
7 WRITING GOOD-QUALITY CODE
‘Programs must be written for people to read, and only incidentally for machines to execute.’
– Harold Abelson
It is not enough to solve a problem if the resulting code is not maintainable. Does it really matter if the code is inefficient, poorly laid out or not commented? In this chapter we consider the answers to this question.
CODING THE SOLUTION
Although it is outside the remit of this book to provide detailed instruction in any given programming language or recommend which one to use in any particular circumstance, there are some techniques you should consider no matter which operating system, hardware or language you are using.
In an ideal world
The heart of software development activity is the production of working code, progressing through the following stages: entry of source code, building of executable code (where appropriate), testing, staging (where relevant) and deployment.
Ideally any solution should:
- produce accurate results
- and do so efficiently
- while working reliably
- and robustly
- while also being coded to appropriate standards
- and being secure
- and most importantly meeting the design requirements
- within the budgeted time allocation.
Of course, this is not an easy set of criteria to meet, and modern software often stumbles in one or two of these categories, often in terms of reliability and security. This is not surprising perhaps, as many organisations do not allocate sufficient resources to test program code thoroughly. It’s an unfortunate shortcut, but one which is often accepted as the price of getting solutions ‘live’.
Make no mistake, though, it can be an exceptionally costly and short-sighted decision. There are often unforeseen consequences that karmically end up costing an organisation even more money than implementing a decently robust testing regime. It’s a tragic and false economy.
Unfortunately, as programmed solutions infiltrate more and more of everyday life, their need to be as bulletproof as possible will only grow more critical. This software will determine medication dosages for critically ill patients, decide how to drive an automated car on public roads and monitor the safety levels in nuclear power stations. The consequences of less-than-perfect reliability and security cannot be underestimated.
How coding is achieved commercially
Producing code often comes down to a personal choice of available editors, compilers, debuggers and operating systems. These create a ‘toolchain’ which enables the developer to create, execute and test their code to the required standard.
In a commercial environment, you will often find two developers sat side by side using very different environments, each singing their choice’s praises and recoiling in horror at the tools chosen by their peer. Some may prefer a powerful editor such as Vi and command line compilation, whereas others may prefer the auto-completion richness of an IDE (integrated development environment) such as IBM’s NetBeans or Microsoft’s Visual Studio.
The list of development tools in use may be mandated by an organisation, but it is not uncommon for programmers to have some degree of latitude, excepting (of course) the actual programming language being used – that is often specified as part of the design and is not a subject for discussion. Commercially it is not uncommon for some organisations to pre-install a new developer’s environment to ensure they are ready to be 100% productive from day one.
Infrastructure-rich organisations often rely on enterprise glue to fix parts of the solution together – for example, to download data files from an FTP server for processing or to automatically download and print generated invoices. In these instances, some freedom may be available, particularly in scripting languages. For example, a programmer may decide on a Linux platform to code in shell script, Perl or Python and achieve similar results. The ability for the organisation to maintain the code in the future may affect the decision here, particularly if expertise in certain languages is known to be thin on the ground.
Although diversification in practical workflows is therefore accepted, the rise of the Agile methodology as the premiere approach in commercial development has become a unifying driver.
The importance of version control
Being a commercial developer typically means working in a team. This will directly impact the code you write and how you contribute to a project. In a modern software development workplace, this is typically achieved via software versioning. This is examined in greater detail in Chapter 14.
Giving identifiers suitable and meaningful names is only part of the equation. The other aspect to consider is the naming convention(s) being used in a software development project. The four common styles are shown in Table 7.1
Table 7.1 Naming convention examples

Naming conventions are typically either mandated by the organisation (as an internal coding standing) or by the programming language itself. In an organisation, naming conventions simply make life easier for all developers when a project (and its team) is large; in theory, with a consistent naming convention, any developer should quickly be able to read the code produced by another.
In languages such as Python, PascalCase (following that language’s popular usage of the styling), camelCase (due to the ‘hump’) and snake_case (lying low to the ‘ground’) can be used to indicate that an identifier represents a class, a function or a variable, respectively. However, organisational standards and those shared by a development team will often prevail.
For the record, if you’re wondering where you might encounter kebab-case, it’s most often used by web application developers when they create CSS classes to format their HTML-based content.
THE IMPORTANCE OF LAYOUT AND COMMENTING
Layout typically takes the form of indentation, the process of highlighting the logical structure of program code by indenting certain parts of code from the left margin. An if statement is a typical example of this. In C, this would appear as follows:
if (age > 18) {
printf("You are older than 18!");
}
And in Python it would appear as follows:
if age > 18:
print("You are older than 18!")
Although the syntax is slightly different, both languages use indentation to highlight that the printing of the message is connected to the evaluation of the expression. In other words, if the condition is true (age is greater than 18) then (and only then) will the indented code be executed.
It is worth noting that in C the indentation is purely aesthetic and has no impact on the logic; C typically uses braces to create blocks of code, which it connects to controlling expressions. In Python, however, the indentation is an important syntax point: it is mandated as four spaces (not a tab) in PEP8 (Python Enhancement Proposal 8), which is the style guide for all Python developers.
COMMENTS AS DOCUMENTATION
Documentation is a significant part of the development process. For some programmers it comes naturally as they start writing comments from their initial pseudocode as an outline of the steps they intend to take to solve the given problem. Pseudocode is a step-by-step list of actions that the expected program will need, written in the user’s native language. You will find more on pseudocode in Chapter 11.
For example:
get first number
get second number
result <- first number + second number
output result
However, it is often derided in industry through the oft-quoted conceit of making program code ‘self-documenting’. This idea suggests that if the code is clearly written, uses meaningful identifier names and has good indentation then it shouldn’t need separate documentation – any reasonably competent programmer should be able to understand it ‘as is’.
That’s true to an extent but it doesn’t tell you the whole story.
The one thing you shouldn’t do when commenting is to just describe the actual syntax being used, as in this example in C:
int qty;
//set quantity to 0
qty = 0;
It’s obvious what’s happening here, so adding this all-too-obvious comment is essentially a waste of time, effort and an employer’s development budget! This is sometimes referred to as WET (write everything twice or, more humorously, we enjoy typing), the opposite of the software engineering principle DRY (don’t repeat yourself!).
Of course, many programming languages support documentation features and although there are differences in their syntax, the basic objectives of good commenting are clear:
- Concisely describe the actions of your code to others from a real-world perspective (what it does, not how it does it).
- Provide specific programming notes – for example, why something is included that might be platform specific (necessary for Microsoft Windows or Linux, for instance) – that might be useful and not immediately obvious.
- Provide an overview to other programmers who must maintain your code so that they can glean its purpose after a quick skim read.
- Act as an aide-memoire when you return to revise the very same code in the future.
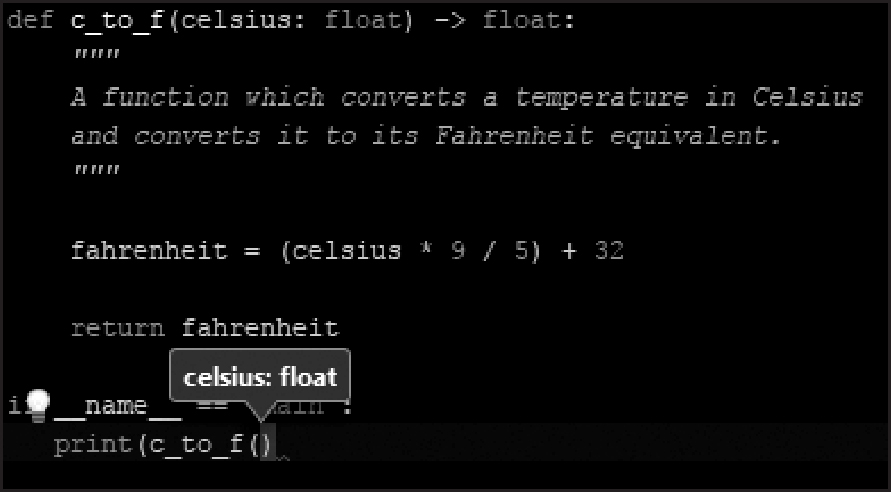
The following Python code extract is a useful function which converts a temperature in degrees Celsius to its equivalent value in Fahrenheit:

These comments (and hints) tell us:
- the type of the reference (data) passed into the function (a floating-point number);
- the type of reference returned by the function (another floating-point number);
- the function’s purpose (stored as a Python docstring).
And, more helpfully, after importing its parent module, the new function is immediately usable by Python’s built-in help function:

In addition, Python’s type hints (specifying the data types passed in and returned by the function) can be accessed by various IDEs, offering developers a helping hand as they type:
Using documentation generator tools
Many tools are available which will generate HTML files that can be viewed through a standard web browser. They typically offer an interactive experience for a programmer, enabling them to easily navigate a hyperlinked version of their complete software project function by function, class by class and so on.
Some tools available for the more popular languages include (the clues are in the names):
- pydoc (part of the standard Python library; see https://docs.python.org/2/library/pydoc.html);
- PhpDocumentator (www.phpdoc.org);
- Javadoc (part of Oracle’s Java Development Kit installation; see https://tinyurl.com/ydhgcray).
For example, issuing the following command in a Microsoft Windows environment:
python -m pydoc -w degcf
will generate HTML documentation for the previously discussed Python c_to_f function, which exists in the degcf module (see Figure 7.1).
Figure 7.1 Automatically generated HTML documentation for a Python function
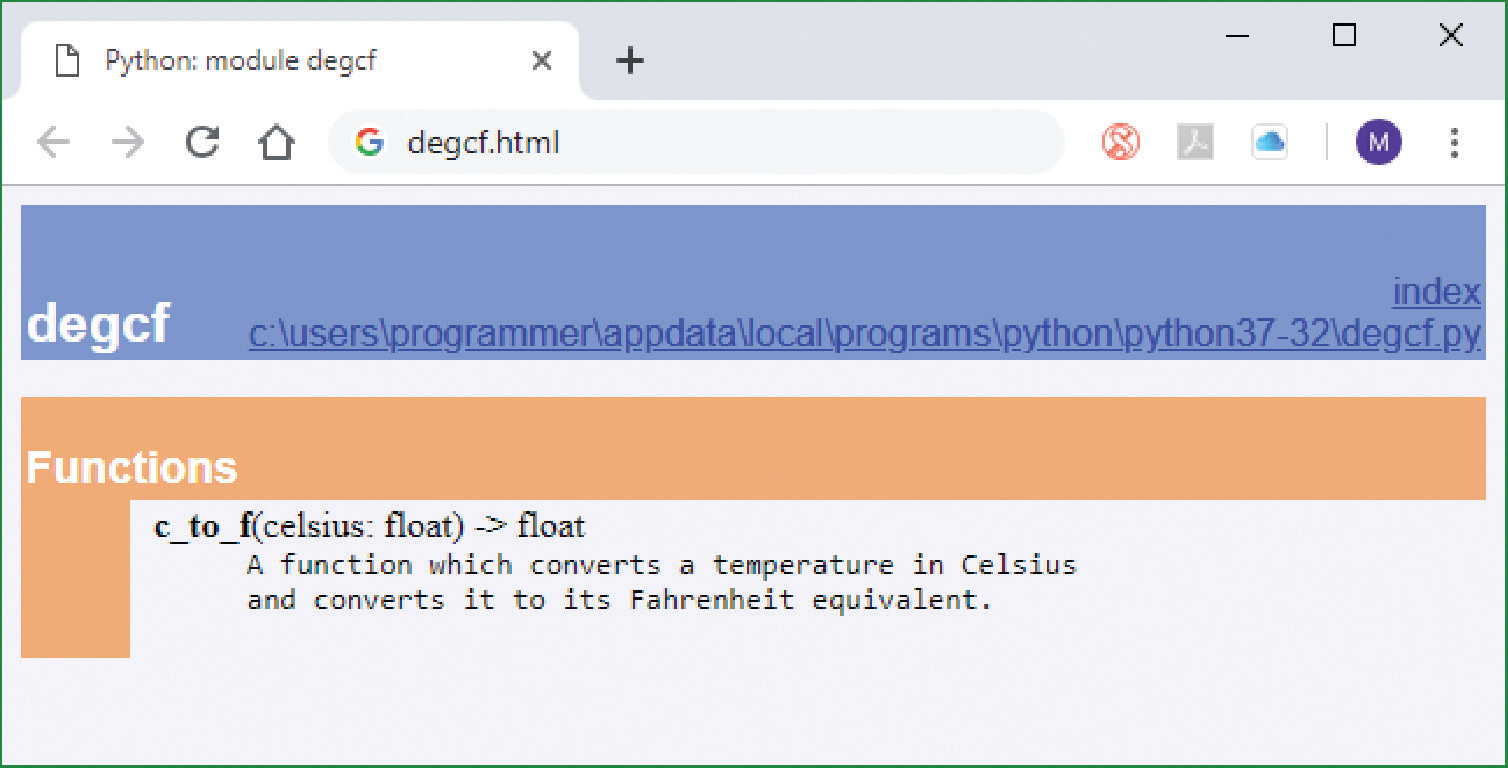
Again, use of Python’s comments has proven very helpful, producing a simple but effective overview of the function we have written.
As you may imagine, a larger project would create a much larger and richer repository of information that any software maintainer would be happy to peruse.
HANDLING ERRORS AND EXCEPTIONS
Handling run-time errors
In many programming languages, your source code is translated into machine code (binary) for the CPU to execute using a process called ‘compilation’. When this process cannot be completed wholly successfully, it results in errors and warnings:
- Error: a fatal error, typically a problem with the language syntax where the programmer has broken the rules of the language in their code, such as by missing out a bracket or semi-colon. These must be fixed before the program can be successfully compiled and executed.
- Warning: a non-fatal error, which is advisory, typically indicating an issue that should be investigated as it may cause a problem at run-time. These typically can be ignored, but the wise programmer does so at their peril!
A typical warning could be the narrowing of a data type, for instance storing a floating-point number (one with decimal places) in an integer variable (a whole number), in which case the accuracy of the original data would be lost through the truncation of the decimal part of the value. Not fixing this could generate wildly inaccurate results, and in real-world contexts it could prove costly or lead to disastrous outcomes.
However, some errors cannot be spotted during the compilation process. These errors can occur unexpectedly as a program is executing; these are called ‘run-time’ errors. In practice, a programmer should code defensively against these, anticipating the problem and providing a suitable solution which handles them; this leads us to exception handling.
Handling exceptions
When a computer program runs some operations, unexpected events can occur, for example an attempt to divide by zero (which results in infinity, something a computer system cannot store). Under normal circumstances, these serious events would cause a fatal run-time error, typically crashing the program (or worse, the entire operating system), necessitating a reboot.
However, in many modern programming languages it is possible to ‘throw’ an exception in response to such errors. Exception handling is then used to manage this type of problem, effectively ‘catching’ the exception and ‘handling’ it with suitable code, allowing the program to continue unhindered.
This is typically achieved using TRY...CATCH blocks:
TRY
<statement>
CATCH (exception)
<statement>
Many different types of exception can occur, each requiring a specific handler. Of course, although the actual syntax for these exception-handling blocks varies between languages, their structure follows a familiar pattern.
Worked example
A common form of run-time error occurs when a program attempts to open a data file which cannot be found, perhaps because it has been moved, renamed or deleted. Here is a Python 3.X excerpt which demonstrates this:
error_filename = "file_import.log"
error_file = open(error_filename, "a")
#...processed filename, e.g. from an FTP server
filename = "100420.dat"
try:
file_to_process = open(filename, "r")
except FileNotFoundError:
print(f"{filename:s} not found", file=error_file)
else:
for line in file_to_process:
print(line, end="")
file_to_process.close()
finally:
error_file.close()
In this example, a FileNotFoundError exception is thrown at run-time when the computer attempts to open the named file. This exception is then caught and gracefully handled by appending a simple message to a log file, which the developer can later examine. Notice that we only attempt to read the file if it is successfully opened; this ‘successful’ action is indicated by using the else clause. The finally clause is executed regardless of the successful opening of the data file. This prevents a serious run-time error in the program.
As discussed, another common form of run-time error occurs when a program attempts to divide by zero, something which is arithmetically impossible. The following TRY…CATCH style of exception handling prevents this type of error occurring in Python 3.X:
total_sales = float(input("Enter total sales: "))
days = int(input("Number of days: "))
try:
sales_per_day = total_sales / days
except ZeroDivisionError:
print("Must enter 1 or more days.")
else:
print(f"Average sales per day: {sales_per_day:.2f}")
In this example, a programmer is trying to calculate the mean average sales over a number of days. However, because the number of days being input has not been validated to check that it is a positive integer, it is possible that a division by 0 could be attempted.
A simple TRY…CATCH block around the calculation will avoid this problem and handle the resulting ZeroDivisionError exception with a friendly error message. A better solution would be to validate the user input, of course – another example of designing the problem out so you don’t have to deal with it.
The exception handler is just a specific block of program code that deals with thrown exceptions. Typically, there are multiple handlers, one for each type of common exception caught by the developer. This is much better practice than having a generic handler that catches everything but cannot act specifically to resolve them.
Why exception handling is important
There are a number of reasons why exception handling is important:
- It is not possible to anticipate all errors that might occur at run-time when designing a program.
- It separates error-handling code from normal program code, which eases code maintenance.
- It is capable of recognising and handling different types of error – for example, a file not existing raises a different exception to a file being of the wrong type.
- It prevents run-time errors from causing programs to fatally crash or become non-responsive.
- The successful handling of run-time errors is particularly important for automated scripts which run outside normal office hours (such as overnight file downloads) as if they spectacularly crash, no developer will be on-site to rectify the problem.
Exception handling is a crucial element in many commercially important programming languages in the IT sector, including Python, Oracle’s Java, Microsoft’s C# and Visual Basic .NET, Apple’s Objective C and Swift.
Programming language idioms
All programming languages have their own unique flavour, typically represented by the ways certain tasks are commonly performed. These language-based ‘code patterns’ are traditionally used when performing certain algorithmic tasks, and they shouldn’t really be translated from one language to another without due consideration.
For example, in C, it is a tried-and-tested tradition to iterate along an array using a for loop and an index:
int data[5] = {10, 20, 30, 40, 50};
for (int i=0; i < 5; i++) {
printf("pos %d value %d ", i, data[i]);
}
This C algorithm can be mechanically replicated in Python:
data = [10, 20, 30, 40, 50]
i = 0
while i < 5:
print(f"pos {i} value {data[i]}")
i += 1
However, most professional Python developers would not code in this way, as it does not use a recognisable idiom. Either of the following patterns would be considered far more ‘Pythonic’:
data = [10, 20, 30, 40, 50]
for i in range(0, 5):
print(f"pos {i} value {data[i]}")
for pos, value in enumerate(data):
print(f"pos {pos} value {value}")
It is interesting to note that even the use of i as an index in a loop could be considered a universal idiom – it’s a nugget of knowledge that all developers inherently understand as an accepted practice and, hence, are not surprised when they see it being used in a coded solution.
Using a programming language’s idioms is a way of using its features appropriately, writing in a more naturally expressive manner and, consequently, producing better code.
EAFP vs LBYL
Traditional programming follows a LBYL (look before you leap) approach to coding. For example, we check to see if a file exists before we try to open it. This makes a lot of sense and it avoids the embarrassment of the underlying operating system reporting a ‘file not found’ error.
However, an EAFP (easier to ask for forgiveness than it is for permission) approach works the opposite way around. If we use this approach, we make the basic assumption that the file (always) exists and try to open it. Placed around this attempt to open a file is a simple TRY…CATCH block which will handle the generated error.
Although the former may seem more sensible, it is the latter approach that is favoured in popular languages such as Python.
Refactoring
It is not a trade industry secret to say that code is often developed at a reasonably frantic rate. This leads to technical shortcuts, a lack of appropriate (i.e. rigorous) testing and, to be honest, less-than-ideal additions to a production codebase. The usual suspects include:
- vulnerable code with insufficient data or data type checking;
- overlong (or overcomplicated) functions;
- functions which break the SRP (single responsibility principle): performing more than one core task;
- badly designed classes, particularly ones that have grown too large and unwieldy;
- orphan functions which possibly should belong elsewhere;
- unnecessary code duplication: WET vs DRY;
- short-term ‘hacks’ which are used to patch a codebase’s behaviour temporarily;
- obsolete and/or potentially misleading comments which no longer reflect the code they accompany;
- over-engineered code which attempts to predict future need (more on this later) and becomes needlessly layered and overcomplicated;
- badly named identifiers – too short, too long or simply do not meet team standards;
- ‘God’ lines, where a single complex line of code possibly defies easy maintenance or breaks coding standards (e.g. recommended maximum line length).
When tight release deadlines loom and code ‘just works’, it is common (and human) for hard-pressed developers to simply walk away and close the box, often hoping that any further revision to the codebase will be assigned to another developer. When this happens, the team (and the project itself) is effectively carrying ‘technical debt’. The longer this debt is carried, much as in real life, the more ‘interest’ will accrue. One solution is to consider refactoring.
Refactoring is a process which, ideally, shouldn’t stand out as a separate (or special) activity in a software development team’s workload. It involves reorganising existing code while not changing its ultimate behaviour. Often, in the first gasp for air after a project has been crunched to completion, time is found to perform some refactoring, particularly if the code ‘smells’. Code smell is a purely subjective concept; it is essentially defined as the innate feeling that something in the codebase ‘isn’t quite right’ and may be the cause of deeper problems (i.e. in performance, accuracy or reliability).
In truth, it is generally better to perform refactoring while new code is being written (i.e. as part of a developer’s everyday routine). In other words, when working on a sub-task, if you notice some existing code that smells, you can simply opt to refactor it there and then. This contributes to the concept of a team’s sense of collective responsibility over their codebase – in itself, no bad thing.
Selected examples of code smells and their refactoring solutions are shown in Table 7.2.
Table 7.2 Refactoring solutions for a range of code smells
Code smell | Typical refactor solution |
Vulnerable code with insufficient data or data type checking | Add extra ‘belt and braces’ checks for data existence, data range and data types (assume nothing) |
Functions which break the SRP (performing more than one core task) | Break the larger function into a number of smaller functions which each meet the SRP – this is by far the most common refactoring activity |
Unnecessary code duplication (WET vs DRY) | Identify the duplicated aspects and create suitable functions |
Orphaned functions which possibly should belong elsewhere | Consider placing each function in a library or add it to an associated class as a static method |
Short-term ‘hacks’ which have been used to patch a codebase’s behaviour temporarily | Re-open the box and solve the issue permanently – hacks should always be removed! |
Many modern IDEs, such as Eclipse and NetBeans, include automated refactoring routines which can assist a developer in the refactoring process.
It is critical to remember that refactoring should change the internal composition of the code but not affect its external behaviour – certainly not in a negative way. If the resulting code executes faster, is more efficient in its memory usage or simply behaves in a more robust manner, complaints are unlikely to be forthcoming.
The exact working practices inside a software development team can vary between organisations so don’t expect them all to work in the same manner. Agile processes entail many different aspects, such as pair programming (see below). When implemented effectively, this can certainly make a positive contribution to the writing of good-quality code.
Pair programming
Pair programming is a common and generally productive Agile software development technique which involves two programmers working together on a single problem at the same terminal (Figure 7.2). The programmers generally have similar levels of experience (this isn’t a traditional master–apprentice arrangement). The arrangement provides an opportunity for each to take turns at coding and reviewing, switching roles regularly and most commonly during changes of module (or function).
Figure 7.2 Pair programming (This photo by Unknown Author is licensed under CC BY-SA-NC)

While one programmer works on the current code, the other reviews and makes suggestions as the code develops line by line on the screen, often identifying potential improvements to the code or correcting syntax or semantic errors as each block of code is written. Discussion and compromise form part of the process when viewpoints don’t coincide; this is natural.
The impacts of pair programming techniques are mixed, as shown in Table 7.3.
The biggest positive impact of using peer coding techniques is that they are very true to the Agile philosophy: feedback on potential mistakes, logic flaws and so on are kept as close as possible to the point of the code’s creation – even before the code reaches the quality assurance process and, better still, before it’s in the hands of the actual customers. In this way, and with working software being the key measure of progress in any Agile environment, peer coding practices work well and should always be considered.
Formal peer code reviews
An Agile development environment offers another mechanism that can encourage the creation of good-quality code – the formal peer code review. In a modern development environment, all members of the team should be encouraged to take a collective attitude to maintaining the underlying state and quality of the active project’s codebase. There are many reasons for this:
Table 7.3 Pros and cons of pair programming
Advantages | Disadvantages |
|
|
- Developers gain a wider understanding of the entire codebase, offering more redundancy in the team (i.e. more ability to cope with illness, members leaving etc.).
- Common coding standards are easier to communicate and adhere to, giving the codebase a more uniform appearance and problem-solving approach (this also benefits new programmers as the style is immediately easier for them to spot and adopt when they start).
- Code documentation tends to improve.
It is generally cheaper to fix identified bugs earlier in the development process rather than later. Early code reviews, achieved through the collaboration of a small team of reviewers, encourage the elimination of shoddy programming practice, use of ill-considered solutions and unrequested deviations from the agreed design documentation.
Pair programming can, of course, be used as a lightweight method of peer code review. In addition, panel reviews via online tools or simply email-based message threads can be effective. It is also common to select a subset of new sections of code to review rather than to review literally everything. The code that is selected may include those sections that cause the most concern among the team (potentially from a new programmer) or those which contain the most critical (and therefore impactful) additions to the existing codebase.
How could the usefulness of code reviews be evaluated? We could simply analyse the relationships between the following variables to generate a useful metric:

In addition, the actual time (and associated costs) required to review the selected code should be factored into any calculation.
As with all review techniques, there can be resistance, especially if a development team does not buy into the process. They (and you, assuming you’re part of the team) simply need to remember that the goal is to measure the quality of the produced code, not make judgements about the ability of its author: we’re all capable of producing poor-quality code on any given day – it’s just a part of being human.
TIPS FOR GOOD CODING
Here are some things to remember to help you to produce good code:
- Use meaningful names when creating identifiers (i.e. variables, constants, classes, functions, structures etc.).
- Ensure each function has one purpose, according to the SRP.
- Delete any unnecessary code – if you’re using version control it’ll still be safe in the change log.
- Readability always counts.
- Code in a consistent manner and follow organisational standards.
- Indent your code appropriately.
- Comment the purpose of your code, not the syntax.
- Never add comments which could be seen as commercially insensitive, rude or unprofessional – you never know who will see them.
- Use the idioms of the language whenever possible.
- Always catch exceptions and never let them pass without comment – logging them is a good start.
- Refactor where appropriate and do it proactively rather than reactively.
- Pair programming can reduce errors and improve the quality of the code produced.
- Play an active part in formal code reviews. There’s always much to learn no matter how experienced you are!
SUMMARY
In this chapter we have examined how to write good-quality code. In truth, it is difficult to get it 100% correct, as readily evidenced by the proliferation of bugs, patches and broken applications you have no doubt encountered in your travels. However, of course, that doesn’t mean we shouldn’t try.
In the next chapter we will turn our attention to the creation of effective user interfaces.