
This chapter will focus primarily on reading and processing the data using Storm. The key aspect being covered here will comprise of the ability of Storm to consume data from various sources, processing and transforming the same, and storing it to data stores. We will also help you to understand these concepts and give examples of filters, joins, and aggregators.
In this chapter, we will cover the following topics:
- Storm input sources
- Meet Kafka
- Reliability of data processing
- Storm simple patterns
- Storm persistence
Storm works well with a variety of input data sources. Consider the following examples:
- Kafka
- RabbitMQ
- Kinesis
Storm is actually a consumer and process of the data. It has to be coupled with some data source. Most of the time, data sources are connected devices that generate streaming data, for example:
- Sensor data
- Traffic signal data
- Data from stock exchanges
- Data from production lines
The list can be virtually endless and so would be the use cases that can be served with the Storm-based solutions. But in the essence of designing cohesive but low coupling systems, it's very important that we keep the source and computation lightly coupled. It's highly advisable that we use a queue or broker service to integrate the streaming data source with Storm's computation unit. The following diagram quickly captures the basic flow for any Storm-based streaming application, where the data is collated from the source and ingested into Storm:
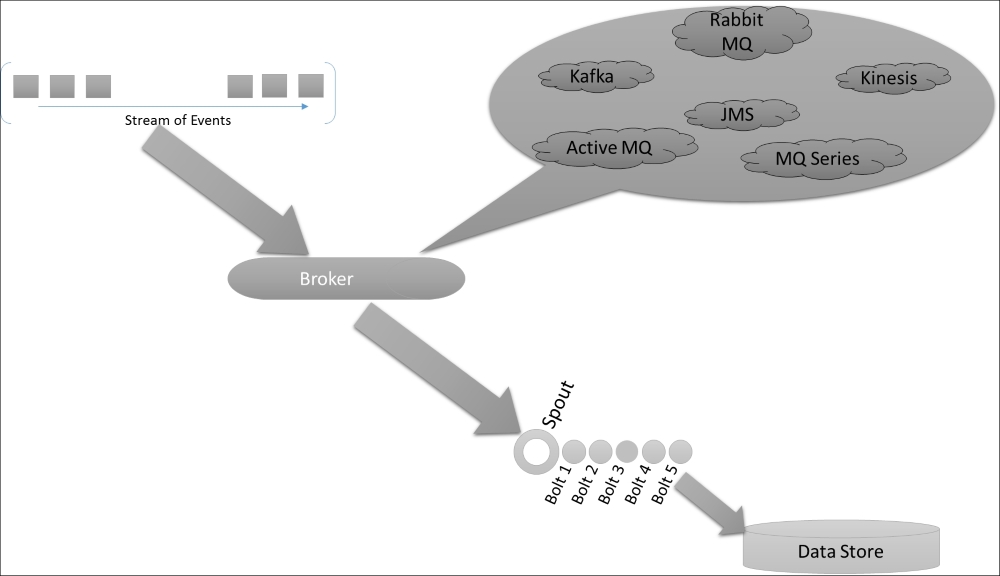
The data is consumed, parsed, processed, and dumped into the database. In the coming sections, we will delve a little deeper into the options that are available for a decoupled integration between a Storm compute unit and the data source.
Kafka is a distributed queuing system that operates on the principle of commit logs. Its execution is based on a traditional publisher-subscriber model and it's known for its built-in performance efficiency and durability. When we essentially mark a data structure as durable, it's due to the ability to retain or recover the messages or data even in the event of failure.
Before moving ahead, let's get acquainted with a few terms that will help us walk through Kafka better:
- Kafka being based on typical pub-sub model, there are Kafka producer processes that produce the messages and Kafka consumer processes that consume the messages.
- The feeds or streams of one or more messages are grouped into the Kafka topic to which the consumer process subscribes while the producer process publishes.
- We have said Kafka is distributed. Thus, it's sure that it executes in a clustered setup in production scenarios. It has one or more broker servers, which are stringed together to form a Kafka cluster.
The following diagram depicts a typical Kafka cluster and its components:

Though the diagram is self-explanatory, here is a brief explanation for the same. The Kafka cluster generally comprises of one or more Kafka servers that communicate with each other through the typical TCP protocol. The producer and consumer processes generally communicate to the servers through clients, which can be in Java, Python, or a variety of languages (Kafka clients can be found at https://cwiki.apache.org/confluence/display/KAFKA/Clients).
Kafka topics can be assumed to be like named letter boxes, where the messages are delivered by the Kafka producers. Talking about one Kafka cluster, one can have multiple topics, each of which is further portioned and chronologically ordered. Topics can be assumed as a logical collection of partitions that actually hold the physical files.

As depicted in the diagram, one Kafka broker can hold multiple partitions and each of the partitions hold multiple messages in a strict order. Ordering (where 0th message is oldest in order of time) is one of the greatest advantages that are provided by the Kafka message broking system. One or more producers can write to a partition and consumers subscribe to retrieve the messages of these partitions. All messages are distinguished by a unique offset ID (unique identifier associated to every message in the partition, and the uniqueness is maintained only within the partition).
Each message published is retained for a specific time denoted by Time to live (TTL) that has been configured. This behavior is irrespective of whether the message has been consumed by the consumer or retained by the partition. The next important attribute to be acquainted within Kafka is topics.
If I describe in simplest words, Kafka continuously writes the messages into a commit log. Each of the partition has its own immutable commit log. As said before, each message is marked with a sequence ID.
Talking about Kafka consumers, it's very important to understand that one of the reasons for Kafka's efficiency is that overloading for setting and maintaining the consumer context is minimal. It actually does what's necessary; per consumer, it just requires to maintain the offset. The consumer metadata is maintained on the server, and it's the job of the consumer to remember the offset. We need to understand a very important implication of the previous statement. Kafka stores all messages in the partition in the form of a commit log. Well, logs are essentially chronologically ordered, but as mentioned, Kafka consumers retain the right to maintain, manage, and advance the offset. Thus, they can read and handle the message the way they want to; for example, they can reset the offset to read from beginning of the queue, or they can move the offset to the end to consume at the end.
Another aspect that adds to the scalability of the Kafka solution is that while one partition is hosted on one machine, one topic can have any number of partitions, thus making it linearly scalable to store extended amounts of data in theory. This mechanism of distributed partitions, along with the replication of data across partitions of a topic, resonates two essential Big Data concepts: high availability and load balancing.
The handling of partitions is done in a very resilient and failsafe manner; each partition has its leader and followers—something very close and similar to the way the Zookeeper quorum operates. When the messages arrive to the topic, they are first written to the partition leader. In the background, there are writes that are replicated to the followers to maintain the replication factor. In the event of failure of the leader, the leader is re-elected and one of the followers becomes the leader. Each Kafka server node serves as a leader to one or more partitions spread across the cluster.
As said earlier, the entire responsibility of the consumption of messages is an equally important role that the Kafka producers execute. First and the foremost, they publish the message to the topic, but it's not as straight and simple as this. They have to make a choice to decide which message should be written to which partition of the topic. This decision is achieved by one of the configured algorithms; it could be round-robin, key-based, or even some custom algorithm.
Now that the messages have been published, we need to understand how essentially Kafka consumers operate and what are the finer dynamics. Traditionally, if we analyze the world of messaging services there are only two models that operate at gross level in theory. Others are more or less abstractions built around them with evolution in implementations. These are the two basic models:
I would like to reiterate that the preceding description is valid at the base level. Various implementations of a queue offer this behavior depending upon their implementations and aspects such as being push-based or pull-based services.

Kafka implementers have been smart enough to offer flexibility and capability of both by coming up with an amalgamation. In Kafka terminology, that's christened as a generalization called a consumer group.
This mechanism effectively implements both the queuing and pub-sub models described previously and provides the advantages of load balancing at the consumer end. This gets the control of rate of consumption and its scalability effectively on the client-consumer end. Each consumer is part of a consumer group, and any message that's published to a partition is consumed by one (note only one) consumer in each of the consumer group(s):

If we try to analyze the preceding diagram, we'd clearly see a graphical depiction of consumer groups and their behavior. Here, we have two Kafka brokers: broker A and broker B. Each of them has two topics: topic A and topic B. Each of the topics is partitioned into two partitions each: partition 0 and partition 1. If you look closely at the preceding diagram, you'll notice that the message from partition 0 in topic A is written to one consumer in consumer group A and one in consumer group B.
Similarly, for all other partitions, the queuing model can be achieved by having all the consumers in a single consumer group, thus achieving one message to be delivered to only one consumer process. Its direct implications are the achievement of load balancing.
If we happen to have a configuration where each consumer group has only a single consumer process in it, then the same behavior as publisher-subscriber model is exhibited and all the messages are published to all consumers.
Kafka comes with following commitments:
- The message ordering is maintained per producer per topic partition
- The messages are presented to consumers in the order they are written to the commit log
- With a replication factor of N, the cluster can overall withstand up to N-1 failures
To set up Kafka on your system(s), download it from http://kafka.apache.org/downloads.html, and then run the following commands:
> tar -xzf kafka_2.11-0.9.0.0.tgz > cd kafka_2.11-0.9.0.0
Kafka requires ZooKeeper to be set up. You can either use your existing ZooKeeper setup and integrate the same with Kafka, or you can use the quick quick-start ZooKeeper Kafka script for the same that comes bundled within the Kafka setup. Check out the following code:
> bin/zookeeper-server-start.sh config/zookeeper.properties [2015-07-22 15:01:37,495] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
Once we have the ZooKeeper up and running, we are all set to have the Kafka server started and running:
> bin/kafka-server-start.sh config/server.properties [2015-07-22 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties) [2015-07-22 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties)
Once we have Kafka up and running, the next step is to create a Kafka topic:
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Once the topic is created the same can be verified using the following commands:
> bin/kafka-topics.sh --list --zookeeper localhost:2181 Test
Here, we have created a topic called test, where the replication factor for the same is kept as 1 and the topic has a single partition.
Now, we are all set to publish the messages and we will run the Kafka command line producer:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test This is message 1 This is message 2
Now, we can have the command-line consumer consume these messages. Kafka also has a command-line consumer that will dump out messages to a standard output:
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning This is message 1 This is message 2
With Kafka set up, let's move back to Storm and work through Storm-Kafka integration in the next sections.