
Chapter 7. OpenCL Case Study
Convolution
This chapter discusses the implementation of more advanced optimizations of OpenCL kernels to improve the performance of a convolution filter.
Keywords Convolution, example program, OpenCL
Introduction
In Chapter 4, we introduced a basic convolution example using OpenCL images. Images provided the benefit of automatically handling out-of-bounds accesses (by clamping or wrapping accesses), which simplified the coding that would have been required for the cases in which the convolution filter accessed data outside of the image. Thus, image support may reduce control flow overhead and provide caching and data access transformations that improve memory system performance. When targeting GPUs, the automatic caching mechanism provided for images is much better than not caching. In many circumstances, however, it can be outperformed by efficient use of local memory. In this chapter, we use a convolution filter to provide some intuition on how to make good use of local memory. We encourage the reader to compare the two different implementation choices and judge which would be best for a particular use case.
Convolution kernel
The OpenCL convolution kernel can be naturally divided into three sections: (1) the caching of input data from global to local memory, (2) performing the convolution, and (3) the writing of output data back to global memory. This chapter focuses on the first task, optimizing data caching for the underlying memory system. Loop unrolling is also discussed in the context of performing the convolution. The write back stage is straightforward and will not be discussed in detail. During the discussion, a 7 × 7 filter is considered when concrete examples facilitate the discussion of optimizations, although the principles should generalize to different filter configurations. Optimizations for the OpenCL kernel are presented inline throughout the chapter, along with any relevant host code. The complete reference implementations are provided in Code Listings.
Selecting Workgroup Sizes
Recall that when performing a convolution, each work-item accesses surrounding pixels based on the size of the filter. The filter radius is the number of pixels in each direction that are accessed, not including the current pixel. For example, a 7 × 7 filter accesses three additional pixels in each direction, so the radius is 3. From Figure 4.5, it is easy to see that adjacent output points have two-dimensional locality for data accesses. Each work region also involves a wide data halo of padding pixels due to the size of the input filter. This tells us that for efficiency, we should use two-dimensional access regions, and a square minimizes the ratio of the halo dimensions to the output data size and hence the input:output efficiency. For this example, we consider a mapping of work-items using a single work-item per output approach, leaving multi-output optimizations to be considered in a histogram example in Chapter 9. Figure 7.1 shows the padding pixels required for a given work region and hence an OpenCL workgroup.
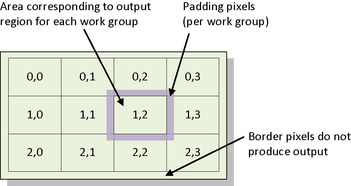 |
| Figure 7.1 |
In OpenCL, work-item creation and algorithm design must be considered simultaneously, especially when local memory is used. For convolution, the size of the workgroups and the algorithm for caching data to local memory are closely related. There are two obvious approaches for caching data. The first approach is to create the same number of work-items as there are data elements to be cached in local memory. That is, create as many work-items as there are in the combined number of output and padding pixels. Using this approach, each element would simply copy one pixel from global to local memory, and then the work-items representing the border pixels would sit idle during the convolution. The limitations of this approach are that larger filter sizes will not allow many output elements to be computed per workgroup, and when targeting GPUs, wavefronts may be fragmented, causing ALU cycles to be wasted. Alternatively, the second approach is to create as many work-items as will be performing the convolution. In this approach, there will be fewer work-items than pixels to be cached, so some work-items will have to copy multiple elements and none will sit idle during the convolution. This approach is obviously much better suited for large filters because the number of padding elements will not limit the number of work-items that generate output pixels. For this example, the second approach to work-item creation is used because it is better suited for OpenCL targeting GPUs.
Taking this optimization approach a step further, we might like to create fewer work-items than output pixels in a group. The reader can easily infer such an approach from the algorithm discussed and may like to experiment with this trade-off. Finding the optimal combination can mean exploring a large design space.
Selecting an efficient workgroup size requires consideration of the underlying memory architecture. Chapter 5 described that when vector processors are targeted, particularly the AMD 6970 GPU, it is important to ensure that many consecutive work-items issue a collaborative memory access. Sixteen consecutive work-items issuing 128-bit reads on an aligned address can come closest to fully utilizing the memory bus bandwidth. The most favorable memory transactions on NVIDIA platforms come from 32 work-items issuing a combined request that is 128 bytes in size and 128-byte aligned (NVIDIA, 2009). This means 32 work-items will access consecutive 4-byte elements, beginning at a 128-byte aligned address boundary, which is the most ideal access pattern. Transactions of 64 and 32 bytes are also supported. For this example, creating workgroups of either 32 or 16 items in width offers us a good chance for creating efficient memory requests regardless of platform. The Y-dimension of the workgroup does not affect memory access performance. On AMD GPUs, the workgroup size limit is 256 work-items, so choosing a width of 32 produces a height of 8, and a width of 16 produces a height of 16. With NVIDIA, larger workgroup sizes are possible, although the “ideal” size is really determined by the interplay between hardware resources. The workgroup size that performs best will be a trade-off between the efficiency of the memory accesses and the efficiency of the computation. For the code and analysis presented in this chapter, we use 16 × 16 workgroups to perform the convolution.
When performing reads from global to local memory, each workgroup needs to copy twice the filter radius additional work-items in each dimension. For a 7 × 7 filter, this would mean an additional six pixels in each dimension. When computing the NDRange size, one filter radius of border pixels around the image (i.e., 3 for a 7 × 7 filter) will not compute output values because they would cause out-of-bounds accesses for the filter. 1 For an image with dimensions imageWidth and imageHeight, only (imageWidth-2*filterRadius) x (imageHeight-2*filterRadius) work-items are needed in each dimension, respectively. Because the image will likely not be an exact multiple of the workgroup size, additional workgroups must be created in both the X- and Y-dimensions (Figure 7.2). These last workgroups in each dimension may not be fully utilized, and this must be accounted for in the OpenCL kernel. A function that takes a value (e.g., the image width) and rounds it up to a multiple of another value (e.g., the workgroup width) is shown here:
1The algorithm could be modified to have the border pixels produce output values by detecting out-of-bounds accesses and returning valid values.
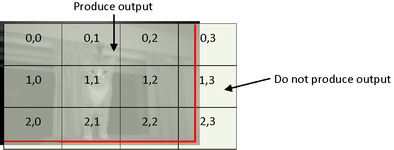 |
| Figure 7.2 |
// This function takes a positive integer and rounds it up to
// the nearest multiple of another provided integer
unsigned int roundUp(unsigned int value, unsigned int multiple) {
}
The code to compute the NDRange size for an image with dimensions imageWidth and imageHeight is as follows:
// Selected workgroup size is 16x16
int wgWidth = 16;
int wgHeight = 16;
// When computing the total number of work-items, the
// padding work-items do not need to be considered
int totalWorkItemsX = roundUp(imageWidth-paddingPixels,
wgWidth);
int totalWorkItemsY = roundUp(imageHeight-paddingPixels,
wgHeight);
// Size of a workgroup
size_t localSize[2] = {wgWidth, wgHeight};
// Size of the NDRange
size_t globalSize[2] = {totalWorkItemsX, totalWorkItemsY};
Caching Data to Local Memory
Caching data in local memory first requires allocating space in local memory—either statically by hard coding the values into the OpenCL kernel or dynamically by specifying a size and passing it as a kernel argument. Because the program will have to cache a different amount of data based on the filter size, the following dynamically allocates local memory space and passes it as the seventh argument (the argument at index 6) to the OpenCL kernel:
The process of copying data from global memory to local memory often requires the most thought and is often the most error-prone operation when writing a kernel. The work-items first need to determine where in global memory to copy from and then ensure that they do not access a region that is outside of their working area or out of bounds for the image. The following code identifies each work-item locally and globally and then performs the copy from global memory to local memory. Figure 7.3 provides an illustration of the variables used to perform the copy in this example:
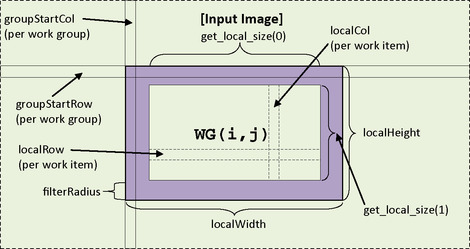 |
| Figure 7.3 |
__kernel
void convolution(__global float* imageIn,
__global float* imageOut,
__constant float* filter,
int rows,
int cols,
int filterWidth,
__local float* localImage,
int localHeight,
int localWidth) {
// Determine the amount of padding for this filter
int filterRadius = (filterWidth/2);
int padding = filterRadius * 2;
int groupStartCol = get_group_id(0)*get_local_size(0);
int groupStartRow = get_group_id(1)*get_local_size(1);
// Determine the local ID of each work-item
int localCol = get_local_id(0);
int localRow = get_local_id(1);
// Determine the global ID of each work-item. work-items
// representing the output region will have a unique
// global ID
int globalCol = groupStartCol + localCol;
int globalRow = groupStartRow + localRow;
// Cache the data to local memory
// Step down rows
for(int i = localRow; i < localHeight; i +=
get_local_size(1)) {
int curRow = groupStartRow+i;
// Step across columns
for(int j = localCol; j < localWidth; j +=
get_local_size(0)) {
int curCol = groupStartCol+j;
// Perform the read if it is in bounds
if(curRow < rows && curCol < cols) {
localImage[i*localWidth + j] =
imageIn[curRow*cols+curCol];
}
}
}
barrier(CLK_LOCAL_MEM_FENCE);
// Perform the convolution
…
Aligning for Memory Accesses
Performance on both NVIDIA and AMD GPUs benefits from data alignment in global memory. Particularly for NVIDIA, aligning accesses on 128-byte boundaries and accessing 128-byte segments will map ideally to the memory hardware. However, in this example, the 16-wide workgroups will only be accessing 64-byte segments, so data should be aligned to 64-byte addresses. This means that the first column that each workgroup accesses should begin at a 64-byte aligned address.
In this example, the choice to have the border pixels not produce values determines that the offset for all workgroups will be a multiple of the workgroup dimensions (i.e., for a 16 × 16 workgroup, workgroup <N, M> will begin accessing data at column N*16). An example of the offset of each workgroup is presented in Figure 7.4. To ensure that each workgroup aligns properly, the only requirement then is to pad the input data with extra columns so that its width becomes a multiple of the X-dimension of the workgroup.
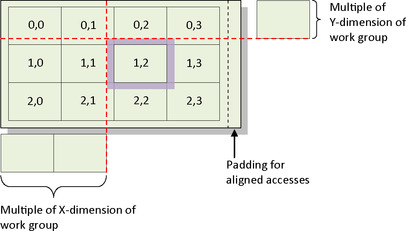 |
| Figure 7.4 |
Manually padding a data array on the host can be complicated, time-consuming, and sometimes infeasible. To avoid such tedious data fixup, OpenCL has introduced a command called clEnqueueWriteBufferRect() to copy a host array into the middle of a larger device buffer. When creating the buffer, the number of columns used to determine the size should be the number of elements required to provide the desired alignment. For a 16 × 16 workgroup, the number of columns should be rounded up to the nearest multiple of 16. The call to clEnqueueWriteBufferRect()that copies the host data into the padded device buffer is listed here:
// Pad the number of columns (assuming 16x16 workgroup)
int deviceWidth = roundUp(imageWidth, 16);
// No padding needed for rows
int deviceHeight = imageHeight;
// Copy the input data on the host to the padded buffer
// on the device
clEnqueueWriteBufferRect(queue, d_inputImage, CL_TRUE,
buffer_origin, host_origin, region,
deviceWidth*sizeof(float), 0, imageWidth*sizeof(float),
0, inputImage, 0, NULL, NULL);
By aligning data to a 64-byte boundary, performance improved by 10% on a Radeon 6970 GPU. The NVIDIA Fermi architecture automatically caches memory transactions on-chip in L1 memory, and because nonaligned reads get turned into an additional access (which is usually used in the following read anyway), negligible performance gains can be achieved on a GTX 480. On the GT200 series architecture, automatic caching is not supported, so memory alignment plays a more significant role. Using the NVIDIA Visual Profiler and a GTX 285 GPU, we see that aligning to a 64-byte address boundary results in fewer memory transactions, each of a larger size, producing an 8% improvement in memory performance over the original version of the code.
Improving Efficiency with Vector Reads
AMD GPUs are optimized for 128-bit read operations per SIMD lane and therefore see performance gains from performing vector reads (i.e., reading float4 data allows us to come closer to achieving peak memory bandwidth than reading float data). Although it is not intuitive to perform the convolution using a vector type, if the width of the data being cached from global memory to local memory is a multiple of four, vector types should be used for the data transfer portion of the algorithm. Furthermore, if a filter has radius of 8 or less (i.e., the filter is at most 17 × 17), a 16 × 16 workgroup can copy all of the padding and output pixels with only a single float4 read per work-item.
The first step is to resize the local memory allocation to include the extra pixels required to support the float4 data type:
int localWidth = roundUp(localSize[0]+padding, 4);
int localHeight = localSize[1]+padding;
size_t localMemSize = (localWidth*localHeight*sizeof(float));
The code to perform the vector transfer of data from global memory to local memory is listed next. To employ a vector read and still use scalar data for the convolution, the input image is given the type float4, and the local memory cache is given the data type float. When the read is performed, a temporary __local float4 pointer is set to the desired location in local memory and is used to read the data. By using float4 as the data type of the input image, the width (number of columns) of the image is divided by four because each column stores four values. The number of rows in the image does not change.
__kernel
void convolution_read4(__global float4* imageIn,
__global float* imageOut,
__constant float* filter,
int rows,
int cols,
int filterWidth,
__local float* localImage,
int localHeight,
int localWidth) {
// scalar memory
__local float4* localImage4;
// Determine the amount of padding for this filter
int filterRadius = (filterWidth/2);
int padding = filterRadius * 2;
// Determine where each workgroup begins reading
int groupStartCol = get_group_id(0)*get_local_size(0)/4;
int groupStartRow = get_group_id(1)*get_local_size(1);
// Flatten the localIds 0-255
int localId = get_local_id(1)*get_local_size(0) +
get_local_id(0);
// There will be localWidth/4 work-items reading per row
int localRow = (localId / (localWidth/4));
// Each work-item is reading 4 elements apart
int localCol = (localId % (localWidth/4));
// Determine the row and column offset in global memory
// assuming each element reads 4 floats
int globalRow = groupStartRow + localRow;
int globalCol = groupStartCol + localCol;
// Set the vector pointer to the correct scalar location
// in local memory
localImage4 = (__local float4*)
&localImage[localRow*localWidth+localCol*4];
// Perform all of the reads with a single load
if(globalRow < rows && globalCol < cols/4 &&
localRow < localHeight) {
localImage4[0] = imageIn[globalRow*cols/4+globalCol];
}
barrier(CLK_LOCAL_MEM_FENCE);
// Perform the convolution
…
On the AMD Radeon 6970, a significant performance gain is achieved by using vector reads. Compared to the initial implementation of the algorithm, a 42% improvement in memory performance was seen when using the float4 data type with aligned memory accesses. The memory hardware on NVIDIA GPUs benefits less from 128-bit reads, and the extra register pressure can decrease overall performance; thus, even though the overall number of memory transactions decreased using the vector type, a slight performance degradation was seen in this example.
Performing the Convolution
Now that the data is stored in local memory, it can be efficiently accessed to perform the convolution. The following code provides an implementation of the algorithm that corresponds to the C version in Chapter 4. Each work-item represents an output location and applies the filter by performing multiply-accumulate operations in a neighborhood around its location. No output is produced for pixels that would need to access out-of-bounds locations in the original image due to the filter size. For a 7 × 7 filter, the first valid output pixel will be located at index (3,3), and issue accesses to the padding pixels beginning at index (0,0). Because we want all work-items to produce output data, the work-item with global index (0,0) will produce the output value at (3,3). In other words, each work-item's output value will be offset from its global ID by the filter radius in both the X and Y directions. The following code performs the convolution:
// the output image to perform the convolution
if(globalRow < rows - padding && globalCol < cols - padding) {
// Each work-item will filter around its start location
// (starting from the filter radius left and up)
float sum = 0.0f;
int filterIdx = 0;
// The convolution loop
for(int i = localRow; i < localRow+filterWidth; i++) {
int offset = i*localWidth;
for(int j = localCol; j < localCol+filterWidth; j++) {
sum += localImage[offset+j] * filter[filterIdx++];
}
}
// Write the data out
imageOut[(globalRow+filterRadius)*cols +
(globalCol+filterRadius)] = sum;
}
}
Improving Performance with Loop Unrolling
Using the AMD APP Profiler, we are able to see that the ALU packing in the VLIW units for this kernel is low (only 43%). This means that less than half of the ALU units are being utilized, and it is a sign that the compiler cannot find sufficient instructions to fill the VLIW units. For the convolution kernel, the tight computation loops are the likely culprit. If we know that the filter size will be static (i.e., at compile time), we can unroll the inner loop to increase the ratio of ALU to branching instructions.
// Only allow work-items mapping to valid locations in
// the output image to perform the convolution
if(globalRow < rows - padding && globalCol < cols - padding) {
// Each work-item will filter around its start location
//(starting from the filter radius left and up)
float sum = 0.0f;
int filterIdx = 0;
// Inner loop unrolled
for(int i = localRow; i < localRow+filterWidth; i++) {
int offset = i*localWidth+localCol;
sum += localImage[offset++] * filter[filterIdx++];
sum += localImage[offset++] * filter[filterIdx++];
sum += localImage[offset++] * filter[filterIdx++];
sum += localImage[offset++] * filter[filterIdx++];
sum += localImage[offset++] * filter[filterIdx++];
sum += localImage[offset++] * filter[filterIdx++];
sum += localImage[offset++] * filter[filterIdx++];
}
// Write the data out
imageOut[(globalRow+filterRadius)*cols +
(globalCol+filterRadius)] = sum;
}
}
On an AMD Radeon 6970, using a 7 × 7 filter and a 600 × 400 image, unrolling the innermost loop provided a 2.4× speedup and increased the ALU packing efficiency to 79%. The GTX 285 and 480 saw similar performance gains—2.6× and 2.2× speedups, respectively.
Completely unrolling both inner and outer loops of the convolution increases the code size and may not be possible for large filtering kernels. However, in general, loop unrolling produces a substantial speedup on both AMD and NVIDIA GPU devices. With a 7 × 7 filter, the Radeon 6970 achieved a 6.3× speedup over the non-unrolled version. The GTX 285 and 480 saw speedups of 3.2× and 2.9×, respectively, over the non-unrolled version.
Using the memory optimizations and loop unrolling described in this chapter, both the Radeon 6970 and the GTX 480 are able to perform the convolution at a rate of approximately 2 billion pixels per second while using a 7 ×7 filter.
Conclusions
This chapter discussed a classical computational kernel, convolution, that is used in many machine vision, statistics, and signal processing applications. We presented how to approach optimization of this OpenCL kernel when targeting either AMD or NVIDIA GPUs. We explored the benefits of different memory optimizations and showed that performance is heavily dependent on the underlying memory architecture of the different devices. However, for all devices considered, significant performance improvements were obtained in the computational portions of the algorithm by giving up the generality of the double convolution loops and unrolling for specific kernel sizes. In general, many performance optimizations will depend on the specifics of the underlying device hardware architecture. To obtain peak performance, the programmer should be equipped with this information.
Code listings
Host Code
#define WGX 16
#define WGY 16
// Uncomment each of these to run with the corresponding
// optimization
#define NON_OPTIMIZED
//#define READ_ALIGNED
//#define READ4
// This function takes a positive integer and rounds it up to
// the nearest multiple of another provided integer
unsigned int roundUp(unsigned int value, unsigned int multiple) {
// Determine how far past the nearest multiple the value is
unsigned int remainder = value % multiple;
// Add the difference to make the value a multiple
if(remainder != 0) {
value += (multiple-remainder);
}
return value;
}
int main(int argc, char** argv) {
// Set up the data on the host
// Rows and columns in the input image
int imageHeight;
int imageWidth;
// Homegrown function to read a BMP from file
float* inputImage = readImage("input.bmp", &imageWidth,
&imageHeight);
// Size of the input and output images on the host
int dataSize = imageHeight*imageWidth*sizeof(float);
// Pad the number of columns
#else // READ_ALIGNED || READ4
int deviceWidth = roundUp(imageWidth, WGX);
#endif
int deviceHeight = imageHeight;
// Size of the input and output images on the device
int deviceDataSize = imageHeight*deviceWidth*sizeof(float);
// Output image on the host
float* outputImage = NULL;
outputImage = (float*)malloc(dataSize);
for(int i = 0; i < imageHeight; i++) {
for(int j = 0; j < imageWidth; j++) {
outputImage[i*imageWidth+j] = 0;
}
}
// 45 degree motion blur
float filter[49] =
{0,0,0,0,0, 0.0145,0,
0,0,0,0, 0.0376, 0.1283, 0.0145,
0,0,0, 0.0376, 0.1283, 0.0376,0,
0,0, 0.0376, 0.1283, 0.0376,0,0,
0, 0.0376, 0.1283, 0.0376,0,0,0,
0.0145, 0.1283, 0.0376,0,0,0,0,
0, 0.0145,0,0,0,0,0};
int filterWidth = 7;
int filterRadius = filterWidth/2;
int paddingPixels = (int)(filterWidth/2) * 2;
// Set up the OpenCL environment
// Discovery platform
cl_platform_id platform;
clGetPlatformIDs(1, &platform, NULL);
// Discover device
cl_device_id device;
clGetDeviceIDs(platform, CL_DEVICE_TYPE_ALL, 1, &device,
NULL);
// Create context
cl_context_properties props[3] = {CL_CONTEXT_PLATFORM,
(cl_context_properties)(platform), 0};
cl_context context;
context = clCreateContext(props, 1, &device, NULL, NULL,
NULL);
// Create command queue
cl_command_queue queue;
// Create memory buffers
cl_mem d_inputImage;
cl_mem d_outputImage;
cl_mem d_filter;
d_inputImage = clCreateBuffer(context, CL_MEM_READ_ONLY,
deviceDataSize, NULL, NULL);
d_outputImage = clCreateBuffer(context, CL_MEM_WRITE_ONLY,
deviceDataSize, NULL, NULL);
d_filter = clCreateBuffer(context, CL_MEM_READ_ONLY,
49*sizeof(float),NULL, NULL);
// Write input data to the device
#ifdef NON_OPTIMIZED
clEnqueueWriteBuffer(queue, d_inputImage, CL_TRUE, 0, deviceDataSize,
inputImage, 0, NULL, NULL);
#else // READ_ALIGNED || READ4
size_t buffer_origin[3] = {0,0,0};
size_t host_origin[3] = {0,0,0};
size_t region[3] = {deviceWidth*sizeof(float),
imageHeight, 1};
clEnqueueWriteBufferRect(queue, d_inputImage, CL_TRUE,
buffer_origin, host_origin, region,
deviceWidth*sizeof(float), 0, imageWidth*sizeof(float), 0,
inputImage, 0, NULL, NULL);
#endif
// Write the filter to the device
clEnqueueWriteBuffer(queue, d_filter, CL_TRUE, 0,
49*sizeof(float), filter, 0, NULL, NULL);
// Read in the program from file
char* source = readSource("convolution.cl");
// Create the program
cl_program program;
// Create and compile the program
program = clCreateProgramWithSource(context, 1,
(const char**)&source, NULL, NULL);
cl_int build_status;
build_status = clBuildProgram(program, 1, &device, NULL, NULL,
NULL);
// Create the kernel
cl_kernel kernel;
#if defined NON_OPTIMIZED || defined READ_ALIGNED
// Only the host-side code differs for the aligned reads
kernel = clCreateKernel(program, "convolution", NULL);
#endif
// Selected workgroup size is 16x16
int wgWidth = WGX;
int wgHeight = WGY;
// When computing the total number of work-items, the
// padding work-items do not need to be considered
int totalWorkItemsX = roundUp(imageWidth-paddingPixels,
wgWidth);
int totalWorkItemsY = roundUp(imageHeight-paddingPixels,
wgHeight);
// Size of a workgroup
size_t localSize[2] = {wgWidth, wgHeight};
// Size of the NDRange
size_t globalSize[2] = {totalWorkItemsX, totalWorkItemsY};
// The amount of local data that is cached is the size of the
// workgroups plus the padding pixels
#if defined NON_OPTIMIZED || defined READ_ALIGNED
int localWidth = localSize[0] + paddingPixels;
#else // READ4
// Round the local width up to 4 for the read4 kernel
int localWidth = roundUp(localSize[0]+paddingPixels, 4);
#endif
int localHeight = localSize[1] + paddingPixels;
// Compute the size of local memory (needed for dynamic
// allocation)
size_t localMemSize = (localWidth * localHeight *
sizeof(float));
// Set the kernel arguments
clSetKernelArg(kernel, 0, sizeof(cl_mem), &d_inputImage);
clSetKernelArg(kernel, 1, sizeof(cl_mem), &d_outputImage);
clSetKernelArg(kernel, 2, sizeof(cl_mem), &d_filter);
clSetKernelArg(kernel, 3, sizeof(int), &deviceHeight);
clSetKernelArg(kernel, 4, sizeof(int), &deviceWidth);
clSetKernelArg(kernel, 5, sizeof(int), &filterWidth);
clSetKernelArg(kernel, 6, localMemSize, NULL);
clSetKernelArg(kernel, 7, sizeof(int), &localHeight);
clSetKernelArg(kernel, 8, sizeof(int), &localWidth);
// Execute the kernel
clEnqueueNDRangeKernel(queue, kernel, 2, NULL, globalSize,
localSize, 0, NULL, NULL);
// Wait for kernel to complete
// Read back the output image
#ifdef NON_OPTIMIZED
clEnqueueReadBuffer(queue, d_outputImage, CL_TRUE, 0,
deviceDataSize, outputImage, 0, NULL, NULL);
#else // READ_ALIGNED || READ4
// Begin reading output from (3,3) on the device
// (for 7x7 filter with radius 3)
buffer_origin[0] = 3*sizeof(float);
buffer_origin[1] = 3;
buffer_origin[2] = 0;
// Read data into (3,3) on the host
host_origin[0] = 3*sizeof(float);
host_origin[1] = 3;
host_origin[2] = 0;
// Region is image size minus padding pixels
region[0] = (imageWidth-paddingPixels)*sizeof(float);
region[1] = (imageHeight-paddingPixels);
region[2] = 1;
// Perform the read
clEnqueueReadBufferRect(queue, d_outputImage, CL_TRUE,
buffer_origin, host_origin, region,
deviceWidth*sizeof(float), 0, imageWidth*sizeof(float), 0,
outputImage, 0, NULL, NULL);
#endif
// Homegrown function to write the image to file
storeImage(outputImage, "output.bmp", imageHeight,
imageWidth);
// Free OpenCL objects
clReleaseMemObject(d_inputImage);
clReleaseMemObject(d_outputImage);
clReleaseMemObject(d_filter);
clReleaseKernel(kernel);
clReleaseProgram(program);
clReleaseCommandQueue(queue);
clReleaseContext(context);
return 0;
}
Kernel Code
__kernel
void convolution(__global float* imageIn,
__global float* imageOut,
int rows,
int cols,
int filterWidth,
__local float* localImage,
int localHeight,
int localWidth) {
// Determine the amount of padding for this filter
int filterRadius = (filterWidth/2);
int padding = filterRadius * 2;
// Determine the size of the workgroup output region
int groupStartCol = get_group_id(0)*get_local_size(0);
int groupStartRow = get_group_id(1)*get_local_size(1);
// Determine the local ID of each work-item
int localCol = get_local_id(0);
int localRow = get_local_id(1);
// Determine the global ID of each work-item. work-items
// representing the output region will have a unique global
// ID
int globalCol = groupStartCol + localCol;
int globalRow = groupStartRow + localRow;
// Cache the data to local memory
// Step down rows
for(int i = localRow; i < localHeight; i +=
get_local_size(1)) {
int curRow = groupStartRow+i;
// Step across columns
for(int j = localCol; j < localWidth; j +=
get_local_size(0)) {
int curCol = groupStartCol+j;
// Perform the read if it is in bounds
if(curRow < rows && curCol < cols) {
localImage[i*localWidth + j] =
imageIn[curRow*cols+curCol];
}
}
}
barrier(CLK_LOCAL_MEM_FENCE);
// Perform the convolution
if(globalRow < rows-padding && globalCol < cols-padding) {
// Each work-item will filter around its start location
float sum = 0.0f;
int filterIdx = 0;
// Not unrolled
for(int i = localRow; i < localRow+filterWidth; i++) {
int offset = i*localWidth;
for(int j = localCol; j < localCol+filterWidth; j++){
sum += localImage[offset+j] *
filter[filterIdx++];
}
}
/*
// Inner loop unrolled
for(int i = localRow; i < localRow+filterWidth; i++) {
int offset = i*localWidth+localCol;
sum += localImage[offset++] * filter[filterIdx++];
sum += localImage[offset++] * filter[filterIdx++];
sum += localImage[offset++] * filter[filterIdx++];
sum += localImage[offset++] * filter[filterIdx++];
sum += localImage[offset++] * filter[filterIdx++];
sum += localImage[offset++] * filter[filterIdx++];
sum += localImage[offset++] * filter[filterIdx++];
}
*/
// Write the data out
imageOut[(globalRow+filterRadius)*cols +
(globalCol+filterRadius)] = sum;
}
return;
}
__kernel
void convolution_read4(__global float4* imageIn,
__global float* imageOut,
__constant float* filter,
int rows,
int cols,
int filterWidth,
__local float* localImage,
int localHeight,
int localWidth) {
// Vector pointer that will be used to cache data
// scalar memory
__local float4* localImage4;
// Determine the amount of padding for this filter
int filterRadius = (filterWidth/2);
int padding = filterRadius * 2;
int groupStartCol = get_group_id(0)*get_local_size(0)/4;
int groupStartRow = get_group_id(1)*get_local_size(1);
// Flatten the localIds 0-255
int localId = get_local_id(1)*get_local_size(0) +
get_local_id(0);
// There will be localWidth/4 work-items reading per row
int localRow = (localId / (localWidth/4));
// Each work-item is reading 4 elements apart
int localCol = (localId % (localWidth/4));
// Determine the row and column offset in global memory
// assuming each element reads 4 floats
int globalRow = groupStartRow + localRow;
int globalCol = groupStartCol + localCol;
// Set the vector pointer to the correct scalar location
// in local memory
localImage4 = (__local float4*)
&localImage[localRow*localWidth+localCol*4];
// Perform all of the reads with a single load
if(globalRow < rows && globalCol < cols/4 &&
localRow < localHeight) {
localImage4[0] = imageIn[globalRow*cols/4+globalCol];
}
barrier(CLK_LOCAL_MEM_FENCE);
// Reassign local IDs based on each work-item processing
// one output element
localCol = get_local_id(0);
localRow = get_local_id(1);
// Reassign global IDs for unique output locations
globalCol = get_group_id(0)*get_local_size(0) + localCol;
globalRow = get_group_id(1)*get_local_size(1) + localRow;
// Perform the convolution
if(globalRow < rows-padding && globalCol < cols-padding) {
// Each work-item will filter around its start location
// (starting from half the filter size left and up)
float sum = 0.0f;
int filterIdx = 0;
// Not unrolled
for(int i = localRow; i < localRow+filterWidth; i++) {
int offset = i*localWidth;
for(int j = localCol; j < localCol+filterWidth; j++){
sum += localImage[offset+j] *
filter[filterIdx++];
}
}
/*
for(int i = localRow; i < localRow+filterWidth; i++) {
int offset = i*localWidth+localCol;
sum += localImage[offset++] * filter[filterIdx++];
sum += localImage[offset++] * filter[filterIdx++];
sum += localImage[offset++] * filter[filterIdx++];
sum += localImage[offset++] * filter[filterIdx++];
sum += localImage[offset++] * filter[filterIdx++];
sum += localImage[offset++] * filter[filterIdx++];
sum += localImage[offset++] * filter[filterIdx++];
}
*/
/*
// Completely unrolled
int offset = localRow*localWidth+localCol;
sum += localImage[offset+0] * filter[filterIdx++];
sum += localImage[offset+1] * filter[filterIdx++];
sum += localImage[offset+2] * filter[filterIdx++];
sum += localImage[offset+3] * filter[filterIdx++];
sum += localImage[offset+4] * filter[filterIdx++];
sum += localImage[offset+5] * filter[filterIdx++];
sum += localImage[offset+6] * filter[filterIdx++];
offset += localWidth;
sum += localImage[offset+0] * filter[filterIdx++];
sum += localImage[offset+1] * filter[filterIdx++];
sum += localImage[offset+2] * filter[filterIdx++];
sum += localImage[offset+3] * filter[filterIdx++];
sum += localImage[offset+4] * filter[filterIdx++];
sum += localImage[offset+5] * filter[filterIdx++];
sum += localImage[offset+6] * filter[filterIdx++];
offset += localWidth;
sum += localImage[offset+0] * filter[filterIdx++];
sum += localImage[offset+1] * filter[filterIdx++];
sum += localImage[offset+2] * filter[filterIdx++];
sum += localImage[offset+3] * filter[filterIdx++];
sum += localImage[offset+4] * filter[filterIdx++];
sum += localImage[offset+5] * filter[filterIdx++];
sum += localImage[offset+6] * filter[filterIdx++];
offset += localWidth;
sum += localImage[offset+0] * filter[filterIdx++];
sum += localImage[offset+1] * filter[filterIdx++];
sum += localImage[offset+2] * filter[filterIdx++];
sum += localImage[offset+3] * filter[filterIdx++];
sum += localImage[offset+5] * filter[filterIdx++];
sum += localImage[offset+6] * filter[filterIdx++];
offset += localWidth;
sum += localImage[offset+0] * filter[filterIdx++];
sum += localImage[offset+1] * filter[filterIdx++];
sum += localImage[offset+2] * filter[filterIdx++];
sum += localImage[offset+3] * filter[filterIdx++];
sum += localImage[offset+4] * filter[filterIdx++];
sum += localImage[offset+5] * filter[filterIdx++];
sum += localImage[offset+6] * filter[filterIdx++];
offset += localWidth;
sum += localImage[offset+0] * filter[filterIdx++];
sum += localImage[offset+1] * filter[filterIdx++];
sum += localImage[offset+2] * filter[filterIdx++];
sum += localImage[offset+3] * filter[filterIdx++];
sum += localImage[offset+4] * filter[filterIdx++];
sum += localImage[offset+5] * filter[filterIdx++];
sum += localImage[offset+6] * filter[filterIdx++];
offset += localWidth;
sum += localImage[offset+0] * filter[filterIdx++];
sum += localImage[offset+1] * filter[filterIdx++];
sum += localImage[offset+2] * filter[filterIdx++];
sum += localImage[offset+3] * filter[filterIdx++];
sum += localImage[offset+4] * filter[filterIdx++];
sum += localImage[offset+5] * filter[filterIdx++];
sum += localImage[offset+6] * filter[filterIdx++];
*/
// Write the data out
imageOut[(globalRow+filterRadius)*cols +
(globalCol+filterRadius)] = sum;
}
return;
}
Reference
NVIDIA Corporation. (2009). NVIDIA OpenCL Programming Guide for the CUDA Architecture. (2009) NVIDIA Corporation, Santa Clara, CA.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.