
Chapter 9. OpenCL Case Study
Histogram
This chapter discusses optimizing memory-bound kernels—in this case, a histogram of 8-bit-per-pixel image data optimized into 256 histogram bins.
Keywords Example program, histogram, image, local, memory-bound, OpenCL
Introduction
This chapter discusses specific optimizations for a memory-bound kernel. The kernel we choose for this chapter is an image histogram operation. The source data for this operation is an 8-bit-per-pixel image with a target of counting into each of 256 32-bit histogram bins.
The principle of the histogram algorithm is to perform the following operation over each element of the image:
for( many input values ) {
histogram[ value ]++;
}
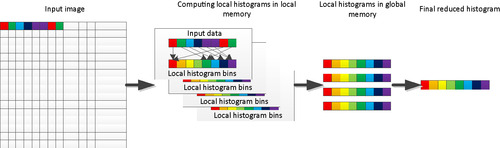
To address the high degree of contention of access in global memory, the algorithm chosen parallelizes the histogram over a number of workgroups, each of which summarizes its block of source data into a number of sub-histograms stored in on-chip local memory. These local histograms are finally reduced into a single global histogram, storing the result for the overall image. The overview of the algorithm is shown in Figure 9.1.
Choosing the Number of Workgroups
When we begin to map an OpenCL kernel to target hardware, we may encounter some constraints on the number of work-items and workgroups that follow from the design of the algorithm, the target architecture, and the size of the various memory regions distributed throughout the target machine. Local memory is shared within a workgroup, and a given group summarizes data into a sub-histogram stored in a region within local memory. This allows many work-items to contribute to the same local memory area, collaborating to reduce memory overhead. Given that the final stage of the histogram computation is a global reduction with a separate local region per workgroup, creating too many workgroups would transfer more local data into global memory, increasing memory usage and require a larger reduction operation.
To most efficiently use local memory and to reduce the overhead of global memory transactions, the number of workgroups should be as close as possible to the number of compute units, or SIMD cores, in the device. The local memory resources exist physically on a per-SIMD core basis in AMD and NVIDIA GPUs and are intended in the OpenCL specification to support access at least as efficient as global memory. It is important to make maximal use of the high bandwidth to such dedicated memory regions and that we use as many local memory spaces as possible to maximise parallel memory access. As just noted, we should avoid creating many more workgroups than the actual number of SIMD cores because this wastes global memory bandwidth.
Through the OpenCL API, we can query the number of compute units on the device at runtime:
clGetDeviceInfo(…, CL_DEVICE_MAX_COMPUTE_UNITS, … );
Choosing the Optimal Workgroup Size
The optimal workgroup size for a given algorithm can be difficult to identify. At a minimum, workgroup sizes should be selected to be an even multiple of the width of the hardware scheduling units. Because targeted architectures are often vector based, it is inefficient to use half vectors for scheduling OpenCL work-items. On AMD GPUs, the hardware scheduling unit is a wavefront—a logical vector of 32 or 64 work-items that runs on a hardware SIMD unit. OpenCL workgroups execute as sets of wavefronts.
A single wavefront per compute unit is inadequate to fully utilize the machine. The hardware schedules two wavefronts at a time interleaved through the ALUs of the SIMD unit, and it schedules additional wavefronts to perform memory transactions. An absolute minimum to satisfy the hardware and fill instruction slots on an AMD GPU is then three wavefronts per compute unit, or 196 work-items on high-end APU GPUs. However, to enable the GPU to perform efficient hiding of global memory latency in fetch-bound kernels, at least seven wavefronts are required per SIMD.
We cannot exceed the maximum number of work-items that the device supports in a workgroup, which is 256 on current AMD GPUs. At a minimum, we need 64 work-items per group and at least three groups per compute unit. At a maximum, we have 256 work-items per group, and the number of groups that fit on the compute unit will be resource limited. There is little benefit to launching a very large number of work-items. Once enough work-items to fill the machine and cover memory latency have been dispatched, nothing is gained from scheduling additional work-items, and there may be additional overhead incurred. Within this range, it is necessary to fine-tune the implementation to find the optimal performance point.
Optimizing Global Memory Data Access Patterns
A histogram is a highly memory-bound operation: Very few arithmetic operations are needed per pixel of the input image. We cannot rely on the often extensive floating point capabilities of OpenCL devices to attain high performance. Instead, we must make as efficient use of the memory system as possible, optimizing memory accesses when moving from one type of device to another.
For the histogram operation, the order of reads from global memory is order independent. This means that we can freely optimize the access pattern without concerns about correctly ordering reads with respect to each other.
The memory subsystems of both AMD GPUs and CPUs are optimized to perform 128-bit read operations, matching the common four-component pixel size of four 32-bit floats. On the GPU, single reads are inefficient because of the availability of vector hardware that can hold up to 64 work-items, so multiples of this 128-bit read allow the memory system to take full advantage of wide and high-speed data paths to memory. The ideal read pattern is for all simultaneously executing work-items to read adjacent 128-bit quantities, forming a 256-byte read burst across the 16 work-items executing in parallel on a given core and directly mapping to a GPU memory channel.
The result is that we transform memory accesses as follows. Each work-item reads unsigned integer quantities, packed into four-wide vectors (unit4), starting at the global work-item index and continuing with a stride that is equal to the total number of work-items to be read.
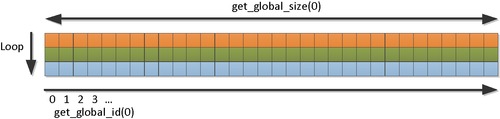
An efficient access pattern for reading input data is shown in the following code and in Figure 9.2:
 |
| Figure 9.2 |
uint gid= get_global_id(0);
uint Stride = get_global_size(0);
for( i=0, idx = gid; i < n4VectorsPerWorkItem; i++, idx += Stride ) {
uint4 temp = Image[idx];
…

uint gid= get_global_id(0);
for( i=0, idx = gid * n4VectorsPerWorkItem;
I < n4VectorsPerWorkItem;
i++, idx++) {
uint4 temp = Image[idx];
…
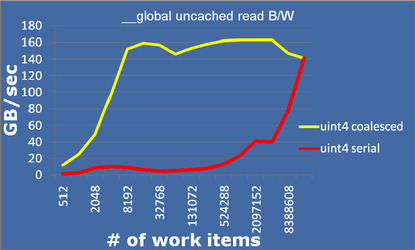
We can see how the difference between these trades off as a function of the number of work-items in Figure 9.4. A clear performance benefit initially, but as we increase the number of work-items performing coalesced reads, performance declines because too many work-items are active in the system. Serial performance is very poor when strides are long, but as strides reduce, cache line reuse and coalescing benefits in the memory system improve performance until the two types of reads converge when they become identical with one data element read per work-item.
Using Atomics to Perform Local Histogram
When we execute this application on a CPU, we execute a workgroup with a single thread and hence have no read-after-write hazards. When targeting an AMD Radeon™ GPU, we can use a wide SIMD vector and provide for fine-grained threading. The combination of these features means that many work-items execute in parallel (16 work-items on high-end GPUs), and we can potentially interleave instruction execution from multiple executing wavefronts. As a result, we cannot guarantee the ordering of read-after-write dependencies on our local histogram bins.
To address this issue, we could reproduce the histogram bins multiple times, but this would require a copy of each bin for each work-item in the group (we do not know what order they will execute in). The resulting memory pressure would be too great.
The alternative solution is to use hardware atomics. As discussed in Chapter 6, the hardware atomics on the AMD Radeon HD6970 architecture are associated with each lane of the local data storage and can improve performance significantly. We can rely on these atomics with little concern about the overhead for our algorithm.
Performing the histogram operation in a local memory buffer becomes as simple as the following code. Note that because we have performed a 128-bit read of 16 pixels simultaneously (where each pixel is really a single 8-bit channel), we repeat this code in the core loop for each channel and use masks and shifts to extract this data. Performing the mask and shift operations explicitly on a uint4 vector maps efficiently to the underlying hardware architecture.
for( int i=0, idx=gid; i<n4VectorsPerWorkItem; i++, idx += Stride ) {
uint4 temp = Image[idx];
uint4 temp2 = (temp & mask);
(void) atomic_inc( subhists + temp2.x );
(void) atomic_inc( subhists + temp2.y );
(void) atomic_inc( subhists + temp2.z );
(void) atomic_inc( subhists + temp2.w );
temp = temp >> 8;
temp2 = (temp & mask);
…
Optimizing Local Memory Access
Directly targeting histogram bins in global memory is a recipe for a nonscalable algorithm (i.e., the performance will not scale when we introduce additional hardware resources to the execution). There is a severe bottleneck when performing binning operations, whether using atomic functions or multiple bins per group, through the DRAM interface that will limit performance due to a significant increase in the total amount of memory traffic.
To avoid this issue, we choose to use separate small histograms for each workgroup using local memory buffers. These local memories are very high bandwidth, whether we are running on a CPU or a GPU. Using small histograms guarantees cache independence on a CPU and effective use of the dedicated high-bandwidth scratchpad memories on many GPUs. Although we are able to map to the scratchpad memory on a GPU, given that we are using wide SIMD vectors to access this memory, care must be taken to access this local data efficiently. Taking the local memory structure on the AMD Radeon 6970 GPU as an example (i.e., local data shares (LDS)), we have an SRAM array with 32 banks addressed using bits 2–7 of the address. Bank conflicts occur if we have multiple work-items from a 16-wide parallel SIMD issue attempt to read or write the same LDS bank.
Because we are limiting ourselves to a small number of workgroups relative to the amount of input data, we know that each work-item will process a significant number of input pixels. We already know that this reduces the size of the final reduction and concentrates work into local memory, localizing memory traffic and hence improving performance. It also gives us a further advantage in that we can afford to expand our local memory buffer slightly, such that instead of a single histogram for the entire workgroup, we use a subset of histograms and perform a reduction at the end. Given the large number of pixels per work-item, the overhead of the reduction stage should be negligible.
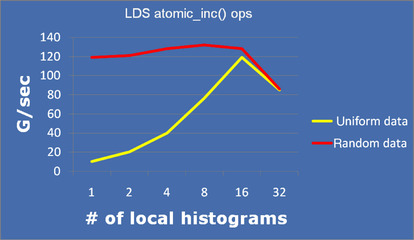
The benefit of using multiple histogram bins is apparent if we are careful with our layout. Figure 9.5 shows how we can reproduce the histogram multiple times to reduce bank conflicts. The AMD hardware has 32 memory banks in LDS and a single set of histogram bins. To attempt to increment the same histogram bin (guaranteed in a single color image) or sets of histogram bins that map to the same bank, sets of 16 work-items are dispatched in a single SIMD instruction. Any collisions will cause the application to stall.
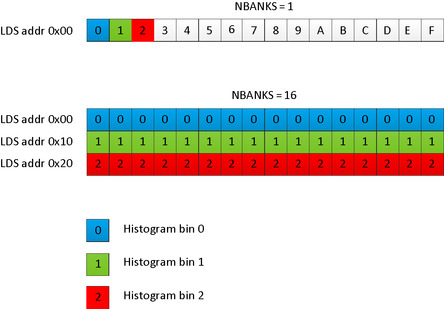
To avoid these stalls, we can reproduce the entire set of histogram bins such that each work-item is guaranteed, whichever histogram bin it aims to use, to access the same bank. In this way, we can guarantee that a single bank will be used per work-item, and no two work-items will use the same bank. The cost is an increase in local memory use per workgroup and the addition of a local reduction stage to the computation.
Figure 9.6 shows the impact of this trade-off when accessing a random data set, where conflicts were few, so the overhead of the reduction is more noticeable. A uniform data set created a significant number of bank conflicts when using a single set of histogram bins and so benefits immediately when increasing the number of copies. Realistic data sets would lie between these two extremes. Note that the peak is found at 16 banks, even though this evaluation is performed on the Radeon HD6970 device with 32 banks in total. Only 16 work-items issue in a given SIMD vector, and atomic operations are limited to 32-bit per SIMD lanes, so we can only use a maximum of 16 banks; the other 16 are unused.
 |
| Figure 9.6 |
We next modify the previous code to compute offsets based on the number of copies of the local histogram we described previously:
#define NBANKS 16
uint offset = (uint) lid % (uint) (NBANKS);
for( int i=0, idx=gid; i<n4VectorsPerWorkItem; i++, idx += Stride ) {
uint4 temp = Image[idx];
uint4 temp2 = (temp & mask) * (uint4) NBANKS + offset;
(void) atomic_inc( subhists + temp2.x );
(void) atomic_inc( subhists + temp2.y );
(void) atomic_inc( subhists + temp2.z );
(void) atomic_inc( subhists + temp2.w );
…
Local Histogram Reduction
Before we conclude the local histogram kernel discussion, we must reduce the data across the copies we created and output this to global memory. We can mask out work-items in the group higher numbered than the number of bins. We can alternatively iterate through bins (if there are more bins than work-items) and then, for each bin histogram, copy the bins and output this to global memory.
barrier( CLK_LOCAL_MEM_FENCE );
for( int binIndex = lid;
binIndex < NBINS;
binIndex += get_local_size(0) ) {
uint bin = 0;
for( int i=0; i<NBANKS; i++ ) {
bin += subhists[
(lid * NBANKS) + ((i + lid) % NBANKS) ];
}
globalHistogram[
(get_group_id(0) * NBINS) + binIndex ] = bin;
}
The Global Reduction
The final step necessary in our histogram algorithm is to reduce the local bins. Because we have carefully limited the number of workgroups, the work to perform the global reduction is minor. Accordingly, we can avoid performing complicated tree-based reductions and multipass algorithms. Instead, we enqueue a single summation kernel similar to the reduction used for the local histograms:
__kernel void reduceKernel(
__global uint * globalHistogram,
uint nSubHists ) {
uint gid = get_global_id(0);
uint bin = 0;
for( int i=0; i < nSubHists; i++ )
bin += globalHistogram [ (i * NBINS) + gid ];
globalHistogram [ gid ] = bin;
}
Full Kernel Code
__kernel __attribute__((reqd_work_group_size(NBINS,1,1)))
void histogramKernel(__global uint4 *Image,
__global uint *globalHistogram,
uint n4VectorsPerWorkItem){
uint gid= get_global_id(0);
uint lid= get_local_id(0);
uint Stride = get_global_size(0);
uint4 temp, temp2;
const uint shift = (uint) NBITS;
const uint mask = (uint) (NBINS-1);
uint offset = (uint) lid % (uint) (NBANKS);
uint localItems = NBANKS * NBINS;
uint localItemsPerWorkItem;
uint localMaxWorkItems;
// parallel LDS clear
// first, calculate work-items per data item,
// at least 1:
localMaxWorkItems = min( 1, get_local_size(0) / localItems );
// but no more than we have items:
localMaxWorkItems = max( 1, localMaxWorkItems / localItems );
// calculate threads total:
localMaxWorkItems = localItems / localMaxWorkItems;
// but no more than LDS banks:
localMaxWorkItems = min( get_local_size(0), localMaxWorkItems );
localItemsPerWorkItem = localItems / localMaxWorkItems;
// now, clear LDS
__local uint *p = (__local uint *) subhists;
if( lid < localMaxWorkItems ) {
for(i=0, idx=lid;
i<localItemsPerWorkItem;
i++, idx+=localMaxWorkItems)
{
p[idx] = 0;
}
}
barrier( CLK_LOCAL_MEM_FENCE );
// read & scatter phase
for( int i=0, idx=gid;
i<n4VectorsPerWorkItem;
i++, idx += Stride ) {
temp = Image[idx];
temp2 = (temp & mask) * (uint4) NBANKS + offset;
(void) atomic_inc( subhists + temp2.y );
(void) atomic_inc( subhists + temp2.z );
(void) atomic_inc( subhists + temp2.w );
temp = temp >> shift;
temp2 = (temp & mask) * (uint4) NBANKS + offset;
(void) atomic_inc( subhists + temp2.x );
(void) atomic_inc( subhists + temp2.y );
(void) atomic_inc( subhists + temp2.z );
(void) atomic_inc( subhists + temp2.w );
temp = temp >> shift;
temp2 = (temp & mask) * (uint4) NBANKS + offset;
(void) atomic_inc( subhists + temp2.x );
(void) atomic_inc( subhists + temp2.y );
(void) atomic_inc( subhists + temp2.z );
(void) atomic_inc( subhists + temp2.w );
temp = temp >> shift;
temp2 = (temp & mask) * (uint4) NBANKS + offset;
(void) atomic_inc( subhists + temp2.x );
(void) atomic_inc( subhists + temp2.y );
(void) atomic_inc( subhists + temp2.z );
(void) atomic_inc( subhists + temp2.w );
}
barrier( CLK_LOCAL_MEM_FENCE );
// reduce __local banks to single histogram per work-group
for( int binIndex = lid;
binIndex < NBINS;
binIndex += get_local_size(0) ) {
uint bin = 0;
for( int i=0; i<NBANKS; i++ ) {
bin += subhists[
(lid * NBANKS) + ((i + lid) % NBANKS) ];
}
globalHistogram[
(get_group_id(0) * NBINS) + binIndex ] = bin;
}
}
__kernel void reduceKernel(
__global uint *globalHistogram,
uint nSubHists ) {
uint gid = get_global_id(0);
uint bin = 0;
// Reduce work-group histograms into single histogram,
// one work-item for each bin.
for( int i=0; i < nSubHists; i++ )
bin += globalHistogram[ (i * NBINS) + gid ];
globalHistogram[ gid ] = bin;
}
Performance and Summary
Combining these activities, we can process a significant amount of input data with very high performance. As measured on the AMD Radeon HD6970 architecture with 256 histogram bins, we can achieve the following:
1. 158 GB/s of input data performing only reads from global memory into registers
2. 140 GB/s of input data adding scattering into local histograms to 1
3. 139 GB/s adding the local reduction operation to 1 and 2
4. 128 GB/s adding the final global reduction, requiring enqueuing a second kernel, to 1–3
In this chapter, we focused on the steps needed to optimize a memory-bound algorithm. We discussed how to restructure reads and to use local memory to reduce access overhead. We showed that we can improve application throughput when performing a full histogram compared with reading data only. We also showed that compared with reading data only, performing a full histogram need only marginally reduce application throughput if implemented efficiently. Techniques to reduce local memory bank conflicts and to improve global memory performance have wide application in other algorithms.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.