
Chapter 4
Content Providers
WHAT’S IN THIS CHAPTER?
- Using content providers
- Publishing a contract: URIs and types
- Implementing a content provider
- Controlling access to your content provider with permissions and registration
- Understanding content provider file operations
WROX.COM CODE DOWNLOADS FOR THIS CHAPTER
Please note that all the code examples in this chapter are available at https://github.com/wileyenterpriseandroid/Examples.git and as a part of the book’s code download at www.wrox.com on the Download Code tab.
Content providers are the foundation for the rest of this book. In this chapter you will meet content providers and the tools used to build them. In addition you are introduced to the REST-like architecture they support and how that architecture enables the use of Android in the enterprise. The application created in this chapter can be found in the project KeyValCP.
The techniques introduced in the previous chapter — creating a globally accessible reference to a database object — might be appropriate for a small application. In more complex applications, however, developers will require better architectural separation between data management and other components of their application.
The Android content provider framework has several parts:
- Contract — A Java source file that publishes symbols and constants that external processes need to access the provider. External applications include this file as part of their source.
- Content Resolver — A part of the Android library that uses system-level services to identify the single content provider currently registered as the manager of the dataset corresponding to a given URI. The URI is typically obtained from the contract.
- Content Provider — The content resolver forwards requests to a content provider. The provider manages a dataset, supplying clients with a consistent view of the data and managing their access to it.
- Content Observer — The content observer API supports a URI-based notification system, which makes it possible for clients to discover changes in the dataset.
The investigation of content providers starts with a review of their use. Approaching the new component from the top down reveals some interesting architectural issues and motivates the discussion of its implementation that comprises the remainder of the chapter.
USING A CONTENT PROVIDER
The final example in Chapter 3 quietly introduced a content provider: It is the source of the data that is displayed through the simple cursor adapter in the list view. The example code is deceptively simple — it slides the content provider into the example with very little comment. Reexamining the code carefully, though, you can infer some of the essential architectural details of the content provider. There are four of them, as follows.
URIs as Names for Virtual Datasets
Listing 4-1 shows an excerpt from the “Loaders” section of the previous chapter. It’s just the snippet in which the cursor loader is created.
LISTING 4-1: Creating a CursorLoader
@Override
public Loader<Cursor> onCreateLoader(int id, Bundle params) {
return new CursorLoader(
this,
KeyValContract.URI,
null, null, null, null);
}There must be a query to the content provider hidden inside the cursor loader created here, because the loader eventually produces a cursor. In order to understand how that might work, let’s review the formal parameters for the CursorLoader constructor. They are:
CursorLoader(
Context context,
Uri uri,
String[] projection,
String selection,
String[] selectionArgs,
String sortOrder)This should look familiar. Most of the parameters are very similar to those shown in Chapter 3, Listing 3-1. They are the parameters required by the database query method. This cursor loader has — as you might expect — enough information to identify some data source and to perform a query against it. Chapter 3 demonstrated that the cursor created by the loader is passed as the argument to the callback method onLoadFinished. In the KeyVal example that returned cursor was used to power the list view that is the application’s main screen.
While most of the parameters to the two methods (the loader constructor and the database query method) are identical, notice that the database query method (shown in Chapter 3) is a method on a SQLite database object. It takes as its first argument the name of a database table. The first parameter to the loader constructor is instead a URI. If the cursor loader is going to be able to construct a complete query from its parameters, there must be some way for it to identify a database — and a table within that database — from the URI.
This is the first important architectural feature of the content provider: URIs are used as abstract names for virtual datasets. Content providers are identified indirectly, using the URIs that name them. Android reserves URIs with the canonical scheme content:// for this purpose. The protocol by which a content provider registers the owner of a particular group of URIs is discussed in detail later in this chapter. For now, let’s return to exploring the behavior of a content provider by observing it in use.
Content Resolvers: The Link between Clients and Providers
In the example code as it stands, the content provider is used entirely behind the scenes in the cursor loader. All of the details are hidden in its implementation. Adding a new feature to the application will help to reveal some of those details. The implementation of this new feature, a data insert, is very similar to the implementation of the query, shown previously. It moves one step closer to the content provider, though, and requires writing code that was hidden in the loader in that example.
To the application UI, add a pair of text fields and a button, which, when pushed, inserts the contents of the text fields into the database as a new key/value pair. Listing 4-2 shows the essentials of the implementation of the new feature. Only the snippet of code that actually uses the content provider is shown here — as noted, the complete code for all of the examples in the chapter, as well as the rest of the book, are available as a part of this book’s download at www.wrox.com.
LISTING 4-2: Using ContentResolver insert
private static class AsyncInsert extends AsyncTask<Void, Void, Void> {
private final Context ctxt;
private final String key;
private final String val;
public AsyncInsert(Context ctxt, String key, String val) {
this.ctxt = ctxt;
this.key = key;
this.val = val;
}
@Override
protected Void doInBackground(Void... params) {
ContentValues values = new ContentValues();
values.put(KeyValContract.Columns.KEY, key);
values.put(KeyValContract.Columns.VAL, val);
try {
ctxt.getContentResolver()
.insert(KeyValContract.URI_KEYVAL, values);
}
catch (Exception e) { Log.w("INSERT", "Insert failed", e); }
return null;
}
}Because database access is a relatively slow operation, it cannot be performed from the UI thread. The implementation of the new feature must call the content resolver’s — and thereby the content provider’s — insert method from a non-UI thread. The cursor loader, in its implementation, does exactly the same thing for the query method. AsyncInsert, the class from which the insert call is performed, is based on an AsyncTask, as is the loader.
The new feature uses a new button, added to the view, to submit the new key/value pair for insertion into the database. The code in the button’s onClick method (not shown) creates a new instance of the AsyncInsert task and executes it. Unlike the query example, this simple insert is fire-and-forget. The insert task does not return a result and, unlike the loader, does not need a way to notify anyone of its completion. The code in AsyncInsert.doInBackground — the business end of the AsyncInsert class — should look entirely familiar. It is nearly identical to the database insert method, described in Chapter 3. As in the previous examination of the cursor loader, you can infer that the name of the table into which the new values are to be inserted must be encoded in the URI passed as the first argument to the insert method. The new tool introduced here is the ContentResolver. It is obtained from the context. The insert method used to add the new key/value pair to the database is a method on this new object.
From this new feature you might deduce that content providers are not, typically, used directly through object references. You do not normally obtain a reference to a content provider object and then call methods on it. Instead, as demonstrated in this code, you obtain a content resolver object from the context and then use it to forward requests to the content provider.
If you were to examine the code for the CursorLoader, you would find that, internally it uses the parameters passed to its constructor to make an analogous call to ContentResolver.query. This is the second important architectural artifact in the content provider framework. The content resolver is the tool that resolves a content URI into a connection to a specific content provider.
Content Observers: Completing the Loop
The next important architectural feature of a content provider is also already part of the example application and is also hidden in the loader. The application as implemented thus far looks like Figure 4-1 when it’s run.

Pressing the Add button causes the display to update so that it looks like Figure 4-2.

This is exactly what should happen. On the other hand, it is a little surprising that it does! Consider that the example code obtained one specific cursor from one specific query to the database and then associated that cursor with the displayed list view. That cursor contains data from a query that was made before the new key and value were added to the database. Why did the new database row become visible in the list view? How did the list view discover that something had changed and that an update was necessary?
The answer is another content resolver method called registerContentObserver. The parameters to this method are:
registerContentObserver(
Uri uri,
boolean notifyForDescendents,
ContentObserver observer))By this time, you may be expecting the URI argument. Its meaning here, though, is quite ingenious. The registerContentObserver method allows an object to register as a listener for changes, but not changes to a particular database, a particular table, or even a particular content provider. Instead, it registers the listener for notification of any changes that affect a particular URI. Using a URI to represent a dataset is a very powerful concept. Listing 4-3 shows how to add a little bit more code to the example application to demonstrate the function of a content observer.
LISTING 4-3: Registering a content observer
getContentResolver().registerContentObserver(
KeyValContract.URI,
true,
new ContentObserver(null) {
public void onChange(boolean selfChange) { toast.show(); }
});This new snippet registers a new content observer with the context’s content resolver. Notice that, unlike many of the callback registration methods in the Android framework (such as setOnClickListener), the registerContentObserver method supports the registration of multiple observers.
This new code uses a Toast — Android’s simple means of briefly displaying a small asynchronous message — to provide notification when it receives the onChange callback. When this code is added to the example, pressing the Add button causes the display, after a very brief pause, to look like Figure 4-3.
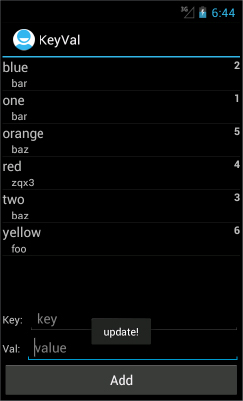
Notice the little “update!” message at the bottom of the display. It was generated in the newly added observer.
The new observer is registered to listen to the same URI that is the target of both the query and insert calls already part of the example. The call to insert changes the dataset that backs that URI and that causes the new observer to be notified.
A similar observer, registered by the cursor loader, causes the list view to be updated. If you were to examine the internals of the cursor loader, you would find that when it obtains a cursor from the database, it registers through a chain of listeners (loader manager to loader, to cursor, to content resolver) as an observer for this same URI. Any change to the underlying dataset that generates a notification to that URI will alert the loader manager that it must requery the database and create a new cursor with the updated data.
Here is a partial log from a run of the example program. It provides a little more insight into what is going on:
10-09 18:18:58.812: D/LOADER(768): onCreateLoader
10-09 18:18:59.663: D/LOADER(768): onLoadFinished
10-09 18:20:16.723: D/INSERT(768): button click!
10-09 18:20:16.843: D/LOADER(768): onLoadFinishedThe first line shows the loader manager calling the example activity’s onCreateLoader method to create a loader. The manager uses the new loader to get a cursor from the content provider (the loader’s query method is run in the background and returns the cursor). Once it has the cursor, the manager calls the activity’s onLoadFinished method, creating the second line in the log. The entire process — creating the loader and using it to obtain a cursor — takes almost a second on an emulator. At this point, the load is complete and the cursor data is visible through the list view.
Almost a minute later, the log registers a click on the Add button. About a quarter of a second later, there is second call to onLoadFinished. This second call is the result of the following steps:
IPC: System-Wide Accessibility
The last important architectural feature supported by content providers is perhaps the most significant. It is the ability to use them no matter where they are on the system. All of the previous examples use URIs to identify specific content providers. They interact with a specific dataset: obtaining or updating data or receiving update notifications based solely on the URI. At no time does anything in the code indicate whether the target content provider is bundled as part of the activity’s application, part of some other application, or a part of some system service.
This exact code works equally well regardless of which application, user, or process owns the content provider. This ability to identify data by its name instead of by the specific object that happens to provide it makes the content provider a powerful tool for extensibility in the enterprise environment. The example code for this chapter includes a second application, the KeyValClient, which is nearly an exact copy of the UI sections of the KeyVal application. It does not, however, include any of the data management sections. As long as the KeyVal application — the app that registers the content provider — is installed on a target device, KeyValClient will also run. It uses the content provider from the other application.
Now that you’ve seen what a content provider looks like from the client side, it’s time to implement one. There are four key parts to a content provider:
- The contract
- CRUD methods and database management
- Content observers
- Registration and permissions
THE CONTRACT: URIS AND TYPES
Because content providers are intended for use across application — and here the term application is intended to mean a compilation unit — there must be some way of describing the provider’s protocol to all of its clients. In order for other applications to interact with a given content provider, they must know its URI at the very least. By convention, they do this by including a small source file called the contract.
A contract is a Java source file that simply defines some global symbols (constants) needed by clients that want to use the provider. The file usually contains no methods and is based on the standard Java idiom for a namespace used only for symbol definition — an uninstantiable class with a private constructor. Also by convention, a content provider’s contract has the name of the content provider, with the suffix Contract.
The example content provider, the KeyValContentProvider, has a contract called KeyValContract. It is shown in its entirety in Listing 4-4.
LISTING 4-4: The contract
public final class KeyValContract {
private KeyValContract() {}
public static final int VERSION = 1;
public static final String AUTHORITY
= "com.enterpriseandroid.database.keyval";
private static final Uri URI_BASE
= new Uri.Builder()
.scheme(ContentResolver.SCHEME_CONTENT)
.authority(AUTHORITY)
.build();
public static final String TABLE_VALS = "vals";
public static final Uri URI_VALS
= URI_BASE.buildUpon().appendPath(TABLE_VALS).build();
public static final String TYPE_VALS
= ContentResolver.CURSOR_DIR_BASE_TYPE
+ "/vnd.com.enterpriseandroid.database.val";
public static final String TYPE_VAL
= ContentResolver.CURSOR_ITEM_BASE_TYPE
+ "/vnd.com.enterpriseandroid.database.val";
public static final String TABLE_KEYVAL = "keyval";
public static final Uri URI_KEYVAL
= URI_BASE.buildUpon().appendPath(TABLE_KEYVAL).build();
public static final String TYPE_KEYVALS
= ContentResolver.CURSOR_DIR_BASE_TYPE
+ "/vnd.com.enterpriseandroid.database.keyval";
public static final String TYPE_KEYVAL
= ContentResolver.CURSOR_ITEM_BASE_TYPE
+ "/vnd.com.enterpriseandroid.database.keyval";
public static final class Columns {
private Columns() {}
// vals table columns
public static final String ID = BaseColumns._ID;
public static final String VAL = "val";
// the keyval table has the following columns,
// in addition to those above
public static final String KEY = "key";
public static final String EXTRA = "extra";
}
public static final class Permission {
private Permission() {}
public static final String READ
= "com.enterpriseandroid.database.keyval.READ";
public static final String WRITE
= "com.enterpriseandroid.database.keyval.WRITE";
}
}Authority
The first item to notice — the most important part of the contract — is the authority string. The authority is the namespace for the data owned by this content provider. Although it can be any string at all as long as it is unique, by convention it starts with the reversed Internet domain name of the owner.
The Android system will not allow two content providers to be registered simultaneously as authorities for any single data namespace. The process by which content providers register their authority is described later in this chapter in the section on registration and permissions. An attempt to register a second content provider as authority for the same namespace will cause an error.
Here, for instance, is what happens to an attempt to use Android’s standard debugging tool, adb, to install a second application that contains a conflicting registration for the authority already registered by the previously installed KeyVal example:
adb install KeyValConflict.apk
1790 KB/s (29937 bytes in 0.016s)
pkg: /data/local/tmp/KeyValConflict.apk
Failure [INSTALL_FAILED_CONFLICTING_PROVIDER]
Within the namespace, a content provider may maintain any number of virtual tables. A table is simply the relation described in Chapter 2 — a rectangular array of data in which each tuple (row) contains data for each of the table’s attributes (columns). As noted previously, the Android architecture does not include the ORM layer that developers accustomed to enterprise programming might expect. Instead of an object model for data, Android uses the relational model consistently from its backend persistent storage mechanisms, all the way up to the UI.
A discussion of relational table model and contract API is as good a place as any to pause and revisit Android’s use of the relational model. Architecturally, it is certainly a plausible decision. The relational model of data is sound, flexible, and well understood. Using it from the bottom of the stack all the way through to the top clearly reduces copy costs. On the other hand, experienced backend developers will smell a rat.
The most compelling arguments against the pervasive use of the relational model have to do with the specific implementation: the mutability of the cursor object. Moving the cursor’s row pointer (its cursor) is an essential part of using it. At the very least, client code must have a protocol establishing ownership of the cursor’s row pointer. Perhaps more important, it is essentially impossible to make a cursor thread-safe. Android’s creators apparently felt the trade-off was worth it.
It is certainly possible to layer an ORM over the Android relational model. Just as certainly, there are commercial and OSS frameworks that do exactly that. Under some circumstances this may be desirable. There are, however, two fairly strong arguments against the general use of this type of architecture.
The first argument is that the cursor is very well integrated into Android’s super-fast interprocess communication mechanism. Although implementing your own cross-process data communication mechanism is simply a matter of programming, it is a matter of a lot of programming. More important, only applications that embed the entire client half of your custom mechanism have access to the data. Content resolvers support content providers and cursors, not their extensions.
A second reason for learning to live with the relational model is that the environment around cursors and the relational model they represent is well used. Chapter 3 demonstrated a very typical list view: It used a cursor all the way up to the UI glass. This architecture helps make the list view quick and responsive. We noted, at the time, that it isn’t absolutely necessary to hand the list view a cursor. We also noted, though, that the tools for working with cursors, the CursorLoader and the SimpleCursorAdapter, are mature and well documented even if the super-classes they specialize in are not. We do not recommend replacing, subclassing, or wrapping cursors.
The contract contains an internal namespace, Columns, that defines the names of the columns in the virtual tables. These are the names of the columns that will appear in a cursor obtained from the content provider. As usual, these names need not be the names of actual columns in any actual database. There is a pretty good argument that revealing the actual names of your tables gives clients too much information about the internal implementation of the content provider.
The KeyVal example is very simple and does expose actual column names. It also has only one set of column names that apply to the columns in both of its virtual tables. Were this not the case, it might have been necessary to define separate inner namespaces for each of the tables or perhaps to define two entirely separate contracts.
Virtual Table URIs
The next important item in the contract is the URI. By convention, a content provider URI looks like Figure 4-4.
The first portion of the URI, the scheme, is always content://. As noted previously, Android reserves this scheme for content providers and all content provider URIs must use it.
The next portion of the URI is the authority. It is the unique name for the dataset, as described previously.
The last section of the URI, the path, is typically the name of a virtual table maintained by the content provider. The virtual table named by a path need not correspond to a physical table in a SQLite database. There is no reason that it needs to correspond with anything in any particular database. A content provider is free to use any convenient storage mechanism — SQLite tables, a directory tree on the file system, or even values obtained from some external hardware sensor — to back its virtual table.
The content provider in the KeyVal example supports two virtual tables: vals, which maps directly to a SQLite table, and keyval, which is a virtual table created from a join of the SQLite keys and vals tables. The URIs for the two virtual tables are:
content://com.enterpriseandroid.database.keyval/vals
content://com.enterpriseandroid.database.keyval/keyvalsIn the KeyVal contract these URIs are constructed from the base URI using the handy URI.Builder class.
The ID portion of a content provider URI is an integer. If a URI contains an ID, the URI refers to a specific, single row in the virtual table named in the path. The ID is meant to act as a primary key into the virtual table.
The path/ID portion of a URI may be arbitrarily complex. One can imagine, for instance, a URI that looks like this:
content://com.android.contacts/contacts/52/phone/2a request for the second phone number of the contact whose ID is 52. Although convention — and even some past documentation — suggest this kind of path, the tools to support it are at best immature.
Return Value MIME Types
A content provider’s virtual table contains data of a particular type, defined by the relational attributes — the columns — in the cursor it returns. The content provider framework includes a protocol that allows providers to specify that type and a provider’s contract should define them for each of its tables. Content provider types are simply MIME types (strings that have the format type/subtype).
The type portion of a content provider MIME type is determined by a strong convention. If the query specifying the returned data is semantically constained so the the returned cursor contains 0 or 1 rows — it is a query that specifies a unique row — the major type of the returned value must be vnd.android.cursor.item. For example, a query that specifies a primary key for the table it references cannot return more than one row. It should, therefore, return the item type. If, on the other hand, the cursor might contain any number of rows (0 to n), the returned major type is vnd.android.cursor.dir. A content provider should be able to tell, simply by examining a URI, whether that URI is legal and whether it is bound to return at most one row from the database.
The subtype portion of the type is defined, entirely, by the service providing the data. For very simple one column data, it might make sense to use one of the standard MIME subtypes: html, jpeg, mpeg3, and so on. By convention, however, any complex (multi-column) data should have its own unique type and that type should begin with the string "vnd.". The KeyVal example defines two tables and, therefore, four MIME types: item and dir for each. Since the contents of the dir and item cursors are the same for a given table, the subtypes for both of the MIME types for that table are also the same.
Permissions
The last set of definitions in a contract comprises the permissions that a client application must request, in order to get access to the provider’s dataset. As you will see toward the end of this chapter, permissions are simple strings used in the application’s manifest file. They do not typically appear in code. It might be perfectly reasonable to document the permissions in a comment, instead of as symbol definitions.
One reasonable approach — used in the actual code for the KeyValContract but excluded here to save space — is to include in the contract the excerpt from the manifest that declares, defines, and applies permissions to the content provider.
Publishing the Contract
It probably goes without saying that designing a content provider’s API and the contract that defines it can be a tricky job. There are no constraints and barely any conventions controlling what a content provider can or can’t do when it translates URIs into references to the dataset it controls. As usual, APIs that take full advantage of the flexibility of the interface tend to be less useful, in the long run, than those that are simpler and more consistent. The architect of a content provider API could do much worse than to take advice from two specific sources:
- Android’s Contacts API — The first design for the Contacts API is an excellent example of a pretty good interface that simply did not support the flexibility that was eventually necessary. The new API is considerably more complex but quite flexible.
- RESTful client/service architecture — The construction and use of APIs that support scalable, stateless, and cacheable data communications are the topic of the rest of this book.
No matter how you choose to implement your contract, remember that it is the only means you have for communicating to potential clients the API that your content provider exposes. The contract file is the place to document exactly how your content provider works. It should contain comments describing the details of your API, including what exceptions it might throw and under what conditions it might throw them, use cases you do not intend to support, even in the long run, and so on.
The Android content provider framework doesn’t really support API versioning in any meaningful way. If you ever have to change the contact provider’s API, you will probably have to create a new authority and support both the old and the new, distinguishing them by URI.
Once you have a well-designed and documented contract, publish it. If you are targeting a specific enterprise, you will use the internal source control system or repository to publish the contract file. If you are targeting a general audience, you might use one of the popular code-sharing sites like GitHub or SourceForge.
IMPLEMENTING THE CONTENT PROVIDER
You’ve now seen how to use a content provider and how to publish its API. The next step it to implement its CRUD methods — create, insert, update, and delete. This section examines the code that does that for the content provider you’ve been considering so far in this chapter — KeyVal.
In the process of creating the content provider CRUD methods, there are a few architectural issues that a developer must keep in mind. As usual when building Android components, one of the most important of these is understanding the component lifecycle and which methods are run on which threads.
A content provider’s onCreate method is always run on the UI thread of the application to which it belongs. This means that it must not undertake any long-running initialization. Fortunately, the framework guarantees that creating a SQLiteDatabaseHelper object is a fast operation — the onCreate method may create an instance of the helper.
It may not, however, use the instance to obtain a database instance! As noted previously, obtaining the actual database instance may require rebuilding a database’s entire schema and repopulating it with data. That is an operation far too slow to be run on the UI thread.
All of the other externally visible methods in the content provider may be called from multiple threads. When used from the application that defines the provider, they will probably be invoked from an AsyncTask — perhaps explicitly, or perhaps using a loader — and thus run on one of several daemon threads in the AsyncTask’s executor’s thread pool. When called from other applications, content provider methods are run on Binder threads, which are threads allocated explicitly for interprocess communications. In either case, because it is the client’s responsibility to make sure they are not run on the UI thread, the externally visible content provider methods may perform long running operations.
Finally, remember to keep the content provider thread safe. Although onCreate is called from a single thread — the UI thread — the other methods in the class may each be called from multiple threads. If onCreate shares data with other methods, it must share it safely. Those other methods must synchronize even to share data across multiple executions.
Creating the Content Provider
Listing 4-5 shows the initialization of the example content provider. Note that the onCreate method returns a boolean indicating whether initialization was completed successfully or not.
LISTING 4-5: Initializing a content provider
public class KeyValContentProvider extends ContentProvider {
// code elided...
private volatile KeyValHelper helper;
@Override
public boolean onCreate() {
helper = new KeyValHelper(getContext());
return null != helper;
}Earlier in this chapter, you read that the virtual tables provided by a content provider are identified by their URIs. The section “Virtual Table URIs” earlier in the chapter explored the syntax of those URIs. A content resolver forwards a data request to the appropriate content provider based on the authority section of the URI in the request. The task of parsing the rest of the URI, however, falls to the content provider. It must identify the table to which the request refers and must extract path and ID sections, if they are present.
Fortunately, the Android framework supplies a simple but very convenient URI parsing tool, called the URI Matcher. Listing 4-6 shows the construction of the URI matcher for the KeyVal example program.
LISTING 4-6: Defining a URIMatcher
private static final int STATUS_VAL_DIR = 1;
private static final int STATUS_VAL_ITEM = 2;
private static final int STATUS_KEYVAL_DIR = 3;
private static final int STATUS_KEYVAL_ITEM = 4;
private static final UriMatcher uriMatcher;
static {
uriMatcher = new UriMatcher(UriMatcher.NO_MATCH);
uriMatcher.addURI(
KeyValContract.AUTHORITY,
KeyValContract.TABLE_VALS,
STATUS_VAL_DIR);
uriMatcher.addURI(
KeyValContract.AUTHORITY,
KeyValContract.TABLE_VALS + "/#",
STATUS_VAL_ITEM);
uriMatcher.addURI(
KeyValContract.AUTHORITY,
KeyValContract.TABLE_KEYVAL,
STATUS_KEYVAL_DIR);
uriMatcher.addURI(
KeyValContract.AUTHORITY,
KeyValContract.TABLE_KEYVAL + "/#",
STATUS_KEYVAL_ITEM);
}Return Types and the URI Matcher
The URI matcher is, essentially, a map of regular expressions to integers. It supports replacing long chains of if-then-else statements with a terser, more compact implementation based on a single switch statement.
In order to see a URI matcher in use, first recall from the section called “Return Value MIME Types” earlier in the chapter that a content provider defines MIME types for the data it manages. There are different types for different tables and different types for cursors that contain single and multiple rows. An implementation of a content provider must define the method getType, which clients use to determine what kind of data will be returned for a request from a particular URI. Because the getType method must determine the return type from the URI, it provides an excellent example of the use of the URI matcher.
The example content provider returns one of four MIME types, a dir, and an item type for each of its two tables. The URI matcher contains the four corresponding regular expressions, two for each table, one ending with the table name, and one ending with the table name followed by /#. Each of these four expressions is mapped to one of the unique integers defined in the symbols STATUS_VAL_DIR, STATUS_VAL_ITEM, STATUS_KEYVAL_DIR, and STATUS_KEYVAL_ITEM. A properly formed URI for this content provider will match exactly one of the expressions and thus be mapped to one of the unique integers.
Consider the URI:
content://com.enterpriseandroid.database.keyval/valsThis is a valid URI for the KeyVal content provider. It matches only one entry in the URI matcher, the first. An attempt to match this URI will therefore return the value STATUS_VAL_DIR.
On the other hand, the following URI:
content://com.enterpriseandroid.database.keyval/vals/47matches only the second entry in the matcher. The second entry is very like the first — matching the same authority and the same table name — but ends with the token #, which matches any string of numerals (the * matches any string). The attempt to match this URI will return the value STATUS_VAL_ITEM.
The following are all examples of URIs that will not match any of the expressions in the URI matcher:
content://com.enterpriseandroid.database.keyval/vals/val
content://com.enterpriseandroid.database.keyval/mango
content://com.enterpriseandroid.database.keyval/47All three of these URIs will be mapped to the URI matcher’s default value, specified in its constructor, called UriMatcher.NO_MATCH.
As shown in Listing 4-7, the implementation of the getType method need only use the URI matcher to categorize a URI into one of the five classes and return the MIME type for the corresponding class, or null, when the URI cannot be matched.
LISTING 4-7: Using a URIMatcher
@Override
public String getType(Uri uri) {
switch (uriMatcher.match(uri)) {
case STATUS_VAL_DIR:
return KeyValContract.TYPE_VALS;
case STATUS_VAL_ITEM:
return KeyValContract.TYPE_VAL;
case STATUS_KEYVAL_DIR:
return KeyValContract.TYPE_KEYVALS;
case STATUS_KEYVAL_ITEM:
return KeyValContract.TYPE_KEYVAL;
default:
return null;
}
}Writing the Database
The content provider in KeyVal, a simplified example application, implements only one of the three possible write methods. Of insert, update, and delete, it supports only insert and supports that on only one of the two tables it maintains. Insert is only legal on the keyval table. It is neither legal to insert a key with no value nor a value with no key. As shown in Listing 4-8, the URI matcher handles this constraint nicely.
LISTING 4-8: Implementing insert
@Override
public Uri insert(Uri uri, ContentValues vals) {
long pk;
switch (uriMatcher.match(uri)) {
case STATUS_KEYVAL_DIR:
pk = insertKeyVal(vals);
break;
default:
throw new UnsupportedOperationException(
"Unrecognized URI: " + uri);
}
getContext().getContentResolver().notifyChange(uri, null);
return uri.buildUpon().appendPath(String.valueOf(pk)).build();;
}The call to the content resolver method notifyChange is an essential part of the content observer feature discussed in the section entitled “Content Observers: Completing the Loop” earlier in the chapter. You’ll see it again shortly in the section “Content Observers (Again).”
The insert method returns a URI for the newly added row. It is the URI for the table into which the row was inserted with the primary key for the new row appended.
Listing 4-9 shows the implementation of the insert.
LISTING 4-9: Insert using a transaction
private long insertKeyVal(ContentValues vals) {
SQLiteDatabase db = helper.getWritableDatabase();
try {
db.beginTransaction();
long id = helper.insertVal(
db,
vals.getAsString(KeyValContract.Columns.VAL));
long pk = helper.insertKey(
db,
vals.getAsString(KeyValContract.Columns.KEY),
id);
db.setTransactionSuccessful();
return pk;
}
finally { db.endTransaction(); }
}The use of the transaction in this method is worthy of note. By default, SQLite wraps each write operation (two inserts, in this case, performed within the helper methods insertKey and insertVal) in its own transaction. In order to implement a transaction, SQLite must open, write, and then close the database’s journal file. This can be incredibly expensive for operations that require multiple writes to the database. In addition to providing the atomicity necessary to preserve referential integrity, explicitly wrapping the two operations in the code in a single transaction can substantially improve performance.
As noted previously, a content provider exposes a virtual relation. Even if there is a real SQLite table backing it, there is no reason that either the name of that virtual table or the names of its virtual columns should match their actual counterparts. To the contrary, best practice suggests that exposing the internal implementation of the content provider, by tying virtual and actual names together, is a bad idea. It both cracks the layer of abstraction between the content provider contract and its implementation and may even allow clients to breach the provider’s security.
The code in Listing 4-9 uses explicit methods on the helper class to insert data into the database. Listing 4-10 demonstrates another means of converting between virtual and actual column names, using a small utility class, ColumnDef, and a static map.
LISTING 4-10: Converting virtual column names to real
COLUMNDEF.JAVA
public class ColumnDef {
public static enum Type {
BOOLEAN, BYTE, BYTEARRAY, DOUBLE, FLOAT, INTEGER, LONG, SHORT, STRING
};
private final String name;
private final Type type;
public ColumnDef(String name, Type type) {
this.name = name;
this.type = type;
}
public void copy(String srcCol, ContentValues src, ContentValues dst) {
switch (type) {
case BOOLEAN:
dst.put(name, src.getAsBoolean(srcCol));
break;
case BYTE:
dst.put(name, src.getAsByte(srcCol));
break;
case BYTEARRAY:
dst.put(name, src.getAsByteArray(srcCol));
break;
case DOUBLE:
dst.put(name, src.getAsDouble(srcCol));
break;
case FLOAT:
dst.put(name, src.getAsFloat(srcCol));
break;
case INTEGER:
dst.put(name, src.getAsInteger(srcCol));
break;
case LONG:
dst.put(name, src.getAsLong(srcCol));
break;
case SHORT:
dst.put(name, src.getAsShort(srcCol));
break;
case STRING:
dst.put(name, src.getAsString(srcCol));
break;
}
}
}KEYVALCONTENTPROVIDER.JAVA
private static final Map<String, ColumnDef> COL_MAP;
static {
Map<String, ColumnDef> m = new HashMap<String, ColumnDef>();
m.put(
KeyValContract.Columns.KEY,
new ColumnDef(KeyValHelper.COL_KEY, ColumnDef.Type.STRING));
m.put(
KeyValContract.Columns.VAL,
new ColumnDef(KeyValHelper.COL_VAL, ColumnDef.Type.STRING));
COL_MAP = Collections.unmodifiableMap(m);
}
// code omitted...
private ContentValues translateCols(ContentValues vals) {
ContentValues newVals = new ContentValues();
for (String colName: vals.keySet()) {
ColumnDef colDef = COL_MAP.get(colName);
if (null == colDef) {
throw new IllegalArgumentException(
"Unrecognized column: " + colName);
}
colDef.copy(colName, vals, newVals);
}
return newVals;
}Although it is not used in the KeyVal example, the ColumnDef utility class is a very handy tool.
There is yet one more tool for making this virtual to actual mapping. It is a class introduced back in Chapter 3, the QueryBuilder. It works only for queries, not any of the write methods. As a tool for managing queries against the virtual tables exposed by a content provider, though, the query builder’s full power becomes evident.
Database Queries
All that remains to complete the implementation of this content provider is to implement the query methods. The KeyVals example supports queries on either of its two tables, keys and keyvals. Because they are very similar, this section examines only the implementation of the more complex of the two, keyvals, in detail. Listing 4-11 shows the first of the two methods that, together, handle queries to the keyvals table.
LISTING 4-11: Implementing query
@Override
public Cursor query(
Uri uri,
String[] proj,
String sel,
String[] selArgs,
String ord)
{
Cursor cur;
long pk = -1;
switch (uriMatcher.match(uri)) {
case STATUS_VAL_ITEM:
pk = ContentUris.parseId(uri);
case STATUS_VAL_DIR:
cur = queryVals(proj, sel, selArgs, ord, pk);
break;
case STATUS_KEYVAL_ITEM:
pk = ContentUris.parseId(uri);
case STATUS_KEYVAL_DIR:
cur = queryKeyVals(proj, sel, selArgs, ord, pk);
break;
default:
throw new IllegalArgumentException(
"Unrecognized URI: " + uri);
}
cur.setNotificationUri(getContext().getContentResolver(), uri);
return cur;
}Again, the URI matcher manages the work of sorting query URIs into five classes: those with and without specified primary keys for the two tables, respectively, and those that are unrecognized and illegal. If a primary key is specified in the URI, it is parsed out and passed to the query method for a specific table as the final parameter.
Note, again, the call to setNotification. You’ll return to it in the section called “Content Observers (Again).” This time, the notification URI is the URI that specified the table to be queried.
Listing 4-12 shows the use of a QueryBuilder to construct and run the join query underlying the content provider’s keyval table.
LISTING 4-12: Using the QueryBuilder
private Cursor queryKeyVals(
String[] proj,
String sel,
String[] selArgs,
String ord,
long pk)
{
SQLiteQueryBuilder qb = new SQLiteQueryBuilder();
qb.setStrict(true);
qb.setProjectionMap(KEY_VAL_COL_AS_MAP);
qb.setTables(
KeyValHelper.TAB_KEYS
+ " INNER JOIN " + KeyValHelper.TAB_VALS
+ " ON(fk=id)");
if (0 <= pk) { qb.appendWhere(KeyValContract.Columns.ID + "=" + pk); }
return qb.query(
helper.getWritableDatabase(),
proj,
sel,
selArgs,
null,
null,
ord);
}
The QueryBuilder method setTables creates the join and the appendWhere method adds the primary key match, if it was specified. Be careful using appendWhere to add multiple constraints. Although anything added using appendWhere is added to the selection clause specified in the call to query — using parentheses and an AND — multiple calls to appendWhere are simply concatenated. Thus, although:
qb.appendWhere("cond1");
//...
qb.query(
//...
"condSel",
//...
);
produces:
(cond1) AND (condSel)perhaps unexpectedly:
qb.appendWhere("cond1");
qb.appendWhere("cond2");
//...
qb.query(
//...
"condSel",
//...
);produces:
(cond1cond2) AND (condSel)If you specify multiple appendWhere constraints, you must add your own conjunctions and parentheses as needed.
The most interesting thing in this code is the use of the query builder’s projection map feature. If a projection map is specified, the query builder parses the select clause and replaces column names it finds there with the names to which they are mapped in the projection map. There is a trick to this! If you simply map each virtual name to its actual counterpart, other clauses specified by the client will fail. For instance, if the projection map contains:
clave => key
valer => valand the query built from client arguments is:
SELECT clave, valer FROM keys INNER JOIN vals ON(fk=id) ORDER BY clave;then after translation by the query builder the query will look like this:
SELECT key, val FROM keys INNER JOIN vals ON(fk=id) ORDER BY clave;which will, of course, fail because there is no column named clave on which to sort. Listing 4-13 shows the projection map used for the keyval table. It works because, instead of mapping the virtual name to the actual name, it instead maps the virtual name to <actual_name> AS <virtual_name>. The previous query, after a similar translation, would look like this:
SELECT key as clave, val as valer
FROM keys INNER JOIN vals ON(fk=id) ORDER BY clave;LISTING 4-13: Creating a ProjectionMap
private static final Map<String, String> KEY_VAL_COL_AS_MAP;
static {
Map<String, String> m = new HashMap<String, String>();
m.put(KeyValContract.Columns.ID,
KeyValHelper.TAB_KEYS + "." + KeyValHelper.COL_ROWID
+ " AS " + KeyValContract.Columns.ID);
m.put(KeyValContract.Columns.KEY,
KeyValHelper.COL_KEY + " AS " + KeyValContract.Columns.KEY);
m.put(KeyValContract.Columns.VAL,
KeyValHelper.COL_VAL + " AS " + KeyValContract.Columns.VAL);
KEY_VAL_COL_AS_MAP = Collections.unmodifiableMap(m);
}Using a query builder projection map provides an additional layer of security for a content provider. If, in the process of mapping virtual column names to their actual counterparts, the query builder encounters a request for a column that is not a key in the projection map, it throws an IllegalArgumentException. The KeyVal content provider, for instance, protects the two columns keys.fk and vals.id from exposure, simply by not including them in the projection map.
The query builder also supports a default projection. Because an empty projection — the list of columns to include in the result — doesn’t make any sense, when a null is passed to the query method, the value of the projection parameter the query builder uses is a default projection that contains all of the actual columns (the map values). If your content provider supports this default value or any other default, for that matter, be sure to document it in the provider’s contract.
As of the Ice Cream Sandwich release, the QueryBuilder supports a strict mode, which is enabled by calling setStrict(true). By default (and in an earlier version of Android), strict mode is off. In this state, a client-supplied column specifier that contains the word as (upper- or lowercase) is allowed, whether or not it is in the projection map. It is best practice to set strict mode if possible.
Content Observers (Again)
In the section earlier in the chapter entitled “Content Observers: Completing the Loop,” you examined content observers from the client side in some detail. During the implementation of the example content provider there were two additional places that the subject of content observers arose. The first of these was near the end of the insert method, when writing to the database. The code uses the content resolver method called notifyChange. Similarly, the cursor method called setNotificationUri is used near the end of the query method, after a database read. It sets a URI as the notification target for the cursor.
These two methods really do complete the content observer loop. Ensuring that your content provider uses them correctly is an important key to making it useful, both within your application and to external clients.
In the query method, the cursor returned from the query is registered as an observer for changes posted for the URI that represents the dataset onto which it is a view. It is because it receives these notifications that it can, as you saw, notify the loader manager that a change has occurred and an update is necessary. Unless the cursor in the example application is registered to receive these notifications, the view will not update when the database changes.
The insert method contains the call to notifyChange, which actually broadcasts the notification to all observers. The URI chosen as the notification target deserves some thought. The second argument to registerContentObserver, which is notifyForDescendents, was not discussed when it was first shown in Listing 4-3. The code in that listing demonstrates registering an observer that posts a toast when a database update occurs. That second argument controls whether the observer is notified only for exact matches to the target URI (false) or whether, instead, it is notified for any URI for which the target URI is a prefix (true). As with all API design decisions, best practice suggests defining a policy and sticking to it.
For instance, it might make sense for the insert method’s notification target to be exactly the URI for the newly inserted row. The code would look like this:
uri = uri.buildUpon().appendPath(String.valueOf(pk)).build();
getContext().getContentResolver().notifyChange(uri, null);
return uri;causing the URIs on which it notified to look like this:
content://com.enterpriseandroid.database.keyval/keyvals/42This finer-grained notification might be preferable. Clients can use the notifyForDescendents parameter when registering their observers if they require notification of any change in the dataset (as the list view in the example does). Remember, though, that more frequent, smaller notifications may be less efficient than broader and less specific ones. Consider your use patterns and design accordingly.
PERMISSIONS AND REGISTRATION
Like all of the other major managed Android components, a content provider must be registered in the manifest. Listing 4-14 shows a typical registration, the one used for the example program.
LISTING 4-14: Registering a content provider
<provider
android:name=".data.KeyValContentProvider"
android:authorities="com.enterpriseandroid.database.keyval"
android:grantUriPermissions="true"
android:readPermission="com.enterpriseandroid.database.keyval.READ"
android:writePermission="com.enterpriseandroid.database.keyval.WRITE" />This registers the content provider defined in the class com.enterpriseandroid.database.keyval.data.KeyValContentProvider — the class that has been the subject of the chapter — as authority for the namespace com.enterpriseandroid.database.keyval. All content URIs for that authority will now be directed to an instance of this content provider. Again, note that this authority is simply a string and that clients must match it exactly. There is no semantic information in the string. Your personal application could probably register as authority for the string "com.google.zqx3".
The declaration also uses permissions to define access rights for the content provider.
Using permissions in Android is a three-step process:
Listing 4-15 shows the definitions for the permissions used by the KeyVal content provider. Although any component — including a content provider — can be protected with the android:permissions attribute, the content provider allows somewhat finer grained control; there are separate read and write permissions.
LISTING 4-15: Defining permissions
<permission
android:name="com.enterpriseandroid.database.keyval.READ"
android:description="@string/content_read_desc"
android:permissionGroup="com.enterpriseandroid.database.keyval"
android:protectionLevel="dangerous" />
<permission
android:name="com.enterpriseandroid.database.keyval.WRITE"
android:description="@string/content_write_desc"
android:permissionGroup="com.enterpriseandroid.database.keyval"
android:protectionLevel="signature" />The most significant feature of a permission is probably its name. The usual warnings apply — a permission name is simply a string that uniquely identifies the permission and contains absolutely no semantic information about the permission. A close second in importance is android:protectionLevel. The protection level determines how difficult it is to obtain the associated permission. The possible values for permission level are:
- Normal — A permission that is granted if requested.
- Dangerous — If an application requests a dangerous permission, the user is offered the opportunity to approve granting the permission to the application before the application is installed. If the user approves, the permission is granted, and the application is installed. If the user does not approve, the application is not installed.
- Signature — Like normal, a signature permission is granted without notifying the user, but only if the application requesting the permission is signed with the same certificate as the application using it to protect a component.
Permissions may be grouped together into collections of permissions that control related capabilities. Permission groups have no effect on permission function. They may affect the way they are displayed to a user when installing the application. In the case of the KeyVal example, the two permissions controlling read and write access to the content provider belong to a single permissions group. The definition for that group is shown in Listing 4-16
LISTING 4-16: Defining a permission group
<permission-group
android:name="com.enterpriseandroid.database.keyval"
android:description="@string/content_group_desc"
android:label="@string/content_group_label" />Once the permissions have been defined, they must be applied, as demonstrated in Listing 4-14. As used in that listing, applications that request the permission named:
android:readPermission="com.enterpriseandroid.database.keyval.READ"are allowed to perform queries against the KeyVal content provider, if the end user approves the capability.
Only applications that request this permission:
android:readPermission="com.enterpriseandroid.database.keyval.WRITE"and that are signed with the same key that was used to sign the KeyVal app itself will be granted the capability to write to the KeyVal content provider. Listing 4-17 shows an example of requests for both permissions taken from the KeyValClient application.
LISTING 4-17: Requesting permissions
<uses-permission
android:name="com.enterpriseandroid.database.keyval.READ" />
<uses-permission
android:name="com.enterpriseandroid.database.keyval.WRITE" />The grantUriPermissions attribute in the provider declaration in Listing 4-14 is also of interest. A full description of this attribute is outside the scope of this section. Documentation can be found on the Android Developer website:
http://developer.android.com/guide/topics/manifest/grant-uri-permission-element.html
In short, this permission allows the application defining the content provider to grant extremely fine-grained access permissions to clients a single URI at a time. The following code, for instance in the application defining the content provider, passes a single, explicit URI to the activity responding to the implicit intent named in the symbol KEYVAL_CLIENT.
Intent i = new Intent(KEYVAL_CLIENT);
i.setData(KeyValContract.URI_KEYVAL.buildUpon().appendPath("2").build());
i.addFlags(Intent.FLAG_GRANT_READ_URI_PERMISSION);
startActivity(i);Presuming the content provider’s manifest declaration sets the grantUriPermissions to true, the client application will, regardless of other permissions, be able to perform a query against the provider, using the single passed URI.
CONTENT PROVIDERS AND FILES
There is one more issue to address, before leaving the discussion of content providers: storing large data objects. Imagine for instance that you are designing an application that will allow doctors to review and comment on patient records. The problem changes dramatically if the records include digitized x-rays, each of which is several megabytes.
To demonstrate solutions to the issue, consider a new feature for the KeyVal application that allows values to be associated with arbitrarily large text “extras.” A key is associated with a value, as is already the case. The new feature adds the ability to associate a value with a very large amount of text.
In the UI, a value that has extras available shows in the list view with a green check to its left. If there is no blob available, the item has a red X, as shown in Figure 4-5.

Clicking on one of the items with a green check starts a new activity that displays the contents of the value’s associated extras, as shown in Figure 4-6.

The details of implementing the UI are left to the curious. The concern here is how to implement a content provider that efficiently stores the large text objects.
Like most database systems, SQLite supports blobs — binary large objects. There are several ways to use SQLite blobs from within the Android framework. For instance, either of the code fragments shown in Listing 4-18 will work.
LISTING 4-18: Using blobs
// blob is a byte array
ContentValues vals = new ContentValues();
vals.put("image", blob);
db.insert(TAB_KEYS, null, vals);
SQLiteStatement ins = db.compileStatement(
"INSERT INTO " + TAB_KEYS + "(image) VALUES(?)");
ins.bindBlob(1, blob);Although this is a plausible solution for small byte arrays — hundreds of bytes or fewer — it is quite inefficient when the arrays get large. There are two reasons for this.
The first reason has to do with the implementation of SQLite. As a database file gets bigger and the widths of columns get larger, operations just get slower. Even for SQLite, with all its clever optimizations, size matters.
There are several ways to optimize blob storage, if necessary.
- One useful trick is to keep the blobs in a separate database file — not a separate table in the same file, but an entirely separate file. A table in the main file holds only the primary key (and other small columns). One or more tables in the second file hold the blobs themselves. There is evidence that this scheme helps SQLite handle database fragmentation caused by deletes, and that it can speed queries. Certainly it will speed up any query that doesn’t actually require recovering a blob.
- There is also evidence that the efficiency of blob storage can be improved by appropriate use of the page size pragma. SQLite stores blobs in blocks called pages. Adjusting the page size for a database file to correspond with the size of the blobs being stored in its tables can significantly improve efficiency. Of course, this may require separate database files for blobs of different sizes.
- Finally, especially when dealing with large data objects, it’s useful to remember that in order to recover file system space after deletes, it may be necessary to use the SQLite VACUUM command:
db.execSQL("VACUUM")
A second reason for avoiding blobs in database tables is much more important. When using a content provider from an external application — an application that runs in a different process — the blob data must be transferred across the interprocess communications channel. Clearly, for large data objects, this is inefficient. Fortunately, the Android framework provides a very slick way to avoid the problem.
Among the kinds of data that can be transferred through Binder, Android’s interprocess communication framework, is a file descriptor. It is possible for one application to open a file and then pass the open file descriptor to another application. The second application may then use the file as if it had opened it itself (constrained, of course, by the read/write permissions on the descriptor). The data contained in the file does not have to cross the IPC boundary! This mechanism, in addition, allows the serving application to share the contents of a file without ever giving the client application access to it on the file system. The client cannot open it, or even find it without the content provider’s help.
This suggests an alternative means of storing large data objects as files. Content providers support this scheme using the methods ContentResolver.openInputStream(URI), ContentResolver.openOutputStream(URI), and ContentProvider.openFile(URI, mode).
As usual, the URI must be a content URI (its scheme must be content://). It is forwarded to the content provider registered as owner of the URI’s authority section. A content provider implements the openFile method to handle these requests. It is free to handle the URIs it receives in any way it chooses.
File requests might, for instance, be modeled as an entirely new virtual table. A content provider implemented in this way will have to handle URIs naming the new table, appropriately, in the previously described CRUD methods. This probably means throwing exceptions.
Listing 4-19 is the beginning of another way to handle file requests.
LISTING 4-19: Implementing openFile
@Override
public ParcelFileDescriptor openFile(Uri uri, String mode)
throws FileNotFoundException
{
switch (uriMatcher.match(uri)) {
case STATUS_VAL_ITEM:
if (!"r".equals(mode)) {
throw new SecurityException("Write access forbidden");
}
return readExtras(uri);
default:
throw new UnsupportedOperationException(
"Unrecognized URI: " + uri);
}
}Again, the URI Matcher manages parsing the passed URI. In this case, it rejects any requests that are not against the values table. Because this is a simplified example, it also rejects any requests for write permission. All legal requests are passed to the readExtras method.
What does readExtras do? It must open a ParcelFileDescriptor — a file descriptor that can be passed over the IPC channel — and return it. You need a place in the Android file system to create, read, and write those files.
A complete review of the Android file system is out of the scope of this book. Before creating and using files, it’s worthwhile to review the documentation. At the very least, you should understand the implications of the various possible locations for saving a file — the application sandbox and the SD card.
The example program will create files in the sandbox, the directory /data/data/<application-package>. Android puts files it creates on your behalf into a directory just beneath the sandbox named files.
Of course, there are many ways to implement readExtras. Since the feature specification dictates that there can be no more than one file associated with a particular value — and values are unique — the implementation might construct a file name from the value itself. Another possibility might add a new column to the virtual keyval table, containing the URI of the file that holds a value’s extras. Especially if there were multiple blobs associated with a keyval record, an implementation along these lines might work well.
Once the code has determined a pathname for the file containing the extras, it will use the framework method ParcelFileDescriptor.open(path, modeBits) to create file handle that can be passed back to the client over the IPC channel. The client reads (or possibly writes) and closes the file normally.
Instead of any of these strategies, the KeyVal implementation of readExtras makes use of yet another feature in the Android framework, the openFileHelper. The complete readExtras method is shown in Listing 4-20.
LISTING 4-20: Using the openFileHelper
private ParcelFileDescriptor readExtras(Uri uri)
throws FileNotFoundException
{
return openFileHelper(uri, "r");
}You might ask what is going on. How can it be so simple? It turns out that the framework supports a special database column named _data. If a normal query to a content provider for the column _data returns a cursor that contains a single row, the single value in that column is used as the full pathname for the file to be opened.
Making this work in KeyVal requires changes to both of the virtual tables managed by the content provider. First, there are some simple changes necessary for the values table. It will need a _data column that contains either null if there are no related extras, or else the full pathname of the file containing the extras if there are. Because openFileHelper makes a normal call to the query method, the new column must be visible. To make it visible, it must be added to the projection map for the values virtual table. That, in turn will make it visible to all clients. The new column is not mentioned in the contract file. That may not be sufficient to ensure security but it at least makes it clear that it is not part of the KeyVal API.
The changes to the keyval table are more interesting and do require a change in the contract. You need to expose a new column that can be used to locate the extras associated with a key’s value, if one exists. The new column must be added to the contract and exposed through the projection map. The right value to use in that column is the primary key of the value that has the extras.
Listing 4-21 shows the definition for the new virtual column.
LISTING 4-21: Using CASE to define a virtual column
m.put(KeyValContract.Columns.EXTRA,
"CASE WHEN " + KeyValHelper.COL_EXTRA
+ " NOT NULL THEN " + KeyValHelper.COL_ID
+ " ELSE NULL END AS " + KeyValContract.Columns.EXTRA);;This definition makes use of the SQL CASE statement to produce the new virtual column. If a value has no associated extra data, this virtual column contains a null. If the value does have associated extras, however, the column contains the primary key for the value from the values table. In order to get the file data, now the client needs to request a file from the content provider. The client does this using the URI for the values virtual table and restricts it with the primary key from this new column. Listing 4-22 is an example of code that does just that.
LISTING 4-22: Reading a file from a content provider
InputStream in = null;
try {
in = getContext().getContentResolver().openInputStream(
KeyValContract.URI_VALS.buildUpon()
.appendPath(String.valueOf(extra))
.build());
// process the file contents
}
catch (FileNotFoundException e) {
Log.w("CONTENT", "File not found: " + extra, e);
}
catch (IOException e) {
Log.w("CONTENT", "Failed reading: " + extra, e);
}
finally {
if (null != in) { try { in.close(); } catch (IOException e) { } }
}There is just one other detail necessary to make the application work. Recall that ParcelFileDescriptor.open(path, modeBits), the method used to open the extras file, requires a full pathname for the file it opens. It follows that the _data field in the values database must contain a full pathname.
The method Context.openFileOutput is a convenient way to create private files. As described, it creates files in a subdirectory of an application’s private sandbox. In order to programmatically obtain the name of that directory, to construct the full pathname for the _data column, use the method Context.getFilesDir. The name of the file stored into the _data column is:
context.getFilesDir() + "/" + filenameSUMMARY
This chapter examined the Android content provider component in thorough detail.
- Starting with a client’s point of view, the chapter uncovered the content provider’s essential behavior.
- Next, it introduced the contract file, an exportable definition of a content provider’s API.
- The chapter took a deep dive into the specifics of content provider implementation, exploring tools like the URI matcher, transactions, the query builder, and a couple of handy tools for implementing a virtual table space.
- It described registering a content provider in the application manifest and the types of permissions used to control access to it.
- As a recurring theme, the chapter discussed one of Android’s most brilliant features, the content observer. The content observer uses a URI as a rendezvous point for the dataset it represents. Notifications sent by clients that change the backing dataset are broadcast to all clients subscribed to those notifications.
- Finally there was a discussion of an advanced topic, using a content provider to facilitate access to large data objects, including the ability to efficiently transfer files.
This chapter completes a low-level foundation upon which you can build an architecture for enterprise application. It steps away from the generic programming concerns of the preceding chapters and introduces one of Android’s key architectural components. The content provider is the basis for Android’s approach to mobile architecture: a RESTful cache pulled up out of the Internet, right onto the mobile device.
The rest of this book explores effective use of this cache.