
2
Statements and Syntax
Python syntax is designed to be simple. There are a few rules; we'll look at some of the interesting statements in the language as a way to understand those rules. Concrete examples can help clarify the language's syntax.
We'll cover some basics of creating script files first. Then we'll move on to looking at some of the more commonly-used statements. Python only has about 20 or so different kinds of imperative statements in the language. We've already looked at two kinds of statements in Chapter 1, Numbers, Strings, and Tuples, the assignment statement and the expression statement.
When we write something like this:
>>> print("hello world")
hello world
We're actually executing a statement that contains only the evaluation of a function, print(). This kind of statement—where we evaluate a function or a method of an object—is common.
The other kind of statement we've already seen is the assignment statement. Python has many variations on this theme. Most of the time, we're assigning a single value to a single variable. Sometimes, however, we might be assigning two variables at the same time, like this:
quotient, remainder = divmod(355, 113)
These recipes will look at some of the more common of the complex statements, including if, while, for, try, and with. We'll touch on a few of the simpler statements as we go, like break and raise.
In this chapter, we'll look at the following recipes:
- Writing Python script and module files - syntax basics
- Writing long lines of code
- Including descriptions and documentation
- Better RST markup in
docstrings - Designing complex
if...elifchains - Saving intermediate results with the
:="walrus" - Avoiding a potential problem with
breakstatements - Leveraging exception matching rules
- Avoiding a potential problem with an
except:clause - Concealing an exception root cause
- Managing a context using the
withstatement
We'll start by looking at the big picture – scripts and modules – and then we'll move down into details of individual statements. New with Python 3.8 is the assignment operator, sometimes called the "walrus" operator. We'll move into exception handling and context management as more advanced recipes in this section.
Writing Python script and module files – syntax basics
We'll need to write Python script files in order to do anything that's fully automated. We can experiment with the language at the interactive >>> prompt. We can also use JupyterLab interactively. For automated work, however, we'll need to create and run script files.
How can we make sure our code matches what's in common use? We need to look at some common aspects of style: how we organize our programming to make it readable.
We'll also look at a number of more technical considerations. For example, we need to be sure to save our files in UTF-8 encoding. While ASCII encoding is still supported by Python, it's a poor choice for modern programming. We'll also need to be sure to use spaces instead of tabs. If we use Unix newlines as much as possible, we'll also find it slightly simpler to create software that runs on a variety of operating systems.
Most text editing tools will work properly with Unix (newline) line endings as well as Windows or DOS (return-newline) line endings. Any tool that can't work with both kinds of line endings should be avoided.
Getting ready
To edit Python scripts, we'll need a good programming text editor. Python comes with a handy editor, IDLE. It works well for simple projects. It lets us jump back and forth between a file and an interactive >>> prompt, but it's not a good programming editor for larger projects.
There are dozens of programming editors. It's nearly impossible to suggest just one. So we'll suggest a few.
The JetBrains PyCharm editor has numerous features. The community edition version is free. See https://www.jetbrains.com/pycharm/download/.
ActiveState has Komodo IDE, which is also very sophisticated. The Komodo Edit version is free and does some of the same things as the full Komodo IDE. See http://komodoide.com/komodo-edit/.
Notepad++ is good for Windows developers. See https://notepad-plus-plus.org.
BBEdit is very nice for macOS X developers. See http://www.barebones.com/products/bbedit/.
For Linux developers, there are several built-in editors, including VIM, gedit, and Kate. These are all good. Since Linux tends to be biased toward developers, the editors available are all suitable for writing Python.
What's important is that we'll often have two windows open while we're working:
- The script or file that we're working on in our editor of choice.
- Python's
>>>prompt (perhaps from a shell or perhaps from IDLE) where we can try things out to see what works and what doesn't. We may be creating our script in Notepad++ but using IDLE to experiment with data structures and algorithms.
We actually have two recipes here. First, we need to set some defaults for our editor. Then, once the editor is set up properly, we can create a generic template for our script files.
How to do it...
First, we'll look at the general setup that we need to do in our editor of choice. We'll use Komodo examples, but the basic principles apply to all editors. Once we've set the edit preferences, we can create our script files:
- Open your editor of choice. Look at the preferences page for the editor.
- Find the settings for preferred file encoding. With Komodo Edit Preferences, it's on the Internationalization tab. Set this to UTF-8.
- Find the settings for indentation. If there's a way to use spaces instead of tabs, check this option. With Komodo Edit, we actually do this backward—we uncheck "prefer spaces over tabs." Also, set the spaces per indent to four. That's typical for Python code. It allows us to have several levels of indentation and still keep the code fairly narrow.
The rule is this: we want spaces; we do not want tabs.
Once we're sure that our files will be saved in UTF-8 encoding, and we're also sure we're using spaces instead of tabs, we can create an example script file:
- The first line of most Python script files should look like this:
#!/usr/bin/env python3This sets an association between the file you're writing and Python.
For Windows, the filename-to-program association is done through a setting in one of the Windows control panels. Within the Default Programs control panel, there's a panel to Set Associations. This control panel shows that
.pyfiles are bound to the Python program. This is normally set by the installer, and we rarely need to change it or set it manually.Windows developers can include the preamble line anyway. It will make macOS X and Linux folks happy when they download the project from GitHub.
- After the preamble, there should be a triple-quoted block of text. This is the documentation string (called a docstring) for the file we're going to create. It's not technically mandatory, but it's essential for explaining what a file contains:
""" A summary of this script. """Because Python triple-quoted strings can be indefinitely long, feel free to write as much as necessary. This should be the primary vehicle for describing the script or library module. This can even include examples of how it works.
- Now comes the interesting part of the script: the part that really does something. We can write all the statements we need to get the job done. For now, we'll use this as a placeholder:
print('hello world')This isn't much, but at least the script does something. In other recipes, we'll look at more complex processing. It's common to create function and class definitions, as well as to write statements to use the functions and classes to do things.
For our first, simple script, all of the statements must begin at the left margin and must be complete on a single line. There are many Python statements that have blocks of statements nested inside them. These internal blocks of statements must be indented to clarify their scope. Generally—because we set indentation to four spaces—we can hit the Tab key to indent.
Our file should look like this:
#!/usr/bin/env python3
"""
My First Script: Calculate an important value.
"""
print(355/113)
How it works...
Unlike other languages, there's very little boilerplate in Python. There's only one line of overhead and even the #!/usr/bin/env python3 line is generally optional.
Why do we set the encoding to UTF-8? While the entire language is designed to work using just the original 128 ASCII characters, we often find that ASCII is limiting. It's easier to set our editor to use UTF-8 encoding. With this setting, we can simply use any character that makes sense. We can use characters like ![]() as Python variables if we save our programs in UTF-8 encoding.
as Python variables if we save our programs in UTF-8 encoding.
This is legal Python if we save our file in UTF-8:
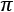 = 355/113
print(
= 355/113
print( )
)
It's important to be consistent when choosing between spaces and tabs in Python. They are both more or less invisible, and mixing them can easily lead to confusion. Spaces are suggested.
When we set up our editor to use a four-space indent, we can then use the button labeled Tab on our keyboard to insert four spaces. Our code will align properly, and the indentation will show how our statements nest inside each other.
The initial #! line is a comment. Because the two characters are sometimes called sharp and bang, the combination is called "shebang." Everything between a # and the end of the line is ignored. The Linux loader (a program named execve) looks at the first few bytes of a file to see what the file contains. The first few bytes are sometimes called magic because the loader's behavior seems magical. When present, this two-character sequence of #! is followed by the path to the program responsible for processing the rest of the data in the file. We prefer to use /usr/bin/env to start the Python program for us. We can leverage this to make Python-specific environment settings via the env program.
There's more...
The Python Standard Library documents are derived, in part, from the documentation strings present in the module files. It's common practice to write sophisticated docstrings in modules. There are tools like pydoc and Sphinx that can reformat the module docstrings into elegant documentation. We'll look at this in other recipes.
Additionally, unit test cases can be included in the docstrings. Tools like doctest can extract examples from the document string and execute the code to see if the answers in the documentation match the answers found by running the code. Most of this book is validated with doctest.
Triple-quoted documentation strings are preferred over # comments. While all text between # and the end of the line is ignored, this is limited to a single line, and it is used sparingly. A docstring can be of indefinite size; they are used widely.
Prior to Python 3.6, we might sometimes see this kind of thing in a script file:
color = 355/113 # type: float
The # type: float comment can be used by a type inferencing system to establish that the various data types can occur when the program is actually executed. For more information on this, see Python Enhancement Proposal (PEP) 484: https://www.python.org/dev/peps/pep-0484/.
The preferred style is this:
color: float = 355/113
The type hint is provided immediately after the variable name. This is based on PEP 526, https://www.python.org/dev/peps/pep-0526. In this case, the type hint is obvious and possibly redundant. The result of exact integer division is a floating-point value, and type inferencing tools like mypy are capable of figuring out the specific type for obvious cases like this.
There's another bit of overhead that's sometimes included in a file. The VIM and gedit editors let us keep edit preferences in the file. This is called a modeline. We may see these; they can be ignored. Here's a typical modeline that's useful for Python:
# vim: tabstop=8 expandtab shiftwidth=4 softtabstop=4
This sets the Unicode u+0009 TAB characters to be transformed to eight spaces; when we hit the Tab key, we'll shift four spaces. This setting is carried in the file; we don't have to do any VIM setup to apply these settings to our Python script files.
See also
- We'll look at how to write useful document strings in the Including descriptions and documentation and Writing better RST markup in docstrings recipes.
- For more information on suggested style, see https://www.python.org/dev/peps/pep-0008/
Writing long lines of code
There are many times when we need to write lines of code that are so long that they're very hard to read. Many people like to limit the length of a line of code to 80 characters or fewer. It's a well-known principle of graphic design that a narrower line is easier to read. See http://webtypography.net/2.1.2 for a deeper discussion of line width and readability.
While shorter lines are easier on the eyes, our code can refuse to cooperate with this principle. Long statements are a common problem. How can we break long Python statements into more manageable pieces?
Getting ready
Often, we'll have a statement that's awkwardly long and hard to work with. Let's say we've got something like this:
>>> import math
>>> example_value = (63/25) * (17+15*math.sqrt(5)) / (7+15*math.sqrt(5))
>>> mantissa_fraction, exponent = math.frexp(example_value)
>>> mantissa_whole = int(mantissa_fraction*2**53)
>>> message_text = f'the internal representation is {mantissa_whole:d}/2**53*2**{exponent:d}'
>>> print(message_text)
the internal representation is 7074237752514592/2**53*2**2
This code includes a long formula, and a long format string into which we're injecting values. This looks bad when typeset in a book; the f-string line may be broken incorrectly. It looks bad on our screen when trying to edit this script.
We can't haphazardly break Python statements into chunks. The syntax rules are clear that a statement must be complete on a single logical line.
The term "logical line" provides a hint as to how we can proceed. Python makes a distinction between logical lines and physical lines; we'll leverage these syntax rules to break up long statements.
How to do it...
Python gives us several ways to wrap long statements so they're more readable:
- We can use
at the end of a line to continue onto the next line. - We can leverage Python's rule that a statement can span multiple logical lines because the
(),[], and{}characters must balance. In addition to using()or, we can also exploit the way Python automatically concatenates adjacent string literals to make a single, longer literal;("a" "b")is the same as"ab". - In some cases, we can decompose a statement by assigning intermediate results to separate variables.
We'll look at each one of these in separate parts of this recipe.
Using a backslash to break a long statement into logical lines
Here's the context for this technique:
>>> import math
>>> example_value = (63/25) * (17+15*math.sqrt(5)) / (7+15*math.sqrt(5))
>>> mantissa_fraction, exponent = math.frexp(example_value)
>>> mantissa_whole = int(mantissa_fraction*2**53)
Python allows us to use to break the logical line into two physical lines:
- Write the whole statement on one long line, even if it's confusing:
>>> message_text = f'the internal representation is {mantissa_whole:d}/2**53*2**{exponent:d}' - If there's a meaningful break, insert the
to separate the statement:>>> message_text = f'the internal representation is ... {mantissa_whole:d}/2**53*2**{exponent:d}'
For this to work, the must be the last character on the line. We can't even have a single space after the . An extra space is fairly hard to see; for this reason, we don't encourage using back-slash continuation like this. PEP 8 provides guidelines on formatting and discourages this.
In spite of this being a little hard to see, the can always be used. Think of it as the last resort in making a line of code more readable.
Using the () characters to break a long statement into sensible pieces
- Write the whole statement on one line, even if it's confusing:
>>> import math >>> example_value1 = (63/25) * (17+15*math.sqrt(5)) / (7+15*math.sqrt(5)) - Add the extra
()characters, which don't change the value, but allow breaking the expression into multiple lines:>>> example_value2 = (63/25) * ( (17+15*math.sqrt(5)) / (7+15*math.sqrt(5)) ) >>> example_value2 == example_value1 True - Break the line inside the
()characters:>>> example_value3 = (63/25) * ( ... (17+15*math.sqrt(5)) ... / (7+15*math.sqrt(5)) ... ) >>> example_value3 == example_value1 True
The matching () character's technique is quite powerful and will work in a wide variety of cases. This is widely used and highly recommended.
We can almost always find a way to add extra () characters to a statement. In rare cases when we can't add () characters, or adding () characters doesn't improve readability, we can fall back on using to break the statement into sections.
Using string literal concatenation
We can combine the () characters with another rule that joins adjacent string literals. This is particularly effective for long, complex format strings:
- Wrap a long string value in the
()characters. - Break the string into substrings:
>>> message_text = ( ... f'the internal representation ' ... f'is {mantissa_whole:d}/2**53*2**{exponent:d}' ... ) >>> message_text 'the internal representation is 7074237752514592/2**53*2**2'
We can always break a long string into adjacent pieces. Generally, this is most effective when the pieces are surrounded by () characters. We can then use as many physical line breaks as we need. This is limited to those situations where we have particularly long string literals.
Assigning intermediate results to separate variables
Here's the context for this technique:
>>> import math
>>> example_value = (63/25) * (17+15*math.sqrt(5)) / (7+15*math.sqrt(5))
We can break this into three intermediate values:
- Identify sub-expressions in the overall expression. Assign these to variables:
>>> a = (63/25) >>> b = (17+15*math.sqrt(5)) >>> c = (7+15*math.sqrt(5))This is generally quite simple. It may require a little care to do the algebra to locate sensible sub-expressions.
- Replace the sub-expressions with the variables that were created:
>>> example_value = a * b / c
We can always take a sub-expression and assign it to a variable, and use the variable everywhere the sub-expression was used. The 15*sqrt(5) product is repeated; this, too, is a good candidate for refactoring the expression.
We didn't give these variables descriptive names. In some cases, the sub-expressions have some semantics that we can capture with meaningful names. In this case, however, we chose short, arbitrary identifiers instead.
How it works...
The Python Language Manual makes a distinction between logical lines and physical lines. A logical line contains a complete statement. It can span multiple physical lines through techniques called line joining. The manual calls the techniques explicit line joining and implicit line joining.
The use of for explicit line joining is sometimes helpful. Because it's easy to overlook, it's not generally encouraged. PEP 8 suggests this should be the method of last resort.
The use of () for implicit line joining can be used in many cases. It often fits semantically with the structure of the expressions, so it is encouraged. We may have the () characters as a required syntax. For example, we already have () characters as part of the syntax for the print() function. We might do this to break up a long statement:
>>> print(
... 'several values including',
... 'mantissa =', mantissa,
... 'exponent =', exponent
... )
There's more...
Expressions are used widely in a number of Python statements. Any expression can have () characters added. This gives us a lot of flexibility.
There are, however, a few places where we may have a long statement that does not specifically involve an expression. The most notable example of this is the import statement—it can become long, but doesn't use any expressions that can be parenthesized. In spite of not having a proper expression, it does, however, still permit the use of (). The following example shows we can surround a very long list of imported names:
>>> from math import (
... sin, cos, tan,
... sqrt, log, frexp)
In this case, the () characters are emphatically not part of an expression. The () characters are available syntax, included to make the statement consistent with other statements.
See also
- Implicit line joining also applies to the matching
[]and{}characters. These apply to collection data structures that we'll look at in Chapter 4, Built-In Data Structures Part 1: Lists and Sets.
Including descriptions and documentation
When we have a useful script, we often need to leave notes for ourselves—and others—on what it does, how it solves some particular problem, and when it should be used.
Because clarity is important, there are some formatting recipes that can help make the documentation very clear. This recipe also contains a suggested outline so that the documentation will be reasonably complete.
Getting ready
If we've used the Writing Python script and module files – syntax basics recipe to build a script file, we'll have to put a small documentation string in our script file. We'll expand on this documentation string in this recipe.
There are other places where documentation strings should be used. We'll look at these additional locations in Chapter 3, Function Definitions, and Chapter 7, Basics of Classes and Objects.
We have two general kinds of modules for which we'll be writing summary docstrings:
- Library modules: These files will contain mostly function definitions as well as class definitions. In this case, the docstring summary can focus on what the module is more than what it does. The docstring can provide examples of using the functions and classes that are defined in the module. In Chapter 3, Function Definitions, and Chapter 7, Basics of Classes and Objects, we'll look more closely at this idea of a package of functions or classes.
- Scripts: These are files that we generally expect will do some real work. In this case, we want to focus on doing rather than being. The docstring should describe what it does and how to use it. The options, environment variables, and configuration files are important parts of this docstring.
We will sometimes create files that contain a little of both. This requires some careful editing to strike a proper balance between doing and being. In most cases, we'll provide both kinds of documentation.
How to do it...
The first step in writing documentation is the same for both library modules and scripts:
- Write a brief summary of what the script or module is or does. The summary doesn't dig too deeply into how it works. Like a lede in a newspaper article, it introduces the who, what, when, where, how, and why of the module. Details will follow in the body of the docstring.
The way the information is displayed by tools like Sphinx and pydoc suggests a specific style for the summaries we write. In the output from these tools, the context is pretty clear, therefore it's common to omit a subject in the summary sentence. The sentence often begins with the verb.
For example, a summary like this: This script downloads and decodes the current Special Marine Warning (SMW) for the area AKQ has a needless This script. We can drop that and begin with the verb phrase Downloads and decodes....
We might start our module docstring like this:
"""
Downloads and decodes the current Special Marine Warning (SMW)
for the area 'AKQ'.
"""
We'll separate the other steps based on the general focus of the module.
Writing docstrings for scripts
When we document a script, we need to focus on the needs of a person who will use the script.
- Start as shown earlier, creating a summary sentence.
- Sketch an outline for the rest of the docstring. We'll be using ReStructuredText (RST) markup. Write the topic on one line, then put a line of
=under the topic to make it a proper section title. Remember to leave a blank line between each topic.Topics may include:
- SYNOPSIS: A summary of how to run this script. If the script uses the
argparsemodule to process command-line arguments, the help text produced byargparseis the ideal summary text. - DESCRIPTION: A more complete explanation of what this script does.
- OPTIONS: If
argparseis used, this is a place to put the details of each argument. Often, we'll repeat theargparsehelp parameter. - ENVIRONMENT: If
os.environis used, this is the place to describe the environment variables and what they mean. - FILES: Names of files that are created or read by a script are very important pieces of information.
- EXAMPLES: Some examples of using the script are always helpful.
- SEE ALSO: Any related scripts or background information.
Other topics that might be interesting include EXIT STATUS, AUTHOR, BUGS, REPORTING BUGS, HISTORY, or COPYRIGHT. In some cases, advice on reporting bugs, for instance, doesn't really belong in a module's docstring, but belongs elsewhere in the project's GitHub or SourceForge pages.
- SYNOPSIS: A summary of how to run this script. If the script uses the
- Fill in the details under each topic. It's important to be accurate. Since we're embedding this documentation within the same file as the code, it needs to be correct, complete, and consistent.
- For code samples, there's a cool bit of RST markup we can use. Recall that all elements are separated by blank lines. In one paragraph, use
::by itself. In the next paragraph, provide the code example indented by four spaces.
Here's an example of a docstring for a script:
"""
Downloads and decodes the current Special Marine Warning (SMW)
for the area 'AKQ'
SYNOPSIS
========
::
python3 akq_weather.py
DESCRIPTION
===========
Downloads the Special Marine Warnings
Files
=====
Writes a file, ''AKW.html''.
EXAMPLES
========
Here's an example::
slott$ python3 akq_weather.py
<h3>There are no products active at this time.</h3>
"""
In the Synopsis section, we used :: as a separate paragraph. In the Examples section, we used :: at the end of a paragraph. Both versions are hints to the RST processing tools that the indented section that follows should be typeset as code.
Writing docstrings for library modules
When we document a library module, we need to focus on the needs of a programmer who will import the module to use it in their code:
- Sketch an outline for the rest of the docstring. We'll be using RST markup. Write the topic on one line. Include a line of = under each topic to make the topic into a proper heading. Remember to leave a blank line between each paragraph.
- Start as shown previously, creating a summary sentence:
- DESCRIPTION: A summary of what the module contains and why the module is useful
- MODULE CONTENTS: The classes and functions defined in this module
- EXAMPLES: Examples of using the module
- Fill in the details for each topic. The module contents may be a long list of class or function definitions. This should be a summary. Within each class or function, we'll have a separate docstring with the details for that item.
- For code examples, see the previous examples. Use
::as a paragraph or the ending of a paragraph. Indent the code example by four spaces.
How it works...
Over the decades, the man page outline has evolved to contain a complete description of Linux commands. This general approach to writing documentation has proven useful and resilient. We can capitalize on this large body of experience, and structure our documentation to follow the man page model.
These two recipes for describing software are based on summaries of many individual pages of documentation. The goal is to leverage the well-known set of topics. This makes our module documentation mirror the common practice.
We want to prepare module docstrings that can be used by the Sphinx Python Documentation Generator (see http://www.sphinx-doc.org/en/stable/). This is the tool used to produce Python's documentation files. The autodoc extension in Sphinx will read the docstring headers on our modules, classes, and functions to produce the final documentation that looks like other modules in the Python ecosystem.
There's more...
RST markup has a simple, central syntax rule: paragraphs are separated by blank lines.
This rule makes it easy to write documents that can be examined by the various RST processing tools and reformatted to look extremely nice.
When we want to include a block of code, we'll have some special paragraphs:
- Separate the code from the text with blank lines.
- Indent the code by four spaces.
- Provide a prefix of
::. We can either do this as its own separate paragraph or as a special double-colon at the end of the lead-in paragraph:Here's an example:: more_code() - The
::is used in the lead-in paragraph.
There are places for novelty and art in software development. Documentation is not really the place to push the envelope.
A unique voice or quirky presentation isn't fun for users who simply want to use the software. An amusing style isn't helpful when debugging. Documentation should be commonplace and conventional.
It can be challenging to write good software documentation. There's a broad chasm between too little information and documentation that simply recapitulates the code. Somewhere, there's a good balance. What's important is to focus on the needs of a person who doesn't know too much about the software or how it works. Provide this semi-knowledgeable user with the information they need to describe what the software does and how to use it.
In many cases, we need to separate two parts of the use cases:
- The intended use of the software
- How to customize or extend the software
These may be two distinct audiences. There may be users who are distinct from developers. Each has a unique perspective, and different parts of the documentation need to respect these two perspectives.
See also
- We look at additional techniques in Writing better RST markup in docstrings.
- If we've used the Writing Python script and module files – syntax basics recipe, we'll have put a documentation string in our script file. When we build functions in Chapter 3, Function Definitions, and classes in Chapter 7, Basics of Classes and Objects, we'll look at other places where documentation strings can be placed.
- See http://www.sphinx-doc.org/en/stable/ for more information on Sphinx.
- For more background on the man page outline, see https://en.wikipedia.org/wiki/Man_page
Writing better RST markup in docstrings
When we have a useful script, we often need to leave notes on what it does, how it works, and when it should be used. Many tools for producing documentation, including docutils, work with RST markup. What RST features can we use to make documentation more readable?
Getting ready
In the Including descriptions and documentation recipe, we looked at putting a basic set of documentation into a module. This is the starting point for writing our documentation. There are a large number of RST formatting rules. We'll look at a few that are important for creating readable documentation.
How to do it...
- Be sure to write an outline of the key points. This may lead to creating RST section titles to organize the material. A section title is a two-line paragraph with the title followed by an underline using
=,-,^,~, or one of the other docutils characters for underlining.A heading will look like this:
Topic =====The heading text is on one line and the underlining characters are on the next line. This must be surrounded by blank lines. There can be more underline characters than title characters, but not fewer.
The RST tools will infer our pattern of using underlining characters. As long as the underline characters are used consistently, the algorithm for matching underline characters to the desired heading will detect the pattern. The keys to this are consistency and a clear understanding of sections and subsections.
When starting out, it can help to make an explicit reminder sticky note like this:
Character
Level
=1
-2
^3
~4
Example of heading characters
- Fill in the various paragraphs. Separate paragraphs (including the section titles) with blank lines. Extra blank lines don't hurt. Omitting blank lines will lead the RST parsers to see a single, long paragraph, which may not be what we intended.
We can use inline markup for emphasis, strong emphasis, code, hyperlinks, and inline math, among other things. If we're planning on using Sphinx, then we have an even larger collection of text roles that we can use. We'll look at these techniques soon.
- If the programming editor has a spell checker, use that. This can be frustrating because we'll often have code samples that may include abbreviations that fail spell checking.
How it works...
The docutils conversion programs will examine the document, looking for sections and body elements. A section is identified by a title. The underlines are used to organize the sections into a properly nested hierarchy. The algorithm for deducing this is relatively simple and has these rules:
- If the underline character has been seen before, the level is known
- If the underline character has not been seen before, then it must be indented one level below the previous outline level
- If there is no previous level, this is level one
A properly nested document might have the following sequence of underline characters:
TITLE
=====
SOMETHING
---------
MORE
^^^^
EXTRA
^^^^^
LEVEL 2
-------
LEVEL 3
^^^^^^^
We can see that the first title underline character, =, will be level one. The next, -, is unknown but appears after a level one, so it must be level two. The third headline has ^, which is previously unknown, is inside level two, and therefore must be level three. The next ^ is still level three. The next two, - and ^, are known to be level two and three respectively.
From this overview, we can see that inconsistency will lead to confusion.
If we change our mind partway through a document, this algorithm can't detect that. If—for inexplicable reasons—we decide to skip over a level and try to have a level four heading inside a level two section, that simply can't be done.
There are several different kinds of body elements that the RST parser can recognize. We've shown a few. The more complete list includes:
- Paragraphs of text: These might use inline markup for different kinds of emphasis or highlighting.
- Literal blocks: These are introduced with
::and indented four spaces. They may also be introduced with the.. parsed-literal::directive. A doctest block is indented four spaces and includes the Python>>>prompt. - Lists, tables, and block quotes: We'll look at these later. These can contain other body elements.
- Footnotes: These are special paragraphs. When rendered, they may be put on the bottom of a page or at the end of a section. These can also contain other body elements.
- Hyperlink targets, substitution definitions, and RST comments: These are specialized text items.
There's more...
For completeness, we'll note here that RST paragraphs are separated by blank lines. There's quite a bit more to RST than this core rule.
In the Including descriptions and documentation recipe, we looked at several different kinds of body elements we might use:
- Paragraphs of Text: This is a block of text surrounded by blank lines. Within these, we can make use of inline markup to emphasize words, or to use a font to show that we're referring to elements of our code. We'll look at inline markup in the Using inline markup recipe.
- Lists: These are paragraphs that begin with something that looks like a number or a bullet. For bullets, use a simple
–or*. Other characters can be used, but these are common. We might have paragraphs like this.It helps to have bullets because:
- They can help clarify
- They can help organize
- Numbered Lists: There are a variety of patterns that are recognized. We might use a pattern like one of the four most common kinds of numbered paragraphs:
- Numbers followed by punctuation like
.or). - A letter followed by punctuation like
.or). - A Roman numeral followed by punctuation.
- A special case of
#with the same punctuation used on the previous items. This continues the numbering from the previous paragraphs.
- Numbers followed by punctuation like
- Literal Blocks: A code sample must be presented literally. The text for this must be indented. We also need to prefix the code with
::. The::character must either be a separate paragraph or the end of a lead-in to the code example. - Directives: A directive is a paragraph that generally looks like
.. directive::. It may have some content that's indented so that it's contained within the directive. It might look like this:
.. important::
Do not flip the bozo bit.
The .. important:: paragraph is the directive. This is followed by a short paragraph of text indented within the directive. In this case, it creates a separate paragraph that includes the admonition of important.
Using directives
Docutils has many built-in directives. Sphinx adds a large number of directives with a variety of features.
Some of the most commonly used directives are the admonition directives: attention, caution, danger, error, hint, important, note, tip, warning, and the generic admonition. These are compound body elements because they can have multiple paragraphs and nested directives within them.
We might have things like this to provide appropriate emphasis:
.. note:: Note Title
We need to indent the content of an admonition.
This will set the text off from other material.
One of the other common directives is the parsed-literal directive:
.. parsed-literal::
any text
*almost* any format
the text is preserved
but **inline** markup can be used.
This can be handy for providing examples of code where some portion of the code is highlighted. A literal like this is a simple body element, which can only have text inside. It can't have lists or other nested structures.
Using inline markup
Within a paragraph, we have several inline markup techniques we can use:
- We can surround a word or phrase with
*for*emphasis*. This is commonly typeset as italic. - We can surround a word or phrase with
**for**strong**. This is commonly typeset as bold. - We surround references with single back-ticks (
`, it's on the same key as the~on most keyboards). Links are followed by an underscore,"_". We might use`section title`_to refer to a specific section within a document. We don't generally need to put anything around URLs. The docutils tools recognize these. Sometimes we want a word or phrase to be shown and the URL concealed. We can use this:`the Sphinx documentation <http://www.sphinx-doc.org/en/stable/>`_. - We can surround code-related words with a double back-tick (
``) to make them look like``code``.
There's also a more general technique called a text role. A role is a little more complex-looking than simply wrapping a word or phrase in * characters. We use :word: as the role name followed by the applicable word or phrase in single ` back-ticks. A text role looks like this :strong:`this`.
There are a number of standard role names, including :emphasis:, :literal:, :code:, :math:, :pep-reference:, :rfc-reference:, :strong:, :subscript:, :superscript:, and :title-reference:. Some of these are also available with simpler markup like *emphasis* or **strong**. The rest are only available as explicit roles.
Also, we can define new roles with a simple directive. If we want to do very sophisticated processing, we can provide docutils with class definitions for handling roles, allowing us to tweak the way our document is processed. Sphinx adds a large number of roles to support detailed cross-references among functions, methods, exceptions, classes, and modules.
See also
- For more information on RST syntax, see http://docutils.sourceforge.net. This includes a description of the docutils tools.
- For information on Sphinx Python Documentation Generator, see http://www.sphinx-doc.org/en/stable/
- The
Sphinxtool adds many additional directives and text roles to basic definitions.
Designing complex if...elif chains
In most cases, our scripts will involve a number of choices. Sometimes the choices are simple, and we can judge the quality of the design with a glance at the code. In other cases, the choices are more complex, and it's not easy to determine whether or not our if statements are designed properly to handle all of the conditions.
In the simplest case, we have one condition, C, and its inverse, ¬C` . These are the two conditions for an if...else statement. One condition, C, is stated in the if clause, the other condition, C's inverse, is implied in else.
This is the Law of the Excluded Middle: we're claiming there's no missing alternative between the two conditions, C and ¬C. For a complex condition, though, this isn't always true.
If we have something like:
if weather == RAIN and plan == GO_OUT:
bring("umbrella")
else:
bring("sunglasses")
It may not be immediately obvious, but we've omitted a number of possible alternatives. The weather and plan variables have four different combinations of values. One of the conditions is stated explicitly, the other three are assumed:
weather == RAINandplan == GO_OUT. Bringing an umbrella seems right.weather != RAINandplan == GO_OUT. Bringing sunglasses seems appropriate.weather == RAINandplan != GO_OUT. If we're staying in, then neither accessory seems right.weather != RAINandplan != GO_OUT. Again, the accessory question seems moot if we're not going out.
How can we be sure we haven't missed anything?
Getting ready
Let's look at a concrete example of an if...elif chain. In the casino game of Craps, there are a number of rules that apply to a roll of two dice. These rules apply on the first roll of the game, called the come-out roll:
- 2, 3, or 12 is Craps, which is a loss for all bets placed on the pass line
- 7 or 11 is a winner for all bets placed on the pass line
- The remaining numbers establish a point
Many players place their bets on the pass line. We'll use this set of three conditions as an example for looking at this recipe because it has a potentially vague clause in it.
How to do it...
When we write an if statement, even when it appears trivial, we need to be sure that all conditions are covered.
- Enumerate the conditions we know. In our example, we have three rules: (2, 3, 12), (7, 11), and a vague statement of "the remaining numbers." This forms a first draft of the
ifstatement. - Determine the universe of all possible alternatives. For this example, there are 11 alternative outcomes: the numbers from 2 to 12, inclusive.
- Compare the conditions, C, with the universe of alternatives, U. There are three possible outcomes of this comparison:
- More conditions than are possible in the universe of alternatives,
 . The most common cause is failing to completely enumerate all possible alternatives in the universe. We might, for example, have modeled dice using 0 to 5 instead of 1 to 6. The universe of alternatives appears to be the values from 0 to 10, yet there are conditions for 11 and 12.
. The most common cause is failing to completely enumerate all possible alternatives in the universe. We might, for example, have modeled dice using 0 to 5 instead of 1 to 6. The universe of alternatives appears to be the values from 0 to 10, yet there are conditions for 11 and 12. - Gaps in the conditions,
 . There are one or more alternatives without a condition. The most common cause is failing to fully understand the various conditions. We might, for example, have enumerated the vales as two tuples instead of sums. (1, 1), (1, 2), (2, 1), and (6, 6) have special rules. It's possible to miss a condition like this and have a condition untested by any clause of the
. There are one or more alternatives without a condition. The most common cause is failing to fully understand the various conditions. We might, for example, have enumerated the vales as two tuples instead of sums. (1, 1), (1, 2), (2, 1), and (6, 6) have special rules. It's possible to miss a condition like this and have a condition untested by any clause of the ifstatement. - Match between conditions and the universe of alternatives,
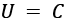 . This is ideal. The universe of all possible alternatives matches of all the conditions in the
. This is ideal. The universe of all possible alternatives matches of all the conditions in the ifstatement.
- More conditions than are possible in the universe of alternatives,
The first outcome is a rare problem where the conditions in our code seem to describe too many alternative outcomes. It helps to uncover these kinds of problems as early as possible to permit rethinking the design from the foundations. Often, this suggests the universe of alternatives is not fully understood; either we wrote too many conditions or failed to identify all the alternative outcomes.
A more common problem is to find a gap between the designed conditions in the draft if statement and the universe of possible alternatives. In this example, it's clear that we haven't covered all of the possible alternatives. In other cases, it takes some careful reasoning to understand the gap. Often, the outcome of our design effort is to replace any vague or poorly defined terms with something much more precise.
In this example, we have a vague term, which we can replace with something more specific. The term remaining numbers appears to be the list of values (4, 5, 6, 8, 9, 10). Supplying this list removes any possible gaps and doubts.
The goal is to have the universe of known alternatives match the collection of conditions in our if statement. When there are exactly two alternatives, we can write a condition expression for one of the alternatives. The other condition can be implied; a simple if and else will work.
When we have more than two alternatives, we'll have more than two conditions. We need to use this recipe to write a chain of if and elif statements, one statement per alternative:
- Write an
if...elif...elifchain that covers all of the known alternatives. For our example, it will look like this:dice = die_1 + die_2 if dice in (2, 3, 12): game.craps() elif dice in (7, 11): game.winner() elif dice in (4, 5, 6, 8, 9, 10): game.point(die) - Add an
elseclause that raises an exception, like this:else: raise Exception('Design Problem')
This extra else gives us a way to positively identify when a logic problem is found. We can be sure that any design error we made will lead to a conspicuous problem when the program runs. Ideally, we'll find any problems while we're unit testing.
In this case, it is clear that all 11 alternatives are covered by the if statement conditions. The extra else can't ever be used. Not all real-world problems have this kind of easy proof that all the alternatives are covered by conditions, and it can help to provide a noisy failure mode.
How it works...
Our goal is to be sure that our program always works. While testing helps, we can still have the same wrong assumptions when doing design and creating test cases.
While rigorous logic is essential, we can still make errors. Further, someone doing ordinary software maintenance might introduce an error. Adding a new feature to a complex if statement is a potential source of problems.
This else-raise design pattern forces us to be explicit for each and every condition. Nothing is assumed. As we noted previously, any error in our logic will be uncovered if the exception gets raised.
The else-raise design pattern doesn't have a significant performance impact. A simple else clause is slightly faster than an elif clause with a condition. However, if we think that our application performance depends in any way on the cost of a single expression, we've got more serious design problems to solve. The cost of evaluating a single expression is rarely the costliest part of an algorithm.
Crashing with an exception is sensible behavior in the presence of a design problem. An alternative is to write a message to an error log. However, if we have this kind of logic gap, the program should be viewed as fatally broken. It's important to find and fix this as soon as the problem is known.
There's more...
In many cases, we can derive an if...elif...elif chain from an examination of the desired post condition at some point in the program's processing. For example, we may need a statement that establishes something simple, like: m is equal to the larger of a or b.
(For the sake of working through the logic, we'll avoid Python's handy m = max(a, b), and focus on the way we can compute a result from exclusive choices.)
We can formalize the final condition like this:

We can work backward from this final condition, by writing the goal as an assert statement:
# do something
assert (m == a or m == b) and m >= a and m >= b
Once we have the goal stated, we can identify statements that lead to that goal. Clearly assignment statements like m = a or m = b would be appropriate, but each of these works only under certain conditions.
Each of these statements is part of the solution, and we can derive a precondition that shows when the statement should be used. The preconditions for each assignment statement are the if and elif expressions. We need to use m = a when a >= b; we need to use m = b when b >= a. Rearranging logic into code gives us this:
if a >= b:
m = a
elif b >= a:
m = b
else:
raise Exception('Design Problem')
assert (m == a or m == b) and m >= a and m >= b
Note that our universe of conditions, U = {a ≥ b, b ≥ a}, is complete; there's no other possible relationship. Also notice that in the edge case of a = b, we don't actually care which assignment statement is used. Python will process the decisions in order, and will execute m = a. The fact that this choice is consistent shouldn't have any impact on our design of if...elif...elif chains. We should always write the conditions without regard to the order of evaluation of the clauses.
See also
- This is similar to the syntactic problem of a dangling else. See http://www.mathcs.emory.edu/~cheung/Courses/561/Syllabus/2-C/dangling-else.html
- Python's indentation removes the dangling else syntax problem. It doesn't remove the semantic issue of trying to be sure that all conditions are properly accounted for in a complex
if...elif...elifchain.
Saving intermediate results with the := "walrus"
Sometimes we'll have a complex condition where we want to preserve an expensive intermediate result for later use. Imagine a condition that involves a complex calculation; the cost of computing is high measured in time, or input-output, or memory, or network resource use. Resource use defines the cost of computation.
An example includes doing repetitive searches where the result of the search may be either a useful value or a sentinel value indicating that the target was not found. This is common in the Regular Expression (re) package where the match() method either returns a match object or a None object as a sentinel showing the pattern wasn't found. Once this computation is completed, we may have several uses for the result, and we emphatically do not want to perform the computation again.
This is an example where it can be helpful to assign a name to the value of an expression. We'll look at how to use the "assignment expression" or "walrus" operator. It's called the walrus because the assignment expression operator, :=, looks like the face of a walrus to some people.
Getting ready
Here's a summation where – eventually – each term becomes so small that there's no point in continuing to add it to the overall total:

In effect, this is something like the following summation function:
>>> s = sum((1/(2*n+1))**2 for n in range(0, 20_000))
What's not clear is the question of how many terms are required. In the example, we've summed 20,000. But what if 16,000 are enough to provide an accurate answer?
We don't want to write a summation like this:
>>> b = 0
>>> for n in range(0, 20_000):
... if (1/(2*n+1))**2 >= 0.000_000_001:
... b = b + (1/(2*n+1))**2
This example repeats an expensive computation, (1/(2*n+1))**2. That's likely to be a waste of time.
How to do it…
- Isolate an expensive operation that's part of a conditional test. In this example, the variable
termis used to hold the expensive result:>>> p = 0 >>> for n in range(0, 20_000): ... term = (1/(2*n+1))**2 ... if term >= 0.000_000_001: ... p = p + term - Rewrite the assignment statement to use the
:=assignment operator. This replaces the simple condition of theifstatement. - Add an
elsecondition to break out of theforstatement if no more terms are needed. Here's the results of these two steps:>>> q = 0 >>> for n in range(0, 20_000): ... if (term := (1/(2*n+1))**2) >= 0.000_000_001: ... q = q + term ... else: ... break
The assignment expression, :=, lets us do two things in the if statement. We can both compute a value and also check to see that the computed value meets some useful criteria. We can provide the computation and the test criteria adjacent to each other.
How it works…
The assignment expression operator, :=, saves an intermediate result. The operator's result value is the same as the right-hand side operand. This means that the expression a + (b:= c+d) has the same as the expression a+(c+d). The difference between the expression a + (b:= c+d) and the expression a+(c+d) is the side-effect of setting the value of the b variable partway through the evaluation.
An assignment expression can be used in almost any kind of context where expressions are permitted in Python. The most common cases are if statements. Another good idea is inside a while condition.
They're also forbidden in a few places. They cannot be used as the operator in an expression statement. We're specifically prohibited from writing a := 2 as a statement: there's a perfectly good assignment statement for this purpose and an assignment expression, while similar in intent, is potentially confusing.
There's more…
We can do some more optimization of our infinite summation example, shown earlier in this recipe. The use of a for statement and a range() object seems simple. The problem is that we want to end the for statement early when the terms being added are so small that they have no significant change in the final sum.
We can combine the early exit with the term computation:
>>> r = 0
>>> n = 0
>>> while (term := (1/(2*n+1))**2) >= 0.000_000_001:
... r += term
... n += 1
We've used a while statement with the assignment expression operator. This will compute a value using (1/(2*n+1))**2, and assign this to term. If the value is significant, we'll add it to the sum, r, and increment the value for the n variable. If the value is too small to be significant, the while statement will end.
Here's another example, showing how to compute running sums of a collection of values. This looks forward to concepts in Chapter 4, Built-In Data Structures Part 1: Lists and Sets. Specifically, this shows a list comprehension built using the assignment expression operator:
>>> data = [11, 13, 17, 19, 23, 29]
>>> total = 0
>>> running_sum = [(total := total + d) for d in data]
>>> total
112
>>> running_sum
[11, 24, 41, 60, 83, 112]
We've started with some data, in the data variable. This might be minutes of exercise each day for most of a week. The value of running_sum is a list object, built by evaluating the expression (total := total + d) for each value, d, in the data variable. Because the assignment expression changes the value of the total variable, the resulting list is the result of each new value being accumulated.
See also
- For details on assignment expression, see PEP 572 where the feature was first described: https://www.python.org/dev/peps/pep-0572/
Avoiding a potential problem with break statements
The common way to understand a for statement is that it creates a for all condition. At the end of the statement, we can assert that, for all items in a collection, some processing has been done.
This isn't the only meaning for a for statement. When we introduce the break statement inside the body of a for, we change the semantics to there exists. When the break statement leaves the for (or while) statement, we can assert only that there exists at least one item that caused the statement to end.
There's a side issue here. What if the for statement ends without executing break? Either way, we're at the statement after the for statement.
The condition that's true upon leaving a for or while statement with a break can be ambiguous. Did it end normally? Did it execute break? We can't easily tell, so we'll provide a recipe that gives us some design guidance.
This can become an even bigger problem when we have multiple break statements, each with its own condition. How can we minimize the problems created by having complex conditions?
Getting ready
When parsing configuration files, we often need to find the first occurrence of a : or = character in a string. This is common when looking for lines that have a similar syntax to assignment statements, for example, option = value or option : value. The properties file format uses lines where : (or =) separate the property name from the property value.
This is a good example of a there exists modification to a for statement. We don't want to process all characters; we want to know where there is the leftmost : or =.
Here's the sample data we're going use as an example:
>>> sample_1 = "some_name = the_value"
Here's a small for statement to locate the leftmost "=" or ":" character in the sample string value:
>>> for position in range(len(sample_1)):
... if sample_1[position] in '=:':
... break
>>> print(f"name={sample_1[:position]!r}",
... f"value={sample_1[position+1:]!r}")
name='some_name ' value=' the_value'
When the "=" character is found, the break statement stops the for statement. The value of the position variable shows where the desired character was found.
What about this edge case?
>>> sample_2 = "name_only"
>>> for position in range(len(sample_2)):
... if sample_2[position] in '=:':
... break
>>> print(f"name={sample_2[:position]!r}",
... f"value={sample_2[position+1:]!r}")
name='name_onl' value=''
The result is awkwardly wrong: the y character got dropped from the value of name. Why did this happen? And, more importantly, how can we make the condition at the end of the for statement more clear?
How to do it...
Every statement establishes a post condition. When designing a for or while statement, we need to articulate the condition that's true at the end of the statement. In this case, the post condition of the for statement is quite complicated.
Ideally, the post condition is something simple like text[position] in '=:'. In other words, the value of position is the location of the "=" or ":" character. However, if there's no = or : in the given text, the overly simple post condition can't be true. At the end of the for statement, one of two things are true: either (a) the character with the index of position is "=" or ":", or (b) all characters have been examined and no character is "=" or ":".
Our application code needs to handle both cases. It helps to carefully articulate all of the relevant conditions.
- Write the obvious post condition. We sometimes call this the happy-path condition because it's the one that's true when nothing unusual has happened:
text[position] in '=:' - Create the overall post condition by adding the conditions for the edge cases. In this example, we have two additional conditions:
- There's no
=or:. - There are no characters at all.
len()is zero, and theforstatement never actually does anything. In this case, thepositionvariable will never be created. In this example, we have three conditions:(len(text) == 0 or not('=' in text or ':' in text) or text[position] in '=:')
- There's no
- If a
whilestatement is being used, consider redesigning it to have the overall post condition in thewhileclause. This can eliminate the need for abreakstatement. - If a
forstatement is being used, be sure a proper initialization is done, and add the various terminating conditions to the statements after the loop. It can look redundant to havex = 0followed byfor x = .... It's necessary in the case of aforstatement that doesn't execute thebreakstatement. Here's the resultingforstatement and a complicatedifstatement to examine all of the possible post conditions:>>> position = -1 >>> for position in range(len(sample_2)): ... if sample_2[position] in '=:': ... break ... >>> if position == -1: ... print(f"name=None value=None") ... elif not(sample_2[position] == ':' or sample_2[position] == '='): ... print(f"name={sample_2!r} value=None") ... else: ... print(f"name={sample_2[:position]!r}", ... f"value={sample_2[position+1:]!r}") name= name_only value= None
In the statements after the for, we've enumerated all of the terminating conditions explicitly. If the position found is -1, then the for loop did not process any characters. If the position is not the expected character, then all the characters were examined. The third case is one of the expected characters were found. The final output, name='name_only' value=None, confirms that we've correctly processed the sample text.
How it works...
This approach forces us to work out the post condition carefully so that we can be absolutely sure that we know all the reasons for the loop terminating.
In more complex, nested for and while statements—with multiple break statements—the post condition can be difficult to work out fully. A for statement's post condition must include all of the reasons for leaving the loop: the normal reasons plus all of the break conditions.
In many cases, we can refactor the for statement. Rather than simply asserting that position is the index of the = or : character, we include the next processing steps of assigning substrings to the name and value variables. We might have something like this:
>>> if len(sample_2) > 0:
... name, value = sample_2, None
... else:
... name, value = None, None
>>> for position in range(len(sample_2)):
... if sample_2[position] in '=:':
... name, value = sample_2[:position], sample2[position:]
... break
>>> print(f"{name=} {value=}")
name='name_only' value=None
This version pushes some of the processing forward, based on the complete set of post conditions evaluated previously. The initial values for the name and value variables reflect the two edge cases: there's no = or : in the data or there's no data at all. Inside the for statement, the name and value variables are set prior to the break statement, assuring a consistent post condition.
The idea here is to forego any assumptions or intuition. With a little bit of discipline, we can be sure of the post conditions. The more we think about post conditions, the more precise our software can be. It's imperative to be explicit about the condition that's true when our software works. This is the goal for our software, and you can work backward from the goal by choosing the simplest statements that will make the goal conditions true.
There's more...
We can also use an else clause on a for statement to determine if the statement finished normally or a break statement was executed. We can use something like this:
>>> for position in range(len(sample_2)):
... if sample_2[position] in '=:':
... name, value = sample_2[:position], sample_2[position+1:]
... break
... else:
... if len(sample_2) > 0:
... name, value = sample_2, None
... else:
... name, value = None, None
>>> print(f"{name=} {value=}")
name='name_only' value=None
Using an else clause in a for statement is sometimes confusing, and we don't recommend it. It's not clear if its version is substantially better than any of the alternatives. It's too easy to forget the reason why else is executed because it's used so rarely.
See also
- A classic article on this topic is by David Gries, A note on a standard strategy for developing loop invariants and loops. See http://www.sciencedirect.com/science/article/pii/0167642383900151
Leveraging exception matching rules
The try statement lets us capture an exception. When an exception is raised, we have a number of choices for handling it:
- Ignore it: If we do nothing, the program stops. We can do this in two ways—don't use a
trystatement in the first place, or don't have a matchingexceptclause in thetrystatement. - Log it: We can write a message and use a
raisestatement to let the exception propagate after writing to a log; generally, this will stop the program. - Recover from it: We can write an
exceptclause to do some recovery action to undo any effects of the partially completedtryclause. - Silence it: If we do nothing (that is, use the
passstatement), then processing is resumed after thetrystatement. This silences the exception. - Rewrite it: We can raise a different exception. The original exception becomes a context for the newly raised exception.
What about nested contexts? In this case, an exception could be ignored by an inner try but handled by an outer context. The basic set of options for each try context is the same. The overall behavior of the software depends on the nested definitions.
Our design of a try statement depends on the way that Python exceptions form a class hierarchy. For details, see Section 5.4, Python Standard Library. For example, ZeroDivisionError is also an ArithmeticError and an Exception. For another example, FileNotFoundError is also an OSError as well as an Exception.
This hierarchy can lead to confusion if we're trying to handle detailed exceptions as well as generic exceptions.
Getting ready
Let's say we're going to make use of the shutil module to copy a file from one place to another. Most of the exceptions that might be raised indicate a problem too serious to work around. However, in the specific event of FileNotFoundError, we'd like to attempt a recovery action.
Here's a rough outline of what we'd like to do:
>>> from pathlib import Path
>>> import shutil
>>> import os
>>> source_dir = Path.cwd()/"data"
>>> target_dir = Path.cwd()/"backup"
>>> for source_path in source_dir.glob('**/*.csv'):
... source_name = source_path.relative_to(source_dir)
... target_path = target_dir/source_name
... shutil.copy(source_path, target_path)
We have two directory paths, source_dir and target_dir. We've used the glob() method to locate all of the directories under source_dir that have *.csv files.
The expression source_path.relative_to(source_dir) gives us the tail end of the filename, the portion after the directory. We use this to build a new, similar path under the target_dir directory. This assures that a file named wc1.csv in the source_dir directory will have a similar name in the target_dir directory.
The problems arise with handling exceptions raised by the shutil.copy() function. We need a try statement so that we can recover from certain kinds of errors. We'll see this kind of error if we try to run this:
FileNotFoundError: [Errno 2] No such file or directory: '/Users/slott/Documents/Writing/Python/Python Cookbook 2e/Modern-Python-Cookbook-Second-Edition/backup/wc1.csv'
This happens when the backup directory hasn't been created. It will also happen when there are subdirectories inside the source_dir directory tree that don't also exist in the target_dir tree. How do we create a try statement that handles these exceptions and creates the missing directories?
How to do it...
- Write the code we want to use indented in the
tryblock:>>> try: ... shutil.copy(source_path, target_path) - Include the most specific exception classes first. In this case, we have a meaningful response to the specific
FileNotFoundError. - Include any more general exceptions later. In this case, we'll report any generic
OSErrorthat's encountered. This leads to the following:>>> try: ... target = shutil.copy(source_path, target_path) ... except FileNotFoundError: ... target_path.parent.mkdir(exist_ok=True, parents=True) ... target = shutil.copy(source_path, target_path) ... except OSError as ex: ... print(f"Copy {source_path} to {target_path} error {ex}")
We've matched exceptions with the most specific first and the more generic after that.
We handled FileNotFoundError by creating the missing directories. Then we did copy() again, knowing it would now work properly.
We logged any other exceptions of the class OSError. For example, if there's a permission problem, that error will be written to a log and the next file will be tried. Our objective is to try and copy all of the files. Any files that cause problems will be logged, but the copying process will continue.
How it works...
Python's matching rules for exceptions are intended to be simple:
- Process
exceptclauses in order. - Match the actual exception against the exception class (or tuple of exception classes). A match means that the actual exception object (or any of the base classes of the exception object) is of the given class in the
exceptclause.
These rules show why we put the most specific exception classes first and the more general exception classes last. A generic exception class like Exception will match almost every kind of exception. We don't want this first, because no other clauses will be checked. We must always put generic exceptions last.
There's an even more generic class, the BaseException class. There's no good reason to ever handle exceptions of this class. If we do, we will be catching SystemExit and KeyboardInterrupt exceptions; this interferes with the ability to kill a misbehaving application. We only use the BaseException class as a superclass when defining new exception classes that exist outside the normal exception hierarchy.
There's more...
Our example includes a nested context in which a second exception can be raised. Consider this except clause:
... except FileNotFoundError:
... target_path.parent.mkdir(exist_ok=True, parents=True)
... target = shutil.copy(source_path, target_path)
If the mkdir() method or shutil.copy() functions raise an exception while handling the FileNotFoundError exception, it won't be handled. Any exceptions raised within an except clause can crash the program as a whole. Handling this can involve nested try statements.
We can rewrite the exception clause to include a nested try during recovery:
... try:
... target = shutil.copy(source_path, target_path)
... except FileNotFoundError:
... try:
... target_path.parent.mkdir(exist_ok=True, parents=True)
... target = shutil.copy(source_path, target_path)
... except OSError as ex2:
... print(f"{target_path.parent} problem: {ex2}")
... except OSError as ex:
... print(f"Copy {source_path} to {target_path} error {ex}")
In this example, a nested context writes one message for OSError. In the outer context, a slightly different error message is used to log the error. In both cases, processing can continue. The distinct error messages make it slightly easier to debug the problems.
See also
- In the Avoiding a potential problem with an except: clause recipe, we look at some additional considerations when designing exception handling statements.
Avoiding a potential problem with an except: clause
There are some common mistakes in exception handling. These can cause programs to become unresponsive.
One of the mistakes we can make is to use the except: clause with no named exceptions to match. There are a few other mistakes that we can make if we're not cautious about the exceptions we try to handle.
This recipe will show some common exception handling errors that we can avoid.
Getting ready
When code can raise a variety of exceptions, it's sometimes tempting to try and match as many as possible. Matching too many exceptions can interfere with stopping a misbehaving Python program. We'll extend the idea of what not to do in this recipe.
How to do it...
We need to avoid using the bare except: clause. Instead, use except Exception: to match the most general kind of exception that an application can reasonably handle.
Handling too many exceptions can interfere with our ability to stop a misbehaving Python program. When we hit Ctrl + C, or send a SIGINT signal via the OS's kill -2 command, we generally want the program to stop. We rarely want the program to write a message and keep running. If we use a bare except: clause, we can accidentally silence important exceptions.
There are a few other classes of exceptions that we should be wary of attempting to handle:
SystemErrorRuntimeErrorMemoryError
Generally, these exceptions mean things are going badly somewhere in Python's internals. Rather than silence these exceptions, or attempt some recovery, we should allow the program to fail, find the root cause, and fix it.
How it works...
There are two techniques we should avoid:
- Don't capture the
BaseExceptionclass. - Don't use
except:with no exception class. This matches all exceptions, including exceptions we should avoid trying to handle.
Using either of the above techniques can cause a program to become unresponsive at exactly the time we need to stop it. Further, if we capture any of these exceptions, we can interfere with the way these internal exceptions are handled:
SystemExitKeyboardInterruptGeneratorExit
If we silence, wrap, or rewrite any of these, we may have created a problem where none existed. We may have exacerbated a simple problem into a larger and more mysterious problem.
It's a noble aspiration to write a program that never crashes. Interfering with some of Python's internal exceptions, however, doesn't create a more reliable program. Instead, it creates a program where a clear failure is masked and made into an obscure mystery.
See also
- In the Leveraging the exception matching rules recipe, we look at some considerations when designing exception-handling statements.
Concealing an exception root cause
In Python 3, exceptions contain a root cause. The default behavior of internally raised exceptions is to use an implicit __context__ to include the root cause of an exception. In some cases, we may want to deemphasize the root cause because it's misleading or unhelpful for debugging.
This technique is almost always paired with an application or library that defines a unique exception. The idea is to show the unique exception without the clutter of an irrelevant exception from outside the application or library.
Getting ready
Assume we're writing some complex string processing. We'd like to treat a number of different kinds of detailed exceptions as a single generic error so that users of our software are insulated from the implementation details. We can attach details to the generic error.
How to do it...
- To create a new exception, we can do this:
>>> class MyAppError(Exception): ... passThis creates a new, unique class of exception that our library or application can use.
- When handling exceptions, we can conceal the root cause exception like this:
>>> try: ... None.some_method(42) ... except AttributeError as exception: ... raise MyAppError("Some Known Problem") from None
In this example, we raise a new exception instance of the module's unique MyAppError exception class. The new exception will not have any connection with the root cause AttributeError exception.
How it works...
The Python exception classes all have a place to record the cause of the exception. We can set this __cause__ attribute using the raise Visible from RootCause statement. This is done implicitly using the exception context as a default if the from clause is omitted.
Here's how it looks when this exception is raised:
>>> try:
... None.some_method(42)
... except AttributeError as exception:
... raise MyAppError("Some Known Problem") from None
Traceback (most recent call last):
File "/Applications/PyCharm CE.app/Contents/helpers/pycharm/docrunner.py", line 139, in __run
exec(compile(example.source, filename, "single",
File "<doctest examples.txt[67]>", line 4, in <module>
raise MyAppError("Some Known Problem") from None
MyAppError: Some Known Problem
The underlying cause has been concealed. If we omit from None, then the exception will include two parts and will be quite a bit more complex. When the root cause is shown, the output looks like this:
Traceback (most recent call last):
File "<doctest examples.txt[66]>", line 2, in <module>
None.some_method(42)
AttributeError: 'NoneType' object has no attribute 'some_method'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Applications/PyCharm CE.app/Contents/helpers/pycharm/docrunner.py", line 139, in __run
exec(compile(example.source, filename, "single",
File "<doctest examples.txt[66]>", line 4, in <module>
raise MyAppError("Some Known Problem")
MyAppError: Some Known Problem
This shows the underlying AttributeError. This may be an implementation detail that's unhelpful and better left off the printed display of the exception.
There's more...
There are a number of internal attributes of an exception. These include __cause__, __context__, __traceback__, and __suppress_context__. The overall exception context is in the __context__ attribute. The cause, if provided via a raise from statement, is in __cause__. The context for the exception is available but can be suppressed from being printed.
See also
- In the Leveraging the exception matching rules recipe, we look at some considerations when designing exception-handling statements.
- In the Avoiding a potential problem with an except: clause recipe, we look at some additional considerations when designing exception-handling statements.
Managing a context using the with statement
There are many instances where our scripts will be entangled with external resources. The most common examples are disk files and network connections to external hosts. A common bug is retaining these entanglements forever, tying up these resources uselessly. These are sometimes called memory leaks because the available memory is reduced each time a new file is opened without closing a previously used file.
We'd like to isolate each entanglement so that we can be sure that the resource is acquired and released properly. The idea is to create a context in which our script uses an external resource. At the end of the context, our program is no longer bound to the resource and we want to be guaranteed that the resource is released.
Getting ready
Let's say we want to write lines of data to a file in CSV format. When we're done, we want to be sure that the file is closed and the various OS resources—including buffers and file handles—are released. We can do this in a context manager, which guarantees that the file will be properly closed.
Since we'll be working with CSV files, we can use the csv module to handle the details of the formatting:
>>> import csv
We'll also use the pathlib module to locate the files we'll be working with:
>>> from pathlib import Path
For the purposes of having something to write, we'll use this silly data source:
>>> some_source = [[2,3,5], [7,11,13], [17,19,23]]
This will give us a context in which to learn about the with statement.
How to do it...
- Create the context by opening the path, or creating the network connection with
urllib.request.urlopen(). Other common contexts include archives likezipfiles andtarfiles:>>> target_path = Path.cwd()/"data"/"test.csv" >>> with target_path.open('w', newline='') as target_file: - Include all the processing, indented within the
withstatement:>>> target_path = Path.cwd()/"data"/"test.csv" >>> with target_path.open('w', newline='') as target_file: ... writer = csv.writer(target_file) ... writer.writerow(['column', 'data', 'heading']) ... writer.writerows(some_source) - When we use a file as a context manager, the file is automatically closed at the end of the indented context block. Even if an exception is raised, the file is still closed properly. Outdent the processing that is done after the context is finished and the resources are released:
>>> target_path = Path.cwd()/"data"/"test.csv" >>> with target_path.open('w', newline='') as target_file: ... writer = csv.writer(target_file) ... writer.writerow(['column', 'data', 'heading']) ... writer.writerows(some_source) >>> print(f'finished writing {target_path.name}')
The statements outside the with context will be executed after the context is closed. The named resource—the file opened by target_path.open()—will be properly closed.
Even if an exception is raised inside the with statement, the file is still properly closed. The context manager is notified of the exception. It can close the file and allow the exception to propagate.
How it works...
A context manager is notified of three significant events surrounding the indented block of code:
- Entry
- Normal exit with no exception
- Exit with an exception pending
The context manager will—under all conditions—disentangle our program from external resources. Files can be closed. Network connections can be dropped. Database transactions can be committed or rolled back. Locks can be released.
We can experiment with this by including a manual exception inside the with statement. This can show that the file was properly closed:
>>> try:
... with target_path.open('w', newline='') as target_file:
... writer = csv.writer(target_file)
... writer.writerow(['column', 'data', 'heading'])
... writer.writerow(some_source[0])
... raise Exception("Testing")
... except Exception as exc:
... print(f"{target_file.closed=}")
... print(f"{exc=}")
>>> print(f"Finished Writing {target_path.name}")
In this example, we've wrapped the real work in a try statement. This allows us to raise an exception after writing the first line of data to the CSV file. Because the exception handling is outside the with context, the file is closed properly. All resources are released and the part that was written is properly accessible and usable by other programs.
The output confirms the expected file state:
target_file.closed=True
exc=Exception('Testing')
This shows us that the file was properly closed. It also shows us the message associated with the exception to confirm that it was the exception we raised manually. This kind of technique allows us to work with expensive resources like database connections and network connections and be sure these don't "leak." A resource leak is a common description used when resources are not released properly back to the OS; it's as if they slowly drain away, and the application stops working because there are no more available OS network sockets or file handles. The with statement can be used to properly disentangle our Python application from OS resources.
There's more...
Python offers us a number of context managers. We noted that an open file is a context, as is an open network connection created by urllib.request.urlopen().
For all file operations, and all network connections, we should always use a with statement as a context manager. It's very difficult to find an exception to this rule.
It turns out that the decimal module makes use of a context manager to allow localized changes to the way decimal arithmetic is performed. We can use the decimal.localcontext() function as a context manager to change rounding rules or precision for calculations isolated by a with statement.
We can define our own context managers, also. The contextlib module contains functions and decorators that can help us create context managers around resources that don't explicitly offer them.
When working with locks, the with statement context manager is the ideal way to acquire and release a lock. See https://docs.python.org/3/library/threading.html#with-locks for the relationship between a lock object created by the threading module and a context manager.
See also
- See https://www.python.org/dev/peps/pep-0343/ for the origins of the with statement.
- Numerous recipes in Chapter 9, Functional Programming Features, will make use of this technique. The recipes Reading delimited files with the cvs module, Reading complex formats using regular expressions, and Reading HTML documents, among others, will make use of the
withstatement.