
8
Data Management in Fog Computing
Tina Samizadeh Nikoui Amir Masoud Rahmani and Hooman Tabarsaied
8.1 Introduction
Fog computing plays an important role in a huge and real‐time data management system for Internet of Things (IoT). IoT is a popular topic; however, as a new one, it has its own challenges in handling the huge amount of data and providing on‐time response are some of them. The high growth rate of data generation in the IoT ecosystem is a considerable issue. It was stated that in 2012, 2500 petabytes of data were created per day [1]. In [2] it was mentioned that 25,000 records were generated per second in a health application with 30 million users. Pramanik et al. [3] outlined that by a fast growing rate, in the near future health‐related data will be in scale of zettabytes. In smart cities, the amount of data is even more, while Qin et al. [1] noted that 1 million/second records may be produced in smart cities. One exabyte of data is generated per year by US smart grid and approximately 2.4 petabytes of data are generated per month by US Library of Congress [4].
The processing time in the cloud and delay of transferring cause the latency that affects performance, and that latency is unacceptable in IoT applications like e‐Health, because late feedback about a suspicious or emergency situation may endanger someone's life.
The sensors and end devices periodically generate row data that include useless, noisy, or repetitive records, but transferring huge amount of data leads to increased errors, packet loss, and high probability of data congestion. In addition, processing and storing the repetitive or noisy data waste the resource with no gain. So interactional applications with large scale of data generation must decrease end‐to‐end delay and achieve real‐time data processing and analytics. Therefore, there is a need to do some local processing. Because of resource constraints and lack of aggregated data in each of IoT devices, however, they are not capable of processing and storing generated data.
Bringing the storage, processing, and network close to the end‐devices in fog computing paradigm is considered a proper solution. There are many definitions for fog computing. Qin defined it as “a highly virtualized platform that provides compute, storage, and networking services between end devices and traditional cloud computer data‐centers, typically, but not exclusively located at the edge of network” [1]. In this way, only on‐site processing and storage would be possible. However, fog computing has other benefits, such as better privacy by providing encryption and decryption, data integration [5], dependability, and load balancing.
A schematic structure of the contents in this chapter is shown in Figure 8.1. This chapter focused on data management in fog computing and proposed a conceptual architecture. In section 8.2, we review fog data management and highlight the management issues; additionally, a number of studies that are done on fog data management are presented. The main concepts of fog data management and the proposed architecture are presented in section 8.3. Future research and directions are presented in section 8.4. We summarize the main contents that are discussed in this chapter in section 8.5.

Figure 8.1 Structure of data management in fog computing.
8.2 Background
Fog plays a role as a mediator between devices and cloud; it is responsible for temporary data storage, some preliminary processing, and analytics. By this way after data generation by IoT devices, fog does some preliminary process and may store data for a while; these data are consumed by the cloud applications, proper feedback is generated by fog or cloud, and they are returned to a device. A three‐layer fog diagram with a data view is depicted in Figure 8.2.

Figure 8.2 Basic data management diagram in fog computing.
This chapter addresses surveys and paper on fog computing architecture. Typical fog computing architecture has three basic layers: device layer (or physical layer), fog layer (or edge network layer), and cloud layer [6]. A reference architectural model for fog computing is addressed in [7]. In [8] with the aim of data acquisition and management in fog computing paradigms, a three‐layer architecture was provided. It was composed of IoT sensor nodes, gateways, and IoT middleware. Data management, processing, virtualization, and service provisioning are done in the fog layer. In [9] a fog‐based schema was proposed for data analytics. The authors proposed a fog‐based architecture with a vertical and three horizontal layers, for crowdsensing applications. In [10] a programming framework was provided to define the processing model on streams of data. Another fog computing multitier framework for data analysis was proposed in [11].
A data‐centered platform for fog computing was proposed in [12]. Fog servers, fog edge nodes, and foglets are introduced as fog elements. Fog servers are responsible for interaction between the fog and cloud. The other entity focuses on data processing, storage, and communication. Foglet is a software agent that plays a middleware role and interacts between fog servers and other fog edge nodes. It is also used for monitoring, controlling, and maintaining.
Fog data management is about handling the data and its related concepts such as data aggregation approaches, data filtering techniques, data placement, providing data privacy, etc. Based on the three‐layer fog architecture, which is shown in Figure 8.2, sensory and collected data as a part of the system are sent to the upper layer and should be managed properly. As before mentioned, end‐to‐end latency and network traffic are two of main motivations to use fog computing. Local data management yields benefits such as better efficiency, more privacy, and so on. The main advantages of data management in fog computing are described as following:
- Increasing efficiency. Local processing on data and elimination of corrupted, repetitive, or unneeded data in fog layer reduces the network load and increase the network efficiency. Because the transferred data to the cloud must be processed, stored, and analyzed in the cloud, by decreasing the amount of data, cloud processing and storage needs would also decrease.
- Increasing the level of privacy. Ensuring data privacy is one of the IoT and cloud computing challenges. In IoT systems, sensors may generate and transfer sensitive and confidential data, but transferring them without any manipulation and encryption bears the risk of disclosure. In addition, resource constraint devices cannot handle complicated mathematical operations. The privacy‐preserving mechanisms such as encrypting algorithms in end‐devices may be impossible. Therefore, privacy, data manipulations and encryption algorithms can be done in a fog layer. Nevertheless, protection of fog devices is another issue that will be investigated further.
- Increasing data quality. Quality of data would be increased though the elimination of low‐quality data such as repetitive, corrupted, or noisy data and the integration of received data in a fog layer.
- Decreasing the end‐to‐end latency. Because of the nature of networks, existence of delay is obvious and inevitable, so response time must account for issues such as network delay and processing time when gathering feedback from cloud in IoT scenarios. Putting data pre‐processing close to the devices in fog layer will minimize the end‐to‐end delay.
- Increasing dependability. System dependability is about the ability of a system to provide the service as is expected. Refer to the definition of dependability which is provided in ISO/IEC/IEEE 24765 [13], three main aspects of dependability are reliability, availability, and maintainability. Fog devices and the local network can cover the possible failure of cloud networks and provide local data processing, therefore, the availability and reliability of a system would be increased.
- Decreasing cost. Local data processing and data compressing in a fog layer reduce the cost of network usage, cloud processing, and storage. However, the cost of fog devices should be considered, and there must be a trade‐off.
8.3 Fog Data Management
Data life cycle and fog data characteristics as the essential concepts of fog data management are elaborated in this section, as well as the other important issues in fog computing such as data cleaning, data fusion, data analysis, privacy concerns, and fog data storage. In addition, a case study of employing fog computing in e‐health application is described. Finally, the proposed architecture is presented.
8.3.1 Fog Data Life Cycle
The fog data life cycle consists of several steps that start from data acquisition in the device layer where data is generated, continue with processing and storing in upper layers and sending feedback to the device layer, and finally end with execution of commands in the device layer. As is shown in Figure 8.3, we consider five main steps: data acquisition, lightweight processing, processing and analysis, study feedback, and command execution. In the following, the main steps are elaborated.

Figure 8.3 Data life cycle in fog computing.
8.3.1.1 Data Acquisition
Data from different types of end devices should be acquired. It must be sent to upper layers. To this end, a sink node or local gateway node may exist to gather data, or sensors can send data directly to the fog.
8.3.1.2 Lightweight Processing
This step provides lightweight data manipulation and local data processing on the collected data. Lightweight processing may include data aggregation, data filtering, and elimination of unnecessary or repetitive data, data cleaning, compression/decompression, or some lightweight data analysis and pattern extraction. As data may be stored for a while in fog devices, the last period's data would be accessible locally, so more feasibility for data pre‐processing will be provided. The aggregated data will be transferred to the cloud via the network. In addition, the feedback as response data should be transferred to the device. Also, as the feedback is received from cloud layer and sent to the device layer, there may be a need for data decompression, data decryption, doing some format change on the received data, etc. These types of change must be supported by the fog layer.
8.3.1.3 Processing and Analysis
Received data may be stored permanently in the cloud layer, and it is processed based on predefined requirements. In addition, the application users may access data to get reports or data analysis. Different types of analysis on stored data may be applied to obtain valuable information and knowledge, and these types of processing and analysis are almost in the scale of big data. They need big data platforms and technologies such as HDFS for storage and map‐reduce for processing [3]. More information about big data concepts and analytics is provided in [14].
8.3.1.4 Sending Feedback
Based on data processing and analyzing, feedbacks such as proper commands or decisions are generated and sent to the fog layer.
8.3.1.5 Command Execution
Actuators must run the proper action based on the received data. In this way, proper feedback and responses are applied to the environment.
8.3.2 Data Characteristics
Reviewing data characteristics is necessary to define and refine data quality and integration standards and to handle the related challenges properly in the data management process. Data quality refers to how much data characteristics are suitable and can comply with consumer requirements.
Some of the main IoT data characteristics are mentioned in [15], which are as follow: uncertainties, erroneous, noisy data, voluminous and distributed, smooth variation, continuous, correlation, periodicity, and Markovian behavior. They reviewed accuracy, confidence, completeness, data volume, and timeliness as data quality dimensions. Three other additional data quality dimensions are ease of access, access security, and interpretability.
Also in [1] IoT data characteristics were categorized into three categories: data generation, data quality, and data interoperability. The IoT data quality characteristics include uncertainty, redundancy, ambiguity, and inconsistency. In the traditional way, after data are captured from different devices, they are stored for further steps. After the data are gathered in storage, batch processing is applied. By increasing in data generation speed and data volumes, new data analytics requirements are raised. One of them is stream processing, which is applied on a continuous and ongoing stream of data. Management of main IoT data characteristics and the related issues can be done in the fog data management process to fulfill the requirements. In the following, these characteristics are reviewed:
- Heterogeneity. Distributed heterogeneous end devices generate data in different formats. Generated data may be diversely varying in terms of structure or format [16, 17].
- Inaccuracy. Inaccuracy or uncertainties of the sensed data refer to the sensing precision, accuracy, or misreading of data [1, 15, 17, 18].
- Weak semantics. As mentioned before, the collected raw data that may be heterogeneous in terms of data formats, data structure, data source, etc. must be processed and managed. Using the concepts of semantic web and injecting some information and extra data to the raw data make the data readable and understandable for machines. Nevertheless, most of the collected data from the environment has weak semantics [1, 16, 17].
- Velocity. Data generation rates and sampling frequencies are varying in different types of end devices [1].
- Redundancy. Repetitive data that are sent by one or more end devices lead to redundancy in the collected data [1].
- Scalability. Large numbers of end devices and high data sampling rate that may exist in different scenarios may lead to generation of a huge amount of data [1].
- Inconsistency. Low precision or misreading in the sensed data may cause inconsistency in the gathered data [1].
8.3.3 Data Pre‐Processing and Analytics
In this section, three of the main data pre‐processing and analytics concepts that play important roles in fog data management are reviewed. They are data cleaning, data fusion, and edge mining.
8.3.3.1 Data Cleaning
Because of the mentioned characteristics, sensory data are not fully reliable, which is unpleasant for further processing and decision‐making. Jeffery et al. stated, “Dirty data” refer to missed readings and unreliable readings [19]. Cleaning mechanisms can be applied on the collected data in fog layers to reduce the effect of dirty and unreliable data, and to increase the quality of them. Data cleaning approaches can be divided in two categories: declarative data cleaning and model‐based data cleaning [18]. In the following, each of them is reviewed briefly:
- Declarative data cleaning. High‐level declarative queries such as CQL (continuous query language) are used to define the sensor values constraints. In this way, the user can express the queries and control the system easily via the provided interface. Extensible sensor stream processing (ESP) [18], is an example of this type. It is a declarative‐based and pipelined framework for sensor data cleaning for use in pervasive applications.
- Model‐based data cleaning. Anomalies are detected by comparison of raw values with the inferred values that are resulted as the most probable values based on selected models. The model‐based approaches also have subcategories such as regression models. These include polynomial regression and Chebyshev regression [18, 20], probabilistic models such as Kalman filter [18], and outliner detection models [21].
8.3.3.2 Data Fusion
Data fusion refers to the elimination of redundant and ambiguous data and integration of data, and can be done in the fog layer as one of the data management tasks to increase the accuracy and efficiency. In [22], data fusion was defined as “multilevel, multifaceted process handling the automatic detection, association, correlation, estimation, and combination of data and information from several sources.” Data fusion models can be categorized into three particular categories: data‐based model, activity‐based model, and role‐based model [23].
Khaleghi et al. [24] categorizes data fusion frameworks into four classes based on data‐related aspects: (i) imperfect data fusion framework; (ii) correlated data fusion framework; (iii) inconsistent data fusion framework; and (iv) disparate data fusion framework. The first category is related to data imperfection, which is one the main data challenges and may be caused by impreciseness, incompleteness, vagueness, or uncertainty [25]. The second category is related to dependency of data. The last two categories are about the conflict and diversity on data. There are some famous data fusion techniques and models, such as Intelligent Cycle (IC) [23] and Joint Directors of Laboratories (JDL) [23, 24].
8.3.3.3 Edge Mining
Fog computing can be effective for local analytics and stream processing to reduce the volume of data. Edge mining refers to utilize mining approaches on row data that are produced by devices in the edge of the network (fog layer). In this way, the size of the transferred data will be reduced and better energy savings can be achieved. Gaura et al. [26] stated that edge mining can be defined as “processing of sensory data near or at the point at which it is sensed, in order to convert it from a raw signal to contextually relevant information.” General Spanish Inquisition Protocol (G‐SIP) is one of the edge mining algorithms; it has three instantiations, which are Linear Spanish Inquisition Protocol (L‐SIP), ClassAct, and Bare Necessities (BN). L‐SIP is a lightweight algorithm for local data compression and aims to reduce data size through the state estimation and improve storage and responsiveness. In this model, end devices and fog devices use a predefined and shared model for state calculation and prediction. In case of unexpected data, data would be sent to the fog devices.
Based on [26], L‐SIP, ClassAct, and BN reduce the packet transmission by 95%, 99.6%, and 99.98% respectively. Collaborative edge mining is another extension of edge mining that was proposed in [27] to reduce the transferred data size.
8.3.4 Data Privacy
Privacy preserving and protection of data against unauthorized access are considered as one of the fog computing functionalities to keeps malicious and unauthorized end devices out of the system. However, due to the mobility of devices in some kinds of applications such as smart‐transportation, the authentication phase must consider the mobility and dynamic nature of the network.
Position is a sensitive data point that can represent the owner's location, and it should be protected, as location privacy is considered as one the data protection issues in the fog data privacy. It was addressed in [28] in secure positioning protocol. The authors defined correctness, positioning security, and location privacy as three properties that the proposed protocol must satisfy to be secure.
Providing the privacy of data aggregation was addressed in [5], which proposed a privacy‐preserving data aggregation schema for fog enhanced IoT. In the proposed approach, Chinese remainder theorem, one‐way hash, and homomorphic Paillier were used for fault‐tolerant data aggregation from hybrid IoT devices, authentication, and detection of false data injection in the fog layer.
8.3.5 Data Storage and Data Placement
Data storage and data placement are the other issues that must be handled in fog data management. Based on the predefined policy, data may be discarded after pre‐processing or may be stored for temporary in the fog devices for further processing or aggregation purpose. It should be noted that in addition to storage and memory constraints, for the sake of decreasing the end‐to‐end latency and providing real‐time response time, storage should have low‐latency, cache, and cache management techniques.
Also, making decisions about the duration and volume of stored data is very dependent to application type and infrastructure capabilities. Another issue concerns efficient placing of gathered data in fog storages based on node characteristics, geographical zone, and type of application, because data placement strategy affects service latencies. Naas et al. proposed using iFogStore to reduce the latency, taking into account fog device characteristics as well as heterogeneity and location [29]. Sharing of data by different data consumers, dynamic location of data consumers, and the capacity constraints of fog devices are considered in iFogStore. In addition, to reduce the overall latency, it considers the storing and retrieval times.
To provide the real‐time decision‐making, in [30] based on the basic three‐layer architecture, a storage management architecture in edge (fog) computing was proposed. In the edge (fog) layer, the architecture has six components to provide storage, and data management mechanism in a storage constrained system: monitoring, data preparation, adaptive algorithm, specification list, storage, and mediator component. The other two layers are cloud layer and gathering layer (device layer). The first is responsible for storing the historical data and the latter generates the row data.
8.3.6 e‐Health Case Study
For clarifying the effect of fog data management, the role of fog data management in e‐Health as one of IoT applications is investigated. e‐Health applications aim to help take care of the elderly and patients. There have been a lot of studies on e‐Health in the last decade, such as [30–32]. In [33], benefits of healthcare systems are described. Some of the main benefits are ease of use, reduction of cost, more considerable availability, and services. Healthcare applications such as ECG devices may generate several GBs of data in a day. Transferring and processing it means that it conserves network bandwidth, storage, and processing cycles [33]. Healthcare solutions can be used for monitoring, controlling, or prediction of emergency conditions based on the captured data.
In emergency conditions, fog computing performs faster than such processes being performed on the cloud layer. In comparison with nursing care, e‐health application can monitor and control patients 24/7 and at lower cost. A number of papers have been published on electronic healthcare systems, such as [35] and [36]. This kind of application remotely monitors health status by controlling some parameters and data such as blood glucose, blood pressure, heartbeat, electroencephalography, electrocardiography, motion, and location data. These sensors transmit collected data to the local gateway (fog device) in short intervals (e.g. every one minute). These data are temporarily stored in the local storage. In addition, these data are pre‐processed in terms of emergency conditions, such as blood pressure higher than 140/90 mmHg, or blood glucose above than 400 mg/dl. Therefore, in the event of an emergency, the necessary actions will be taken immediately through fog devices. For example, as the sequence diagram shows in Figure 8.4, if the measured blood glucose is above 400 mg/dl, injection must be done through the inclusion bracelet, or in the case of high blood pressure above 140/90 mmHg, notifications are sent to emergency services.
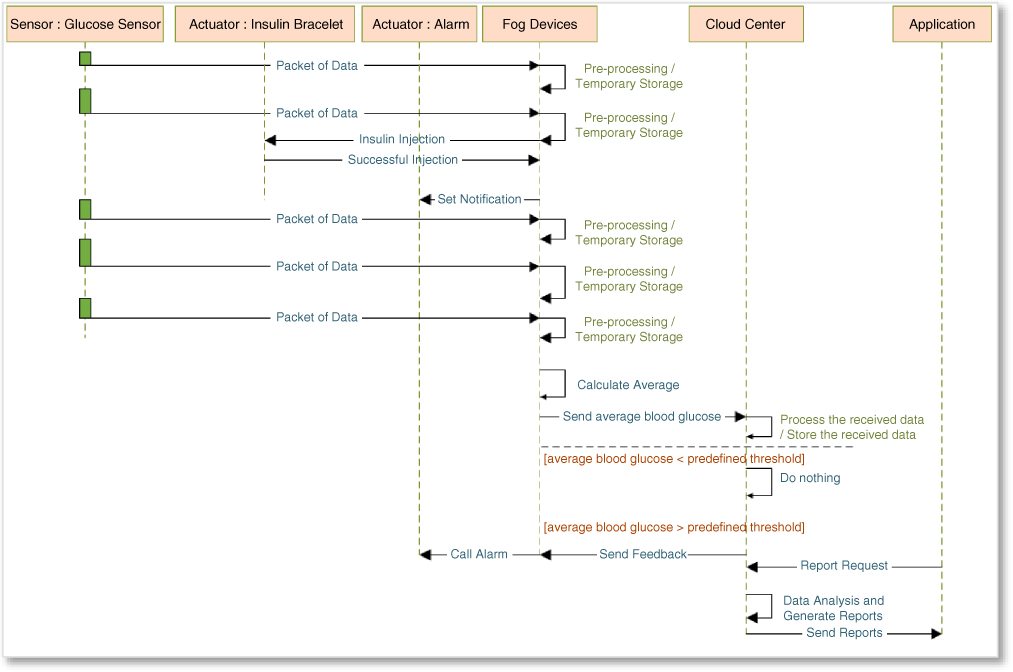
Figure 8.4 A simple sequence diagram of an e‐health application.
Some kinds of data compression or encryption can be done in the fog layer before sending data to the cloud layer in order to increase efficacy and privacy. After preliminary data aggregation, manipulation and processing were done in fog devices. Then data were sent to the cloud layer in the predefined intervals or events. Data can be stored and processed in the cloud layer and the application users can access these data and receive the health reports.
8.3.7 Proposed Architecture
This section provides a conceptual architecture based on the three‐layer model to handle data management issues. As shown in Figure 8.5, our proposed architecture consists of a device layer, fog layer, and cloud layer. Located sensors and actuators in the device layer interact with the physical environment – the sensors collect data and the actuators run the commands that are received from the fog.

Figure 8.5 Proposed architecture.
The device layer sends the collected data to the fog layer and receives commands from it. The fog layer is divided into two sub‐layers. The lower fog sub‐layer, called the fog‐device sub‐layer, is responsible for controlling physical device routines, protocol interpretation, de‐noising the received signals, authentication, and data storage. In addition, lightweight analysis and local decision‐making that are based on the business of fog application are located in this layer. The other sub‐layer, the fog‐cloud sub‐layer, interacts with the cloud layer. It is in charge of compression/decompression and encryption/decryption on the packets. The cloud layer stores data permanently; it processes the received data and makes global decisions. Also, in terms of incoming query from applications, it analyses the stored data to send responses. Each of the modules is described as follows.
8.3.7.1 Device Layer
Modules of the device layer are registration module, data collection module, and command execution module.
Registration.
Physical devices can join to the network or leave it dynamically via this module. Registration is necessary for sending and receiving messages. Registration requests as an initial message should be sent by the device to the fog layer. Through the registration process, devices get a unique ID and key that should be attached in the messages for authentication process.
Data Collection/Command Execution.
Registered sensors collect data to transfer to the fog layer. Actuators are responsible for running the received commands from the fog layer by this module.
8.3.7.2 Fog Layer
Modules of the fog layer are resource management module, temporary storage module, authentication module, protocol interpretation and conversion module, pre‐processing module, encryption/decryption, and compression/ decompression.
Resource Management.
The fog layer receives the join requests that are sent by the device layer, the resource management module queries the list of devices and adds the device specifications to the list in case of absence or deactivation of device, and it will be added. Also, based on fog applications policy, registered devices that are not sending message for a predefined period may be deactivated.
Temporary Storage.
Temporary storage can be a module to store some of the incoming data or intermediate computation results, for example, for further processing in a database. In addition, it also stores specifications of registered devices and their IDs and keys for authentication process.
Authentication.
The authentication module searches the list of registered devices on temporary storage to find related key and ID to authenticate the incoming messages.
Interpretation and Conversion.
The communication of devices and fog may be received data, heterogeneity in terms of communication types between devices and the fog layer is possible, so data may be sent via different technologies such as Wi‐Fi, Bluetooth, ZigBee, RFID, or etc. Therefore, Interpretation and conversion provides different protocols and conversion methods.
Pre‐Processing.
Storing the received data in the temporary storage, preparing and aggregating them are the responsibilities for the pre‐processing module. Also some kinds of data processing may be needed on the received data, such as data cleaning, data fusion, edge mining, and quality improvement of received signals by data filtering or de‐noising them, decision making in case of emergency situations by checking and comparing the received or collected data against the predefined threshold and conditions. Lightweight analyzing, feature extraction, pattern recognition, and decision making need more specific algorithms to be applied on data. However, selected approaches in level of the fog, must be simple and comply with the existed constraints.
Encryption/Decryption.
To improve data privacy and protect sensitive data in the message, encryption and decryption algorithms are provided in this module.
Compression/Decompression.
Compression techniques can be applied on the packet size of data to reduce overhead of networks by this module.
8.3.7.3 Cloud Layer
Modules of the cloud layer are permanent storage, global decision making, encryption/decryption, compression/decompression and data analysis modules. This section describes each of them.
Permanent Storage.
This module receives data from different fog zones and stores the data in permanent storage. Depending on the fog application type, the size of permanent storage might vary from gigabytes to even petabytes. Thus, big data technologies are applied in this layer to store data.
Global Decision‐Making.
Received data are processed to send proper feedback to the lower layers and to store the needed and useful data in permanent storage. In case of receiving/sending compressed or encrypted messages from fog layer, decompression or decryption units are used, respectively. Data in motion and data stream processing, which were described previously, are the other issues raised in IoT and fog computing for some kinds of applications.
Encryption/Decryption, Compression/Decompression.
As mentioned before, for privacy and efficiency concerns and to support encryption and compression, these modules must be located in both the cloud and fog layers. Encryption and compression approaches must be agreed by both of them.
Data Analysis.
Gathering of data will be very valuable when it leads to knowledge, so data analysis, pattern recognition, and knowledge discovery from the heterogeneous data that are collected from different devices are considered an important stage in the data life cycle. This module is responsible for data analysis based on the application user requests for providing reports and getting global analysis on the gathered data. Depending on the size of stored data in data storage, data analysis approaches and technologies may vary. In the case of large‐scale data storage, big data analytics technologies may be applied.
Based on the proposed architecture shown in Figure 8.5, interaction of components are presented in Figure 8.6.

Figure 8.6 Interaction of the main process in proposed architecture.
8.4 Future Research and Direction
Despite the benefits of fog computing, new challenges arise that should be handled in future research to provide better and more efficient services to the fog users. This section addresses some key challenges that are related to data management issues.
8.4.1 Security
As was mentioned before, fog computing can increase the privacy via encryption and local processing of sensitive data. However, methods for maintaining the encryption keys and selection of proper encryption algorithms must be considered. As fog devices might not be properly secured, controlling and protecting distributed fog devices against different attacks and data leakage are both considerable security challenges. Other issues regard the structure and dynamic nature of fog computing, which different devices can join to a region or leave it, protection of fog devices against inaccurate and malicious data, and implementation of proper authentication methods.
8.4.2 Defining the Level of Data Computation and Storage
In comparison with end devices, fog devices have more computing and storage resources, but these are still not enough for complicated processing or permanent storage. Therefore, lightweight algorithms for data pre‐processing based on a short time history must be provided. Also, determining the level of processing and storage in the fog devices based on existing constraints must be further studied.
8.5 Conclusions
To decrease the response time of real‐time systems for IoT applications and handle the huge amount of data in IoT systems, the fog computing paradigm can be considered a good solution. In this chapter, we reviewed data management in fog computing, which plays an important and effective role in improving the quality of services for real‐time IoT applications. We discussed the concept of fog data management, its main benefits, preliminary processes such as clearing mechanism, mining approaches and fusions, privacy issues, and data storage. To provide a better understanding of fog data management, an enhanced e‐health application with fog data management was elaborated as a case study. Finally, based on the three‐layered model, a conceptual architecture was provided for fog data management.
References
- 1 Y. Qin. When things matter: A survey on data‐centric Internet of Things. Journal of Network and Computer Applications , 64: 137–153, April 2016.
- 2 A. Dastjerdi, and R. Buyya. Fog computing: Helping the Internet of Things realize its potential. Computer, 49(8): 112–116, August 2016.
- 3 M. I. Pramanik, R. Lau, H. Demirkan, and M. A. KalamAzad. Smart health: Big data enabled health paradigm within smart cities. Expert Systems with Applications 87: 370–383, November 2017.
- 4 M. Chiang and T. Zhang. Fog and IoT: An overview of research opportunities. IEEE Internet of Things Journal , 3(6): 854–864, December 2016.
- 5 R. Lu, K. Heung, A. H. Lashkari, and A. A. Ghorbani. A lightweight privacy‐preserving data aggregation scheme for fog computing‐enhanced IoT. IEEE Access 5: 3302–3312, March 2017.
- 6 M. Taneja, and A. Davy. Resource aware placement of data analytics platform in fog computing. Cloud Futures: From Distributed to Complete Computing, Madrid, Spain , October 18–20, 2016.
- 7 A. V. Dastjerdi, H. Gupta, R. N. Calheiros, S. K. Ghosh, R. Buyya. Fog computing: Principles, architectures, and applications. Internet of Things: Principles and Paradigms , R. Buyya, and A. V. Dastjerdi (Eds), ISBN: 978‐0‐12‐805395‐9, Todd Green, Cambridge, USA, 2016.
- 8 P. Charalampidis, E. Tragos, and A. Fragkiadakis. A fog‐enabled IoT platform for efficient management and data collection. 2017 IEEE 22nd International Workshop on Computer Aided Modeling and Design of Communication Links and Networks (CAMAD) , Lund, Sweden, June 19–21, 2017.
- 9 A. Hamid, A. Diyanat, and A. Pourkhalili. MIST: Fog‐based data analytics scheme with cost‐efficient resource provisioning for IoT Crowdsensing Applications. Journal of Network and Computer Applications 82: 152–165, March 2017.
- 10 E. G. Renart, J. Diaz‐Montes, and M. Parashar. Data‐driven stream processing at the edge. 2017 IEEE 1st International Conference on Fog and Edge Computing (ICFEC), Madrid, Spain, May 14–15, 2017.
- 11 J.He, J. Wei, K. Chen, Z. Tang, Y. Zhou, and Y. Zhang. Multi‐tier fog computing with large‐scale IoT data analytics for smart cities. IEEE Internet of Things Journal. Under publication, 2017.
- 12 J. Li, J. Jin, D. Yuan, M. Palaniswami, and K. Moessner. EHOPES: Data‐centered fog platform for smart living. 2015 International Telecommunication Networks and Applications Conference (ITNAC), Sydney, Australia, November 18–20, 2015.
- 13 International Organization for Standardization. Systems and software engineering – Vocabulary. ISO/IEC/IEEE 24765:2010(E), December 2010.
- 14 R. Buyya, R. Calheiros, and A.V. Dastjerdi. Big Data: Principles and Paradigms , Todd Green, USA, 2016.
- 15 A. Karkouch, H. Mousannif, H.Al Moatassime, and T. Noel. Data quality in Internet of Things: A state‐of‐the‐art survey. Journal of Network and Computer Applications , 73: 57–81, September 2016.
- 16 S. K. Sharma and X. Wang. Live data analytics with collaborative edge and cloud processing in wireless IoT networks. IEEE Access , 5: 4621–4635, March 2017.
- 17 M. Ma, P. Wang, and C. Chu. Data management for Internet of Things: Challenges, approaches and opportunities. 2013 IEEE and Internet of Things (iThings/CPSCom), IEEE International Conference on and IEEE Cyber, Physical and Social Computing Green Computing and Communications (GreenCom). Beijing, China, August 20–23, 2013.
- 18 S. Sathe, T.G. Papaioannou, H. Jeung, and K. Aberer. A survey of model‐based sensor data acquisition and management. Managing and Mining Sensor Data , C. C. Aggarwal (Eds.), Springer, Boston, MA, 2013.
- 19 S. R. Jeffery, G. Alonso, M. J. Franklin, W. Hong, and J. Widom. Declarative support for sensor data cleaning. Pervasive Computing. K.P. Fishkin, B. Schiele, P. Nixon, et al. (Eds.), 3968: 83–100. Springer, Berlin, Heidelberg, 2006.
- 20 N. Hung, H. Jeung, and K. Aberer. An evaluation of model‐based approaches to sensor data compression. IEEE Transactions on Knowledge and Data Engineering , 25(11) (November): 2434–2447, 2012.
- 21 O. Ghorbel, A. Ayadi, K. Loukil, M.S. Bensaleh, and M. Abid. Classification data using outlier detection method in Wireless sensor networks. 2017 13th International Wireless Communications and Mobile Computing Conference (IWCMC), Valencia, Spain, June 26–30, 2017.
- 22 F. E. White. Data Fusion Lexicon. Joint Directors of Laboratories, Technical Panel for C3, Data Fusion Sub‐Panel, Naval Ocean Systems Center, San Diego, 1991.
- 23 M. M. Almasri and K. M. Elleithy. Data fusion models in WSNs: Comparison and analysis. 2014 Zone 1 Conference of the American Society for Engineering Education. Bridgeport, USA, April 3–5, 2014.
- 24 B. Khaleghi, A.Khamis, F. O. Karray, and S.N. Razavi. Multisensor data fusion: A review of the state‐of‐the‐art. Information Fusion , 14(1): 28–44, January 2013.
- 25 M.C. Florea, A.L. Jousselme, and E. Bosse. Fusion of Imperfect Information in the Unified Framework of Random Sets Theory. Application to Target Identification. Defence R&D Canada. Valcartier, Tech. Rep. ADA475342, 2007.
- 26 E.I. Gaura, J. Brusey, M. Allen, et al. Edge mining the Internet of Things. IEEE Sensors Journal , 13(10): 3816–3825, October 2013.
- 27 K. Bhargava, and S. Ivanov. Collaborative edge mining for predicting heat stress in dairy cattle. 2016 Wireless Days (WD). Toulouse, France, March 23–25, 2016.
- 28 R. Yang, Q. Xu, M. H. Au, Z. Yu, H. Wang, and L. Zhou. Position based cryptography with location privacy: a step for fog computing. Future Generation Computer Systems , 78(2): 799–806, January 2018.
- 29 M. I. Naas, P. R. Parvedy, J. Boukhobza, J. Boukhobza, and L. Lemarchand. iFogStor: an IoT data placement strategy forF infrastructure. 2017 IEEE 1st International Conference on Fog and Edge Computing (ICFEC). Madrid, Spain, May 14–15, 2017.
- 30 A.A. Rezaee, M. Yaghmaee, A. Rahmani, A.H. Mohajerzadeh. HOCA: Healthcare Aware Optimized Congestion Avoidance and control protocol for wireless sensor networks. Journal of Network and Computer Applications , 37: 216–228, January 2014.
- 31 A. A. Rezaee, M.Yaghmaee, A. Rahmani, and A. Mohajerzadeh. Optimized Congestion Management Protocol for Healthcare Wireless Sensor Networks. Wireless Personal Communications , 75(1): 11–34, March 2014.
- 32 S. M. Riazul Islam, D. Kwak, M.D.H. Kabir, M. Hossain, K.‐S. Kwak. The Internet of Things for Health Care: A Comprehensive Survey. IEEE Access 3: 678–708, June 2015.
- 33 I. Lujic, V.De Maio, I. Brandic. Efficient edge storage management based on near real‐time forecasts. 2017 IEEE 1st International Conference on Fog and Edge Computing (ICFEC). Madrid, Spain, May 14–15, 2017.
- 34 B. Farahani, F. Firouzi, V. Chang, M. Badaroglu, N. Constant, and K. Mankodiya. Towards fog‐driven IoT eHealth: Promises and challenges of IoT in medicine and healthcare. Future Generation Computer Systems , 78(2): 659–676, January 2018.
- 35 F. Alexander Kraemer, A. Eivind Braten, N. Tamkittikhun, and D. Palma. Fog computing in healthcare: A review and discussion. IEEE Access , 5: 9206–9222, May 2017.
- 36 B. Negash, T.N. Gia, A. Anzanpour, I. Azimi, M. Jiang, T. Westerlund, A.M. Rahmani, P. Liljeberg, and H. Tenhunen. Leveraging Fog Computing for Healthcare IoT. Fog Computing in the Internet of Things. A. Rahmani, P. Liljeberg, J.S. Preden, et al. (Eds.). Springer, Cham, 2018.