
Chapter 15. Continuous integration
| 15.1 | Introducing continuous integration | |
| 15.2 | Luntbuild | |
| 15.3 | Moving to continuous integration | |
| 15.4 | Summary |
This book has now covered the entire process of building an application with Ant, from a simple library with a few unit tests, to a server-side application that’s tested by running functional tests on a client or by running unit tests inside the application server.
There’s one more thing that Ant enables that can transform how your project works. Instead of running the builds by hand, why not delegate all the work to a machine? A machine that can rerun the builds and tests nightly, hourly, or whenever you feel the need? Running builds repeatedly is useful, but far too boring to do by hand. That’s the kind of dull, repetitive work that machines are for, and where Ant can help.
This chapter is going to cover setting up a machine to run builds for you, not just to save developer time but also to transform your entire development process. It’s a bit of a change from the previous chapters, as there are more screen shots than XML listings. This doesn’t make it any less important. Indeed, the earlier a project sets up a continuous-integration system, the better.
This chapter will use Luntbuild, which is a web application that can be set up to run Ant builds on demand. But before we can get down to the application itself, we have to understand the concept of continuous integration.
15.1. Introducing continuous integration
Continuous integration is the practice of setting up a system to do your build for you all the time. This is one of the most profound changes you can make to your development process. If you have a machine always building and testing your project, then you can see at a glance whether all is well or not. But you don’t need to check: if things break, the machine can email everyone a warning of the problem. It may even be able to identify what change broke the build and who checked it in.
Nightly builds have long been a feature of software projects: it’s a famous aspect of the development of Windows NT and its successors. But a nightly build has to handle everything checked in during the day. You don’t find out until the morning that something broke, and then nobody can work with the latest code—it’s broken. The whole team ends up wasting half the day finding out what went wrong and fixing it, only having half a day to write new code. And then the whole process repeats itself the next day.
With continuous integration, you find out minutes after any change gets checked in whether it breaks the build or the tests; this lets you fix it before anyone else notices.
Ant builds can be scheduled and automated by using operating system job-scheduling services, such as the Unix cron tool, but that’s still not enough. Dedicated tools can deliver much more, such as the following:
- Automated builds
- Build logs
- Application deployment to test servers
- In-container test suite runs
- Direct reporting of failures to the appropriate developers
- Build numbering and tagging in the SCM repository
- Web-based reporting
Martin Fowler and Matthew Foemmel introduced the term continuous integration in their 2001 paper “Continuous Integration.”[1] This paper showed the benefits of the concept and introduced a tool, CruiseControl, that enabled it. Figure 15.1 shows the architecture of this product. The core of the tool is the build loop, a thread that polls the source code repository every few minutes looking for changes. Any change triggers the bootstrap-and-build process, in which the changed files are retrieved and the build initiated. After running a build, the results are published, along with notifications to developers and other interested parties.
1http://www.martinfowler.com/articles/continuousIntegration.html
Figure 15.1. CruiseControl was the first continuous-integration server. The build loop polled for changes, ran the builds, and published reports; the web front end displayed the results. Everything was driven by the config.xml file.
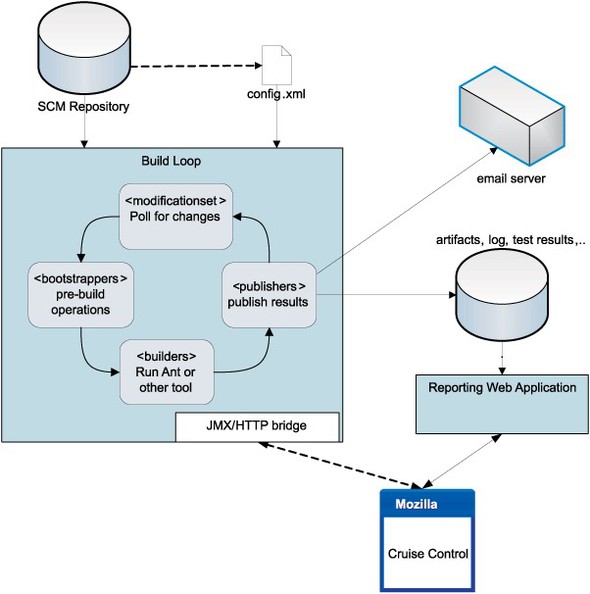
In CruiseControl, the build loop was configured by a single configuration file, config.xml. The web application was a separate process that does little, other than present results. A servlet could act as a front end to the Java management extensions (JMX) beans in the build loop process so it could trigger builds, but all configuration was through that single XML file.
CruiseControl is the venerable king of continuous-integration tools, and one we’ve used extensively in the past. However, there are many challengers for the crown, some of which are listed in table 15.1. It’s a competitive area, with products competing on features, ease of use, and integration with other processes.
Table 15.1. Some of the continuous-integration tools that work with Ant.
|
Product |
URL |
Description |
|---|---|---|
| Anthill | http://www.urbancode.com/ | A tool with good web-based configuration |
| Bamboo | http://atlassian.com/ | Released in early 2007; integrates with the JIRA bug-tracking system |
| Beetlejuice | http://www.pols.co.uk/beetlejuice/ | Commercial; free to open-source projects |
| Continuum | http://maven.apache.org/continuum/ | A new tool from the Maven team |
| CruiseControl | http://cruisecontrol.sourceforge.net/ | The original tool; widely used |
| Gump | http://gump.apache.org/ | A hosted build of open-source Java |
| Hudson | https://hudson.dev.java.net/ | Sun’s open-source continuous integration tool |
| Luntbuild | http://luntbuild.javaforge.com/ | An easy to set up, full-featured tool |
| TeamCity | http://www.jetbrains.com/teamcity/ | From the people that wrote IntelliJ IDEA |
CruiseControl is hard to get up and running; it often needs a bit of nurturing to restart it or fix some problem. This is the main reason why we’re not covering it, looking at Luntbuild instead. Luntbuild is very representative of the latest generation of tools, with web-based configuration and cross-project integration. It’s one of the continuous-integration servers that a team could try out before committing to a specific product.
15.1.1. What do you need for continuous integration?
If you have a project in an SCM repository with a build file that can run to completion without human intervention, you’re ready to begin. What else do you need to bring up a continuous-integration system? You need five things:
- A dedicated server
- A new user
- A build that runs to completion
- A continuous-integration tool
- Free time
That’s all. It’s well worth the effort.
A dedicated server
You need a dedicated machine for running the builds. Don’t try to reuse a developer’s own machine, as the developer can break the build by running tests at the same time, or by changing the system configuration in some incompatible way. Find an old but reliable box, add more memory, install a clean OS release, tighten up security, and then install Java and Ant. If you don’t have a spare machine, try running a Linux system under VMWare, Xen or something similar.
A new user
Create a special user account with an email address, SCM login, and an IM account. This user will be used for sending out notifications and for accessing and labeling the SCM repository.
A build that runs to completion
You need a build file that runs. This is such a minimal requirement that you can start with a continuous-integration service the moment you start a new project. The one thing to avoid is taking a build that doesn’t work and trying to host it on the server. You should avoid doing this because it’s so hard to distinguish problems related to the continuous-integration server from those of the build itself. If you have this problem, set up the server to build a target that succeeds, skipping failing parts of the build such as the tests. You can turn on the tests once the continuous-integration build is functional.
A continuous-integration tool
You need a program to run the build and notify people when it fails. Some people try to do this in Ant, using its <cvs> and <mail> tasks, but this is a wasted effort. There’s a lot of work alongside the build, including polling the repository for changes, assigning blame, and generating the status web pages that Ant doesn’t do. People have written tools to do all of this, so use them.
Free time
Allocate half a day to bring up a continuous-integration server. The more ambitious you get about running functional tests on the server or using different reporting mechanisms, the longer things will take.
Of all these requirements for continuous integration, time is the most precious, especially on a late project. Start early. A continuous-integration system is harder to bring up the more complex the build, so using a simple build from the start of a project makes setup easier. More subtly, just as writing tests from the outset changes how people code, having a machine continually building the application and running the tests changes how people work. It’s better if this new lifestyle is lived from the birth of a project, rather than forced onto the team later on when they already have a defined style of working.
The rarity of free time in a project is also why we prefer Luntbuild over older tools such as Cruise Control. The easier it is to start using a continuous-integration system, the more likely you are to start using it and keep it running.
15.2. Luntbuild
Luntbuild is an open source project, whose homepage is http://luntbuild.javaforge.com/. It’s very easy to install: all configuration is done through web pages. It also has a strong notion of dependencies across projects. You create a separate entry for each project, and can link them together, rebuilding and testing a project if a dependency changes.
It has a self-contained mode, using a private database and servlet engine, or you can host it on your own web server and switch to another database, such as MySQL. That means that it could be used in a managed production environment, with the application running under a central server, sharing a central database. You could even have extra reporting programs running through the build information in the database.
Luntbuild uses the following terms, which we’ll explain in a moment: users, projects, VCS adaptors, builders, and schedules.
User
A Luntbuild user is someone with password-protected access to the site. Each user can have email, instant messaging, and weblog contact information. Different users can have different rights.
Version Control System (VCS) adaptors
Luntbuild uses the term version control system, with the acronym VCS, to refer to a software configuration management (SCM) repository. A VCS adaptor is a binding to a specific SCM repository, including login information. The tool supports CVS, Subversion, Perforce, ClearCase, StarTeam, AccuRev, and Visual SourceSafe.
Project
This represents a software project. It binds a VCS configuration with builds and schedules. Every project also maps accounts in the SCM/VCS repository to Luntbuild user accounts, so it knows who to contact when things break.
Builders
A builder builds projects. It can be Ant or any other command-line program. Builds can be clean or incremental; incremental ones preserve the results of the previous build, and are faster, though they can be contaminated by previous builds.
Schedule
Luntbuild builds things to a schedule. Schedules can be triggered by the clock, by changes in the repository, or by manual requests.
Projects can have multiple builds and schedules, so a clean build can run every night, incremental builds every fifteen minutes, and tests run every hour. Builds can depend on other builds, even across projects.
15.2.1. Installing Luntbuild
Luntbuild comes with an installer JAR, which installs the server, asking a few questions on the way. The simplest installation is a self-contained server using a private database. Follow these steps to install Luntbuild:
1. Download the -installer.jar version of the application, such as luntbuild-1.3final-installer.jar.
2. Install the program on a disk with plenty of space.
3. In the “web application configuration” page,
- Increase the session timeout from 30 minutes to something longer.
- Leave the “path to war deploy dir” field blank. This enables a standalone installation.
4. For the database, select HSQLDB and leave the option fields alone.
5. Skip the LDAP server integration page.
6. Install the documentation as well as everything else.
7. Don’t bother with the automated installation script.
Hosting the tool under Tomcat or JBoss would ensure that the program restarts after it reboots, while a binding to MySQL may scale better. Tomcat and JBoss also increase the installation effort, which is why they’re left alone.
15.2.2. Running Luntbuild
To start Luntbuild, run the application giving your hostname and a socket port that you aren’t using.
java -jar luntbuild-standalone.jar k2 8088
If you’re using Ivy for library management or checking source out from a remote Subversion repository, you may need to add proxy settings to the command line:
java -Dhttp.proxyHost=proxy -Dhttp.proxyPort=8080
-jar luntbuild-standalone.jar k2 8088
Make sure the output shows that the program is listening on the server’s external network address:
21:18:59.096 EVENT Starting Jetty/4.2.23 21:18:59.870 EVENT Started WebApplicationContext[/luntbuild,Luntbuild] Luntbuild : --> context initialization started Luntbuild : --> context initialization finished 21:19:06.112 EVENT Started SocketListener on 192.168.2.68:8088 21:19:06.112 EVENT Started org.mortbay.jetty.Server@1a2961b
If you aren’t careful, Luntbuild may just listen on the local loopback address such as 127.0.0.1:
>java -jar luntbuild-standalone.jar localhost 8088 21:19:42.996 EVENT Starting Jetty/4.2.23 21:19:43.491 EVENT Started WebApplicationContext[/luntbuild,Luntbuild] Luntbuild : --> context initialization started Luntbuild : --> context initialization finished 21:19:49.956 EVENT Started SocketListener on 127.0.0.1:8088 21:19:49.956 EVENT Started org.mortbay.jetty.Server@1a2961b
This means the web page is only accessible to users on the same machine, not for anyone else on the network. Start Luntbuild with the raw IP address if you cannot prevent the system from mapping from a hostname to a loopback address:
java -jar luntbuild-standalone.jar 192.168.2.68 8088
Next, browse to the location of the service:
http://192.168.2.68:8088/luntbuild/
You’ll be prompted for username and password; use luntbuild for both. This should then bring you to the home page of the program, from where you can configure it.
15.2.3. Configuring Luntbuild
Luntbuild claims you can be up and running in half an hour. It’s relatively straightforward, and best shown through screen shots.
Creating users
The first step is to create users, both for login and for notification. Figure 15.2 shows the dialog for a single user. The various notification options—Lotus Sametime, MSN, Jabber, and blog login information—are all for notifications. The email address matters; the rest can be added later.
Figure 15.2. Adding a user to Luntbuild. You can be notified by email, IM, or blog postings.
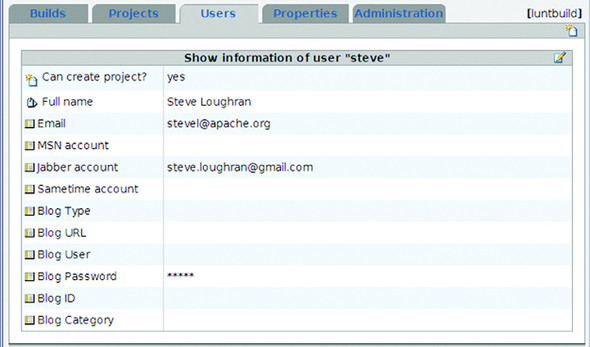
The password is set on the same page as the other options. This forces you to re-enter the password whenever updating any other setting, which means that whoever manages the users needs to know all the passwords. Don’t consider reusing any sensitive passwords in this tool.
Once the users have been entered, you should have a list such as that of figure 15.3. Different users can work on different projects and can have different rights. We tend to run a relaxed house on a private network, but you may want to lock down the system.
Figure 15.3. A server populated with a full set of users

Creating a project
After creating the users, you can create a project. Navigate to the “projects” tab. Create a new project by clicking on the new document icon on the top-right corner of the page. Give the project a name. Add all the users you want on the project.
As anonymous users still appear to have read access to all projects and builds, you cannot keep builds private from anyone with access to the web server.
Binding to an SCM repository
The “VCS Adaptors” tab of a project is where you set up the repositories of a project. Every project needs at least one VCS adaptor, with one module underneath. The settings for the Ant book are shown in figures 15.4 and 15.5. As well as declaring a repository, you also must define a module. This represents a subsection of the repository and may be a specific branch or label.
Figure 15.4. A Luntbuild project is bound to a source code repository and can have different builders to build parts of the project on defined schedules.

Figure 15.5. The VCS Adaptor to check out the project from SourceForge

Being able to mix branches and labels of different parts of the repository is an interesting feature. It may let a team build and test multiple branches of a project.
A single project can also have multiple SCM/VCS repositories. We haven’t tried that; instead, we just create different projects for each repository.
Creating a builder
The builder is where we have to set up Ant builds. The configuration to build the whole diary is shown in figure 15.6.
Figure 15.6. Luntbuild configuration of our builder. To create a new builder, click the “new document” icon on the top-right corner.
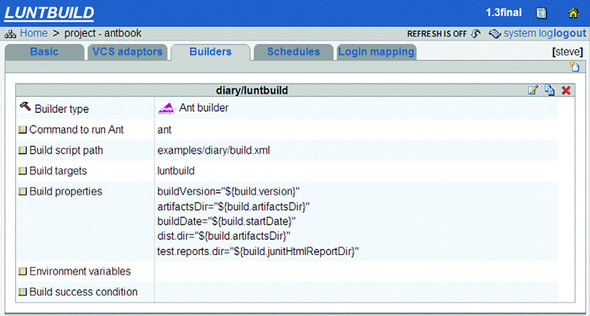
This is an important form, as it’s where the tool bridges to Ant. It has the fields shown in table 15.2.
Table 15.2. The options to configure an Ant builder
|
Option |
Meaning |
|---|---|
| Command to run Ant | The path to Ant; ant will suffice if it’s on the path. |
| Build script path | The path to the build file from the base of the repository. |
| Build targets | One or more space-separated targets to run. |
| Build properties | Properties to pass down to Ant. |
| Environment variables | Any environment variables to set before Ant runs. To set up Ant’s JVM, set up the ANT_OPTS variable here. |
| Build success condition | How to determine if a build was successful. |
The build properties field comes pre-populated with some Luntbuild options to be passed down to Ant, which we extended with three more:
dist.dir="${build.artifactsDir}"
test.reports.dir="${build.junitHtmlReportDir}"
no.sign.jar=true
These properties will place the distributable files in a place where Luntbuild users can browse and download them, with test reports available under the “reports” tab of the build results. The no.sign.jar property tells our build file to skip targets that prompt for the keystore password and to sign the JAR files.
The last field of the form is “Build success condition,” which, for an Ant build, defaults to result==0 and logContainsLine("BUILD SUCCESSFUL"), checking both the return code and the last line of output. Delete the contents of this condition to make it default to using the return code, if you ever plan on editing ANT_OPTS to select a different logger, such as Ant’s time-stamped logger. The moment your text output changes, the string comparison fails, and Luntbuild thinks the build was unsuccessful. This is why the build machine should be separate from any developer’s box. It’s too easy for developers to change their system in a way that breaks the scheduled builds; a tweak to ANT_OPTS is enough to confuse Luntbuild.
Creating a schedule
With the builder configured, Luntbuild knows how to build a project. But it doesn’t know when. For that we need a schedule, which is a set of rules about what triggers a build. A project may have different schedules, such as a clean nightly build and full test and a more frequent incremental build with partial testing. A schedule has a trigger, which can be manual, simple (every few minutes), or cron, which can be used to set an absolute date or time for a schedule to start. Figure 15.7 shows the schedule for the incremental build of this book’s examples. It runs every 17 minutes, and builds if anything in the repository has changed or something it depends upon has been successfully rebuilt.
Figure 15.7. The schedule contains the settings to run an incremental build of our project. It declares dependencies on other schedules, the builder to run, and the actions to take on success.

The schedule configuration is quite complex, especially once you turn to the dependency system. Any schedule can be marked as depending on any other schedule. The schedules can then be set to trigger builds of everything they depend on, or everything that depends on them. We haven’t found that feature to be too useful, because it ends up making builds slower and slower. If every component builds on its own schedule, that should be all you need. The exception is configuring one big “clean build of everything” target to run sporadically, such as every night.
Different schedules have notification policies. That’s good for builds triggered by check-ins just to notify the individual team members by email or IM, so they can fix the problem before anyone else is disturbed. Nightly builds can be set up to notify the team mailing list, so the problem becomes more obvious.
One useful feature of a schedule is a post-build strategy. This is a list of builders to invoke after a project builds. For example, a builder could be set up to deploy the application after a successful build or to create a distribution package. Luntbuild would run these dependent builds only if the main build succeeded. We could use this build to have a scaled-up set of tests, with the long-lived performance tests starting only if the functional tests of the system pass.
Login mappings
The final piece of project configuration is the mapping between user names in the SCM repository and Luntbuild users. This is so that Luntbuild knows who to blame when things break. Figure 15.8 shows our mapping.
Figure 15.8. Mappings from usernames in the repository to Luntbuild users
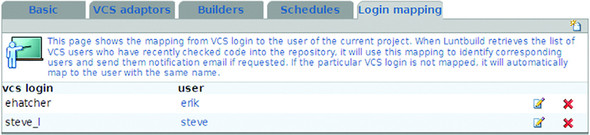
The default mapping uses the repository username as the email address of the recipient, and sends notification messages over email as the notification.
Triggering a build
Once a schedule has been defined, it can be run by pressing the green arrow icon on the schedule’s page or on the big list of all builds. Doing so will queue the build for execution. If the schedule requires predecessor builds to be built first, all the predecessors will be built. Similarly, if dependent schedules are triggered after a build, then they will be queued to run if the scheduled build completes successfully.
While getting Luntbuild to work, it’s handy to have a schedule you can run whenever you feel like it. To do so, set the trigger condition to always to ensure that it runs even if the repository files haven’t changed.
15.2.4. Luntbuild in action
With everything configured, Luntbuild should run continually, polling the SCM repositories for change and executing builders—which run the Ant builds and targets of the project—on the predefined schedules. Figure 15.9 shows our example server, which is running a set of schedules from three different projects.
Figure 15.9. The Luntbuild status page. The book is building; some of the other projects are failing. A clean build is under way.
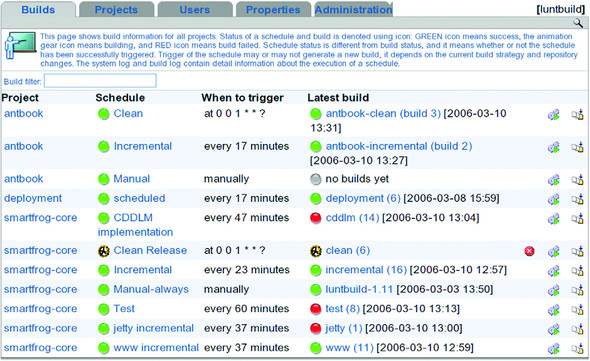
The builds have quite a complex interdependency. Every build publishes its artifacts to the local Ivy repository, to be picked up by dependent builds. The (currently failing) test run, Test, is decoupled from the run Incremental that builds the artifacts. This decoupling enables the builds of all the dependent projects to continue even if a test fails upstream. The failing test run will not be ignored, but fixing it is something that can be dealt with in a relaxed and methodical manner. The clean build of the Clean Release schedule of the smartfrog-core is active, so its status line is animated; a button lets a logged-on user halt this run.
Despite the high number of scheduled builds, the daytime load on this system is light. The tool may poll for changes quite frequently, but builds are triggered only when source or dependencies change.
This status page can act as an at-a-glance status page for a big project, showing which bits are working and which bits are not. To determine what’s working and what isn’t, you need to subdivide a project into modules that can be built and tested independently. It can take time to do so, but the benefit is that it’s immediately obvious which parts of a project have problems.
In use, the biggest problem we’ve found is that nothing kills builds that take too long. Luntbuild will happily let a test run all weekend. This may be what you want, but it if isn’t, then other builds get delayed while one build has hung. After we encountered this situation, we made sure that all our <junit> runs gained the attribute timeout="600000", to stop them from running after ten minutes.
We also found it a bit tricky to track down failures, especially when learning to use the tool. There’s a link in the top of the page to the “System Log,” which shows all the log output from the tool related to problems checking out files from the repository. If a schedule fails to run and there’s no build log, turn to the system log page to see what went wrong.
15.2.5. Review of Luntbuild
Luntbuild is an excellent example of a second-generation continuous-integration system. The tool authors have looked at the worst bit of CruiseControl—getting it to work—and addressed that problem through a web-based configuration mechanism.
Where they’ve really been innovative is when managing dependencies between projects, and when integrating scheduled builds with triggered releases. Scheduled builds let you run a big overnight “soak test” alongside commit-triggered builds, which can stop at the unit tests. The goal of the soak test is not to finish as quickly as possible, but to act much like a real application, even with realistic pauses if that’s how end users are expected to interact with the server. Such tests find problems with memory leakage, concurrency, state management, and other aspects of a system that a normal test suite can miss. By their very nature, they are slow, so you run them overnight. Luntbuild will let you do that.
Strengths
- There’s no need to edit configuration files.
- If you use MySQL as the repository, other programs can access the data.
- It’s got a good installer; the default options are the best way to get up and running.
- The dependency chain logic can demand-rebuild a project if something needs it.
- Displays the HTML-formatted output from <junit> test runs.
- It’s easy to add new projects.
- The post-build actions let you run deployment and redistribution build file targets, which can be triggered after the main build or test run completes.
- You can give multiple people the right to create new projects, which lets developers add new builds without unrestricted access to the host.
Limitations
- The more builds and schedules you add, the more the configuration GUI becomes a limit to scalability.
- It doesn’t automatically kill builds that run for a long time.
- It takes time to learn your way around.
- We wouldn’t trust the user accounts system to keep the build status private.
It’s easy to install, so it’s worthwhile investing an hour or two in getting it running. If it isn’t suitable, there are the many alternatives listed in table 15.1, on page 390, to try out.
Alongside the technical problem of bringing up a continuous-integration server is the social one: having the team adapt to a world in which errors get caught in minutes. That’s the final challenge of continuous integration.
15.3. Moving to continuous integration
The hardest part of getting a continuous-integration system up and running is not the software; it’s changing how developers work.
With a continuous-integration server, you know within minutes if the program has stopped compiling. Perhaps a newly created file was omitted, or perhaps there was an error in the source. Compilation failures will be caught before the developer has finished the next cup of coffee. Indeed, if the server can page their phone, they get summoned back to their keyboard before the coffee has cooled enough to drink. Test failures can take longer to show up if a project has a thorough enough test suite. Even so, you should expect to see errors from the unit and functional tests within half an hour of a defect being checked in. If nothing went wrong: silence.
If the team cares about the error messages, then the problem gets fixed. The idea is that the best time to fix a problem is immediately after adding the problematic code. If the fix takes, then the application is working again. The result is that a program is rarely broken. It may not be complete, but the source will always compile, the build files will always work, and the tests that the server is set to run will pass.
That’s a profound change. There’s no more uncertainty about the state of the program: anyone can look at the server status page and check that all is well, reviewing the tests to see what the build tests. Furthermore, the entire history of builds can be preserved, so anyone can go back and look at what changed. This capability helps with blame assignment—finding out who or what broke the system. It’s also a good way of keeping management happy without them bothering you for status reports: the server lets everyone know what’s going on.
For this reason, continuous integration is more than just setting up a server somewhere to run builds; it’s changing how you write code. Is it worth it? Very much so. One of our projects has two servers running constant builds, one on Linux/Java1.5 and the other on Windows Server 2003/Java1.4. The Java 1.4 build acts as a check that everything can still build on that version of Java. The different operating systems verify that the application is portable. They also deploy the system and run all the single-host functional tests, which take about 30 minutes to complete. If the servers are happy, the program is probably in a shippable condition. Sometimes the test fails, with problems that can take some days to fix—particularly if the problem is fundamental, or a new test is added that shows a new fault in the system. In that situation, someone has to sit down and fix the problem; it’s a team problem, not that of any particular individual. Everyone has the right to fix any part of the program in order to get the build passing again.
It isn’t easy adopting such a process, particularly if the cause is not “your part of the program.” However, it’s critical for everyone to care about the overall status of the build and for management to care enough about it to let developers spend time fixing the build, as opposed to adding new features.
In the project mentioned previously, the team has debated setting up a separate continuous-integration server for every branch, and having developers work on short-lived branches of only a few days, rather than share the main SVN branch. This setup would give every developer a private continuous-integration build, with the main branch hosting working code that has passed all the tests. With Xen/VMWare-hosted servers, having one background build per developer is possible.
Developers
If warning emails from the server are ignored, there’s no point in having an automated build service.
A common reason for ignoring a message is the belief that someone else will fix the problem, because it’s in their part of the project or because they broke the build. This is a mistake. As more changes are added, soon the build will be broken in many places, making the effort to fix the build that much harder. Sometimes tests fail for no apparent reason: if everyone assumes it’s some else’s problem, the build may not get fixed for a very long time.
At the very least, the initial failure report should trigger some discussion about what broke and why. Any developer should be able to get their hands dirty and fix the build. If it’s in some part of the project that they don’t understand yet, a broken test is an ideal excuse to learn their way around that bit of the system.
Management
Developers will fix a broken build only if they care about it. This should happen once they have adopted the process and recognize the benefits. But how do you convince developers that time spent fixing the build is more important than other things? That’s where management has to help. Whoever is in charge of a project needs to encourage the developers to care about the notification emails and the build’s status.
In an open source project, the team leaders need to set an example by caring about the build status. When failure notifications come in to the mailing list, team leaders could start discussions about the problem, fix it wherever they can, or ask others to fix it. The leaders also can credit people who put in the effort to fix the build.
Private projects have a management chain that the developers have to listen to, so if the managers say, “the continuous-integration build must work,” then developers will keep it working. That is, “I spent yesterday fixing the build” has to be accepted as a legitimate reason for a feature being delayed. If managers think that testing matters, they have to support anyone who gets a broken build working again.
One subtle way of getting management support is to use the status page as a way of tracking changes and watching the status of the project. If the developers know that their manager uses the status page as a way of measuring a project’s health, then they’ll try to keep that page “green.”
The less-subtle way to do this is to force a halt to all other work until the build is fixed. It certainly makes priorities clear, but it’s an option that should come out only in emergencies, at least after the first couple of times. Developers themselves need to care about the build; the problem for management is working out how to make developers care.
Despite all of these warnings, a team can adopt a continuous-integration tool and build a development process around it. Even developers who are too lazy to run the tests can start to rely on the server to test for them. It takes time, and the gradual addition of more and more work to the background builds. The key to success is support from the team leads—management, key developers, and architects. If the senior members of a project embrace continuous integration and change how they work, the rest of the team will follow.
15.4. Summary
Continuous integration is the concept of having a dedicated program that continually builds and tests an application. The continuous-integration server polls the source code repository on a regular basis, and, whenever it has changed, triggers a rebuild. If the build fails, the developers get email. If everything works: silence.
Luntbuild is one of the many continuous-integration applications you can install; it’s one of the easiest applications to get up and running, yet it has support for complex inter-project dependencies. This lets you build up a background build process, with clean nightly builds and incremental ones running throughout the day.
Continuous integration transforms how projects are developed. It hands off the repetitive work of building and testing to machines that are happy to do it all day long, leaving developers to write the code and the tests. More subtly, by integrating everything all the time, different parts of a big system are able to work together.
Looking back at past projects, the biggest mistakes we’ve done with continuous integration are
- Not starting off with it at the beginning of the project
- Not paying enough attention to failures
We used to delay using it, primarily because CruiseControl was so painful to set up. Tools like Luntbuild make it so easy to get up and running that there’s no such excuse anymore. A single server can build many projects, whether they depend on each other or not. Every project should adopt continuous integration, ideally as soon as the project is started.