
Querying XML
3.1 Introduction
In Chapter 2 we looked at what it means to query data in general and described SQL as a language for querying relational data. In this chapter we discuss the notion of querying XML (which, after all, is why you’re reading this book). XML is quite different from relational data, and it offers its own special challenges and opportunities for the query writer.
We start with the assumption that it is necessary to query the XML representation of data. You could, of course, convert XML data to some other representation (say, relational) and query that representation using some language (such as SQL). Sometimes that is the most appropriate strategy – for example, if the XML data is highly regular and will be queried many times in the same way, you may be able to query it more efficiently in a purely relational context. Often, though, you want to store and represent the data as XML throughout its life (or at least preserve the XML abstraction over your data when querying).
We also assume that you want to do all the things described in Chapter 2 and at least all the things that SQL can do on relational data. Querying XML data is different from querying relational data – it requires navigating around a tree structure that may or may not be well defined (in structure and in type). Also, XML arbitrarily mixes data, metadata, and representational annotation (though the latter is frowned on).
We give some examples of queries in XPath, but this chapter is intended for discussion of querying XML in general terms. As you read the examples, we invite you to map the simple example data onto your own data and to decide how useful the query constructs are in your own environment. After the examples, we introduce some other languages in use today for querying XML. We argue that knowledge of document structure and data types is a good thing and that XQuery 1.0 and XPath 2.0 will be the most important languages for querying XML.
3.2 Navigating an XML Document
Since an XML document is by nature hierarchical, it can be represented easily in a tree diagram. The movie document we introduced in Chapter 1 is represented as a tree diagram in Figure 3-1. The figure is incomplete, but it should give you an idea of what the XML tree looks like.
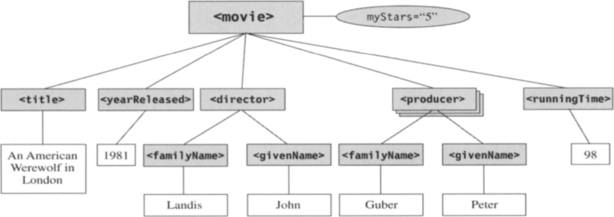
What kinds of questions might you ask about the data represented in Figure 3-1? First, you might want to know the title of this movie. If the data were stored in a relational database and you were querying with SQL, you’d need to know which cell represented the title of this movie (which table, column, row). With an XML document, you can find the title of the movie in two ways.
First, you can ask for the value of the title by name. In English, “return the value of the title element.” That’s fine if the XML document is as simple as this one, but what if there are title elements in more than one place in the tree? For example, a director or producer or cast member might have a title (Mr., Ms., Dr., etc.). What if there is more than one title – say, an English title and a French title?
The second way to ask for the title of the movie is to walk the tree – that is, give explicit instructions on how to navigate from the top of the tree (if this is an XML document, we know that the tree has a single “top” since it’s a rooted tree)1 to the element you are interested in. In English, “start at the top of the tree, move down to the first child element, and return its value.” You could simply walk the structure (if you knew where to go to get the data you want), but it would be useful to be able to apply conditions (predicates) along the way – at least check the names of nodes and, better yet, check the contents of elements and the values of attributes.
As you will read in later chapters, the popular languages for querying XML offer both methods. In XPath, for example, //title returns the element named “title” (actually a sequence of all title elements) anywhere in the document, while/movie/title returns the title by starting at the root node and navigating to the title element that is a child of the movie element. XPath is described in detail in Chapter 9, “XPath 1.0 and XPath 2.0” – in this introductory chapter we give just enough explanation about XPath to understand the examples. // can be read as “at any point in the XML tree,” so that //title means quite simply “at any point in the XML tree, return all nodes with the name title.” In the second example, the leading “/” means “start at the top of the tree.” Any other “/” in the XPath can be read as “go down one level in the tree, i.e., select the children of the current node.” After each “/” (after each step), the result is filtered so that it contains only elements whose names match the name in the XPath expression, i.e., “movie” and then “title.” Note that the “top of the tree” is not the element named “movie,” it’s a notional node2 above the element named “movie.” For more on this notional top node, see Chapter 6, “The XML Information Set (Infoset) and Beyond,” and Chapter 10, “Introduction to XQuery 1.0.”
In the rest of this section, we look in more detail at walking the XML tree.
3.2.1 Walking the XML Tree
Let’s consider the XML document purely as an abstract tree. To traverse or walk a tree, you need to be able to express the following:
• The top node – in XPath, this is called the root node (an imaginary node that sits above the topmost node) and is represented by a leading “/”.
• The current position – in XPath, this is called the context node and is represented by
• The node directly above the current position – in XPath, this is called a reverse step (specifically, the parent) and is represented by “·”.
• The nodes directly below the current position – in XPath, this is a step, and is represented by a “/” (a step separator), typically followed by a condition.
• A condition – in XPath, this can be a node test or a predicate list. A node test is used to test either the name of the node or its kind (element, attribute, comment, etc.). A predicate tests either the position of the node as the N-th child (child nodes are numbered starting from 1) or it tests the value of the node.
Once you can express these five concepts, and you can combine them into an arbitrarily complex expression, you have a language for traversing a tree. In the case of XPath, you have a language for traversing the XML tree and therefore for querying XML. (Of course, XPath offers far more than these five concepts – we’re just describing the basics here.)
Let’s look at some examples using the movies tree (Figure 3-2). Since XML is hierarchical in nature, we can represent any set (or collection) of documents as a single document simply by concatenating them and wrapping them in a pair of element tags. With XML, then, the boundary between documents is often unclear (some have suggested that all the data in the universe could be represented as a single XML document, though we’re not sure what the top-level element should be called).

The following examples illustrate the kinds of tree traversal you might want to do and give solutions in XPath. The explanations describe in a slightly more formal way how the XPath works.
A Simple Walk Down the Tree
In Example 3-1, we simply walk down the tree, starting at the top node and deciding which way to go next according to the names of the child elements – walk to the element named “movies,” then down to the element named “movie,” then down to the element named “title.” In fact, it’s not quite as simple as that – we walk to “movies,” then there are two child nodes named “movie,” so we walk to both at once. Another way to describe the same process is to talk about selecting and filtering a sequence of nodes,3 which is the way the evaluation of an XPath expression is generally described. We select the “movies” node, then we select the sequence of child element nodes with the name “movie,” then we select the sequence of child element nodes with the name “title.” You might prefer to think of this as pruning, rather than walking, the XML tree.

Note that the result of evaluating the XPath expression in Example 3-1 is not a string containing the titles of all the movies in the document – it’s a sequence of nodes (title element nodes). If you want to do anything with the results (other than pass them to a program that knows about sequences of nodes), you need to serialize the results, i.e., convert the results from the data model of your query language into something you can read or print. When you serialize a sequence of title element nodes, it’s reasonable to take the string value of each node4 (take the characters between the start and end tags of the node and convert them to a string), along with some representation of the element tag (“title”).
If you run the XPath expression/movies/movie/title using your favorite XPath engine, it will probably do a good job of serializing the results in an intuitive way. XMLSpy, for example, displays a table where the first column is the name of the element and the second is the value – each row represents a member of the sequence. If you need to convert the node sequence into a sequence of strings (e.g., to pass them into a Java program), you can use/movies/movie/title/text ( ) to pull out the text nodes, but even then you may need to do some more work to map those text nodes into something your host language will understand. See Chapter 14, “XQuery APIs,” for a description of one way to solve that problem.
Adding a Value Predicate
If you want to query the XML data, as opposed to just walking its structure and pulling out values according to their positions, you need to be able to walk (or prune) the tree according to some conditions. Example 3-2 shows how XPath expresses value predicates – now we are walking down the tree, pruning branches that do not meet the predicate condition as we go.

This begs the question of, “What constitutes a match?” For example, if the predicate is “[@myStars=5],” does this match elements where the attribute myStars is “05”? “5.00”? That depends on the data type associated with the myStars attribute and on the assumptions you make about how the “=” operator deals with types (type promotion, casting, etc.). We’ll talk a lot more about data types later in this book.5
Adding a Positional Predicate
Adding a positional predicate (Example 3-3) lets you choose the N-th node from a sequence of nodes. Of course, this implies that there is a persistent ordering to the XML document that you are querying – the XQuery Data Model spec6. defines document order like this: “Informally, document order is the order in which nodes appear in the XML serialization7 of a document.” Document order is one of the things that sets XML data apart from, say, SQL data – in a relational database, the order of rows in a table is undefined, and a query must specify an order explicitly or the results of the query will be unordered.8 In our movies document, order is not significant unless the author gives it some special significance. For example, you might append movies to the end of the document as you watch them so that the last movie in the document is the last movie you watched, though it would be better practice to add an element for “dateWatched” to make this explicit. In general, data-centric XML documents, such as movies, do not rely on document order. On the other hand, document-centric XML documents, such as books, articles, and papers, rely heavily on document order. Without document order, XML authors would have to number every chapter, section, paragraph, bolded term, etc., and explicitly order every query.

The Context Item
Example 3-4 uses contains, which is an XQuery/XPath built-in function9 that takes two string parameters and returns true if the string in the first parameter contains the string in the second parameter. This example illustrates the use of the context item (“. “). The context item indicates the current node being considered, as the predicate is applied to each title element node in turn.

Up the Tree and Down Again
The XPath expression in Example 3-5 illustrates walking down to a leaf node (runningTime), then back up to that node’s parent (![]() ), and then down another branch of the tree (to title) to apply a condition. The equivalent XPath expression noted in the example walks down to movie and then walks down from movie to title to apply a condition and down from movie to runningTime to select the result.
), and then down another branch of the tree (to title) to apply a condition. The equivalent XPath expression noted in the example walks down to movie and then walks down from movie to title to apply a condition and down from movie to runningTime to select the result.

Comparison in Different Parts of the Tree
Example 3-6 involves walking down two different subtrees, and comparing the results.
Example 3-6 Comparison in Different Parts of the Tree

*For simplicity, we assume that directors and producers can be uniquely identified by their family names.
This operation looks quite straightforward, until you consider the case where there is more than one director and/or more than one producer. Comparison of sequences might be defined in a number of ways, including:
1. The condition holds if any director’s name matches any producer’s name (existential comparison10).
2. The condition holds if any director’s name matches all producers’ names.
3. The condition holds if the sequences are identical – i.e., same number of names, same names, in the same order.
4. The condition holds if the first director’s name matches the first producer’s name.
XPath (1.0 and 2.0) uses the first definition of “=” when comparing sequences.
What about comparing nodes rather than values? An element node might contain just text (like familyName), or it might be a complex element, containing subelements (like movie). If you want to know whether two nodes are equal, you might choose:
1. Two nodes are equal if their string values (all the text content between the start and end tags of the element) are equal.
2. Two nodes are equal if they have the same children, in the same order, and those children are equal.
3. Two nodes are equal if they are the same node – that is, you are not comparing two different nodes that happen to have the same content, but you are comparing the exact same node with itself (i.e., the same node from the same document).
XPath (1.0 and 2.0) uses the first definition of “=” when comparing nodes, which can lead to some odd results.11 XQuery 1.0 and XPath 2.0 introduced the deep-equal ( ) function, so you can make the comparison in the second definition, and the “is” operator,12 to enable the comparison in the third definition.
XQuery 1.0 and XPath 2.0 also introduced a new set of comparison operators (eq, ne, It, le, gt, and ge) for comparing values rather than sequences. These new operators are called value comparison operators to distinguish them from the general comparison operators (=, !=, <, <=, >, and >=).
When querying XML, we are often dealing with sequences (ordered lists) rather than single items, and the items in a sequence may be values (strings, integers, dates, …) or nodes (elements, complex elements such as those containing child elements, attributes, …), or a mixture of values and nodes.13
3.2.2 Some Additional Wrinkles
So far in this section, we have presented issues around querying XML using very simple examples on very simple data – the movie and movies documents. Before we leave this section, we must mention a few more common issues, which require a slightly more complicated document. Figure 3-3 is a tree representation of an XML book – the rest of the examples in this section are based on the data represented in Figure 3-3.

Find an Element by Name

At the start of this section, we said you should be able to query XML by asking for an element by name. Example 3-7 shows a simple way to get all the titles from our movies sample, effectively requesting all elements named “title.” But this method is considered dangerous (or at least sloppy) by some people. The method breaks down when the element name “title” is used in more than one place in the tree, as in the book document represented by the tree in Figure 3-3. Here, context is important. Do you really want to find all titles in any context? Or just chapter titles? Or section titles? In general, context is important, and a request by the element name alone doesn’t include any context. If context were not important, we could simplify XML massively by making it a system of name-value pairs.14
Attributes vs. Elements
If you evaluate the XPath expression in Example 3-7 (//title) in the context of the data represented by Figure 3-3 (the book document), you will miss the title of the book. That’s because the book title is an attribute of the book element (while the chapter title is an element child of the chapter element), and //title returns only elements named title.
There are a number of different views on attributes – some people think you should design XML documents that use elements rather than attributes, some think leaf elements and attributes should be entirely interchangeable. Of course, you may well need to query XML data whose structure was designed by someone else – i.e., you just need to query whatever is thrown at you. We’ll just say here that attributes are different from elements (they have different properties),15 and XML query languages should and do treat elements and attributes differently.
Mixed-Content Models and Text Nodes
The movies tree illustrated in Figure 3-2 is very simple – it only has data at its leaf nodes, and each leaf node has exactly one piece of data. This is fairly typical for data-centric XML documents (such as purchase orders). Figure 3-3 is more typical of document-centric XML documents (such as books and reports) – if you were to look at the XML for this document, you’d see element tags sprinkled throughout the text. In XPath, this is represented as a number of child elements plus a number of text nodes (see Chapter 6, “The XML Information Set (Infoset) and Beyond,” for a description of the XPath 1.0 data model and text nodes).
It’s not obvious, without knowing both the structure and the semantics of the data, what a query should search, or return, when confronted with this kind of node (which the XML recommendation calls mixed content). XPath gives us a couple of ways of dealing with it. First, we can filter out all the text nodes. For example,
![]()
returns a sequence of the text nodes of the first paragraph in the first section of the first chapter, i.e., the sequence (“This is the “,” paragraph of “, “.”).16 This result does not include child elements, so the word “first” (which is part of the child element named “emph”), and the phrase “the book” (which is part of the child element named “link”) are missing. Sometimes you do want to collect together only the text nodes, for example, when the tags inside the text represent footnotes or annotations or reviewers’ comments. But in this case the paragraph makes more sense if you take its string value, like this:
![]()
This returns “This is the first paragraph of the book,” which is all the character data between the start and end tags for this paragraph (and no attribute data).17 You will read in Chapter 13, “What’s Missing?,” that it’s particularly difficult to make rules about what is searched, and what is returned when you do full-text search over mixed-content XML.
Querying the Structure Only
We discussed at some length querying XML by walking the XML tree, and we discussed briefly querying by asking for an element by name. There is another way to query XML, which is to use only the structure.
In the context of the movie document in Figure 3-1, / * / * [1] returns the title by starting at the root node and navigating to the first child. The leading “/” means “start at the top of the tree.” “*” is a wildcard, so it means “take all the element nodes at this level, no matter what their names are.” And “[1]” is a positional condition – it means “take just the first node.” So /*/* [1] means “starting from the top of the tree, take all the child element nodes, go down one level, take the first node, and return it.”
Building Up a Result Set
The results returned by the examples in this section are somewhat limited. For example, in Example 3-6 we found the titles of all movies whose director was also a producer. It would be nice to return the title plus the full name of the director/producer and perhaps some other information about the movie (or about the director/producer). XPath is limited in this area – you need XQuery (or XSLT)18 to build up XML result sets.
Documents, Collections, Elements
We said earlier in this chapter (at the start of this section) that, with XML, the distinction between individual documents and collections of documents is not as sharp as, say, the distinction between rows and tables in a SQL database – any collection of documents can be expressed as a single document. Similarly, each document can be seen as a set of subdocuments. This is the nature of tree structures. Sometimes the decision about what to call a document is somewhat arbitrary. Querying XML and returning documents, then, is far too coarse-grained to be generally useful. For example, if you decided to store data about your movies in a collection of movie documents (as in Figure 3-1), then returning the documents that satisfy the query would be somewhat useful.19 On the other hand, if all the movies were in a single document (as in Figure 3-2), then every query would simply return the whole movies document (or nothing). Clearly, an XML query on documents like the movies document needs to return fine-grained results, i.e., results that are subtrees at any level (including leaves).20
3.2.3 Summary – Things to Consider
The examples in the previous section illustrate a number of the factors that make querying XML interesting. Let’s summarize here before moving on.
• XML is hierarchical, and you can think of an XML document as a tree.
• When querying XML, you must be able at least to ask for an element by name and walk the XML tree. When walking the tree, you must be able to go up, down, and across and apply conditions. You should be able to walk the XML tree without knowing the names of any of the elements or attributes.
• When querying XML, you are likely to be working with sequences of nodes and values. You need special rules to define how to compare nodes and sequences of nodes, and you need special rules to define how to serialize (output) nodes and sequences of nodes.
• In many (but not all) XML documents, document order is important.
• When comparing values, the data types of the values is generally important.
• “//” is considered by many to be dangerous (and expensive) – it’s a simple way to get to a named element, but it may give unexpected results if the structure of the data changes.
• Elements and attributes are different – if you expect to see attributes in your query result, you generally need to do something extra to get them.
• Mixed content – an element that contains a mixture of text and child elements – presents issues around what should be taken into account when querying and what should be returned.
• It is often useful to build up a result set, typically in XML. XPath is limited here, though XQuery can build arbitrarily complex XML output.
3.3 What Do You Know about Your Data?
We have often heard that one of the big advantages of XML is that it’s so flexible. Compared to SQL, say, where you have to put a lot of effort into data modeling to define the properties of your data – its structure, data types, relationships to other data – XML is simple and easy to use. Just open up a text editor and start writing tags. We hope that, having read the introductory chapters to this book, you can already see the shortcomings of this worldview.
Knowing about Structure
It’s very difficult to query data if you don’t know how it’s laid out. Just as it would be impossible to write a SQL query if you didn’t know how the data was laid out in tables and columns, it’s impossible to query XML unless you know something about how the XML documents you are querying are structured. For example, if you want to find the titles of all movies released in 1985, you have to know which part of the XML tree contains the title, which part contains the year released, and at least something about how they are related. You read in the section with the heading “Attributes vs. Elements” that if your query looks for a piece of data in an element but the data occurs in an attribute, then your query will miss it. To query XML in the simplest possible way (walking the XML tree, paying attention to context, and preferably using node names along the way to improve robustness) you have to know something about the structure of the document.
Knowing about Data Types
If you want to include conditions in your query, in general you’ll need to know about the data types you are dealing with (though you can get a long way with the simple type system in XPath 1.0). If the XML documents you are querying are text-centric, then data typing is less important.
Knowing about the Semantics of the Data
Clearly, there is no point in searching for “titles” if you don’t know what a “title” is – you need to know the semantics of the XML data in order to write sensible queries.
We have often heard that XML is “self-describing,” meaning that an XML document contains content plus metadata about that content. In fact, XML documents typically contain content plus metadata plus marked-up content. The marked-up content may be marked up to provide additional semantic information about the data, or it may be marked up to provide presentation information about the data (though this is rightly frowned on). There is no way to distinguish between these different elements in an XML document without some outside reference.
XML element names should (but do not always!) say something about the data they enclose. But the tags do not describe the data in any way that can be used by a query language or any other application. In our movies example, we could just as easily have used “film” as “movie” in the tag names. Similarly, there’s no way to tell how the “yearReleased” data was derived. Was it the year the movie was first shown in some theater in the United States? Or was it the year when the first DVD was released in Europe? And how do you know that all the data is about movies? There’s nothing preventing us from adding plays, books, and songs and keeping the same tags. At best, tag names merely give some hints about what the data represents.
In some cases we know very little about the data we are querying. The obvious case is the web, which contains billions of documents with a loosely defined structure and almost no metadata or semantic information. We discuss this scenario in Chapter 18, “Finding Stuff.” But in most cases, you know – and need to know – all about the data you are querying. For effective, accurate, and efficient querying of XML, as with querying any data, you should know the structure of the data, the types of the data, and the semantics of the data. An XML document on its own is not self-describing, but an XML document plus a DTD or XML Schema plus an XML language definition does fully describe the data.
3.4 Some Ways to Query XML Today
We use XPath in this chapter to illustrate querying XML, but there are other ways to query XML.
The Document Object Model (DOM) defines an interface to the data and structure of an XML (or HTML) document so that a program can navigate and manipulate them. Using the DOM API (Application Programming Interface), you can write a program to return values of named elements/attributes or to walk the XML tree and return values of elements and/or attributes at specified positions in the tree. The DOM API also supports manipulation of the tree – inserting and deleting elements and attributes. The DOM is a popular API for accessing and manipulating XML (for example, it’s used in JavaScript), but by itself it’s not very useful for querying XML. The DOM is largely untyped – element content and attribute values are returned as strings – so you have to explicitly cast values in order to perform comparison operations that depend on type (equality, greater than, less than, and so on). We describe the DOM in Chapter 6, “The XML Information Set (Infoset) and Beyond.”
The Simple API for XML (SAX) and the Streaming API for XML (StAX) are described in Chapter 14, “XQuery APIs.” Like the DOM, these are both APIs rather than query languages, but they are popular ways to walk the XML tree and return results. SAX is an event-based API for XML, for use with Java and other languages. To write a SAX program you will need to obtain a SAX XML parser and then register an event handler to define a callback method for elements, for text, and for comments. SAX is a serial access API, which means you cannot go back up the tree, or rearrange nodes, as you can with DOM. But SAX has a smaller footprint and is more flexible.
StAX is a Java pull parsing API. That is, StAX lets you pull the next item in the document as it parses. You (the calling program) decide when to pull the next item (whereas with an event-based parser, it’s the parser that decides when to cause the calling program to take some action). StAX also lets you write XML to an output stream.
Lastly, XQuery is a language defined by the W3C specifically for querying XML data. It is a strongly typed, expression-based, highly expressive language. XQuery 1.0 also includes the XPath 2.0 expressions. Manually coding programs to manipulate DOM or SAX is tedious and error-prone, and a standardized query language that eliminates the need for manual coding of parsing operations will increase productivity and improve software quality. We confidently predict that, while APIs such as DOM, SAX, and StAX (and their cousins such as JAXP and JAXB) will continue to be used for general-purpose XML access and manipulation, XQuery 1.0 and XPath 2.0 will become the standard way to query XML.
Many people believe that SQL/XML (the extensions to SQL first introduced as part of SQL:2003) competes with XQuery as an XML query language. As you will read in Chapter 15, “SQL/XML,” that’s not true! SQL/XML provides an API – a harness – for querying XML data in a SQL environment, using XPath and XQuery to query the XML structure and values.
3.5 Chapter Summary
In this chapter we discussed querying XML – the process of either retrieving element contents and attribute values by requesting them by name or walking the XML tree, possibly with some conditions, and retrieving values or subtrees from that XML data. We gave some examples of queries involving walking the XML tree, illustrated with XPath expressions, and introduced some of the challenges of querying XML. We argued that if you know more about the data you are querying – its structure and data types – then you can formulate better (more accurate, more efficient) queries. Lastly, we introduced a number of ways to query XML today and argued that XQuery 1.0 and XPath 2.0 will be the standard languages for querying XML.
This introductory part of the book – Chapters 1, 2, and 3 – provide a framework for understanding the rest of the book. Now that you have read these first three chapters, you are ready to dig deeper into Querying XML.
1See Chapter 6, “The XML Information Set (Infoset) and Beyond.”
2The top node is notional, in the sense that it doesn’t map to anything in the serialized XML document. When looking at an XML document on a page (or on a screen), you have to imagine this top node.
3The XPath 1.0 spec refers to a node set, even though document order is preserved. In this chapter, we use the term node sequence, which is used in the XQuery 1.0 and XPath 2.0 spec.
4For details on how XQuery 1.0 and XPath 2.0 defines serialization, see XSLT 2.0 and XQuery 1.0 Serialization (Cambridge, MA: World Wide Web Consortium, 2005). Available at: http://www.w3.org/TR/xslt-xquery-serialization/.
5Especially in Chapter 6, “The XML Information Set (Infoset) and Beyond,” and Chapter 10, “Introduction to XQuery 1.0.”
6XML Path Language (XPath) Version 1.0 (Cambridge, MA: World Wide Web Consortium, 2005). Available at: http://www.w3.org/TR/xpath-datamodel/
7You can think of serialization as “the way XML is written down on paper (or displayed on a screen),” as opposed to any abstract model of the data. You’ll read more about serialization in Chapter 10, “Introduction to XQuery 1.0.”
8By unordered we mean “in no particular order.” SQL query results are not generally in random order; they are ordered in some implementation-specific way, but the SQL user cannot rely on that order.
9XQuery 1.0 and XPath 2.0 Functions and Operators (Cambridge, MA: World Wide Web Consortium, 2005). Available at
http://www.w3.org/TR/xpath-functions/.
10Existential comparison means that this expression evaluates to true if there exists any pair of values, one taken from the sequence specified on the left side of the comparison operator and the other taken from the sequence specified on the right side, for which the comparison operator yields true.
11For example, in the XML snippet

the elements w and z are equal according to this rule, since both have the string value “abcdefghi.” See Bob DuCharme, Transforming XML, Seeking Equality (XML.com, 2005). Available at: http://www.xml.eom/pub/a/2005/06/08/tr.html.
12In some earlier drafts of the XQuery 1.0 and XQuery 2.0 Functions and Operators spec, there was a built-in function node-id ( ) for this purpose.
13This is how XQuery 1.0 defines a sequence, which is its basic unit of operation. Other languages for querying XML have less flexible data models.
14Another consideration here is efficiency. If your query engine is doing a simple tree walk (as is common with simple DOM implementations), then //title may involve examining every node in the document. If the document is large, this can be horribly expensive. On the other hand, more sophisticated implementations will use an index rather than actually walking the XML tree.
15For example, attributes have no implicit order, they cannot have children, and they do not have a parent-child relationship with the element they appear in. Attributes are conceptually “stuck on the side” of the XML tree.
16We wrote this as a sequence of strings, but the careful reader will notice that it is, in fact, a sequence of text nodes.
17It’s not obvious from the tree diagram, but all the white space in “This is the first paragraph of the book” is present in the character data between the start and end tags for this paragraph – taking the string value doesn’t add any white space, so it doesn’t always give you the result you might expect. The serialized form of this paragraph element is:
<paragraph>This is the <emph>first</emph> paragraph of <link href=“Error! Hyperlink reference not valid. book</link>.</paragraph>
18XSLT (XSL transformations) is a language for transforming XML documents into other XML documents, which makes heavy use of XPath. See: XSL Transformations (XSLT) Version 1.0 (Cambridge, MA: World Wide Web Consortium, 1999). Available at: http://www.w3.org/TR/xslt.
19In SQL terms, this would satisfy the requirement for selection but not projection.
20That is, XML query needs to do both selection and projection of arbitrary subtrees.