
13. Case Studies of Endpoint Security Failures
As has been the case for many parts of this book, understanding some history is an important aspect of the learning process. All too often, we fail to learn from our mistakes, and it costs us dearly in the future. I hope this brief look into the past helps you understand how the proposed solution in this book can work to your advantage.
Précis
In this final chapter, we discuss some network environments that had to deal with some “issues” that caused the enterprise owners significant loss/embarrassment. We’ve all read in the newspapers about some of the high-profile attacks, but what about some of the failures that didn’t make the papers? As a consultant and a security world insider, I get to learn of some pretty scary things. Because I learned of these failures in my capacity as a consultant, I’m really not at liberty to give out names, dates, or places. I think the circumstances, outcome, and analysis serve to make the important points. Besides, if it were you, would you want the world knowing about your failures?
Each section examines the failure mode, how the endpoint was involved, various impacts, the missing process control, and how the failure could have been avoided.
Case Study 1
A large commercial manufacturer of computer products
Failure Mode: What Went Wrong
This company had the practice of giving all employees who inhabited a cube or office a computer and a stack of boxes that contained all the Microsoft Windows software packages. The thought was that by getting familiar with the process they would become familiar with the hardware, software, and the “customer experience.” I suppose the idea was to feel the customer’s pain and thereby become sensitive to it. As a business model, it did exactly that. Employees became familiar with all aspects of the computing “experience.”
Any person could have a server or any service running that he or she wanted. All flavors of servers, desktops, and notebooks were running Web servers and FTP servers, sharing files, and, in general, using the snot out of the rich feature set that Microsoft provides. Essentially, the network was there to provide connectivity between systems and services.
Like most large companies, this company was managed as individual divisions, and each division had a great deal of autonomy to make decisions regarding resources. This meant that IT was there to make sure that each division stayed on the network. Customer interfaces, and a great deal of customer support, were hinged on the network being up. For this reason, no expense was spared when it came to deciding on network hardware. They weren’t foolish, but they did have some heavy-duty iron running and slinging packets.
It was that heavy-duty iron that allowed the almost instantaneous spread of CodeRed.
How the Endpoint Was Involved
In this instance, it was a pretty simple correlation between the unprotected endpoints and the spread of the virus.
The Impact
In a matter of minutes, every system that could be infected was infected. The network was running at collision rates that had the data centers glowing red from the collision lights. Thankfully, the network being at overload helped slow down the spread.
Some estimates put the level of infection at higher than 90 percent, and they couldn’t fix it. As they would bring a new system up, other systems would attack it. All totaled, they lost more than three days of productivity. Production stopped, shipping stopped, receiving stopped; and because the trouble ticket system was now dead, customer service was being handled over a private branch exchange (PBX) system that wasn’t designed to handle the load. Customers didn’t care that there was a problem; customers were only concerned with their individual problem. It’s interesting to note that many of the customers were calling to complain that their systems had slowed down or crashed, and they wanted to know what to do.
Missing Process Control
I could start by saying that from an endpoint security perspective that they did everything that you could possibly do wrong. But that would be unfair. Business is business. The reality of the situation was that they had no real process except a trouble ticket system.
There was no:
• Centralized build process
• Centralized patch management
• Enforcement of antivirus (AV) requirements
How It Could Have Been Avoided
The sad truth here is that until the corporate mind set changed, there wasn’t going to be any real improvement in the situation. Management had to come to grips with the fact that handing a new employee a stack of cool technology and hoping that the employee could get it to work while learning something about the customer experience wasn’t a good plan.
Throwing patch updates and AV at the endpoints with an insane hope that it would stick wasn’t much different from what they were already doing. A complete overhaul of their policy was in order. Instead of “feeling the customer’s pain,” their policy needed to be “please make the pain go away.”
Chaos had to be replaced with order, and eventually it was. Management of the desktop and notebook endpoints was turned over to IT, and mandatory system requirements were placed on all endpoints. All endpoints were configured with a firewall, AV, and the Windows built-in patch management and update process.
One contentious point had to do with administrative access to the system and who would have that level of control. IT rightly argued that only users with verifiable administrative skills who possessed a need to modify the system should have access. After a few days of discussion and many system re-images, the new policy was not to allow any user to be administrator. I’m sure you’ll understand that this bent a few jaws out of joint. But, after a few days of zero productivity, all but the real hardliners came to see the wisdom of allowing IT to do their job. Exceptions were granted on a case-by-case basis.
In the end, they had the foundation for a good closed-loop process control (CLPC) system: They had control over most of their endpoints, and they had invested in network infrastructure that would (for the most part) support a migration to network access control (NAC). Had a CLPC system been in place, noncompliant systems would not have been allowed to join the network and spread the virus.
Case Study 2
A large package-shipping company
Failure Mode: What Went Wrong
This story starts with our customer saying, “Get in. I don’t care how you do it so long as you don’t break anything or hurt anyone.” This wasn’t a simple scan and report. This was a complex cat-and-mouse game that would test the customer’s ability to detect and report what we were doing. We called them “womb to tombs” because everything from physical attacks to social engineering, and everything in between, was permitted. These were fun because we knew that it was only a matter of time before we got in. And get in we did.
What we discovered was a fairly well-run shop with a centralized IT department that controlled the configuration of the endpoints fairly well. Simple scans didn’t turn up anything from the outside, so we knew that we would have to get inside. It turned out to be simple enough. We just walked in with our notebook, sat down in a conference room, and plugged in. Once connected, we had complete access to their entire network from a conference room!
How the Endpoint Was Involved
This was a case in which the endpoint was the attacker and the network was the victim. Had the network been capable of defending itself, the attacking—well, really sniffing and snarfing—endpoint wouldn’t have been able to join the network.
The Impact
At this point, the impact could have been catastrophic. We had access to routers, switches, their entire server farm, and all the desktops. We did a basic scan of the internal network and discovered hundreds of potential targets of attack. If we had been bad people, we could have easily stolen data, destroyed data, disrupted processes, and generally wreaked havoc until they decided to have a meeting about it. They would have come into a conference room with two strangers in it, and I’m sure somebody would have put the pieces together rather quickly. We documented our findings and were gone in less than 30 minutes. To prove our point, we left a marker on one of the file systems that proved that we were there. We also copied some PowerPoint presentations describing the next set of services that they were planning to deploy.
Because this customer was wise enough to know that they didn’t have a good idea of their security posture, the impact was generally low and distributed over a longer period of time due to careful planning.
The executive who had requested the assessment was considering retiring at the end of the year. When we were through, he commented to me that he was going to move up his retirement plans.
Missing Process Control
Although they did have a good handle on the endpoint, they didn’t have a good handle on the network. The support people were desktop people who had moved up through the ranks and believed the garbage that their network vendor was feeding them about simplicity and ease of use. When a new box came in, they just plugged it in and waited for the vendor’s engineer to show up. In many cases, switches were patched into place to address some pressing and acute need for the day, only to be left when the situation passed. This was the case in the conference room. To accommodate a demonstration of one of the new database services that was going to be offered online, a connection had to be made to the internal server development network. The cable connecting the conference room to the Internet was replaced with a cable that connected the conference room to the internal network.
How It Could Have Been Avoided
This is a case where CLPC and NAC would have been a deterrent to access. The network would have noticed that we didn’t have the required authorization, and we would have been shunted to a remediation network or only allowed Internet access. At a minimum, there should have been a manual process in place or a timed firewall rule that allowed access from the conference room to the internal network for the period of the test only.
Case Study 3
Manufacturer of satellite-based communications equipment
Failure Mode: What Went Wrong
Like most situations that lead to security issues, this wasn’t a cut-and-dry vulnerability discovery exercise. It really started out as an episode of “America’s Dumbest System Administrators.” We were called in to investigate a claim made to HR that the corporate system administrator and his assistant were storing porn on a Windows server share. As was our standard practice, we ran a scan from the outside and discovered that the Internet router, the router that connected them to the hostile world, had a default password on it!
An internal scan of the network revealed that there were several unauthorized file servers running in various stages of update. Virtually every machine had a vulnerability that would allow remote compromise or elevated privileges.
Analysis of the system administrator and the assistant system administrator systems uncovered numerous infections and back doors. One system even had BackOrifice (known as BO) installed on it. Analysis of other endpoints within the enterprise helped identify (through the similarity of infection) those who had taken advantage of the porn available.
And yes, they were running a peer-to-peer (P2P) sharing network that allowed them to collect and exchange porn between them. It was one of the few complete collections of the Pam Anderson videos that I’d ever seen.
How the Endpoint Was Involved
In this instance, the endpoints were part of the perpetration but also the detectors. Although this started out as a case of abuse, it quickly turned into a case of poor administration and planning.
The Impact
This was another case of “boy, did you guys just dodge a bullet.” If attackers had managed to discover this router, they could have changed the configuration and set the password to something a tad more difficult than the default password.
In addition, there was the concern that sensitive and proprietary information had leaked out of the network. However, the firewall was configured to provide Network Address Translation (NAT) services, and the enterprise was using a private Internet Protocol (IP) address space. Analysis further concluded that due to an installation error, BO would not have been able to communicate through the present network as it was configured.
It took approximately a week to clean up all the systems, add AV, and reconfigure the network to a more secure posture. The system administrator received a week of unpaid leave, as did the assistant system administrator. Others who were suspected of viewing the questionable material received remedial sexual harassment and acceptable-use training.
Missing Process Control
Well, it didn’t help starting with a brain-dead system administrator who was more interested in a “collection,” but the lack of a vulnerability management (VM) process coupled with the lack of a managed AV program exacerbated an already bad situation. A VM program would have uncovered the open router and the inconsistent patch management on the endpoints. It would have also uncovered the rogue servers in the first place. The lack of oversight led to a careless decision on the part of the system administrator and his assistant.
How It Could Have Been Avoided
All roads lead back to the lack of adult supervision and a documented security plan. I’m not talking about a policy; they had the benefit of having some silent partners who made it clear what the policy was. However, there was no real plan or vision to implement it. Systems were built and installed as needed to execute on the start-up’s business objectives. Not uncommon, but at some point the adults take over, and policy and process begin to seep into the system. In this case, the lack of any senior IT people within the company left a vacuum with respect to the greater objectives of the IT group. As much as I’d like to point to a CLPC failure here, this is a perfect example of a human failure. Our recommendation was for them to hire a senior IT person as soon as possible so that a one-year plan could be fleshed out.
You can have the greatest technology in the world, but if it’s not implemented effectively and the people aren’t part of the solution, they will be part of the failure.
Case Study 4
Large software company that specializes in security software
Failure Mode: What Went Wrong
I almost had to laugh when I learned about this one. One day I got an email from a very angry system administrator telling me that one of our systems was attacking his Domain Name System (DNS) server. I thought, “Hmm, that can’t be possible. We’re a security company!” But, a complaint is a complaint, and it must be investigated. So, doing my due diligence, I began looking into the issue. After a few hours, I came to the stark realization that sure enough, we were in fact attacking his DNS server. As much as this is an issue, it’s not the real problem here. More on this in the section “The Impact.”
So, you might be questioning how this could happen. I did! The story goes something like this: An instructor was ramping up a class to teach DNS administration and decided to install and configure BIND prior to the class starting. The self-starting instructor picked what he thought was a fictitious name for his class company and used it to configure the DNS database. Unfortunately, there was a real DNS server out on the Internet with the exact same name. To keep a long story short, the classroom DNS server slave decided to try a zone transfer and was banging on the real DNS server. It wasn’t hard to track down the source of the bogus zone transfer requests, and the owner naturally wanted them to stop, so he sent an email to our abuse and security email addresses. This is where is starts to get strange. After not getting an answer for more than two weeks, the real DNS domain owner starts to copy people he knows in our organization. I was forwarded the email because it made it to the security operations folks and they were rightfully mystified, and concerned, about what to do.
How the Endpoint Was Involved
In this case, the endpoint was the attacker. Misconfiguration was the root cause, but the network did not attempt to stop the rogue requests. A DNS zone transfer is something that should be monitored and logged. Oh, and on occasion, the logs should be examined.
The Impact
Outside of one very irked DNS administrator and an embarrassed instructor, the impact was pretty low. It took about a day to put all the pieces together, but there was no real loss of productivity or leakage of data.
Missing Process Control
It was abysmally clear to me that outside of some minor procedural failures, the internal incident response process (IRP) had failed completely. It took two weeks for a victim of our misguided attacks to get any attention. Sadly, what did get our attention was his threat to turn over copies of the emails and logs to the press.
How It Could Have Been Avoided
The neat thing about CLPC is that it’s an automatic function. As the temperature goes up, the thermostat kicks in, and the AC starts. Just because something is supposed to be automatic doesn’t mean that it doesn’t require calibration occasionally. An IRP is supposed to be started when an event makes it into the queue. To test that it’s working properly, you have to, on occasion, submit an incident with a known outcome. For example, if you want to test the AV portion of your IRP, you open a ticket saying that a system has been infected with some virulent piece of malware. That should drive the IRP into action, the proper personnel should be notified, the proper collaborations should occur, the appropriate actions should be taken, and the appropriate entries should be made to the ticket. All of this and time stamps, too! Only then can you observe how fast and effective your IRP process really is and where it needs to improve.
Unfortunately, most of our processes, such as the test scenario outlined in the preceding paragraph, are still human driven—meaning that someone has to kick-start them before anything happens.
This never happened. The short answer is that this could have been avoided by a regular test of the IRP.
Key Points
Clearly, there are still failures related to the fact that human-driven processes are always susceptible to failure. There were differences and similarities in these case studies, but the common thread was always process. As we begin to embrace CLPC as a philosophy, we can better understand how to build our security solutions around it.
Differences and Similarities
The organizations in these case studies differed with regard to their size and the maturity of their security program. However, these differences didn’t seem to matter. As you can see in Table 13-1, the one common element was a process-related failure.
Table 13-1. The Common Thread in the Case Studies: Process Failures
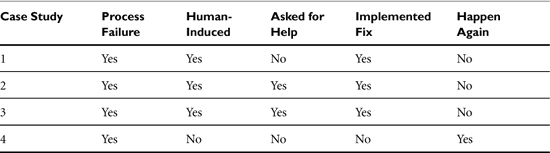
We had two very large, worldwide enterprises fail—one in a catastrophic way, and one in a fairly subtle way.
We had what would be considered a start-up dodge a bullet because of a system administrator-induced failure (never tell Batman how you’re going to kill him), only to come away stronger from the incident because they knew to ask for help. Finally, we had a medium-size software company fail because they failed to test their processes.
Some followed best practices and failed, whereas others didn’t follow them and failed. The main similarities between these case studies has to do more with how the discovery process began than what processes were missing. In all of these cases, it was an outside entity that told them that they had a severe problem. Yes, two of the case studies knew enough to understand that they had a problem, but neither of them understood the scope of the failure and how far reaching it could turn out to be.
The good news is that they were all process-oriented failures and not technology failures. Process failures have the benefit of helping you examine your solution from a philosophic perspective rather than the “tear out the old box” mentality that a technology failure induces.
People played an important role in the failure and the solution, or nonsolution in the case of the last case study. In the last case study, an active decision was made not to do anything different because they hadn’t finished examining all the parameters. Well, analysis paralysis is a mode that many folks get into when the really don’t understand the problem and refuse to ask for help.
CLPC Philosophy
Although this book has been about closing the trust loop with endpoints, CLPC is really a philosophy that embraces the notion that we can use our processes to self-govern our networks. CLPC says that our decisions and our actions have consequences and that we can use those consequences to help make the solution better.
Let’s go back to our thermostat model so that we can compare it to our present-day networks. What we would find is that instead of a thermostat that automatically senses the temperature, we would have a person turning the heater on and off based on how he felt at the moment. The person could be sitting in a chair or roaming around the room to get a better idea of how the room “feels.” But, if that person happens to be wearing a parka and it’s cold outside, there’s not going to be much help for those who are counting on the “heater person” to regulate the temperature in the room.
Closing the loop removes the subjective nature of much of the control process. We have set-points, and we measure to see whether we’re above, below, or at the set-point. There’s nothing subjective about running an IRP test to see how your organization reacts. Either it does, or it doesn’t.
Remaining Work
A great deal of work remains to be done. With more and varied types of endpoints, we’re going to find ourselves with a colossal management problem that isn’t going to be solved with more and better-trained bodies. Our architectures are going to have to embrace the requirement associated with establishing a level of trust through an integrity check. This means more software, and that means better software assurance programs to ensure that the software we’re using is trustworthy. It also means that at some point we’re going to have to hand off the job of verifying that trust to a third party.
We can’t wait on the next version of Windows, Linux, OS X, or the next wave of disruptive technology that may open our networks to serious attack. We need to analyze our networks as CLPC problems and find ways to automate the feedback loops and control points. Without automation, and CLPC, we’re never going to survive the next big failure that will inevitably come.