
Chapter 5. Event-level Data and Differential Privacy
In 2006, AOL released an anonymized data set of search activity from its service. This sample contained 20 million queries made by more than 650,000 users over 3 months. Although the usernames were obfuscated, many of the search queries themselves contained personally-identifiable information. This resulted in several users being identified and matched to their account and search history. 1
This release led to the resignation of two senior staff members and a class action lawsuit that was settled in 2013. It also caused enormous harm to AOL’s public image, and exposed the identities of real people who were using the service with the assumption that their privacy would be protected.
The AOL release is an example of an event-level database, where each row represents an action, and an individual may contribute to multiple rows. Privatizing such databases requires different approaches than the databases we have so far encountered.
This example demonstrates that you need to be careful when dealing with event-level data. The privacy leak could have been avoided with differential privacy, but not in the way you’ve been using it. Why not? Previous chapters have considered scenarios where each row in a dataset represents a unique individual. This chapter shows how database characteristics affect differential privacy and how to adapt the concepts introduced so far to different database types. Differentially private values always rely on the concept of neighboring databases. Up until now, the neighboring databases have each differed by one row that represents a single individual.
What happens when a database contains multiple rows that correspond to a single individual? This is common in many practical scenarios, such as hospital visit databases, network log databases, and others. In such cases, a straightforward application of the concept of neighboring databases and function sensitivity used in the previous chapters won’t provide differential privacy guarantees.
This chapter explores the differences between user-level and event-level databases and the differences faced when designing a differential privacy project on an event-level database.
By the end of this chapter, you should:
-
Understand the main differences between user-level databases and event-level databases
-
Be able to define neighboring databases for event-level databases
-
Be able to define function sensitivity when applying functions to event-level databases
-
Understand the process of clamping events in an event-level database using reservoir sampling
-
Understand the process of optimizing Database clamping in event-level databases
-
Understand
User-level Databases and Event-level Databases
A user-level database is a database where each row in the database represents an individual. For example, the student database from chapter 3 is an example of a user-level database, where each row represents a student.
- User-level database
-
A user-level database is a database where each row corresponds to a unique individual in a database. For such databases, neighboring databases are understood as databases that differ by a single row.
Now suppose there is a database where each row corresponds to a test taken by a student. Since a student can take multiple tests in a year, each student can appear in multiple rows. In this case, each row corresponds to a test rather than a student. Each row uniquely corresponds to an event: a student taking a single test.
- Event-level databased
-
Event-level database is a database where a single individual can contribute multiple events. Usually, each row in the database corresponds to a single event. For this type of database, neighboring databases are understood as databases that differ by a single individual. In event-level databases a single individual can be represented by a fixed number of rows, or by a variable number of rows.
Applying DP to Event-level Databases: A Naive Approach
Given that multiple rows in an event-level database can correspond to a single user, it is reasonable to conclude that user-level and event-level data must be treated differently in order to guarantee differential privacy. Let’s see an example of a differentially private data release that utilizes an event-level database to compute differentially private aggregates. In this example, the employment of differential privacy will follow a naive approach to an event-level problem. This example should help you understand the importance of understanding the nature of the dataset.
Suppose a data scientist wants to release the visit count to four websites. They have access to the following dataset that contains browser logs of 1234 employees of a company, from August to December 2020. Sample of the data:
| Employee Id | Date | Time | Domain |
|---|---|---|---|
872 | 08-01-2020 | 12:00 | mail.com |
867 | 10-01-2020 | 11:00 | games.com |
934 | 11-01-2020 | 08:00 | social.com |
872 | 09-15-2020 | 17:00 | social.com |
867 | 11-13-2020 | 05:00 | mail.com |
014 | 10-27-2020 | 13:00 | social.com |
In this database, each row represents an event described by the following fields:
-
Employee Id,
-
date of the event,
-
time the event occurred, and
-
the address of the domain visited.
The data scientist needs to compute a differentially private count of visits to each of the following websites:
-
mail.com,
-
bank.com,
-
social.com,
-
games.com
in each of the following months:
-
August,
-
September,
-
October,
-
November,
-
December
To proceed with the task, the data scientist naively sets the sensitivity of the COUNT query to 1 and starts making queries to the database to get the counts of visits to each website per month.
The data scientist uses the Laplace mechanism to privatize the count.
Let’s set the budget of the data release to
The data scientist proceeds to make the queries and budget calculations
the same way as they would if he had been using a user-level database. If the same budget is spent on each query,
each query will require
| August | September | October | November | December | |
|---|---|---|---|---|---|
bank.com | 32465 | 32687 | 32495 | 32406 | 32879 |
games.com | 346 | 398 | 412 | 32 | 41 |
mail.com | 70567 | 73640 | 72857 | 71948 | 71954 |
social.com | 2305 | 1726 | 2126 | 0 | 0 |
When visit counts are released, the data scientist notices a significant drop in the number of visits from October to November for games.com and social.com. If you knew your co-worker took a leave of absence during this time, then you could surmise your co-worker’s browsing habits, even though the data scientist made a release utilizing the Laplace mechanism, i.e. with noise added.
Could it be a coincidence, or is the data release actually releasing more information than it should about an employee? How did this happen if the data scientist used differential privacy in a data release?
Privacy Issues When Using the Naive Approach
Let’s understand why this happened.
According to the definition of
So what is happening here? Why is it so easy to identify the contributions of an individual user? The problem is that the distance between neighboring datasets is unbounded when we have event-level data.
You can see in this example that a user contributes to multiple rows, so we will need to bound the distance between the databases. Because of this we will need to use another metric to measure the distance between two databases and calibrate the differential privacy mechanism accordingly.
Defining “Neighboring”: Event-level Databases
So far we’ve defined two datasets as neighboring if their distance is 1. However, for event-level datasets, that definition does not apply! We need a more general notion of adjacency to take into account that one individual can affect multiple rows in the data.
- Neighboring event-level databases
-
For two event-level datasets
In English, this just says the distance between datasets must be less than k!
Note
Note that the core concept is still the same as you saw in Chapter 2. Neighboring databases still differ by a single individual. However, in an event-level dataset, an individual may appear in multiple rows, so the distance between the two datasets can be greater than 1.
Yet Another Classroom Example: 2 Tests Are Better than One
Let’s imagine another classroom scenario, where you’ve taken 2 tests so far this semester, and the teacher has a dataset of each student’s scores on both of the tests. This means that each student will contribute no more than 2 rows to the database.
Name | Score |
test 1 | 100 |
test 1 | 95 |
test 2 | 85 |
test 2 | 86 |
test 3 | 79 |
test 3 | 81 |
test 4 | 74 |
test 4 | 72 |
test 5 | 90 |
test 5 | 92 |
test 6 | 85 |
test 6 | 88 |
test 7 | 90 |
test 7 | 82 |
test 8 | 83 |
test 8 | 90 |
test 9 | 42 |
test 9 | 48 |
test 10 | 88 |
test 10 | 92 |
Now if one student (say, student 10) drops the class, the data set loses 2 rows instead of 1. This is still “neighboring” because it differs by one individual, but that individual contributed 2 rows to the dataset:
Name | Score |
test 1 | 100 |
test 1 | 95 |
test 2 | 85 |
test 2 | 86 |
test 3 | 79 |
test 3 | 81 |
test 4 | 74 |
test 4 | 72 |
test 5 | 90 |
test 5 | 92 |
test 6 | 85 |
test 6 | 88 |
test 7 | 90 |
test 7 | 82 |
test 8 | 83 |
test 8 | 90 |
test 9 | 42 |
test 9 | 48 |
Using the definition of k-neighboring from above, you can define a metric M that returns the number of non-identical
rows between two datasets X and Y.
Formally: for the ith row,
If you let
Name | Scores (Before) | Scores (After) | Difference |
test 1 | 100 | 100 | 0 |
test 1 | 95 | 95 | 0 |
test 2 | 85 | 85 | 0 |
test 2 | 86 | 86 | 0 |
test 3 | 79 | 79 | 0 |
test 3 | 81 | 81 | 0 |
test 4 | 74 | 74 | 0 |
test 4 | 72 | 72 | 0 |
test 5 | 90 | 90 | 0 |
test 5 | 92 | 92 | 0 |
test 6 | 85 | 85 | 0 |
test 6 | 88 | 88 | 0 |
test 7 | 90 | 90 | 0 |
test 7 | 82 | 82 | 0 |
test 8 | 83 | 83 | 0 |
test 8 | 90 | 90 | 0 |
test 9 | 42 | 42 | 0 |
test 9 | 48 | 48 | 0 |
test 10 | 88 | NULL | 1 |
test 10 | 92 | NULL | 1 |
Summing the values of
fromcollectionsimportCounterdefd_Sym(u,v):"""symmetric distance between u and v"""# NOT this, as sets are not multisets. Loses multiplicity:# return len(set(u).symmetric_difference(set(v)))u_counter,v_counter=Counter(u),Counter(v)# indirectly compute symmetric difference via the union of asymmetric differencesreturnsum(((u_counter-v_counter)+(v_counter-u_counter)).values())# consider two simple example datasets, u and v# [Jane, Joe, John, Jack, Alice]u=[1,1,2,3,4]# [Jane, Joe, John, Jack] (without Alice!)v=[1,1,2,3]# compute the symmetric distance between these two example datasets:d_Sym(u,v)
Defining Sensitivity: Event-level Databases
In an event-level database, multiple rows may correspond to the actions of a single user. The key is to understand exactly how many rows correspond to each individual.
Let’s say that, in the browser logs example, due to company restrictions, an employee can only make 10 website visits a day. For simplicity, we will consider a dataset consisting of 150 days (5 months). This means that the maximum number of website visits an employee can contribute to the dataset is 1,500. See the exercises at the end of this chapter for more generalizations.
As we’ve already mentioned, the dataset distance is the maximum number of rows that a single user can contribute. It is necessary to consider the dataset distance when calculating the sensitivity.
- Sensitivity on event-level databases
-
For two event-level datasets X and Y that are “k-neighboring”, we say that our function
In English, this just says the greatest amount that the function may change is
Notice that as
In the browser logs example, the data scientist makes
Given two neighboring databases,
Now that the data scientist knows that the sensitivity of
The resulting differentially-private data release looks like this:
| August | September | October | November | December | |
|---|---|---|---|---|---|
bank.com | 1421003 | 806110 | 1180930 | 2127025 | 2818066 |
games.com | 0 | 0 | 2344329 | 312941 | 805690 |
mail.com | 961078 | 449405 | 358651 | 7117039 | 1219565 |
social.com | 343344 | 715161 | 0 | 5045865 | 0 |
From the data release, it is hard to know that employee #789 is an outlier when visiting websites. This is what differential privacy should do - mask the presence/absence of any individual in a database.
This example demonstrates how to properly calibrate sensitivity when we know a bound on the distance between neighboring datasets.
What happens when we don’t have a bound on the distance, that is, when the number of events an individual can contribute is unknown or unlimited? In the next example, we will see how to deal with datasets with unknown or unlimited number of events.
Datasets with Unbounded Number of Events per User
When the distance between datasets is unbounded, the sensitivity is also unbounded. We need a finite sensitivity to establish privacy guarantees.
Therefore, in the case of datasets with an unbounded number of events it becomes difficult, or even impossible, to define sensitivity for many functions due to the unbounded number of rows a user might appear in.
Let
Methods for Bounding the Number of Events
We will discuss two different approaches for creating the subset of number of events, and its advantages and disadvantages.
- Keep first (or last)
-
Using the timestamp as a filtering condition is a simple and efficient method for selecting a subset of events for a user. However, this kind of event selection might result in a set of events that does not accurately represent the complete picture of what happens in reality. In the browsing logs database, suppose a data scientist wants to limit the number of events per user, and decides to keep only the first 5 events that happens in each day. Suppose further that there is a common behavioral pattern at the company where for 95% of employees, the first 4 browser visits are always to mail.com. Choosing events based on the time stamp would create a bias towards mail.com, and most likely, a data analysis made using the data could lead to incorrect conclusions.
- Sample
-
As mentioned before, using the timestamp to select events in a database can result in selection bias. Reservoir sampling is randomized algorithm for selecting
# to randomly select k items from a stream of itemsimportrandomdefreservoir_sampling(stream,k):"""randomly select k items from stream [0..n-1]"""i=0# index of events in user event stream[]reservoir=[0]*kwhilei<len(stream):# Pick a random index from 0 to i.j=random.randrange(i+1)# If the random value j is smaller than k,# replace the element present at the index j# with new element from streamifj<k:reservoir[j]=stream[i]i+=1returnreservoir
To illustrate how reservoir sampling works, let’s imagine you want to sample 10 items from the set
i | j | reservoir |
0 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] | |
1 | 0 | [1, 0, 0, 0, 0, 0, 0, 0, 0, 0] |
2 | 1 | [1, 2, 0, 0, 0, 0, 0, 0, 0, 0] |
3 | 1 | [1, 3, 0, 0, 0, 0, 0, 0, 0, 0] |
4 | 11 | [1, 3, 0, 0, 0, 0, 0, 0, 0, 0] |
5 | 3 | [1, 3, 0, 4, 0, 0, 0, 0, 0, 0] |
6 | 1 | [1, 5, 0, 4, 0, 0, 0, 0, 0, 0] |
7 | 2 | [1, 5, 6, 4, 0, 0, 0, 0, 0, 0] |
8 | 4 | [1, 5, 6, 4, 7, 0, 0, 0, 0, 0] |
9 | 1 | [1, 8, 6, 4, 7, 0, 0, 0, 0, 0] |
10 | 9 | [1, 8, 6, 4, 7, 0, 0, 0, 0, 9] |
Notice that the reservoir is not updated on iteration 4, since 11 > 10. As the algorithm progresses, it begins to sample values from across the stream (in this case, closer to 1000), and the random value j is more likely to be greater than k, meaning that the reservoir is updated less often:
i | j | reservoir |
71 | 99 | [1, 69, 47, 4, 46, 31, 55, 32, 34, 54] |
72 | 3 | [1, 69, 47, 71, 46, 31, 55, 32, 34, 54] |
…. | …. | …. |
99 | 24 | [87, 69, 47, 71, 46, 31, 93, 32, 80, 54] |
100 | 45 | [87, 69, 47, 71, 46, 31, 93, 32, 80, 54] |
…. | …. | …. |
107 | 101 | [87, 69, 47, 71, 46, 31, 93, 32, 80, 54] |
108 | 7 | [87, 69, 47, 71, 46, 31, 93, 107, 80, 54] |
…. | …. | …. |
643 | 425 | [87, 543, 146, 323, 582, 616, 172, 367, 594, 370] |
644 | 0 | [643, 543, 146, 323, 582, 616, 172, 367, 594, 370] |
…. | …. | …. |
825 | 524 | [643, 543, 146, 323, 582, 616, 172, 800, 594, 370] |
826 | 2 | [643, 543, 825, 323, 582, 616, 172, 800, 594, 370] |
…. | …. | …. |
915 | 856 | [643, 543, 825, 323, 582, 616, 172, 800, 594, 370] |
916 | 2 | [643, 543, 915, 323, 582, 616, 172, 800, 594, 370] |
Tip
Using reservoir sampling, you’ve just returned a uniform sample of size k from the data in the stream. Reservoir sampling is a common choice for bounding a user’s contribution in a sequestered dataset.
Defining the Bound on the Number of Events
The previous section showed how to pre-process an event-level dataset with unbounded number of events and calculate sensitivity for different functions applied to event-level data.
Assume the data scientist has a threshold
The choice of threshold
The true distribution of the data.
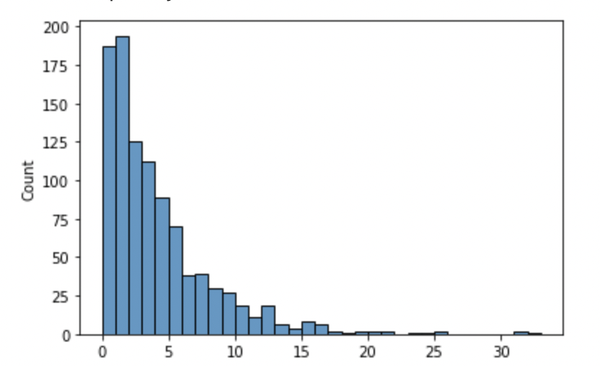
Figure 5-1. Hospital visits per patient without bounding user contribution.
In the original data, without bounding user contribution, the mean number of visits per patient is 2.62 visits, the median is 2 visits, and the total number of visits is 5247. However, we need to set a bound on user contribution so that we can compute the sensitivity of functions we apply to the database. In the original data, the maximum number of visits a patient has is 35. If we decide to make a simple differentially private count query of all visits to the hospital, the sensitivity of the count query is 35. The SmartNoise library can be used to make this query.
importpandasaspdimportsnsqlfromsnsqlimportPrivacyvisits=pd.read_csv('visits.csv')# This is a filename which will be read in `from_connection`metadata='metadata.yml'privacy=Privacy(epsilon=1.0)reader=snsql.from_connection(visits,privacy=privacy,metadata=metadata)total_visits=reader.execute('''SELECT SUM(visits) as TotalVisitsFROM HospitalRecords.Visits''')avg_visits=reader.execute('''SELECT AVG(visits) as AverageVisitsFROM HospitalRecords.Visits''')(total_visits)[['TotalVisits'],[5275]](avg_visits)[['AverageVisits'],[2.623022731761945]]
In the case where a data scientist needs to make a decision on the bound k, let’s see the different outcomes between choosing a high versus a low threshold.
Case 1: Low threshold.
Suppose the data scientist chooses a threshold
The Laplace distribution from which the noise for the
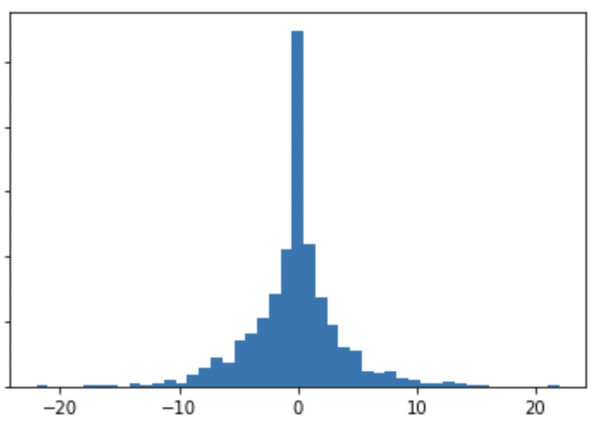
Figure 5-2. Laplace distribution used in differential privacy mechanism for counting hospital visits: bounding user contribution to 3 hospital visits.
Let’s further analyze if it is a good solution to lower the threshold more. The data scientist starts by preprocessing the data, such that each user can have at most 3 hospital visits. The visits from each user are sampled according to some sampling rule, e.g. reservoir sampling. After the data preprocessing, the data has a new distribution.
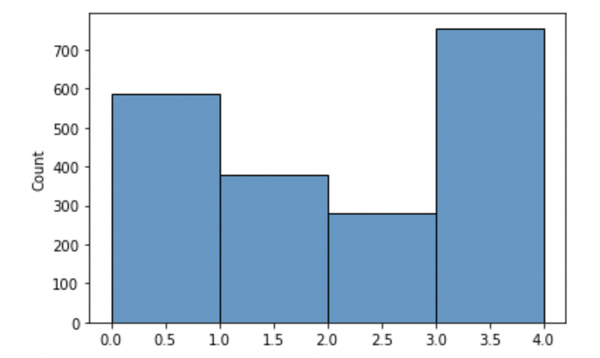
Figure 5-3. Distribution of hospital visits per patient bounding user contribution to 3 hospital visits.
Lowering the bound on the user contribution results in less noise from the Laplace distribution. However, applying this bound can change the data such that the results are compromised. Using the SmartNoise library to make the same queries as before:
importpandasaspdimportsnsqlfromsnsqlimportPrivacyvisits=pd.read_csv('visits.csv')metadata='metadata.yml'#Calculating the differentially private count of# all visits and the average number of visits per patientprivacy=Privacy(epsilon=1.0)reader=snsql.from_connection(visits,privacy=privacy,metadata=metadata)total_visits=reader.execute('''SELECT SUM(Visits) as TotalVisitsFROM HospitalRecords.Visits''')avg_visits=reader.execute('''SELECT AVG(Visits) as AverageVisitsFROM HospitalRecords.Visits''')(total_visits)[['TotalVisits'],[3205]](avg_visits)[['AverageVisits'],[1.6016713415567314]]
As we can see from the case above, the data scientist set the user contribution threshold too low and changed the data distribution to the point that the results were no longer meaningful.
Let’s see what happens when the threshold is high:
Case 2: High threshold
Now suppose the data scientist chooses a threshold k = 500. A high threshold makes the possible contribution of each user higher. Instead of the addition or subtraction of a user impacting 33 rows, now it can impact up to 500 rows. In the case of COUNT queries, by setting the bound to the user contribution to 500 rows, the sensitivity changes from 33 to 500.
The Laplace distribution from which the noise for the
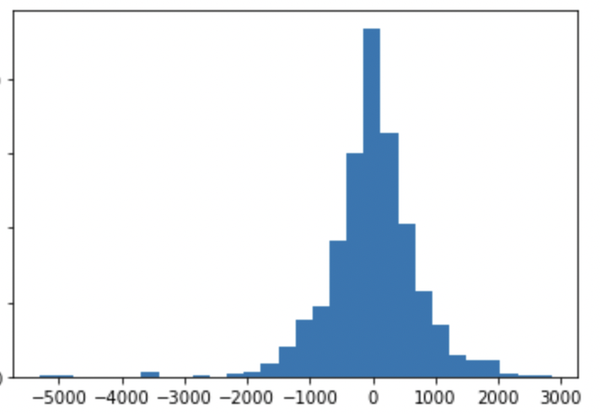
Figure 5-4. Laplace distribution used in differential privacy mechanism for counting hospital visits: bounding user contribution to 500 hospital visits.
The following code uses the SmartNoise library to make the same queries as the previous example. The adjusted sensitivity accounts for up to 500 rows per user:
importpandasaspdimportsnsqlfromsnsqlimportPrivacyvisits=pd.read_csv('visits.csv')metadata_high='metadata_high.yml'privacy=Privacy(epsilon=1.0)reader=snsql.from_connection(visits,privacy=privacy,metadata=metadata_high)total_visits=reader.execute('''SELECT SUM(visits) as TotalVisitsFROM HospitalRecords.Visits''')avg_visits=reader.execute('''SELECT AVG(visits) as AverageVisitsFROM HospitalRecords.Visits''')(total_visits)[['TotalVisits'],[4334]](avg_visits)[['AverageVisits'],[2.254073722721487]]
From these examples we see that the choice of k heavily impacts utility. In many cases, finding an optimal k when the data distribution is unknown might require additional differentially private analyses. We will see more about this in the following section.
Making Queries to a Database of Browser Visits to Top 500 Domains
Consider the example where a data scientist has access to a database with one week of browser logs. The dataset contains over 9000 users and has the following columns:
| ID | Day | Domain |
|---|---|---|
9015 | Thursday | netflix.com |
5647 | Monday | update.googleapis.com |
8592 | Tuesday | office.net |
6826 | Wednesday | prod.ftl.netflix.com |
4571 | Wednesday | itunes.apple.com |
(This dataset was generated by the authors for educational purposes. The code to generate the dataset can be found in the Hands-on Differential Privacy GitHub. The domains used in this dataset were obtained using Cisco’s DNS list 2)
The data scientist needs to answer the following questions:
-
Which are the top 5 most-visited domains?
-
How many visits are there to the top 5 domains?
-
How many visits are there for each day of the week?
Since the data scientist does not know the optimal k for bounding the number of events, a natural process would be testing different values of k and selecting the best k based on a metric chosen by the data scientist.
Suppose the data scientist wants to find the k that will give the best utility for the counts of visits per user. Doing so in a non-privacy preserving manner would consist in looking at the distribution of events per user and choosing a k that would include 90% or 95% of events.
However, this process is not differentially private. In this case, the data scientist reveals the number of events in the 95th or 90th percentiles.
One way to make the above analysis differentially private is to use part of the privacy budget (we will talk more about
this in Chapter 6) to generate a differentially private histogram of the number of events.
The data scientist can use a small
For the browsing logs dataset, let’s choose k = 50 visits. To make this preliminary analysis, the data scientist will bound each individual in the dataset to 50 visits.
The data scientist has no information about the data distribution. To make this analysis, instead of generating a histogram of all possible values of number of visits, they will create categories of event ranges.
Tip
When creating histograms for data exploration, the more individuals there is in a histogram bin, the less distorted the differentially private histogram will be.
fromimportlib.metadataimportmetadataimportpandasaspdfromsnsqlimportPrivacy,from_dffromsnsql.sql._mechanisms.baseimportMechanismfromsnsql.sql.privacyimportStatbudget=0.5k=50eps=budget/kmetadata='events.yaml'privacy=Privacy(epsilon=eps)reader=from_df(df,privacy=privacy,metadata=metadata)query='''SELECT Events, COUNT(Events) AS eFROM MySchema.MyTable GROUP BY Events'''privacy.mechanisms.map[Stat.count]=Mechanism.laplace("Running query with Laplace mechanism for count:")(privacy.mechanisms.map[Stat.count])res=reader.execute_df(query)(res)
The code returns following output:
Running query with Laplace mechanism for count:
Mechanism.laplace
Events e
0 0 - 10 273449
1 10 - 20 118348
2 20 - 30 43548
3 30 - 40 15783
4 40 - 50 5960Based on this differentially private analysis,
But how good are these estimates?
Let’s take a look into the real numbers, and see how close this analysis is to the real values:
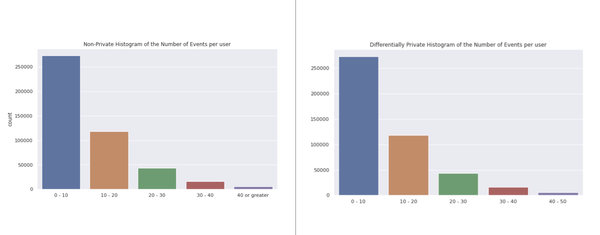
Figure 5-5. Histogram of number of events per user. On the x-axis, number of events (categories). On the y-axis, counts of users that fall into those categories. On the Left, differentially private histogram generated as described above. On the right, histogram with true values.
At first glance, it is easy to notice that the distribution of events per user is very similar. Even though the maximum number of events in the non-private data is greater than 50, choosing 50 as the maximum number of events did not create a bias in the data. The non-private data has 134 as the maximum number of events for a single user.
When looking at quantiles on the non-private data, 92% of users have less than 26 events and 98% of users have less
than 40 events.
This shows that histogram analysis, even with a small
Now that the scientist has an understanding of the distribution of events per user in the dataset, they can now sample the events per user.
Using reservoir sampling and k = 40:
importpandasaspdimportnumpyasnpimportrandomk=40df=pd.read_csv('data/user_visits.csv')# Code for generating the user_visits dataset will be available# at the Hands-on Differential Privacy GitHubdefreservoir_sampling(stream,k):"""randomly select k items from stream [0..n-1]"""i=0# index of events in user event stream[]reservoir=[0]*kwhilei<len(stream):# Pick a random index from 0 to i.j=random.randrange(i+1)# If the random value j is smaller than k,# replace the element present at the index j# with new element from streamifj<k:reservoir[j]=stream[i]i+=1returnreservoirforiinset(df.ids):iflen(df[df.ids==i])<=k:continueelse:indexes=list(df[df.ids==i].index)sample_ids=reservoir_sampling(indexes,k)drop_ids=list(set(indexes)-set(sample_ids))df=df.drop(drop_ids)
Now that the data has a bounded number of events per individual, making the following queries to the data should be straightforward, since sensitivity can now be easily calculated:
1- Which are the visited domains? 2- How many visits are there to each domain? 3- Average visits per user for each day of the week?
In the above analysis, the data scientist needs to guarantee that the bound k = 40 is accounted for in the sensitivity of all queries.
In the first query, we are interested in the top 5 most-visited domains.
As seen in chapter 4, the exponential mechanism is an
The most visited domains in the dataset can be identified by generating a differentially private histogram with the Laplace Mechanism. Due to the tightly bound L1 distance on a vector-valued count query, this kind of mechanism achieves optimal utility.
In the case of the browser logs event-level database, the L1 distance between two count vectors from adjacent databases is at most 40. When querying the counts of visits to each domain using the SmartNoise sql library, we adjust the epsilon in order to account for the database distance.
1fromimportlib.metadataimportmetadata2importpandasaspd3fromsnsqlimportPrivacy,from_df4fromsnsql.sql._mechanisms.baseimportMechanism5fromsnsql.sql.privacyimportStat6 7epsilon=2.08 9k=4010 11adjusted_eps=epsilon/k12 13metadata='domain.yaml'14privacy=Privacy(epsilon=epsilon)15reader=from_df(df,privacy=privacy,metadata=metadata)16 17query='''SELECT domain, COUNT(domain) AS DomainVisits18FROM MySchema.MyTable19GROUP BY domain'''20 21privacy.mechanisms.map[Stat.count]=Mechanism.laplace22("Running query with Laplace mechanism for count:")23(privacy.mechanisms.map[Stat.count])24res=reader.execute_df(query)25(res.sort_values(by='DomainVisits',ascending=False))
The resulting visit count for each domain is:
Running query with Laplace mechanism for count:
Mechanism.laplace
domain DomainVisits
18 windowsupdate.com 3754
19 www.google.com 3698
8 microsoft.com 3667
2 data.microsoft.com 3646
0 api-global.netflix.com 3612
10 netflix.com 3599
5 google.com 3590
3 events.data.microsoft.com 3586
4 ftl.netflix.com 3534
14 prod.ftl.netflix.com 3522
7 live.com 1078
9 microsoftonline.com 1026
12 partner.netflix.net 1003
15 prod.partner.netflix.net 970
1 ctldl.windowsupdate.com 969
6 ichnaea.netflix.com 957
11 netflix.net 939
17 settings-win.data.microsoft.com 934
13 preapp.prod.partner.netflix.net 924
16 safebrowsing.googleapis.com 915Comparing with the non-privatized counts:
windowsupdate.com 3781 www.google.com 3698 api-global.netflix.com 3652 netflix.com 3642 data.microsoft.com 3639 microsoft.com 3638 google.com 3600 events.data.microsoft.com 3599 prod.ftl.netflix.com 3590 ftl.netflix.com 3571 live.com 1050 partner.netflix.net 1003 microsoftonline.com 998 prod.partner.netflix.net 989 ichnaea.netflix.com 982 ctldl.windowsupdate.com 958 safebrowsing.googleapis.com 951 netflix.net 933 settings-win.data.microsoft.com 914 preapp.prod.partner.netflix.net 914
Consider that the utility of a count vector is measured as follows: 1) order of the domains, and 2) counts of visits for each domain. From this perspective, the values of Counts of Visits on the differentially private vector are relatively close to the non-private vector. The second observation is regarding ranking order of the domains. The top 2 domains are the same in both rankings, so when analyzing the top 5 domains, there are 4 domains in the intersection of the dp-top5 and non-private top5.
The third query, the average visits per user for each day of the week, is formulated as two distinct queries as follows:
1fromimportlib.metadataimportmetadata2importpandasaspd3fromsnsqlimportPrivacy,from_df4fromsnsql.sql._mechanisms.baseimportMechanism5fromsnsql.sql.privacyimportStat6 7budget=2.08k=409eps=budget/k10 11metadata='domain.yaml'12privacy=Privacy(epsilon=eps)13reader=from_df(df,privacy=privacy,metadata=metadata)14 15query_count_domain='''SELECT Day_id, COUNT(*) AS DomainVisits16FROM MySchema.MyTable17GROUP BY Day_id'''18 19 20query_count_users='''SELECT Day_id, COUNT(DISTINCT ids_num) AS Users21FROM MySchema.MyTable22GROUP BY Day_id'''23 24privacy.mechanisms.map[Stat.count]=Mechanism.laplace25("Running query with Laplace mechanism for count:")26(privacy.mechanisms.map[Stat.count])27 28 29domains_visits=reader.execute_df(query_count_domain)30(domains_visits)31 32user_counts=reader.execute_df(query_count_users)33(user_counts)
The result of the queries above are used as input to the average of visits per user calculation. As seen in previous chapters, a differentially private mean when the total size of the database is unknown results in a function with an undefined sensitivity. The most reliable way to compute means is by making two separate queries: One query for the numerator (total number of visits per day) and one query for the denominator (total number of unique users per day). The calculation of the average becomes a post-processing step of two differentially private functions.
Running query with Laplace mechanism for count:
Mechanism.laplace
Day_id DomainVisits
0 Friday 232366
1 Monday 233873
2 Saturday 146003
3 Sunday 145656
4 Thursday 232830
5 Tuesday 232038
6 Wednesday 232574
Day_id Users
0 Friday 232381
1 Monday 233867
2 Saturday 146040
3 Sunday 145640
4 Thursday 232746
5 Tuesday 232071
6 Wednesday 232576
Average visits per user per day of the week
Friday 1.230472
Monday 1.233458
Saturday 1.147276
Sunday 1.144335
Thursday 1.232094
Tuesday 1.231370
Wednesday 1.232915The computation of the mean is a post-processing step. As noted in chapter 3, post-processing of differentially private statistics does not incur in additional privacy losses.
The process described in this example illustrates the steps of a practical differentially private data release. This example shows important phases of a differentially private data release, such as when the data scientist:
-
identifies the browser logs data as an event-level dataset
-
recognizes that the number of events per user is unbounded
-
estimates, in a privacy-preserving manner, a bound k of events per user without previous knowledge on the data distribution
-
pre-processes the database in order to make it ready for a differential privacy analysis
-
makes differentially private queries to the database taking into consideration the necessary code changes to account for multiple events per user
-
evaluates the results of different queries
-
post-processes the results. Budget composition analysis is left as an exercise to the reader.
Unknown Key Set
In the previous example, each row of the browser logs database consists of an event, described by a user visiting a domain on a specific day. From the data description, we know that the data only contains logs of visits to 20 domains. The set of days of the week and domains is well-defined. However, what happens if the database has logs to any set of domains? What if the logs contains logs to URLs or search queries? In this case, even if we apply differential privacy to a data release, just knowing that an event exists in the dataset can reveal the presence or absence of an individual. It is very common for URLs and search queries to contain personally identifiable information (PII). This type of scenario happened in the AOL data release mentioned in the beginning of this chapter.
The idea is to throw away rare items to avoid a privacy-compromising situation such as the AOL release.
To determine whether a query should be published or not, the frequency of the query plus some noise should exceed
a threshold
The above algorithm only releases real queries. Therefore, it does not satisfy pure differential privacy,
with
Conclusion
It is crucially important to understand the structure of a data set before releasing statistics from it. In this chapter, you’ve seen that there is an important difference between user-level and event-level data. Up until now, you have only seen user-level data, where a user only appears in a single row. With event-level data, this condition is relaxed, and a user can appear in multiple (potentially unlimited) rows.
The presence of an individual across multiple rows has implications for the process of ensuring that a statistic is differentially private. You’ve just seen how to understand sensitivity when this is the case. Trying to perform a DP analysis with your prior assumptions would lead to a privacy leakage. In order to have a well-defined sensitivity, you may need to bound the number of rows that a user can appear in. This hasn’t been an issue until now, since each user has only appeared in one row! This clamping can be accomplished via a handy method called reservoir sampling. With reservoir sampling, you can sample a maximum of k rows for each individual. Knowing that each individual appears a maximum of k times, you now have a data set with a well-defined sensitivity.
Exercises
1 For the following data:
a) Calculate the mean
b) Clip the data on [0, 900.00]. How does the mean change?
c) Clip the data on [0, 100.00]. How does the mean change?
d) Plot the mean versus the clipping bound for values from 1.0 to 1000.0
| Score |
|---|
916.42 |
986.41 |
543.71 |
719.28 |
68.11 |
732.5 |
621.91 |
601.82 |
569.32 |
966.64 |
2 Which of the following datasets are adjacent?
a)
| id | Score |
|---|---|
1 | 916.42 |
1 | 986.41 |
4 | 543.71 |
4 | 719.28 |
5 | 68.11 |
5 | 732.5 |
7 | 621.91 |
7 | 601.82 |
10 | 569.32 |
10 | 966.64 |
| id | Score |
|---|---|
1 | 916.42 |
1 | 986.41 |
4 | 543.71 |
4 | 719.28 |
5 | 68.11 |
5 | 732.5 |
7 | 621.91 |
7 | 601.82 |
9 | 569.32 |
9 | 966.64 |
b)
| id | Score |
|---|---|
1 | 916.42 |
1 | 986.41 |
4 | 543.71 |
4 | 719.28 |
5 | 68.11 |
5 | 732.5 |
7 | 621.91 |
7 | 601.82 |
10 | 569.32 |
10 | 966.64 |
| id | Score |
|---|---|
1 | 916.42 |
1 | 986.41 |
4 | 543.71 |
4 | 719.28 |
5 | 68.11 |
5 | 732.5 |
6 | 621.91 |
6 | 601.82 |
9 | 569.32 |
9 | 966.64 |
3 Using the browser logs dataset:
a) Demonstrate how the presence of rare events can lead to a privacy violation.
b) Set an appropriate value of
4 Use the browser logs dataset to demonstrate the parallel composability theorem.
a) How do you have to divide the dataset so that it is disjoint?
b) How does this process differ from using parallel composition on a user-level dataset?
1 In one particular stroke of journalistic brilliance, the NY Times was able to re-identify a 62 year old woman in Georgia just from her search queries.
2 https://s3-us-west-1.amazonaws.com/umbrella-static/index.html