
CHAPTER 5
Bias, Fairness, and Vulnerability in Decision-Making
“…you do not really understand a topic until you can teach it to a mechanical robot.”
—Judea Pearl and Dana Mackenzie
In recent times, topics related to the ethical use of artificial intelligence (AI) and machine learning have been much debated by industry practitioners, regulators, and the public. It is now well understood that one of the unintended consequences of AI and machine learning is the risk of making biased decisions that can lead to unfair outcomes. The biases can stem from the historical and societal biases in the data that is used for training the models or introduced in the model development process itself. Biased models and decisions can lead to unintended consequences such as disparity or lack of access to the issuance of credit and insurance policies for minority groups.
One of the promises of AI and machine learning is to reduce bias and unfairness in financial decision-making, facilitated through automation. However, despite the promise, we do not need to look far to find examples where AI and machine learning reinforced bias and amplified unfairness in decision-making: from prioritizing job applications based on gender, to computer vision that discriminates based on race, to credit limit approvals that are gender biased.1
Data input and data capture by people, source systems, and applications that vary across different geographic localities can result in inaccuracies due to mislabeling, misinterpretation, or incomplete data processing. The data may not be representative of the population that the data will be applied on.
When the dataset used for model development includes historically biased outcomes, the same biased dataset is then used to train potentially biased models. In AI and machine learning, the issues that lead to bias increase the risk of unfair decisions and are made worse when characteristics or features that are correlated to protected variables are used. Protected variables are variables with legal or ethical restrictions. These can include groups that cannot be discriminated against in certain jurisdictions (e.g., demographic variables like gender and race). The models and business rules may also introduce bias.
It is also important to consider that bias in decision-making can originate from a range of sources, not only the training data. These sources may include the data used for model development, model assumptions, the models themselves, or business rules or other decisions made independently from the model that are impacting the model outcome.
Risk decisions are often further complicated by manual assessment processes and procedures where outcomes are by nature qualitative. An example includes judgmental decisions made by different manual assessors, analysts, and managers. Although most organizations have policies and procedures in place to guard against irresponsible conduct and hold decision makers accountable, it does not mean that all decisions are fully exempt from bias.
ASSESSING BIAS IN AI SYSTEMS
In recent years, the conversation of responsible AI has evolved from the philosophy of ethics in the use of machine-led decision-making, to a sociotechnological discussion on quantifiable ways to ensure automated systems are upheld by the same codes of conduct and ethical standards as human decision-making.
Keep in mind that with supervised learning, like AI and machine learning, predictive modeling is discriminatory by design, as the goal is to differentiate based on the values of a labeled variable. However, when the algorithm discriminates based on data that is nonrepresentative of the population or inputs with legal and ethical restrictions, it may violate consumer protection and data privacy laws. In the context of lending and insurance decisions, it is generally in the best interests of the services provider that the model outcome is as accurate as possible using all reasonably available information. This may come at the expense of the desire of the consumer, which is interested in the most favorable model outcome. This means that a careful balance is needed between business aims and fair and responsible model outcomes. Addressing bias and ensuring that decisions are made equitably can help safeguard vulnerable consumers from exploitation throughout their lifetime. To counter bias, fairness assessments should be embedded across the customer lifecycle (Figure 5.1). In this diagram, models at the point of loan onboarding have been selected as the working example, but assessing the fairness of outcomes is needful for model types across the customer lifecycle, including those used for account management and collection strategies.
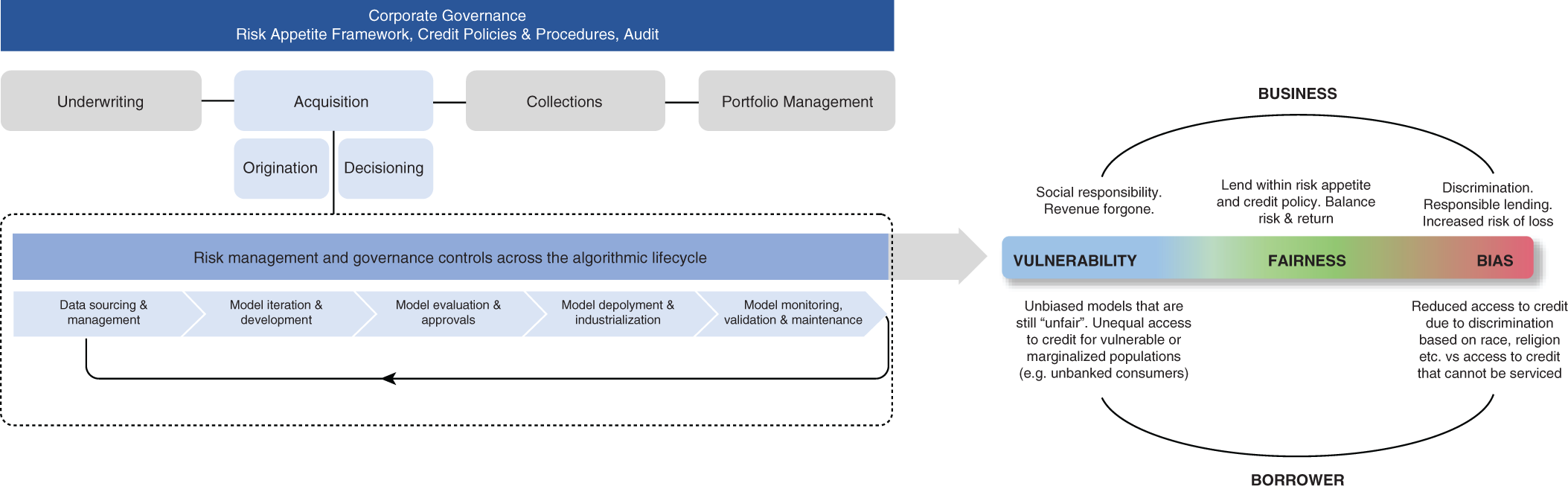
Figure 5.1 Assessing bias, fairness, and vulnerability across the customer lifecycle.
For example, biased decisions at the time of onboarding, either from the model design or data capture, can result in measurable differences in the treatment of consumers with similar risk profiles, and are considered unfair.
Fairness is concerned with the fair decisions of models and the equitable distribution of benefits. Consumers' vulnerability is measured along the customer journey and is typically marked by circumstantial changes that can be worsened by unfair decisions. For services providers, it is becoming increasingly important to incorporate the vulnerability of consumers in their decision-making. For example, a change in circumstances can lead to financial stress and may require active account management.
Importantly, balancing fairness with business objectives will require:
- Assessing a range of fairness metrics to mitigate different types of bias (data bias, model bias, evaluation bias, etc.), including an ability to select metrics appropriate to the context in which the model is used
- Ensuring that fairness assessments are embedded in the end-to-end model lifecycle and decisioning processes
- Using powerful tools to assess fairness at an individual and group level
The use of advanced fairness measurement tools supports the careful analysis of protected variables, the investigation of fairness risk, and its root causes.
In this chapter, we explain the current definitions and measures of bias, fairness, and vulnerability as they relate to data and models. It must be noted that most risk models, whether traditional, statistical models, or those developed using AI and machine learning, need to be assessed for latent bias and unfairness. With AI and machine learning, bias and unfairness are more challenging to detect by human intuition alone. In this chapter, we focus on the application of models as it relates to impacting consumers. That does not preclude other types of models from the risk of leading to unfair decisions. Having said that, this chapter will pay attention to vulnerability concerns throughout the customer journey. This will be helpful to ensure that automated systems are able to deliver on the promise of addressing fairness in decision-making and thus increasing the value of the risk models to organizations, consumers, and society.
WHAT IS BIAS?
Bias in AI systems occurs when human prejudice based on mistaken assumptions becomes part of the way automated decisions are made. A well-intentioned algorithm may inadvertently make biased decisions that may discriminate against or treat protected groups of consumers differently.
Bias may occur and enter at any point in the model lifecycle. A common misnomer is that bias stems only from training data that is not well diversified, and although that is a common source for bias to arise in automated systems, in fact, bias may enter the model lifecycle much earlier—for example, in the way the problem statement is formulated or in the way data gets collected.
When the bias stays undetected, it may be systematized and amplified by automated decision systems.
In risk models—including those leveraging AI and machine learning—bias may stem from the training data. Such issues may arise from historical biases as well as the ways in which the data is sampled, collected, and processed. This means that the training data is not representing the population to which the model will be applied, leading to unfair decisions. Bias can also be created during the model design phase. That can create measurable differences in the way a model performs in definable subpopulations based on a profile. For example, the profile can be based on the variables included or approximated in model construction like age, gender, race, ethnicity, and religion. An example is the historical racial bias that has been captured by credit bureau scores. Although the scores are not capturing race directly, they have been developed on historical data that includes payment history, amounts owed, length of credit history, new credit, and credit mix information. These variables are themselves influenced by the generational wealth that African American and Hispanic borrowers did not have equal access to. This bias will continue to produce lower credit scores and lower ability to access credit for these groups.2 As another example, in 2015, the White House together with the Federal Trade Commission conducted research that found that as consumers operate in groups, minority groups may be unfairly treated when big data is used for credit scoring. The study emphasized the need to assess correlations of key drivers with protected variables when big data is used.3
WHAT IS FAIRNESS?
Fairness is considered a moral primitive and is by nature judgmental. Given its qualitative character, it is more challenging to define fairness comprehensively and globally across applications. Distinct cultures will have different definitions of what constitutes a fair decision. The philosophy of fairness is outside the scope of the book; however, when it comes to the technological approaches to incorporate fairness checks in AI systems, in recent years, system integrators and software providers have started to package fairness detection and remediation techniques.
Most societies uphold values of equality and equity. In the USA, fair lending laws, such as Regulation B and the Equal Credit Opportunity Act (ECOA), protect consumers from discrimination in lending decisions. The statute makes it unlawful for any creditor to discriminate against any applicant with respect to any aspect of a credit transaction based on race, color, religion, national origin, sex, marital status, or age.
Any adverse action for credit needs to be supported by evidence to prove the decision is not based on a prohibited characteristic. The Consumer Financial Protection Bureau has recently published a report with guidelines on the use of AI-based lending decisions.4 In summary, it emphasizes the need for explanations that can help lenders generate fair lending and adverse action notices, while utilizing AI and machine learning models.
In the context of algorithmic models, the widespread practice is to associate fairness with equitable decisions and parity in the distribution of benefits across demographic segments.
Kusner, Russell, and Silva5 define algorithms as fair on a range of fairness levels. For example, if an algorithm is fair through unawareness, then the algorithm is unaware of protected variables, and therefore cannot discriminate against groups of protected variables. An unintended consequence of fairness through unawareness is that a combination of characteristics may inadvertently approximate protected variables.
Kusner et al. go further in defining a second level of fairness when an algorithm gives similar predictions to similar consumers. In addition, a third level of fairness is seen when the algorithm supplies equality of opportunity and similarity across demographics. Finally, a fourth level of fairness is observed when an algorithm is counterfactually fair—that is, fair in the actual dimension, as well as in the counterfactual dimension.
A problem with fairness is that when fairness expectations are translated into quantifiable terms, these terms are not mutually exclusive. A recidivism example highlighted the nonexclusivity of fairness metrics.6
TYPES OF BIAS IN DECISION-MAKING
Bias may stem from multiple sources. Let us differentiate between cognitive and statistical biases.
In the early 1970s, Amos Tversky and Daniel Kahneman7 introduced the term cognitive biases to describe people's systematic but purportedly flawed patterns of responses to decision problems.
When putting in place a governance framework for AI and machine learning, it is helpful to first consider the types of cognitive bias to be aware of, and the controls that can safeguard against these.
A few of the cognitive biases are:8
- Overconfidence results from a false sense of control, optimism, and the desirability effect: an AI system will make fair predictions because we want it to. A variant of that is the herd mentality (see below).
- Self-serving bias results from a human tendency to attribute good success to skills and bad success to unfortunate events: an AI system is correct on a set of data because the model is well developed, and inaccurate on another, not due to poor construction, but population drift or other uncontrollable reasons.
- Herd mentality is when decision-making is performed by blindly copying what peers are doing. In this case, the decision is influenced by heuristic simplification or emotion rather than independent analysis.
- Loss aversion is a tendency to experience larger regret from losing than satisfaction from winning.
- Framing is when a decision is made based on the way the information has been represented. If it was represented in another way, a different conclusion would be reached.
- Narrative bias is a human tendency to make sense of the world using stories. Information that does not fit the storyline gets ignored.
- Anchoring occurs when preexisting data is used as reference point and influences later decisions.
- Confirmation bias is a tendency to seek out information and data to confirm preexisting ideas.
- Representativeness heuristic is a false sense that if two objects are similar, they are also correlated.
Here are some common sources of statistical bias:
- Selection bias occurs when the data for model development is systemically different from the population to which the model will be applied.
- Sampling bias refers to an error caused by non-random sampling. It means that the data will not be representative of the population. It can occur based on the data collection method, confirmation bias, the selected time interval or changes made to the raw data.
- Survivorship bias is a variant of selection bias, the phenomenon where only those who “survived” a lengthy process are included in or excluded from the analysis, thus creating a biased sample.
Current Guidance, Laws, and Regulations
As there is, in general, a lack of legislation on fairness in AI systems, a good example to consider is of existing consumer protection frameworks. As mentioned in the previous section, the Fair Credit Reporting Act and the Equal Credit Opportunity Act (ECOA) defined the standards for fair lending in the United States.
The Fair Credit Reporting Act (Title VI of the Consumer Credit Protection Act) enforces the protection of consumer data and limits its use to specific purposes as specified by the act. It also allows for the investigation of disputed information.
The Equal Credit Opportunity Act (Regulation B) promotes equal access to credit to creditworthy applicants and prohibits discrimination based on race, skin color, religion, national origin, sex, marital status, or age. It goes further to notify applicants of actions taken on their application, to collect information on race for dwelling-related loans, and to keep records of applications.
Even though fair lending in credit decisions has been regulated in some jurisdictions for decades, there are still persistent issues with the fair treatment of minority groups and equal access to credit.
Having said that, we do have a precedent of how fairness in some automated systems is regulated today, together with industry consultation on how that can be extended for AI and machine learning.
Given its evolving nature, the intention of the next section is not to present a final solution to address fairness (and bias) in automated systems, but to provide an overview of current and evolving practices.
Methods and Measures to Address Bias and Fairness
Many measures have been developed in different areas, such as finance, insurance, and healthcare, to identify bias in data and to assess the fairness of model outcomes. For risk management, it is recommended that bias and fairness measures are embedded as controls throughout the lifecycle of the customer and across the risk model lifecycle (Figure 5.1). It is important to understand the limitations of fairness metrics: the measures to detect bias and fairness cannot guarantee the presence or absence of bias and fairness or expunge the fact that fairness concerns can appear later due to other exogenous factors, such as changes to data. Next, we will explain some of the methods and measures that can be used to detect and remediate bias by signaling for human intervention to correct bias and fairness issues.
At the time of writing, the development of fairness metrics is maturing, including metrics for AI and machine learning.
Following are examples of common approaches and metrics used to detect bias and fairness:
- Demographic parity. This is where each segment of a demographic variable, or “protected class,” is assessed to receive the same positive outcome at an equal rate.
- Equal opportunity. The metric validates that the true positive rate between segments is the same. By extension, it also measures that an equal true negative rate is observed across segments.
- False positive rate balance. It measures that the false positive rates (and by virtue, the true negative rates) between segments are equal. An example is loan applicants, where the rate balance ensures a representative fraction of each segment that is predicted to default on their loan.
- Equalized odds or average odds. This assumes that the true positive rates between segments and the false positive rates between segments are equal (equivalently, equal true negative rates and equal false negative rates).
- Positive predictive parity. Here, the positive predictive value between segments is equal (i.e., each segment has the same false negative predictive rates). This is achieved by comparing the fraction of true positives to the fraction of predicted positives in each segment.
- False omission rate balance. The false omission rates between segments are equal (i.e., the segments have equal negative predictive value). The rate compares the fraction of false negatives to the fraction of rejections/negative benefit.
- Feature attribution analysis. Utilize feature attribution analysis to find drivers that affect decisions, for example, to ensure that factors are not correlated with protected variables.
- Sensitivity analysis. Perturbations are used to assess sensitivity to changes in demographics.
- Correlation analysis. When there are variables that are correlated with sensitive variables such as age, sex, or family status, it can lead to unfair outcomes.
- Cross referencing. Utilize outcome analysis and cross-referencing to assess model accuracy across protected and nonprotected groups. An unfair individual decision may be observable in a particular demographic segment but is not measurable when the entire population is considered.
- Triangulation. This is where a situation is explored in depth using more than two sources to validate findings. There are other types of triangulations:
- Methodology: using more than one method to gather data points and where more than one measure is used.
- Data: involving varying dimensions such as time, space, and person.
- Investigator: where more than one person is involved.
- Counterfactual analysis. To assess fairness at the individual level, in counterfactual analysis, to evaluate the change in outcome, the causal attributes of the same record is compared with an adjusted version of the record.
As mentioned previously, a good starting point is to assess for bias and fairness by comparing the prediction and performance made by a model for different values of protected or “sensitive” variables (Figure 5.2). Examples of sensitive variables are those that are demographic in nature, including variables such as age, gender, race, religion, family status, marital status, and ethnicity.
Using AI and Machine Learning to Detect and Remediate Bias: A Word of Caution
In some cases, the use of AI and machine learning can help detect and remediate bias automatically. Similar to other AI and machine learning use cases, to assess fair lending risk may pose the same challenges of explainability (understanding the reason for a prediction estimate). One of the challenges to confirming AI-based models is that some traditional model validation approaches or metrics are not readily applicable. The drivers behind the decisions cannot be easily found or separated from other variables due to the additional complexity of the input data and algorithms.
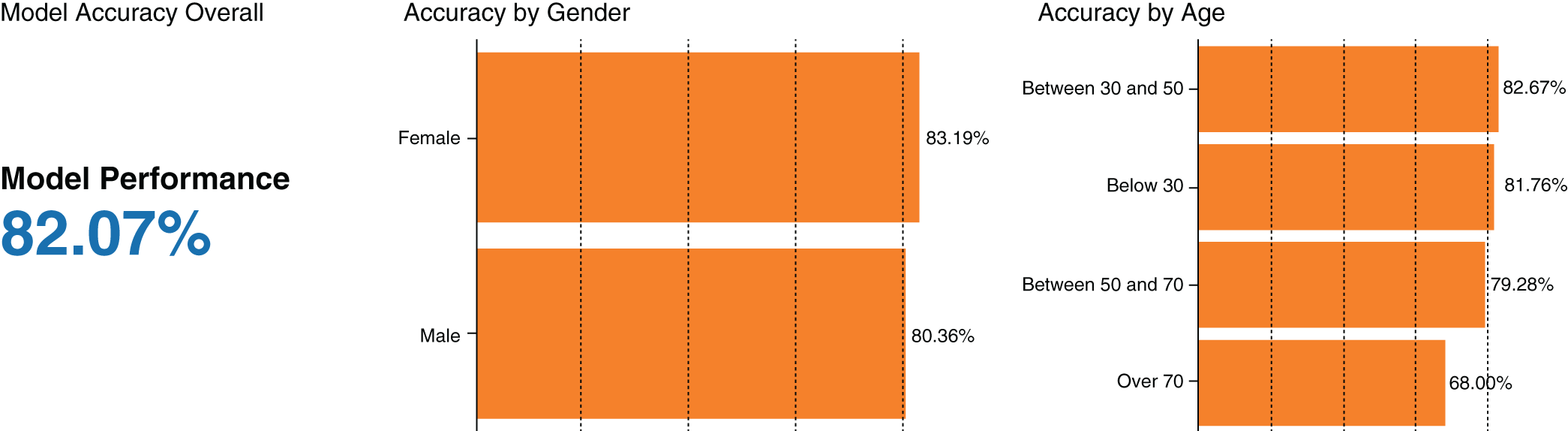
Figure 5.2 Disparity analyses assess model performance across classes of protected characteristics (in this case, gender and age).
Another challenge is to understand why the AI and machine learning identified a high risk of bias given its inherent inability to justify the inclusion of model variables, compared to a traditional, statistical model where the variables and signs of parameters are known.
The AI system itself may be subject to protected variables implicitly or indirectly. In this case, standard techniques to determine correlations in the model can be applied. In addition, explainability metrics can be used to explain the main drivers behind decisions. Model sensitivity analysis, benchmarking, and trade-off analysis are other popular methods that are often used by financial institutions to test and confirm models.
In summary, AI approaches will still need to follow existing consumer protection and regulatory frameworks (including Regulation B and the ECOA). Like any other type of model, AI models can be flawed and are also subject to bias, which impacts model predictability. Bias can be caused by either data or algorithms that cause the model to be insufficiently or incorrectly trained. When the sample data used to train the models does not sufficiently represent the population, the model that will be applied to over- or underrepresenting minority groups will have higher risk of unfair treatment. If the AI is biased, that bias will be perpetuated and potentially be amplified through automated decision-making.
A benefit of automation is that if the bias is properly addressed, automated decision-making has the potential to be more consistent and traceable than human decision-making. In areas with strict requirements for explainability, model governance frameworks should be extended with the specifics for AI and machine learning.
Model risks associated with AI-based modeling approaches can be more pronounced as complex algorithms and input data are usually involved in the modeling process. Complex transformations or interdependence of model variables can make it more challenging to uncover hidden patterns that may potentially violate fair lending laws. Thus, it is more important for institutions to ensure model risk management principles and governance are enforced when developing AI and machine learning.
These principles aid the evaluation of AI-based approaches as many organizations have in place model risk and data governance systems.
Financial institutions must prove their understanding of the model inaccuracies and potential for unintended consequences (i.e., risk of noncompliance with fair lending laws).
Robust model risk management framework will collect, and make readily available, information that consistently and reliably enforces fair lending laws. This can be further extended to financial institutions having the ability to recognize and remediate the potential for discrimination above and beyond regulations.
In addition, financial institutions can enforce constraints or rules on input data, ensure that the training data does not have protected characteristics, apply data quality checks to prevent data measures from contamination or influence by subjective errors, and document and validate the methods used to debias the data.
Vulnerability
Today, the identification of customers that are “vulnerable” is not regulated in all given authorities. Despite this, understanding that customers are more vulnerable to disruption in the customer lifecycle by unfair decisions, or changes that impact lifestyle is a key consideration by market players that issue products and services. These lifecycles have many stages, ranging from the point of awareness or investigation through to an expanding relationship where more products or services are acquired by a customer, including, financial services (including unregulated “fringe” lenders), insurance, superannuation, and telecommunications (Figure 5.3).
As a customer journey with a market player progresses from awareness through to expanding the existing relationship the risk to vulnerability “shocks” can increase. There are many different contact channels that exist between a market player and a customer that can serve as interaction points to assess the increased likelihood of customer vulnerability.
Figure 5.3 Vulnerability is a key consideration that market players that offer products, goods, and services are starting to consider throughout their entire journey with customers.
Protecting vulnerable customers from hardship or stress has continued to be a major consideration throughout the COVID-19 pandemic and left many small business owners facing serious financial stress and insolvency. The stress has shown to also extend to homeownership, where mortgagees have changed their repayments or deferred them. For financial credit providers, there is value in predicting which customers are more likely to default after the expiration of a repayment deferral program. Such models focus on the major stress event of a pandemic, but not on the increased risk of vulnerability that may have existed before the COVID-19 pandemic. Such latent vulnerability risk is important to understand and model, especially considering the best opportunity to provide support through the customer journey (Figure 5.3).
Regulators are increasingly focusing their attention on better understanding the context in which automated decision systems operate. Better protecting vulnerable customers has been receiving attention from the government and regulatory bodies long before the COVID-19 pandemic but has become more pronounced in recent times.
For example, the energy regulator in the United Kingdom, Office of Gas and Electricity markets (OFGEM), published its first consumer vulnerability strategy in 2013.9 The strategy helped OFGEM to better understand vulnerable consumers, which in turn led to the development of frameworks and the practical implementation of consumer protection policies for better decision-making.
For consumer lending, the Financial Conduct Authority (also in the United Kingdom) has a broad definition for vulnerable consumers as “…someone who, due to their personal circumstances, is especially susceptible to detriment, particularly when a firm is not acting with appropriate level of care.”
Their guidance defines the details on the key drivers and characteristics of vulnerability. Key drivers include health, financial ability, financial resiliency, and life events.
The FCA defines the personal, behavioral, social, and market-led characteristics that may be associated with increased vulnerability of consumers as:
- Age—young or old
- Living in a remote area
- Low income
- Periods of over-indebtedness
- Homelessness
- Having an indigenous background
- Low reading, writing, and numerical skills
- Speaking a primary language other than the predominant language of a country
- Diverse cultural background, assumptions, or attitudes
- Having either an intellectual, psychiatric, physical, sensory, neurological, or learning disability
- Having limited access to technology
- Inexperience with products or services offered
- Insufficient or misleading information released to the market
The FCA published guidance as well as policies like Policy 18/19 that highlights the importance of assessing affordability in credit risk, including the use of income and expenditure information. In 2017, the FCA published guidance on conduct for forbearance that helps guide financial institutions on how to better embed fairness and assessments of the customer’s ability to repay into their pre-collections and collections treatment strategies.
By better understanding vulnerable consumers, financial institutions can offer better services, reduce losses, and avoid costly investigations into misconduct. This can be achieved by:
- Making better use of internal demographic data so that vulnerable customers are better identified
- Developing toolkits or using third-party software to help design frameworks, governance processes, and products and services to reduce vulnerability
- Engaging with customers at the earliest time possible to help with the design of products and services to mitigate the impacts of vulnerability
- Tailoring offerings of products and services to ensure appropriateness for vulnerable customers
The costs of not investing in better identifying or protecting vulnerable customers are high. This can involve multi-million-dollar penalties imposed due to the violation of consumer protection laws as well as reputational damage. On the other side, implementing vulnerability safeguards can generate benefits such as better customer and employee satisfaction and improved sales opportunities from more flexible products and services for a wider range of customers.
At financial institutions, the efforts underway are often driven by regulatory compliance. An example is reducing the time needed to resolve customer-initiated disputes. Some of the early studies have leveraged sentiment analysis using voice-to-text data to find sequences of sentiments that are expressed during a discussion. These sequences are then used as classifiers to predict dispute or nondispute targets.10 Furthermore, convolutional neural networks can also be applied to voice-to-text data to identify sentiment word vectors.11 Dispute resolution and complaints analysis represents an easy way to apply advanced analytics to reduce the time to resolution and scale across multiple interaction channels across the enterprise.
CONCLUDING REMARKS
The use of advanced analytics to better understand bias, fairness, and the vulnerability of consumers is increasingly being brought to the frontline, rather than functioning in the back or middle office. Creating frameworks and processes to mitigate bias and assess fairness in decision-making will mean that in future these can also be expanded to other risk models, including those used for real-time risk assessments, and the managing and mitigation of emerging risks.
ENDNOTES
- 1. Basileal Imana, Aleksandra Korolova, and John Heidemann, “Auditing for discrimination in algorithms delivering job ads.” In Proceedings of The Web Conference 2021 (WWW ‘21), Ljubljana, Slovenia, (April 19–23, 2021), https://ant.isi.edu/datasets/addelivery/; Larry Hardesty, “Study finds gender and skin-type bias in commercial artificial-intelligence systems,” MIT News (February 11, 2018), https://news.mit.edu/2018/study-finds-gender-skin-type-bias-artificial-intelligence-systems-0212; Associated Press, NY regulator investigating Apple Card for possible gender bias. NBC News (November 10, 2019), https://www.nbcnews.com/tech/apple/ny-regulator-investigating-apple-card-possible-gender-bias-n1079581
- 2. N. Campisi, From Inherent Racial Bias to Incorrect Data—The Problems with Current Credit Scoring Models (Los Angeles: Forbes Advisor, 2021).
- 3. The World Bank, Financial Consumer Protection and New forms of data processing beyond credit reporting (2018) https://elibrary.worldbank.org/doi/abs/10.1596/31009
- 4. Bureau of Consumer Financial Protection, Fair Lending Report of the Bureau of Consumer Financial Protection (2020), https://files.consumerfinance.gov/f/documents/cfpb_2019-fair-lending_report.pdf
- 5. Matt J. Kusner, Joshua R. Loftus, Chris Russell, and Ricardo Silva, “Counterfactual fairness,” arXiv 1703(06856) (2017), 1–18.
- 6. Sam Corbett-Davies, Emma Pierson, Avi Feller, and Sharad Goel, “A computer program used for bail and sentencing decisions was labeled biased against blacks. It's actually not that clear,” Washington Post (2016), https://www.washingtonpost.com/news/monkey-cage/wp/2016/10/17/can-an-algorithm-be-racist-our-analysis-is-more-cautious-than-propublicas/
- 7. Amos Tversky and Daniel Kahneman, “Judgment under uncertainty: Heuristics and biases: Biases in judgments reveal some heuristics of thinking under uncertainty, Science 185(4157) (1974): 1124–1131.
- 8. Marcus Lu, “50 cognitive biases in the modern world,” Visual Capitalist (February 1, 2020), https://www.visualcapitalist.com/50-cognitive-biases-in-the-modern-world/
- 9. Kate Smith, Consumer Vulnerability Strategy (London: Ofgem, 2013), https://www.ofgem.gov.uk/sites/default/files/docs/2013/07/consumer-vulnerability-strategy_0.pdf
- 10. Lu Wang and Claire Cardie, A Piece of My Mind: A Sentiment Analysis Approach (Ithaca, NY: arXiv.org, 2016).
- 11. Man Lan, Zhihua Zhang, Yue Lu, and Ju Wu, Three Convolutional Neural Network-based Models for Learning Sentiment Word Vectors towards Sentiment Analysis (Vancouver, BC:, International Joint Conference on Neural Networks (IJCNN), 2016).