
CHAPTER 3
Artificial Intelligence, Machine Learning, and Deep Learning Models for Risk Management
Despite the hype of the last few years, artificial intelligence (AI) and machine learning have proven themselves as useful tools in risk management. As stated earlier, the main reasons are the availability of vast amounts of digital data, greater computing power, and easier access to complex analytics via available modeling tools. More recently, both adoption of digital channels and increase in generated data have accelerated due to the COVID-19 pandemic. This came at a time when financial institutions were already facing myriad internal and external demands:
- Regulatory demands—compliance to new waves of prudential and financial reporting standards
- Macroeconomic demands—sustained low interest rates and inefficiencies putting pressure on profitability and increasing costs, due in part to the inflated cost of compliance
- Technological advancements—advanced analytics, big data, open banking, cloud-based and high-performance computing
- Emerging risks—cyberattacks, those created by the COVID-19 pandemic, climate change, and geopolitical uncertainty
- Digital transformation—challenges to the traditional banking model from new customer demands and the rise of newer, more nimble financial technology companies
Although not without challenges of their own, the use of AI and machine learning is one effective way that organizations can improve their agility to respond to these demands. Some of the benefits of AI and machine learning in risk management include a better, more real-time ability to respond to changes in market conditions and efficiency benefits from automation, while making sense of the copious quantities of data from digitalization.
In speaking to financial institutions and other industry practitioners, the following practical and tangible benefits of AI and machine learning to the risk function were cited:
- Improved accuracy in predictive modeling and forecasting. Some studies have also found that AI and machine learning achieve superior accuracy beyond what traditional models achieve (given their ability to rapidly detect nonlinear relationships).
- Improved handling of big and diverse datasets. AI and machine learning can handle a diverse range of high-dimensional data, including unstructured data.
- Challenger models. AI and machine learning are effective at challenging the status quo by identifying accuracy improvements. In the case of AI and machine learning, a range of algorithms can be utilized.
- Automate complex risk processes (CCAR (Comprehensive Capital Analysis and Review), CECL/IFRS 9). AI and machine learning can automate complex risk processes with robotic process automation.
- Approximate complex risk calculations. AI and machine learning are effective at approximating complex risk calculations, for example, in derivatives pricing.
- Improve risk data quality. AI and machine learning can detect and remediate data quality issues.
- Risk-based optimization. AI and machine learning can effectively be applied to optimize based within a set of constraints.
- Automate steps in the model development process. AI and machine learning can accelerate the model development process with automated feature engineering and automated machine learning.
Often, when existing models meet current expectations, reluctance in using AI and machine learning is based on this question: “Why use machine learning when my current model are effective at risk profiling, with sufficient performance that is likely to continue for the foreseeable future?” This is a common sentiment, especially in highly regulated industries that have established processes for traditional models in place, and a level of comfort around them. And yes, current models may be effectively designed to respond well to the challenges listed above in estimating risk parameters—traditional models are able to capture nonlinear interactions to some degree. However, there are masked risks that newer approaches of AI and machine learning are better suited for, and are more efficient to identify.
For example, financial technology companies employ AI and machine learning to provide personalized customer experiences and process legal documents. Extreme credit and fraud risk events and other anomalies that represent a small percentage of portfolios are more effectively modeled by machine learning algorithms. Machine learning is also effective at approximating complex risk calculations: a neural network, for example, is sophisticated in its architecture but surprisingly easy to execute. Machine learning is also effective at automating model development tasks such as feature engineering. In the COVID-19 pandemic, organizations have turned to machine learning to adapt to changes in market dynamics—for example, detect early signals of stress by identifying customers with higher repayment difficulty, from more granular transactional data. Furthermore, machine learning can also effectively be applied to segment portfolios into micro-segments.
Innovative models need an innovative approach to risk model development and deployment. With more automation and an accelerated risk model lifecycle, especially in the context of current or impending exogenous events, like COVID-19, risk managers can more quickly respond to dynamic market conditions.
Previously, acceleration was often impeded by additional regulatory demands. Such measures included buffers to expected credit loss provisions due to the uncertainty created by divergent economic data across markets. However, the slowness to develop new models can also be attributed to the manual nature of model development and legacy processes. In addition, technologies that lack repeatable and standardized frameworks can cause bottlenecks in the risk model development cycle. The COVID-19 pandemic provided a means to focus on identifying bottlenecks in model development and decision-making cycles, and this highlighted the need to combine increased automation with a level of human-based decision-making so that organizations can better respond in a forward-looking manner.
The acceleration of risk model development and deployment will enable organizations to develop and deploy more models into production with the same number of staff and timelines compared to models currently in production. More models will also require more automated monitoring processes. They might also need to be reviewed more frequently—potentially daily—to quickly identify any recalibration needs.
This chapter further defines AI and machine learning and includes case studies on how AI and machine learning are used to strengthen risk management. Although the chapter will provide some historical applications of artificial intelligence, machine and deep learning, it also includes practical use cases to demonstrate how machine learning can be leveraged at present.
RISK MODELING USING MACHINE LEARNING
Most of us first started to take notice of AI in 1996 when Deep Blue beat Garry Kasparov in a chess match, and then in 2001 when the IBM Watson Supercomputer famously beat contestants of the game show Jeopardy.1 One of the game show contestants famously joked, “I, for one, welcome our new computer overlords.”2
With all jokes aside, advanced AI and machine learning are extensively utilized for predictive analytics in cloud-based deployments, and many companies have now embraced its use.3 Such companies include:
- The global office supply retailer Staples, which created a smart ordering system
- General Motors, which analyzes drivers' preferences and decision-making
- The global pharmaceutical company GlaxoSmithKline (GSK), which enabled customers to ask questions by voice and text via online advertisements
- The University of Southampton, in the United Kingdom, which created a cognitive computing module that offers research modules online
There is also a growing list of Global Systemically Important Banks, Domestic Important Banks, commercial banks, and insurance and financial technology companies that are piloting or have leveraged advanced AI and machine learning to improve customer experience and offer new products and services. The range of applications is wide: from chatbots in call centers to machine learning models used for loan originations and fraud detection to simulating scenarios and synthetic data for stress testing. Today, for many organizations, the use of AI and machine learning is either directly or indirectly involved in risk management processes, risk decision-making, and/or complex risk calculations.
What follows are AI and machine learning stories to highlight the practical ways that financial institutions are using these advanced techniques. However, as there is a tradeoff between complexity and accuracy, the focus for risk management should be on the applications of AI and machine learning where it makes sense. Not every problem is an AI problem. For example, if it makes sense to retain traditional models for regulatory calculations, then there is no need to replace these models with AI and machine learning. In addition, for simple binary target prediction problems where there is little data available, simpler techniques can provide easy solutions.
Tier 1 Commercial Bank in Latin America
A Tier 1 commercial bank, headquartered in Latin America, comprising both retail and wholesale banking operations, had a problem with maintaining asset quality in their loan portfolio, while meeting ambitious growth targets by acquiring new customers. It became especially challenging against a backdrop of rising interest rates and increases in loan-level defaults.
To effectively scale, the bank decided to invest in a new risk modeling platform that operationalized the risk model lifecycle. The platform needed to be robust enough to automate the development and deployment of machine learning models. It became a “machine learning model factory” where highly structured and industrialized model development and deployment processes were put in place. These included data preparation and model development processes, where nonregulatory machine learning models for selected market segments could be developed and automatically deployed into production.
The bank used the opportunity to modernize its technology to also improve its processes. It analyzed each step in its model-building process and identified bottlenecks and their causes. This allowed the bank to improve, for example, model dataset creation from months to days. This delivered an important lesson—simply buying new technology without addressing existing infrastructure, human, or process issues does not yield great results.
The Machine Learning Factory dramatically reduced model development and deployment time from more than 12 months to less than one day. Target markets were able to be segmented at a more granular level, producing better models with more accurate prediction outcomes. A faster, more efficient model lifecycle allowed for more models to be developed and deployed, increasing the number of models under management fivefold. It was achieved by improved model pipeline designs that enabled some machine learning algorithms to update dynamically, with continuous development of challenger models that were used to contest the production champion models. When the challenger was deemed to be better performing, it was deployed into production automatically.
This resulted in better quality of loans and millions of dollars in credit losses avoided. New loans could also be issued with more ease, which enabled expansion of the bank's portfolio across many markets.
Tier 1 Financial Institution in Asia Pacific
Many financial institutions in Asia Pacific are actively using machine learning in nonregulatory settings. One interesting application is the detection of complex transactions that indicate instances of fraud. In some cases, banks are relying on financial technology companies that specialize in AI to build these models. But with easier access to platforms and no-code/low-code interfaces for AI and machine learning, increasingly organizations are developing these themselves.
The occurrence of credit application fraud represents a very small fraction of the population, less than 1%. However, the losses are typically severe. A major concern at a Tier 1 commercial bank in Asia Pacific was that although the number of fraud cases was small, the vast majority bypassed the bank's existing fraud rules. This was a complex problem. The best efforts of the bank, including manual interventions and contacting applicants, meant that some incidents still slipped through the credit- and fraud-checking processes.
To detect the fraudulent behavior, the bank built predictive models based on actual historical data of the approved applications using a gradient boosting machine (GBM). This technique used thousands of decision trees and hundreds of variables as a basis of generating weak prediction models that get ensembled to a final prediction via a score.
Although the GBM models were great at detecting suspicious behavior, the obstacle the bank faced was that the current infrastructure was not robust enough to support the deployment and implementation of advanced machine learning models like GBMs. In the end, the sophistication of the GBM needed to be completely stripped back to a linear model, which meant that the predictive capability was reduced. This story illustrates the potential power of machine learning in improving predictions—but it also reminds us that infrastructure capability needs to be addressed before deploying resources, in the form of funds and time, toward a machine learning project.
Process Automation for Claims Processing
Several organizations have started to use AI and machine learning to develop AI-based behavioral models that can be used to support other applications to improve customer experience. One such model was developed using over a decade of insurance data to find hidden pathways that exist between the question sets asked and the most profitable 20–40 customer segments. Based on the insights of the model, over 30 questions previously used to ascertain medical history were reduced to 7 key questions needed to confirm or deny coverage. What this predictive underwriting capability of the model supplies is faster, easier, and more accurate insurance outcomes that greatly improve the customer experience.
Other AI and machine learning models have been developed to identify the key reason for excluding customers for medical insurance, such as those with a particular type of disability, and whether the excluded population has a higher propensity to make claims at a later point in time. Again, this has contributed to a more efficient underwriting process by reducing time, cost, and paperwork needed to make insurance decisions.
The one condition for all models developed for this project was that it needed to be transparent, meaning that all the inputs and output decisions can be easily explained. The avoidance of “black box” models in favor of those that can be explained easily is a common requirement in financial institutions. As such, explainable AI is a key consideration with any development project and is discussed in greater detail in Chapter 4.
Navigating through the Storm of COVID-19
Like many financial institutions across the globe, a Tier 1 commercial bank in the Asia Pacific region provided repayment holidays to eligible small business customers during the COVID pandemic. Since the customers' risk of default could not be measured using current systems and processes, payments appeared up-to-date due to the referred repayment period, putting the bank at risk. If income were lost during the repayment holiday period, the current behavioral models would not accurately reflect these events, as these models were not designed to predict short-term and immediate events, like a sudden loss of income due to widespread business shutdowns. What this meant is that the current definition of “delinquency” were not a reliable differentiator of risk for small business customers who received deferral arrangements under emergency procedures enacted during COVID-19.
Suddenly, the bank needed to assess how this would affect customer payments, and to do this they turned to machine learning. The bank used data immediately before the COVID-19 pandemic, using 3 months of historical data rather than the 12 months performance window used by the legacy behavioral models. The smaller historical period of 3-months meant that shorter-term variables that are highly impacted by COVID19 needed to be derived, rather than using the long-term drivers of the current models. For the short-term variables, the modelers derived these using advanced feature engineering techniques from customer transactions data, to ensure that recent changes in cash flows could be detected and modeled by the algorithm. Importantly, the transaction data–based feature engineering used income and expense variables highly affected by COVID19. Other variables used in the model included point-in-time ratios, early delinquency at customer group level, and drivers related to velocity of change such as utilization, disposable income, and business-specific risk drivers and self-employment flags. The bank observed that a GBM with a small depth and <100 trees were able to better predict which customers were likely to suffer sudden loss of income events and likely to experience default post-expiry of the COVID-19 holiday repayment scheme.
Approximation of Complex Risk Calculations
Like other sophisticated risk calculations, expected credit loss calculations are typically run as a batch, back-end process. Forward-looking, marginal losses are calculated for a range of scenarios, discounted back to the net present value, and weighted according to the probability of the scenario. If the probability of default has significantly increased since origination, the loan is recognized as stage 2 and lifetime losses are recognized. If not, a 12-month loss is recognized as provision for expected credit loss.
Before deciding on a new loan, what is the expected credit loss under this scenario? This can be approximated using machine learning. The benefit of machine learning is that it can quickly inform the estimated expected credit loss in real time, at the time of loan origination, leading to better decisions.
DEFINITIONS OF AI, MACHINE, AND DEEP LEARNING
Although we have discussed practical use cases of AI and machine learning in risk management, it is also important to appreciate how AI and machine learning is defined, and the major types that are used.
Artificial Intelligence
In 1950, the famous English mathematician Alan Turing asked the question, “Can a machine think?”4 That question has provoked the computer science domain from its very beginning. Turing's work during World War II on a machine that was able to decipher code from the Nazis' “Enigma” machine provided the edge that the Allied Forces needed to win the war in Europe. The machine underwent several improvements and influenced the development of the first digital computers.
Later in 1955, the American father of AI, the computer scientist John McCarthy, first coined the term artificial intelligence while preparing for a conference that explored ways to make machines reason like humans, capable of abstracting thought and solving problems.5 And this is what AI is essentially about, a computer system that can do tasks that humans need intelligence to do.
In general, AI is often used to describe computer-based systems that can think, learn, and respond to stimuli in their environment. Importantly, like human intelligence, the AI computing system can also subsequently act in response to these stimuli and create its own objective.6
Let us further solidify the understanding of AI by taking a purely hypothetical situation of a “paper clip maximizer”7: a machine that is programmed to make as many paper clips as possible. What if the machine became intelligent and, like a human, decided to create new paper clips by manufacturing machines to achieve its programmed goal and never stopped production? In this situation, humans may then intervene to create a governance framework to oversee the manufacturing process to ensure that only a million paper clips are created. However, what if, in turn, the paper clip machines decided to check their own work to ensure that they had correctly counted a million paper clips? To achieve this, the machines become self-teaching to make themselves smarter. The now smart and intelligent machines then create new raw-computing material to further check all aspects of the paper clip production that includes constraints (only 1 million paper clips are produced daily). But with each new check, the machines start to question what raw materials work best and so in response, the machines decide to create new raw materials. The result is that the now super-intelligent machines are mimicking every aspect of learning. They display features of intelligence and are thus essentially simulating what it is to be human.8
AI has already become deeply embedded in society and used by most of us daily, even if we are not aware. The wide availability of AI is a further tribute to the legacy of McCarthy. McCarthy did not leave us with a collection of theories and exploratory questions on machines and intelligence, but “list processing” (LISP), which was the language of choice for natural language processing (NLP) functions.9 To this day, LISP remains the standard AI language due to its ability to integrate LISP macros, which are a sequence of instructions that allow control over when and whether arguments are evaluated. More generally, NLP is used by programmers when an AI-enabled system interprets human language in the form of speech and text.10
Some great contemporary examples of LISP-enabled AI systems include the voice recognition technology used in iPhone's Siri or Amazon's Alexa that allow mobile devices to interpret essential elements of human language to return an answer.11 LISP is also used in navigation systems and applications that instantly translate language. Interestingly, from 2016, speech recognition has had profound improvements and has an ever-decreasing error rate. It is also about three times faster than typing text on a mobile phone.12 Currently, although LISP is used for keyword recognition and text to speech, it tends to be weaker on contextual analysis and informal expressions like “slang” that are used quite commonly in many spoken human languages.
Machine Learning
Machine learning was created by Arthur Samuel at IBM very early in the quest to develop AI. Samuel created a program that had the ability to learn parameters of a function for evaluating the position of checkers on a board during a game of play.13 Other programmers then created additional methods to enable self-learning by a computer, the most prominent of which is symbolic AI.14 Symbolic AI uses high-level symbolic representations of a problem that are human readable. The symbols are manipulated in an attempt to replicate human intelligence.15 One of the most successful methods of symbolic AI is so-called production rules that connect symbols to a relationship that shares close similarity to an IF–THEN statement in many programming languages. The system then processes the rules to determine if additional information is needed to solve a problem.16 However, the symbols can only be used when the input problem is definite.17 If any uncertainty to the problem exists, as is the case when making a prediction, then a neural network needs to be developed based on “fuzzy logic,” which is a type of stochastic search.
Coming back to the definition of machine learning, it is a subset of AI, and over many decades, has matured into a discipline to focus on solvable, practical problems using models and methods borrowed from statistics and probability theory.18
In essence machine learning refers to the ability of a machine to learn from data and to keep improving its performance without need of human interference.19 This means that in the process of a machine learning, a human does not need to continually dictate how to accomplish tasks, while the machine has the ability to utilize an automated self-learning/feedback loop. Machine learning is divided into three broadly defined categories of algorithms: (1) supervised learning, (2) unsupervised learning, and (3) reinforcement learning. Let us further look at each of these.
Supervised Learning
Supervised learning is where machine learning uses learning methods with a target variable to make a prediction.20 The data used for supervised learning is called labeled datasets since it includes the target variable.21 The labeled data is the training dataset from which the algorithms learn to make new predictions. Large datasets are needed to train supervised learning algorithms.22 Algorithms that can be used for supervised learning include:23
- Gradient boosting machine (GBM)
- Random forest and decision trees
- Naive Bayes classification
- Support vector machines
- Ensemble methods
As an example of how supervised machine learning is used in risk management, machine learning algorithms such as GBM and random forests have been used in decision science applications to improve accuracy and perform well with larger and higher dimensional datasets.
Gradient Boosting Machines
Gradient boosting is an ensemble method for regression and classification problems. It follows a boosted approach, whereby a group of models (weak learners) are combined to form a composite model (strong learner). Gradient boosting uses regression trees for prediction purposes and builds the model iteratively by fitting a model on the residuals. It generalizes by allowing optimization of an objective function.
Random Forests
Random forests are a combination of tree predictors such that each tree depends on a sample (or subset) of the model development data (or training data) selected at random.24 Working with multiple different sub-datasets can help reduce the risk of overfitting. Random forests or random decision forests are ensemble methods for regression and classification problems based on constructing multiple decision trees and outputting the class that may be either the mode of the classes (classification) or the mean prediction (regression) of the individual trees.
Unsupervised Learning
Unsupervised learning is another category of machine learning, but unlike supervised learning, it uses unlabeled datasets for knowledge discovery. As such, an unsupervised learning algorithm does not include a target variable. The following methods use algorithms to construct understanding of data that allows for machine learning to self-identify patterns in the data:
- Clustering
- Singular value decomposition
- Independent component analysis
Reinforcement Learning
Reinforcement learning differs from both supervised and unsupervised learning as it mimics the way that “agents”—an entity that understands how to make a decision based on past positive and negative experiences—learn by goal-seeking behavior in response to a reward stimulus.25 It entered the spotlight in 2016 when Google's AI program called AlphaGo beat the 18-time world champion of the game Go.26 A notable example that is often used to describe reinforcement learning is a grid world, where a robot is in a particular cell, say cell 2,3, and receives an instruction to let it know what cell it is in. In this context, the robot is capable of four possible subsequent actions: either to move one cell up, right, down, or left. The robot is assigned a negative point (–1) whenever it hits a wall of the grid or moves into a blocked cell, but it receives a positive award when it moves into a cell marked as goal. If the robot is moved to a random cell and then moves in a manner to increase its chances to receive a positive reward, then it has displayed features of learning. An example of reinforcement learning in risk management is in collections path treatment development. Here, the goals is set to maximize dollars recovered while minimizing costs of collections.
Reinforcement learning works well when humans can specify the goal but are uncertain about the optimal path.27
Deep Learning
The machine learning approaches described thus far have limitations in that they rely on a programmer to determine what is informative for making a decision that can achieve a preset goal.28 This means that the machine learning algorithm is dependent on the programmer and thus programmer insight. Furthermore, the machine learning approaches and algorithms previously described have all demonstrated to reach a definable plateau in their performance as the amount of data increases.
This is not the case with a more scalable machine learning algorithm referred to as deep learning where performance relies on large amounts of data to build models more accurately.29 Essentially, deep learning is performed when nets of neural networks that resemble layers are utilized for learning. Classes of deep learning include: (1) convolutional neural networks that analysts widely use for image recognition and classification, and (2) recurrent neural networks for sequence data like time series, text, speech, etc. The other side is that deep learning is not suited to smaller datasets used to develop traditional machine learning models.30
The reason deep learning does not deteriorate in terms of performance as the size of data increases is because the algorithms are able to learn independently by identifying structures in data (Figure 3.1). It then focuses on parts of these structures to achieve a goal.31 The power of deep learning is derived by use of a computing model that is inspired by the human brain32 and imitates the most basic biological processes of a brain cell, called the neuron, that in the brain contributes to learning and memory. Let us take a second to explain the neuron to better appreciate the biology that underpins the artificial process of deep learning. The human brain contains 8.6 billion fundamental units of nerve cells called neurons33 and these cells are highly specialized to transmit information.34 The 8.6 billion neurons are crammed into about 1.2L volume of brain tissue and form a vast network in that small space.35 Neurons are composed of a main body with very tiny extensions that branch off the main body called dendrites. An impulse transmits along dendrites to the information center of the cell body or to a dendrite of a neighboring neuron.36
To mimic the complexity of the biological neuronal network of the brain and create a deep learning model, the artificial neuron works like a biological cell where it receives a set of inputs (x) or impulses, each of which is assigned a specific weight (w). The neuron then computes numerous functions (y) on each of the now weighted inputs.37 Weights assigned are not arbitrary and derived by training a neuron, achieved by showing neurons a large number of training examples. These are iteratively changed to reduce error on the training examples.

Figure 3.1 Deep learning is the most complex form of supervised machine learning. It can scale because there are no performance limitations as the amount of data used for training increases. Also shown in the graph are other supervised and unsupervised machine learning algorithms/techniques. The size of the bubbles indicates complexity relative to others within each quadrant.
A classical challenge is overfitting. It is possible that a neural network becomes overfitted where the model produced by the algorithm perfectly performs each time on the training sample but fails in practice. The issue of overfitting occurs when too many parameters have been used and not enough training data points.38 The problem can be overcome by either adding more training samples that can run into the hundreds of thousands, sometimes millions, of data points,39 or by reducing the connectedness between neurons.40
The way in which the weighted inputs are computed depends on the type of activation function used. An activation function is a mathematical transformation that acts as the transfer function: it translates the input signal to the output signal. The more common activation functions used are:
- Identity functions that are linear. The value of the argument used for training is not changed and its range is potentially not bounded.
- Sigmoidal functions are S-shaped like logistic and hyperbolic tangent (or tanh) functions that produce bounded values with a range of 0 to 1, or –1 to 1.
- Softmax functions are multiple logistic functions and are a generalized representation of logistic regression that forces the sum of their values to be 1.
- Value functions are bell-shaped functions such as a Gaussian function.
- Exponential and reciprocal functions are bounded by 0 and 1.
Linear activation functions take a linear combination of each weighted input, while nonlinear activation functions like the sigmoidal function take a sum of the weighted inputs into a logistic function. For example, when learning the sigmoidal logistic function initially approximates an exponential equation. Please note that these intrinsic characteristics of the sigmoidal logistic function are not to be confused with machine learning optimization discussed in Chapter 8. Furthermore, with a sigmoidal neuron, the value that gets returned is between 0 and 1 and is dependent on the weighed input that gets summed. For instance, if the weighed sum is negative, then the returned value is close to “0.” Despite their limitation, sigmoidal neurons are used more often than linear neurons, as the generated algorithms are much more versatile in comparison.41
Neurons are also the building blocks of the entire nervous system of the body and receive sensory information from the external environment and send commands to muscles among many other known functions.42 The functionality of the neuron is extremely complex, and the complexity in turn stimulates active areas of research and development that could, at some point, further augment and drive new ways of approaching and applying deep learning along the road to replicate human intelligence.
Artificial Neural Networks
An artificial neural network in a deep learning algorithm is created in an analogous manner to a biological neural network in that its creation is dependent on many interactions: from the input data, between many neurons, and the output generated from the neural network's response. Deep learning algorithms are further complicated by nets of neural networks that resemble layers. Neurons at the input layer are connected to the actual output or answer to the problem and need not connect to each other, while neurons at the output layer are connected to one another and directly receive input data. The network can be feed-forward where there are no connections between neurons at the input to those at the output layer, or recursive where there are connections between input and output layers43 (Figure 3.2).
There can also be a hidden layer that exists between the input and output layers. The hidden layer itself is where the wondrous power of the network solves problems and derive features of the input data that are extracted to learn and derive an output. Technically, the hidden layer involves an extra transformation of some type but requires no extra parameters. Interestingly, the hidden layer is where the “deep” aspect of deep learning gets derived—a neural network with many hidden layers is considered “deep.”44 The most popular form of a neural network is a multilayer perceptron (MLP) that has any number of inputs, usually at least one hidden layer, and many neurons in each hidden layer. The MLP can have a different number of neurons in each hidden layer and has weights between the following:
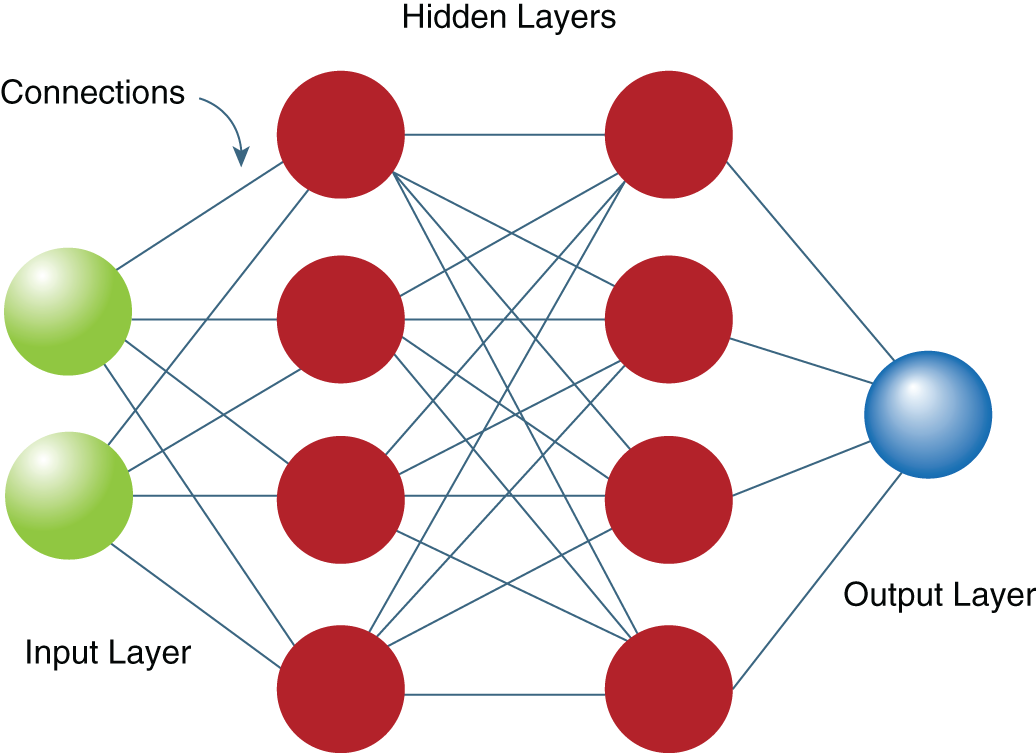
Figure 3.2 Schema of an artificial neural network with hidden layers.
- The input layer and first hidden layer
- One hidden layer to the next hidden layer when there is more than one hidden layer
- The last hidden layer and the output
Automated Machine Learning
There are now platforms available that offer automated machine learning (AutoML). These offer predeveloped model templates for a range of algorithms. This allows the predefined model pipelines to run in parallel against a training dataset and automate, train, and evaluate predictive accuracy of each model, with very little human intervention required. AutoML is useful when modelers are not certain of choice of algorithm.
Overall, AutoML allows for fewer assumptions to be made by a modeler by evaluating different model pipelines to find the most predictive model for the dataset, so that the best predictive models that are the best fit for the dataset are developed. Model pipelines can be based on templates that can include data processing, apply regulatory constraints and check for bias and fairness of model outcomes. In addition, the models generated by AutoML still need review and justification, including explaining both the interpretations and decisions are fair, safe, and transparent. We explain these considerations in Chapters 4 and 5.
A Further Note: Robotic Process Automation
Once a machine has been taught to solve a problem, the resulting logic can then be deployed—this is the aim of a machine learning algorithm. When deployment of the machine replaces a business process, is truly self-sustaining, and requires little human intervention, then that automation is referred to as robotic process automation (RPA). In some cases, RPA is successfully deployed to replace the traditional strategies of cost savings, such as offshoring and outsourcing business operations.45
RPA has started to replace traditional cost-saving strategies because it is estimated in some cases to run at a much lower total cost of a typical human resources. In addition, RPA has been shown to dramatically reduce processing time and eliminate error rates.46 Interestingly, the International Foundation of Robotics published that the use of robotics has nearly doubled over five years, and as of December 2021 there are now 126 robots per 10,000 employees. There are many examples of RPA in the insurance industry where the process of claim forms that once took workers four days to complete has been cut to a mere two hours.47
Putting It All Together
To summarize the terms of reference48 AI is referred to as the “superset” and was the first to be discovered in the 1950s. It has rapidly evolved and expanded ever since. Machine learning is a subset of AI and was created as part of our continuing quest to simulate human intelligence. Although deep learning was discovered soon after machine learning, its power and scalability had to wait for appropriate computing power.49 Deep learning is an innermost subset, being a class of machine learning that utilizes layers of neural networks that enable complex tasks like computer vision.
CONCLUDING REMARKS
AI and machine learning are progressing rapidly in the financial services industry around the globe. However, it should be noted that some countries have much slower rates of adoption due to the unease around its use for regulatory compliance purposes.50 Companies in some countries are embracing AI and machine learning at rates that are half of that compared with global peers. As such, it has been argued that these countries need to double their pace of AI and machine learning to reap the benefits, estimated at $15.7 trillion to be added to the global economy by 2030.51 However, financial institutions must have an action plan for extending their use of innovative, advanced techniques, while ensuring that the fundamentals to manage the risk model lifecycle, including data management, and quality and robust infrastructure to support deployment are in place.
ENDNOTES
- 1. Jo Best, “IBM Watson: The inside story of how the Jeopardy-winning supercomputer was born, and what it wants to do next,” TechRepublic, (CBS Interactive, 2013); C. Mercer, “Which companies are using Watson's big data and analytics to power their business?” Computerworld (2018).
- 2. John Markoff, “Computer Wins on Jeopardy!: Trivial, It's Not,” New York Times (February 16, 2011).
- 3. Mercer, Which companies are using Watson's big data and analytics to power their business?
- 4. Alan Turing, “Computing machinery and intelligence,” Mind: A quarterly review of psychology and philosophy IX(236) (1950); Rebecca Jacobson, “8 things you didn't know about Alan Turing,” PBS News Hour (2014).
- 5. Martin Childs, John McCarthy: Computer scientist known as the father of AI (Kensington, London: Independent, 2011).
- 6. Anand S. Rao, Gerard Verweij, and E. Cameron, Sizing the Prize—What's the Real Value of AI for Your Business and How Can You Capitalise? (Boston: PricewaterhouseCoopers, 2017).
- 7. Nick Bostrom, Superintelligence: Paths, Dangers, Strategies (Oxford United Kingdom: Oxford University Press, 2016).
- 8. Childs, John McCarthy.
- 9. Sarah Butcher, The Ancient Programming Language That Will Get You an AI Job in Finance (New York: efinancial careers, 2017).
- 10. Childs, John McCarthy; Margot O'Neill, Explainer: What is artificial intelligence? (Sydney, NSW, Australia: ABC News, 2017).
- 11. Sarah Butcher, The Ancient Programming Language That Will Get You an AI Job in Finance.
- 12. Erik Brynjolfsson and Andrew McAfee, “The business of artificial intelligence—What it can and cannot do for your organization,” Harvard Business Review (July 18, 2017).
- 13. Arthur L. Samuel, “Some Studies in Machine Learning Using the Game of Checkers,” IBM Journal of Research and Development 3:211–229 (July 1959); Nils J. Nilsson et al., An Introduction to Machine Learning—An Early Draft of a Proposed Textbook. 1st ed. (Stanford, CA: Robotics Laboratory, Department of Computer Science, Stanford University, 1998).
- 14. Allen Newell and Herbert Simon, “Computer science as empirical inquiry: Symbols and search,” Communications of the ACM 19(3)(1976): 113–126; Nilsson, An Introduction to Machine Learning.
- 15. Nilsson, An Introduction to Machine Learning.
- 16. Newell and Simon, Computer Science as Empirical Inquiry, 113–126.
- 17. Newell and Simon, Computer Science as Empirical Inquiry, 113–126; Nilsson, An Introduction to Machine Learning.
- 18. Pat Langley, “The changing science of machine learning,” Machine Learning 82(3) 2011): 275–279.
- 19. Brynjolfsson and McAfee, The business of artificial intelligence.
- 20. O. Zhao, AI, Machine Learning and Deep Learning Explained (New York: ElectrifAI, 2017).
- 21. J. Le, Algorithms, Machine Learning, Supervised Learning, Unsupervised Learning (Detroit, MI: KD Nuggets, 2016); Zhao, AI, Machine Learning and Deep Learning Explained.
- 22. Le, Algorithms, Machine Learning, Supervised Learning, Unsupervised Learning.
- 23. Le, Algorithms, Machine Learning, Supervised Learning, Unsupervised Learning; Zhao, AI, Machine Learning and Deep Learning Explained.
- 24. Leo Breiman, Random Forests (Berkeley: Statistics Department, University of California–Berkeley, 2001).
- 25. Nilsson, An Introduction to Machine Learning.
- 26. Zhao, AI, Machine Learning and Deep Learning Explained.
- 27. Brynjolfsson and McAfee, The business of artificial intelligence.
- 28. Nikhil Buduma, Deep Learning in a Nutshell—What It Is, How It Works, Why Care? (Detroit, MI: KDnuggets, 2015); Brynjolfsson and McAfee, The business of artificial intelligence.
- 29. Zhao, AI, Machine Learning and Deep Learning Explained.
- 30. Brynjolfsson and McAfee, The business of artificial intelligence.
- 31. Buduma, Deep Learning in a Nutshell; D. Petereit, AI, Machine Learning and Deep Learning Explained (Hanover, Germany: CEBIT, Deutsche Messe, 2017).
- 32. Buduma, Deep Learning in a Nutshell; D. Petereit, AI, Machine Learning and Deep Learning Explained; Zhao, AI, Machine Learning and Deep Learning Explained.
- 33. Suzana Herculano-Houzel, “The human brain in numbers: A linearly scaled-up primate brain,” Frontiers in Human Neuroscience 3(31) (2009).
- 34. Kenneth S. Kosik, “Life at low copy number: How dendrites manage with so few mRNAs,” Neuron 92(6) (December 21, 2016): 1168–1180.
- 35. Herculano-Houzel, The human brain in numbers.
- 36. Kosik, Life at low copy number, 1168–1180.
- 37. Buduma, Deep Learning in a Nutshell.
- 38. Buduma, Deep Learning in a Nutshell.
- 39. A. Copeland, Deep Learning Explained—What It Is, and How It Can Deliver Business Value to Your Organisation (Santa Clara, CA: NVIDIA Deep Learning, 2016).
- 40. Buduma, Deep Learning in a Nutshell.
- 41. Buduma, Deep Learning in a Nutshell.
- 42. Herculano-Houzel, The human brain in numbers; Kosik, Life at low copy number, 1168–1180.
- 43. Buduma, Deep Learning in a Nutshell.
- 44. Zhao, AI, Machine Learning and Deep Learning Explained.
- 45. Shane O'Sullivan and Brandon Stafford, RPA and Your Digitisation Strategy (Sydney, NSW, AUS: PricewaterhouseCoopers, 2016).
- 46. O'Sullivan and Stafford, RPA and Your Digitisation Strategy.
- 47. Jared Wade, RPA in Action: Innovative Ways Five Financial Services Companies Are Using Automation (Amsterdam, Netherlands: Finance TnT, 2018).
- 48. Zhao, AI, Machine Learning and Deep Learning Explained.
- 49. Copeland, Deep Learning Explained; Zhao, AI, Machine Learning and Deep Learning Explained.
- 50. Lin Evlin and Margot O'Neill, Australia must embrace AI revolution with automation set to affect every job, report says, Lateline, (Sydney, AUS: ABC News, August 8, 2017), https://www.abc.net.au/news/2017-08-08/australia-must-embrace-ai-revolution-alphabeta-report/8774044
- 51. Rao and Verweij, Sizing the Prize.