
Chapters 6 through 16 cover the implementation of the CSLA .NET framework as described in Chapter 2. I think it is useful to get a good idea of the types of business objects the framework is designed to support before looking at the implementation itself. In this chapter and in Chapter 5, I discuss the primary types of objects supported by the framework and walk through the basic code structure of each object type.
In object-oriented design terms, objects that share a broad set of behavioral characteristics and play a similar role in the application architecture are said to belong to a stereotype. A stereotype is a way of categorizing or describing a broad set of similar objects. This chapter covers in detail the object stereotypes directly supported by CSLA .NET. You may extend or enhance CSLA .NET to support other stereotypes as required by your application but the stereotypes supported out of the box do cover the needs of most business applications.
This chapter covers the life cycle of each type of business object in general terms. Then in Chapter 5, I get into code, creating a basic template showing the structure of each stereotype:
Editable root
Editable child
Editable, "switchable" (i.e., root or child) object
Editable root collection
Editable child collection
Read-only root
Read-only root collection
Read-only child
Read-only child collection
Command object
Name/value list
Dynamic editable list
Dynamic editable root
Criteria
Though the templates are not complete business object implementations, each one illustrates the basic structure you need to follow when creating that type of business object. You can use this information to create class templates or code snippets for use in Visual Studio to make your development experience more productive.
Most frameworks and application models have their own jargon and terminology, and CSLA .NET is no exception. To discuss the stereotypes supported by CSLA .NET, I think it is important to first define some common terms. These are listed in Table 4-1.
Table 4.1. CSLA .NET Common Terms
When working with CSLA .NET, there is always one object that is identified as the root object. This object may be a parent, in which case it contains other child objects, or it may simply be a single object, as shown in Figure 4-1.

Figure 4-2 illustrates a more complex object graph where the root object is also a parent containing two other objects.
Notice that the child list is also a parent containing other child objects. The important thing to remember is that an object graph can only have exactly one root object. That root object may contain many child or child list objects, and some of those child objects may also be parent objects. In other words, the CSLA .NET stereotypes have rich support for the concept of containment, where objects contain other objects.

A common example of containment is a sales order, which contains a list of line item objects. Typically the SalesOrder object is a root and a parent; the LineItemList object is a child and a parent; and each LineItem object is a child.
It is also possible for a list to be a root, as shown in Figure 4-3.

Another important object-oriented concept is the using relationship, where one object uses or interacts with another object but does not contain that object. This is a fundamentally different type of relationship, but it is quite common to accidentally confuse a using relationship with containment.
For example, the previously mentioned SalesOrder object might use a CustomerInfo object, but it makes no sense to think that a sales order contains or owns a customer, even though it may require information from a customer information object. Figure 4-4 illustrates how a using relationship can exist between two root objects.

There are many variations on the using relationship, including a root using a child, a child using a root, or a child using another child. But the key to understanding the using relationship is to remember that neither object owns or contains or controls the other object. Editing or saving one object does not edit or save the other object.
This is fundamentally different from containment, where each parent owns its children and controls their lifetimes, and ultimately the root object owns all the objects in the object graph and their lifetimes are determined by the root object.
By combining these various concepts you can see how the stereotypes fit together. Table 4-2 lists the stereotypes and provides a definition for each. Additionally, the table lists the CSLA .NET base class you will inherit from to implement each stereotype.
Table 4.2. CSLA .NET Object Stereotypes
By combining objects based on these stereotypes in various ways, it is possible to meet the needs of most business application use cases by using the object-oriented design techniques discussed in Chapter 3.
Before getting into the code structure for the business objects, it's worth spending some time to understand the life cycle of those objects. By life cycle, I mean the sequence of methods and events that occur as the object is created and used. Although it isn't always possible to predict the business properties and methods that might exist on an object, there's a set of steps that occur during the lifetime of every business object.
Typically, an object is created by UI code, whether that's WPF, Windows Forms, Web Forms, a WCF service, or a Windows Workflow Foundation activity. Sometimes an object may be created by another object, which will happen when there's a using relationship between objects, for instance.
Whether editable or read-only, all root objects go through the same basic creation process. (Root objects are those that can be directly retrieved from the database, while child objects are retrieved within the context of a root object, though never directly.)
It's up to the root object to invoke methods on its child objects and child collections so that they can load their own data from the database. Usually, the root object actually calls the database and gets all the data back and then provides that data to the child objects and collections so that they can populate themselves. From a purely object-oriented perspective, it might be ideal to have each object encapsulate the logic to get its own data from the database, but in reality it's not practical to have each object independently contact the database to retrieve one row of data.
Root Object Creation
Root objects are created by calling a factory method, which is a method that's called in order to create an object. Factory methods will typically be static methods on the class. The factory method uses the CSLA .NET data portal to load the object with default values. The data portal is a CSLA .NET technology that abstracts communication with the application server (if there is one), enabling the mobile object concept described in Chapter 1.
I am often asked why you would need to communicate with the database to create a new object. Why not just use the constructor and be done with it? The reason is that business applications often need to load new objects with default values, and those values are often in database tables. While some simple objects can be directly created, it is quite common for an object to require data from the database as it is created.
The following steps outline the process of creating a new root object:
The factory method is called.
The factory method calls
DataPortal.Create()to get the business object.The data portal uses its channel adapter and message router functionality as described in Chapter 15; the result is that the data portal creates a new instance of the business object.
The data portal does one of the following:
If no
ObjectFactoryattribute is specified, theDataPortal_Create()method is called and this is where the business object implements data access code to load its default values.If an
ObjectFactoryis specified, the data portal will create an instance of a factory object and will invoke a specified create method on that factory object. This method is responsible for creating an instance of the business object and implementing data access code to load its default values.
The business object is returned.
With no ObjectFactory attribute, from the business object's perspective, two methods are called, as follows:
The default constructor
DataPortal_Create()
This is illustrated in Figure 4-5.
If the object doesn't need to retrieve default values from the database, the RunLocal attribute can be used to short-circuit the data portal so the object initialization occurs in the same location as the calling code.
If an object doesn't require any initialization, the DataPortal_Create() method doesn't need to be overridden. The CSLA .NET base classes provide a default implementation decorated with RunLocal.
With an ObjectFactory attribute, the business developer will have defined two classes: the object factory class and the business class. From the object factory's perspective, two methods are called, as follows:
The default constructor
The create method specified by the
ObjectFactoryattribute
As illustrated in Figure 4-6, it is then entirely up to the object factory to create and initialize the business object.


The RunLocal attribute can be applied to methods of an object factory and will have the same effect as it would on DataPortal_Create(), assuming the assembly containing the object factory class is deployed to the client workstation.
To the UI code, of course, there's no difference; that code just calls the factory method and gets an object back:
var root = Root.NewRoot();
For the business object, most of the work occurs in the DataPortal_Create() method, where the object's values are initialized.
The use of a criteria object is optional; the DataPortal.Create() method is overloaded to accept no parameter or criteria object parameter.
Child Object Creation
Child objects are usually created when the UI code calls an Add() method on the collection object that contains the child object. Ideally, the child class and the collection class will be in the same assembly, so the static factory methods on a child object can be scoped as internal, rather than public. This way, the UI can't directly create the object, but the collection object can create the child when the UI calls the collection's Add() method.
The CSLA .NET framework doesn't actually dictate this approach. Rather, it's a design choice on my part because I feel that it makes the use of the business objects more intuitive from the UI developer's perspective. It's quite possible to allow the UI code to create child objects directly by making the child factory methods public; the collection's Add() method would then accept a prebuilt child object as a parameter. I think that's less intuitive, but it's perfectly valid, and you can implement your objects that way if you choose.
Note
Child objects can optionally be created through data binding, in which case the addition is handled by overriding the AddNewCore() method in the collection class.
Another way child objects are sometimes created is through lazy loading. In that case, the parent object creates the child object on demand, typically in the property get block for the child object. For example, the following code may be in the parent object:
public ChildType Child
{
get
{
if (!FieldManager.FieldExists(ChildProperty))
LoadProperty(ChildProperty, ChildType.NewChild());
return GetProperty(ChildProperty);
}
}Notice how the NewChild() factory method is invoked to create an instance of the child object, but only if the UI code ever retrieves the value of the Child property.
As with the root objects, you may or may not need to load default values from the database when creating a child object.
Tip
If you don't need to retrieve default values from the database, you could have the collection object create the child object directly, using the new keyword. For consistency, however, it's better to stick with the factory method approach so that all objects are created the same way.
The steps to create a child object that doesn't need to load itself with default values from the database are as follows:
The factory method (
internalscope) is called.The factory method calls
DataPortal.CreateChild(), which creates an instance of the child object and marks it as a child.The child object does any initialization in the
Child_Create()method.The child object is returned.
From the child object's perspective, two methods are called, as follows:
Default constructor
Child_Create()
This is illustrated in Figure 4-7.

Notice the use of the CreateChild() method on the data portal. This method tells the data portal to create an instance of the object, as a child, without making a call to a remote application server. This means the child object is created in the same location as the calling code, and the Child_Create() method runs in that location as well.
Once the child object is created and added to the parent, the UI code can access the child via the parent's interface. Typically, the parent provides an indexer that allows the UI to access child objects directly.
If the object needs to load itself with default values from the database, the process is a little different because the Create() method of the data portal must be invoked so the call is transferred to the application server (if there is one):
The factory method (
internalscope) is called.The factory method calls
DataPortal.Create()to get the child business object.The data portal uses its channel adapter and message router functionality as described in Chapter 15; the result is that the data portal creates a new instance of the business object.
The
DataPortal_Create()method is called and this is where the child object implements data access code to load its default values.The child object must call
MarkAsChild()in theDataPortal_Create()implementation to mark the object as a child.The child object is returned. Again, the factory method is called by the collection object rather than the UI, but the rest of the process is the same as with a root object.
From the child object's perspective, two methods are called, as follows:
The default constructor
DataPortal_Create()
This is illustrated in Figure 4-8.

Note that in either of these cases, the UI code is the same: it calls the Add() method on the parent object and then interacts with the parent's interface to get access to the newly added child object. The UI is entirely unaware of how the child object is created (and possibly loaded with default values).
Also note that the parent object is unaware of the details. All it does is call the factory method on the child class and receive a new child object in return. All the details about how the child object got loaded with default values are encapsulated within the child class.
Finally, as with creating a root object, the use of a criteria object is optional.
Retrieving an existing object from the database is similar to the process of creating an object that requires default values from the database. Only a root object can be retrieved from the database directly by code in the user interface. Child objects are retrieved along with their parent root object, not independently.
Root Object Retrieval
To retrieve a root object, the UI code simply calls the static factory method on the class, providing the parameters that identify the object to be retrieved. The factory method calls DataPortal.Fetch(), which in turn creates the object and calls DataPortal_Fetch(), as follows:
The factory method is called.
The factory method calls
DataPortal.Fetch()to get the business object.The data portal uses its channel adapter and message router functionality as described in Chapter 15; the result is that the data portal creates a new instance of the business object.
The business object can do basic initialization in the constructor method.
The data portal does one of the following:
If no
ObjectFactoryattribute is specified, theDataPortal_Fetch()method is called; this is where the business object implements data access code to retrieve the object's data from the database.If an
ObjectFactoryis specified, the data portal will create an instance of a factory object and will invoke a specified fetch method on that factory object. This method is responsible for creating an instance of the business object and implementing data access code to load it with data from the database.
The business object is returned.
If there is no ObjectFactory attribute on the business class, from the business object's perspective, two methods are called, as follows:
The default constructor
DataPortal_Fetch()
Figure 4-9 illustrates the process.

With an ObjectFactory attribute, the business developer will have defined two classes: the object factory class and the business class. From the object factory's perspective, two methods are called, as follows:
The default constructor
The fetch method specified by the
ObjectFactoryattribute
As illustrated in Figure 4-10, it is then entirely up to the object factory to create an instance of the business class and to load it with data from the database.

The RunLocal attribute can be applied to methods of an object factory and will have the same effect as it would on DataPortal_Fetch(), assuming the assembly containing the object factory class is deployed to the client workstation.
It's important to note that the root object's DataPortal_Fetch() or factory object's fetch method is responsible not only for loading the business object's data but also for starting the process of loading the data for its child objects.
The key thing to remember is that the data for the entire object, including its child objects, is retrieved when the root object is retrieved. This avoids having to go back across the network to retrieve each child object's data individually. Though the root object gets the data, it's up to each child object to populate itself based on that data.
The exception to this is if you choose to use lazy loading to load a child object or collection later in the root object's lifetime. In that case you would not load the child in the root object's DataPortal_Fetch() or factory object's fetch method. Instead you'd leave the child field with a null value at this point.
Let's dive one level deeper and discuss how child objects load their data.
Child Object Retrieval
The retrieval of a child object can be done in two different ways. You can use the data portal's support for loading child objects, or you can have your parent objects call methods on the child objects to create and load those objects however you choose.
The advantage to using the data portal to load the child objects is that it enables a simple and consistent approach for loading data into any object. However, there is some overhead to using the data portal in this manner, so it may not be appropriate in very performance-intensive scenarios.
The advantage to writing the code yourself is that you can design an optimized approach for your particular objects, and that may be very fast. However, you lose the benefits of standardization and simplicity provided by the data portal. Also, you must remember to have each child object manually call MarkAsChild() as it is created, typically in its constructor.
Note
I believe it is important, when possible, to offer choices between performance and maintainability/simplicity. This allows individual application designers to make choices based on the needs of their specific organization and application. This type of choice, enabling you to trade off one cost/benefit for another, can be found in many places throughout CSLA .NET.
Either way the steps are basically the same. As stated earlier, the root object's DataPortal_Fetch() method or factory fetch method is responsible for loading not only the root object's data but also the data for all child objects. It then calls either the data portal or methods on the child objects themselves, passing the preloaded data as parameters so the child objects can load their fields with data. The sequence of events goes like this:
The root object's
DataPortal_Fetch()creates the child collection using a factory method on the collection class (scoped asinternal) and it passes an object containing the child data as a parameter.The child collection's constructor loops through the list of child data provided by the parent, performing the following steps for each record:
The child collection creates a child object by calling a factory method on the child class, passing the data for that particular child as a parameter.
The collection object adds the child object to its collection.
At the end of the list of child data, the child collection and all child objects are fully populated.
Figure 4-11 is a sequence diagram that illustrates how this works using the data portal. Note that this diagram occurs during the process of loading the root object's data. This means that this diagram is really an expansion of Figure 4-8, the sequence diagram for retrieving a root object.

For read-only objects, retrieval is the only data-access concept required. Editable business objects and editable collections (those deriving from BusinessBase and BusinessListBase) support update, insert, and delete operations as well.
Adding and Editing Root Objects
After an object is created or retrieved, the user will work with the object, changing its values by interacting with the user interface. At some point, the user may click the OK or Save button, thereby triggering the process of updating the object into the database. The sequence of events at that point is as follows:
The UI calls the
Save()orBeginSave()method on the business object.The
Save()andBeginSave()methods callDataPortal.Update()to start the data portal process.The data portal does one of the following:
If no
ObjectFactoryattribute is specified, the data portal calls aDataPortal.Update(), DataPortal_Insert(), orDataPortal_DeleteSelf()method on the business object as appropriate; those methods contain the data access code needed to update, insert, or delete the data in the database.If an
ObjectFactoryattribute is specified, the data portal creates an instance of the specified factory class and calls the specified update method on the factory object. That update method is responsible for inserting, updating, or deleting the business object's data and returning an updated object as a result.
During the update process, the business object's data may change.
The updated business object is returned as a result of the
Save()method.
If no ObjectFactory attribute is specified on the business class, from the business object's perspective, two methods are called:
Save()One of
DataPortal_Update(), DataPortal_Insert(), orDataPortal_DeleteSelf()
Figure 4-12 illustrates this process.

If an ObjectFactory attribute is specified on the business class, the business developer is responsible for creating two classes: the object factory class and the business class. Figure 4-13 illustrates that the object factory class must implement an update method that manages all insert, update, and delete operations for the business object type.
The Save() and BeginSave() methods are implemented in BusinessBase and BusinessListBase and typically require no change or customization. The framework's save methods include checks to ensure that objects can only be saved if the object is valid, has been changed, and isn't currently being edited and the user is authorized to do the update. This helps to optimize data access by preventing the update of an object that clearly can't be updated.
Tip
If you don't like this behavior, your business class can override the framework's Save() and BeginSave() methods and replace that logic with other logic.
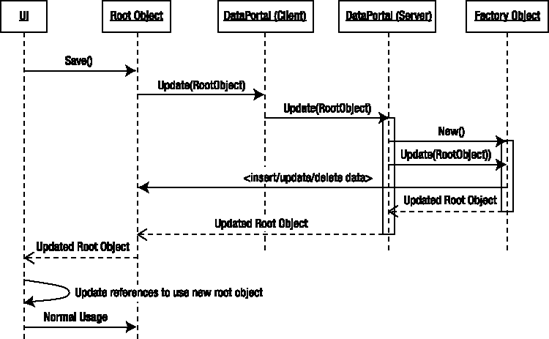
When not using ObjectFactory, all the data access code that handles the saving of the object is located in DataPortal_Update(), DataPortal_Insert(), and DataPortal_DeleteSelf(). All editable objects automatically maintain IsNew and IsDeleted properties, and the data portal includes logic to check these properties to route any save operation to the appropriate DataPortal_XYZ method.
Note
It's important to understand that the updated root object returned to the UI is a new object. The UI must update its references to use this new object in lieu of the original root object.
The DataPortal_XYZ methods are responsible not only for saving the object's data but also for starting the process of saving all the child object data.
This is true when the ObjectFactory attribute is used as well. In that case the factory object is responsible for saving the business object's data and all child object data, as shown in Figure 4-13.
Adding, Editing, and Deleting Child Objects
Child objects are inserted, updated, or deleted as part of the process of updating a root parent object. As with retrieving child objects, you can use the data portal or your own custom methods to perform this task. Using the data portal incurs a certain amount of overhead but is simple and standardized, while implementing your own internal methods is often faster but harder to write and maintain.
When using the data portal, the parent object calls a CSLA .NET method to update its child objects, and the data portal automatically invokes Child_Update(), Child_Insert(), or Child_DeleteSelf() based on the child object's IsNew and IsDeleted properties. If you have a child collection, it will automatically cascade this call down to the objects contained in the collection. The basic process is the same as when you update a root object.
It is important to realize that all child object references are managed using a CSLA .NET feature called the field manager. The field manager helps manage child relationships and the state of child objects. It also simplifies the process of updating child objects when using the data portal.
If you want to manually write and call your own methods, your child collections will typically implement an internal method named Update(). This Update() method must loop through all the objects in the collection and in the DeletedList collection to tell each child object to update itself. Child objects within a collection typically implement internal methods, named Insert(), Update(), and DeleteSelf(), that can be called by the collection during the update process. It is helpful for related root, child, and child collection classes to be placed in the same project (assembly) so that they can use internal scope in this manner.
Because the manual approach is much more complex and bug-prone, I recommend using the data portal if at all possible. The sequence of events to add, edit, or delete a child object using the data portal is as follows:
The root object's
DataPortal_XYZmethod callsFieldManager.UpdateChildren(), which uses the data portal to update all child objects; typically the parent object is passed as a parameter so that child objects can use root object property values as needed (such as for foreign key values).The data portal calls each child object's
Child_Update(), Child_Insert(), orChild_DeleleSelf()method based on the child object's state.At this point, all the child object data has been inserted, updated, or deleted as required.
Figure 4-14 illustrates this process. Remember that this diagram is connected with the previous diagram showing the update of a root object. The events depicted in this diagram occur as a result of the root object's DataPortal_Insert(), DataPortal_Update(), or DataPortal_DeleteSelf() being called, as shown earlier in Figure 4-12.

Typically the business object author will only need to write the Child_XYZ methods in editable child objects. The field manager and data portal take care of most details, including a prebuilt implementation of Child_Update() for editable list objects.
The Child_Insert() and Child_Update() methods often accept parameters. The root object's primary key value is often a required piece of data when saving a child object (since it would be a foreign key in the table) and so a reference to the root object is usually passed as a parameter to the FieldManager.UpdateChildren() method, and that value is automatically passed as a parameter to each child object's Child_Insert(), Child_Update(), or Child_DeleteSelf() method.
Passing a reference to the root object is better than passing any specific property value because it helps to decouple the root object from the child object. Using a reference means that the root object doesn't know or care what actual data is required by the child object during the update process; that behavior is encapsulated within the child class.
Deleting Root Objects
While child objects are deleted within the context of the root object that's being updated, deletion of root objects is a bit different. The data portal supports two ways of deleting objects: immediate and deferred deletion.
Immediate Deletion
Immediate deletion occurs when the UI code calls a static delete method on the business class, providing parameters that define the object to be deleted: typically, the same criteria that would be used to retrieve the object.
Most applications will use immediate deletion for root objects. The sequence of events flows like this:
The
staticdelete method is called.The
staticdelete method callsDataPortal.Delete().The data portal does one of the following:
If no
ObjectFactoryattribute is specified, the data portal creates an instance of the business class and calls theDataPortal_Delete()method on the business object, which contains the code needed to delete the object's data (and any related child data, etc.).If an
ObjectFactoryattribute is specified, the data portal creates an instance of the specified object factory class and calls the specified delete method on the factory object, which contains the code needed to delete the business object's data (and any related child data, etc.).
When not using an ObjectFactory, from the business object's perspective, two methods are called, as follows:
The default constructor
DataPortal_Delete()
Figure 4-15 illustrates the process of immediate deletion.
Since this causes the deletion of a root object, the delete process must also remove any data for child objects. This can be done through LINQ to SQL, ADO.NET data access code, a stored procedure, or by the database (if cascading deletes are set up on the relationships). In the example application for this book, child data is deleted by the stored procedures created in Chapter 3.
When using the ObjectFactory attribute, the business developer is responsible for authoring two classes: the factory class and the business class. The factory class must implement a delete method that deletes the data for the business object and any child objects.

Deferred Deletion
Deferred deletion occurs when the business object is loaded into memory and the UI calls a method on the object to mark it for deletion. Then when the Save() method is called, the object is deleted rather than being inserted or updated.
The sequence of events flows like this:
The object is loaded by the UI.
The UI calls a method to mark the object for deletion (that method must call
MarkDeleted()).The UI calls the object's
Save()orBeginSave()method.The save method invokes the data portal just like it does when doing an insert or an update (as discussed earlier in this chapter).
The data portal does one of the following:
When not using an
ObjectFactoryattribute, typically, theDataPortal_DeleteSelf()method calls the object'sDataPortal_Delete()method, which contains the code needed to delete the object's data (and any related child data, etc.).When using an
ObjectFactoryattribute, the data portal creates an instance of the specified object factory class and invokes the specified delete method. This delete method contains the code needed to delete the business object's data, along with any related child data.
When not using an ObjectFactory attribute, from the business object's perspective, one method is called: DataPortal_DeleteSelf().
Earlier in the chapter, Figure 4-12 showed the process of saving a root object; it also depicts deferred deletion.
When an ObjectFactory attribute is specified on the business class, the business developer must provide both a factory class and the business class. The factory class must implement a delete method that removes the business object's data, along with any child object data.
The CSLA .NET framework supports both deletion models to provide flexibility for the UI developer. It is up to the business object author to decide which model to support by implementing either a static or instance delete method on the object.
Most business objects contain moderate amounts of data in their fields. For these, the default .NET garbage collection behavior is fine. With that behavior, you don't know exactly when an object will be destroyed and its memory reclaimed. But that's almost always OK because it is exactly what garbage collection is designed to do.
However, the default garbage collection behavior may be insufficient when objects hold onto "expensive" or unmanaged resources until they're destroyed. These resources include things such as open database connections, open files on disk, synchronization objects, handles, and any other objects that already implement IDisposable. These are things that need to be released as soon as possible in order to prevent the application from wasting memory or blocking other users who might need to access a file or reuse a database connection. If business objects are written properly, most of these concerns should go away. Data access code should keep a database connection open for the shortest amount of time possible, and the same is true for any files the object might open on disk. However, there are cases in which business objects can legitimately contain an expensive resource—something like a multimegabyte image in a field, perhaps.
Implementing IDisposable
In such cases, the business object should implement the IDisposable interface, which will allow the UI code to tell the business object to release its resources. This interface requires that the object implement a Dispose() method to actually release those resources:
[Serializable] public class MyBusinessClass : BusinessBase<MyBusinessClass>,IDisposable{private bool _disposedValue;protected void Dispose(bool disposing){if (!_disposedValue)if (disposing){// free unmanaged resources}// free shared unmanaged resources_disposedValue = true;}public void Dispose(){Dispose(true);GC.SuppressFinalize(this);}~MyBusinessClass(){Dispose(false);}}
The UI code can now call the object's Dispose() method (or employ a using statement) when it has finished using the object, at which point the object will release its expensive resources.
Careful Object Disposal
If a business object is retrieved using a remote data portal configuration, the business object will be created and loaded on the server. It's then returned to the client. The result, however, is that there's a copy left in memory on the server. Because of this, there's no way to call the business object's Dispose() method on the server. To avoid this scenario, any time that the data portal may be configured to run outside of the client process, the business object designs must avoid any requirement for a Dispose() method.
Note
If you're calling a remote data portal, you must avoid object designs that require IDisposable. Alternatively, you can modify the SimpleDataPortal class to explicitly call Dispose() on your business objects on the server.
Also, if a business object is retrieved using a local data portal configuration, the business object will be cloned, and the clone is what is actually saved and returned to the client. The result is that there's a copy left in memory on the client.
If you implement IDisposable in your business object and use a local data portal configuration, your UI code must call Dispose() on the original object if the Save() call is successful, and you'll have to modify the client-side DataPortal class to call Dispose() on the clone if an exception occurs during the update process. Happily, these are almost never issues you'll face with a properly designed business object because all database connections or open files should be closed in the same method from which they were opened.
As you've seen, business objects follow the same sequence of events for creation, retrieval, and updates. Because of this, there's a structure and a set of features that are common to all of them. Although the structure and features are common, the actual code varies for each business object. Due to the consistency in structure, however, there's great value in providing some foundations that make it easier for the business developer to know what needs to be done.
Also, there are differences between editable and read-only objects and between root and child objects. After discussing the features common to all business objects, which I do next, I'll create "templates" to illustrate the structure of each type of business object that you can create based on CSLA .NET.
There are some common features or conventions that should be followed when coding any business classes that will inherit from the CSLA .NET base classes. These are as follows:
SerializableorDataContractattributeCommon regions
Non-
publicdefault constructor
Let's briefly discuss each of these requirements.
All business objects must be unanchored so that they can move across the network as needed. This means that they must be marked as serializable by using the Serializable attribute, as shown here:
[Serializable]public class MyBusinessClass{}
This is required for all business classes that inherit from any of the CSLA .NET base classes. It's also required for any objects that are referenced by business objects. If a business object references an object that isn't serializable, you must be sure to mark its field with the NonSerialized attribute to prevent the serialization process from attempting to serialize that object. If you don't do this, the result will be a runtime exception from the .NET Framework.
Alternately you can use the DataContract attribute, as shown here:
[DataContract]public class MyBusinessClass{}
The DataContract attribute is part of WCF. WCF includes two serialization engines: DataContractSerializer and NetDataContractSerializer (NDCS). Both of these engines support two new attributes: DataContract and DataMember.
DataContractSerializer can be thought of as the replacement for the older XmlSerializer. This serializer is primarily designed to support service-oriented scenarios by creating and consuming SOAP-compliant XML blobs. Not all types or object graphs can be serialized using this component.
NetDataContractSerializer can be thought of as the replacement for the older BinaryFormatter. This serializer is primarily designed to support client/server or n-tier scenarios by providing full fidelity for even complex .NET data types. Any Serializable or DataContract type (or object graph of Serializable or DataContract types) can be serialized using this component. Only the NDCS is pertinent to this discussion because CSLA .NET uses the BinaryFormatter and only NDCS provides comparable functionality in WCF.
The DataContract attribute is somewhat like the Serializable attribute, in that it marks an object as being eligible for serialization by one of the new serializers. The Serializable attribute uses an opt-out model, where all fields are serialized unless you explicitly mark the field with the NonSerialized attribute. DataContract, on the other hand, uses an opt-in model, where fields (or properties) are only serialized if you explicitly mark them with the DataMember attribute.
The BinaryFormatter, of course, only understands the Serializable attribute. If you only mark a class with DataContract, the BinaryFormatter will throw an exception because it views the object as not being serializable.
The NDCS understands both the DataContract and Serializable attributes. This means that you can use NDCS to serialize objects that are Serializable, objects that are a DataContract, and even object graphs composed of both types of objects at once. This makes sense because all the core .NET types to date are Serializable, not DataContract. They can't be changed without massive repercussions throughout the existing .NET Framework itself. Any serializer intended to replace the BinaryFormatter must do what the BinaryFormatter does, and then do more.
When to Use DataContract
Given that DataContract and Serializable provide the same functionality, though with an opt-in or opt-out philosophy, the obvious question is when to use each option. Or to be blunt: when should anyone use DataContract?
In general, I don't recommend switching from Serializable to DataContract. For most business objects, the desired behavior is to include all fields when an object is serialized, and so the opt-out model used by Serializable is better.
If you use the opt-in model of DataContract, it is too easy to forget to put the DataMember attribute on a field, in which case that field is ignored when the object is serialized. The resulting bug can be difficult to discover and debug.
You should also be aware that WF uses the BinaryFormatter to serialize objects when a workflow is suspended. If you intend to use your business objects within a workflow, you should avoid using DataContract to ensure that your objects can be serialized if necessary.
The DataContract and DataMember attributes are designed to support service-oriented design. In Chapter 21, I show how you can build service-oriented WCF services. That is the appropriate place for using these attributes.
CSLA .NET directly uses the BinaryFormatter in only a few places: when cloning an object graph, in the n-level undo implementation, and in some of the data portal channels.
CSLA .NET does support the optional use of DataContract when cloning an object graph and when using n-level undo. To do this, CSLA .NET must use the NDCS instead of the BinaryFormatter to do any explicit serialization.
Configuring CSLA .NET to Use NetDataContractSerializer
You must configure CSLA .NET to use NDCS rather than the BinaryFormatter. Because I believe the opt-out model is better for business object development, the default is to use the BinaryFormatter.
Tip
I recommend that you only configure CSLA .NET to use the NDCS if you use the DataContract attribute instead of the Serializable attribute in your business classes.
To configure CSLA .NET to use the NDCS you must add an element to the appSettings of your app.config or web.config file:
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
<appSettings>
<add key="CslaAuthentication" value="Csla" />
<add key="CslaSerializationFormatter" value="NetDataContractSerializer"/>This will cause both the clone and n-level undo implementations in CSLA .NET to use NDCS. The result is that you can use the DataContract attribute instead of or in combination with the Serializable attribute in your business classes.
Note that only the WCF data portal channel uses the NDCS, so if you use the DataContract attribute in your business objects you cannot use any of the older data portal channels.
Warning
If you are using the DataContract and DataMember attributes in your business classes, you can only use the local or WCF data portal channels. The Remoting, Web Services, and Enterprise Services channels will all throw serialization exceptions if you attempt to use them.
The important thing to remember is that all business classes must use Serializable or DataContract to work with CSLA .NET. Throughout the rest of the book I assume the use of the Serializable attribute.
When writing code in VS .NET, the #region directive can be used to place code into collapsible regions. This helps organize the code and allows you to look only at the code pertaining to a specific type of functionality.
All business collection classes have a common set of regions, as follows:
Factory Methods
Data Access
And so classes derived from BusinessListBase and ReadOnlyListBase follow this basic structure:
[Serializable]public class MyCollectionClass : Csla.baseclass<MyCollectionClass, MyChildType>{#region Factory Methods#endregion#region Data Access#endregion}
The one exception to this is when you use the ObjectFactory attribute on the business class, in which case there would be no Data Access region because that code would be in a separate object factory class.
All noncollection (editable and read-only) classes have the following set of regions:
Business Methods
Business and Validation Rules
Authorization Rules
Factory Methods
Data Access
This means that the skeletal structure of a business object, with these regions, is as follows:
[Serializable]public class MyBusinessClass : Csla.baseclass<MyBusinessClass>{#region Business Methods#endregion#region Business and Validation Rules#endregion#region Authorization Rules#endregion#region Factory Methods#endregion#region Data Access#endregion}
The one exception to this is when you use the ObjectFactory attribute on the business class, in which case there would be no Data Access region because that code would be in a separate object factory class.
Command objects that inherit from CommandBase have the following regions:
Authorization Rules
Factory Methods
Client-side Code
Server-side Code
[Serializable]public class MyCommandClass : Csla.CommandBase{#region Authorization Rules#endregion#region Factory Methods#endregion#region Client-side Code#endregion#region Server-side Code#endregion}
The one exception to this is when you use the ObjectFactory attribute on the business class, in which case there would be no Server-side Code region because that code would be in the update method of a separate object factory class.
Name/value list objects that inherit from NameValueListBase will typically have the following regions:
Factory Methods
Data Access
[Serializable]public class MyListClass : Csla.NameValueListBase<KeyType, ValueType>{#region Factory Methods#endregion#region Data Access#endregion}
The one exception to this is when you use the ObjectFactory attribute on the business class, in which case there would be no Data Access region because that code would be in a separate object factory class.
And objects that inherit from EditableRootListBase will typically have the following regions:
Factory Methods
Data Access
[Serializable]public class MyListClass : Csla.EditableRootListBase<MyRootType>{#region Factory Methods#endregion#region Data Access#endregion}
Again, the one exception is when you use the ObjectFactory attribute on the business class; there would be no Data Access region in this case either.
The Business Methods region contains the methods that are used by UI code (or other client code) to interact with the business object. This includes any properties that allow retrieval or changing of values in the object as well as methods that operate on the object's data to perform business processing.
The Business Rules region contains the AddBusinessRules() method and any custom validation or business rule methods required by the object.
The Authorization Rules region contains the AddAuthorizationRules() and AddObjectAuthorizationRules() methods.
The Factory Methods region contains the static factory methods to create or retrieve the object, along with the static delete method (if the object is an editable root object). It also contains the default constructor for the class, which must be scoped as non-public (i.e., private or protected) to force the use of the factory methods when creating the business object.
The Data Access region contains the DataPortal_XYZ or Child_XYZ methods, unless you use the ObjectFactory attribute, in which case any code that would have been in the DataPortal_XYZ methods is in a separate object factory class.
Your business objects may require other code that doesn't fit neatly into these regions, and you should feel free to add extra regions if needed. But these regions cover the vast majority of code required by typical business objects, and in most cases they're all you'll need.
Object Factory Classes
Any root business object can specify an ObjectFactory attribute, which causes the data portal to change its behavior. Rather than directly interacting with the business object, the data portal creates an instance of an object factory class and it interacts with that factory object.
Applying the ObjectFactory attribute is straightforward:
[ObjectFactory("Factories.MyFactory,Factories")]
[Serializable]
public class MyBusinessClass : Csla.baseclass<MyBusinessClass>The parameter passed to the attribute is an assembly-qualified type name for the object factory class. An instance of this class is created by the data portal.
Note
It is possible to provide an object factory loader, which is a class you implement to create the factory object. If you do this, your object factory loader can interpret the string parameter to ObjectFactory in any way you choose. Use the CslaObjectFactoryLoader configuration setting in appSettings to specify the assembly-qualified type of your object factory loader, which must implement Csla.Server.IObjectFactoryLoader. The default object factory loader is Csla.Server.ObjectFactoryLoader.
You may also specify, as string values, the names of the create, fetch, update, and delete methods that should be invoked on the factory object. By default, the data portal invokes methods named Create(), Fetch(), Update() and Delete(), which must be implemented in the object factory class.
An object factory class looks like this:
public class MyFactory : Csla.Server.ObjectFactory{public object Create(){}public object Fetch(SingleCriteria<MyBusinessClass, int> criteria){}public object Update(object obj){}public void Delete(SingleCriteria<MyBusinessClass, int> criteria){}}
As with the DataPortal_Create(), DataPortal_Fetch(), and DataPortal_Delete() methods, you may implement multiple overloads of the Create(), Fetch(), and Delete() methods, and the data portal will invoke the correct overload based on the parameters provided when the data portal is first called.
Inheriting from the ObjectFactory base class is optional but useful. The factory object is responsible for creating and manipulating the business object, including managing the business object's state values as I discuss in Chapter 18. The ObjectFactory base class provides the protected methods listed in Table 4-3 to assist in this process.
Table 4.3. Protected Methods Supplied by ObjectFactory
Method | Description |
|---|---|
| Marks the business object as being a new object |
| Marks the business object as being an old (preexisting) object |
| Marks the business object as a child object |
See Chapter 7 for a detailed discussion of these terms and concepts. For now you should understand that inheriting from ObjectFactory makes these methods available, and if you choose not to inherit from ObjectFactory, you'll have to develop your own mechanism for managing the states of your business objects.
All business objects will be implemented to make use of the class-in-charge scheme discussed in Chapter 1. Factory methods are used in lieu of the new keyword, which means that it's best to prevent the use of new, thereby forcing the UI developer to use the factory methods instead.
The data portal mechanism requires business classes to include a default constructor. As I reviewed the create, fetch, update, and delete processes for each type of object earlier in this chapter, each sequence diagram showed how the server-side data portal created an instance of the business object. This is done using a technique that requires a default constructor.
By making the default constructor private or protected (and by not creating other public constructors), you ensure that UI code must use the factory methods to get an instance of any object:
// ... #region Factory Methodsprivate MyBusinessClass(){ /* require use of factory methods */ }#endregion // ...
This constructor both prevents the new keyword from being called by code outside this class and provides the data portal with the ability to create the object via reflection. Your classes might also include other non-public constructors, but this one is required for all objects.
This chapter discussed the basic concepts and requirements for all business classes based on CSLA .NET. I discussed the life cycle of business objects and walked through the creation, retrieval, update, and delete processes.
The basic structure of each type of business class was covered at a high level. There are common requirements, including making all the classes Serializable, implementing a common set of code regions for clarity of code, and including a non-public constructor. I continue that discussion in Chapter 5 by walking through the kind of code that goes into each code region for the different object stereotypes. Then Chapters 6 through 16 cover the implementation of the CSLA .NET framework that supports these stereotypes.
Finally, Chapters 17 through 21 show how to use these stereotypes and the framework to construct the Project Tracker application described in Chapter 3.