
Chapter 3. Autoscaling Knative Services
Serverless-style architecture is not only about terminating your services when they are not in use but also about scaling them up based on demand. Knative handles these requirements effectively using its scale-to-zero and autoscaling capabilities:
- Scale-to-zero
-
After a time of idleness your Knative Serving Service’s Revision is considered to be inactive. Knative will terminate all the pods that correspond to that inactive Revision, and the Routes for that inactive Revision will be mapped to Knative Serving’s activator service. The activator becomes the endpoint for receiving and buffering your end-user’s HTTP traffic, to allow for the autoscaler—that is, the Knative Service’s ability to scale from zero to n pods—to do its job.
- Autoscaling
-
Autoscaling is the ability for the Knative Service to scale out its pods based on inbound HTTP traffic. The autoscaling feature of Knative is managed by:
The HPA relies on three important metrics: concurrency, requests per second, and cpu. The KPA can be thought of as an extended version of the HPA with a few tweaks to the default HPA algorithms to make it more suited to handle the more dynamic and load-driven Knative scaling requirements.
Note
With our current setup of a Kubernetes cluster with minikube, which is a smaller cluster with limited resources, it is easy to demonstrate the autoscaling using the concurrency metric. Hence, all the recipes in this chapter focus on the concurrency metric.
Before You Begin
All the recipes in this chapter will be executed from the directory $BOOK_HOME/scaling, so change to the recipe directory by running:
$cd$BOOK_HOME/scaling
The recipes of this chapter will deployed in the chapter-3 namespace, so switch to the chapter-3 namespace with the following command:
$kubectlconfigset-context--current--namespace=chapter-3
3.1 Configuring Knative Service for Autoscaling
Solution
All the scale-to-zero and autoscaling parameters are defined in a Kubernetes ConfigMap called config-autoscaler in the knative-serving namespace. You can view the ConfigMap with a simple kubectl command:
$kubectl-nknative-servinggetcmconfig-autoscaler-oyaml
The following code snippet provides an abridged version of the config-autoscaler ConfigMap contents. We focus on the few properties that impact the recipes included in this chapter:
apiVersion:v1data:container-concurrency-target-default:"100"enable-scale-to-zero:"true"stable-window:"60s"scale-to-zero-grace-period:"30s"
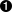
The default container concurrency for each service pod; defaults to
100
Flag to enable or disable scale down to zero; defaults to
true
The time period in which the requests are monitored for calls and metrics; defaults to
60 seconds
The time period within which the inactive pods are terminated; defaults to
30 seconds
Discussion
Each Knative Service pod is configured to handle 100 concurrent requests from its clients. The property container-concurrency-target-default of the config-autoscaler ConfigMap is used to configure the concurrency for each service pod; when the concurrent requests reach this limit, Knative Serving will scale up additional pods to handle the excess load.
The scale-to-zero—that is, the ability of Knative to terminate the inactive pods—can be controlled by the property enable-scale-to-zero. The default is true, which instructs Knative to scale-to-zero the pod if it has not received requests within the stable-window interval. You disable scale-to-zero to by setting this property to false.
The stable-window is the time period in which the autoscaler is monitoring requests/metrics; if there are zero requests to a pod over the default 60 seconds, then the autoscaler will begin to scale-to-zero by setting it to inactive.
The scale-to-zero-grace-period is the time period in which the autoscaler is monitoring inactive pods and will attempt to terminate those pods.
The recipes in this chapter rely on the defaults and any overridden configuration will be seen as annotations on the Knative Serving Service YAML. Check config-autoscaler for a list of all possible autoscaling properties.
3.2 Observing Scale-to-Zero
Solution
After deployment of your Knative Service as described in Chapter 2, simply watch the pod lifecycle with the following command:
$watchkubectlgetpods
Tip
Use the watch command in a new terminal window, as that will allow you to observe the scale-to-zero and autoscaling from zero to N. You can monitor the AGE column of the pod to measure how long it takes to scale down. By default, it should happen shortly after 60 seconds but before 90 seconds.
If you have not deployed the greeter Knative Serving Service, run:
$kubectl-nchapter-3apply-f$BOOK_HOME/basics/service.yamlservice.serving.knative.dev/greetercreated
Open a new terminal window and watch the pod lifecycle with the command:
$watchkubectlgetpodsNAMEREADYSTATUSAGEgreeter-v1-deployment-b8db5486c-jl9gv2/2Running8s
And as you wait and watch, you will see the pod terminate:
NAME READY STATUS AGE greeter-v1-deployment-b8db5486c-jl9gv 2/2 Terminating 64s
To make sure the pod is up and running, use the script call.sh:
$$BOOK_HOME/bin/call.shHigreeter=>9861675f8845:1
Discussion
The mapping from the actual service URL to the Knative activator URL is transparent and is not visible by viewing the Knative Route of the corresponding Knative Service. The reprogramming of the network from the actual service pod to the activator pod in knative-serving is asynchronous in nature, so the scale-to-zero-grace-period should provide enough slack for this to happen. Once the stable-window scale-to-zero-grace-period is exceeded, the Revision will be scaled-to-zero replicas and those pods will be terminated.
When another request targets an inactive Revision, the activator intercepts that request and will instruct the Knative autoscaler to create new pods for that service Revision.
3.3 Configuring Your Knative Service to Handle Request Spikes
Solution
In your Knative Serving Service YAML, you can add annotations that will override the default behavior and autoscaling parameters:
autoscaling.knative.dev/target:"10"
The following listing illustrates the Knative Service Revision Template that adds the container concurrency annotation to reconfigure it from the default 100 to 10:
apiVersion:serving.knative.dev/v1alpha1kind:Servicemetadata:name:prime-generatorspec:template:metadata:name:prime-generator-v1annotations:# Target 10 in-flight-requests per pod.autoscaling.knative.dev/target:"10"spec:containers:-image:quay.io/rhdevelopers/prime-generator:v27-quarkuslivenessProbe:httpGet:path:/healthzreadinessProbe:httpGet:path:/healthz
Configure the container concurrency to be 10
Discussion
By default, the Knative Service container concurrency is set to 100 requests per pod. With the autoscaling.knative.dev/target annotation you are now overriding that value to be 10. You may also set this value to 0, where Knative will autoconfigure the value. In the absence of the annotation autoscaling.knative.dev/target, Knative by default sets this value to be 0.
Since we need to simulate the slowness in response to observe autoscaling, the service that you will use for doing the load test is a prime number generator using the Sieve of Eratosthenes. The Sieve of Eratosthenes is one of the slowest and least optimal ways to compute prime numbers within a range. The application tries to spice up the slowness by adding memory load, which makes the Knative Service respond slowly, thereby allowing it to autoscale.
Navigate to the recipe directory $BOOK_HOME/scaling and run:
$kubectlapply-nchapter-3-fservice-10.yaml
The very first deployment of a Knative Serving Service will automatically scale to a single pod; wait for that service pod to come up:
$watchkubectlget-nchapter-3podsNAMEREADYSTATUSAGEprime-generator-v1-deployment-7464d56df-zhxzw2/2Running5s
You can test the prime-generator service by using the script $BOOK_HOME/bin/call.sh with the service name prime-generator as a parameter:
$$BOOK_HOME/bin/call.shprime-generatorValueshouldbegreaterthan1butrecevied0
In order to verify your updated concurrency setting (e.g., autoscaling.knative.dev/target: "10") you need to drive enough load into the system to observe its behavior.
Sending 50 concurrent requests will cause the Knative autoscaler to scale up 7 service pods. The formula to calculate the target number of pods is as follows:
number of pods = total number of requests / container-concurrency
In the sample code repository, we have provided a load testing script called load.sh, and it leverages a command-line utility called hey. Run the following command to send 50 concurrent requests to the prime-generator service:
#!/bin/bash hey -c 50 -z 10s
Invoke the
heyload testing tool with a concurrency of50requests and for a duration of10secondsAs you did earlier, pass the
Hostheader; in this case it will beprime-generator.chapter-3.example.comThe request URL parameters:
sleepSimulates slow-performing operations so that the requests pile up by sleeping for
3 secondsuptoCalculates the prime number up to this maximum
loadSimulates the memory load of
100 megabytes(mb)
To watch the autoscaling in action, you should open two terminal windows, one to run the watch command watch kubectl get pods -n chapter-3 and the other to run the load test script $BOOK_HOME/bin/load.sh.
$$BOOK_HOME/bin/load.sh
$watchkubectlgetpodsNAMEREADYSTATUSAGEprime-generator-v1-deployment-6b8c59c85b-2tnb92/2Running5sprime-generator-v1-deployment-6b8c59c85b-522952/2Running9sprime-generator-v1-deployment-6b8c59c85b-67jdm2/2Running7sprime-generator-v1-deployment-6b8c59c85b-dm4zm2/2Running7sprime-generator-v1-deployment-6b8c59c85b-fwghr2/2Running7sprime-generator-v1-deployment-6b8c59c85b-rfm972/2Running7sprime-generator-v1-deployment-6b8c59c85b-trmtl2/2Running3s
Based on the parameters provided to the load testing script and the value of autoscaling.knative.dev/target: "10", you will see more than 7 pods springing to life.
If you continue watching the pod lifecycle and do not continue to send in load, you will see that Knative will aggressively start to terminate unneeded pods:
NAME READY STATUS AGE prime-generator-v1-deployment-6b8c59c85b-2tnb9 2/2 Terminating 66s prime-generator-v1-deployment-6b8c59c85b-52295 2/2 Running 70s prime-generator-v1-deployment-6b8c59c85b-67jdm 2/2 Terminating 68s prime-generator-v1-deployment-6b8c59c85b-dm4zm 2/2 Terminating 68s prime-generator-v1-deployment-6b8c59c85b-fwghr 2/2 Terminating 68s prime-generator-v1-deployment-6b8c59c85b-rfm97 2/2 Terminating 68s prime-generator-v1-deployment-6b8c59c85b-trmtl 2/2 Terminating 64s
3.4 Cold Start Latency
Solution
The minScale and maxScale annotations on the Knative Service Template allow you to set limits on the minimum and maximum number of pods that can be scaled:
- minScale
-
By default, Knative will scale-to-zero—that is, your service will scale-to-zero pods when no requests arrive within the
stable-windowtime period. When the next requests come in, Knative will autoscale to the appropriate number of pods to handle those requests. This starting from zero and the associated wait time is known as cold start latency.If your application needs to stay particularly responsive and/or has a long startup time, then it may be beneficial to keep a minimum number of pods always up. This technique is also called pod warming. With Knative Serving this is achieved by adding the annotation
autoscaling.knative.dev/minScaleto the Knative Service YAML. - maxScale
-
Knative by default does not set an upper limit to the number of pods. This means you are at risk of exceeding your computational resource limits. In order to mitigate the risk, Knative Serving allows you to add the annotation
autoscaling.knative.dev/maxScaleto the Knative Service YAML. WithmaxScaleyou can restrict the upper limit of the autoscaler.
In the following section you will set the minScale and maxScale on the Knative Service Revision Template and run a load test. You will notice that the autoscaling will max out at 5 pods and once the requests are responded to, it will scale down to 2 and not 0.
The following code snippet shows the Knative Service Revision Template with minScale and maxScale annotations configured:
apiVersion:serving.knative.dev/v1alpha1kind:Servicemetadata:name:prime-generatorspec:template:metadata:name:prime-generator-v2annotations:# the minimum number of pods to scale down toautoscaling.knative.dev/minScale:"2"# the maximum number of pods to scale up toautoscaling.knative.dev/maxScale:"5"# Target 10 in-flight-requests per pod.autoscaling.knative.dev/target:"10"spec:containers:-image:quay.io/rhdevelopers/prime-generator:v27-quarkuslivenessProbe:httpGet:path:/healthzreadinessProbe:httpGet:path:/healthz
The minimum number of pods is set to
2; these pods should always be available even after the Knative Service has exceeded thestable-window.The maximum number of pods is set to
5, the number of pods the service can scale up to when it receives more requests than its container concurrency limits.
To see these settings in action, first watch your pod lifecycle with the following command:
$watchkubectlgetpodsNoresourcesfound.
Depending on when you last invoked call.sh or load.sh, there should be no pods available as Knative would have terminated the inactive pods.
Now, apply an update to the prime-generator service that includes the minScale and maxScale annotations:
$kubectlapply-nchapter-3-fservice-min-max-scale.yaml
You should see an immediate response in your watch kubectl get pods terminal as shown here:
$watchkubectlgetpodsNAMEREADYSTATUSAGEprime-generator-v2-deployment-84f459b57f-8kp6m2/2Running14sprime-generator-v2-deployment-84f459b57f-rlrqt2/2Running10s
Discussion
You will notice that the prime-generator has been scaled up to 2 replicas as described by the autoscaling.knative.dev/minScale value and those pods will not be automatically scaled down to zero even after the termination period.
The final test is to attempt to overload the service with too many requests by running the load test script $BOOK_HOME/bin/load.sh. You will observe that maxScale will limit the autoscaler to 5 pods:
$$BOOK_HOME/bin/load.sh
$watchkubectlgetpodsNAMEREADYSTATUSAGEprime-generator-v2-deployment-84f459b57f-6vxxx2/2Running5sprime-generator-v2-deployment-84f459b57f-8kp6m2/2Running2m35sprime-generator-v2-deployment-84f459b57f-8trh22/2Running5sprime-generator-v2-deployment-84f459b57f-ldg8m2/2Running5sprime-generator-v2-deployment-84f459b57f-rlrqt2/2Running2m39s
And if you wait long enough, without another spike in requests, Knative Serving will scale down the unwanted pods:
NAME READY STATUS AGE prime-generator-v2-deployment-84f459b57f-6vxxx 2/2 Terminating 68s prime-generator-v2-deployment-84f459b57f-8kp6m 2/2 Running 10m prime-generator-v2-deployment-84f459b57f-8trh2 2/2 Terminating 68s prime-generator-v2-deployment-84f459b57f-ldg8m 2/2 Terminating 68s prime-generator-v2-deployment-84f459b57f-rlrqt 2/2 Running 10m
In this chapter, you learned about Knative Serving autoscaling behaviors by observing the default configuration and behavior, overriding the default Knative Serving concurrency configuration, and addressing cold start latency and an unlimited upper boundary.
In the next chapter, you will learn how to make your Knative Service respond to external events, such as a message received at a message broker topic.