
Understanding or controlling a physical system often requires a model of the system, that is, knowledge of the characteristics and structure of the system. A model can be a predefined structure or can be determined solely through data. In the case of Kalman filtering, we create a model and use the model as a framework for learning about the system.
What is important about Kalman filters is that they rigorously account for uncertainty in a system that you want to know more about. There is uncertainty in the model of the system, if you have a model, and uncertainty (i.e., noise) in measurements of a system.
A system can be defined by its dynamical states and its parameters, which are nominally constant. For example, if you are studying an object sliding on a table, the states would be the position and velocity. The parameters would be the mass of the object and the friction coefficient. There might also be an external force on the object that we might want to estimate. The parameters and states compose the model. You need to know both to properly understand the system. Sometimes it is hard to decide if something should be a state of a parameter. Mass is usually a parameter, but in a plane, car, or rocket where the mass changes as fuel is consumed, it is often modeled as a state.
Kalman filters, invented by R. E. Kalman and others, are a mathematical framework for estimating or learning the states of a system. An estimator gives you statistically best estimates of the position and velocity. Kalman filters can also be written to identify the parameters of a system. Thus, the Kalman filter provides a framework for both state and parameter identification.
This field is also known as system identification. System identification is the process of identifying the structure and parameters of any system. For example, with a simple mass on a spring it would be the identification or determination of the mass and spring constant values along with determining the differential equation for modeling the system. It is a form of machine learning that has its origins in control theory. There are many methods of system identification. In this chapter we will study only the Kalman filter. The term “learning” is not usually associated with estimation, but it is really the same thing.
An important aspect of the system identification problem is determining what parameters and states can actually be estimated given the measurements that are available. This applies to all learning systems. The question is can we learn what we need to know about something through our observations? For this we want to know if a parameter or state is observable and can be independently distinguished. For example, suppose we are using Newton’s law ![]() (10.1)
(10.1)
where F is force, m is mass, and a is acceleration as our model, and our measurement is acceleration. Can we estimate both force and mass? The answer is no because we are measuring the ratio of force to mass ![]() (10.2) We can’t separate the two. If we had a force sensor or a mass sensor we could determine each separately. You need to be aware of this issue in all learning systems including Kalman filters.
(10.2) We can’t separate the two. If we had a force sensor or a mass sensor we could determine each separately. You need to be aware of this issue in all learning systems including Kalman filters.
10.1 A State Estimator
10.1.1 Problem
You want to estimate the velocity and position of a mass attached through a spring and damper to a structure. The system is shown in Figure 10.1. m is the mass, k is the spring constant, c is the damping constant, and F is an external force. x is the position. The mass moves in only one direction.

Figure 10.1 Spring-mass-damper system. The mass is on the right. The spring is on the top to the left of the mass. The damper is below.
The continuous-time differential equations modeling the system are ![]() (10.3)
(10.3)
![]() (10.4)
(10.4)
This says the change in position r with respect to time t is the velocity v. The change in velocity with respect to time is an external force, minus the damping constant times velocity, minus the spring constant times the position. The second equation is just Newton’s law where ![]() (10.5)
(10.5)
![]() (10.6)
(10.6)
To simplify the problem we divide both sides of the second equation by mass and get ![]() (10.7)
(10.7)
![]() (10.8)
(10.8)
where ![]() (10.9)
(10.9)
![]() (10.10)
(10.10)
a is the acceleration, ![]() , ζ is the damping ratio, and ω is the undamped natural frequency. The undamped natural frequency is the frequency at which the mass would oscillate if there was no damping. The damping ratio indicates how fast the system damps and what level of oscillations we observe. With a damping ratio of 0, the system never damps and the mass oscillates forever. With a damping ratio of 1, you don’t see any oscillation. This form makes it easier to understand what damping and oscillation to expect. c and k don’t make this clear.
, ζ is the damping ratio, and ω is the undamped natural frequency. The undamped natural frequency is the frequency at which the mass would oscillate if there was no damping. The damping ratio indicates how fast the system damps and what level of oscillations we observe. With a damping ratio of 0, the system never damps and the mass oscillates forever. With a damping ratio of 1, you don’t see any oscillation. This form makes it easier to understand what damping and oscillation to expect. c and k don’t make this clear.
The following simulation generates damped waveforms.
%% Damping ratio Demo
% Demonstrate an oscillator with different damping ratios.
%% See also
% RungeKutta, RHSOscillator, TimeLabel
%% Initialize
nSim = 1000; % Number of simulation steps
dT = 0.1; % Time step (sec)
d = RHSOscillator; % Get the default data structure
d.a = 0.0; % Disturbance acceleration
d.omega = 0.2; % Oscillator frequency
zeta = [0 0.2 0.7071 1];
%% Simulation
xPlot = zeros(length(zeta),nSim);
s = cell(1,4);
for j = 1:length(zeta)
d.zeta = zeta(j);
x = [0;1]; % Initial state [position;velocity]
s{j} = sprintf(’\zeta␣=␣%6.4f’,zeta(j));
for k = 1:nSim
% Plot storage
xPlot(j,k) = x(1);
% Propagate (numerically integrate) the state equations
x = RungeKutta( @RHSOscillator, 0, x, dT, d );
end
end
%% Plot the results
[t,tL] = TimeLabel(dT*(0:(nSim-1)));
PlotSet(t,xPlot,’x␣label’,tL,’y␣label’,’r’,’figure␣title’,’Damping␣Ratios’,’legend’,s,’plot␣set’,{1:4})
The results of the simulation are shown in Figure 10.2. The initial conditions are a zero position and a velocity of 1. The responses to different levels of damping ratios are seen.

Figure 10.2 Spring-mass-damper system simulation with different damping ratios.
This is in true state-space form because the derivative of the state vector  (10.11) has nothing multiplying it.
(10.11) has nothing multiplying it.
The right-hand side for the state equations (first-order differential equations) is shown in the following listing. Notice that if no inputs are requested, it returns the default data structure. The if (nargin < 1) code tells the function to return the data structure if no inputs are given. This is a convenient way of helping people to use your functions.
%% RHSOSCILLATOR Right hand side of an oscillator.
%% Form
% xDot = RHSOscillator( ~, x, a )
%
%% Description
% An oscillator models linear or rotational motion plus many other
% systems. It has two states, position and velocity. The equations of
% motion are:
%
% rDot = v
% vDot = a - 2*zeta*omega*v - omega^2*r
%
% This can be called by the MATLAB Recipes RungeKutta function or any MATLAB
% integrator. Time is not used.
%
% If no inputs are specified it will return the default data structure.
%
%% Inputs
% t (1,1) Time (unused)
% x (2,1) State vector [r;v]
% d (.) Data structure
% .a (1,1) Disturbance acceleration (m/s^2)
% .zeta (1,1) Damping ratio
% .omega (1,1) Natural frequency (rad/s)
%
%% Outputs
% x (2,1) State vector derivative d[r;v]/dt
%
function xDot = RHSOscillator( ~, x, d )
if( nargin < 1 )
xDot = struct(’a’,0,’omega’,0.1,’zeta’,0);
return
end
xDot = [x(2);d.a-2*d.zeta*d.omega*x(2)-d.omega^2*x(1)];
The following listing is the simulation script. It causes the right-hand side to be numerically integrated. We start by getting the default data structure from the right-hand side. We fill it in with our desired parameters.
%% Initialize
nSim = 1000; % Simulation end time (sec)
dT = 0.1; % Time step (sec)
dRHS = RHSOscillator; % Get the default data structure
dRHS.a = 0.1; % Disturbance acceleration
dRHS.omega = 0.2; % Oscillator frequency
dRHS.zeta = 0.1; % Damping ratio
x = [0;0]; % Initial state [position;velocity]
baseline = 10; % Distance of sensor from start point
yR1Sigma = 1; % 1 sigma position measurement noise
yTheta1Sigma = asin(yR1Sigma/baseline); % 1 sigma angle measurement noise
%% Simulation
xPlot = zeros(4,nSim);
for k = 1:nSim
% Measurements
yTheta = asin(x(1)/baseline) + yTheta1Sigma*randn(1,1);
yR = x(1) + yR1Sigma*randn(1,1);
% Plot storage
xPlot(:,k) = [x;yTheta;yR];
% Propagate (numerically integrate) the state equations
x = RungeKutta( @RHSOscillator, 0, x, dT, dRHS );
end
%% Plot the results
yL = {’r␣(m)’ ’v␣(m/s)’ ’y_ heta␣(rad)’ ’y_r␣(m)’};
[t,tL] = TimeLabel(dT*(0:(nSim-1)));
PlotSet( t, xPlot, ’x␣label’, tL, ’y␣label’, yL,...
’plot␣title’, ’Oscillator’, ’figure␣title’, ’Oscillator’ );
The results of the simulation are shown in Figure 10.3. The input is a disturbance acceleration that goes from zero to its value at time t = 0. It is constant for the duration of the simulation. This is known as a step disturbance. This causes the system to oscillate. The magnitude of the oscillation slowly goes to zero because of the damping. If the damping ratio were 1, we would not see any oscillation.

Figure 10.3 Spring-mass-damper system simulation. The input is a step acceleration. The oscillation slowly damps out; that is, it goes to zero over time. The position develops an offset because of the constant acceleration.
The offset is found analytically by setting v = 0. Essentially, the spring force is balancing the external force. ![]() (10.12)
(10.12)
![]() (10.13) We have now completed the derivation of our model and can move on to building the Kalman filters.
(10.13) We have now completed the derivation of our model and can move on to building the Kalman filters.
10.1.2 Solution
Kalman filters can be derived from Bayes’ theorem. What is Bayes’ theorem? Bayes’ theorem is ![]() (10.14)
(10.14)
![]() (10.15)
(10.15)
which is just the probability of A
i
given B. P means “probability.” The vertical bar | means “given.” This assumes that the probability of B is not zero; that is, P(B) ≠ 0. In the Bayesian interpretation, the theorem introduces the effect of evidence on belief. This provides a rigorous framework for incorporating any data for which there is a degree of uncertainty. Put simply, given all evidence (or data) to date, Bayes’ theorem allows you to determine how new evidence affects the belief. In the case of state estimation, this is the belief in the accuracy of the state estimate.

Figure 10.4 The Kalman filter family tree.
Figure 10.4 shows the Kalman filter family and how it relates to the Bayesian filter. In this book we are covering only the ones in the colored boxes. The complete derivation is given below; this provides a coherent framework for all Kalman filtering implementations. The different filters fall out of the Bayesian models based on assumptions about the model and sensor noise and the linearity or nonlinearity of the measurement and dynamics models. All of the filters are Markov; that is, the current dynamical state is entirely predictable from the previous state. Particle filters are not addressed in this book. They are a class of Monte Carlo methods. Monte Carlo (named after the famous casino) methods are computational algorithms that rely on random sampling to obtain results. For example, a Monte Carlo approach to our oscillator simulation would be to use the MATLAB function nrandn to generate the accelerations. We’d run many tests to verify that our mass moves as expected.
10.1.3 How It Works
Our derivation will use the notation N(μ, σ 2) to represent a normal, which is another word for Gaussian, variable, which means it is distributed as the normal distribution with mean μ (average) and variance σ 2. The following code computes a Gaussian or Normal distribution around a mean of 2 for a range of standard deviations. Figure 10.5 shows a plot. The height of the plot indicates how likely a given measurement of the variable is to have that value.
%% Initialize
mu = 2; % Mean
sigma = [1 2 3 4]; % Standard deviation
n = length(sigma);
x = linspace(-7,10);
%% Simulation
xPlot = zeros(n,length(x));
s = cell(1,n);
for k = 1:length(sigma)
s{k} = sprintf(’Sigma␣=␣%3.1f’,sigma(k));
f = -(x-mu).^2/(2*sigma(k)^2);
xPlot(k,:) = exp(f)/sqrt(2*pi*sigma(k)^2);
end
%% Plot the results
h = figure;
set(h,’Name’,’Gaussian’);
plot(x,xPlot)
grid
xlabel(’x’);
ylabel(’Gaussian’);
grid on
legend(s)

Figure 10.5 Normal or Gaussian random variable about a mean of 2.
Given the probabilistic state-space model in discrete time [1] ![]() (10.16)
(10.16)
where x is the state vector and w is the noise vector, the measurement equation is ![]() (10.17)
(10.17)
where v
n
is the measurement noise. This has the form of a hidden Markov model (HMM) because the state is hidden.
If the process is Markovian, that is, the future x
k
is dependent only on the current state and is not dependent on the past states (the present is x
k−1), then ![]() (10.18)
(10.18)
The | means given. In this case, the first term is read as “the probability of x
k
given x
1: k−1 and y
1: k−1.” This is the probability of the current state given all past states and all measurements up to the k − 1 measurement. The past, x
k−1, is independent of the future given the present (which is x
k
): ![]() (10.19)
(10.19)
where T is the last sample and the measurements y
k
are conditionally independent given x
k
: ![]() (10.20)
(10.20)
We can define the recursive Bayesian optimal filter that computes the distribution: ![]() (10.21) given
(10.21) given
the prior distribution p(x 0), where x 0 is the state prior to the first measurement,
the state-space model
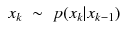 (10.22)
(10.22)
 (10.23)
(10.23)
the measurement sequence y 1: k = y 1, …, y k .
Computation is based on the recursion rule ![]() (10.24)
(10.24)
This means we get the current state from the prior state and all the past measurements. Assume we know the posterior distribution of the previous time step ![]() (10.25)
(10.25)
The joint distribution of x
k
, x
k−1 given y
1: k−1 can be computed as ![]() (10.26)
(10.26)
![]() (10.27)
(10.27)
because this is a Markov process. Integrating over x
k−1 gives the prediction step of the optimal filter, which is the Chapman–Kolmogorov equation  (10.28)
(10.28)
The Chapman–Kolmogorov equation is an identity relating the joint probability distributions of different sets of coordinates on a stochastic process. The measurement update state is found from Bayes’ rule ![]() (10.29)
(10.29)
![]() (10.30)
(10.30)
C
k
is the probability of the current measurement, given all past measurements.
If the noise is additive and Gaussian with the state covariance Q
n
and the measurement covariance R
n
, the model and measurement noise have zero mean, we can write the state equation as ![]() (10.31)
(10.31)
where x is the state vector and w is the noise vector. The measurement equation becomes ![]() (10.32)
(10.32)
Given that Q is not time dependent, we can write ![]() (10.33)
(10.33)
We can now write the prediction step, Eq. 10.28, as  (10.34)
(10.34)
We need to find the first two moments of x
k
. A moment is the expected value (or mean) of the variable. The first moment is of the variable, the second is of the variable squared, and so forth. They are ![]() (10.35)
(10.35)
![]() (10.36)
(10.36)
E means expected value. E[x
k
] is the mean and E[x
k
x
k
T
] is the covariance. Expanding the first moment and using the identity E[x] = ∫ xN(x; f(s), Σ)dx = f(s) where s is any argument gives ![]() (10.37)
(10.37)
![]() (10.38)
(10.38)
![]() (10.39)
(10.39)
Assuming that ![]() where P
xx
is the covariance of x and noting that x
k
= f
k
(x
k−1) + w
k−1, we get
where P
xx
is the covariance of x and noting that x
k
= f
k
(x
k−1) + w
k−1, we get  (10.40)
(10.40)
For the second moment we have ![]() (10.41)
(10.41)
![]() (10.42)
(10.42)
which results in  (10.43)
(10.43)
The covariance for the initial state is Gaussian and is P
0
xx
. The Kalman filter can be written without further approximations as ![]() (10.44)
(10.44)
![]() (10.45)
(10.45)
![]() (10.46)
(10.46)
where K
n
is the Kalman gain and P
yy
is the measurement covariance. The solution of these equations requires the solution of five integrals of the form 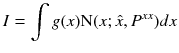 (10.47)
(10.47)
The three integrals needed by the filter are ![]() (10.48)
(10.48)
![]() (10.49)
(10.49)
![]() (10.50)
(10.50)
10.1.4 Conventional Kalman Filter
Assume we have a model of the form ![]() (10.51)
(10.51)
![]() (10.52) where
(10.52) where
 is the state of system at time k.
is the state of system at time k.A k−1 is the state transition matrix at time k − 1.
B k−1 is the input matrix at time k − 1.
q k−1N(0, Q k ) is the process noise at time k − 1.
 is the measurement at time k.
is the measurement at time k.H k is the measurement matrix at time k. This is found from the Jacobian of h(x).
r k N(0, R k ) is the measurement noise at time k.
The prior distribution of the state is x 0 = N(m 0, P 0), where parameters m 0 and P 0 contain all prior knowledge about the system. m 0 is the mean at time zero and P 0 is the covariance. Since our state is Gaussian, this completely describes the state.
![]() means real numbers in a vector of order n; that is, the state has n quantities. In probabilistic terms the model is
means real numbers in a vector of order n; that is, the state has n quantities. In probabilistic terms the model is ![]() (10.53)
(10.53)
![]() (10.54)
(10.54)
The integrals become simple matrix equations. In these equations P
k
− means the covariance prior to the measurement update. ![]() (10.55)
(10.55)
![]() (10.56)
(10.56)
![]() (10.57)
(10.57)
![]() (10.58)
(10.58)
![]() (10.59)
(10.59)
The prediction step becomes ![]() (10.60)
(10.60)
![]() (10.61)
(10.61)
The first term in the above covariance equation propagates the covariance based on the state transition matrix, A. Q
k+1 adds to this to form the next covariance. Process noise Q
k+1 is a measure of the accuracy of the mathematical model, A, in representing the system. For example, suppose A was a mathematical model that damped all states to zero. Without Q, P would go to zero. But if we really weren’t that certain about the model, the covariance would never be less than Q. Picking Q can be difficult. In a dynamical system with uncertain disturbances you can compute the standard deviation of the disturbances to compute Q. If the model A is uncertain, then you might do a statistical analysis of the range of models. Or you can try different Q in simulation and see which ones work the best!
The update step is ![]() (10.62)
(10.62)
![]() (10.63)
(10.63)
![]() (10.64)
(10.64)
![]() (10.65)
(10.65)
![]() (10.66)
(10.66)
S
k
is an intermediate quantity. v
k
is the residual. The residual is the difference between the measurement and your estimate of the measurement given the estimated states. R is just the covariance matrix of the measurements. If the noise is not white, a different filter should be used. White noise has equal energy at all frequencies. Many types of noise, such as the noise from an imager, is not really white noise but are band limited; that is, it has noise in a limited range of frequencies. You can sometimes add additional states to A to model the noise better, for example, adding a low-pass filter to band limit the noise. This makes A bigger but is generally not an issue.
We will investigate the application of the Kalman filter to the oscillator. First we need a method of converting the continuous-time problem to discrete time. We only need to know the states at discrete times or at fixed intervals, T. We use the continuous to discrete transform that uses the MATLAB expm function shown in the following function.
function [f, g] = CToDZOH( a, b, T )
if( nargin < 1 )
Demo;
return
end
[n,m] = size(b);
q = expm([a*T b*T;zeros(m,n+m)]);
f = q(1:n,1:n);
g = q(1:n,n+1:n+m);
%% Demo
function Demo
T = 0.5;
fprintf(1,’Double␣integrator␣with␣a␣%4.1f␣second␣time␣step. ’,T);
a = [0 1;0 0]
b = [0;1]
[f, g] = CToDZOH( a, b, T );
f
g
If you run the demo, for a double integrator, you get the following results. A double integrator is  (10.67)
(10.67)
Written in state-space form, it is ![]() (10.68)
(10.68)
![]() (10.69)
(10.69)
or in matrix form ![]() (10.70)
(10.70)
where  (10.71)
(10.71)
 (10.72)
(10.72)
 (10.73)
(10.73)
 (10.74)
(10.74)
>> CToDZOH
Double integrator with a 0.5-s time step.
a =
0 1
0 0
b =
0
1
f =
1.0000 0.5000
0 1.0000
g =
0.1250
0.5000
The discrete plant matrix f is easy to understand. The position state at step k + 1 is the state at k plus the velocity at step k multiplied by the time step T of 0.5 s. The velocity at step k + 1 is the velocity at k plus the time step times the acceleration at step k. The acceleration at the time k multiplies ![]() to get the contribution to position. This is just the standard solution to a particle under a constant acceleration.
to get the contribution to position. This is just the standard solution to a particle under a constant acceleration. ![]() (10.75)
(10.75)
![]() (10.76)
(10.76)
In matrix form this is ![]() (10.77)
(10.77)
With the discrete-time approximation we can change the acceleration every step k to get the time history. This assumes that the acceleration is constant over the period T. We need to pick T so that this is approximately true if we are to get good results.
The script for testing the Kalman filter, KFSim.m, is shown below. KFInitialize is used to initialize the filter (a Kalman filter, ’kf’, in this case).
%% KFINITIALIZE Kalman Filter initialization
%% Form:
% d = KFInitialize( type, varargin )
%
%% Description
% Initializes Kalman Filter data structures for the KF, UKF, EKF and
% UKFP, parameter update..
%
% Enter parameter pairs after the type.
%
% If you return with only one input it will return the default data
% structure for the filter specified by type. Defaults are returned
% for any parameter you do not enter.
%
%
%% Inputs
% type (1,1) Type of filter ’ukf’, ’kf’, ’ekf’
% varargin {:} Parameter pairs
%
%% Outputs
% d (1,1) Data structure
%
function d = KFInitialize( type, varargin )
% Default data structures
switch lower(type)
case ’ukf’
d = struct( ’m’,[],’alpha’,1, ’kappa’,0,’beta’,2, ’dT’,0,...
’p’,[],’q’,[],’f’,’’,’fData’,[], ’hData’,[],’hFun’,’’,’t’,0);
case ’kf’
d = struct( ’m’,[],’a’,[],’b’,[],’u’,[],’h’,[],’p’,[],...
’q’,[],’r’,[], ’y’,[]);
case ’ekf’
d = struct( ’m’,[],’x’,[],’a’,[],’b’,[],’u’,[],’h’,[],’hX’,[],’hData’,[],’fX’,[],’p’,[],...
’q’,[],’r’,[],’t’,0, ’y’,[],’v’,[],’s’,[],’k’,[]);
case ’ukfp’
d = struct( ’m’,[],’alpha’,1, ’kappa’,0,’beta’,2, ’dT’,0,...
’p’,[],’q’,[],’f’,’’,’fData’,[], ’hData’,[],’hFun’,’’,’t’,0,’eta’,[]);
otherwise
error([type ’␣is␣not␣available’]);
end
% Return the defaults
if( nargin == 1 )
return
end
% Cycle through all the parameter pairs
for k = 1:2:length(varargin)
switch lower(varargin{k})
case ’a’
d.a = varargin{k+1};
case {’m’ ’x’}
d.m = varargin{k+1};
d.x = varargin{k+1};
case ’b’
d.b = varargin{k+1};
case ’u’
d.u = varargin{k+1};
case ’hx’
d.hX = varargin{k+1};
case ’fx’
d.fX = varargin{k+1};
case ’h’
d.h = varargin{k+1};
case ’hdata’
d.hData = varargin{k+1};
case ’hfun’
d.hFun = varargin{k+1};
case ’p’
d.p = varargin{k+1};
case ’q’
d.q = varargin{k+1};
case ’r’
d.r = varargin{k+1};
case ’f’
d.f = varargin{k+1};
case ’eta’
d.eta = varargin{k+1};
case ’alpha’
d.alpha = varargin{k+1};
case ’kappa’
d.kappa = varargin{k+1};
case ’beta’
d.beta = varargin{k+1};
case ’dt’
d.dT = varargin{k+1};
case ’t’
d.t = varargin{k+1};
case ’fdata’
d.fData = varargin{k+1};
case ’nits’
d.nIts = varargin{k+1};
case ’kmeas’
d.kMeas = varargin{k+1};
end
end
You set up the Kalman filter by first converting the continuous-time model into discrete time. You add KFPredict and KFUpdate to the simulation loop. Be careful to put the predict and update steps in the right places so that the estimator is synchronized with simulation time. The simulation starts by assigning values to all of the variables used in the simulation. We get the data structure from the function RHSOscillator and then modify its values. We write the continuous-time model in matrix form and then convert it to discrete time. randn is used to add Gaussian noise to the simulation. The rest is the simulation loop with plotting afterward.
%% KFSim
% Demonstrate a Kalman Filter.
%% See also
% RungeKutta, RHSOscillator, TimeLabel, KFInitialize, KFUpdate, KFPredict
%% Initialize
tEnd = 100.0; % Simulation end time (sec)
dT = 0.1; % Time step (sec)
d = RHSOscillator; % Get the default data structure
d.a = 0.1; % Disturbance acceleration
d.omega = 0.2; % Oscillator frequency
d.zeta = 0.1; % Damping ratio
x = [0;0]; % Initial state [position;velocity]
y1Sigma = 1; % 1 sigma position measurement noise
% xdot = a*x + b*u
a = [0 1;-2*d.zeta*d.omega -d.omega^2]; % Continuous time model
b = [0;1]; % Continuous time input matrix
% x[k+1] = f*x[k] + g*u[k]
[f,g] = CToDZOH(a,b,dT); % Discrete time model
xE = [0.3; 0.1]; % Estimated initial state
q = [1e-6 1e-6]; % Model noise covariance ;
% [1e-4 1e-4] is for low model noise test
dKF = KFInitialize(’kf’,’m’,xE,’a’,f,’b’,g,’h’,[1 0],...
’r’,y1Sigma^2,’q’,diag(q),’p’,diag(xE.^2));
%% Simulation
nSim = floor(tEnd/dT) + 1;
xPlot = zeros(5,nSim);
for k = 1:nSim
% Measurements
y = x(1) + y1Sigma*randn(1,1);
% Update the Kalman Filter
dKF.y = y;
dKF = KFUpdate(dKF);
% Plot storage
xPlot(:,k) = [x;y;dKF.m-x];
% Propagate (numerically integrate) the state equations
x = RungeKutta( @RHSOscillator, 0, x, dT, d );
% Propagate the Kalman Filter
dKF.u = d.a;
dKF = KFPredict(dKF);
end
%% Plot the results
yL = {’r␣(m)’ ’v␣(m/s)’ ’y␣(m)’ ’Delta␣r_E␣(m)’ ’Delta␣v_E␣(m/s)’ };
[t,tL] = TimeLabel(dT*(0:(nSim-1)));
PlotSet( t, xPlot, ’x␣label’, tL, ’y␣label’, yL,...
’plot␣title’, ’Oscillator’, ’figure␣title’, ’KF␣Demo’ );
The prediction Kalman filter step is shown in the following listing. The prediction propagates the state one time step and propagates the covariance matrix with it. It is saying that when we propagate the state there is uncertainty so we must add that to the covariance matrix.
function d = KFPredict( d )
% The first path is if there is no input matrix b
if( isempty(d.b) )
d.m = d.a*d.m;
else
d.m = d.a*d.m + d.b*d.u;
end
d.p = d.a*d.p*d.a’ + d.q;
The update Kalman filter step is shown in the following listing. This adds the measurements to the estimate and accounts for the uncertainty (noise) in the measurements.
function d = KFUpdate( d )
s = d.h*d.p*d.h’ + d.r; % Intermediate value
k = d.p*d.h’/s; % Kalman gain
v = d.y - d.h*d.m; % Residual
d.m = d.m + k*v; % Mean update
d.p = d.p - k*s*k’; % Covariance update
You will note that the “memory” of the filter is stored in the data structure. No persistent data storage is used. This makes it easier to use these functions in multiple places in your code. Note also that you don’t have to call KFUpdate every time step. You need only call it when you have new data. However, the filter does assume uniform time steps.
The script gives two examples for the model noise covariance matrix. Figure 10.6 shows results when high numbers, [1e-4 1e-4], for the model covariance are used. Figure 10.7 when lower numbers, [1e-6 1e-6], are used. We don’t change the measurement covariance because only the ratio between noise covariance and model covariance is important.
When the higher numbers are used, the errors are Gaussian but noisy. When the low numbers are used, the result is very smooth, with little noise seen. However, the errors are large in the low model covariance case. This is because the filter is essentially ignoring the measurements since it thinks the model is very accurate. You should try different options in the script and see how it performs. As you can see, the parameters make a huge difference in how well the filter learns about the states of the system.

Figure 10.6 The Kalman filter results with the higher-model-noise matrix, [1e-4 1e-4].

Figure 10.7 The Kalman filter results with the lower-model-noise matrix, [1e-6 1e-6]. Less noise is seen but the errors are large.
The extended Kalman filter was developed to handle models with nonlinear dynamical models and/or nonlinear measurement models. Given a nonlinear model of the form ![]() (10.78)
(10.78)
![]() (10.79)
(10.79)
the prediction step is ![]() (10.80)
(10.80)
![]() (10.81)
(10.81)
F is the Jacobian of f. The update step is ![]() (10.82)
(10.82)
![]() (10.83)
(10.83)
![]() (10.84)
(10.84)
![]() (10.85)
(10.85)
![]() (10.86)
(10.86)
F
x
(m, k − 1) and H
x
(m, k) are the Jacobians of the nonlinear functions f and h. The Jacobians are just a matrix of partial derivatives of F and H. This results in matrices from the vectors F and H. For example, assume we have f(x, y), which is  (10.87)
(10.87)
The Jacobian is  (10.88)
(10.88)
The matrix is computed at x
k
, y
k
.
The Jacobians can be found analytically or numerically. If done numerically, the Jacobian needs to be computed about the current value of m k . In the iterated extended Kalman filter, the update step is done in a loop using updated values of m k after the first iteration. H x (m, k) needs to be updated on each step.
We don’t give an example using the extended Kalman filter but include the code for you to explore.
10.2 Using the Unscented Kalman Filter for StateEstimation
10.2.1 Problem
You want to learn the states of the spring-damper-mass system given a nonlinear angle measurement.
10.2.2 Solution
The solution is to create an unscented Kalman filter (UKF) as a state estimator. This will absorb measurements and determine the state. It will autonomously learn about the state of system based on a preexisting model.
10.2.3 How It Works
With the UKF we work with the nonlinear dynamical and measurement equations directly. We don’t have to linearize them. The UKF is also known as a σ point filter because it simultaneously maintains models one sigma (standard deviation) from the mean.
In the following sections we develop the equations for the nonaugmented Kalman filter. This form only allows for additive Gaussian noise. This assumes additive Gaussian noise. Given a nonlinear model of the form ![]() (10.89)
(10.89)
![]() (10.90)
(10.90)
define weights as ![]() (10.91)
(10.91)
![]() (10.92)
(10.92)
![]() (10.93)
(10.93)
![]() (10.94)
(10.94)
Note that W
m
i
= W
c
i
. ![]() (10.95)
(10.95)
![]() (10.96)
(10.96)
α, β, and κ are scaling constants. General rules for the scaling constants are
α: 0 for state estimation, 3 minus the number of states for parameter estimation
β: Determines spread of sigma points. Smaller means more closely spaced sigma points.
κ: Constant for prior knowledge. Set to 2 for Gaussian processes.
n is the order of the system. The weights can be put into matrix form. ![]() (10.97)
(10.97)
 (10.98)
(10.98)
I is the 2n + 1 by 2n + 1 identity matrix. In the equation vector w
m
is replicated 2n + 1 times. W is 2n + 1 by 2n + 1. The weights are computed in UKFWeight.
%% UKFWEIGHT Unscented Kalman Filter weight calculation
%% Form:
% d = UKFWeight( d )
%
%% Description
% Unscented Kalman Filter weights.
%
% The weight matrix is used by the matrix form of the Unscented
% Transform. Both UKSPredict and UKSUpdate use the data structure
% generated by this function.
%
% The constant alpha determines the spread of the sigma points around x
% and is usually set to between 10e-4 and 1. beta incorporates prior
% knowledge of the distribution of x and is 2 for a Gaussian
% distribution. kappa is set to 0 for state estimation and 3 - number of
% states for parameter estimation.
% d = UKFWeight( d )
%% Inputs
% d (1,1) Data structure with constants
% .kappa (1,1) 0 for state estimation, 3-#states for
% parameter estimation
% .m (:,1) Vector of mean states
% .alpha (1,1) Determines spread of sigma points
% .beta (1,1) Prior knowledge - 2 for Gaussian
%
%% Outputs
% d (1,1) Data structure with constants
% .w (2*n+1,2*n+1) Weight matrix
% .wM (1,2*n+1) Weight array
% .wC (2*n+1,1) Weight array
% .c (1,1) Scaling constant
% .lambda (1,1) Scaling constant
%
function d = UKFWeight( d )
% Compute the fundamental constants
n = length(d.m);
a2 = d.alpha^2;
d.lambda = a2*(n + d.kappa) - n;
nL = n + d.lambda;
wMP = 0.5*ones(1,2*n)/nL;
d.wM = [d.lambda/nL wMP]’;
d.wC = [d.lambda/nL+(1-a2+d.beta) wMP];
d.c = sqrt(nL);
% Build the matrix
f = eye(2*n+1) - repmat(d.wM,1,2*n+1);
d.w = f*diag(d.wC)*f’;
The prediction step is ![]() (10.99)
(10.99)
![]() (10.100)
(10.100)
![]() (10.101)
(10.101)
![]() (10.102)
(10.102)
where X is a matrix where each column is the state vector possibly with an added sigma point vector. The update step is ![]() (10.103)
(10.103)
![]() (10.104)
(10.104)
![]() (10.105)
(10.105)
![]() (10.106)
(10.106)
![]() (10.107)
(10.107)
![]() (10.108)
(10.108)
![]() (10.109)
(10.109)
![]() (10.110)
(10.110)
μ
k
is a matrix of the measurements in which each column is a copy modified by the sigma points. S
k
and C
k
are intermediate quantities. The brackets around Y
k
− are just for clarity.
The script for testing the UKF, UKFSim, is shown below. As noted earlier, we don’t need to convert the continuous-time model into discrete time. Instead, we pass the filter the right-hand side of the differential equations. You must also pass it a measurement model which can be nonlinear. You add UKFPredict and UKFUpdate to the simulation loop. We start by initializing all parameters. KFInitialize takes parameter pairs, after ’ukf’ to initialize the filter. The remainder is the simulation loop and plotting.
%% UKFSim
% Demonstrate an Unscented Kalman Filter.
%% See also
% RungeKutta, RHSOscillator, TimeLabel, KFInitialize, UKFUpdate, UKFPredict
% AngleMeasurement
%% Initialize
nSim = 5000; % Simulation steps
dT = 0.1; % Time step (sec)
d = RHSOscillator; % Get the default data structure
d.a = 0.1; % Disturbance acceleration
d.zeta = 0.1; % Damping ratio
x = [0;0]; % Initial state [position;velocity]
y1Sigma = 0.01; % 1 sigma measurement noise
dMeas.baseline = 10; % Distance of sensor from start
xE = [0;0]; % Estimated initial state
q = diag([0.01 0.001]);
p = diag([0.001 0.0001]);
dKF = KFInitialize( ’ukf’,’m’,xE,’f’,@RHSOscillator,’fData’,d,...
’r’,y1Sigma^2,’q’,q,’p’,p,...
’hFun’,@AngleMeasurement,’hData’,dMeas,’dT’,dT);
dKF = UKFWeight( dKF );
%% Simulation
xPlot = zeros(5,nSim);
for k = 1:nSim
% Measurements
y = AngleMeasurement( x, dMeas ) + y1Sigma*randn;
% Update the Kalman Filter
dKF.y = y;
dKF = UKFUpdate(dKF);
% Plot storage
xPlot(:,k) = [x;y;dKF.m-x];
% Propagate (numerically integrate) the state equations
x = RungeKutta( @RHSOscillator, 0, x, dT, d );
% Propagate the Kalman Filter
dKF = UKFPredict(dKF);
end
%% Plot the results
yL = {’r␣(m)’ ’v␣(m/s)’ ’y␣(rad)’ ’Delta␣r_E␣(m)’ ’Delta␣v_E␣(m/s)’ };
[t,tL] = TimeLabel(dT*(0:(nSim-1)));
PlotSet( t, xPlot, ’x␣label’, tL, ’y␣label’, yL,...
The prediction UKF step is shown in the following listing.
function d = UKFPredict( d )
pS = chol(d.p)’;
nS = length(d.m);
nSig = 2*nS + 1;
mM = repmat(d.m,1,nSig);
x = mM + d.c*[zeros(nS,1) pS -pS];
xH = Propagate( x, d );
d.m = xH*d.wM;
d.p = xH*d.w*xH’ + d.q;
d.p = 0.5*(d.p + d.p’); % Force symmetry
%% Propagate each sigma point state vector
function x = Propagate( x, d )
for j = 1:size(x,2)
x(:,j) = RungeKutta( d.f, d.t, x(:,j), d.dT, d.fData );
end
UKFPredict uses RungeKutta for prediction that is done by numerical integration. In effect, we are running a simulation of the model and just correcting the results with the next function, UKFUpdate. This gets to the core of the Kalman filter. It is just a simulation of your model with a measurement correction step. In the case of the conventional Kalman filter, we use a linear discrete-time model.
The update UKF step is shown in the following listing. The update propagates the state one time step.
function d = UKFUpdate( d )
% Get the sigma points
pS = d.c*chol(d.p)’;
nS = length(d.m);
nSig = 2*nS + 1;
mM = repmat(d.m,1,nSig);
x = mM + [zeros(nS,1) pS -pS];
[y, r] = Measurement( x, d );
mu = y*d.wM;
s = y*d.w*y’ + r;
c = x*d.w*y’;
k = c/s;
d.v = d.y - mu;
d.m = d.m + k*d.v;
d.p = d.p - k*s*k’;
%% Measurement estimates from the sigma points
function [y, r] = Measurement( x, d )
nSigma = size(x,2);
% Create the arrays
lR = length(d.r);
y = zeros(lR,nSigma);
r = d.r;
for j = 1:nSigma
f = feval(d.hFun, x(:,j), d.hData );
iR = 1:lR;
y(iR,j) = f;
end
The sigma points are generated using chol. chol is Cholesky factorization and generates an approximate square root of a matrix. A true matrix square root is more computationally expensive and the results don’t really justify the penalty. The idea is to distribute the sigma points around the mean, and chol works well. Here is an example that compares the two approaches:
>> z = [1 0.2;0.2 2]
z =
1.0000 0.2000
0.2000 2.0000
>> b = chol(z)
b =
1.0000 0.2000
0 1.4000
>> b*b
ans =
1.0000 0.4800
0 1.9600
>> q = sqrtm(z)
q =
0.9965 0.0830
0.0830 1.4118
>> q*q
ans =
1.0000 0.2000
0.2000 2.0000
The square root actually produces a square root! The diagonal of b*b is close to z, which is all that is important. The measurement geometry in shown in Figure 10.8.

Figure 10.8 The measurement geometry. Our measurement is the angle.
The results are shown in Figure 10.9. The errors Δ r E and Δ v E are just noise. The measurement goes over a large angle range, which would make a linear approximation problematic.

Figure 10.9 The unscented Kalman filter results for state estimation.
10.3 Using the UKF for Parameter Estimation
10.3.1 Problem
You want to learn the parameters of the spring-damper-mass system given a nonlinear angle measurement.
10.3.2 Solution
The solution is to create a UKF configured as a parameter estimator. This will absorb measurements and determine the mass, spring constant, and damping. It will autonomously learn about the system based on a preexisting model. We develop the version that requires an estimate of the state that could be generated with a UKF running in parallel, as in the previous recipe.
10.3.3 How It Works
Initialize the parameter filter with the expected value of the parameters, η [2]:
![]() (10.111)
(10.111)
and the covariance for the parameters ![]() (10.112)
(10.112)
The update sequence begins by adding the parameter model uncertainty, Q, to the covariance, P, ![]() (10.113)
(10.113)
Q is for the parameters, not the states. The sigma points are then calculated. These are points found by adding the square root of the covariance matrix to the current estimate of the parameters. ![]() (10.114)
(10.114)
γ is a factor that determines the spread of the sigma points. We use chol for the square root. If there are L parameters, the P matrix is L × L, so this array will be L × (2L + 1).
The state equations are of the form ![]() (10.115)
(10.115)
and the measurement equations are ![]() (10.116)
(10.116)
x is the previous state of the system, as identified by the state estimator or other process. u is a structure with all other inputs to the system that are not being estimated. η is a vector of parameters that are being estimated and t is time. y is the vector of measurements. This is the dual estimation approach in that we are not estimating x and η simultaneously.
The script, UKFPSim, for testing the UKF parameter estimation is shown below. We are not doing the UKF state estimation to simplify the script. Normally you would run the UKF in parallel. We start by initializing all parameters. KFInitialize takes parameter pairs to initialize the filters. The remainder is the simulation loop and plotting.
%% UKFPSim
% Demonstrate parameter learning using Unscented Kalman Filter.
%% See also
% RungeKutta, RHSOscillator, TimeLabel, KFInitialize, UKFPUpdate
% AngleMeasurement
%% Initialize
nSim = 150; % Simulation steps
dT = 0.01; % Time step (sec)
d = RHSOscillator; % Get the default data structure
d.a = 0.0; % Disturbance acceleration
d.zeta = 0.0; % Damping ratio
d.omega = 2; % Undamped natural frequency
x = [1;0]; % Initial state [position;velocity]
y1Sigma = 0.0001; % 1 sigma measurement noise
q = 0.001; % Plant uncertainty
p = 0.4; % Initial covariance for the parameter
dRHSUKF = struct(’a’,0.0,’zeta’,0.0,’eta’,0.1);
dKF = KFInitialize( ’ukfp’,’x’,x,’f’,@RHSOscillatorUKF,...
’fData’,dRHSUKF,’r’,y1Sigma^2,’q’,q,...
’p’,p,’hFun’,@LinearMeasurement,...
’dT’,dT,’eta’,d.omega/2,...
’alpha’,1,’kappa’,2,’beta’,2);
dKF = UKFPWeight( dKF );
y = LinearMeasurement( x );
%% Simulation
xPlot = zeros(5,nSim);
for k = 1:nSim
% Update the Kalman Filter parameter estimates
dKF.x = x;
% Plot storage
xPlot(:,k) = [y;x;dKF.eta;dKF.p];
% Propagate (numerically integrate) the state equations
x = RungeKutta( @RHSOscillator, 0, x, dT, d );
% Measurements
y = LinearMeasurement( x ) + y1Sigma*randn;
dKF.y = y;
dKF = UKFPUpdate(dKF);
end
%% Plot the results
yL = {’y␣(rad)’ ’r␣(m)’ ’v␣(m/s)’ ’omega␣(rad/s)’ ’p’ };
[t,tL] = TimeLabel(dT*(0:(nSim-1)));
PlotSet( t, xPlot, ’x␣label’, tL, ’y␣label’, yL,...
’plot␣title’, ’UKF␣Parameter␣Estimation’, ’figure␣title’, ’UKF␣Parameter␣Estimation’ );
The UKF parameter update functional is shown in the following code. It uses the state estimate generated by the UKF. As noted, we are using the exact value of the state generated by the simulation. This function needs a specialized right-hand side that uses the parameter estimate, d.eta. We modified RHSOscillator for this purpose and wrote RHSOscillatorUKF.
%% UKFPUPDATE Unscented Kalman Filter parameter update step
%% Form:
% d = UKFPUpdate( d )
%
%% Description
% Implement an Unscented Kalman Filter for parameter estimation.
% The filter uses numerical integration to propagate the state.
% The filter propagates sigma points, points computed from the
% state plus a function of the covariance matrix. For each parameter
% there are two sigma parameters. The current estimated state must be
% input each step.
%
%% Inputs
% d (1,1) UKF data structure
% .x (n,1) State
% .p (n,n) Covariance
% .q (n,n) State noise covariance
% .r (m,m) Measurement noise covariance
% .wM (1,2n+1) Model weights
% .wC (1,2n+1) Model weights
% .f (1,:) Pointer for the right hand side function
% .fData (.) Data structure with data for f
% .hFun (1,:) Pointer for the measurement function
% .hData (.) Data structure with data for hFun
% .dT (1,1) Time step (s)
% .t (1,1) Time (s)
% .eta (:,1) Parameter vector
% .c (1,1) Scaling constant
% .lambda (1,1) Scaling constant
%
%% Outputs
% d (1,1) UKF data structure
% .p (n,n) Covariance
% .eta (:,1) Parameter vector
%
%% References
% References: Van der Merwe, R. and Wan, E., "Sigma-Point Kalman Filters for
% Probabilistic Inference in Dynamic State-Space Models".
% Matthew C. VanDyke, Jana L. Schwartz, Christopher D. Hall,
% "UNSCENTED KALMAN FILTERING FOR SPACECRAFT ATTITUDE STATE AND
% PARAMETER ESTIMATION,"AAS-04-115.
function d = UKFPUpdate( d )
d.wA = zeros(d.L,d.n);
D = zeros(d.lY,d.n);
yD = zeros(d.lY,1);
% Update the covariance
d.p = d.p + d.q;
% Compute the sigma points
d = SigmaPoints( d );
% We are computing the states, then the measurements
% for the parameters +/- 1 sigma
for k = 1:d.n
d.fData.eta = d.wA(:,k);
x = RungeKutta( d.f, d.t, d.x, d.dT, d.fData );
D(:,k) = feval( d.hFun, x, d.hData );
yD = yD + d.wM(k)*D(:,k);
end
pWD = zeros(d.L,d.lY);
pDD = d.r;
for k = 1:d.n
wD = D(:,k) - yD;
pDD = pDD + d.wC(k)*(wD*wD’);
pWD = pWD + d.wC(k)*(d.wA(:,k) - d.eta)*wD’;
end
pDD = 0.5*(pDD + pDD’);
% Incorporate the measurements
K = pWD/pDD;
dY = d.y - yD;
d.eta = d.eta + K*dY;
d.p = d.p - K*pDD*K’;
d.p = 0.5*(d.p + d.p’); % Force symmetry
%% Create the sigma points for the parameters
function d = SigmaPoints( d )
n = 2:(d.L+1);
m = (d.L+2):(2*d.L + 1);
etaM = repmat(d.eta,length(d.eta));
sqrtP = chol(d.p);
d.wA(:,1) = d.eta;
d.wA(:,n) = etaM + d.gamma*sqrtP;
d.wA(:,m) = etaM - d.gamma*sqrtP;
It also has its own weight initialization function UKFPWeight.m.
%% UKFPWEIGHT Unscented Kalman Filter parameter estimation weights
%% Form:
% d = UKFPWeight( d )
%
%% Description
% Unscented Kalman Filter parameter estimation weights.
%
% The weight matrix is used by the matrix form of the Unscented
% Transform.
%
% The constant alpha determines the spread of the sigma points around x
% and is usually set to between 10e-4 and 1. beta incorporates prior
% knowledge of the distribution of x and is 2 for a Gaussian
% distribution. kappa is set to 0 for state estimation and 3 - number of
% states for parameter estimation.
%
%% Inputs
% d (.) Data structure with constants
% .kappa (1,1) 0 for state estimation, 3-#states
% .alpha (1,1) Determines spread of sigma points
% .beta (1,1) Prior knowledge - 2 for Gaussian
%
%% Outputs
% d (.) Data structure with constants
% .wM (1,2*n+1) Weight array
% .wC (1,2*n+1) Weight array
% .lambda (1,1) Scaling constant
% .wA (p,n) Empty matrix
% .L (1,1) Number of parameters to estimate
% .lY (1,1) Number of measurements
% .D (m,n) Empty matrix
% .n (1,1) Number of sigma i
%
function d = UKFPWeight( d )
d.L = length(d.eta);
d.lambda = d.alpha^2*(d.L + d.kappa) - d.L;
d.gamma = sqrt(d.L + d.lambda);
d.wC(1) = d.lambda/(d.L + d.lambda) + (1 - d.alpha^2 + d.beta);
d.wM(1) = d.lambda/(d.L + d.lambda);
d.n = 2*d.L + 1;
for k = 2:d.n
d.wC(k) = 1/(2*(d.L + d.lambda));
d.wM(k) = d.wC(k);
end
d.wA = zeros(d.L,d.n);
y = feval( d.hFun, d.x, d.hData );
d.lY = length(y);
d.D = zeros(d.lY,d.n);
RHSOscillatorUKF is the oscillator model used by the UKF. It has a different input format than RHSOscillatorUKF.
%% RHSOSCILLATORUKF Right hand side of a double integrator.
%% Form
% xDot = RHSOscillatorUKF( t, x, a )
%
%% Description
% An oscillator models linear or rotational motion plus many other
% systems. It has two states, position and velocity. The equations of
% motion are:
%
% rDot = v
% vDot = a - omega^2*r
%
% This can be called by the MATLAB Recipes RungeKutta function or any MATLAB
% integrator. Time is not used. This function is compatible with the
% UKF parameter estimation. eta is the parameter to be estimated which is
% omega in this case.
%
% If no inputs are specified, it will return the default data structure.
%
%% Inputs
% t (1,1) Time (unused)
% x (2,1) State vector [r;v]
% d (.) Data structure
% .a (1,1) Disturbance acceleration (m/s^2)
% .zeta (1,1) Damping ratio
% .eta (1,1) Natural frequency (rad/s)
%
%% Outputs
% x (2,1) State vector derivative d[r;v]/dt
%
%% References
% None.
function xDot = RHSOscillatorUKF( ~, x, d )
if( nargin < 1 )
xDot = struct(’a’,0,’eta’,0.1,’zeta’,0);
return
end
xDot = [x(2);d.a-2*d.zeta*d.eta*x(2)-d.eta^2*x(1)];
LinearMeasurement is a simple measurement function for demonstration purposes. The UKF can use arbitrarily complex measurement functions.
%% LINEARMEASUREMENT Function for an angle measurement
%% Form
% y = LinearMeasurement( x, d )
%
%% Description
% A linear measurement
%
%% Inputs
% x (2,1) State [r;v]
% d (.) Data structure
%
%% Outputs
% y (1,1) Distance
%
%% References
% None.
function y = LinearMeasurement( x, ~ )
if( nargin < 1 )
y = [];
return
end
y = x(1);
The results of a simulation of an undamped oscillator are shown in Figure 10.10. The filter rapidly estimates the undamped natural frequency. The result is noisy, however. You can explore this script by varying the numbers in the script.

Figure 10.10 The UKF parameter estimation results.
Summary
This chapter has demonstrated learning using Kalman filters. In this case learning is the estimation of states and parameters for a damped oscillator. We looked at conventional and unscented Kalman filters. We examined the parameter learning version of the latter. All examples were done using a damped oscillator.
Table 10.1 Chapter Code Listing
File | Description |
|---|---|
AngleMeasurement | Angle measurement of the mass |
LinearMeasurement | Position measurement of the mass |
OscillatorSim | Simulation of the damped oscillator |
OscillatorDampingRatioSim | Simulation of the damped oscillator with different damping ratios |
RHSOscillator | Dynamical model for the damped oscillator |
RungeKutta | Fourth-order Runge–Kutta integrator |
PlotSet | Create two-dimensional plots from a data set |
TimeLabel | Produce time labels and scaled time vectors |
Gaussian | Plot a Gaussian distribution |
KFInitialize | Initialize Kalman filters |
KFSim | Demonstration of a conventional Kalman filter |
KFPredict | Prediction step for a conventional Kalman filter |
KFUpdate | Update step for a conventional Kalman filter |
EKFPredict | Prediction step for an extended Kalman filter |
EKFUpdate | Update step for an extended Kalman filter |
UKFPredict | Prediction step for a UKF |
UKFUpdate | Update step for a UKF |
UKFPUpdate | Update step for a UKF parameter update |
UKFSim | Demonstration of a UKF |
UKFPSim | Demonstration of parameter estimation for a UKF |
UKFWeights | Generates weights for the UKF |
UKFPWeights | Generates weights for the UKF parameter estimator |
RHSOscillatorUKF | Dynamical model for the damped oscillator for use in UKF parameter estimation |
[1] S. Sarkka. Lecture 3: Bayesian Optimal Filtering Equations and the Kalman Filter. Technical report, Department of Biomedical Engineering and Computational Science, Aalto University School of Science, February 2011.
[2] M. C. VanDyke, J. L. Schwartz, and C. D. Hall. Unscented Kalman filtering for spacecraft attitude state and parameter estimation. Advances in Astronautical Sciences, 2005.