
Chapter 1: The Large Language Model Revolution
"art is the debris from the collision between the soul and the world" #gpt3
"technology is now the myth of the modern world" #gpt3
"revolutions begin with a question, but do not end with an answer" #gpt3
"nature decorates the world with variety" #gpt3
Imagine waking up to a beautiful, sunny morning. It’s Monday, and you know the week will be hectic. Your company is about to launch a new personal-productivity app, Taskr, and start a social media campaign to inform the world about your ingenious product.
This week, your main task is writing and publishing a series of engaging blog posts.
You start by making a to-do list:
● Write an informative and fun article about productivity hacks, including Taskr. Keep it under 500 words.
● Create a list of 5 catchy article titles.
● Choose the visuals.
You hit Enter, take a sip of coffee, and watch an article unravel on your screen, sentence by sentence, paragraph by paragraph. In 30 seconds, you have a meaningful, high-quality blog post, a perfect starter for your social media series. The visual is fun and attention-grabbing. It’s done! You choose the best title and begin the publishing process.
This is not a distant, futuristic fantasy but a glimpse of the new reality made possible by advancements in AI. As we write this book, many such applications are being created and deployed to a broader audience.
GPT-3 is a cutting-edge language model created by OpenAI, a company at the frontier of artificial intelligence R&D. OpenAI’s research paper announcing GPT-3 was released in May 2020, following a launch of access to GPT-3 via OpenAI API in June 2020. Since the GPT-3 release, people around the world coming from different backgrounds, including technology, art, literature, marketing, etc., have already found hundreds of exciting applications of the model that have the potential to elevate the ways we communicate, learn, and play.
GPT-3 can solve general language-based tasks, like generating and classifying text, with unprecedented ease, moving freely between different text styles and purposes. The array of problems it can solve is vast.
In this book, we invite you to think of what problems you might solve with GPT-3 yourself. We’ll show you what it is and how to use it, but first, we want to give you a bit of context. The rest of this chapter will discuss where this technology comes from, how it is built, what tasks it excels at, and its potential risks. Let’s dive right in by looking at the field of natural language processing (NLP) and how large language models (LLMs) and GPT-3 fit into it.
A Behind-the-Scenes Look at Natural Language Processing
NLP is a subfield focusing on the interaction between computers and human languages. Its goal is to build systems that can process natural language, which is the way people communicate with each other. NLP combines linguistics, computer science, and artificial intelligence techniques to achieve this.
NLP combines the field of computational linguistics (rule-based modeling of human language) with machine learning to create intelligent machines capable of identifying the context and understanding the intent of natural language. Machine learning is a branch of AI that focuses on the study of how machines can improve their performance on tasks through experiences without being explicitly programmed to do so. Deep learning is a subfield of machine learning that involves using neural networks modeled after the human brain to perform complex tasks with minimal human intervention.
The 2010s saw the advent of deep learning, and with the maturity of the field came large language models consisting of dense neural networks composed of thousands or even millions of simple processing units called artificial neurons. Neural networks became the first significant game-changer in the field of NLP by making it feasible to perform complex natural language tasks, which had been possible only in theory so far. The second major milestone was the introduction of pre-trained models (such as GPT-3) that could be fine-tuned on various downstream tasks, saving many hours of training. (We discuss pre-trained models later in this chapter.)
NLP is at the core of many real-world AI applications, such as:
Spam detection
The spam filtering in your email inbox assigns a percentage of the incoming emails to the spam folder, using NLP to evaluate which emails look suspicious.
Machine translation
Google Translate, DeepL, and other machine translation programs use NLP to assess millions of sentences translated by human speakers of different language pairs.
Virtual assistants and chatbots
All the Alexas, Siris, Google Assistant, and customer support chatbots of the world fall into this category. They use NLP to understand, analyze, prioritize user questions and requests, and respond to them quickly and correctly.
Social media sentiment analysis
Marketers collect social media posts about specific brands, conversation subjects, and keywords, then use NLP to analyze how users feel about each topic, individually and collectively. It helps the brands with customer research, image evaluation, and social dynamics detection.
Text summarization
Summarizing a text involves reducing its size while keeping key information and the essential meaning. Some everyday examples of text summarization are news headlines, movie previews, newsletter production, financial research, legal contract analysis, email summaries, and applications delivering news feeds, reports, and emails.
Semantic search
Semantic search leverages deep neural networks to intelligently search through the data. You interact with it every time you search on Google. Semantic search is helpful when searching for something based on the context rather than specific keywords.
"The way we interact with other humans is through language,” says Yannic Kilcher, one of the most popular YouTubers and influencers in the NLP space. “Language is part of every business transaction, every other interaction we have with other humans, even with machines in part we interact with some sort of language, be that via programming or a user interface.” It’s no wonder, then, that NLP as a field has been the site of some of the most exciting AI discoveries and implementations of the past decade.
Language Models Getting Bigger & Better
Language modeling is the task of assigning a probability to a sequence of words in a text in a specific language. Based on a statistical analysis of existing text sequences, simple language models can look at a word and predict the next word (or words) most likely to follow. To create a language model that successfully predicts word sequences, you must train it on large data sets.
Language models are a vital component in natural language processing applications. You can think of them as statistical prediction machines, giving text as input and getting a prediction as the output. You’re probably familiar with this from the autocomplete feature on your phone. For instance, if you type good, autocomplete might come up with suggestions like “morning” or “luck.”
Before GPT-3 there was no general language model that could perform well on an array of NLP tasks. Language models were designed to perform one NLP task, such as text generation, summarization, or classification. So, in this book, we will discuss GPT-3’s extraordinary capabilities as a general language model. We’ll start this chapter by walking you through each letter of “GPT” to show what they stand for and what are the elements with which the famous model was built. We’ll give a brief overview of the model’s history and how the sequence-to-sequence models we see today came into the picture. After that, we will walk you through the importance of API access and how it evolved based on users' demands. We recommend signing up for an OpenAI account before you move on to the rest of the chapters.
The Generative Pre-Trained Transformer: GPT-3
The name GPT-3 stands for “Generative Pre-trained Transformer 3.” Let's go through all these terms one by one to understand the making of GPT-3.
Generative models
GPT-3 is a generative model because it generates text. Generative modeling is a branch of statistical modeling. It is a method for mathematically approximating the world.
We are surrounded by an incredible amount of easily accessible information— both in the physical and digital worlds. The tricky part is to develop intelligent models and algorithms that can analyze and understand this treasure trove of data. Generative models are one of the most promising approaches to achieving this goal.[1]
To train a model, you must prepare and preprocess a dataset, a collection of examples that helps the model learn to perform a given task. Usually, a dataset is a large amount of data in some specific domain: like millions of images of cars to teach a model what a car is, for example. Datasets can also take the form of sentences or audio samples. Once you have shown the model many examples, you must train it to generate similar data.
Pre-trained models
Have you heard of the theory of 10,000 hours? In his book Outliers, Malcolm Gladwell suggests that practicing any skill for 10,000 hours is sufficient to make you an expert.[2] This “expert” knowledge is reflected in the connections your human brain develops between its neurons. An AI model does something similar.
To create a model that performs well, you need to train it using a specific set of variables called parameters. The process of determining the ideal parameters for your model is called training. The model assimilates parameter values through successive training iterations.
A deep learning model takes a lot of time to find these ideal parameters. Training is a lengthy process that depending on the task, can last from a few hours to a few months and requires a tremendous amount of computing power. Reusing some of that long learning process for other tasks would significantly help. And this is where the pre-trained models come in.
A pre-trained model, keeping with Gladwell’s 10,000 hours theory, is the first skill you develop to help you acquire another faster. For example, mastering the craft of solving math problems can allow you to acquire the skill of solving engineering problems faster. A pre-trained model is trained (by you or someone else) for a more general task and can be fine-tuned for different tasks. Instead of creating a brand new model to address your issue, you can use a pre-trained model that has already been trained on a more general problem. The pre-trained model can be fine-tuned to address your specific needs by providing additional training with a tailored dataset. This approach is faster and more efficient and allows for improved performance compared to building a model from scratch.
In machine learning, a model is trained on a dataset. The size and type of data samples vary depending on the task you want to solve. GPT-3 is pre-trained on a corpus of text from five datasets: Common Crawl, WebText2, Books1, Books2, and Wikipedia.
Common Crawl
The Common Crawl corpus comprises petabytes of data, including raw web page data, metadata, and text data collected over eight years of web crawling. OpenAI researchers use a curated, filtered version of this dataset.
WebText2
WebText2 is an expanded version of the WebText dataset, an internal OpenAI corpus created by scraping particularly high-quality web pages. To vet for quality, the authors scraped all outbound links from Reddit, which received at least three karma (an indicator for whether other users found the link interesting, educational, or just funny). WebText contains 40 gigabytes of text from these 45 million links, and over 8 million documents.
Books1 and Books2
Books1 and Books2 are two corpora, or collections of text, that contain the text of tens of thousands of books on various subjects.
Wikipedia
A collection including all English-language articles from the crowdsourced online encyclopedia Wikipedia at the time of finalizing the GPT-3’s dataset in 2019. This dataset has roughly 5.8 million English articles.
This corpus includes nearly a trillion words altogether.
GPT-3 is capable of generating and successfully working with languages other than English as well. Table 1-1 shows the top 10 other languages within the dataset.
Rank
| Language
| Number of documents
| % of total documents
|
1.
| English
| 235987420
| 93.68882%
|
2.
| German
| 3014597
| 1.19682%
|
3.
| French
| 2568341
| 1.01965%
|
4.
| Portuguese
| 1608428
| 0.63856%
|
5.
| Italian
| 1456350
| 0.57818%
|
6.
| Spanish
| 1284045
| 0.50978%
|
7.
| Dutch
| 934788
| 0.37112%
|
8.
| Polish
| 632959
| 0.25129%
|
9.
| Japanese
| 619582
| 0.24598%
|
10.
| Danish
| 396477
| 0.15740%
|
Table 1-1. Top ten languages in the GPT-3 dataset
While the gap between English and other languages is dramatic - English is number one, with 93% of the dataset; German, at number two, accounts for just 1% - that 1% is sufficient to create perfect text in German, with style transfer and other tasks. The same goes for other languages on the list.
Since GPT-3 is pre-trained on an extensive and diverse corpus of text, it can successfully perform a surprising number of NLP tasks without users providing any additional example data.
Transformer Models
Neural networks are at the heart of deep learning, with their name and structure being inspired by the human brain. They are composed of a network or circuit of neurons that work together. Advances in neural networks can enhance the performance of AI models on various tasks, leading AI scientists to continually develop new architectures for these networks. One such advancement is the transformer, a machine learning model that processes a sequence of text all at once rather than one word at a time and has a strong ability to understand the relationship between those words. This invention has dramatically impacted the field of natural language processing.
Sequence-to-sequence models
Researchers at Google and the University of Toronto paper introduced a transformer model in a 2017 paper:
We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train.[3]
The foundation of transformer models is sequence-to-sequence architecture. Sequence- to-sequence (Seq2Seq) models are useful for converting a sequence of elements, such as words in a sentence, into another sequence, such as a sentence in a different language. This is particularly effective in translation tasks, where a sequence of words in one language is translated into a sequence of words in another language. Google Translate started using a Seq2Seq-based model in 2016.
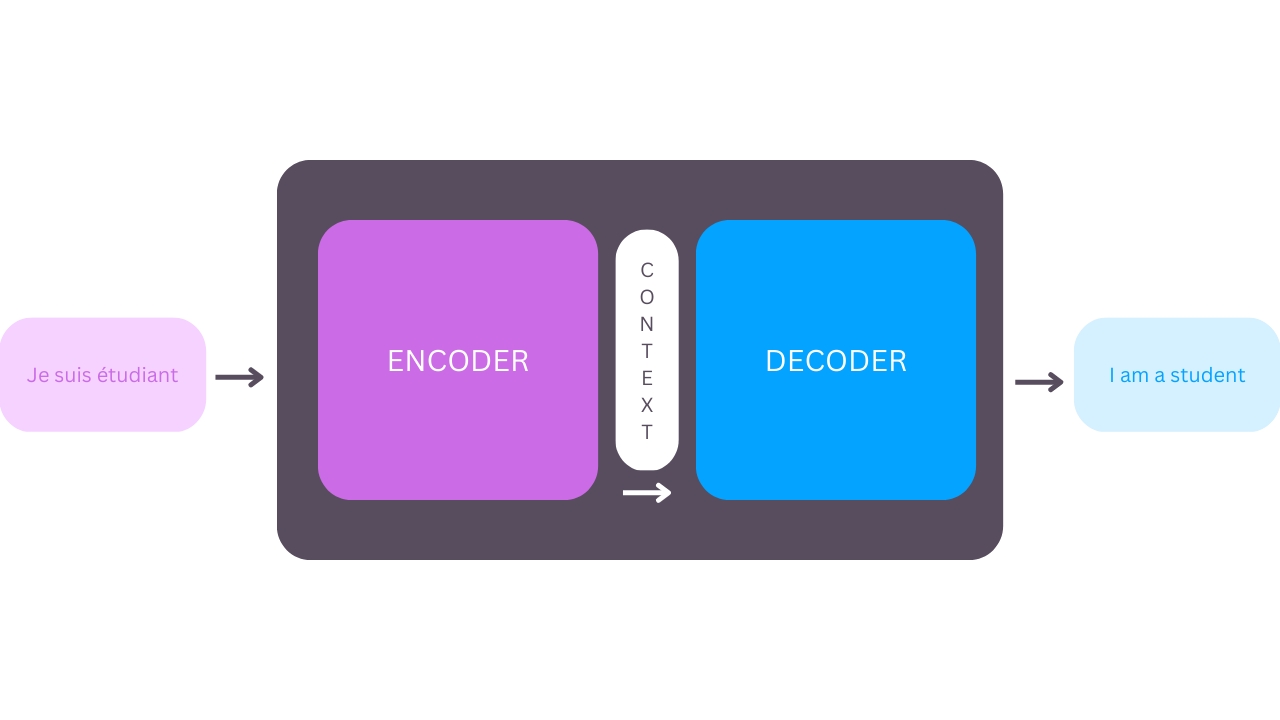
Figure 1-1. Seq-to-Seq Model (Neural Machine Translation)[4]
Seq2Seq models are comprised of two components: an Encoder and a Decoder. The Encoder can be thought of as a translator who speaks French as their first language and Korean as their second language. The Decoder is a translator who speaks English as their first language and Korean as their second language. To translate French to English, the Encoder converts the French sentence into Korean (also known as the context) and passes it on to the Decoder. Since the Decoder understands Korean, it can translate the sentence from Korean to English. The Encoder and Decoder can successfully translate from French to English[5], as illustrated by Figure 1-1.
Transformer attention mechanisms
Transformer architecture was invented to improve AIs’ performance on machine translation tasks. “Transformers started as language models,” Kilcher explains, “not even that large, but then they became large."
To use transformer models effectively, it is crucial to grasp the concept of attention. Attention mechanisms mimic how the human brain focuses on specific parts of an input sequence, using probabilities to determine which parts of the sequence are most relevant at each step.
For example, look at the sentence,” The cat sat on the mat once it ate the mouse.” Does it in this sentence refer to “the cat" or "the mat"? The transformer model can strongly connect "it" with "the cat." That's attention.
An example of how the Encoder and Decoder work together is when the Encoder writes down important keywords related to the meaning of the sentence and provides them to the Decoder along with the translation. These keywords make it easier for the Decoder to understand the translation, as it now has a better understanding of the critical parts of the sentence and the terms that provide context.
The transformer model has two types of attention: self-attention (the connection of words within a sentence) and Encoder-Decoder attention (the connection between words from the source sentence to words from the target sentence).
The attention mechanism helps the transformer filter out the noise and focus on what’s relevant: connecting two words in semantic relationship to each other that do not carry any apparent markers pointing to one another.
Transformer models benefit from larger architectures and larger quantities of data. Training on large datasets and fine-tuning for specific tasks improve results. Transformers better understand the context of words in a sentence than any other kind of neural network. GPT is just the Decoder part of the transformer.
Now that you know what “GPT” means, let’s talk about that “3”- as well as 1 and 2.
GPT-3: A Brief History
GPT-3 was created by, and is a significant milestone for, OpenAI, a San Francisco-based pioneer of AI research. OpenAI’s stated mission is “to ensure that artificial general intelligence benefits all of humanity,” as well as its vision of creating artificial general intelligence: a type of AI not confined to being specialized tasks, instead performing well at a variety of tasks, just like humans do.
GPT-1
OpenAI presented GPT-1 in June 2018. The developers’ key finding was that combining the transformer architecture with unsupervised pre-training yielded promising results. GPT-1, they write, was fine-tuned for specific tasks to achieve “strong natural language understanding.”
GPT-1 was an essential stepping stone towards a language model with general language-based capabilities. It proved that language models can be effectively pre-trained, which could help them generalize well. The architecture could perform various NLP tasks with very little fine-tuning.
The GPT-1 model used the BooksCorpus dataset, which contains some 7,000 unpublished books and self-attention in the transformer's decoder to train the model. The architecture was similar to the original transformer, with 117 million parameters. This model paved the way for future models with larger datasets and more parameters to utilize its potential better.
One of its notable abilities was its decent performance on zero-shot tasks in natural language processing, such as question-answering and sentiment analysis, thanks to pre-training. Zero-shot learning is the ability of a model to perform a task without having previously seen examples of that task. In Zero-shot task transfer, the model is given little to no examples and must understand the task based on instructions and a few examples.
GPT-2
In February 2019, OpenAI introduced GPT-2, which is bigger but otherwise very similar. The significant difference is that GPT-2 can multitask. It successfully proved that a language model could perform well on several tasks without receiving any training examples.
GPT-2 showed that training on a larger dataset and having more parameters improves a language model’s capability to understand tasks and surpass the state-of-the-art of many tasks in zero-shot settings. It also showed that even larger language models would better understand natural language.
To create an extensive, high-quality dataset, the authors scraped Reddit and pulled data from outbound links of upvoted articles on the platform. The resulting dataset, WebText, had 40GB of text data from over 8 million documents, far larger than GPT-1’s dataset. GPT-2 was trained on the WebText dataset and had 1.5 billion parameters, ten times more than GPT-1.
GPT-2 was evaluated on several datasets of downstream tasks like reading comprehension, summarisation, translation, and question answering.
GPT-3
In the quest to build an even more robust and powerful language model, OpenAI built the GPT-3 model. Both its dataset and the model are about two orders of magnitude larger than those used for GPT-2: GPT-3 has 175 billion parameters and was trained on a mix of five different text corpora, a much bigger dataset than the dataset used to train GPT-2. The architecture of GPT-3 is largely the same as GPT-2. It performs well on downstream NLP tasks in zero-shot and few-shot settings.
GPT-3 has capabilities like writing articles that are indistinguishable from human-written articles. It can also perform on-the-fly tasks for which it was never explicitly trained, like summing numbers, writing SQL queries, and even writing React and JavaScript codes given a plain English description of the tasks.
Note: Few, one, and zero-shot settings are specialized cases of zero-shot task transfer. In a few-shot setting, the model is provided with a task description and as many examples as fit into the context window of the model. The model is provided with exactly one example in a one-shot setting and in a zero-shot setting with no example.
OpenAI focuses on the democratic and ethical implications of AI in its mission statement. This can be seen in their decision to make the third version of their model, GPT-3, available via a public API. Application programming interface allows for a software intermediary to facilitate communication between a website or app and the user.
APIs act as a means of communication between developers and applications, allowing them to build new programmatic interactions with users. Releasing GPT-3 via an API was a revolutionary move. Until 2020, the powerful AI models developed by leading research labs were available to only a select few researchers and engineers working on these projects. The OpenAI API gives users all over the world unprecedented access to the world's most powerful language model via simple sign-in. (OpenAI’s business rationale for this move is to create a new paradigm it calls “Model-as-a-Service” where developers can pay per API call; we will take a closer look at this in chapter 3.)
OpenAI researchers experimented with different model sizes while working on GPT-3. They took the existing GPT-2 architecture and increased the number of parameters. What came out as a result of that experiment was a model with new and extraordinary capabilities in the form of GPT-3. While GPT-2 displayed some zero-shot capabilities on downstream tasks, GPT-3 can carry out even more novel tasks when presented with example context.
OpenAI researchers found it remarkable that merely scaling the model parameters and the size of the training dataset led to such extraordinary advances. They are generally optimistic that these trends will continue even for models much larger than GPT-3, enabling ever-stronger learning models capable of few-shot or zero-shot learning just by fine-tuning on a small sample size.
As you read this book, experts estimate that well over a trillion parameter-based language models are probably being built and deployed. We have entered the golden age of Large Language Models, and now it's time for you to become a part of it.
GPT-3 has captured a lot of public attention. The MIT Technology Review considered GPT-3 as one of the 10 Breakthrough Technologies of 2021. Its sheer flexibility in performing generalized tasks with near-human efficiency and accuracy makes it so exciting. As an early adopter, Arram Sabeti tweeted (Figure 1-2):

Figure 1-2. Tweet from Arram Sabeti
The API release created a paradigm shift in NLP and attracted many beta testers. Innovations and startups followed at lightning speed, with many commentators calling GPT-3 a “fifth Industrial Revolution”.
Within just nine months of the launch of the API, according to OpenAI, people were building more than three hundred businesses with it. Despite this suddenness, some experts argue that the excitement isn’t exaggerated. Bakz Awan is a developer turned entrepreneur and influencer and one of the major voices in the OpenAI API developer community. He has a YouTube channel “Bakz T. Future” and a podcast. Awan argues that GPT-3 and other models are actually “underhyped for how usable and friendly and fun and powerful they really are. It’s almost shocking.”
Daniel Erickson, CEO of Viable, which has a GPT-3 powered product, praises the model’s ability to extract insights from large datasets through what he calls prompt-based development:
Companies going down that path cover use cases such as generating copy for ads and websites. The design philosophy is relatively simple: the company takes your data in, sends it over into a prompt, and displays the API-generated result. It solves a task that is easily done by a single API prompt and wraps a UI around that to deliver it to the users.
The problem Erickson sees with this category of use cases is that it is already overcrowded, attracting many ambitious startup founders competing with similar services. Instead, Erickson recommends looking at another use case, as Viable did. Data-driven use cases are not as crowded as prompt-generation use cases, but they are more profitable and allow you to create a moat easily.
The key, Erickson says, Erickson says, is to build a large dataset that you can keep adding to and that can provide potential insights. GPT-3 will help you extract valuable insights from it. At Viable, this was the model that let them monetize easily. “People pay much more for data than they do for prompt output,” Erickson explains.
It should be noted that technological revolutions also bring controversies and challenges. GPT-3 is a powerful tool in the hands of anyone trying to create a narrative. Without great care and benevolent intentions, one such challenge we will face is curbing the attempts to use the algorithm to spread misinformation campaigns. Another one would be eradicating its use for generating mass quantities of low-quality digital content that will then pollute the information available on the internet. Yet another one is the limitations of its datasets that are filled with various kinds of bias, which can be amplified by this technology. We will look closer at these and more challenges in Chapter 6, along with discussing the various efforts by OpenAI to address them.
Accessing the OpenAI API
As of 2021, the market has already produced several proprietary AI models with more parameters than GPT-3. However, access to them is limited to a handful of people within the company's R&D walls, making it impossible to evaluate their performance on real-world NLP tasks.
Another factor that makes GPT-3 accessible is its simple and intuitive “text-in, text-out” user interface. It doesn’t require complex gradient fine-tuning or updates, and you don’t need to be an expert to use it. This combination of scalable parameters and relatively open access makes GPT-3 the most exciting and arguably the most relevant language model to date.
Due to GPT-3's extraordinary capabilities, there are significant risks in terms of security and misuse associated with making it open-source, which we will cover in the last chapter—considering that, OpenAI decided not to publicly release the source code of GPT-3 and came up with a unique, never seen before access sharing model via an API.
The company initially decided to release API access in the form of a limited beta user list. There was an application process where people had to fill in a form detailing their background and the reasons for requesting API access. Only the approved users were granted access to a private beta of the API with an interface called Playground.
In its early days, the GPT-3 beta access waitlist consisted of tens of thousands of people. OpenAI swiftly managed the applications pouring in and adding developers in batches. It also closely monitored their activity and feedback about the API user experience to improve it continuously.
Thanks to the progress with safeguards, OpenAI removed the waitlist in November 2021. GPT-3 is now openly accessible via a simple sign-in. This is a significant milestone in the history of GPT-3 and a highly requested move by the Community. To get API access, go to the sign-up page, sign up for a free account, and start experimenting with it right away.
New users initially get a pool of free credits that allows them to freely experiment with the API. The number of credits is equivalent to creating text content as long as three average-length novels. After the free credits are used, users start paying for usage or, if they have a need, they can request additional credits from OpenAI API customer support.
OpenAI strives to ensure that API-powered applications are built responsibly. For that reason, it provides tools, best practices, and usage guidelines to help developers bring their applications to production quickly and safely.
The company has also created content guidelines to clarify what kind of content the OpenAI API can be used to generate. To help developers ensure their applications are used for the intended purpose, prevent potential misuse, and adhere to the content guidelines, OpenAI offers a free content filter. OpenAI policy prohibits the use of the API in ways that do not adhere to the principles described in its charter, including content that promotes hate, violence, or self-harm, or that intends to harass, influence political processes, spread misinformation, spam content, and so on.
Once you have signed up for an OpenAI account, you can move on to Chapter 2, where we will discuss the different components of the API, the GPT-3 Playground, and how to use the API to the best of its abilities for different use cases.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.