-space-name ---...------>
.-INSERT ALGORITHM---0--------.
>---+-----------------------------+------...-------------><
'-INSERT ALGORITHM--level-----'
In the INSERT ALGORITHM level, an integer value is required and it is used only where applicable for MEMBER CLUSTER UTS. The level values are as follows:
0 Specifies that the insert algorithm level is determined by the DEFAULT_INSERT_ALGORITHM subsystem parameter at the time of an insert.
1 Specifies that the basic insert algorithm is used.
2 Specifies that the fast insert algorithm is used. Altering the insert algorithm for a table space occurs immediately.
13.4.2 SYSIBM.SYSTABLESPACE new column: INSERTALG
To accommodate the insert algorithm level (described in 13.4.1, “DDL clause on CREATE TABLESPACE and ALTER TABLESPACE” on page 235), the INSERTALG column is added to SYSIBM.SYSTABLESPACE catalog table.
The data type of this column is SMALLINT NOT NULL WITH DEFAULT and the corresponding values are as follows:
0 The insert algorithm level is determined by the DEFAULT_INSERT_ALGORITHM DSNZPARM.
1 The level is the basic insert algorithm.
2 The level is the fast insert algorithm.
13.4.3 ZPARM: DEFAULT_INSERT_ALGORITHM
The DEFAULT_INSERT_ALGORITHM subsystem parameter specifies the default algorithm for inserts into a table space. This ZPARM value affects only table spaces that are defined with a value of 0 (zero) as the insert algorithm level. The default is 2.
1 Specifies the basic insert algorithm is the default.
2 Specifies the fast insert algorithm is the default.
13.5 Query performance enhancements
DB2 12 provides query performances enhancements that result in CPU and elapsed-time savings. Figure 13-5 illustrates some query performance measurement results that are covered in this topic.

Figure 13-5 Query performance measurements results
The following topics explain and exemplify how these numbers were achieved:
13.5.1 UNION ALL and Outer Join enhancements
The query patterns UNION ALL and Outer Join have similar issues with materialization (workfile) usage and inability to apply filtering early.
DB2 12 introduces the following high-level solutions:
Reorder outer join tables to avoid materializations
Allowing DB2 to internally reorder the outer join tables within the query overcomes a limitation that can be exposed when combining outer and inner joins in the same query. In certain instances, DB2 11 and previous releases materialized some tables that can result in local or join filtering not being applied before the materialization. Some users who have been exposed to this performance challenge have rewritten their queries to ensure that all inner joins appear before outer joins in the query, if possible. Rewriting a query is often difficult given the proliferation of generated queries and applications being deployed without thorough performance evaluation. Therefore, minimizing exposure to this limitation in DB2 12 provides a valuable performance boost for affected queries.
UNION ALL and Outer Join predicate pushdown
When joining a table expression or an undistributed UNION ALL, DB2 considers whether to push the join predicate into the table expression or UNION ALL legs.
The decision was cost-based because the decision whether to push the join predicate into the view must be based on whether the query will run faster by pushing down the predicate, so if the cost of the query is estimated to be smaller when the join predicate is pushed down, then DB2 pushes down that join predicate.
In this way, choosing the best performing access is possible. It also improves archive transparency queries that internally transform a base table into a materialized table expression. For more information about archive transparency, see Managing Ever-Increasing Amounts of Data with IBM DB2 for z/OS: Using Temporal Data Management, Archive Transparency, and the DB2 Analytics Accelerator, SG24-8316.
Avoid workfile for outer materialization
DB2 12 can “pipeline” the rows from the first UNION ALL (on the left side of the join). Transferring rows from one query block to another can require the results to be written (materialized) to an intermediate work file. Pipeline means to pass the rows from one query block to the next, without writing the intermediate result to a work file.
The work file avoidance for outer materialization with correlation predicate has the objective of improving the performance.
Up to DB2 11, one work file was created to materialize the result of inner table expression for each outer row; also, each work file was only allocated and read once, then was deallocated. This method applied a reduction of allocation and deallocation overhead by reusing the same work file, and in addition it applied only when the workfile fits a 32K page and the inner guaranteed to return one row for each probe.
DB2 12 is able to change its execution time logic to call the UNION ALL processing directly to avoid work file usage. Using this new method, DB2 enables the leading table expression pipeline join to subsequent tables without materializing the leading table expression, saving the cost of work file allocation and deallocation.
The results for this enablement are as follows:
•For outer pipelining (for the outer table of a join):
– CPU time savings for the queries with access path change from ACCESSTYPE 'R' to 'O'
– Workfile get page counts reduced due to the avoidance of workfile materialization.
•For inner pipelining (for the inner table of the join):
– Internal DB2 workloads achieved CPU reduction in WF getpages
– CPU and elapsed reduction for best case
Push predicates inside UNION ALL legs or outer join query blocks
Figure 13-6 demonstrates performance challenges when UNION ALL is combined with an outer join. The original query is shown at the top of the figure as a simple two-table (left outer) join of T1 to T2. In this example, both T1 and T2 have archive enabled (which refers to the DB2 11 transparent archive feature), thus DB2 will rewrite the query to include the active and archive tables—with T1 circled and the arrow pointing to the first UNION ALL on the left side of the join, and T2 circled with arrow pointing to the second UNION ALL on the right side of the join. This representation is true of any UNION ALL within a view, where the view definition is replaced within the query where it is referenced.

Figure 13-6 DB2 11 left outer join query with transparent archive tables (or any UNION ALL views)
The performance challenge for this query example is that DB2 will execute each leg of the UNION ALL separately and combine the results from each side of the first UNION ALL, and then combine each side of the second UNION ALL, before joining the two results together as requested in the outer query block. In the V11 rewrite of the query, there are no join predicates or any filtering within the UNION ALL legs. The term combining means that DB2 will return all columns and all rows from T1 in the first UNION ALL and all columns and all rows from H1 and materialize those rows to a work file. The work file will then be sorted in preparation for the join. This is repeated for the second UNION ALL—all columns and all rows from T2 and H2 are materialized into a work file and sorted in preparation for the join on column C1 from both work files.
The performance of this query will depend heavily on the size of the tables involved, with very large tables consuming significant CPU and work file resources to complete.
In using the same example (from Figure 13-6), the next figure (Figure 13-7 on page 239) explain how several of the UNION ALL enhancements in DB2 12 can improve the performance of this query. While the internal rewrite of the tables to the UNION ALL representation remains the same, DB2 12 adds the ability for the optimizer to make a cost-based decision as to whether to push the join predicates into the UNION ALL legs.
Figure 13-7 demonstrates the example where the optimizer chose to push the join predicates inside each UNION ALL leg. The join predicates occur on only the right side of the join because a join is FROM the left TO the right. The TABLE keyword is required externally for this example to be syntactically valid because pushing down the predicates results in the query appearing as a correlated table expression.

Figure 13-7 DB2 12 left outer join query with transparent archive tables (or any UNION ALL views)
Having the join predicates in each UNION ALL leg allows the join to “look up” each leg of the UNION ALL for every row coming from the outer, rather than sort the full results for the join. An additional optimization, to reduce work file usage and materialization, DB2 12 can “pipeline” the rows from the first UNION ALL (on the left side of the join). Transferring rows from one query block to another can require the results to be written (materialized) to an intermediate work file as in the DB2 11 example. However, DB2 12 can “pipeline” the result from the first UNION ALL to the join without requiring this materialization.
The result for this query in DB2 12, given the (cost based) join predicate pushdown, is that the work file/materializations are avoided, and available indexes can be exploited for each leg, as shown in Figure 13-7.
Sort outer into table expression order
Figure 13-8 on page 240 demonstrates additional DB2 12 enhancements that can improve performance closer to queries that do not use the UNION ALL infrastructure. One option that the optimizer has for improving join performance between two tables sequentially is for the optimizer to introduce a sort of the outer (composite—denoted as SORTC_JOIN='Y' in the EXPLAIN). If data from the outer table is accessed in a different sequence than the index used for the join to the inner, DB2 can choose to sort the outer into the sequence of the inner—allowing the access to the inner to occur in order. This approach is extended in DB2 12 to joins to UNION ALL views/table expressions and is a cost-based choice for the optimizer.

Figure 13-8 DB2 12 left outer join UNION ALL query with sort of outer
Enable sparse index for inner table/view expression
Up to DB2 11, a supporting index was required for optimal performance and executed like a correlated subquery for table/view expression with or without UNION ALL coded with correlation predicates.
DB2 12 supports sparse index creation on the correlated table/view expression, so it avoids the worst case of executing a correlated subquery without a supporting index.
Figure 13-9 on page 241 demonstrates another variation of the same query where there are no supporting indexes for the join to T2.C1 or H2.C1. DB2 12 allows a sparse index to be built on an individual leg of a UNION ALL. This applies to one or both legs, and is also cost-based and thus can be combined with the other UNION ALL-focused enhancements.
|
Note: If sparse index is chosen, then no need exists to sort the outer into join order, as depicted in Figure 13-8, because a sparse index can use hashing if the result can be contained within memory and thus no concerns exist regarding random I/O.
|
Remember H1 is the archive table for T1, and H2 is the archive table for T2, as used in previous examples.

Figure 13-9 DB2 12 left outer join UNION ALL query without supporting join indexes
Pruning unused columns from materialized result
The select list pruning is extended, pruning unused columns from a materialized result when table expressions, views, and table functions are involved.
This extension offers the following benefits:
•Reduction of the size of the intermediate result with less work file consumption, smaller sort row, and so on.
•Enablement of more outer join, which means outer join tables that do not return columns for the result may be pruned.
Example 13-2 involves a LEFT OUTER JOIN to a UNION ALL table expression. In the select list for each leg of the UNION ALL is SELECT *, which means returning all columns from that table. However, the referencing SELECT only requires P2.P_PARTKEY (for the SELECT list and ON clause). Given the materialization of the UNION ALL table expression in DB2 11, all columns from PART table will be accessed and materialized to the work file. DB2 11 processes all columns in materialized view/table expression.
Example 13-2 DB2 11 processing all columns in materialized view/table expression
SELECT P.P_PARTKEY,P2.P_PARTKEY
FROM TPCH30.PART AS P LEFT JOIN
(SELECT *
FROM TPCH30.PART
UNION ALL
SELECT *
FROM TPCH30.PART) P2
ON P.P_PARTKEY = P2.P_PARTKEY;
DB2 12 will prune the unnecessary columns and only require P_PARTKEY to be returned from each UNION ALL leg, whereas DB2 11 returned all columns.
If the UNION ALL table expression is materialized, then only P_PARTKEY is retrieved and written or materialized to a work file compared with all columns retrieved in the DB2 11 example. And if P_PARTKEY is indexed, the optimizer might choose a non-matching index scan in DB2 12 rather than table space scan in DB2 11. Similarly, if the join predicates were pushed down in DB2 12 and matching index access was chosen on P_PARTKEY, then index-only would now be possible because only P_PARTKEY is required.
Example 13-3 refers to unreferenced columns with optional join pushdown being pruned by DB2 12.
Example 13-3 DB2 12 pruning unreferenced columns with optional join pushdown
SELECT P.P_PARTKEY,P2.P_PARTKEY
FROM TPCH30.PART AS P LEFT JOIN
(SELECT P_PARTKEY
FROM TPCH30.PART
UNION ALL
SELECT P_PARTKEY
FROM TPCH30.PART) P2
ON P.P_PARTKEY = P2.P_PARTKEY; <- Cost based pushdown available
to UA legs
It achieved the following performance result:
•CPU and elapsed reduction when no access path change.
•CPU reduction for access path change and when tables are pruned. If columns that are not needed are pruned by the query, the result might be that the query does not need any columns from a table. And if that table is on the right side of a LEFT OUTER JOIN, and the query will not return duplicates from that table, then the table can be pruned.
Extended LEFT JOIN table pruning
DB2 10 introduced LEFT OUTER JOIN table pruning when right table guaranteed not to return duplicates (due to unique index or DISTINCT/GROUP BY) and no columns were required for the final result, as shown in Figure 13-10.

Figure 13-10 DB2 10 left outer join table pruning
Figure 13-11 on page 243 represents DB2 11 LEFT OUTER JOIN query with materialization and an unnecessary join. Similar to prior UNION ALL examples, the UNION ALL will retrieve all columns and all rows from T1 and T2 and materialize these to a work file, which will be sorted for the join. T3 is then joined to this materialized result and a sort to remove duplicate C1 values (given the DISTINCT). Because no columns were required from the UNION ALL of T1 and T2, and the DISTINCT would remove any duplicates that were introduced, this join is unnecessary.

Figure 13-11 DB2 11 LEFT OUTER JOIN to unnecessary table expression
DB2 12 extends table pruning to views and table expressions where no columns are required and no duplicates are returned and also provides a simple rewrite as shown in Figure 13-12. The view definitions and the query against the views are the same between the two figures. What differs is how DB2 12 is able to prune out the table expression that contains the UNION ALL. The result is simply a SELECT DISTINCT requiring access only to T3.

Figure 13-12 DB2 12 LEFT OUTER JOIN to unnecessary table expression
13.5.2 Sort improvements
The following topics cover sort, work file, and sparse index improvements:
Sort minimization for partial order with FETCH FIRST
Up to DB2 11, a sort could be avoided and only “n” rows processed but only if an index was chosen that completely avoided the ORDER BY sort. In many situations if a sort is still required, seeing all the data is not necessary.
DB2 12 reduces the number of rows fetched or processed when there is no index that avoids the sort, if ordering by more than one column and only the leading column has an index.
Figure 13-13 shows how the sort minimization for a partial order with FETCH FIRST works:.

Figure 13-13 Sort minimization for partial order with FETCH FIRST
In the previous DB2 versions, the scenario was fetching all rows and sort into C1, C2 sequence, so in this way, millions of rows in the example above.
In DB2 12, when the tenth row is reached, then fetch until C1 changes. Using this method, 13 rows are fetched and 12 rows are sorted.
Sort avoidance for OLAP functions with PARTITION BY
Sort avoidance is also extended to online analytical processing (OLAP) functions that combine PARTITION BY and ORDER BY. Although DB2 11 already supports sort avoidance, if an index matches the ORDER BY clause with an OLAP function (such as RANK), that did not apply for sort avoidance when PARTITION BY was involved. Example 13-4 highlights an appropriate index that can be used in DB2 12 to avoid the sort for this SQL statement.
Example 13-4 Sort avoidance for OLAP functions with PARTITION BY clause
CREATE INDEX SK_SD_1 ON LINEITEM(L_SUPPKEY, L_SHIPDATE);
SELECT L_SUPPKEY, L_SHIPDATE,
RANK() OVER(PARTITION BY L_SUPPKEY
ORDER BY L_SHIPDATE) AS RANK1
FROM LINEITEM;
Reducing sort row length
A common behavior is that predicates coded in the WHERE clause are redundantly included in the SELECT list and any redundancy in the sort key or data row has a negative impact on sort performance and resource consumption. ORDER BY sort will remove columns from the sort key if covered by the equals predicates in the WHERE clause.
DISTINCT or GROUP BY already removes redundant columns for sort avoidance. But if a sort is required for DISTINCT or GROUP BY, such redundant columns remain until DB2 12, when they are removed from the sort key, as shown in Example 13-5. Also, because C1 has an equals predicate in the WHERE clause, all sorted rows are guaranteed to contain that same value, and thus only C2 is needed for the sort.
Example 13-5 Redundant columns in the sort key
SELECT DISTINCT C1, C2
FROM TABLE
WHERE C1 = ?
Up to DB2 11, for a SELECT (like SELECT C1, C2…..ORDER BY C1, C2), columns C1 and C2 are duplicated as the sort key. With DB2 12, the sort does not duplicate if the sort key is equal to the leading SELECT list columns.
This situation is applied for only fixed length columns (not VARCHAR, VARGRAPHIC, and others).
Improve GROUP BY/DISTINCT sort performance and In-memory sort exploitation
When sort cannot be avoided, exploiting memory to process the sort and reducing the length of the sort can result in that sort being contained in-memory or at a minimum to reduce the number of work file resources needed to complete the sort.
Prior to DB2 12, the maximum number of nodes of the sort tree was 32,000, and less for longer sort keys that were limited by ZPARM SRTPOOL.
DB2 12 enables sort tree and hash entries growth to 512,000 nodes (non-parallelism sort) or 128,000 (parallel child task sort). In addition, default 10MB SRTPOOL can support 100,000 nodes for 100 byte rows.
Also, DB2 9 added hashing as input to GROUP BY/DISTINCT sort; in DB2 the number of hash entries is tied to the number of nodes of the sort tree. Therefore, increasing the number of nodes can result in higher cardinality GROUP BY/DISTINCT results, consolidating the groups as rows are input to sort. This can increase the chance that the sort can be contained in memory or at least reduce the amount of work file space required to consolidate duplicates during the final sort merge pass.
DB2 12 can use the memory up to the ZPARM SRTPOOL value that might not have been exploited in the previous DB2 versions.
As result, DB2 12 performance improvements for GROUP BY/DISTINCT provides a CPU savings when sort can be contained in memory.
Sort workfile impacts
The large sorts may use the 32K page size regardless of row length on DB2 12. That is a big difference from DB2 9, in which this page size was limited to less than 100-byte rows.
This increase can result in more 32K page size data sets for sort. However, it was developed for other performance advantages that DB2 12 provides such as increased in-memory sorts, increased tree and hash size, reduced materialization, reduced sort keys size, and sort avoidance.
Sparse index improvements
DB2 12 provides sparse indexes support for the VARGRAPHIC data type. With this support, the memory allocation was improved when multiple sparse indexes in query. Also, the sort component improves its algorithms to adjust the type of sparse index that is built to optimize memory and also to reduce getpages when a sparse index must overflow to the work file.
When building a sparse index, sort also attempts to trim the information that must be stored.
Sparse index is able to avoid duplicate key information when key equals the data and fixed length keys, in addition, trimming trailing blanks for VARCHAR/VARGRAPHIC and prefix if all keys have the same prefix.
13.5.3 Predicate optimization
The following DB2 12 predicate optimizations are covered in this topic:
Sort for stage 2 join expressions
Expressions as join predicates are often stage 2, unless the exception for expression on the outer (without sort) for nested loop joins.
DB2 12 allows resolution of expression before sort to support join support for expression on inner and sparse index without sort on outer. See Example 13-6.
Example 13-6 Stage 2 join predicate
SELECT …
FROM T1, T2
WHERE T1.col1 = T2.col1 and
T1.col2 = SUBSTR(T2.col2,1,10)
DB2 12 can improve the performance of stage 2 join predicates by allowing sort to evaluate the function, and allowing sparse index to be built on the result for the join—which becomes an optimal candidate on the inner table when the result can be contained in-memory, or when there is no other viable index to support the filtering of the join. Alternatively, if the table with the join expression is the outer table of the join, a sort for join order can allow access to the inner table to be performed sequentially.
Stage 2 join predicates are often observed if tables are not designed with consistent data types for joined columns, which might occur if applications are integrated at a later date, or if business information is embedded within columns, or if timestamp columns are used within each table and the join is by the consistent date portion of those columns (for example, insert timestamps do not match between two tables). DB2 12 can therefore improve performance significantly for these situations without requiring a targeted index on expression to be built.
User-defined table function predicate optimizations
User-defined table functions (also known as table UDFs, table functions, or TUDFs) were initially targeted to allow an application program to be called from within an SQL statement. This provided the flexibility to access objects that are not DB2 and represent them as a table within SQL to be joined with DB2 tables. Inline table UDFs were a further extension to DB2 support, allowing the definitions to contain native SQL. An increase in table functions has occurred as an alternative to views because of the capability to create a table function with input parameters, whereas parameterized views are not supported in DB2 for z/OS.
Although prior releases provided similar merge (and thus materialization avoidance) capabilities for table functions that were syntactically equivalent to views, DB2 12 improves both the merge of deterministic table functions with input parameters and also improves indexability of input parameters as predicates within the table function, as demonstrated in Figure 13-14 on page 247.

Figure 13-14 Table function with input variables
VARBINARY data type indexability
Up to DB2 11, support was limited for BINARY and VARBINARY predicate indexability when the lengths of the operands of the predicates did not match. DB2 12 implicitly adds CAST expressions on the VARBINAR and BINARY predicates when the length of the operands does not match. Figure 13-15 compares the pre DB2 12 predicate as stage 2 of that with a CAST added in DB2 12 to support indexability of mismatched length VARBINARY.
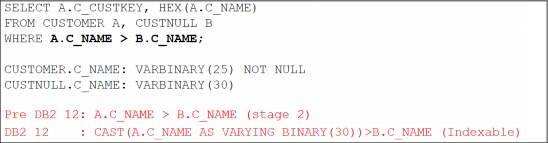
Figure 13-15 Pre-DB2 12 predicate as stage 2 of that with a CAST added in DB2 12 comparison
Although many clients might identify that VARBINARY or BINARY data types are not exploited within their environments, improving indexability is important because DB2 scalar functions can return a result as BINARY or VARBINARY. These improvements to the underlying support of BINARY and VARBINARY indexability were necessary to allow indexing on expressions to be built on those scalar functions and to be exploited for matching index access.
Example 13-7 shows a scalar function as an index on expression that is indexable in DB2 12. This example demonstrates the COLLATION_KEY scalar function with a parameter tailored to German.
Example 13-7 Index on expression for VARBINARY-based expression
CREATE INDEX EMPLOYEE_NAME_SORT_KEY ON EMPLOYEE
(COLLATION_KEY(LASTNAME, 'UCA410_LDE', 600));
SELECT *
FROM EMPLOYEE
WHERE COLLATION_KEY(LASTNAME, 'UCA410_LDE', 600) = < ?
Row permission to correlated subquery indexability
In versions prior to DB2 12, the correlation predicates in child-correlated subquery were stage 2 on row permissions for insert and update and DB2 12 provides support indexability for correlated subqueries on row permissions for insert and update, benefitting efficiency of security validation. Figure 13-16 shows a correlated subquery example of a row permission.

Figure 13-16 Correlated subquery predicates in a row permission
Additional IN-list performance enhancements
DB2 10 added IN-list table, where the optimizer could choose list prefetch for matching IN-list access. The execution was one list prefetch request per IN-list element, so performed poorly if low number of duplicates per element existed.
DB2 12 introduces an improvement to matching IN-list performance for poor clustering index, allowing the accumulation of 32 RIDs per list prefetch request. Also, DB2 12 removes a limitation that IN-lists cannot be used with index screening predicate for range-list access.
13.5.4 Execution time adaptive index
Execution time adaptive index is provided in DB2 12 as a solution for generic search queries that used to be a challenge for query optimizers. They were considered a challenge for these reasons:
•Filtering that could change each execution, so that choosing the one best access path was impossible.
• Fields not searched by the user will populate with the whole range:
LIKE ‘%’ or BETWEEN 00000 AND 99999.
•Fields searched will use their actual values:
LIKE ‘SMITH’ or BETWEEN 95141 AND 95141.
Runtime adaptive index solution has the following benefits:
•Allows list prefetching-based plans (single or multi-index) to quickly determine index filtering.
•Adjusts at execution time based on determined filtering:
– Does not require REOPT(ALWAYS).
– For list prefetching or multi-index OR:
• Earlier opportunity exists to fall back to tablespace scan if large percentage of table is to be read.
– For multi-index AND:
• Reorder index legs from most to least filtering.
• Early-out for non-filtering legs, and fallback to table space scan if no filtering.
– Quick evaluation is done based on literals that are used (for example LIKE ‘%’).
– Further costlier evaluation of filtering is deferred until after one RID block is retrieved from all participating indexes:
• Provides better optimization opportunity while minimizing overhead for short running queries.
•IFCID 125 is enhanced to track this feature.
•Solution is not limited to the search screen challenge:
– Any query where high uncertainty in the optimizer’s estimates exists:
• Range predicates.
• JSON, Spatial, and Index on expression.
The performance measurements evaluated to runtime adaptive index are as follows:
•List prefetching CPU reduction (when failover to table space scan is needed).
•Multi-index OR CPU reduction (when failover to table space scan is needed).
•Multi-index AND CPU reduction for re-ordering to put most filtering leg first.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.