
Chapter 13. Taming wild EJBs: performance and scalability
This chapter covers
- Entity locking
- Performance improvement of JPA entities
- Tuning of session beans and MDB performance
- EJB clustering
When it comes to building software systems, it’s the end that matters—not the means. Working, reliable software that is usable is what it all boils down to. In the end, what customers care about is that your product produces consistent results, performs well, and meets scalability and availability requirements. Most developers and users can agree on that. But then there’s the part they can’t always agree on—the part that’s implied and expected by the users, but not always understood by the developers. Surely you’ve seen it before. You just finish plopping your latest new-fangled application into production and the e-mails start flying and the calls come rolling in. It turns out that the users had some other expectations as well. Something about how they expected the program to perform. Sure, the application has the features they asked for, and everything appeared to work during user acceptance testing (UAT), but now that it’s in production everything’s so slow. Can anything be done?
In the final assessment, how well your applications perform is important. Users have expectations for performance, even when they don’t articulate or just don’t communicate them well. In most application development projects, performance goals are ignored during development. While making something work is the first step development should take, some attention must also be paid to performance concerns during development, to avoid the potential rework that will occur if they are completely ignored until the system is deployed. According to some surveys,[1],[2] around half of software development projects fail to deliver their performance objectives.
1 According to the Wily Tech 2003 Survey of Java Applications, 60 percent fail to meet performance expectations (http://www.wilytech.com/news/releases/031120.html).
2 Forrester (2004) reports that 66 percent of the time, developers find out about performance problems from support calls.
Up to this point we have focused on how to build EJB applications. However, you also need to consider the performance aspects of your application in order to effectively build, configure, and deploy your applications.
In this chapter you’ll learn about general performance tuning of all the EJB 3 components and issues surrounding scalability and availability for EJB 3 applications. We’ll start by looking at how to handle entity locking. You may remember from our discussion in chapter 6 that consistency is a critical aspect of transactional applications and improper locking mechanisms not only lead to inconsistent data but also may cause performance degradation. An athlete makes sure that he runs within his track before running faster; otherwise he’ll be disqualified. Similarly an application is useless if it has consistency issues. We’ll begin by discussing entity locking.
13.1. Handling entity locking issues
When you build a high-end transactional trading application like ActionBazaar, you need to understand concurrency issues so that you can take appropriate actions during development. Too many users trying to read or update the same piece of data can cause havoc with system performance. Or even worse, one user is working with data that is no longer valid due to the data having been changed or deleted by another user. Dealing with concurrency is a nontrivial problem domain and requires a certain amount of forethought before the coding begins.
When these scenarios have occurred in the past, have they been documented? Are there recommended patterns and terminology on how to discuss and resolve such problems? It turns out that there are some known approaches to handling such problems. Before we discuss them, though, let’s get some terminology straight. In a concurrent system, you may run into one or more of the following issues when isolating actions involving multiple users:
- Dirty read— Occurs when a user sees some uncommitted transactions from another user. For example, in the ActionBazaar system, suppose a Seller reads an Item in transaction T1 and makes some changes without committing them, and a Bidder gets a copy of the uncommitted changes in a separate transaction T2. Then the Seller decides to cancel his change, rolling back the transaction T1. Now we have a situation where the Bidder has a copy of an Item that never existed.
- Nonrepeatable read— Occurs when a user is allowed to change data employed by another user in a separate transaction. Suppose a Bidder reads an Item in transaction T1 and keeps a copy of the Item while at the same time the Seller removes the Item in transaction T2. The Bidder now has a copy of the Item that no longer exists and any attempt to create a Bid on the Item will fail with unexpected (and unexplainable, unrepeatable) errors.
- Phantom read— Occurs when a user receives inconsistent results in two different attempts of the same query, in the same transaction. For instance, a Bidder runs one query to retrieve a list of Items available for bidding on within a specific Category in transaction T1, and a Seller creates a new Item in that Category in transaction T2. When the Bidder runs the query again, he gets a larger list of Items than originally retrieved.
You may recall that we briefly discussed transaction isolation levels in chapter 6, and that we encouraged you to choose the appropriate transactional isolation level supported by the underlying database system(s). Additionally, a highly transactional system must enforce appropriate locking strategies to make sure that users don’t step on one another.
Now we’re ready to cover the known patterns on how to deal with concurrency. Given how important locking is to multiuser applications, let’s discuss the various types of locking next. Then we’ll focus on optimistic locking with JPA and show how you can obtain locks on entities using the EntityManager API.
13.1.1. Understanding locking types
To avoid concurrency issues, applications must use appropriate locking mechanisms. Locking strategies are generally grouped into two camps: optimistic and pessimistic. Optimistic locking can be viewed as a “cure it” mind-set, whereas pessimistic locking is more of a “prevent it” concept. This section examines the differences between these two locking approaches.
Pessimistic locking
Pessimistic locking is a strategy reflective of a pessimistic state of mind, where you prevent users from doing certain things, assuming that they will go wrong. When using pessimistic locking, you lock all involved database rows for the entire span of time a user shows an interest in modifying an entity.
Note
JPA does not have support for pessimistic locking strategies. However, some persistence providers will have vendor-specific extensions to use pessimistic locking.
Figure 13.1 illustrates pessimistic locking. A user may acquire two types of lock on an entity: write or read. A write lock prevents users from attempting any kind of operations such as read, update, or delete, on the locked row(s). A read lock allows others to read the locked data but they are unable to update or delete it.
Figure 13.1. In pessimistic locking, when a user wants to update the data the underlying records are locked and no other user can perform any operation on the data. It is typically implemented using SELECT ... FOR UPDATE semantics.

A pessimistic lock is relatively easy to implement, since most databases allow you to lock tables, rows, and so forth. You can use the SELECT FOR UPDATE semantics in the database to implement pessimistic locking.
Pessimistic locking has many disadvantages. For instance, it may make your applications slower because all users have to wait for an entity’s locks to be released. It may also introduce deadlock conditions into your system. If a system has several users, transactions involve a greater number of objects, or transactions are long-lived, then the chance of having to wait for a lock to be released increases. Pessimistic locking therefore limits the practical number of concurrent users that the system can support.
Optimistic locking
By contrast, optimistic locking is a strategy that assumes that concurrency problems will occur rarely, and you should detect and resolve each problem when it happens. The optimistic locking mechanism is more difficult to implement, but is a popular approach to enforce control while allowing full data access concurrency. JPA supports the optimistic locking strategy. Although the ActionBazaar system is a high-transaction system, rarely do concurrency problems happen.
In the ActionBazaar system, a Seller (as well as the system administrator) is allowed to update her item. Several Bidders may bid for the same item since they are not allowed to change the item. It is less likely that a Seller and an administrator will be updating the same item at the same time, so an optimistic locking strategy makes sense.
Figure 13.2 depicts how optimistic locking works. When a user retrieves an entity for update, a copy of the object is provided and changes are made to the copy. After the user makes some changes to the entity, he is ready to save it. The application now obtains a write lock on the object and checks whether data has been updated since the user obtained it. If there has been no update to the original data, then the user is allowed to commit the copy of the entity to the database. Otherwise, the application should throw an exception.
Figure 13.2. How optimistic locking strategy is implemented by a persistence provider. If the locking mode is set to WAIT, the User2 would wait until User1 releases the lock.

The optimistic locking strategy is typically implemented by adding a column to the database table for the entity, and either storing a version number or a timestamp to track changes. The version number approach is preferred and quite reliable, because it could be that two users may be trying to update the same data—at the same instant (timestamp).
Every time a specific database row is updated, the version column is incremented by the application. When a user reads the entity, the version column is retrieved and stored with the entity instance. After making changes in the entity object, as the user tries to save the entity to the database, the application compares the version attribute of the entity object with that of the database. If the version attributes are the same, then the user is allowed to hold a write lock on the object, saves the object to the database, increments the version attribute, and then releases the write lock. If the version attributes are different, then it is assumed the entity has since been updated by someone else and the update is rejected with an OptimisticLockingException.
If you’re building an application with JDBC, then you’ll have to implement a locking strategy yourself. However, if you’re using the EJB 3 JPA, the persistence provider makes your life much simpler. The EJB 3 JPA persistence providers are required to support the optimistic locking strategy using a version number column in the database table. Let’s take a closer look at how this is done.
13.1.2. Optimistic locking and entity versioning
If any of your entities are accessed concurrently in your applications, or detached entity instances are merged, then you must enable optimistic locking for those entities. For example, in the ActionBazaar application entities such as Item and Category are accessed concurrently. You must enable optimistic locking for these entities by adding a version attribute in these entities.
Note
The JPA specification does not mandate supporting optimistic locking without a version field on the entity.
We can define a version attribute in the Entity item as follows:

As this code shows, you can use @javax.persistence.Version on a persistence field or property. The persistence field should be a numeric field of type long, Long, int, or Integer, and it should be mapped to a database column on the primary table to which the entity is mapped. In our example, the version property is mapped to the OPT_LOCK column. You may see some resistance from your DBA to adding an extra column to store the version, but you will have to persuade her that you need this column to support optimistic locking in your applications.
Applications cannot set the version attribute, as it is used directly by the persistence provider. The version column is automatically incremented when the persistence provider commits changes to the database. When you merge an entity instance to a persistence context, the persistence provider will check the version column to ensure that the detached entity has not become stale.
If you are using TopLink Essentials, you can enable logging to see SQL statements when a detached entity instance is merged as follows:
--Assign return row DatabaseRecord(ITEMS.OPT_LOCK => 2)
... Connection (
... )
--UPDATE ITEMS SET ITEM_NAME = ?, OPT_LOCK = ?
WHERE ((ITEM_ID = ?) AND (OPT_LOCK = ?))
bind => [New Title: Vintage Cars from junkyard, 2, 902, 1]
In this code, the persistence provider is incrementing the value for the version attribute (ITEMS.OPT_LOCK) and updating the ITEMS table with the new value in the OPT_LOCK column. The WHERE clause includes the OPT_LOCK column and compares it with the old value. If the WHERE clause fails, then the persistence provider will throw an OptimisticLockException.
Some persistence providers may choose to support additional mechanisms to check optimistic locking and, depending on their implementation, may render your applications less portable.
13.1.3. EntityManager and lock modes
Although you will very rarely need it, the EntityManager provides a lock method to explicitly acquire a lock on an entity:
// begin transaction...
entityManager.lock(item, LockModeType.READ);
...
System.out.println(item.getInitialPrice());
Note
The lock mode can be one of two types: READ or WRITE. You must have version attributes on any entity to be locked using the lock method, and the entity must be managed.
As mentioned earlier, some persistence providers may use alternate mechanisms to support an optimistic lock on objects. If you have not created version attributes on your entities and you are attempting to lock them, your persistence provider won’t be able to acquire the lock. It will notify the application of this situation by throwing a javax.persistence.PersistenceException. The EntityManager automatically translates these locks to the appropriate database locks.
Note
If you use LockModeType.READ, then your application acquires a READ lock on an entity. You are ensured that neither of the issues such as dirty reads or nonrepeatable reads will occur in your applications.
One common use of the READ lock is when your application generates reports. You obviously don’t want other users updating entities when you are reading them to populate the report.
In addition to this behavior, when you use LockModeType.WRITE, the persistence provider will check for conflicts. When you acquire a WRITE lock on an entity, no UPDATE or DELETE operation is performed on the entity, even from separate transactions. The persistence provider will generate an OptimisticLockException if another user tries to update the locked entity from a separate transaction. The persistence provider will automatically increment the value for the version column when the transaction successfully commits or roll backs. LockModeType.WRITE is useful when you are trying to manage relationships between two entities that may be updated in different transactions and you want to avoid inconsistencies.
Here is an example of using LockModeType.WRITE:
...
Item item = em.find(Item.class, itemId);
em.lock(item, LockModeType.WRITE);
item.addBid(bid);
bid.setItem(item);
...
Performance tuning: an iterative approach
Performance tuning is neither an art nor an exact science. There is no silver bullet that you can use to hunt down your application’s performance issues. A typical enterprise application that uses EJB components probably has multiple tiers. When you experience performance issues, where do you start? In our experience organizational groups spend more time finger-pointing than trying to investigate and identify the real issues. Sometimes the developers are blamed, sometimes the database group, and sometimes the support personnel. Instead, these groups should spend more time working with one another to find a mutually beneficial resolution.
Performance tuning is a very iterative process. We recommend that you limit changes to a single modification; you should understand the impact of each change by rerunning the whole scenario. Only then can you determine if another change is needed, if further tuning is required, or if the change you made had an unexpected or adverse effect and needs to be reversed. Changing multiple items is uncontrolled and can lead to an unstable, sometimes even unrecoverable, situation. The result of changing one thing at a time is that you can determine if you need to reverse the last change before proceeding to the next. Otherwise, you can accumulate random behavior, which can leave your application in a more unstable state than when it started.
Finding bottlenecks for multitier applications is not an easy task and may involve looking for several things. Several books have been written on tuning the different tiers of distributed applications.
If you get an OptmisticLockException in your application, there is no way to recover, and it probably makes sense to retrieve a fresh copy of the entity and try to reapply the changes.
To summarize, if you use the right locking strategy your application won’t suffer from consistency issues. If you are trying to implement vendor-specific pessimistic locking, you may have performance issues and we suggest you use optimistic locking instead.
This brings an end to our discussion on locking strategies for entities. It’s important that a locking strategy be in place for your applications, and that it be clearly communicated to the development team—especially when there is any turnover within the team. Now that we’ve put locking strategies in perspective, let’s turn our attention to how you can tune the performance of entities in your EJB 3 applications.
13.2. Improving entity performance
Many would agree that the persistence tier remains the primary suspect of most performance issues. Sometimes this is due to poor design or a failure to understand the technologies in play and how they interact. Sometimes it can be due to a weak vendor implementation or tool, or insufficient training on how to use the tool properly the way it was intended. Yet another cause can be not getting your database team involved during the design process. Your DBAs should have intimate knowledge of the data and database server(s), and be able to give you some insight on how best to interact with it, as well as be able to make modifications that your application could benefit from.
Our own experience has shown that the response time of applications will improve from 2 to 10 times simply by tuning the data access layer. When you are experiencing unacceptable performance, there might be several reasons to suspect this layer. For instance, the SQL statements are generated by the persistence provider, and unless you know how the persistence provider generates the SQL statement, you put the blame on the JPA provider!
You can take several actions to improve how your applications access the database. In this section we’ll offer some advice on these design considerations.
13.2.1. Remodeling and schema redesign
Your entity model and the underlying table design may severely impact the performance of your application. This means you must keep performance goals for your applications in mind when designing your entity model and schema. This section shows how you can align your design with your performance goals. All teams involved in your project should review the design, and you may need to introduce some non-domain-specific data into your domain model in order to achieve your performance goals. This review should take place on a case-by-case basis. Don’t hesitate to adjust your domain model to achieve your business objectives.
Merging tables
You may improve performance by merging two small tables and making slight adjustments to the domain model. While building ActionBazaar we found that a one-to-one relationship exists between BillingInfo and Address. In the original design, BillingInfo and Address were mapped to two different tables, BILLING_DETAILS and ADDRESSES, as seen here:
@Entity
@Table(name = "BILLING_DETAILS")
public class BillingInfo implements java.io.Serializable {
@Id
protected long billingId;
...
@OneToOne
protected Address address;
...
}
@Entity
@Table(name = "ADDRESSES")
public class Address implements java.io.Serializable {
@Id
protected long addressId;
...
...
}
We realized that retrieving BillingInfo makes no sense without also retrieving the Address information. In addition, Address is always eagerly loaded and there is always a JOIN performed between the BILLING_DETAILS and ADDRESSES tables. Performance can be improved in this case by merging the ADDRESSES table into the BILLING_DETAILS table and making Address an embedded object like so:
@Entity
@Table(name = "BILLING_DETAILS")
public class BillingInfo implements java.io.Serializable {
@Id
protected long billingId;
...
@Embedded
protected Address address;
...
}
@Embeddable
public class Address implements java.io.Serializable {
...
}
In this way you can avoid a JOIN between two tables and achieve a little performance boost as a bonus. Another option to consider is to remove secondary tables by merging them into the primary table. This avoids a JOIN between the primary table and secondary table when an entity is loaded.
Dividing a table into multiple tables
In ActionBazaar, a Seller may provide some additional information, such as original purchase date, manufacturing date, warranty information, picture, or video files for an Item. When we originally modeled ActionBazaar, the Item entity had attributes for all these fields, and all the fields were stored in a single table as shown here:
@Entity
@Table(name = "ITEMS")
public class Item implements Serializable {
@Id
private Long itemId;
private String title;
...
private String originalPurchaseDate;
@Lob
private byte[] itemPicture;
...
}
Most of this information is not frequently used, so we marked these fields to be lazily loaded. However, what we did not realize is that lazy loading of BLOB fields is not mandatory for EJB 3 persistence providers. In our case, the itemPicture was retrieved when we tried to retrieve an Item instance, and performance was poor. We were able to improve things by dividing ITEMS into two tables: ITEMS and ITEM_DETAILS. Both ITEMS and ITEM_DETAILS share the same primary key, and we remodeled our Item entity to carve out two entities: Item and ItemDetails. We then established a one-to-one relationship between these entities and set the load type for relationship to be LAZY as follows:
@Entity
@Table(name = "ITEMS")
public class Item implements Serializable {
@Id
private Long itemId;
private String title;
...
@OneToOne(fetch = FetchType.LAZY)
@PrimaryKeyJoinColumn(name = "ITEM_ID",
referencedColumnName = "ITEM_DETAIL_ID")
private ItemDetails itemDetails;
}
@Entity
@Table(name = "ITEM_DETAILS")
public class ItemDetails implements Serializable {
@Id
private Long itemDetailsId;
private String originalPurchaseDate;
@Lob
private byte[] itemPicture;
...
}
This change gives us the performance we are looking for, and helps us overcome the reality that not all implementations of the EJB 3 specification are done the same way. This way, we remain neutral with respect to application server vendors, and therefore our application is more portable across persistence provider implementations.
Choosing the right inheritance strategy
As you learned in chapter 8, EJB 3 supports three type of inheritance mapping strategies. Each has its own advantages and disadvantages, but the single-table strategy will probably give you the best performance. This is because all entities are stored in a single table and JOINs between tables are avoided. As discussed in chapter 8, we can create a single table named USERS for User and all its subclasses such as Bidder, Seller, Admin, etc., and use a discriminator column to track the subtypes. Consider the following:

Notice ![]() that discriminatorType has a data type of DiscriminatorType.STRING and a length of 1. These are set in conjunction with the inheritance strategy
that discriminatorType has a data type of DiscriminatorType.STRING and a length of 1. These are set in conjunction with the inheritance strategy ![]() of SINGLE_TABLE. This means that you can assign the actual value as a Java String type, but the value will be whatever your application decides to use for the various subtypes supported. In this case "S" is used to represent a Seller
of SINGLE_TABLE. This means that you can assign the actual value as a Java String type, but the value will be whatever your application decides to use for the various subtypes supported. In this case "S" is used to represent a Seller ![]() and "B" represents a Bidder
and "B" represents a Bidder ![]() . But then you already figured that out, didn’t you?
. But then you already figured that out, didn’t you?
13.2.2. Tuning the JDBC layer
You remember from our discussion earlier in this book that JPA internally uses JDBC to store and retrieve entities. When you deploy your applications using the EJB 3 JPA in an application server environment, you are taking advantage of the JDBC connection pooling configuration of the application server. Tuning the application server may improve performance of your applications.
Properly sizing the connection pool
Every application server supports pooling connections, and you should not forget to size the connection pool appropriately. In a high-transaction system, if there are more concurrent users than the available number of connections, users have to wait until connections are released in order for their requested functions to be performed. This may degrade performance of your applications. You have to properly size the pool’s startup and runtime characteristics (such as both the minimum and maximum number of connections in the pool, and the timeout before an unused connection is automatically returned to the pool) based on your application requirements. Review your vendor’s documentation for available options.
Caching SQL statements
The persistence provider executes SQL on your behalf. In a transaction-centric system like ActionBazaar, it is likely that the same SQL statement will be executed by the persistence provider many times. Applications servers such as BEA WebLogic and Oracle Application Server provide the ability to cache SQL statements and reuse them. This lowers the overhead of cursor creation as well as the parsing of SQL statements—both of which can be very time consuming. Typically this is configured in the data-source configuration of the application server as follows:
<data-source>
...
num-cached-statements = "200"
...
</data-source>
Check your application server documentation to see whether it supports statement caching and make the appropriate changes.
You must use parameter binding for your queries in order to take advantage of statement caching instead of concatenating the parameters in the query. For example, you may choose to write your query as follows:
Query query = em.createQuery(
"SELECT c FROM Category c" +
"WHERE c.categoryName = " + categoryName);
The problem with this statement is that it does not use parameter binding, and therefore cannot be cached by the persistence provider. Change your query to use a parameter as follows:
Query query = em.createQuery(
"SELECT c FROM Category c" +
"WHERE c.categoryName = ?1");
query.setParameter(1, categoryName);
This allows your query to be a candidate for the cache. This small change to the programming model of the developer can have a huge impact in the overall performance of your application, depending on how many SQL statements your application has, and how often they find their way into the cache at runtime. This is one small change you can make in the early stages of development that can help build better performance into your programs.
Using named queries
Instead of using dynamic queries, make sure that you use named queries in your applications. A named query is prepared once and can be efficiently reused by the persistence provider. Also, the generated SQL can be cached.
You can convert the previous query to a named query like this:
@NamedQuery(
name = "findCategoryByName",
query = "SELECT c FROM Category c WHERE c.categoryName = ?1")
public class Category implements Serializable {
}
Then you can use the named query in your application as follows:
Query query = em.createNamedQuery("findCategoryByName");
query.setParameter(1, categoryName);
The named query findCategoryByName contains a placeholder for a value to be passed at runtime (?1). This code snippet specifies that parameter 1 should be categoryName. You provide the parameters to named queries in the same way you would when using dynamic queries. However, named queries can be optimized, so we recommend you use them whenever possible.
Avoiding transactions for read-only queries
Transaction management is an expensive affair. If the results of your queries won’t be updated, then don’t use a transaction. By default the transaction attribute for a session bean is REQUIRED. Change it to NOT_SUPPORTED for read-only queries.
13.2.3. Reducing database operations
Reducing database operations directly improves performance of applications. But while using the EJB 3 JPA you don’t directly write SQL since the SQL is generated by the persistence provider. At this point you’re asking yourself, “Then how you can reduce the database operations?” We’re glad you asked...
Choosing the right fetch type
In chapter 9 you learned that a relationship may either be eagerly or lazily loaded. Lazy loading leads to multiple SQL statements, whereas eager loading relates to a SQL JOIN statement and translates to unnecessary data. If you’re using EJB 3, by default the associated entities are eagerly loaded when you have a one-to-one or many-to-one relationship, or lazily loaded when you have a one-to-many or many-to-many relationship. However, there may be several situations when you don’t need a related entity, such as the BillingInfo for a given User, or a related ItemDetails for a specific Item. In such cases you can disable eager loading.
There may also be situations when you want a related collection of entities to be loaded automatically, where a one-to-many relationship exists that forces you to switch to EAGER loading. We warn you to be very careful when turning on eager loading for one-to-many relationships.
If you’re not sure whether eager loading is the right strategy for your association, you may want to try setting eager loading in your JPQL query. Suppose you want to eagerly load the BillingInfo for a User entity. We can use the FETCH clause with a JOIN like this:
SELECT u
FROM User u JOIN FETCH u.billingInfo
WHERE u.firstName like ?1
This query will eagerly load the BillingInfo object for User even if fetch mode is specified as LAZY in the association definition.
Deferring database updates until the end of transactions
By default the flush mode for EJB 3 is AUTO; that is, the EJB 3 persistence providers execute SQL statements to update the database at the end of the transaction and whenever a query is executed that may retrieve updated data. The persistence providers optimize SQL at the end of the transaction.
You can control the database updates by using the EntityManager’s flush method. Using flush in between a transaction may lead to multiple SQL statements. Excessive use of flush may degrade the performance of your application, so we recommend that you not use it unless you have exhausted all other options.
You can optionally set the flush mode to COMMIT. This means that all updates are deferred until the end of the transaction. In this situation the EntityManager doesn’t check for pending changes. You can set FlushMode for the EntityManager em as follows:
em.setFlushMode(FlushModeType.COMMIT)
This will set FlushMode to COMMIT for all queries executed within the active persistence context.
On the other hand, if you want to set FlushMode on a per-query basis, you can do this:
Query query = em.createNamedQuery("findAllItems");
query.setFlushMode(FlushModeType.COMMIT);
List items = query.getResultList();
As you can see, you have the flexibility to manually control flushing by calling the flush method, setting FlushMode on a persistence context basis (discussed in chapter 9), or setting FlushMode on a per-query basis (discussed in chapter 10). The EJB 3 Expert Group wants you to have your FlushMode “your way”!
Using the lowest-cost lock in the database
Although the EJB 3 JPA doesn’t require persistence providers to support pessimistic locking, your persistence provider may support this lock mode as an extension. We recommend you avoid pessimistic locking unless you really need it because the database locks the record or page during the transaction. Even if you are using optimistic locking, use the lowest lock (i.e., the READ lock) if it will satisfy your application requirement.
Using DELETE_CASCADE appropriately
In chapter 8, we discussed setting the cascade type to REMOVE for one-to-many or one-to-one relationships. If you set cascade to REMOVE or ALL, when you remove an entity any associated entities are also automatically removed. For example, if we remove a Seller entity, then the associated BillingInfo is also removed. This will lead to at least two DELETE statements in the database.
public class Seller {
...
@OneToOne(cascade = CascadeType.REMOVE)
public BillingInfo getBillingInfo() {
}
}
For a one-to-many relationship, it may lead to removal of multiple rows, which could have a negative impact on performance. Many databases support enforcing a CASCADE DELETE constraint on tables:

We suggest you consider using CASCADE DELETE as a table constraint. This normally yields better performance than a DELETE statement.
Using the cascade property
Remember from our discussions in part 3 that you can set the cascade type of relationships to NONE, PERSIST, MERGE, REFRESH, REMOVE, or ALL, as in this example:
public class Seller {
...
@OneToMany(cascade = CascadeType.ALL)
public Items getItems() {
}
}
Each of these options impacts how the related entities are handled when an entity operation is performed. For example, when set to ALL, the persistence provider will try each operation (persist, merge, refresh, etc.) on the target entity. These may result in unnecessary database operations when you have several associated entities, and each of the operations is cascaded. So when setting the cascade property, take into account the needs of your applications.
Bulk updates
Your application may require changes to multiple entities within one transaction. You may wish to retrieve a collection of entities and iterate through each to make changes. If we want to give Gold status to all Sellers who have been members of ActionBazaar for longer than five years, we can do it like this:
Query query = em.createQuery(
"SELECT s FROM Seller s WHERE s.createDate <= ?1");
...
List sellers = query.getResultList();
Iterator i = seller.iterator();
while (i.hasNext()) {
Seller seller = (seller) i.next();
seller.setStatus("Gold");
}
This will lead to many UPDATE statements being generated by the persistence provider. You can reduce this to a single UPDATE statement by using the bulk Update feature of JPQL as follows:
Update Seller s
SET s.status = 'Gold' WHERE s.createDate <= ?1
This JPQL statement will update all Sellers to a Gold status with the creation date specified—in one fell swoop. If 10,000 sellers meet this criterion, executing this in one SQL statement instead of 10,000 is a huge performance improvement.
Avoiding association tables in one-to-many relationships
Association tables are commonly used to store unidirectional, one-to-many relationships. This is supported in EJB 3 with the @JoinTable annotation. Using an association table will require extra SQL statements to manage the relationship, as well as unnecessary JOINs between the base tables and association tables. You can gain some performance benefit by avoiding association tables.
13.2.4. Improving query performance
Even trivial applications can make extensive use of queries. When using EJB 3, you write queries in JPQL and they are translated to SQL. Although you develop in JPQL, you can take certain actions to ensure that the corresponding queries will perform well. DBAs can certainly play a big part in helping improve queries.
You may also be interested in enabling a higher level of logging in your persistence provider to expose and capture the generated SQL statements, and run them through a “tuning utility” provided by your database vendor. This can help you determine whether the SQL can be improved. Certain databases provide an automatic SQL tuning utility that provides suggestions for improving the SQL executed by an application. You can work with your DBA to use such tools and get their recommendations on how to improve query performance.
There is no magic sequence of steps that address all query issues, but we’ll discuss some of the more common scenarios.
Avoiding full-table scans
Unless your entity is mapped to a very small table, you must avoid using SELECT statements that perform full-table scans. For example, you can retrieve all items in a query like this:
SELECT FROM Item I
Next, you retrieve the returned collection, iterate through the collection, and perform one or more operations on the resulting data. The persistence provider will generate the following SQL:
SELECT *
FROM ITEMS
There are two problems here. First, this code will retrieve and bring in a lot of rows into the middle tier and consume a lot of memory. Second, it will cause a FULL TABLE SCAN in your database and the query will be very slow. Your DBA will advise you to avoid such SQL. Realistically, the number of available items you want is much less than the total number of items in your database. You must utilize the full potential of database filtering by changing your query to limit the number of rows retrieved as follows:
SELECT i
FROM Item i
WHERE i.status = "Available"
The query will be much faster and you don’t have to do any extra filtering work in the middle tier.
Using indexes to make queries faster
Indexes make your query faster. Your DBAs are probably responsible for building the indexes on tables, but there’s a good chance that they don’t know the details of how your application works. You should work with them so that they understand the queries used by your application. Only then can they build appropriate indexes for your application. Queries that include the primary key always use an indexed scan, meaning that no additional indexes are required. In spite of this, here are some additional cases where you’ll want to use an index to improve performance.
Filtering based on a nonidentity field
This is very prevalent in applications. For example, suppose you want to retrieve your Item entities by itemTitle as follows:
SELECT i
FROM Item i
WHERE i.itemTitle = ?1
This JPQL statement will be translated to SQL as follows:
SELECT *
FROM ITEMS
WHERE ITEMS.ITEM_TITLE = ?1
If you do not have an index on ITEM_TITLE, the query will include a FULL TABLE SCAN. Therefore, we recommend you create an index in these situations. In this case, the index would be created on ITEM_TITLE.
Using indexes for relationship fields
Relationships are implemented in the database by using foreign key constraints. However, you may not have indexes on the foreign key column(s). When you retrieve an associated entity, a JOIN between the two underlying tables is performed. But this is slow because a FULL TABLE SCAN will be executed on the associated entities. Creating an index on the underlying table will allow the database to use that index while joining the tables, which is must faster than joining two large tables without an index.
In ActionBazaar, Item and Bid have a one-to-many relationship due to eager loading. If you have a JPQL query that uses a JOIN clause, the persistence provider could generate the following SQL statement:
SELECT *
FROM BIDS INNER JOIN ITEMS ON ITEMS.ITEM_ID = BIDS.ITEM_ID
WHERE ITEMS.ITEM_ID = ?1
If we assume that there is no index on the BIDS.ITEM_ID, the Oracle database handles this SQL statement like so:
SELECT STATEMENT ()
NESTED LOOPS ()
TABLE ACCESS (BY INDEX ROWID ITEMS)
INDEX (UNIQUE SCAN) ITEM_PK
TABLE ACCESS (FULL) BIDS
If you add an index on the ITEM_ID column for the BIDS table, you’ll see the query plan for our SQL statement change as follows:
SELECT STATEMENT ()
NESTED LOOPS ()
TABLE ACCESS (BY INDEX ROWID ITEMS)
INDEX (UNIQUE SCAN) ITEMS_PK
TABLE ACCESS (BY INDEX ROWID BIDS)
INDEX (RANGE SCAN) BID_ITEM_IDX
Review your queries with your DBAs and they should be able to determine whether adding an index for a column makes sense.
Ordering a collection of entities
You can order the entities retrieved in a collection by using the @OrderBy annotation. In ActionBazaar, if we want to retrieve Bids in descending order of bidPrice, we can do this:
@OneToMany
@OrderBy("order by bidPrice DESC")
public List<Bids> getBids() {
return bids;
}
Ordering of rows is an expensive operation in the database, especially when a lot of rows are retrieved. Therefore, it doesn’t always make sense to retrieve the entities in an ordered collection. Unless another sort order is required, let’s set the default order using a JPQL query as follows:
SELECT b
FROM Bid b
WHERE b.item = ?1
ORDER BY b.bidPrice
The database will try to order the matching records by BID_PRICE. We expect your DBA will agree that adding an index on BID_PRICE for the BIDS table will improve query performance.
Using functions in the WHERE clause of JPQL
You can use JPQL functions in the WHERE clause of a query. For example, you can create a JPQL query as follows:
SELECT u
FROM User u
WHERE upper(u.firstName) = ?1
This statement will be translated to SQL as follows:
SELECT *
FROM USERS
WHERE UPPER(FIRST_NAME) = ?1
Remember that when you use a function in the WHERE clause, the database won’t use an indexed scan, even if an index exists on the FIRST_NAME column. Because of this, you should avoid using functions in the WHERE clause. Some databases support creating function-based indexes and you can use them if needed. Just be aware that the function-based indexes may not be portable.
For our example, you could consider storing the names in uppercase instead of using the JPQL Upper function.
Reducing round-trips to the database
If your query retrieves a lot of entities, that means a lot of rows are retrieved from the database, and this translates into multiple round-trips between your application and the database. Some JDBC drivers provide facilities to reduce the number of round-trips to the database by setting the number of rows to be prefetched in the middle tier while a result set is being populated. This improves performance of queries that retrieve a large number of rows.
You can pass the JDBC fetch size as a vendor-specific @QueryHint in either a named query or dynamic query as follows. If you’re using TopLink or Hibernate, you can use toplink.jdbc.fetch-size or org.hibernate.fetchSize, respectively. The following code snippet demonstrates using @QueryHint for Hibernate:
@NamedQuery(
name = "findUserWithNoItems",
query = "SELECT distinct u FROM User u WHERE u.items is EMPTY",
hints = {@QueryHint(name = "org.hibernate.fetchSize ", value = "50")}
)
Check the documentation for your persistence provider to find out whether setting the JDBC fetch size is supported.
13.2.5. Caching
The EJB 3 JPA does not require persistence providers to do any type of caching. On the other hand, one of the primary benefits of using most O/R mapping frameworks is that they provide a certain level of caching to reduce trips to the database. Some people think caching is the solution for every performance problem. The reality is that improper use of caching may lead to stale data and a whole different set of performance issues. Before jumping into using a cache, you need to understand how your vendor supports caching.
In most cases, you can improve performance of your applications with the appropriate use of caching. Most persistence providers support caching either entity objects, queries, or both.
Caching probably makes sense for data that is read-only or is not frequently updated (read-mostly). For example, in ActionBazaar some entities such as Category rarely change. Knowing this helps us decide that it makes sense to cache Catalog entity objects.
Some queries may always result in the same data within a specific time interval. For example, a named query findFiveMostPopularItems may always return the same set of entities for a four- to five-hour interval. You may wish to cache the results of that query because almost all users of ActionBazaar would probably wish to see the most popular items.
The caching types you can use with an EJB 3 JPA provider can be broken into three levels, as shown in figure 13.3.
Figure 13.3. You may use caching of objects at three levels: 1) the transactional cache, which is made available by the persistence provider within a transaction to reduce database round-trips; 2) the extended persistence context, which you can use as a caching mechanism with stateful session beans; and 3) the persistence unit level cache (if provided by the persistence provider), which is a shared cache that all clients of the persistence unit can use.
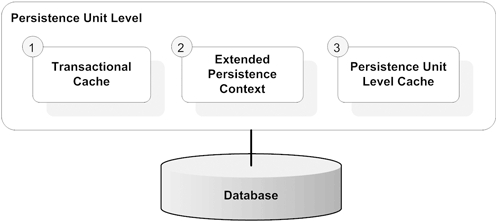
Keep these three levels in mind when evaluating possible options to put in your cache. Try moving items from one cache to another if possible, to determine which configuration works best for your specific application and runtime usage patterns.
Transactional cache
Transactional caching ensures that the object from the cache is returned when the same object is requested again. A typical example is that you run a query that returns an Item entity, and that entity will be cached in the transactional cache. When you use the EntityManager.find method to retrieve the Item again, the persistence provider will return the same Item instance from the transactional cache.
The other benefit of a transactional cache is that all updates to an entity are deferred to the end of the transaction. Imagine what would happen if you did the following in the same transaction:
Item item = new Item();
item.setTitle(title);
item.setInitialPrice(initialPrice);
Seller seller = entityManager.find(Seller.class, sellerId);
item.setSeller(seller);
entityManager.persist(item);
item.setInitialPrice(newInitialPrice);
If your persistence provider doesn’t use a cache and doesn’t defer the commit until the end of the transaction, then it probably will perform what translates to at least two SQL statements. First, it will execute a SQL INSERT to persist the Item. This will be followed by a SQL UPDATE to modify the initialPrice. Most persistence providers will make use of a cache and then execute a single INSERT that will take the new price into account.
Hibernate calls this cache its first level or session cache, and TopLink calls it the UnitOfWork cache. Both of these products enable these caches by default. Check whether your persistence provider supports this type of cache. We aren’t aware of any reason you’d want to disable the transactional cache.
Using an extended persistence context
The transaction cache will demarcate a single transaction. This could be a problem if your application needs to maintain conversational state between different method calls, since it will require multiple round-trips to the database to retrieve the same entity. You can avoid this situation by using an extended persistence context.
You may remember from our discussions in chapter 9 that only stateful session beans support extended persistence contexts. They allow you to keep entity instances managed beyond single method calls and transaction boundaries. You can use extended persistence context as a cache for your stateful bean instance during the state of conversation, which can reduce the number of round-trips to your database. Additionally, all database updates resulting from persist, merge, remove, and so forth are queued until the end of the persistence context, reducing the number of database operations.
Listing 13.1 shows how you can use an extended persistence context for caching entities between method calls of your application.
Listing 13.1. Using an extended persistence context to cache objects across method calls

The PlaceOrderBean uses an extended EntityManager by setting the PersistenceContextType to EXTENDED. The persistence context will live during the entire state of conversation and will be destroyed when the bean instance is
destroyed or removed ![]() . You can store entities as the instance variables of the stateful session bean
. You can store entities as the instance variables of the stateful session bean ![]() and values for the instances are set by different methods
and values for the instances are set by different methods ![]() , and the entities are managed during the lifespan of the extended EntityManager and can be used without having to be detached at the end of the method call. Entity operations such as merge
, and the entities are managed during the lifespan of the extended EntityManager and can be used without having to be detached at the end of the method call. Entity operations such as merge ![]() can be performed outside the scope of a transaction since we have set the default transaction attribute for the bean to NOT_SUPPORTED. The database updates resulting from these operations are queued up and performed when the persistence context is associated
with a transaction
can be performed outside the scope of a transaction since we have set the default transaction attribute for the bean to NOT_SUPPORTED. The database updates resulting from these operations are queued up and performed when the persistence context is associated
with a transaction ![]() . This reduces the number of round-trips to the database.
. This reduces the number of round-trips to the database.
However, you have to be careful when your stateful session bean invokes another EJB such as a stateless session bean—there are several limitations related to the propagation of extended persistence contexts.
Persistence unit level cache
The transactional and persistence context caching mechanisms can only be used with a single client and cannot be shared. You’ll probably see a real performance boost when entity instances in the cache are shared by multiple clients, thus reducing trips to the database for all of them. You can call this an application cache, but we call it a PersistenceUnit cache because entities are scoped in a persistence unit. Hibernate calls this a second-level cache, and you need to configure an external cache provider to take advantage of this second level or session factory level cache. TopLink refers to it as a session cache, and it’s integrated with the persistence provider. In addition, the TopLink implementation provides several options for configuring this cache. Review your vendor documentation to see whether it provides the ability to cache objects out of the box.
You can either cache entities or queries in the PersistenceUnit cache. When you retrieve some entities using a query, those entities will be cached. If you try to retrieve a cached entity by using the EntityManager’s find method, then the entity instance will be returned from the cache. Typically, persistence providers store the entities in the cache using their identities, so you must use the find method to retrieve an entity by its primary key.
If your EJB 3 persistence provider supports caching of entities in a PersistenceUnit cache, it is probably done with a vendor-specific name-value pair of properties in a configuration file. In the following example we are trying to cache 5000 instances of the Category entity in TopLink Essentials:
<persistence>
<persistence-unit name = "actionBazaar">
...
<properties>
<property name = "toplink.cache.type.Category"
value = "CacheType.Softweak"/>
<property name = "toplink.cache.size.Category"
value = "5000"/>
</properties>
</persistence-unit>
</persistence>
If you want to cache a query result, then you probably want to do it on a per-query basis, either stored in an external configuration or as a QueryHint for the query. Check your persistence provider documentation to determine how it supports the caching of queries.
Here is an example of how TopLink Essentials can be used for caching in a named query using @QueryHint:
@NamedQuery(
name = "findActiveCategory",
query = "SELECT c FROM Category c WHERE c.status = 'Active",
hints = {@QueryHint(name = "toplink.cache-usage",
value = "CheckCacheOnly")}
)
You can also provide a hint to refresh the cache from the database with a query like this:
Set<Category> category = (Category)
em.createNamedQuery("findActiveCategory")
.setHint("toplink.refresh", "true")
.getResultList();
Now that you have seen some examples of caching, let’s discuss some caching best practices.
Read-only entities
You can significantly improve application performance by using read-only entities. Examine your applications to determine whether any entities may be made read-only. For example, in our ActionBazaar system, office locations change very rarely and we can make the ShippingType entity read-only. Unfortunately, like caching features, the read-only feature is a vendor extension and you have to depend on either a vendor-specific API or configuration to mark an entity as read-only. Normally, read-only entity instances will be loaded into the PersistenceUnit cache and never discarded.
Read-only entities will significantly improve performance because persistence providers won’t calculate the change set for the read-only entity, and no clone or merge operations will be performed against a read-only entity.
Caching best practices
Understanding your applications and checking your caching strategy usually makes sense for your applications. The cache is best used for entities that are not frequently updated or that are read only. Make sure that table data is updated only by the application that is using the cache, because if any external applications update the same cache, someone working with the cache will end up with stale data.
Check your persistence provider for details on how they support caching entities and queries; the caching mechanism varies from provider to provider. For example, one provider may follow this rule: if an entity is updated in a transaction, then the entity will be updated in the cache when the transaction is committed to the database. However, some persistence providers may choose to expire the cache instead.
Stress-test your applications with and without a cache. It’s the only way to determine if using the cache, and more specifically the particular cache configuration, will improve or degrade your applications’ performance.
That concludes our discussion on improving EJB 3 entity performance. Are you feeling faster yet? Even if you’re not, your entities should be. Next, let’s look at how you can improve the performance of session and message-driven beans.
13.3. Improving performance of EJB 3 components
Most application servers provide the ability to generate usage and utilization statistics of EJB components such as session beans and MDBs grouped by application. You have to read your vendor documentation about the parameters they provide, and you have to work through some amount of trial and error to utilize these parameters optimally to improve the performance of your EJB components.
This section provides general guidelines, some of which are design practices that you can follow while building your applications. As stated earlier, it’s a good idea to factor in performance considerations throughout the development lifecycle of your applications. Don’t try to do it all up front, because you’ll end up with a more complicated design than you need, and it’s going to change anyway at multiple points during the life of the system. Don’t try to do it all at the end, because you’ll have to make sweeping changes in order to effectively implement the required optimizations. Follow the same strategy you would to fill your car’s fuel tank; a little at a time over the life of the vehicle. Sometimes you top the tank off, and sometimes you just get $10 worth. (All right, with today’s prices maybe $25.) But you don’t calculate how many miles you will ever drive the car and try to carry around that much gas when you buy it. And you certainly don’t wait until you want to sell the vehicle before buying any gas; it wouldn’t be much use as a form of transportation if you took that approach. Simply think about where you’re going in the near future, and buy that much gas. Tackle performance tuning in the same way, and you’ll be on your way to a bunch of happy users.
We’ve already covered performance concerns surrounding entities. Let’s see what we can do to make our session and message-driven beans a little snappier.
13.3.1. Session bean performance
Session beans are probably the most frequently used EJB component. Like the teenyboppers vying for a spot on American Idol, they’re everywhere. It’s hard to visit a Java EE application and not hit one. Even with the tremendous pull that alternative inversion-of-control containers like Spring have had, session EJBs live on. Since you’re likely to trip over one getting to your Dilbert cube in the morning, this section will focus on how you can improve session bean performance.
Local vs. remote interface
EJB 3 not only provides the ability to invoke components remotely, but also empowers you to build lightweight components that can be deployed and run locally with your presentation modules. If your clients and EJB components are collocated together, then you must make sure you do not mark your interface with the @Remote annotation. @Remote uses an expensive RMI call requiring copy-by-value semantics, even if the clients are in the same JVM. Most containers provide optimizations to change RMI calls to local EJB invocation when possible by setting some attributes in your vendor-specific deployment descriptor. Refer to your application server documentation for details about your specific server.
Use stateful session beans only when necessary
We have observed gross misuse of stateful session beans, which causes developers to become disappointed with their performance. Most enterprise applications are stateless in nature, so you should determine whether you need stateful session beans. Stateless session beans perform much better than stateful session beans since they are not required to manage state. The extended persistence context is supported only with EJB 3 stateful session beans, and there is no way out if you want to use it. Later in this chapter we provide some guidelines to specifically improve performance of stateful session beans.
Refactor multiple method calls to use the Session Façade design pattern
EJB invocation is expensive, particularly when you use it remotely. You should avoid building fine-grained EJBs by following the Session Façade design pattern. Check to see whether you can consolidate several EJB methods into a single coarse-grained EJB method. Reducing multiple method calls to a single call will improve the performance of your EJB applications.
Look at transaction attribute settings
Recall from chapter 6 that transaction management is an expensive affair. Verify that each EJB method really needs a transaction. If you are using CMT (by default), the container will start a transaction for you because the default transaction attribute is Required. For methods that don’t require a transaction, you should explicitly disable transactions by setting the transaction type to NOT_SUPPORTED as follows:
@TransactionAttribute(TransactionAttributeType.NOT_SUPPORTED)
public List<Item> findMostPopularItems() {
...
}
If you are confused about which transaction options are available, refer to chapter 6, or consult your application server’s documentation.
Optimize the stateless bean pool
Stateless session bean instances are pooled and shared by clients. You should have sufficient bean instances to serve all your concurrent clients. If you don’t have enough bean instances in the pool, the client will block until an instance is available. Most application servers provide the ability to configure the bean pool in a vendor-specific deployment descriptor by specifying a value for the minimum and maximum number of instances to be kept in the bean pool. Keeping it too low will create contention issues, whereas keeping it too high may consume excessive memory. Use the “Goldilocks” principle here, and try to get the minimum/maximum range “just right.”
The stateful bean cache and passivation
A stateful bean is associated with a specific client. When a client needs a bean instance, the container creates a bean instance for it. However, the container cannot maintain an infinite number of active bean instances in memory while constantly passivating bean instances that are not actively being used. The container serializes all instance variables stored in a stateful bean and writes the bean’s state into secondary storage (an external file) when it decides to passivate the bean instance. The passivated bean instance is activated or brought back into memory when the associated client invokes a method on a bean instance that has been temporarily pushed out of the cache. Unnecessary passivation and activation will slow down the performance of your applications. Investigate your server’s configuration options in order to properly set the bean cache or passivation policy so that frequent passivation and activation is avoided.
Use a remove method for stateful beans
You must destroy a stateful bean instance by using the @Remove annotation when the conversation ends. As explained in chapter 3, any business method can be annotated with @Remove so that upon successful completion of that business method, the bean instance will be destroyed. Take a look at confirmOrder:
@Remove
public Long confirmOrder() {
}
If you do not remove stateful bean instances when they are no longer needed, then the number of inactive (essentially dead) instances will grow, forcing passivation/activation in the container.
In addition to @Remove, most containers provide the ability to time out and destroy a bean instance by setting an expiration time in the vendor-specific deployment descriptor. This timeout can be used to help keep the number of bean instances to a manageable number. Its purpose is to set a timer for beans that are not used by clients for longer than the specified expiration time. We recommend you take advantage of this timeout to reduce the time that unused bean instances hang around, soaking up space.
Control serialization by making variables transient
As stated earlier, the container performs serialization and deserialization of instance variables during passivation and activation. Serialization and deserialization are expensive processes. When you store large objects in your instance variables, the server spends a lot of CPU cycles and memory in the serialization and deserialization process. If you don’t want to serialize a particular object, mark that object to be a transient object and the container will skip that object during passivation/activation.
@Stateful
public class PlaceOrderBean implements PlaceOrder {
transient private Bidder bidder;
private List<Item> items;
private ShippingInfo shippingInfo;
private BillingInfo billingInfo;
..
}
Here we have defined bidder as a transient object and the EJB container will not serialize the bidder object when a bean instance gets passivated or when its state is replicated to another server. If after marking several fields as transient you observe data missing from your objects, it simply means that you went a little overboard and will need to undo some of the fields you marked as transient.
13.3.2. Improving MDB performance
The following are some guidelines that you can use to optimize the performance of your MDB applications. We provided some MDB best practices in chapter 5 that you can use as a starting point. After implementing those techniques, you may want to revisit this section for some additional tips.
Tuning the JMS provider
Most of the performance issues surrounding MDBs are generally related to the underlying JMS providers. Some general tips that we provided in chapter 4 include choosing the right messaging models and persistence strategy, using the correctly sized messages, setting the lifetime of messages, and using appropriate filters and handling of poison messages. Check your vendor documentation for the JMS provider you are using for your applications.
Initializing resources
Like stateless session beans, MDB instances are pooled, and initialization tasks are performed only once, for any given MDB instance. You can perform expensive tasks such as initialization of resources (opening database connections, sockets, files, etc.) in any method annotated with @PostConstruct. Methods marked with @PostConstruct will be invoked only once, immediately after creation. Similarly, close any resources in methods annotated with @PreDestroy. This will significantly improve the performance of your classes in general, and your MDBs in particular.
Sizing the pool
MDBs are pooled, and the pool size is usually configured using vendor-specific deployment descriptors. Improper sizing of MDB pools may degrade performance of your applications when large numbers of messages arrive and there is not a sufficient number of bean instances available to process those messages.
Make sure you do some predictive analysis in determining the capacity your system will need to support (including spikes, and growth over the short term). Then run some tests that will show how your hardware, operating system, and application server will perform to meet these expectations. There are almost as many ways to configure hardware and operating systems as there are combinations of the two. Once you are happy with that configuration, make sure your application server pool for MDBs is sized as well.
This concludes the discussion on EJB performance. It’s time to focus on scalability and high availability, which are two other important aspects of enterprise applications.
13.4. Clustering EJB applications
High availability and scalability go hand in hand. Every application has some requirement for availability and scalability, and meeting those requirements begins when you start architecting the application. Availability requirements can vary widely. Some applications, say a human resources (HR) application, may have a requirement to be available only during normal business hours. On the other hand, an online bidding system may have a requirement to be available 24/7, year-round. Similarly, the scalability requirements for an HR application may not be as demanding as an online bidding system.
The EJB 3 specification doesn’t address clustering aspects for EJB applications. However, most application server vendors allow customers to cluster EJB containers to achieve the desired scalability and availability aspects required by today’s demanding enterprise applications. Before we dive into such architectural concerns, let’s discuss a couple of concepts that will help you understand the basic aspects of EJB clustering:
- Load balancing— This is when multiple application server instances work as a group to balance the incoming request load across all the servers. This allows for scalability of applications. When your user base increases, you can simply add new server instances to the group. This is typically most useful when your application is stateless in nature.
- Failover— Adding failover capability to your applications improves the availability of your applications. Clients typically get bound to a specific server instance by stateful applications. In the event of a catastrophic failure of a server, the client requests are routed to a separate server in a seamless manner, transparent to the user.
Clustering of EJB applications adds load balancing and failover capabilities to your applications. Covering all aspects of clustering is beyond the scope of this book. In this section we’ll provide architectural primers, and focus on the knowledge you need to effectively build scalable, available EJB applications.
There are several ways to deploy EJB applications. We’ll discuss three commonly used approaches. We won’t describe any configuration details related to clustering because clustering tends to be vendor specific.
13.4.1. Collocated architecture
This popular architecture is where EJB applications and their clients (web applications) are hosted in the same container, and typically the HTTP requests are load-balanced between multiple instances of application servers. If your application is stateless in nature, then you probably don’t have to do anything except deploy the identical application on multiple servers, as illustrated in figure 13.4.
Figure 13.4. EJB(s) and web applications are collocated, and web applications use the local EJB interface to access the nearby EJBs.

If your application requires statefulness and you want to achieve session failover, then you must enable HTTP and EJB session state replication, which allows you to replicate HTTP session objects between two server instances. This is done so that if one instance fails, the client doesn’t lose the session state. If your business logic is stateless in nature, this is something you don’t have to worry about. Your application will work as expected when your sessions fail over to another container, assuming the identical application is deployed.
If you are using stateful session beans to store session objects, then things will be a little trickier here. As mentioned in chapter 12, you should store the EJB object in the HttpSession object. Check your vendor documentation before you start developing your applications, because it will avoid frantic refactoring of code the day before you release everything to production.
You have to enable session replication for your application server; that way, when a session failover occurs, the client will be routed to another server instance where the HTTP session was replicated. The HttpSession object will be restored and the client can retrieve the EJB object to perform the necessary operations. Some vendors may not allow replication of local EJB stateful session beans, so check your vendor documentation. You may have to use the remote interface, even if the client and bean are collocated in the same Java EE container in order to enable session replication.
What happens when multiple instances of your application are required in order to divide the web and EJB tiers into different containers? Next we’ll see how EJB containers support load balancing of stateless EJBs.
13.4.2. Load-balancing stateless session beans
Your clients may be located remotely from the EJB container. The clients may be JSF or JSP applications running in a separate container, or Swing/SWT clients running in an application client container. You must realize that when dividing EJBs and their clients into separate JVMs, you are imposing a condition that Remote Method Invocation (RMI) be used to communicate between them. If you plan to use this architecture, you’ll have to use remote interfaces for your EJBs.
Most application servers support load balancing of requests between multiple application server instances. When using this architecture, the same application is deployed in all instances. Since the EJBs are stateless, the client can go to any of the servers being load-balanced, as seen in figure 13.5.
Figure 13.5. EJB and web applications are in separate JVMs. Clients access EJBs using the remote interface via RMI. The same EJB application can be deployed to multiple servers.

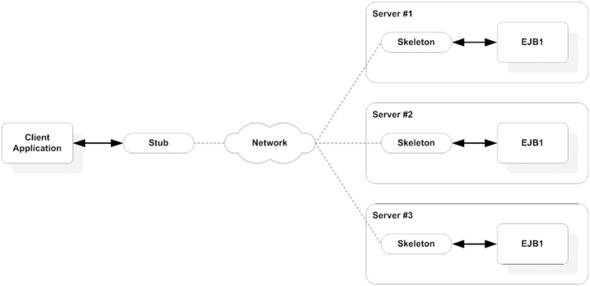
If you want to use load balancing of stateless session beans deployed in a cluster, you need a basic understanding of RMI and remote invocation of an EJB. We briefly discussed RMI in chapter 1. Figure 13.6 shows how remote invocation of an EJB works.
Figure 13.6. The skeleton in the EJB server gives out a stub to the client. This stub is used by the client to communicate with the EJB remotely.

As evident from figure 13.6, the client stub has the information on how to communicate to the remote EJB server. Most application servers automatically generate the client stub while looking up an EJB remotely.
This information is commonly based on the JNDI environments, which are populated while creating the InitialContext. You typically provide this in a jndi.properties file. If you remember our discussion from chapter 1, you provide the URL for the server that hosts the EJB we are accessing.
Again, because EJB clustering is considered a proprietary enhancement, each application server implements it in its own way. That way, the application server knows the load-balancing algorithm and the servers being load-balanced. An example of this appears in figure 13.7.
Figure 13.7. The stub that is downloaded by the client is instrumented with the load-balancing algorithm and has knowledge of the load-balancing servers.
A remote EJB lookup requires that you specify a JNDI provider URL for a JNDI server. The client looks up the EJB and downloads the client stub. The stub contains information about all the servers being load-balanced, as well as the load-balancing algorithm being used. Once more, check your vendor documentation for the various JNDI properties that you need for creating the InitialContext. You may have to do some configuration in your EJB applications to enable load balancing between different application server instances.
If you want to use load balancing for stateless session beans, as a developer you’ll have to do the following:
- Build a remote interface for your stateless session bean and expose the appropriate methods in the remote interface.
- Reduce the number of method invocations by using a coarse-grained session bean.
- Make appropriate configurations using the vendor-specific deployment descriptors if required.
- Because the client code for the EJB needs to know that you are using clustered application server instances, provide the URL for the clustered JNDI server or application server.
The disadvantage of this approach is that it will only work for stateless applications, not when using stateful session beans. We tackle that situation next!
13.4.3. Clustering stateful session beans
As you know, stateful session beans are used to maintain conversation state between the client and server by storing the state in instance variables. If you want end-to-end availability for your applications, then you have to maintain state. You probably also want session state to be replicated to other servers, so that if one server crashes the client state is restored from another server, as shown in figure 13.8. Assume that when a client accesses a stateful session bean in a cluster it gets bound to a stateful EJB in Server 2. It establishes a conversation, and state is stored in the bean instance in Server 2. Because we have session state replication enabled for the EJB, the state is replicated to Server 1 and Server 3. If Server 2 should happen to crash, then the client will be routed to one of the other servers and the conversation state will be restored.
Figure 13.8. Session state is replicated to other servers based on the server: 1) clients establish a session with a stateful bean in Server 2; 2) conversation state is replicated to Server 1 and Server 3 because state replication is enabled; and 3) if Server 2 crashes, the client gets routed to either Server 1 or Server 3 and there will be no loss in its state.

Application servers support several mechanisms to propagate changes in the session state, such as IP multicasting peers and peer-to-peer. The session state change is copied to other servers in the group when one of the following occurs:
- At regular intervals (such as the end of every method call)
- When a JVM is terminated
- At the end of a transaction
Refer to your vendor documentation to learn what propagation mechanisms are supported for session replication. Additionally, you have to make changes in your session bean configuration using either a proprietary annotation or a deployment descriptor to enable session replication. This will set the appropriate propagation mechanism for your session bean. To expedite the configuration process, we recommend that you check your vendor’s documentation before you implement stateful session bean clustering.
Here are some best practices we recommend to developers for using stateful session bean clustering:
- Check whether you really need stateful session beans and have to replicate the session for them. Stateful session bean replication requires expensive serialization, propagation of the serialization, and deserialization of the session state.
- Make sure any required session state is minimal. Most vendors recommend that you not store stateful objects larger than 4KB. When storing a state, it is better to store a key rather than a large entity object in the session state. Perform some testing on your applications if you think you need more state than this. The common technique to get around the 4KB limit is to store only one or more session keys in the state, and use these to retrieve the larger data on the server where it is used.
- Don’t hard-code any vendor-specific annotations to enable session replication. Instead, use vendor-specific deployment descriptors.
- The client code for an EJB needs to know that you are using clustered application server instances and enabling session replication. Therefore, you have to provide the URL for the clustered JNDI server or application server that knows about this information.
13.4.4. Entities and clustered cache
Section 13.3 covered how you can enable caching for your persistence unit if you want to enhance the performance of your applications. However, if you are using the same entities in multiple server instances, then each instance has its own cache. It is highly likely that your cache may become stale or out of synch with the actual data when a client writes to the database. If you are using entities in an enterprise application and you want to make the application readily available, then you must have some mechanism to synchronize the cache between different server instances. The approach we’ll discuss is depicted in figure 13.9.
Figure 13.9. Distributed cache synchronization is used to synchronize the entity cache between two different Java EE containers.

Because EJB 3 JPA implementations are new, very few application servers will provide this feature. At the time of this writing, only JBoss’s and Oracle’s implementations provided support for distributed cache synchronization.
It’s a very challenging task to synchronize the cache for a large distributed application, and this becomes nearly impossible when you have a large number of server nodes. You must keep this in perspective when designing the application. The persistence providers typically depend on the clustering configuration of the application servers, which may use IP multicasting, RMI, or JMS to synchronize the caches. Check your vendor documentation for their level of support.
Remember to
- Determine whether you really need distributed cache synchronization. Check your vendor documentation to see whether it is supported.
- Analyze your refresh policy. Caching and refreshing queries may not yield the best results in a distributed cache situation.
- Confirm whether the caching solution provides a distributed transactional guarantee. Compare your persistence provider’s support against commercial caching solutions such as Tangosol’s Coherence. Using a distributed cache is not recommended in a highly transactional system. It is difficult to achieve good performance from a distributed cache.
13.5. Summary
In this chapter we provided several guidelines to tame those wild EJBs. First, we discussed various types of locking strategies. The EJB 3 JPA specification requires support for optimistic locking of entities.
We then turned our attention to entity tuning. You can improve performance of your persistence tier by making some modeling and/or schema changes, writing appropriate queries, and working with your DBAs to create appropriate indexes for your database. Persistence providers use caching to reduce round-trips to the database, and you may benefit from using an appropriate caching strategy to increase your entity performance.
We explored several ways to optimize the performance of session beans and MDBs. We also surveyed the scalability and availability landscape. EJB clustering is not covered in the specification, and we encourage you to evaluate the clustering support in the application server of your choice.
The next chapter considers EJB 3 migration and interoperability issues.