
8
More Advanced Class Design
In Chapter 7, Basics of Classes and Objects, we looked at some recipes that covered the basics of class design. In this chapter, we'll dive more deeply into Python classes.
In the Designing classes with lots of processing and Using properties for lazy attributes recipes in Chapter 7, Basics of Classes and Objects, we identified a design choice that's central to object-oriented programming, the "wrap versus extend" decision. One way to add features is to create a new subclass via an extension. The other technique for adding features is to wrap an existing class, making it part of a new class.
In addition to direct inheritance, there are some other class extension techniques available in Python. A Python class can inherit features from more than one superclass. We call this design pattern a mixin.
In Chapter 4, Built-In Data Structures Part 1: Lists and Sets, and Chapter 5, Built-In Data Structures Part 2: Dictionaries, we looked at the core built-in data structures. We can combine and extend these collection definition features to create more complex data structures or data structures with additional features.
In this chapter, we'll look at the following recipes:
- Choosing between
inheritanceandcomposition– the "is-a" question - Separating concerns via multiple
inheritance - Leveraging Python's duck typing
- Managing
globalandsingletonobjects - Using more complex structures – maps of lists
- Creating a
classthat has orderable objects - Improving performance with an ordered
collection - Deleting from a
listof complicated objects
There are a great many techniques of object-oriented class design available in Python. We'll start with a foundational concept: making the design choice between using inheritance from a base class and wrapping a class to extend it.
Choosing between inheritance and composition – the "is-a" question
In the Using cmd for creating command-line applications recipe in Chapter 6, User Inputs and Outputs, and the Extending a collection – a list that does statistics recipe in Chapter 7, Basics of Classes and Objects, we looked at extending a class. In both cases, the class implemented in the recipe was a subclass of one of Python's built-in classes. In Chapter 7, Basics of Classes and Objects, we defined the DiceCLI class to extend the cmd.Cmd class via inheritance. In We also defined a StatsList class to extend the built-in list class.
The idea of extension via inheritance is sometimes called the generalization-specialization relationship. It's sometimes also called an is-a relationship.
There's an important semantic issue here: it's sometimes referred to as the wrap versus extend problem. There are two common choices:
- Do we mean that instances of the subclass are also examples of the superclass? This is an is-a relationship. An example in Python is the built-in
Counter, which extends the base classdict. ACounterinstance is a dictionary with a few extra features. - Or do we mean something else? Perhaps there's an association, sometimes called a has-a relationship. An example of this is in the Designing classes with lots of processing recipe in Chapter 7, Basics of Classes and Objects, where
CounterStatisticswraps aCounterobject. In this case, theCounterStatisticsobject has aCounter, but is not a kind ofCounter, nor is it a dictionary.
We'll look at both the inheritance and composition techniques for creating new features for existing classes. Seeing both solutions to the same problem can help clarify the differences.
Getting ready
For this recipe, we'll use models for a deck of playing cards as concrete examples. We have two ways to model a deck of playing cards:
- As a class of objects that extends the built-in
listclass. The deck is a list. - As a wrapper that combines the built-in
listclass with some other features. The deck has a list as an attribute.
The core ingredient for both implementations is the underlying Card object. We can define this using typing.NamedTuple:
>>> from typing import NamedTuple
>>> class Card(NamedTuple):
... rank: int
... suit: str
>>> Spades, Hearts, Diamonds, Clubs = 'u2660u2661u2662u2663'
We've created the class definition, Card, by extending the NamedTuple class. This creates a new subclass with two attributes of rank and suit. We've provided the type hints to suggest rank should be an integer value, and suit should be a string. The mypy tool can be used to confirm the type hints are followed by the code using this class.
We also defined the various suits as four different Unicode character strings, each of length one. The four-character literal was decomposed into four single-character substrings. The "u2660" string, for example, is a single Unicode character that displays the black spade character.
Here's how we can build a Card object with a rank and suit:
>>> Card(2, Spades)
Card(rank=2, suit=' ')
')
We could provide an Enum class to define the collection of suit values. We'll leave this as an exercise for the reader.
We'll use this Card class in the rest of this recipe. In some card games, a single 52-card deck is used. In other games, a dealing shoe is used; this is a box that allows a dealer to shuffle and deal from multiple decks.
What's important is that the various kinds of collection—deck, shoe, and the built-in list type—all have considerable overlaps in the kinds of features they support. This means that both inheritance and wrapping will work. The two techniques make different claims and can lead to different ways of understanding the resulting code.
How to do it...
This recipe has three overall sections. In the first section, we'll take a close look at a previous recipe. We'll be working with the Using a class to encapsulate data and processing recipe in Chapter 7, Basics of Classes and Objects, with this recipe. After looking at the design changes, we'll show how to implement them using both inheritance and composition.
Here's the first part of the recipe to examine and plan the design changes:
- Use the nouns and verbs from the original story or problem statement to identify all of the classes.
- Look for overlaps in the feature sets of various classes. In many cases, the relationships will come directly from the problem statement itself. In the preceding example, a game can deal cards from a deck, or deal cards from a shoe. In this case, we might state one of these two views:
- A shoe is a specialized deck that starts with multiple copies of the 52-card domain
- A deck is a specialized shoe with only one copy of the 52-card domain
- Clarify the relationships among the classes where necessary. We expected
Deckto have one copy of eachCard.Shoe, however, will have many copies of eachCard. A large number of cards can share rank numbers and suit strings. There are a number of common patterns to these dependencies:- Aggregation: Some objects are bound into collections, but the objects have a properly independent existence. Our
Cardobjects might be aggregated into aHandcollection. When the game ends, theHandobjects can be deleted, but theCardobjects continue to exist. - Composition: Some objects are bound into collections, but do not have an independent existence. When looking at card games, a
Handof cards cannot exist without aPlayer. We might say that aPlayerobject is composed—in part—of aHand. If aPlayeris eliminated from a game, then theHandobjects must also be removed. While this is important for understanding the relationships among objects, there are some practical considerations that we'll look at in the next section. - An is-a relationship among classes (also called inheritance): This is the idea that a
Shoeis aDeckwith an extra feature (or two). This may be central to our design. We'll look into this in detail in the Extending – inheritance section of this recipe.
- Aggregation: Some objects are bound into collections, but the objects have a properly independent existence. Our
We've identified several paths for implementing the associations. The aggregation and composition cases are generally implemented by some kind of "wrapping" design techniques. The inheritance or is-a case is the "extending" technique. We'll look at these techniques separately.
Wrapping – aggregation and composition
Wrapping is a way to understand a collection. It can be a class that is an aggregate of independent objects. This could be implemented as a class that wraps an existing list object, meaning that the underlying Card objects will be shared by a list collection and a Deck collection.
We can implement the desired design changes through composition using this portion of the overall recipe:
- Define the independent collection. It might be a built-in collection, for example, a
set,list, ordict. For this example, it will be alistthat contains the individualCardinstances:>>> domain = list( ... Card(r+1,s) ... for r in range(13) ... for s in (Spades, Hearts, Diamonds, Clubs)) - Define the aggregate class. To distinguish similar examples in this book, the name has a
_Wsuffix. This not a generally recommended practice; it's only used here to emphasize the distinctions between class definitions in this recipe. (A short suffix like"_W"doesn't add much clarity in the long run; in this context, it's helpful to keep the example code short.) Later, we'll see a slightly different variation on this design. Here's the definition of the class:class Deck_W: - Use the
__init__()method of this class as one way to provide the underlying collection object. This will also initialize any stateful variables. We might create an iterator for dealing:def __init__(self, cards: List[Card]) -> None: self.cards = cards self.deal_iter = iter(cards)This uses a type hint,
List[Card]. Thetypingmodule provides the necessary definition of theListtype hint. (This can be generalized to use a parameter annotation ofIterable[Card]andself.cards = list(cards). It's not clear that this generalization is helpful for this application.) - If needed, provide other methods to either replace the collection or update the collection. This is rare in Python, since the underlying attribute,
cards, can be accessed directly. However, it might be helpful to provide a method that replaces theself.cardsvalue. - Provide the methods appropriate to the aggregate object. In this case, we've included two additional processing methods that encapsulate some of the behaviors of a deck of cards. The
shuffle()method randomizes the internal list object,self.cards. It also creates an iterator used to step through theself.cardslist by thedeal()method. We've provided a type hint ondeal()to clarify that it returns aCardinstance:def shuffle(self) -> None: random.shuffle(self.cards) self.deal_iter = iter(self.cards) def deal(self) -> Card: return next(self.deal_iter)
Here's how we can use the Deck_W class. We'll be working with a list of Card objects. In this case, the domain variable was created from a list comprehension that generated all 52 combinations of 13 ranks and four suits:
>>> domain = list(
... Card(r+1,s)
... for r in range(13)
... for s in (Spades, Hearts, Diamonds, Clubs))
>>> len(domain)
52
We can use the items in this collection, domain, to create a second aggregate object that shares the same underlying Card objects. We'll build the Deck_W object from the list of objects in the domain variable:
>>> import random
>>> from Chapter_08.ch08_r01 import Deck_W
>>> d = Deck_W(domain)
Once the Deck_W object is available, it's possible to use the unique features:
>>> random.seed(1)
>>> d.shuffle()
>>> [d.deal() for _ in range(5)]
[Card(rank=13, suit=' '),
Card(rank=3, suit=''),
Card(rank=10, suit=''),
Card(rank=6, suit='
'),
Card(rank=3, suit=''),
Card(rank=10, suit=''),
Card(rank=6, suit=' '),
Card(rank=1, suit='')]
'),
Card(rank=1, suit='')]
We've seeded the random number generator to force the shuffle operation to leave the cards in a known order. We can deal five cards from the deck. This shows how the Deck_W object, d, shares the same pool of objects as the domain list.
We can delete the Deck_W object, d, and create a new deck from the domain list. This is because the Card objects are not part of a composition. The cards have an existence independent of the Deck_W collection.
Extending – inheritance
Here's an approach to defining a class that extends one of the built-in collections of objects. We'll define a Deck_X class as an aggregate that wraps an existing list. The underlying Card objects will be part of the Deck_X list.
We can implement the desired design changes through inheritance using the steps from this portion of the overall recipe:
- Start by defining the extension class as a subclass of a built-in collection. To distinguish similar examples in this book, the name has an
_Xsuffix. A short suffix like this is not a generally recommended practice; it's used here to emphasize the distinctions between class definitions in this recipe. The subclass relationship is a formal statement—aDeck_Xis also a kind of list. Here's the class definition:class Deck_X(list): - No additional code is needed to initialize the instance, as we'll use the
__init__()method inherited from thelistclass. - No additional code is needed to update the list, as we'll use other methods of the
listclass for adding, changing, or removing items from theDeck. - Provide the appropriate methods to the extended object. The
shuffle()method randomizes the object as a whole. The collection here isself, because this method is an extension of thelistclass. Thedeal()object relies on an iterator created by theshuffle()method to step through theself.cardslist. Exactly like inDeck_W, we've provided a type hint ondeal()to clarify that it returns aCardinstance:def shuffle(self) -> None: random.shuffle(self) self.deal_iter = iter(self) def deal(self) -> Card: return next(self.deal_iter)
Here's how we can use the Deck_X class. First, we'll build a deck of cards:
>>> from Chapter_08.ch08_r01 import Deck_X
>>> d2 = Deck_X(
... Card(r+1,s)
... for r in range(13)
... for s in (Spades, Hearts, Diamonds, Clubs))
>>> len(d2)
52
We used a generator expression to build individual Card objects. We can use the Deck_X() class in exactly the same way we'd use the list() class to create a new instance. In this case, we built a Deck_X object from the generator expression. We could build a list similarly.
We did not provide an implementation for the built-in __len__() method. This was inherited from the list class; it works nicely.
Using the deck-specific features for this implementation looks exactly like the other implementation, Deck_W:
>>> random.seed(1)
>>> d2.shuffle()
>>> [d2.deal() for _ in range(5)]
[Card(rank=13, suit=' '),
Card(rank=3, suit=''),
Card(rank=10, suit=''),
Card(rank=6, suit='
'),
Card(rank=3, suit=''),
Card(rank=10, suit=''),
Card(rank=6, suit=' '),
Card(rank=1, suit='')]
'),
Card(rank=1, suit='')]
We've seeded the random number generator, shuffled the deck, and dealt five cards. The extension methods work as well for Deck_X as they do for Deck_W. The shuffle() and deal() methods do their jobs.
There are some huge differences between these two definitions. When wrapping, we get precisely the methods we defined and no others. When using inheritance, we receive a wealth of method definitions from the superclass. This leads to some additional behaviors in the Deck_X class that may not be desirable:
- We can use a variety of collections to create
Deck_Xinstances. TheDeck_Wclass will only work for sequences offering the methods used by shuffling. We used a type hint to suggest that onlyList[Card]was sensible. - A
Deck_Xinstance can be sliced and indexed outside the core sequential iteration supported by thedeal()method. - Both classes create an internal
deal_iterobject to iterate through the cards and expose this iterator through thedeal()method.Deck_X, being a list, also offers the special method__iter__(), and can be used as an iterable source ofCardobjects without thedeal()method.
These differences are also important parts of deciding which technique to use. If the additional features are desirable, that suggests inheritance. If the additional features create problems, then composition might be a better choice.
How it works…
This is how Python implements the idea of inheritance. It uses a clever search algorithm for finding methods (and attributes.) The search works like this:
- Examine the object's class for the method or attribute.
- If the name is not defined in the immediate class, then search in all of the parent classes for the method or attribute.
Searching through the parent classes assures two things:
- Any method defined in any superclass is available to all subclasses
- Any subclass can override a method to replace a superclass method
Because of this, a subclass of the list class inherits all the features of the parent class. It is a specialized variation of the built-in list class.
This also means that all methods have the potential to be overridden by a subclass. Some languages have ways to lock a method against extension. Because Python doesn't have this, a subclass can override any method.
To explicitly refer to methods from a superclass, we can use the super() function to force a search through the superclasses. This allows a subclass to add features by wrapping the superclass version of a method. We use it like this:
def some_method(self):
# do something extra
super().some_method()
In this case, the some_method() method of a class will do something extra and then do the superclass version of the method. This allows us a handy way to extend selected methods of a class. We can preserve the superclass features while adding features unique to the subclass.
When designing a class, we must choose between several essential techniques:
- Wrapping: This technique creates a new class. All the methods you want the new class to have, you must explicitly define. This can be a lot of code to provide the required methods. Wrapping can be decomposed into two broad implementation choices:
- Aggregation: The objects being wrapped have an independent existence from the wrapper. The
Deck_Wexample showed how theCardobjects and even the list of cards were independent of the class. When anyDeck_Wobject is deleted, the underlying list will continue to exist; it's included as a reference only. - Composition: The objects being wrapped don't have any independent existence; they're an essential part of the composition. This involves a subtle difficulty because of Python's reference counting. We'll look at this shortly in some detail.
- Aggregation: The objects being wrapped have an independent existence from the wrapper. The
- Extension via inheritance: This is the is-a relationship. When extending a built-in class, then a great many methods are available from the superclass. The
Deck_Xexample showed this technique by creating a deck as an extension to the built-inlistclass.
There's more...
When looking at the independent existence of objects, there's an additional consideration regarding memory use. Python uses a technique called reference counting to track how many times an object is used. A statement such as del deck doesn't directly remove the deck object. A del statement removes the deck variable, which decrements the reference count for the underlying object. When the reference count reaches zero, the underlying object is no longer used by any variable and can be removed (that removal is known as "garbage collection").
Consider the following example:
>>> c_2s = Card(2, Spades)
>>> c_2s
Card(rank=2, suit=' ')
>>> another = c_2s
>>> another
Card(rank=2, suit='')
')
>>> another = c_2s
>>> another
Card(rank=2, suit='')
After the above four statements, we have a single object, Card(2, Spades), and two variables that refer to the object: both c_2s and another. We can confirm this by comparing their respective id values:
>>> id(c_2s) == id(another)
True
>>> c_2s is another
True
If we remove one of those variables with the del statement, the other variable still has a reference to the underlying object. The object won't be removed from memory until sometime after both variables are removed.
This consideration minimizes the distinction between aggregation and composition for Python programmers. In languages that don't use automatic garbage collection or reference counts, composition becomes an important part of memory management. In Python, we generally focus on aggregation over composition because the removal of unused objects is entirely automatic.
See also
- We've looked at built-in collections in Chapter 4, Built-In Data Structures Part 1: Lists and Sets. Also, in Chapter 7, Basics of Classes and Objects, we looked at how to define simple collections.
- In the Designing classes with lots of processing recipe, we looked at wrapping a class with a separate class that handles the processing details. We can contrast this with the Using properties for lazy attributes recipe of Chapter 7, Basics of Classes and Objects, where we put the complicated computations into the class as properties; this design relies on extension.
Separating concerns via multiple inheritance
In the Choosing between inheritance and extension – the is-a question recipe earlier in the chapter, we looked at the idea of defining a Deck class that was a composition of playing card objects. For the purposes of that example, we treated each Card object as simply having a rank and a suit. This created two small problems:
- The display for the card always showed a numeric rank. We didn't see J, Q, or K. Instead we saw 11, 12, and 13. Similarly, an ace was shown as 1 instead of A.
- Many games, such as Blackjack and Cribbage, assign a point value to each rank. Generally, the face cards have 10 points. For Blackjack, an ace has two different point values; depending on the total of other cards in the hand, it can be worth 1 point or 10 points.
Python's multiple inheritance lets us handle all of these variations in card game rules while keeping a single, essential Card class. Using multiple inheritance lets us separate rules for specific games from generic properties of playing cards. We can define a base class with mixin features.
Getting ready
A practical extension to the Card class needs to be a mixture of two feature sets:
- The essential features, such as rank and suit. This includes a method to show the
Cardobject's value nicely as a string (perhaps including "K," "Q," and so on, for court cards and aces, and numbers for spot cards). - Other, less essential, game-specific features, such as the number of points allotted to each particular card.
Python lets us define a class that includes features from multiple parents. A class can have both a Card superclass and a GameRules superclass.
In order to make sense of this kind of design, we'll often partition the various class hierarchies into two subsets of features:
- Essential features: These include the
rankandsuitattributes that apply to allCardinstances. - Mixin features: These features are mixed in to the class definition; they cover additional, more specialized use cases.
The idea is to define concrete classes from both essential and mixin features.
How to do it...
This recipe will create two hierarchies of classes, one for the essential Card and one for game-specific features including Cribbage point values. The essential class and mixin classes are then combined to create final, concrete classes appropriate to a specific game:
- Define the essential class. This is a generic
Cardclass, suitable for ranks 2 to 10:@dataclass(frozen=True) class Card: """Superclass for cards""" rank: int suit: str def __str__(self) -> str: return f"{self.rank:2d} {self.suit}" - Define the subclasses to implement specializations. We need two subclasses of the
Cardclass—theAceCardclass and theFaceCardclass, as defined in the following code:class AceCard(Card): def __str__(self) -> str: return f" A {self.suit}" class FaceCard(Card): def __str__(self) -> str: names = {11: "J", 12: "Q", 13: "K"} return f" {names[self.rank]} {self.suit}" - Define the core features required by the mixin classes. In Python parlance, this is called a "protocol" that the mixin classes implement. (In other languages, it might be called an interface.) We've used the
typing.Protocoltype hint as the superclass. The type annotation requires each card to possess an integer rank attribute:class PointedCard(Protocol): rank: int - Define a mixin subclass that identifies the additional features that will be added. For the game of Cribbage, the points for some cards are equal to the rank of the card. In this example, we'll use a concrete class that handles the rules for ace through 10:
class CribbagePoints(PointedCard): def points(self: PointedCard) -> int: return self.rank - Define concrete mixin subclasses for other kinds of features. For the three ranks of face cards, the points are always 10:
class CribbageFacePoints(PointedCard): def points(self: PointedCard) -> int: return 10 - Create the final, concrete class definitions that combine one of the essential base classes and any required mixin classes. While it's technically possible to add unique method definitions here, this example has sets of features entirely defined in separate classes:
class CribbageCard(Card, CribbagePoints): pass class CribbageAce(AceCard, CribbagePoints): pass class CribbageFace(FaceCard, CribbageFacePoints): pass - Define a factory function (or factory class) to create the appropriate objects based on the input parameters. Even with the mixins, the objects being created will all be considered as subclasses of
Cardbecause it's first in the list of base classes:def make_cribbage_card(rank: int, suit: str) -> Card: if rank == 1: return CribbageAce(rank, suit) if 2 <= rank < 11: return CribbageCard(rank, suit) if 11 <= rank: return CribbageFace(rank, suit) raise ValueError(f"Invalid rank {rank}")
We can use the make_cribbage_card() function to create a shuffled deck of cards as shown in this example interactive session:
>>> import random
>>> random.seed(1)
>>> deck = [make_cribbage_card(rank+1, suit) for rank in range(13) for suit in SUITS]
>>> random.shuffle(deck)
>>> len(deck)
52
>>> [str(c) for c in deck[:5]]
[' K  ', ' 3 ', '10 ', ' 6
', ' 3 ', '10 ', ' 6  ', ' A ']
', ' A ']
We've seeded the random number generator to assure that the results are the same each time we evaluate the shuffle() function. Having a fixed seed makes unit testing easier with predictable results.
We use a list comprehension to generate a list of cards that include all 13 ranks and 4 suits. This is a collection of 52 individual objects. The objects belong to two class hierarchies. Each object is a subclass of Card as well as being a subclass of CribbagePoints. This means that both collections of features are available for all of the objects.
For example, we can evaluate the points() method of each Card object:
>>> sum(c.points() for c in deck[:5])
30
The hand has two face cards, plus three, six, and ace, so the total points are 30.
How it works...
Python's mechanism for finding a method (or attribute) of an object works like this:
- Search the instance for the attribute.
- Search in the class for the method or attribute.
- If the name is not defined in the immediate class, then search all of the parent classes for the method or attribute. The parent classes are searched in a sequence called, appropriately, the Method Resolution Order (MRO).
We can see the method resolution order using the mro() method of a class. Here's an example:
>>> c = deck[5]
>>> str(c)
'10 '
>>> c.__class__.__name__
'CribbageCard'
>>> c.__class__.mro()
[<class 'Chapter_08.ch08_r02.CribbageCard'>, <class 'Chapter_08.ch08_r02.Card'>, <class 'Chapter_08.ch08_r02.CribbagePoints'>, <class 'Chapter_08.ch08_r02.PointedCard'>, <class 'typing.Protocol'>, <class 'typing.Generic'>, <class 'object'>]
We picked a card from the deck, c. The card's __class__ attribute is a reference to the class. In this case, the class name is CribbageCard. The mro() method of this class shows us the order that's used to resolve names:
- First, search the class itself,
CribbageCard. - If it's not there, search
Card. - Try to find it in
CribbagePointsnext. - Try to find it in the
PointedCardprotocol definition. This leads to a potential search ofProtocol, andGeneric, also. - Use
objectlast.
Class definitions generally use internal dict objects to store method definitions. This means that the search is an extremely fast hash-based lookup of the name.
There's more...
There are several kinds of design concerns we can separate in the form of mixins:
- Persistence and representation of state: We might add methods to manage conversion to a consistent external representation. For example, methods to represent the state of an object in CSV or JSON notation.
- Security: This may involve a mixin class that performs a consistent authorization check that becomes part of each object.
- Logging: A mixin class could create a logger that's consistent across a variety of classes.
- Event signaling and change notification: In this case, we might have objects that produce state change notifications; objects can subscribe to those notifications. These are sometimes called the Observable and Observer design patterns. A GUI widget might observe the state of an object; when the object changes, the mixin feature notifies the GUI widget so that the display is refreshed.
In many cases, these concerns can be handled by separating the core state definition from these additional concerns. Mixin classes provide a way to isolate the various considerations.
As an example, we'll create a mixin to introduce logging to cards. We'll define this class in a way that must be provided first in the list of superclasses. Since it's early in the MRO list, it uses the super() function to use methods defined by subsequent classes in the MRO list.
This class will add the logger attribute to each class that has the PointedCard protocol defined:
class Logged(PointedCard):
def __init__(self, *args, **kw):
self.logger = logging.getLogger(self.__class__.__name__)
super().__init__(*args, **kw)
def points(self):
p = super().points()
self.logger.debug("points {0}", p)
return p
Note that we've used super().__init__() to perform the __init__() method of any other classes defined. The order for these initializations comes from the class MRO. As we just noted, it's generally the simplest approach to have one class that defines the essential features of an object, and all other mixins add features to the essential object.
It's common to see the super().__init__() method called first. We've established the logger before performing other initializations so that mixin classes can depend on the presence of a logger prior to their initialization. This can help in debugging initialization problems.
We've provided a definition for points(). This will search other classes in the MRO list for an implementation of points(). Then it will log the results computed by the method from another class.
Here are some classes that include the Logged mixin features:
class LoggedCribbageAce(Logged, AceCard, CribbagePoints):
pass
class LoggedCribbageCard(Logged, Card, CribbagePoints):
pass
class LoggedCribbageFace(Logged, FaceCard, CribbageFacePoints):
pass
Each of these classes are built from three separate class definitions. Since the Logged class is provided first, we're assured that all classes have consistent logging. We're also assured that any method in Logged can use super() to locate an implementation in the class list that follows it in the sequence of classes in the definition.
To make use of these classes, we'd need to make one more small change to an application:
def make_logged_card(rank: int, suit: str) -> Card:
if rank == 1:
return LoggedCribbageAce(rank, suit)
if 2 <= rank < 11:
return LoggedCribbageCard(rank, suit)
if 11 <= rank:
return LoggedCribbageFace(rank, suit)
raise ValueError(f"Invalid rank {rank}")
We need to use this function instead of make_cribbage_card(). This function will use the set of class definitions that creates logged cards.
Here's how we use this function to build a deck of card instances:
deck = [make_logged_card(rank+1, suit)
for rank in range(13)
for suit in SUITS]
We've replaced make_card() with make_logged_card() when creating a deck. Once we do this, we now have detailed debugging information available from a number of classes in a consistent fashion.
See also
- The method resolution order is computed when the class is created. The algorithm used is called C3. More information is available at https://dl.acm.org/doi/10.1145/236337.236343. The process was originally developed for the Dylan language and is now also used by Python. The C3 algorithm assures that each parent class is searched exactly once. It also assures that the relative ordering of superclasses is preserved; subclasses will be searched before any of their parent classes are examined.
- When considering multiple inheritance, it's always essential to also consider whether or not a wrapper is a better design than a subclass. See the Choosing between inheritance and extension – the is-a question recipe.
Leveraging Python's duck typing
When a design involves inheritance, there is often a clear relationship from a superclass to one or more subclasses. In the Choosing between inheritance and extension – the is-a question recipe of this chapter, as well as the Extending a collection – a list that does statistics recipe in Chapter 7, Basics of Classes and Objects, we've looked at extensions that involve a proper subclass-superclass relationship.
In order to have classes that can be used in place of one another ("polymorphic" classes), some languages require a common superclass. In many cases, the common class doesn't have concrete implementations for all of the methods; it's called an abstract superclass.
Python doesn't require common superclasses. The standard library, however, does offer the abc module. This provides optional support creating abstract classes in cases where it can help to clarify the relationships among classes.
Instead of defining polymorphic classes with common superclasses, Python relies on duck typing to establish equivalence. This name comes from the quote:
"When I see a bird that walks like a duck and swims like a duck and quacks like a duck, I call that bird a duck."
In the case of Python class relationships, if two objects have the same methods, and the same attributes, these similarities have the same effect as having a common superclass. No formal definition of a common class is required.
This recipe will show how to exploit the concept of duck typing to create polymorphic classes. Instances of these classes can be used in place of each other, giving us more flexible designs.
Getting ready
In some cases, it can be awkward to define a superclass for a number of loosely related implementation choices. For example, if an application is spread across several modules, it might be challenging to factor out a common superclass and put this by itself in a separate module where it can be imported into other modules.
Instead of factoring out a common abstraction, it's sometimes easier to create two equivalent classes that will pass the "duck test"—the two classes have the same methods and attributes, therefore, they are effectively interchangeable, polymorphic classes. The alternative implementations can be used interchangeably.
How to do it...
We'll define a pair of classes to show how this works. These classes will both simulate rolling a pair of dice. We'll create two distinct implementations that have enough common features that they are interchangeable:
- Start with a class,
Dice1, with the required methods and attributes. In this example, we'll have one attribute,dice, that retains the result of the last roll, and one method,roll(), that changes the state of the dice:class Dice1: def __init__(self, seed=None) -> None: self._rng = random.Random(seed) self.roll() def roll(self) -> Tuple[int, ...]: self.dice = ( self._rng.randint(1, 6), self._rng.randint(1, 6)) return self.dice - Define another class,
Dice2, with the same methods and attributes. Here's a somewhat more complex definition that creates a class that has the same signature as theDice1class:class Die: def __init__(self, rng: random.Random) -> None: self._rng = rng def roll(self) -> int: return self._rng.randint(1, 6) class Dice2: def __init__(self, seed: Optional[int] = None) -> None: self._rng = random.Random(seed) self._dice = [Die(self._rng) for _ in range(2)] self.roll() def roll(self) -> Tuple[int, ...]: self.dice = tuple(d.roll() for d in self._dice) return self.dice
At this point, the two classes, Dice1 and Dice2, can be interchanged freely. Here's a function that accepts either class as an argument, creates an instance, and yields several rolls of the dice:
def roller(
dice_class: Type[Dice2],
seed: int = None,
*,
samples: int = 10
) -> Iterator[Tuple[int, ...]]:
dice = dice_class(seed)
for _ in range(samples):
yield dice.roll()
We can use this function with either the Dice1 class or Dice2 class. This interactive session shows the roller() function being applied to both classes:
>>> from Chapter_08.ch08_r03 import roller, Dice1, Dice2
>>> list(roller(Dice1, 1, samples=5))
[(1, 3), (1, 4), (4, 4), (6, 4), (2, 1)]
>>> list(roller(Dice2, 1, samples=5))
[(1, 3), (1, 4), (4, 4), (6, 4), (2, 1)]
The objects built from Dice1 and Dice2 have enough similarities that they're indistinguishable.
How it works...
We've created two classes with identical collections of attributes and methods. This is the essence of duck typing. Because of the way Python searches through a sequence of dictionaries for matching names, classes do not need to have a common superclass to be interchangeable.
This leads to two techniques for creating related families of classes:
- When several subclasses have a common superclass, any search that fails to find a name in a subclass will search the common superclass. This assures common behavior.
- When several classes have common method names, then they can be used in place of each other. This is not as strong a guarantee as having a common superclass, but careful design and unit testing can make sure the various kinds of classes are all interchangeable.
There's more...
When we look at the decimal module, we see an example of a numeric type that is distinct from all of the other numeric types. In order to make this work out well, the numbers module includes the concept of registering a class as a part of the Number class hierarchy. This process of registration makes a class usable as a number without relying on inheritance.
Previously, we noted that the search for a method of a class involves the concept of a descriptor. Internally, Python uses descriptor objects to create gettable and settable properties of an object. In some cases, we may want to leverage explicit descriptors to create classes that appear equivalent because they have the same methods and attributes.
A descriptor object must implement some combination of the special methods __get__, __set__, and __delete__. When the attribute appears in an expression (or in a call to the getattr() built-in function), then __get__ will be used to locate the value. When the attribute appears on the left side of an assignment (or in a call to the setattr() built-in function), then __set__ is used. In a del statement, (or in a call to the delattr() built-in function), the __delete__ method is used.
The descriptor object acts as an intermediary so that a simple attribute can be used in a variety of contexts. It's rare to use descriptors directly. We can use the @property decorator to build descriptors for us. This can be used to provide attribute names that are similar to other classes; they will pass the "duck test" and can be substituted for each other to create alternative implementations.
See also
- The duck type question is implicit in the Choosing between inheritance and extension – the is-a question recipe; if we leverage duck typing, we're also making a claim that two classes are not the same thing. When we bypass inheritance, we are implicitly claiming that the is-a relationship doesn't hold.
- When looking at the Separating concerns via multiple inheritance recipe, we're also able to leverage duck typing to create composite classes that may not have a simple inheritance hierarchy.
Managing global and singleton objects
The Python environment contains a number of implicit global objects. These objects provide a convenient way to work with a collection of other objects. Because the collection is implicit, we're saved from the annoyance of explicit initialization code.
One example of this is an implicit random number generating object that's part of the random module. When we evaluate random.random(), we're actually making use of an instance of the random.Random class that's an implicit part of the random module.
Other examples of this include the following:
- The collection of data encode/decode methods (
codecs) available. Thecodecsmodule lists the available encoders and decoders. This also involves an implicit registry. We can add encodings and decodings to this registry. - The
webbrowsermodule has a registry of known browsers. For the most part, the operating system default browser is the one preferred by the user and the right one to use, but it's possible for an application to launch a browser other than the user's preferred browser, as long as it's installed on the system. It's also possible to register a new browser that's unique to an application. - The logging module maintains a collection of named loggers. The
getLlogger()function tries to find an existing logger; it creates a new logger if needed.
This recipe will show to work with an implicit global object like the registries used for codecs, browsers, and logger instances.
Getting ready
A collection of functions can all work with an implicit, global object, created by a module. The benefit is to allow other modules to share the common object without having to write any code that explicitly coordinates between the modules by passing variables explicitly.
For a simple example, let's define a module with a global singleton object. We'll look more at modules in Chapter 13, Application Integration: Configuration.
Our global object will be a counter that we can use to accumulate centralized data from several independent modules or objects. We'll provide an interface to this object using a number of separate functions.
The goal is to be able to write something like this:
for row in source:
count('input')
some_processing()
print(counts())
This implies two functions that refer to a shared, global counter:
count(): It will increment the counter and return the current valuecounts(): It will provide all of the various counter values
How to do it...
There are two ways to handle global state information. One technique uses a module global variable because modules are singleton objects. The other uses a class-level variable (called static in some programming languages.) In Python, a class definition is a singleton object and can be shared without creating duplicates.
Global module variables
We can do the following to create a variable that is global to a module:
- Create a module file. This will be a
.pyfile with the definitions in it. We'll call itcounter.py. - If necessary, define a class for the global singleton. In our case, we can use this definition to create a
collections.Counterwith a type hint ofCounter:import collections from typing import List, Tuple, Any, Counter - Define the one and only instance of the global singleton object. We've used a leading
_in the name to make it slightly less visible. It's not—technically—private. It is, however, gracefully ignored by many Python tools and utilities:_global_counter: Counter[str] = collections.Counter() - Define the two functions to use the global object,
_global_counter. These functions encapsulate the detail of how the counter is implemented:def count(key: str, increment: int = 1) -> None: _global_counter[key] += increment def count_summary() -> List[Tuple[str, int]]: return _global_counter.most_common()
Now we can write applications that use the count() function in a variety of places. The counted events, however, are fully centralized in a single object, defined as part of the module.
We might have code that looks like this:
>>> from Chapter_08.ch08_r04 import *
>>> from Chapter_08.ch08_r03 import Dice1
>>> d = Dice1(1)
>>> for _ in range(1000):
... if sum(d.roll()) == 7: count('seven')
... else: count('other')
>>> print(count_summary())
[('other', 833), ('seven', 167)]
We've imported the count() and count_summary() functions from the ch08_r04 module. We've also imported the Dice1 object as a handy object that we can use to create a sequence of events. When we create an instance of Dice1, we provide an initialization to force a particular random seed. This gives repeatable results.
We can then use the object, d, to create random events. For this demonstration, we've categorized the events into two simple buckets, labeled seven and other. The count() function uses an implied global object.
When the simulation is done, we can dump the results using the count_summary() function. This will access the global object defined in the module.
The benefit of this technique is that several modules can all share the global object within the ch08_r04 module. All that's required is an import statement. No further coordination or overheads are necessary.
Class-level "static" variable
We can do the following to create a variable that is global to all instances of a class definition:
- Define a class and provide a variable outside the
__init__method. This variable is part of the class, not part of each individual instance. It's shared by all instances of the class. In this example, we've decided to use a leading_so the class-level variable is not seen as part of the public interface:import collections from typing import List, Tuple, Any, Counter class EventCounter: _class_counter: Counter[str] = collections.Counter() - Add methods to update and extract data from the class-level
_class_counterattribute:def count(self, key: str, increment: int = 1) -> None: EventCounter._class_counter[key] += increment def summary(self) -> List[Tuple[str, int]]: return EventCounter._class_counter.most_common()
It's very important to note that the _class_counter attribute is part of the class, and is referred to as EventCounterl._class_counter. We don't use the self instance variable because we aren't referring to an instance of the class, we're referring to a variable that's part of the overall class definition.
When we use self.name on the left side of the assignment, it may create an instance variable, local to the instance. Using EventCounter.name guarantees that a class-level variable is updated instead of creating an instance variable.
All of the augmented assignment statements, for example, +=, are implemented by an "in-place" special method name based on the operator. A statement like x += 1 is implemented by x.__iadd__(1). If the __iadd__() method is defined by the class of x, it must perform an in-place update. If the __iadd__() method returns the special NotImplemented value, the fall-back plan is to compute x.__add__(1) and then assign this to variable x. This means self.counter[key] += increment will tend to work for the large variety of Python collections that provide __iadd__() special methods.
Because explicit is better than implicit, it's generally a good practice to make sure class-level variables are explicitly part of the class namespace, not the instance namespace. While self._class_counter will work, it may not be clear to all readers that this is a class-level variable. Using EventCounter._class_counter is explicit.
The various application components can create objects, but the objects all share a common class-level value:
>>> from Chapter_08.ch08_r04 import *
>>> c1 = EventCounter()
>>> c1.count('input')
>>> c2 = EventCounter()
>>> c2.count('input')
>>> c3 = EventCounter()
>>> c3.counts()
[('input', 2)]
In this example, we've created three separate objects, c1, c2, and c3. Since all three share a common variable, defined in the EventCounter class, each can be used to increment that shared variable. These objects could be part of separate modules, separate classes, or separate functions, yet still share a common global state.
Clearly, shared global state must be used carefully. The examples cited at the beginning of this recipe mentioned codec registry, browser registry, and logger instances. These all work with shared global state. The documentation for how to use these registries needs to be explicitly clear on the presence of global state.
How it works...
The Python import mechanism uses sys.modules to track which modules are loaded. Once a module is in this mapping, it is not loaded again. This means that any variable defined within a module will be a singleton: there will only be one instance.
We have two ways to share these kinds of global singleton variables:
- Using the module name, explicitly. We could have created an instance of
Counterin the module and shared this viacounter.counter. This can work, but it exposes an implementation detail. - Using wrapper functions, as shown in this recipe. This requires a little more code, but it permits a change in implementation without breaking other parts of the application.
The defined functions provide a way to identify relevant features of the global variable while encapsulating details of how it's implemented. This gives us the freedom to consider changing the implementation details. As long as the wrapper functions have the same semantics, the implementation can be changed freely.
Since we can only provide one definition of a class, the Python import mechanism tends to assure us that the class definition is a proper singleton object. If we make the mistake of copying a class definition and pasting the definition into two or more modules used by a single application, we would not share a single global object among these class definitions. This is an easy mistake to avoid.
How can we choose between these two mechanisms? The choice is based on the degree of confusion created by having multiple classes sharing a global state. As shown in the previous example, three variables share a common Counter object. The presence of an implicitly shared global state can be confusing. A module-level global is often more clear.
There's more...
A shared global state can be called the opposite of object-oriented programming. One ideal of object-oriented programming is to encapsulate all state changes in individual objects. Used too broadly, global variables break the idea of encapsulation of state within a single object.
A common global state often arises when trying to define configuration parameters for an application. It can help to have a single, uniform configuration that's shared widely throughout multiple modules. When these objects are used for pervasive features such as configuration, audits, logging, and security, they can be helpful for segregating a cross-cutting concern into a generic class separate from application-specific classes.
An alternative is to create a configuration object explicitly and make it part of the application in some obvious way. For example, an application's startup can provide a configuration object as a parameter to other objects throughout the application.
See also
- Chapter 14, Application Integration: Combination, covers additional topics in module and application design.
Using more complex structures – maps of lists
In Chapter 4, Built-In Data Structures Part 1: Lists and Sets, we looked at the basic data structures available in Python. The recipes generally looked at the various structures in isolation.
We'll look at a common combination structure—the mapping from a single key to a list of related values. This can be used to accumulate detailed information about an object identified by a given key. This recipe will transform a flat list of details into details structurally organized by shared key values.
Getting ready
In order to create a more complex data structure, like a map that contains lists, we're going to need more complex data. To get ready, we're going to start with some raw log data, decompose it into individual fields, and then create individual Event objects from the fields of data. We can then reorganize and regroup the Event objects into lists associated with common attribute values.
We'll start with an imaginary web log that's been transformed from the raw web format to the comma-separated value (CSV) format. This kind of transformation is often done with a regular expression that picks out the various syntactic groups. See the String parsing with regular expressions recipe in Chapter 1, Numbers, Strings, and Tuples, for information on how the parsing might work.
The raw data looks like the following:
[2016-04-24 11:05:01,462] INFO in module1: Sample Message One
[2016-04-24 11:06:02,624] DEBUG in module2: Debugging
[2016-04-24 11:07:03,246] WARNING in module1: Something might have gone wrong
Each line in the file has a timestamp, a severity level, a module name, and some text. We need to decompose the text into four separate fields. We can then define a class of Event objects and collections of Event instances.
Each row can be parsed into the component fields with a regular expression. We can create a single NamedTuple class that has a special static method, from_line(), to create instances of the class using these four fields. Because the attribute names match the regular expression group names, we can build instances of the class using the following definition:
class Event(NamedTuple):
timestamp: str
level: str
module: str
message: str
@staticmethod
def from_line(line: str) -> Optional['Event']:
pattern = re.compile(
r"[(?P<timestamp>.*?)]s+"
r"(?P<level>w+)s+"
r"ins+(?P<module>w+)"
r":s+(?P<message>w+)"
)
if log_line := pattern.match(line):
return Event(
**cast(re.Match, log_line).groupdict()
)
return None
The attributes of the Event subclass of the NamedTuple class are the fields from the log entry: a timestamp, a severity level, the module producing the message, and the body of the message. We've made sure the regular expression group names match the attribute names.
We've used the "walrus" operator in the if statement to assign the log_line variable and also check to see if the variable has a non-None value. This lets us work with the match.groupdict() dictionary. The cast() function is required to help the current release of mypy understand that the log_line variable will have a non-None value in the body of the if clause.
We can simulate applying the from_line() method to each line of a file with some test data. At the Python prompt, it looks like the following example:
>>> Event.from_line(
... "[2016-04-24 11:05:01,462] INFO in module1: Sample Message One")
Event(timestamp='2016-04-24 11:05:01,462', level='INFO', module='module1', message='Sample Message One')
Our objective is to see messages grouped by the module name attribute, like this:
'module1': [
('2016-04-24 11:05:01,462', 'INFO', 'module1', 'Sample Message One'),
('2016-04-24 11:07:03,246', 'WARNING', 'module1', 'Something might have gone wrong')
]
'module2': [
('2016-04-24 11:06:02,624', 'DEBUG', 'module2', 'Debugging')
]
We'd like to examine the source log file, creating a list of all the messages organized by module, instead of sequentially through time. This kind of restructuring can make analysis simpler.
How to do it...
In order to create a mapping that includes list objects, we'll need to start with some core definition. Then we can write a summize() function to restructure the log data as follows:
- Import the required
collectionsmodule and some type hints for various kinds of collections:import re from typing import List, DefaultDict, cast, NamedTuple, Optional, Iterable - Define the source data type, an
Event NamedTuple. This class definition was shown above, in the Getting ready section. - Define an overall type hint for the summary dictionary we'll be working with:
Summary = DefaultDict[str, List[Event]] - Start the definition of a function to summarize an iterable source of the
Eventinstances, and produce aSummaryobject:def summarize(data: Iterable[Event]) -> Summary: - Use the
listfunction as the default value for adefaultdict. It's also helpful to create a type hint for this collection:module_details: Summary = collections.defaultdict(list) - Iterate through the data, appending to the list associated with each key. The
defaultdictobject will use thelist()function to build an empty list as the value corresponding to each new key the first time each key is encountered:for event in data: module_details[event.module].append(event) return module_details
The result of this will be a dictionary that maps from a module name string to a list of all log rows for that module name. The data will look like the following:
{'module1': [
Event(timestamp='2016-04-24 11:05:01,462', level='INFO', module='module1', message='Sample'),
Event(timestamp='2016-04-24 11:07:03,246', level='WARNING', module='module1', message='Something')],
'module2': [
Event(timestamp='2016-04-24 11:06:02,624', level='DEBUG', module='module2', message='Debugging')]
}
The key for this mapping is the module name and the value in the mapping is the list of rows for that module name. We can now focus the analysis on a specific module.
How it works...
There are two choices for how a mapping behaves when a key that we're trying to access in that mapping is not found:
- The built-in
dictclass raises an exception when a key is missing. This makes it difficult to accumulate values associated with keys that aren't known in advance. - The
defaultdictclass evaluates a function that creates a default value when a key is missing. In many cases, the function isintorfloatto create a default numeric value. In this case, the function islistto create an empty list.
We can imagine using the set function to create an empty set object for a missing key. This would be suitable for a mapping from a key to a set of objects that share that key.
There's more...
We can also build a version of this as an extension to the built-in dict class:
class ModuleEvents(dict):
def add_event(self, event: Event) -> None:
if event.module not in self:
self[event.module] = list()
self[event.module].append(event)
We've defined a method that's unique to this class, add_event(). This will add the empty list if the key, the module name in event[2], is not currently present in the dictionary. After the if statement, a postcondition could be added to assert that the key is now in the dictionary.
We've used the list() function to create an empty list. This can be extended to create other empty collection types by using the class name. Using the empty [] has to be replaced with set() to replace a list with a set, a change that can be a little less clear than replacing list() with set(). Also, the class name here parallels the way the class name is used by the collections.defaultdict() function.
This allows us to use code such as the following:
>>> module_details = ModuleEvents()
>>> for event in event_iter:
... module_details.add_event(event)
The resulting structure is very similar to defaultdict.
See also
- In the Creating dictionaries – inserting and updating recipe in Chapter 4, Built-In Data Structures Part 1: Lists and Sets, we looked at the basics of using a mapping.
- In the Avoiding mutable default values for function parameters recipe of Chapter 4, Built-In Data Structures Part 1: Lists and Sets, we looked at other places where default values are used.
- In the Using more sophisticated collections recipe of Chapter 7, Basics of Classes and Objects, we looked at other examples of using the
defaultdictclass.
Creating a class that has orderable objects
We often need objects that can be sorted into order. Log records are often ordered by date and time. When simulating card games, it's often essential to be able to sort the Card objects into a defined order. When cards form a sequence, sometimes called a straight, this can be an important way to score points. This is part of games such as Poker, Cribbage, and Pinochle.
Most of our class definitions have not included the features necessary for sorting objects into order. Many of the recipes have kept objects in mappings or sets based on the internal hash value computed by the __hash__() method, and an equality test defined by the __eq__() method.
In order to keep items in a sorted collection, we'll need the comparison methods that implement <, >, <=, and >=. These are in addition to == and !=. These comparisons are all based on the attribute values of each object and are distinct for every class we might define.
Getting ready
The game of Pinochle generally involves a deck with 48 cards. There are 6 ranks—9, 10, Jack, Queen, King, and ace—organized in the standard four suits. Each of these 24 kinds of cards appears twice in the deck. We have to be careful to avoid a structure such as a dict or set collection because cards are not unique in Pinochle; duplicates in a hand are very likely.
In the Separating concerns via multiple inheritance recipe, we defined playing cards using two class definitions. The Card class hierarchy defined essential features of each card. A second set of mixin classes provided game-specific features for each card.
We'll need to add features to those cards to create objects that can be ordered properly. Here are the first two elements of the design:
from Chapter_08.ch08_r02 import AceCard, Card, FaceCard, SUITS, PointedCard
class PinochlePoints(PointedCard):
def points(self: PointedCard) -> int:
_points = {9: 0, 10: 10, 11: 2, 12: 3, 13: 4, 14: 11}
return _points[self.rank]
We've imported the existing Card hierarchy. We've also defined a rule for computing the points for each card taken in a trick during play, the PinochlePoints class. This has a mapping from card ranks to the potentially confusing points for each card.
A 10 is worth 10 points, and an ace is worth 11 points, but the King, Jack, and Queen are worth four, three, and two points respectively. The nine is worthless. This can be confusing for new players.
Because an ace ranks above a King for purposes of identifying a straight, we've made the rank of the ace 14. This slightly simplifies the processing.
In order to use a sorted collection of cards, we need to add yet another feature to the card class definitions. We'll need to define the comparison operations. There are four special methods used for object ordering comparison. These require some additional type hints to make them applicable to other objects.
How to do it...
To create an orderable class definition, we'll create a comparison protocol, and then define a class that implements the protocol, as follows:
- We're defining a new protocol for
mypyto be used when comparing objects. This formal protocol definition describes what kinds of objects the mixin will apply to. We've called itCardLikebecause it applies to any kind of class with at least the two attributes ofrankandsuit:class CardLike(Protocol): rank: int suit: str - Using this protocol, we can create the
SortedCardsubclass for the comparison features. This subclass can be mixed into any class that fits the protocol definition:class SortedCard(CardLike): - Add the four order comparison methods to the
SortedCardsubclass. In this case, we've converted the relevant attributes of any class that fits theCardLikeprotocol into a tuple and relied on Python's built-in tuple comparison to handle the details of comparing the items in the tuple in order, starting with rank. Here are the methods:def __lt__(self: CardLike, other: Any) -> bool: return (self.rank, self.suit) < (other.rank, other.suit) def __le__(self: CardLike, other: Any) -> bool: return (self.rank, self.suit) <= (other.rank, other.suit) def __gt__(self: CardLike, other: Any) -> bool: return (self.rank, self.suit) > (other.rank, other.suit) def __ge__(self: CardLike, other: Any) -> bool: return (self.rank, self.suit) >= (other.rank, other.suit) - Write the composite class definitions, built from an essential
Cardclass and two mixin classes to provide the Pinochle and comparison features:class PinochleAce(AceCard, SortedCard, PinochlePoints): pass class PinochleFace(FaceCard, SortedCard, PinochlePoints): pass class PinochleNumber(Card, SortedCard, PinochlePoints): pass - There's no simple superclass for this hierarchy of classes. To an extent, we can consider these all as subclasses of the
Cardclass. When we look at all the features that were added, theCardclass could be misleading to any person reading our code. We'll add a type hint to create a common definition for these three classes:PinochleCard = Union[PinochleAce, PinochleFace, PinochleNumber] - Now we can create a function that will create individual card objects from the classes defined previously:
def make_card(rank: int, suit: str) -> PinochleCard: if rank in (9, 10): return PinochleNumber(rank, suit) elif rank in (11, 12, 13): return PinochleFace(rank, suit) else: return PinochleAce(rank, suit)
Even though the point rules are dauntingly complex, the complexity is hidden in the PinochlePoints class. Building composite classes as a base subclass of Card plus PinochlePoints leads to an accurate model of the cards without too much overt complexity.
We can now make cards that respond to comparison operators, using the following sequence of interactive commands:
>>> from Chapter_08.ch08_r06 import make_card
>>> c1 = make_card(9, '')
>>> c2 = make_card(10, '')
>>> c1 < c2
True
>>> c1 == c1
True
>>> c1 == c2
False
>>> c1 > c2
False
The equality comparisons to implement == and != are defined in the base class, Card. This is a frozen dataclass. We didn't need to implement these methods. By default, dataclasses contain equality test methods.
Here's a function that builds the 48-card deck by creating two copies of each of the 24 different rank and suit combinations:
def make_deck() -> List[PinochleCard]:
return [
make_card(r, s)
for _ in range(2)
for r in range(9, 15)
for s in SUITS]
The value of the SUITS variable is one of the four Unicode characters for the suits. The generator expression inside the make_deck() function builds two copies of each card using the 6 ranks from 9 to the special rank of 14 for the ace, and four characters in the SUITS variable.
How it works...
Python uses special methods for a vast number of things. Almost every visible behavior in the language is due to some special method name. In this recipe, we've leveraged the four ordering operators.
When we write the following expression:
c1 <= c2
The preceding code is evaluated as if we'd written c1.__le__(c2). This kind of transformation happens for all of the expression operators. By defining the comparison special methods, including the __le__() method, in our classes, we make these comparison operators work for us.
Careful study of Section 3.3 of the Python Language Reference shows that the special methods can be organized into several distinct groups:
- Basic customization
- Customizing attribute access
- Customizing class creation
- Customizing instance and subclass checks
- Emulating callable objects
- Emulating container types
- Emulating numeric types
withstatement context managers
In this recipe, we've looked at only the first of these categories. The others follow some similar design patterns.
Here's how it looks when we work with instances of this class hierarchy. The first example will create a 48-card Pinochle deck:
>>> from Chapter_08.ch08_r06 import make_deck
>>> deck = make_deck()
>>> len(deck)
48
If we look at the first eight cards, we can see how they're built from all the combinations of rank and suit:
>>> [str(c) for c in deck[:8]]
[' 9 ', ' 9 ', ' 9 ', ' 9  ', '10 ', '10 ', '10 ', '10 ']
', '10 ', '10 ', '10 ', '10 ']
If we look at the second half of the unshuffled deck, we can see that it has the same cards as the first half of the deck:
>>> [str(c) for c in deck[24:32]]
[' 9  ', ' 9 ', ' 9 ', ' 9 ', '10 ', '10 ', '10 ', '10 ']
', ' 9 ', ' 9 ', ' 9 ', '10 ', '10 ', '10 ', '10 ']
Since the deck variable is a simple list, we can shuffle the list object and pick a dozen cards:
>>> import random
>>> random.seed(4)
>>> random.shuffle(deck)
>>> [str(c) for c in sorted(deck[:12])]
[' 9  ', '10 ', ' J
', '10 ', ' J  ', ' J ', ' J ', ' Q
', ' J ', ' J ', ' Q  ', ' Q ', ' K ', ' K ', ' K ', ' A ', ' A ']
', ' Q ', ' K ', ' K ', ' K ', ' A ', ' A ']
The important part is the use of the sorted() function. Because we've defined proper comparison operators, we can sort the Card instances, and they are presented in the expected order from low rank to high rank. Interestingly, this set of cards has Q ![]() and
and J ![]() , the combination called a Pinochle.
, the combination called a Pinochle.
There's more...
A little formal logic suggests that we really only need to implement two of the comparisons in detail. From an equality method and an ordering method, all the remaining methods can be built. For example, if we build the operations for less than (__lt__()) and equal to (__eq__()), we could compute the missing three following these equivalence rules:
Python emphatically does not do any of this kind of advanced algebra for us. We need to do the algebra carefully and implement the necessary comparison methods.
The functools library includes a decorator, @total_ordering, that can generate these missing comparison methods. As of the writing of this chapter, issue 4610 in the mypy project is still open, and the type hint analysis is not quite correct. See https://github.com/python/mypy/issues/4610 for details.
The comparison special methods all have a form similar to __lt__(self, other: Any) -> bool. The other parameter has a type hint of Any. Because this is part of the CardLike protocol, mypy narrows the meaning of other to other objects of the same protocol. This allows us to assume each CardLike object is compared against another CardLike object with the expected rank attribute.
The use of the Any type hint is very broad and permits some code that doesn't really work. Try this:
>>> c1 = make_card(9, '')
>>> c1 <= 10
This raises an AttributeError exception because the integer object 10 doesn't have a rank. This is the expected behavior; if we want to compare only the rank of a card, we should always be explicit and use c1.rank <= 10.
An implicit comparison between the rank of the CardLike object and an integer is possible. We can extend or modify the comparison special methods to handle two kinds of comparisons:
CardLikeagainstCardLike, using the existing comparison implementationCardLikeagainstint, which will require some additional code
Comparing a CardLike object against an integer is done by using the isinstance() function to discriminate between the actual argument types.
Each of our comparison methods could be changed to look like this:
def __lt__(self: CardLike, other: Any) -> bool:
if isinstance(other, int):
return self.rank < other
return (self.rank, self.suit) < (other.rank, other.suit)
This isn't the only change that's required for comparison against integers. The base class, Card, is a dataclass and introduced the __eq__() and __ne__() equality tests. These methods are not aware of the possibility of integer comparisons and would need to be modified, also. The complexity of these changes, and the implicit behavior, suggest we should avoid going down this path.
See also
- See the Defining an ordered collection recipe, which relies on sorting these cards into order.
Improving performance with an ordered collection
When simulating card games, the player's hand can be modeled as a set of cards or a list of cards. With most conventional single-deck games, a set collection works out nicely because there's only one instance of any given card, and the set class can do very fast operations to confirm whether a given card is or is not in the set.
When modeling Pinochle, however, we have a challenging problem. The Pinochle deck is 48 cards; it has two each of the 9, 10, Jack, Queen, King, and ace cards. A simple set object won't work well when duplicates are possible; we would need a multiset or bag. A multiset is a set-like collection that permits duplicate items.
In a multiset, a membership test becomes a bit more complex. For example, we can add the Card(9,'![]()
') object to a bag collection more than once, and then also remove it more than one time.
We have a number of ways to create a multiset:
- We can base a multiset collection on the built-in
listcollection. Appending an item to alisthas a nearly fixed cost, characterized as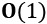 . The complexity of testing for membership tends to grow with the size of the collection, n; it is characterized as
. The complexity of testing for membership tends to grow with the size of the collection, n; it is characterized as  . This search cost makes a
. This search cost makes a listundesirable. - We can base a multiset on the built-in
dictcollection. The value can be an integer count of the number of times a duplicated element shows up. Dictionary operations are on average characterized as. (The amortized worst case is , but worst cases are a rarity.) While this can seem ideal, it limits us to immutable items that are hashable. We have three ways of implementing this extension to the built-in dictclass:- Define our own subclass of the
dictclass with methods to count duplicate entries. This requires overriding a number of special methods. - Use a
defaultdict. See the Using more complex structures – maps of lists recipe, which usesdefaultdict(list)to create a list of values for each key. Thelen()of eachlistis the number of times the key occurred. This can become rather complex when cards are added and removed from the multiset, leaving keys with zero-length lists. - Use
Counter. We've looked atCounterin a number of recipes. See the Avoiding mutable default values for function parameters recipe in Chapter 4, Built-In Data Structures Part 1: Lists and Sets, the Designing classes with lots of processing and Using properties for lazy attributes recipes in Chapter 7, Basics of Classes and Objects, and the Managing global and singleton objects recipe of this chapter for other examples.
- Define our own subclass of the
- We can base our multiset implementation on a sorted
list. Maintaining the items in order means inserting an item will be slightly more expensive than inserting into a list. The complexity varies with the length of the list but grows more slowly. It is characterized as . Searching, however, is less expensive than an unsorted list; it's
. Searching, however, is less expensive than an unsorted list; it's  . The
. The bisectmodule provides functions that help us maintain a sorted list.
In this recipe, we will build a sorted collection of objects, and a multiset or bag using a sorted collection.
Getting ready
In the Creating a class that has orderable objects recipe, we defined cards that could be sorted. This is essential for using bisect. The algorithms in this module require a full set of comparisons among objects.
We'll define a multiset to keep 12-card Pinochle hands. Because of the duplication, there will be more than one card of a given rank and suit.
In order to view a hand as a kind of set, we'll also need to define some set operators on hand objects. The idea is to define set membership and subset operators.
We'd like to have Python code that's equivalent to the following:

That means for a given card, c, and a hand of cards, ![]() , whether or not the given card is in the hand. We'd like this to be faster than a search through each individual card.
, whether or not the given card is in the hand. We'd like this to be faster than a search through each individual card.
We'd also like code equivalent to this:
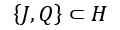
This is for a specific pair of cards, called the Pinochle, and a hand of cards, H; we want to know if the pair of cards is a proper subset of the cards in the hand. We'd like this to be faster than two searches through all the cards of the hand.
We'll need to import two things:
from Chapter_08.ch08_r06 import make_deck, make_card
import bisect
The first import brings in our orderable card definitions from the Creating a class that has orderable objects recipe. The second import brings in the various bisect functions that we'll use to maintain an ordered set with duplicates.
How to do it...
We'll define a Hand collection that maintains Card items in order, as follows:
- Define the
Handclass with an initialization that can load the collection from any iterable source of data. We can use this to build aHandfrom a list or possibly a generator expression. If the list is non-empty, we'll need to sort the items into order. Thesort()method of theself.cardslist will rely on the comparison operators implemented by theCardobjects. (Technically, we only care about objects that are subclasses ofSortedCard, since that is where the comparison methods are defined.):class Hand: def __init__(self, card_iter: Iterable[Card]) -> None: self.cards = list(card_iter) self.cards.sort() - Define an
add()method to add cards to a hand. We'll use thebisectmodule to assure that the card is properly inserted in the correct position in theself.cardslist:def add(self, aCard: Card) -> None: bisect.insort(self.cards, aCard) - Define an
index()method to find the position of a given card instance in aHandcollection. We'll use thebisectmodule for locating a given card. The additionaliftest is recommended in the documentation forbisect.bisect_left()to properly handle an edge case in the processing:def index(self, aCard: Card) -> int: i = bisect.bisect_left(self.cards, aCard) if i != len(self.cards) and self.cards[i] == aCard: return i raise ValueError - Define the
__contains__()special method to implement theinoperator. When we write the expressioncard in some_handin Python, it's evaluated as if we had writtensome_hand.__contains__(card). We've used theindex()method to either find the card or raise an exception. The exception is transformed into a return value ofFalse:def __contains__(self, aCard: Card) -> bool: try: self.index(aCard) return True except ValueError: return False - Define an iterator over the items in a
Handcollection. This is a delegation to theself.cardscollection. When we write the expressioniter(some_hand)in Python, it's evaluated as if we had writtensome_hand.__iter__(). While we could also use theyield fromstatement, it seems a little misleading to useyield fromoutside the context of a recursive function; we'll delegate the__iter__()request to aniter()function in a direct and hopefully obvious way:def __iter__(self) -> Iterator[Card]: return iter(self.cards) - Define a subset operation between two
Handinstances:def __le__(self, other: Any) -> bool: for card in self: if card not in other: return False return True
Python doesn't have the ![]() or
or ![]() symbols, so the
symbols, so the < and <= operators are conventionally pressed into service for comparing sets. When we write pinochle <= some_hand to see if the hand contains a specific combination of cards, it's evaluated as if we'd written pinochle.__le__(some_hand).
The in operator is implemented by the __contains__() method. This shows how the Python operator syntax is implemented by the special methods.
We can use this Hand class like this:
>>> from Chapter_08.ch08_r06 import make_deck, make_card
>>> from Chapter_08.ch08_r07 import Hand
>>> import random
>>> random.seed(4)
>>> deck = make_deck()
>>> random.shuffle(deck)
>> h = Hand(deck[:12])
>>> [str(c) for c in h.cards]
[' 9  ', '10 ', ' J ', ' J
', '10 ', ' J ', ' J  ', ' J ', ' Q ', ' Q ', ' K ', ' K ', ' K ', ' A
', ' J ', ' Q ', ' Q ', ' K ', ' K ', ' K ', ' A  ', ' A ']
', ' A ']
The cards are properly sorted in the Hand collection. This is a consequence of the way the Hand instance was created; cards were put into order by the collection.
Here's an example of using the subset operator, <=, to compare a specific pattern to the hand as a whole. In this case, the pattern is a pair of cards called the pinochle, a Jack of diamonds and a Queen of spades. First, we'll build a small tuple of two Card instances, then we can use the operator we've defined for comparing two collections of Card objects, as shown in this example:
>>> pinochle = Hand([make_card(11,''), make_card(12,'')])
>>> pinochle <= h
True
Because a Hand is a collection, it supports iteration. We can use generator expressions that reference the Card objects within the overall Hand object, h:
>>> sum(c.points() for c in h)
56
How it works...
Our Hand collection works by wrapping an internal list object and applying an important constraint to that object. The items are kept in sorted order. This increases the cost of inserting a new item but reduces the cost of searching for an item.
The core algorithms for locating the position of an item are from the bisect module, saving us from having to write (and debug) them. The algorithms aren't really very complex. But it is more efficient to leverage existing code.
The module's name comes from the idea of bisecting the sorted list to look for an item. The essence is shown in this snippet of code:
while lo < hi:
mid = (lo + hi)//2
if x < a[mid]: hi = mid
else: lo = mid+1
This code searches a list, a, for a given value, x. The value of lo is initially zero and the value of hi is initially the size of the list, len(a).
First, the midpoint index, mid, is computed. If the target value, x, is less than the value at the midpoint of the list, a[mid], then it must be in the first half of the list: the value of hi is shifted so that only the first half is considered.
If the target value, x, is greater than or equal to the midpoint value, a[mid], then x must be in the second half of the list: the value of lo is shifted so that only the second half is considered.
Since the list is chopped in half at each operation, it requires ![]() steps before the values of
steps before the values of lo and hi converge on the position that should have the target value. If the item is not present, the lo and hi values will converge on a non-matching item. The documentation for the bisect module suggests using bisect_left() to consistently locate either the target item or an item less than the target, allowing an insert operation to put the new item into the correct position.
If we have a hand with 12 cards, then the first comparison discards 6. The next comparison discards 3 more. The next comparison discards 1 of the final 3. The fourth comparison will locate the position the card should occupy.
If we use an ordinary list, with cards stored in the random order of arrival, then finding a card will take an average of 6 comparisons. The worst possible case means it's the last of 12 cards, requiring all 12 to be examined.
With bisect, the number of comparisons is always ![]() . This means that each time the list doubles in size, only one more operation is required to search the items.
. This means that each time the list doubles in size, only one more operation is required to search the items.
There's more...
The collections.abc module defines abstract base classes for various collections. If we want our Hand to behave more like other kinds of sets, we can leverage these definitions.
We can add numerous set operators to this class definition to make it behave more like the built-in MutableSet abstract class definition.
A MutableSet is an extension to Set. The Set class is a composite built from three class definitions: Sized, Iterable, and Container. Because the Set class is built from three sets of features, it must define the following methods:
__contains__()__iter__()__len__()add()discard()
We'll also need to provide some other methods that are part of being a mutable set:
clear(),pop(): These will remove items from the setremove(): Unlikediscard(), this will raise an exception when attempting to remove a missing item
In order to have unique set-like features, it also needs a number of additional methods. We provided an example of a subset, based on __le__(). We also need to provide the following subset comparisons:
__le__()__lt__()__eq__()__ne__()__gt__()__ge__()isdisjoint()
These are generally not trivial one-line definitions. In order to implement the core set of comparisons, we'll often write two and then use logic to build the remainder based on those two.
In order to do set operations, we'll need to also provide the following special methods:
__and__()and__iand__(). These methods implement the Python&operator and the&=assignment statement. Between two sets, this is a set intersection or .
.__or__()and__ior__(). These methods implement the Python|operator and the|=assignment statement. Between two sets, this is a set union or .
.__sub__()and__isub__(). These methods implement the Python-operator and the-=assignment statement. Between sets, this is the set difference, often written as .
.__xor__()and__ixor__(). These methods implement the Python^operator and the^=assignment statement. When applied between two sets, this is the symmetric difference, often written as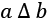 .
.
The abstract class permits two versions of each operator. There are two cases:
- If we provide
__iand__(), for example, then the statementA &= Bwill be evaluated asA.__iand__(B). This might permit an efficient implementation. - If we do not provide
__iand__(), then the statementA &= Bwill be evaluated asA = A.__and__(B). This might be somewhat less efficient because we'll create a new object. The new object is given the labelA, and the old object will be removed from memory.
There are almost two dozen methods that would be required to provide a proper replacement for the built-in Set class. On one hand, it's a lot of code. On the other hand, Python lets us extend the built-in classes in a way that's transparent and uses the same operators with the same semantics as the existing classes.
See also
- See the Creating a class that has orderable objects recipe for the companion recipe that defines Pinochle cards.
Deleting from a list of complicated objects
Removing items from a list has an interesting consequence. Specifically, when item list[x] is removed, all the subsequent items move forward. The rule is this:
Items list[y+1] take the place of items list[y] for all valid values of ![]() .
.
This is a side-effect that happens in addition to removing the selected item. Because things can move around in a list, it makes deleting more than one item at a time potentially challenging.
When the list contains items that have a definition for the __eq__() special method, then the list remove() method can remove each item. When the list items don't have a simple __eq__() test, then it becomes more challenging to remove multiple items from the list.
We'll look at ways to delete multiple items from a list when they are complicated objects like instances of the built-in dict collection or of a NamedTuple or dataclass.
Getting ready
In order to create a more complex data structure, like a list that contains dictionaries, we're going to need more complex data. In order to get ready, we're going to start with a database-like structure, a list of dictionaries.
After creating the list of dictionaries, we'll look at the problem with a naïve approach to removing items. It's helpful to see what can go wrong with trying repeatedly to search a list for an item to delete.
In this case, we've got some data that includes a song name, the writers, and a duration. The dictionary objects are rather long. The data looks like this:
>>> song_list = [
... {'title': 'Eruption', 'writer': ['Emerson'], 'time': '2:43'},
... {'title': 'Stones of Years', 'writer': ['Emerson', 'Lake'], 'time': '3:43'},
... {'title': 'Iconoclast', 'writer': ['Emerson'], 'time': '1:16'},
... {'title': 'Mass', 'writer': ['Emerson', 'Lake'], 'time': '3:09'},
... {'title': 'Manticore', 'writer': ['Emerson'], 'time': '1:49'},
... {'title': 'Battlefield', 'writer': ['Lake'], 'time': '3:57'},
... {'title': 'Aquatarkus', 'writer': ['Emerson'], 'time': '3:54'}
... ]
The type hint for each row of this complex structure can be defined with the typing.TypedDict hint. The definition looks like the following:
from typing import TypedDict, List
SongType = TypedDict(
'SongType',
{'title': str, 'writer': List[str], 'time': str}
)
The list of songs as a whole can be described as List[SongType].
We can traverse the list of dictionary objects with the for statement. The following snippet shows the items we'd like to remove:
>>> for item in song_list:
... if 'Lake' in item['writer']:
... print("remove", item['title'])
remove Stones of Years
remove Mass
remove Battlefield
To properly delete items from a list, we must work with index positions in the list. Here's a naïve approach that emphatically does not work:
def naive_delete(data: List[SongType], writer: str) -> None:
for index in range(len(data)):
if 'Lake' in data[index]['writer']:
del data[index]
The idea is to compute the index positions of the writers we'd like to remove. This fails with an index error as shown in the following output:
>>> naive_delete(song_list, 'Lake')
Traceback (most recent call last):
File "/Applications/PyCharm CE.app/Contents/plugins/python-ce/helpers/pycharm/docrunner.py", line 138, in __run
exec(compile(example.source, filename, "single",
File "<doctest ch07_r08.__test__.test_naive_delete[2]>", line 1, in <module>
naive_delete(song_list, 'Lake')
File "Chapter_08/ch08_r08.py", line 72, in naive_delete if 'Lake' in data[index]['writer']:
IndexError: list index out of range
We can't use range(len(data)) in a for statement because the range object's limits are fixed to the original size of the list. As items are removed, the list gets smaller, but the upper bound on the range object doesn't change. The value of the index will eventually be set to a value that's too large.
Here's another approach that doesn't work. When removing items with a direct equality test, we could try to use something like this:
while x in list:
list.remove(x)
The problem here is the List[SongType] collection we're using doesn't have an implementation of __contains__() to identify an item with Lake in the item['writer'] collection. We don't have a simple test usable by the remove() method.
If we want to use the list remove() method, we could consider creating a subclass of dict that implements __eq__() as a comparison against the string parameter value in self['writer']. This may violate the semantics of dictionary equality in general because it only checks for membership in a single field, something that might be a problem elsewhere in an application. We'll suggest that this is a potentially bad idea and abandon using remove().
To parallel the basic while in...remove loop, we could define a function to find the index of an item we'd like to remove from the list:
def index_of_writer(data: List[SongType], writer: str) -> Optional[int]:
for i in range(len(data)):
if writer in data[i]['writer']:
return i
This index_of_writer() function will either return the index of an item to delete, or it will return None because there are no items to be deleted:
def multi_search_delete(data: List[SongType], writer: str) -> None:
while (position := index_of_writer(data, 'Lake')) is not None:
del data[position] # or data.pop(position)
More importantly, this approach is wildly inefficient. Consider what happens when a target value occurs x times in a list of n items. There will be x trips through this loop. Each trip through the loop examines an average of ![]() trips through the list. The worst case is that all items need to be removed, leading to
trips through the list. The worst case is that all items need to be removed, leading to ![]() processing iterations. For a large data collection, this can be a terrible cost. We can do better.
processing iterations. For a large data collection, this can be a terrible cost. We can do better.
How to do it...
To efficiently delete multiple items from a list, we'll need to implement our own list index processing as follows:
- Define a function to update a
listobject by removing selected items:def incremental_delete( data: List[SongType], writer: str) -> None: - Initialize an index value,
i, to zero to begin with the first item in the list:i = 0 - While the value for the
ivariable is not equal to the length of the list, we want to make a state change to either increment theivariable or shrink the list:while i != len(data): - The decision is written as an
ifstatement. If thedata[i]dictionary is a target, we can remove it, shrinking the list:if 'Lake' in data[i]['writer']: del data[i] - Otherwise, if the
data[i]dictionary is not a target, we can increment the index value,i, one step closer to the length of the list. The post-condition for thisifstatement guarantees that we'll get closer to the termination condition ofi == len(data):else: i += 1
This leads to the expected behavior of removing the items from the list without suffering from index errors or making multiple passes through the list items. The rows with 'Lake' are removed from the collection, the remaining rows are left intact, and no index errors are raised, nor are items skipped.
This makes exactly one pass through the data removing the requested items without raising index errors or skipping items that should have been deleted.
How it works...
The goal is to examine each item exactly once and either remove it or step over it. The loop design reflects the way that Python list item removal works. When an item is removed, all of the subsequent items are shuffled forward in the list.
A naïve process to update a list will often have one or both of the following problems:
- Items will be skipped when they have shifted forward after a deletion. This is common when using a naïve
forloop with arange()object. It will always increment, skipping items after a deletion. - The index can go beyond the end of the list structure after items are removed because
len()was used once to get the original size and create arange()object.
Because of these two problems, the design of the invariant condition in the body of the loop is important. This reflects the two possible state changes:
- If an item is removed, the index must not change. The list itself will change.
- If an item is preserved, the index must change.
We can argue that the incremental_delete() function defined earlier makes one trip through the data, and has a complexity that can be summarized as ![]() . What's not considered in this summary is the relative cost of each deletion. Deleting an item from a list means that each remaining item is shuffled forward one position. The cost of each deletion is effectively
. What's not considered in this summary is the relative cost of each deletion. Deleting an item from a list means that each remaining item is shuffled forward one position. The cost of each deletion is effectively ![]() . Therefore, the complexity is more like
. Therefore, the complexity is more like ![]() , where x items are removed from a list of n items.
, where x items are removed from a list of n items.
While removing items from a mutable list is appealing and simple, it's rarely the ideal solution. Technically, ![]() is equivalent to
is equivalent to ![]() , which reveals the potential cost of large operations. In many cases, we might want to use a mapping for complex updates.
, which reveals the potential cost of large operations. In many cases, we might want to use a mapping for complex updates.
There's more...
An alternative is to create a new list with some items rejected. Making a shallow copy of items is much faster than removing items from a list, but uses more storage. This is a common time versus memory trade-off.
We can use a list comprehension like the following one to create a new list of selected items:
[
item
for item in data
if writer not in item['writer']
]
This will create a shallow copy of the data list, retaining the items in the list that we want to keep. The items we don't want to keep will be ignored. For more information on the idea of a shallow copy, see the Making shallow and deep copies of objects recipe in Chapter 4, Built-In Data Structures Part 1: Lists and Sets.
We can also use a higher-order function, filter(), as shown in this example:
list(
filter(
lambda item: writer not in item['writer'],
data
)
)
The filter() function has two arguments: a lambda object, and the original set of data. The lambda object is a kind of degenerate case for a function: it has arguments and a single expression, but no name. In this case, the single expression is used to decide which items to pass. Items for which the lambda is False are rejected.
The filter() function is a generator. This means that we need to collect all of the items to create a final list object. A for statement is one way to process all results from a generator. The list() and tuple() functions will also consume all items from a generator, stashing them in the collection object they create and return.
See also
- We've leveraged two other recipes: Making shallow and deep copies of objects and Slicing and dicing a list in Chapter 4, Built-In Data Structures Part 1: Lists and Sets.
- We'll look closely at filters and generator expressions in Chapter 9, Functional Programming Features.