
Flood and Famine: Rethinking Enterprise Data
For many large companies, there’s no shortage of data in the business. You probably have sales data, customer information, supply chain data, and a vast number of additional sets of data. This can often lull managers into believing that they’ve got enough data. But the right way to think about this is through the lens of your decisions. If you’re looking to improve your product performance, how much data do you have about how customers are using your product. Or if you’re rationalizing your store locations, are you doing this with the data you need? Is there a mismatch between the data you have and the decisions you need to make? Do you find yourself in situations where you have some but not all the data you need? Does it take too long to get the data in a usable form? Are you having to custom create reports that require days and weeks to get done? These are all the typical problems I’ve seen in organizations that also simultaneously feel that they have more data than they’re actually using. It is definitely possible for both of these to be true. You have data sets A, B, C, and D. You need data sets C, D, E, and F. Your data team is complaining that you don’t use all the data you already have, and you feel you’re not getting the data you need.
Tip: Take any decision you need to make at work and think of all the information that you would need to make a perfect decision. Then see what percentage of information is available to you.
Analytics and Business Intelligence
The idea that by capturing data about business operations, we might find ways to improve them goes back to the start of the 20th century, to the time of Henry Ford and Frederick Taylor. Since then, and especially spurred on by computerization, spreadsheets, and many more sophisticated tools, most businesses use analytics and business intelligence or BI extensively. Walmart was famous for leading the charge on gathering and exploiting retail data not just for its own operations but also for sharing with all its providers and partners.
It’s a useful practice, while embarking on any digital project, to envision the postproject state, and think about what data you will be generating, how you want that data to be presented, and what decisions you want to be making with that data. Each of these questions might impact the other, but working back from this will shape your project much more effectively. Otherwise, you will end up with a lot of data being thrown into a generic dashboard that nobody actually uses. Most data now lives in the cloud, and it makes sense that the analytics and BI tools are also similarly on the cloud—a good example is Splunk, a tool that captures data across your IT environment, and provides data, tools, and reports in the cloud. This means that the entire process can run where the data is, and what gets delivered is the specific report or data stream that you need. For example, if you’re digitizing a call center, with online human chats and chatbots, once the project is complete, every customer conversation will generate data. You’ll be able to run sentiment analysis, keyword analyses, and more. You might also get geographical information and device information, which is additionally useful to your marketing team. You could then provide a bunch of report options and allow the business managers to create their own parameters to choose from, for reporting. The training manager could look at the escalations and average time per conversation. The chatbot design team could look at levels of engagement and handover. The head of customer service could look at the average time to resolution and satisfaction levels. Each of these people could run their own reports, choose the period of reporting, and add and remove parameters (split by age of user, or type of customer, etc.). You’ve now reached the stage of providing the reporting as a self-service option.
You would then typically add visualization tools. There’s a longer discussion a little later, but for now, let’s remember that there’s already a huge push for visualization and infographics. The latter often turns into throwing pictures and words together. But the purpose of both are the same—to use the best possible means to communicate complex information in a way that’s easy to absorb and memorable.
Tip: Resist the urge to add unnecessary embellishments in your data visualization, especially if the user has to see the same report regularly.
Collectively, these data analytics tools are referred to as systems of insight, for obvious reasons. It’s worth noting that multiple types of analytics works coexist within these environments. Not everything is required at the same velocity and urgency, so costs can be traded off. Some data is inherently structured, such as customer names and contacts, while others such as weather or relationship information, or the spread of disease or crime, is inherently unstructured. Appropriate tools and methodologies are required for each.
Avoiding Data Antiquity
One day, just a few years ago, I lost my debit card. I say lost, but my daughter, then four, discovered it under the car seat the next day. By then, I had canceled the card via the bank website, and my bank assured me that a new one was on its way. As it turned out, this was within a day of my wife’s card expiring, so she was also talking with the same bank for the same purpose—a new debit card.
A week went by and no cards showed up, so we started following up. Imagine our surprise when we were told that the card had been dispatched, but to our previous address—which we had left exactly 13 months earlier. The bank didn’t know that we had moved. How was this possible? Even worse, they had my old mobile phone number—which I had not used in 6 months.
Having moved home a few times, we have a comprehensive checklist for all services we need to update. From utility providers, to post office, to banks to employers, it’s all there, and we’re pretty sure we did it all. In fact, our credit cards, with the same bank had all the right information. We received the statements, and our online purchases went through with the new address confirmation. But, this information had not filtered through to the savings account side of my bank.
And consider this: quite apart from the inconvenience and the confusion, the bank had effectively posted my card and my pin to the wrong person. It was sent by registered post—but as we know, anybody can really sign for it. How ironic is it that after all the effort of sending the card and pin in separate packs and taking all the precautions of masking the pin, it gets sent to the wrong person! A reminder that you’re only as secure as your weakest link!
You’re probably thinking at this point that the credit card business and the consumer banking business may not be sharing data. But even without sharing data, it’s easy to highlight it when address data for the same customer is different across the parts of the business, or flag it to the other business one when one address has changed. The alternative, as in this case, was to put the onus back on the consumer to notify each individual branch of the bank individually, about change of address. That can’t be right. I’m sure you’ve had similar experiences with either your bank or your health care provider, utility provider, or some other service you consume. And I’m sure many of you, like me, have been unwilling recipients of retargeting ads—being told about great new folding cycles a month after you searched for and bought it. How many such businesses are trying to leap into the 21st century, with one foot still stuck in the 1980s?
Real-Time Data
If data is at the heart of decisions, then data systems are effectively the nervous system of the organization. The ability of a business to react to its environment depends critically on its ability to bring the relevant data to its decision points, at the right time. The art and science of managing data in the organization is one of the most critical skills for digital organizations today. This is an area that has gone through huge changes in the digital era.
For a lot of businesses, even 10 years ago, it took a while for businesses to even understand their own performance. Broadcast businesses, for example, were dependent on data produced by the Broadcasters’ Audience Research Bureau or the BARB in the UK. BARB collects viewership data based on a sample and reports back to the broadcasters. It used to be a two-week cycle and is now an overnight one. At some point, this will be near-real time, or the broadcasters will know within minutes if not seconds of airing a show how many people watched it, or perhaps they will know the figures even as the show is airing. The competition from traditional TV channels is no longer other TV channels but online video. Be it Netflix, Prime, Disney+, YouTube, or any other. And any over-thetop (OTT) provider, as they are called, because they bypass the broadcast infrastructure, knows what their audience is watching every minute, in real time. They know when you paused your show and when you skipped the credits. And what you searched for and browsed before you selected something to watch. When Prime broadcasts sports, as they now do, they also know if you switched off during the game, or if you rewound a part of the action.
Today, a lot of businesses have moved to real-time data. Tools such as SAP HANA enable the aggregation and analysis of data in real time, that is, as it happens. An apparel retail chain may want to know its daily sales and stock figures an hour after stores close, in a region, or the relative performance of different colors within a line, in order to move stock for the next day or place new orders on suppliers. The faster movement of data has enabled faster business cycles. Zara and H&M were brands that built competitiveness around the speed of their business cycles. Traditional shoppers visited apparel stores four times a year, but Zara customers came in once every three weeks for new fashions. But now they have been superseded by the next generation such as BooHoo and Asos who are running at Internet speed. Zara was revolutionary for offering hundreds of new items a week; nowadays, Asos adds as many as 7,000 new styles to its website over the same period.
The New Crystal Ball: Predictive Data
We aren’t stopping at the present. Future telling may have been a black art with crystal balls in fair grounds, but today, a lot of near-future outcomes are predictable, given the patterns, with a high degree of accuracy. DeepMind, an Alphabet company, works with the Royal Free Hospital Trust in London to help predict acute kidney infections, thereby saving lives saving as saving nurses two hours per day on average. This is just one example, you only have to read the newspapers to see everyday instances of predictive date analysis in managing customer churn, or in managing maintenance work on asset networks. Over the next few years, we will see the focus of AI in any number of ways looking to predict the near future.
Knowledge Management 2.0
There have been multiple points over the past 40 years when the term knowledge management was in vogue. As the Internet was spreading its wings across commerce, content, and supply chains, it suddenly became apparent that we were sitting on one of the largest treasure troves of information ever, and it was accessible to everybody. Knowledge management involved the idea that we could get our experts to share their knowledge and experience through systems, which would allow this knowledge to be passed on to others. The support engineer who has been fixing gas leaks for 20 years would share the patterns, experiences, and challenges in a way that the novice engineer could access and gain from. Or an experienced nurse could contribute to building an expert system that could run basic diagnostics for a person with basic symptoms. Every major company was looking to recast their products as knowledge management systems—from IBM’s Lotus, to Microsoft Collaboration tools, to Oracle Databases. It never took off. Not because the technology was missing, but the assumption that experts would have the incentives and the time and even the capability to articulate their methods, data, and experience in a structured manner was a flawed one in the main. The power of gut decisions is also their weakness. They are near impossible to replicate.
Today, we might be reaching the same point but through a very different route. By connecting all these experts to systems that enable them to do their job better, we are getting them to create that same dataset of their choices, and experiences, almost as a byproduct. By getting a service engineer to log a job on a phone or scan a barcode to identify a part, we gather not just the core data about which customer, what job, which spare part, and what problem, but also meta-data—time, location, duration between jobs, etc., which collectively give us a richer data set to work with. Over time, this would give us the same kind of knowledge capability that we were seeking back then, but without trying to get people to simply dump their knowledge into an artificial system.
Adding Love to Data
A few years ago, at the annual FT Innovate Conference, a lively roundtable discussion followed after a well-known retail CEO had made a presentation about data and analysis. The presentation covered examples of analyzing customers to great and occasionally worrying insight, within the industry. From knowing if a woman is pregnant even before she knows it herself, to people having affairs, or stacking beer and nappies together, in front of the stores, all of this can today be deduced from data itself.
Let’s remind ourselves though—while there’s been a lot of talk about analyzing customers, it misses the point of empathy. The customer does not want to be analyzed. As with any relationship, he or she wants to be loved, cherished, understood, and served better. At the end of the day, for most businesses, this translates to a mind-shift again, of adding a layer of human understanding to data, to creatively and emotionally assess the customers’ needs, and to allow the analytics to feed off the empathy and emotional connect, rather than be driven purely by the algorithm.
Data Visualization
Imagine that you’re trying to control a cholera epidemic in the 19th century. Although everybody believes that the disease is airborne, you have a hunch that it might be something else. You gather data about cholera patients and you have their names, ages, and addresses. If you’re John Snow, the famous physician, you plot the cases on a map, overlay it with the visual of the water supply and sewage, and establish your hypothesis that the spread of the disease follows the water system, rather than over the air. Look at the following picture, which shows the cholera-impacted households in Soho, London. Now just for a moment, imagine that instead of this map, you have a table with names and addresses, and you have another table describing the path of sewage systems. Do you think it would be as easy to assess the linkage between the disease and the water system? Sure, it could be done, but it would hardly be as intuitive as when you look at the map. John Snow not only established the cause of spread of cholera, he’s credited with being a pioneer of epidemiology—the science of tracking epidemic diseases.
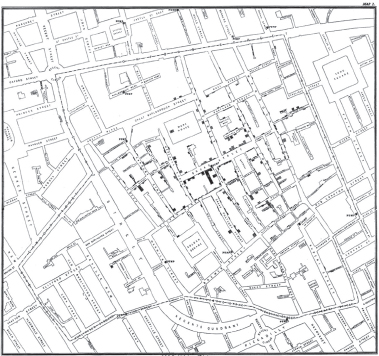
Figure 14.1 Cholera/sewage map—John Snow
You can look at data in any way you want, but there’s obvious merit to presenting it in a way that will aid decision making. This can work in two ways. Either we know the needs of the decision, and the data is presented accordingly. Or we use the data to trigger new thoughts for decision makers. For example, the decision of “where to open our next store” will involve a lot of geographic data—including customer clusters, competition, and potentially complementary products. All of this will make more sense visually on a map. On the other hand, data from a patient’s health wearable showing level of movement might be best presented using a 360° clock interface. Getting too creative with data is a risk if it gets in the way of decision making, or if it masks the decision data. A good visualization uses every aspect of the visual—color, shape, size, position, and relationship, to draw focus on the key decision criteria, and tries to keep it as simple as possible. As a simple example, tools like Microsoft Word, or Gmail, which people use frequently, have to be extremely understated, so as not to get on your nerves over time. The designers have to strongly resist the urge for unnecessary flourishes. This is also true of data visualization—so be clear about whether it’s a single-use visualization or something that will be used frequently. There are a number of tools for visualization, the most popular ones in corporations tend to be Tableau, Qlik, and Microstrategy, but open-source tools such as Charted have gained ground as well.
Data Economics—The Crown Jewels
Adrian Slywotzky’s great book on Value Migration1 talks about how economic value migrates from older to newer business models or from a segment to another, or even one firm to another. In the digital era, we are going to see significant value moving to those companies in each industry that get the value of the data, be it health care, or education, or automobiles, insurance, or even heavy industry. The Howden Group of companies (formerly Hyperion) has been known for underwriting and brokerage in the European insurance space. Hyperion X is the business within the portfolio that offers data insights to other insurers and brokers. This is just one example of many businesses looking to trade off the value of their data capabilities.
It’s the reason why Google bought Nest for a valuation far higher than any thermostat company could hope to get, or why startups such as 23AndMe are valued at $3.5 billion—you can see the data-centric companies starting to become value magnets. The question you want to be asking yourself is, in your industry and in your firm, what are some of the areas of opportunity where you can create new platforms to data-enable processes, or value to customers. How can you converge the primary and ancillary meaning in your data onto areas of your competitive strategy? And also, you may want to perform an audit of what data you might be giving away, perhaps because you feel that it’s not core to your business or you have a player in the industry who has historically been collecting this data. For example, Experian and credit scores. Ask yourself, are you merely giving away data that you don’t use, or are you handing over the source of competitive differentiation in your industry?
To underscore the earlier point, I believe that value will increasingly migrate, in each industry, to those who best manage, and build strategic and competitive alignment with their data strategies and/or new offerings based on the data and its meaning, while building trust and reducing friction.
Tip: Identify the analog products, services, and processes in your business and try and explore the value of the data if these were digital processes.
Alongside the explosion of value data is the reduction in the unit cost of storage. In 1985, there weren’t too many gigabyte storage options. But a 26 MB drive cost $5,000, which meant you were paying $193,000 per GB. In 1990, the price per GB had dropped to $105,000. In 1995, it was $11,000; in 2000, it dropped to $1,100; and in 2015, it was $0.05. In 2021, on Amazon’s lowest pricing tier, you can get a GB of storage at $0.0125 Do you know anything else that went from a price of $193,000 to $0.0125 in 36 years? You can see why this reduction in storage costs is essential to and possibly an outcome of the explosion of data generation. This goes hand in hand with similar, if not same, reductions in the cost of bandwidth and computing.