
7
A Lightweight Container Middleware for Edge Cloud Architectures
David von Leon Lorenzo Miori Julian Sanin Nabil El Ioini Sven Helmer and Claus Pahl
7.1 Introduction
In typical cloud applications, most of the data processing is done on the back end and the clients are relatively thin. Integrating Internet‐of‐Things (IoT) devices and sensors into such an environment in a straightforward manner causes several problems. If billions of new devices start shipping data into the cloud, this will have a major impact on the flow of network traffic. Also, certain applications require real‐time behavior (e.g. self‐driving cars) and cannot afford to wait for data, which may arrive late due to network delays. Finally, users may also not want to send sensitive or private data into the cloud, losing control over it (this is especially important for healthcare applications). Consequently, cloud computing is moving away from large, centralized structures toward multicloud environments. The integration of cloud and sensor‐based IoT environments results in edge cloud or fog computing [1, 2], in which a substantial part of the data processing takes place on the IoT devices themselves. Rather than moving data from the IoT to the cloud, the computation moves to the edge of the cloud [3].
However, when running these kinds of workloads on such an infrastructure, we are confronted with different issues: the deployed devices are constrained in terms of computational power, storage capability, reliable connectivity, power supply, and other resources. For a start, we need solutions that are lightweight enough to be run on resource‐constrained devices. Nevertheless, we still aim to develop visualized solutions providing scalability, flexibility, and multi‐tenancy. We address flexibility and multi‐tenancy via containerization. Containers form the basis of a middleware platform that suits the needs of platform‐as‐a‐service (PaaS) clouds [4, 5], where application packaging and orchestration are key issues [6–8]. We address scalability by proposing to cluster small devices to boost and share their computational power and other resources. Using Raspberry Pi (RPi) clusters as a proof‐of‐concept, we demonstrate how this can be achieved [9].
In edge cloud environments, additional requirements include cost‐efficiency, low power consumption, and robustness. In a sense, our solution should not just be lighweight in terms of the software platform but also in terms of the hardware platform. We show how the additional requirements can be met by implementing containers on clusters of single‐board devices like RPis [10–12]. The lightweight hardware and software architecture we envision allows us to build applications based on multicloud platforms on a range of nodes from data centers to small devices.
Edge cloud systems are also subject to security concerns. Data, software, and hardware might join or leave a system at any time, requiring all to be identified and their traces to be tracked. Traceability and auditability also apply for the orchestration aspects. By looking at blockchain technologies, we explore a conceptual architecture that manages security concerns for IoT fog and edge architecture (FEA) using blockchain mechanisms.
Our chapter is organized as follows. We first introduce architecture requirements and review technologies and architectures for edge clouds. We then discuss core principles of an edge cloud reference architecture that is based on containers as the packaging and distribution mechanism. We specifically present different options for storage, orchestration, and cluster management for distributed clusters in edge cloud environments. To this end, we report on experimental results with Raspberry Pi clusters to validate the proposed architectural solution. The settings included are: (i) an own‐build storage and cluster orchestration; (ii) an OpenStack storage solution; (iii) Docker container orchestration; and (iv) IoT/sensor integration. We also include practical concerns such as installation and management efforts, since lightweight edge clusters are meant to be run in remote areas.
7.2 Background/Related Work
We identify some principles and requirements for a reference architecture for edge cloud computing, illustrating these principles and requirements with a use case.
7.2.1 Edge Cloud Architectures
Supporting the management of data collections, including their pre‐processing and further distribution, via computational and storage resources in the case of edge computing with integrated IoT objects is different to traditional cloud computing architectures. It is facilitated by smaller devices spread across a distributed network and due to these smaller device sizes results in different resource restrictions, which in turn requires some form of lightweightness [13]. Still, virtualization is a suitable mechanism for edge cloud architectures [14, 15], as recent work on software‐defined networks (SDNs) shows. The compute and storage resources can be managed, i.e., packaged, deployed and orchestrated, by platform services. Figure 7.1 shows that we need to provide compute, storage, and network resources between end devices and traditional data centers, including data transfer support between virtualized resources.

Figure 7.1 Edge cloud architecture.
Other requirements that emerge are location awareness, low latency, and software mobility support to manage cloud end points with rich (virtualized) services. A specific requirement is continued configuration and update – this particularly applies to service management. What is needed is a development layer that allows for provision and manage applications on these edge architectures. We propose to adjust the abstraction level for edge cloud management at a typical PaaS layer.
We propose an edge cloud reference architecture based on containers as the packaging and distribution mechanism, addressing a number of concerns. This includes application construction and orchestration and resource scheduling as typical distributed systems services. Furthermore, we need an orchestration model for an (edge) cloud‐native architecture where applications are deployed on provided platform services. For this type of architecture, we need a combination of lightweight technologies – single‐board devices as lightweight hardware combined with containers as a lightweight software platform. Container technologies can take care of the application management. They are specifically useful for constrained resources in edge computing clusters.
7.2.2 A Use Case
Consider the following use case. Modern ski resorts operate extensive IoT‐cloud infrastructures. Sensors gather a variety of data in this setting – on weather (air temperature/humidity, sun intensity), on snow quality (snow humidity, temperature), and on people (location and numbers). With the combination of these data sources, two sample functions are the following:
- Snow management. Snow groomers (snow cats) are heavy‐duty vehicles that rely on sensor data (ranging from tilt sensors in the vehicle and GPS location all the way to snow properties) to provide an economic solution in terms of time needed for the preparation of slopes, while at the same time allowing a near‐optimal distribution of snow. This is a real‐time application where cloud‐based computation is not feasible (due to unavailability of suitable connectivity). As a consequence, local data processing for all data collection, analysis, and reaction is needed.
- People management. Through mobile phone apps, skiers can get recommendations regarding snow quality and possible overcrowding at lifts and on the slopes. A mobile phone app can use the cloud as an intermediary to receive data from. For performance, however, the application architecture would benefit from data pre‐processing at the sensor location to reduce the data traffic between local devices and cloud services.
Performance is a critical concern that can be addressed by providing local computation. This avoids high data volumes to be transferred into centralized clouds. Local processing of data, particularly for the snow management where data sources and actions resulting through the snow groomers happen in the same place, is beneficial, but needs to be facilitated through robust technologies that can operate in remote areas under difficult environmental conditions. Clusters of single‐board computers such as Raspberry Pis are a suitable, robust technology.
Another critical concern is flexibility. The application would benefit from flexible platform management with different platform and application services deployed at different times in different locations to facilitate short‐term and long‐term change [16]. For instance, a sensor responsible for people management during daytime could support snow management during the night. Containers are suitable but require good orchestration support. Two orchestration patterns emerge that illustrate this point. The first pattern is about fully localized processing in clusters (organized around individual slopes with their profile): full computation on board and locally between snow groomers is required, facilitated by the deployment of analysis, but also decision making and actuation features, all as containers. The second pattern is about data pre‐processing for people management: reducing data volume in transfer to the cloud is the aim. Analytics services packaged as containers that filter and aggregate data need to be deployed on selected edge nodes.
7.2.3 Related Work
Container technologies that provide lightweight virtualization are a viable option to hypervisors, as demonstrated in [17]. This lightweightness is a benefit for smaller devices due to their limitations as a result of the reduced size and capabilities.
Bellavista and Zanni [18] have investigated an infrastructure based on Raspberry Pis to host Docker container. Their work also confirms the suitability of single‐board devices. Work carried out at the University of Glasgow [19] also uses Raspberry Pis for edge cloud computing. The work there is driven by lessons learned from practical applications of RPis in real‐world settings. In addition to the results presented there, we have added here a comparative evaluation of different cluster‐based architectures based on architecture‐relevant observations regarding installation, performance, cost, power, and security.
If we want to consider a middleware platform for a cluster architecture of smaller devices, be that in constrained or mobile environments, the functional scope of a middleware layer needs to be suitably adapted [20]:
- Robustness is a requirement that needs to be facilitated through fault tolerance mechanisms that deal with failure of connections and nodes. Flexible orchestration and load balancing are such functions.
- Security is another requirement, here relevant in the form of identity management in unsecured environments. Other security concerns such as data provenance or smart contracts accompanying orchestration instructions are also relevant. De Coninck et al. [21] also approach this problem from a middleware perspective. Dupont et al. [22] look at container migration to enhance the flexibility, which is an important concern in IoT settings.
7.3 Clusters for Lightweight Edge Clouds
In the following, we explain how to build platforms that are lightweight, in terms of software and hardware.
7.3.1 Lightweight Software – Containerization
Containerization allows a lightweight virtualization through the construction of containers as application packages from individual images (generally retrieved from an image repository). This addresses performance and portability weaknesses of current cloud solutions. Given the overall importance of the cloud, a consolidating view on current activities is important. Many container solutions build on top of Linux LXC techniques, providing kernel mechanisms such as namespaces and cgroups to isolate operating system processes. Docker, which is basically an extension of LXC, is the most popular container platform at the moment [23].
Orchestration is about constructing and managing a possibly distributed assembly of container‐based software applications. Container orchestration is not only about the initial deployment, starting and stopping of containers, but also about the management of the multicontainers as a single entity, concerning availability, scaling, and networking of the containers, and moving them between servers. In this way, edge cloud‐based container construction is a form of orchestration within the distributed cloud environment. However, the management solution for containers provided by cluster management solutions needs to be combined with development and architecture support. A multi‐PaaS based on container clusters can serve as a solution for managing distributed software applications in the cloud, but this technology still faces challenges. These include a lack of suitable formal descriptions or user‐defined metadata for containers beyond image tagging with simple IDs. Description mechanisms need to be extended to clusters of containers and their orchestration as well [24]. The topology of distributed container architectures must be more explicitly specified and its deployment and execution orchestrated [25]. So far, there is no accepted solution for these orchestration challenges.
Docker has started to develop its own orchestration solution (Swarm) and Kubernetes is another relevant project, but a more comprehensive solution that would address the orchestration of complex application stacks could involve Docker orchestration based on the topology‐based service orchestration standard TOSCA [26]. The latter is done by the Cloudify PaaS, which supports TOSCA.
In Figure 7.2, we illustrate an orchestration plan for the use case from the previous section. A container host selects either the people management or the snow management as the required node configuration. For instance, the people management architecture could be upgraded to a more local processing mode that includes analysis and storage locally. The orchestration engine takes care of the deployment of the containers at the right time. Container clusters need network support. Usually, containers are visible on the network using the shared host's address. In Kubernetes, each group of containers (called pods) receives its own unique IP address that is reachable from any other pod in the cluster, whether co‐located on the same physical machine or not. This needs to be supported by network virtualization with specific routing features.
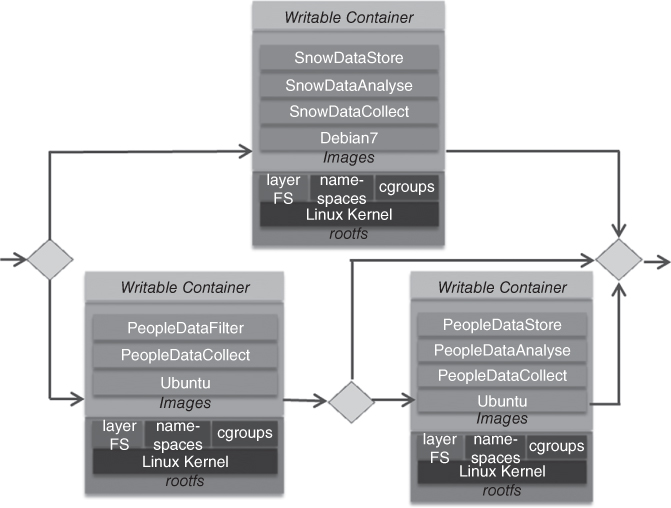
Figure 7.2 Simplified container orchestration plan for the ski resort case study.
Container cluster management also needs data storage support. Managing containers in Kubernetes clusters cause challenges due to the need of Kubernetes pods to co‐locate with their data: a container needs to be linked to a storage volume that follows it to any physical machine.
7.3.2 Lightweight Hardware – Raspberry Pi Clusters
We focus on Raspberry Pis as the hardware device infrastructure and illustrate orchestration for Raspberry Pi clusters in edge cloud environments. These small single‐board computers create both opportunities and challenges. Creating and managing clusters are typical PaaS functions, including setting up and configuring hardware and system software, monitoring and maintaining the system, up to hosting container‐based applications.
A Raspberry Pi (RPi) is relatively cheap (around $30, depending on the version) and has a low power consumption, which makes it possible to create an affordable and energy‐efficient cluster that is particularly suitable for environments for which high‐tech installations are not possible. Since a single RPi lacks computing power, in general we cannot run computationally intensive software. On the other hand, this limitation can be overcome by combining several RPis into a cluster. This allows platforms to be better configured and customized so that they are at the same time robust against failure through their cluster architecture.
7.4 Architecture Management – Storage and Orchestration
Raspberry Pi clusters are the hardware basis for our middleware platform. In order to explore different options for this, we look at different implementations types:
- An own‐build storage and cluster orchestration
- An OpenStack storage implementation
- A Docker container orchestration
Furthermore, we look at IoT/sensor integration. For each of the three core architectural patterns, we describe the concrete architecture and implementation work, which we will evaluate later. The aim is to address the general suitability of the proposed architectures in terms of performance, but also take specifically practical concerns such as physical maintenance, power, and cost into account. Consequently, the evaluation criteria are as follows: installation and management effort, cost, power consumption, and performance.
7.4.1 Own–Build Cluster Storage and Orchestration
7.4.1.1 Own–Build Cluster Storage and Orchestration Architecture
As demonstrated in (Abrahamsson, 2013), our Raspberry Pi cluster can be configured with up to 300 nodes (using RPi 1 with a lower spec compared to RPi 2 and 3 strengthens the case for lightweightness). The core of an RPi 1 is a single board with an integrated circuit with an ARM 700 MHz processor (CPU), a Broadcom VideoCore graphics processor (GPU) and 256 or 512 MB of RAM. Also provided is an SD card slot for storage and I/O units for USB, Ethernet, audio, video, and HDMI. Power support is enabled using a micro‐USB connector. Raspbian is a version of the widely used Linux distribution Debian, optimized for the ARMv6 architecture, that serves as the operating system. We use a Debian 7 image to support core middleware services such as storage and cluster management. In [27], we have investigated basic storage and cluster management for an RPi cluster management solution.
The topology of our cluster is a star network. In this configuration, one switch acts as the core and other switches link the core to the RPIs. A master node and an uplink to the Internet are connected to the core switch. In addition to deploying existing cluster management tools such as Swarm or Kubernetes, we also built our own dedicated tool, covering important features for a dynamic edge cloud environment, such as low‐level configuration, monitoring, and maintenance of the cluster as an architectural option. This approach gives flexibility for monitoring the joining and leaving of nodes to and from the cluster, with the master handling the (de)registration process.
7.4.1.2 Use Case and Experimentation
A key objective is the suitability of an RPi for running standard application in terms of performance and power. In previously conducted experiments, a sample file with a size of 64.9 KB was used. An RPi (model B) was compared to different other processor configurations: a 1.2 GHz Marvell Kirkwood, a 1 GHz MK802, a 1.6 GHz Intel Atom 330, and a 2.6 GHz dual core G620 Pentium. All tested systems had a wired 1 GB Ethernet connection (which the Raspberry Pi could not utilize fully, only including a 10/100 Mbit Ethernet card). As a benchmark, ApachBench2 was used. The test involved a total of 1000 requests, with 10 of them running concurrently. In Table 7.1, page/sec as performance measure and power consumptions (in Watts) are summarized.
Table 7.1 Speed and power consumption of the Raspberry Pi cluster. Adapted from [28].
| Device | Page/Sec | Power |
| RPi | 17 | 3W |
| Kirkwood | 25 | 13W |
| MK802 | 39 | 4W |
| Atom 330 | 174 | 35W |
| G620 | 805 | 45W |
Table 7.1 shows that RPis are suitable for most sensor integration and data processing requirements. They are suitable in an environment where robustness is required and that is subject to power supply problems.
7.4.2 OpenStack Storage
7.4.2.1 Storage Management Architecture
In Miori [29], we have investigated OpenStack Swift as a distributed storage device for our setting, porting OpenStack Swift onto RPis. By using a fully fledged platform such as OpenStack Swift, we can substantially extend our self‐built storage approach. The challenges are adopting an open‐source solution that is meant for significantly larger devices.
Swift is useful for distributing storage clusters. Using a network storage system can improve the cluster performance in a common filesystem. In our own implementation of Swift, we used a four‐bay network attached storage (NAS) from QNAP Systems, but can now demonstrate that a more resource‐demanding OpenStack Swift is a feasible option. The Swift cluster provides a solution for storing objects such as application data as well as system data. Data are replicated and distributed among different nodes: we considered different topologies and configurations. While we showed that this is technically feasible, the performance of OpenStack Swift performance is a key downside that would need further optimization to become a practically relevant solution.
7.4.2.2 Use Case and Experimentation
In order to evaluate the Swift‐based storage, we have run several benchmarks based on YCSB and ssbench.
- Single node installation. Here, a significant bottleneck around data uploads emerges. This means that a single server cannot handle all the traffic, resulting in either cache (memcached) or container server failures.
- Clustered file storage. Here, a real‐world case study has been carried out using the ownCloud cloud storage system. A middleware layer on a Raspberry cluster was configured and benchmarked. We can demonstrate the utility of this option by running ownCloud on top that facilitates a (virtualized) storage service across the cluster. Performance is not great, but is acceptable.
In the implementation, we used a FUSE (filesystem‐in‐userspace) module called cloudfuse. This connects to a Swift cluster and manages content as in traditional directory‐based filesystems. An ownCloud instance accesses the Swift cluster via cloudfuse. The application GUI loads sufficiently fast. File listing is slower, but is still acceptable. The significant limitations here stem from cloudfuse. Some operations, like renaming folders, are not possible. Neither is it always sufficiently efficient. This could be remedied by a direct implementation, or possibly by improving the built‐in Swift support.
Apart from performance, scalability remains a key concern. We can demonstrate that the addition of more Raspberry Pi predictably results in better performances, i.e., that Swift is scalable. Though based on hardware configuration limitations, we cannot confirm if the trend is linear.
The next concern is costs. The cluster costs are acceptable (see Table 7.2 for a pricing of some cluster configurations). The PoE (Power over Ethernet) add‐on boards and PoE managed switches that we used are not specific to the project and could easily be replaced by a cheaper solution that involves a separate power supply unit and a simple unmanaged switch without having a negative impact on the system's performance. In comparing our configuration with other architectures, modern gateway servers (e.g., Dell Gateway 5000 series) would be higher, all hardware included.
Table 7.2 Approximate costs of the Raspberry Pi cluster.
| Component | Price | Units | Total |
| Raspberry Pi | 35 € | 7 | 245 € |
| PoE module | 45 € | 7 | 315 € |
| Cat.5e SFTP Cable | 3 € | 7 | 21 € |
| Aruba 2530 8 PoE+ | 320 € | 1 | 320 € |
| Total | 901 |
7.4.3 Docker Orchestration
Docker and Kubernetes as the most prominent examples of lightweight virtualization mechanisms via containers have been successfully placed on Raspberry Pis [23]. This demonstrates the feasibility of running container clusters on clustered RPi architectures.
As our focus is on edge cloud architectures, we investigate the core components for a middleware platform for edge clouds. Figure 7.3 describes a complete orchestration flow for containers on edge cloud architectures. The first step is the construction of a container from individual images, for instance from an open repository of images such as a container hub. Different containers for a specific processing problem are composed, which forms an orchestration plan. This plan defines the edge cloud topology on which the orchestration is enacted. This orchestration mechanism realizes central components of an edge PaaS‐oriented middleware platform. Containerization helps to overcome limitations of the earlier two solutions we discussed.

Figure 7.3 Overall orchestration flow.
7.4.3.1 Docker Orchestration Architecture
With RPis, we can facilitate in a cost‐effective way an intermediate layer for local edge data processing. Its advantages are reliability, low‐energy consumption, low‐cost devices that are still capable of performing data‐intensive computations.
Implementation – Hardware and Operating System.
As in the earlier architectural patterns, we constructed clusters composed of a number Raspberry Pis. Installation and power management were initial concerns. Technically, the devices were connected to a switch via cables for signal processing and power supply to the devices. Each unit was equipped with a PoE module, connected to the Raspberry Pi. By replicating the GPIO interface, further modules can be connected easily. A network connection is setup by connecting the switch through an Ethernet port. The switch can be configured to connect to an existing DHCP (dynamic host configuration protocol) server that can distribute network configuration parameters like IP (internet protocol) addresses. Furthermore, via virtual LANs subnets can be created. As the operating system, Hypriot OS, a Debian distribution, was chosen. The distribution already contains Docker software.
Swarm Cluster Architecture and Security.
The cluster nodes have different roles. A selected node becomes the user gateway into the cluster. This is initialized by creating Docker Machines on the gateway node. Then both the OS and the Docker daemon are configured on all Raspberry Pis cluster nodes. Docker Machines can manage remote hosts by sending the commands from the Docker client to the Docker demon on the remote machine over a secured connection. When the first Docker Machine is created, in order to create a trusted network, new TLS protocol certificates are created on the local machine and then copied to the remote machines. In order to address security concerns, we replaced the default authentication, which is considered insecure, by a public‐key authentication during the cluster setup process. This way, we avoid a password‐based authentication. We enhanced security by requiring the SSH daemon on the remote machine to only accept public‐key authentication.
We used Docker Swarm for cluster management: normal nodes run one container that identifies them as a swarm node. The swarm managers deploy an additional dedicated container that provides the management interface. Swarm managers can be configured to support fault tolerance through redundancy (running as replicas in that case). There are mechanisms to avoid inconsistencies in the swarm that could lead to potential misbehavior. If several swarm managers exist, they can also share their knowledge about the swarm by communicating information from a nonleading manager to the one in charge.
Service Discovery.
Information about a swarm, images, and how they can be reached must be shared. In a multihost network, we can use, for instance, a key‐value store that keeps information about network state (e.g., discovery, networks, endpoints and IP addresses).
We used Consul as a key‐value store for our implementation, which supports redundant swarm managers and works without a continuous Internet connection, which is important for our need to support intermittent connectivity. For fault tolerance, it can be replicated. Consul selects a lead node in a cluster and manages information distribution across the nodes.
Swarm Handling.
In a properly set‐up swarm configuration of Docker Machines, the nodes communicate their presence to both Consul server and swarm manager. Users can interact with the swarm manager and each Docker Machine separately. Docker‐specific environment variables can be requested from a Docker Machine for this. A Docker client tunnels into the manager and executes remote commands over there. Users can obtain swarm information and execute swarm tasks (e.g., launching a new container) in this way. The manager then deploys it according to any given constraints following the selected swarm strategy.
7.4.3.2 Docker Evaluation – Installation, Performance, Power
This evaluation section looks at the key concerns of performance and power consumption. Furthermore, we will also address practical concerns such as installation effort. The evaluation of the project focuses on the complexity to build and handle it and its costs, before concentrating on the performance and power consumption [11].
Installation Effort and Costs.
Assembling the hardware for the Raspberry Pi cluster does not require special tools or advanced skills. This makes the architecture suitable to be installed and managed in remote areas without expert support available. Once running, handling the cluster is straightforward. Interacting with clusters does not differ from single Docker installations. One drawback is the reliance on the ARM architecture, where images are not always available, causing the need for them to be created on demand.
Performance.
We stress‐tested the swarm manager by deploying larger numbers of containers (with a fixed image) over a given period of time. We measured
- Time to deploy the images
- Launch time for containers
In the test, we deployed 250 containers on the swarm with five requests at a time. To determine the efficiency of the Raspberry Pi cluster, both the time to execute the analysis and the power consumption are measured and put into perspective with a virtual machine cluster on a desktop computer and a single Raspberry Pi.
The tests were run on a desktop PC, which was a 64‐bit Intel Core 2 Quad Q9550 @2.83GHz Windows 10 machine with 8GB Ram and a 256GB SSD.
If we compare the RPi setup with a normal VM configuration in Table 7.3, there is less performance for the Raspberry Pi cluster. This is a consequence of the limits of the single board architecture. A particular problem is the I/O of the micro SD card slot, which is slow in terms of reading and writing, with a maximum of 22MB/s and 20MB/s, respectively, for the two operations. This can be partially explained by a network connectivity of only 10/100Mbit/s.
Table 7.3 Time comparison – listing the overall, the mean, and the maximal time of container.
| Launching | Idle | Load | |
| Raspberry Pi cluster | 228s | 2137ms | 9256ms |
| Single Raspberry Pi node | 510s | 5025ms | 14115ms |
| Virtual machine cluster | 49s | 472ms | 1553ms |
| Single virtual machine node | 125s | 1238ms | 3568ms |
Power.
The observations for power consumption are presented in Tables 7.4 and 7.5. With 26W (2.8W per unit) under load, as shown in Table 7.4, the modest power consumption of the Raspberry Pi cluster puts its moderate performance that we noted above into perspective. Table 7.5 details the consumption in two situations (idle and under load).
Table 7.4 Comparison of the power consumption while idling and under load.
| Idle | Load | |
| Raspberry Pi cluster | 22.5W | 25‐26W |
| Single Raspberry Pi node | 2.4W | 2.8W |
| Virtual machine cluster | 85‐90W | 128‐132W |
| Single virtual machine node | 85‐90W | 110‐114W |
Table 7.5 Power consumption of the Raspberry Pi cluster while idling and under load.
| Idle | Load | |
| Single node | 2.4W | 2.7W |
| All nodes | 16W | 17‐18W |
| Switch | 5W | 8W |
| Complete system | 22.5W | 25‐26W |
With still‐acceptable performance and suitability from the installation and operations perspective (including power consumption), the suitability for an environment with limitations that requires robustness can be assumed.
7.5 IoT Integration
Apart from looking at the suitability of the three different architectural options, we also need to analyze the suitability of the proposed solutions for IoT applications with sensor integration. In order to demonstrate this, we refer to a medical application. For this healthcare application, we integrated health status sensing devices into a Raspberry Pi infrastructure.
Protocols exist for bridging between the sensor world and Internet‐enabled technologies such as MQTT, making the installation and management work easy. Our experiments, however, have demonstrated the need for dedicated power management. Some sensors required considerable energy and caused overheating. Thus, solutions to prevent overheating and reduce consumption are needed.
7.6 Security Management for Edge Cloud Architectures
IoT/edge computing networks are distributed environments in which we cannot assume that sensor owners, network, and device providers trust each other. In order to guarantee a secure edge cloud computing architecture [30] with reliable and secure orchestration activities, we need to consider several aspects:
- Things (sensors, devices, software) might join, leave, and rejoin the network, so we need to be able to identify them.
- Data are generated and communicated, making it necessary to trace this by providing provenance and making sure that data have not been tampered with.
- Dynamic and local architectural management decisions, e.g. changing or updating software for maintenance or in emergency situations, need to be agreed upon by the relevant participants.
In this section, we explore the suitability of blockchain technology for providing a security platform that addresses the above concerns for edge architectures. Blockchains enable a form of distributed software architectures, where agreement on shared state for decentralized and transactional data can be established across a network of untrusted participants – as it is in the case in edge clouds. This approach avoids relying on central trusted integration points, which quickly become single points of failure. Edge platforms built on blockchains can take advantage of common blockchain properties such as data immutability, integrity, fair access, transparency, and nonrepudiation of transactions.
The key aim is to manage trust locally in lightweight edge clusters with low computational capabilities and limited connectivity. Blockchain technologies can be applied to identity management, data provenance, and transaction processing. For orchestration management, we can employ advanced blockchain concepts such as smart contracts.
7.6.1 Security Requirements and Blockchain Principles
Blockchain technology is a solution for untrusted environments that lack a central authority or trusted third party: many security‐related problems can be addressed using the decentralized, autonomous, and trusted capabilities of blockchains. Additionally, blockchains are tamper‐proof, distributed, and shared databases where all participants can append and read transactions but no one has full control over it. Every added transaction is digitally signed and timestamped. This means that all operations can be traced back and their provenance can be determined [31].
The security model implemented by blockchains ensures data integrity using consensus‐driven mechanisms to enable the verification of all the transactions in the network, which makes all records easily auditable. This is particularly important since it allows tracking all sources of insecure transactions in the network (e.g., vulnerable IoT devices) [32]. A blockchain can also strengthen the security of edge components in terms of identity management and access control and prevent data manipulation.
The principles of blockchains can be summarized as follows:
- A transaction is a signed piece of information created by a node in the network, which is then broadcast to the rest of the network. The transactions are digitally signed to maintain integrity and enforce nonrepudiation.
- A block is a collection of transactions that are appended to the chain. A newly created block is validated by checking the validity of all transactions contained within.
- A blockchain is a list of all the created and validated blocks that make up the network. The chain is shared between all the nodes in the network. Each newly created and validated block is linked to the previous block in the chain with a hash value generated by applying a hashing algorithm over its content. This allows the chain to maintain nonrepudiation.
- Public keys act as addresses. Participants in the network use their private keys to sign their transactions.
- A block is appended to the existing blockchain using a specific consensus method and respective coordination protocol. Consensus is driven by collected self‐interest.
- Three types of blockchain platforms can be identified: (i) permissionless, where anyone can have a copy of the database and join the network both for reading and writing; (ii) permissioned, where access to the network is controlled by a preselected set of participants; and (iii) private, where the participants are added and validated by a central organization.
One of the (more recent) key concepts that has been introduced in blockchains is a smart contract, which is a piece of executable code residing on the blockchain that gets executed if a specific agreement (condition) is met. Smart contracts are not processed until their invoking transactions are included in a new block. Blocks impose an order on transactions, thus resolving nondeterminism that might otherwise affect their execution results. Blockchain contracts increase the autonomy of the edge/IoT devices by allowing them to sign agreements directly with any interested party that respects the contract requirements.
7.6.2 A Blockchain‐Based Security Architecture
However, blockchains cannot be considered the silver bullet to all security issues in edge/IoT devices, especially due to massive data replication, performance and scalability. This is a challenge in the constrained environment we are working in. Blockchain technology has been applied for transactional processing before, but the novelty here is the application to lightweight IoT architectures, as shown in Figure 7.4:
- Application of consensus methods and protocols in localized clusters of edge devices to manage trust between the participating Edge/IoT devices.
- Smart contracts define orchestration decisions in the architecture.

Figure 7.4 Blockchain‐based IoT orchestration and security management.
In such environments, IoT/edge endpoints are generally what we call sleepy nodes, meaning that they are not online all the time to save battery life. This constrains them to only have intermittent Internet connectivity, especially when they are deployed in remote locations. We propose to use blockchains to manage security (trust, identity) in distributed autonomous clusters [10, 12]. As a starting point, we use permissioned blockchains with brokers, since they achieve higher performance in terms of block mining time and reduce transaction validation time and cost. We recommend using partially centralized/decentralized settings with permissioned blockchains with permissions for fine‐grained operations on the transaction level (e.g., permission to create assets). In an implementation, we can consider both permissioned blockchains with permissioned miners (write) and also permissionless normal nodes (read). Additionally, not all IoT/edge endpoints need to behave as full blockchain nodes. Rather, they would act as lightweight nodes that access a blockchain to retrieve instructions or identity‐related information (e.g., who has access to sensor data). For instance, each of the IoT endpoints, when connected to the network, would receive a receipt proof of payment (proof of payment is a receipt proving that a specific party has the necessary credentials to access a certain resource) that states which devices to trust and interact with. Then, when the endpoint receives a request, it needs to be signed by one of the trusted devices. A verifier is a third party that provides information about the external world. When the validation of a transaction depends on the external state, the verifier is requested to check the external state and to provide the result to the validator (miner), which then validates the condition. A verifier can be implemented as a server outside the blockchain, and has the permission to sign transactions using its own key pair on demand.
With respect to concerns such as cost efficiency, performance, and flexibility, a crucial point is choosing what data and computation should be placed on‐chain and what should be kept off‐chain.
Basing our architecture on container‐based orchestration, software becomes another artefact that is subject to identity and authorization concerns, since edge computing is essentially based on the idea to bring software to the edge (to process data locally) rather than to bring data to the cloud center. Device and container orchestration involving the deployed software can be implemented within a smart contract transaction of the blockchain.
Blockchains use specialized protocols to coordinate the consensus process. The protocol configuration affects security and scalability. Different strategies have been used to confirm that a transaction is securely appended to the blockchain, for instance to prevent double spending in blockchains like bitcoin. An option is to wait for a certain number (X) of blocks to have been generated after the transaction is included into the blockchain. We will also investigate mechanisms such as checkpointing with respect to the best suitability for trusted orchestration management through blockchains. The option here is to add a checkpoint to the blockchain, so that all the participants can accept the transactions up to the checkpoint as valid and irreversible. Checkpointing relies on an entity trusted by the community to define the checkpoint (see discussion on architectural options with trusted broker), while traditional X‐block confirmation can be decided by the developers of the applications using blockchain.
Consensus protocols can be configured to improve scalability in terms of transaction processing rate (sample sizes are 1 to 8MB). Larger sizes can include more transactions into a block and thus increase maximum throughput. Another configuration change would be to adjust mining difficulty to shorten the time required to generate a block, thus reducing latency and increasing throughput (but a shorter inter‐block time would lead to an increased frequency of forks).
7.6.3 Integrated Blockchain‐Based Orchestration
We singled out data provenance, data integrity, identity management, and orchestration as important concerns in our framework. Based on the outline architecture from Figure 7.4, we detail now how blockchains are integrated into our framework. The starting point is the W3C PROV standard (https://www.w3.org/TR/prov‐overview/). According to the PROV standard, provenance is information about entities, activities, and people involved in producing, in our case, data. This provenance data aids the assessment of quality, reliability or trustworthiness in the data production (See Figure 7.5.) The goal of PROV is to enable the representation and interchange of provenance information using common formats such as XML.

Figure 7.5 Provenance model. Adapted from W3C. “PROV Model Primer,” April 30, 2013.© 2013 World Wide Web Consortium, (MIT, ERCIM, Keio, Beihang). https://www.w3.org/TR/2013/NOTE‐prov‐primer‐20130430/.
Provenance records describe the provenance of entities, which in our case are data objects. An entity's provenance can refer to other entities, e.g. compiled sensor data to the original records. Activities create and change entities, often making use of previously existing entities to achieve this. They are dynamic parts, here the processing components. The two fundamental activities are generation and usage of entities, which are represented by relationships in the model. Activities are carried out on behalf of agents that also act as owners of entities, i.e. are responsible for the processing. An agent takes some degree of responsibility for the activity taking place. Actors in our case are orchestrators in charge of deploying software and managing infrastructure.
We can expand this idea by considering the provenance of an agent. In our case, the orchestrator is also a container, though one with a management rather than an application role. In order to make provenance assertions about an agent in PROV, the agent must then be declared explicitly both as an agent and as an entity.
In the schematic example in Figure 7.6, the orchestrator is the agent that orchestrates, i.e. deploys the collector and analyzer containers. This effectively forms a contract between orchestrator and nodes, whereby the nodes are contracted to carry out the collection and analyzer activities:
- The collector USES sensor data and GENERATES the joint data.
- The analyzer USES the joint data and GENERATES the results.

Figure 7.6 Blockchain‐based tracking of an orchestration plan.
This sequence of activities forms an orchestration plan. This plan is enacted based on the blockchain smart contract concept, requiring the contracted activity to
- Obtain permissions (credentials) to retrieve the data (USES)
- Create output entities (GENERATE) as an obligation defined in the contract.
A smart contract is defined through a program that defines the implementation of the work to be done. It includes the obligations to be carried out, the benefits (in terms of SLAs), and the penalties for not achieving the obligations. Generally, fees paid to the contractor and possible penalties to compensate the contract issuer shall be neglected here. Each step based on the contract is recorded in the blockchain:
- The generation of data through a provenance entry: what, by whom, when.
- The creation of a credentials object defining, based on the identity of the processing component, the authorized activities.
- The formalized contract between the orchestrator and the activity node. The obligations formalized include in the IoT edge context data‐oriented activities such as storage, filtering and analysis, and container‐oriented activities such as deploying or redeploying (updating) a container.
Figure 7.7 shows the full architecture of the system, including the interactions between all the components. All transactions are recorded in the blockchain to guarantee data provenance. Additionally, the identity of all components (e.g., containers, verifier) is stored to ensure identity. The transactions are executed by invoking the appropriate smart contract. For instance, when a sensor container collects data, it invokes the send_collected_data smart contract defined by the collector container by passing a signed hash of the collected data. At this point the collected container checks the identity of the sensor container (e.g., signature) and the integrity of the data (e.g., the hash of the data), and then downloads the data in order to process it.

Figure 7.7 Architecture of the blockchain integration.
7.7 Future Research Directions
We identified some limitations and have discussed concerns that require further work such as the security aspect where we explored blockchain technologies for provenance and identity management.
In the cloud context, some existing PaaS platforms have started to address limitations in the orchestration and DevOps. Some observations shall clarify this:
- Containers: Containers are now widely adopted for PaaS clouds.
- DevOps: Development and operations integration is still at an early stage, particularly if complex orchestrations on distributed topologies are considered that need to be managed in an integrated DevOps‐style pipeline.
As a first concern, architecting applications for container‐based clustered environments in a DevOps style is addressed by microservice‐style software architecting [33–36]. Microservices are small, self‐contained, and independently deployable architectural units that find their counterparts at deployment level in the form of containers.
For cluster management, more work is needed in addition to (static) architectural concerns. The question arises to which extent their distribution reaches an edge consisting of small devices and embedded systems and what the platform technology for that might be [31, 38]. A sample question is whether devices that run small Linux distributions such as the Debian‐based DSL (which requires about 50MB storage) can support container host and cluster management. Significant improvements are still required to reliably support data and network management. Orchestration, the way it is realized in cluster solutions at the moment, is ultimately not adequate and requires further improvements, among them performance management. What is needed are controllers [39, 40] that manage performance, workload, and failure in these unreliable contexts, while, for instance, fault‐tolerance [41] or performance management [42] has been addressed for the cloud, edge and fog adaptation are still needed.
Another concern that needs more attention is security. We have discussed blockchain technology for provenance management and other security concerns as a possible solution, but here more implementation and empirical evaluation work are needed.
Our ultimate aim is an edge cloud PaaS. We have implemented, experimented with, and evaluated some core ingredients of such an edge cloud PaaS, demonstrating that containers are the most suitable technology platform to reach this goal. Currently, cloud management platforms are still at an earlier stage than the container platforms they build on. Some recent third‐generation PaaS support a build‐your‐own‐PaaS idea, while being lightweight at the same time. We believe that the next development step could be a fourth‐generation PaaS in the form of an edge cloud PaaS bridging the gap between IoT and cloud technology.
7.8 Conclusions
Edge cloud computing environments are distributed to bring specific services to the users away from centralized computing infrastructures [43], shifting computation from heavyweight data center clouds to more lightweight resources. Consequently, we require more lightweight virtualization mechanisms on these lightweight devices and have identified the need to orchestrate the deployment of services in this environment as key challenges. We looked at requirements for a platform (PaaS) middleware solution that specifically supports application service packaging and orchestration as a key PaaS concern.
We presented and evaluated different cluster management architectural options, including the recently emerging container technology, an open‐source cloud solution (OpenStack), and an own‐build solution to analyze the suitability of these options for edge clouds built on single‐board lightweight device clusters. Our observations and evaluations support the current trend toward container technology as the most suitable option. Container technology is better suited than the other options to migrate and apply cloud PaaS technology toward distributed heterogeneous clouds through lightweightness and interoperability as key properties.
References
- 1 A. Chandra, J. Weissman, and B. Heintz. Decentralized Edge Clouds. IEEE Internet Computing, 2013.
- 2 F. Bonomi, R. Milito, J. Zhu, and S. Addepalli. Fog computing and its role in the internet of things. Workshop Mobile Cloud Computing, 2012.
- 3 N. Kratzke. A lightweight virtualization cluster reference architecture derived from Open Source PaaS platforms. Open Journal of Mobile Computing and Cloud Computing, 1: 2, 2014.
- 4 O. Gass, H. Meth, and A. Maedche. PaaS characteristics for productive software development: An evaluation framework. IEEE Internet Computing, 18(1): 56–64, 2014.
- 5 C. Pahl and H. Xiong. Migration to PaaS clouds – Migration process and architectural concerns. International Symposium on the Maintenance and Evolution of Service‐Oriented and Cloud‐Based Systems, 2013.
- 6 C. Pahl, A. Brogi, J. Soldani, and P. Jamshidi. Cloud container technologies: a state‐of‐the‐art review. IEEE Transactions on Cloud Computing, 2017.
- 7 C. Pahl and B. Lee. Containers and clusters for edge cloud architectures – a technology review. Intl Conf on Future Internet of Things and Cloud, 2015.
- 8 C. Pahl. Containerization and the PaaS Cloud. IEEE Cloud Computing, 2015.
- 9 C. Pahl, S. Helmer, L. Miori, J. Sanin, and B. Lee. A container‐based edge cloud PaaS architecture based on Raspberry Pi clusters. IEEE Intl Conference on Future Internet of Things and Cloud Workshops, 2016.
- 10 C. Pahl, N.El Ioini, and S. Helmer. A decision framework for blockchain platforms for IoT and edge computing. International Conference on Internet of Things, Big Data and Security, 2018.
- 11 D. von Leon, L. Miori, J. Sanin, N. El Ioini, S. Helmer, and C. Pahl. A performance exploration of architectural options for a middleware for decentralised lightweight edge cloud architectures. International Conference on Internet of Things, Big Data and Security, 2018.
- 12 C. Pahl, N. El Ioini, and S. Helmer. An Architecture Pattern for Trusted Orchestration in IoT Edge Clouds. Third IEEE International Conference on Fog and Mobile Edge Computing FMEC, 2018.
- 13 J. Zhu, D.S. Chan, M.S. Prabhu, P. Natarajan, H. Hu, and F. Bonomi. Improving web sites performance using edge servers in fog computing architecture. Intl Symp on Service Oriented System Engineering, 2013.
- 14 A. Manzalini, R. Minerva, F. Callegati, W. Cerroni, and A. Campi. Clouds of virtual machines in edge networks. IEEE Communications, 2013.
- 15 C. Pahl, P. Jamshidi, and O. Zimmermann. Architectural principles for cloud software. ACM Transactions on Internet Technology, 2018.
- 16 C. Pahl, P. Jamshidi, and D. Weyns. Cloud architecture continuity: Change models and change rules for sustainable cloud software architectures. Journal of Software: Evolution and Process, 29(2): 2017.
- 17 S. Soltesz, H. Potzl, M.E. Fiuczynski, A. Bavier, and L. Peterson. Container‐based operating system virtualization: a scalable, high‐performance alternative to hypervisors, ACM SIGOPS Operating Syst Review, 41(3): 275–287, 2007.
- 18 P. Bellavista and A. Zanni. Feasibility of fog computing deployment based on docker containerization over Raspberry Pi. International Conference on Distributed Computing and Networking, 2017.
- 19 P. Tso, D. White, S. Jouet, J. Singer, and D. Pezaros. The Glasgow Raspberry Pi cloud: A scale model for cloud computing infrastructures. Intl. Workshop on Resource Management of Cloud Computing, 2013.
- 20 S. Qanbari, F. Li, and S. Dustdar. Toward portable cloud manufacturing services, IEEE Internet Computing, 18(6): 77–80, 2014.
- 21 E.De Coninck, S. Bohez, S. Leroux, T. Verbelen, B. Vankeirsbilck, B. Dhoedt, and P. Simoens. Middleware platform for distributed applications incorporating robots, sensors and the cloud. Intl Conf on Cloud Networking, 2016.
- 22 C. Dupont, R. Giaffreda, and L. Capra. Edge computing in IoT context: Horizontal and vertical Linux container migration. Global Internet of Things Summit, 2017.
- 23 J. Turnbull. The Docker Book, 2014.
- 24 V. Andrikopoulos, S. Gomez Saez, F. Leymann, and J. Wettinger. Optimal distribution of applications in the cloud. Adv Inf Syst Eng: 75–90, 2014.
- 25 P. Jamshidi, M. Ghafari, A. Ahmad, and J. Wettinger. A framework for classifying and comparing architecture‐centric software evolution research. European Conference on Software Maintenance and Reengineering, 2013.
- 26 T. Binz, U. Breitenbücher, F. Haupt, O. Kopp, F. Leymann, A. Nowak, and S. Wagner. OpenTOSCA – a runtime for TOSCA‐based cloud applications, Service‐Oriented Computing: 692–695, 2013.
- 27 P. Abrahamsson, S. Helmer, N. Phaphoom, L. Nicolodi, N. Preda, L. Miori, M. Angriman, Juha Rikkilä, Xiaofeng Wang, Karim Hamily, Sara Bugoloni. Affordable and energy‐efficient cloud computing clusters: The Bolzano Raspberry Pi Cloud Cluster Experiment. IEEE 5th Intl Conference on Cloud Computing Technology and Science, 2013.
- 28 R.van der Hoeven. “Raspberry pi performance,” http://freedomboxblog.nl/raspberry‐pi‐performance/, 2013.
- 29 L. Miori. Deployment and evaluation of a middleware layer on the Raspberry Pi cluster. BSc thesis, University of Bozen‐Bolzano, 2014.
- 30 C.A. Ardagna, R. Asal, E. Damiani, T. Dimitrakos, N.El Ioini, and C. Pahl. Certification‐based cloud adaptation. IEEE Transactions on Services Computing, 2018.
- 31 A. Dorri, S. Salil Kanhere, and R. Jurdak. Towards an Optimized BlockChain for IoT, Intl Conf on IoT Design and Implementation, 2017.
- 32 N. Kshetri. Can Blockchain Strengthen the Internet of Things? IT Professional, 19(4): 68–72, 2017.
- 33 P. Jamshidi, C. Pahl, N.C. Mendonça, J. Lewis, and S. Tilkov. Microservices – The Journey So Far and Challenges Ahead. IEEE Software, May/June 2018.
- 34 R. Heinrich, A.van Hoorn, H. Knoche, F. Li, L.E. Lwakatare, C. Pahl, S. Schulte, and J. Wettinger. Performance engineering for microservices: research challenges and directions. In Proceedings of the 8th ACM/SPEC on International Conference on Performance Engineering Companion, 2017.
- 35 C.M. Aderaldo, N.C. Mendonça, C. Pahl, and P. Jamshidi. Benchmark requirements for microservices architecture research. In Proceedings of the 1st International Workshop on Establishing the Community‐Wide Infrastructure for Architecture‐Based Software Engineering, 2017.
- 36 D. Taibi, V. Lenarduzzi, and C. Pahl. Processes, motivations, and issues for migrating to microservices architectures: an empirical investigation. IEEE Cloud Computing, 4(5): 22–32, 2017.
- 37 A. Gember, A Krishnamurthy, S. St. John, et al. Stratos: A network‐aware orchestration layer for middleboxes in the cloud. Duke University, Tech Report, 2013.
- 38 T.H. Noor, Q.Z. Sheng, A.H.H. Ngu, R. Grandl, X. Gao, A. Anand, T. Benson, A. Akella, and V. Sekar. Analysis of Web‐Scale Cloud Services. IEEE Internet Computing, 18(4): 55–61, 2014.
- 39 P. Jamshidi, A. Sharifloo, C. Pahl, H. Arabnejad, A. Metzger, and G. Estrada. Fuzzy self‐learning controllers for elasticity management in dynamic cloud architectures, Intl ACM Conference on Quality of Software Architectures, 2016.
- 40 P. Jamshidi, A.M. Sharifloo, C. Pahl, A. Metzger, and G. Estrada. Self‐learning cloud controllers: Fuzzy q‐learning for knowledge evolution. International Conference on Cloud and Autonomic Computing ICCAC, pages 208–211, 2015.
- H. Arabnejad, C. Pahl, G. Estrada, A. Samir, and F. Fowley. A Fuzzy Load Balancer for Adaptive Fault Tolerance Management in Cloud Platforms, European Conference on Service‐Oriented and Cloud Computing (CCGRID): 109–124, 2017.
- H. Arabnejad, C. Pahl, P. Jamshidi, and G. Estrada. A comparison of reinforcement learning techniques for fuzzy cloud auto‐scaling, 17th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID): 64–73, IEEE, 2017.
- 43 S. Helmer, C. Pahl, J. Sanin, L. Miori, S. Brocanelli, F. Cardano, D. Gadler, D. Morandini, A. Piccoli, S. Salam, A.M. Sharear, A. Ventura, P. Abrahamsson, and T.D. Oyetoyan. Bringing the cloud to rural and remote areas via cloudlets. ACM Annual Symposium on Computing for Development, 2016.