
Chapter 14
Indexing Your Database
WHAT’S IN THIS CHAPTER
- Index-Related Features Available in SQL Server 2012 and Previous Versions
- How Partitioned Tables and Indexes Enable your Databases to be More Manageable and Scalable
- Implementing Partitioned Tables and Indexes
- Maintaining and Tuning Indexes
One of the most important functions of production database administrators is to ensure that query times are consistent with service-level agreements (SLAs) or within user expectations. One of the most effective techniques to improve query performance is to create indexes.
Query performance is generally measured in the amount of time the query takes to run and the amount of work and resources it consumes. Long-running and expensive queries consume resources over an extended period of time and may slow down or cause applications, reports, and other database operations to time-out.
For this reason understanding what indexing features are available in SQL Server 2012 and how to implement them is essential to any production DBA.
This chapter offers an overview of the indexing-related features available in SQL Server 2012, including the newest feature known as column-store indexes, which can greatly increase query performance over traditional row-based indexes.
NOTEWORTHY INDEX-RELATED FEATURES IN SQL SERVER
This section highlights the new indexing features introduced in SQL Server 2012 and overviews the index-related features introduced in previous versions of SQL Server.
What’s New for Indexes in SQL Server 2012
SQL Server 2012 introduces a new type of index called columnstore index based on the Vertipaq engine acquisition. Additionally, online index operations such as index build and rebuild containing LOB columns are now supported. The next two sections describe these two new enhancements in detail.
Columnstore Index
Columnstore index is the new type of index introduced in SQL Server 2012. It is a column-based non-clustered index geared toward increasing query performance for workloads that involve large amounts of data, typically found in data warehouse fact tables.
This new type of index stores data column-wise instead of row-wise, as indexes currently do. For example, consider an Employee table containing employee data, as shown in Table 14-1.
TABLE 14-1: Sample Employee Table

In a row-based index, the data in the Employee table is stored in one or more data pages, as shown in Figure 14-1.
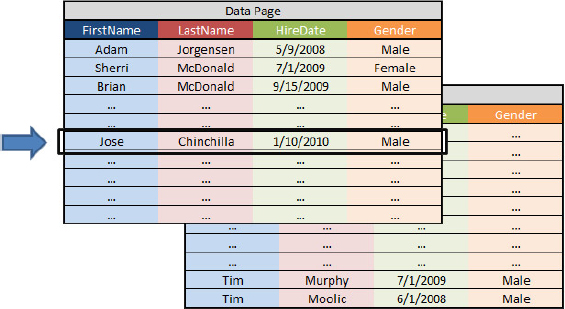
In a column-based index, the data in the Employee table is stored in separate pages for each of the columns, as shown in Figure 14-2.
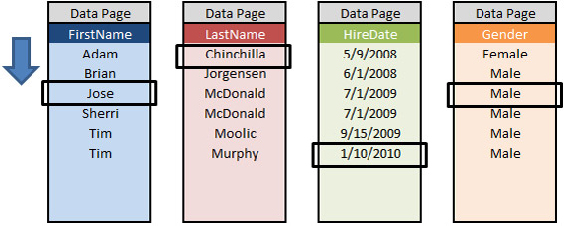
Performance advantages in columnstore indexes are possible by leveraging the VertiPaq compression technology, which enables large amounts of data to be compressed in-memory. This in-memory compressed store reduces the number of disk reads and increases buffer cache hit ratios because only the smaller column-based data pages that need to satisfy a query are moved into memory.
For wide tables, such as those commonly found in data warehouses, columnstore indexes come in handy as you essentially reduce the amount and size of data needed to be accessed for any given query. For example, consider the following query:
SELECT FirstName, LastName, FROM EmployeeTable WHERE HireDate >= '1/1/2010'
A column-store index is more efficient for this example because only one smaller-sized (compressed) data page is needed to satisfy the query. In this case, the columnstore index for the HireDate column satisfies the WHERE clause. A row-based index is not as efficient because it may need to load one or more larger-sized data pages into memory and read the entire rows, including columns not needed to satisfy the query. A larger-sized data page and additional unnecessary columns increases data size, memory usage, disk reads, and overall query time. Imagine if this table had 20 or more columns!
Columnstore indexes have some requirements and limitations, as shown in Table 14-2.
TABLE 14-2: Requirements and Limitations of Columnstore Index
| DESCRIPTION | REQUIREMENT/LIMITATION |
| No. of columnstore indexes per table | 1 |
| Index record size limit of 900 bytes | No limit/Not applicable. |
| Index limit of 16 key columns | No limit/Not applicable. |
| Table partitioning support | Yes, as a partition aligned index. |
| Can be combined with row-based indexes? | Yes, if clustered index, all columns must be present in columnstore index. |
| Update, Delete, Insert, Merge supported? | No, columnstore indexes are read-only but workarounds exist. Refer to Books Online: Best Practices: Updating Data in a Columnstore Index. |
| Data types that can be included in a columnstore index | Char, varchar except varchar(max), nchar, nvarchar except nvarchar(max), decimal and numeric except with precision greater than 18 digits, int, bigint, smallint, tinyint, float, real, bit, money, smallmoney, all date and time data types except datetimeoffset with scale greater than 2. |
| Data types that cannot be included in a columnstore index. | Binary, varbinary, ntext, text, image, varchar(max), nvarchar(max), uniqueidentifier, rowversion, timestamp, sql_variant, decimal and numeric with precision greater than 18 digits, datetimeoffset with scale greater than 2, CLR types including hierarchyid and spatial types, xml. |
Following is the basic syntax to create a columnstore index:
CREATE COLUMNSTORE INDEX idx_cs1 ON EmployeeTable (FirstName, LastName, HireDate, Gender)
You can also create columnstore indexes using SQL Server Management Studio. Simply navigate to the Indexes section of the table, and select New Index ![]() Non-Clustered Columnstore Index.
Non-Clustered Columnstore Index.
Online Index Operations with LOB Columns
In previous versions of SQL Server, online index operations were not possible on indexes with columns defined as large object data types. LOB datatypes include image, text, ntext, varchar(max), nvarchar(max), varbinary(max), and xml datatypes.
SQL Server 2012 supports building and rebuilding indexes that contain LOB columns while keeping the index available for read and write operations. A new reference consistency and sharing mechanism is employed during the online rebuild process to keep track of the data referenced by the old index and the new index.
Index Features from SQL Server 2008R2, SQL Server 2008, and SQL Server 2005
While the core functionality of index hasn’t changed, there have been a number of enhancements in the last few releases of SQL Server. This section highlights all the index-related features introduced in previous versions of SQL Server that are now part of SQL Server 2012.
SQL Server 2008 introduced index-related features:
- Support for up to 15K partitions: In SQL Server 2008 Service Pack 2 and SQL Server 2008 R2 Service Pack 1 (SP1), the limit of 999 table partitions increased to 15,000.
- Filtered indexes and statistics: You can use a predicate to create filtered indexes and statistics on a subset of rows in the table. Prior to SQL Server 2008, indexes and statistics were created on all the rows in the table. Now you can include a WHERE predicate in the index or statistics you create to limit the number of rows to be included in the indexes or stats. Filtered indexes and statistics are especially suitable for queries that select from well-defined subsets of data; columns with heterogeneous categories of values; and columns with distinct ranges of values.
- Compressed storage of tables and indexes: SQL Server 2008 added support for on-disk storage compression in both row and page format for tables, indexes, and indexed views. Compression of partitioned tables and indexes can be configured independently for each partition. Chapter 12, “Monitoring Your SQL Server,” covers this topic in detail.
- Spatial indexes: SQL Server 2008 introduced support for spatial data and spatial indexes. Spatial data in this context represents geometric objects or physical location. SQL Server supports two spatial data types: geography and geometry. A spatial column is a table column that contains data of a spatial data type, such as geometry or geography. A spatial index is a type of extended index that enables you to index a spatial column. SQL Server uses the NET CLR (Common Language Runtime) to implement this data type. Refer to the topic “Working with Spatial Indexes (Database Engine)” in Books Online (BOL) for details.
SQL Server 2005 introduced these index-related features:
- Partitioned tables and indexes: Beginning with SQL Server 2005, you can create tables on multiple partitions and indexes on each partition. This enables you to manage operations on large datasets, such as loading and unloading a new set of data, more efficiently by indexing just the new partition, rather than having to re-index the whole table. You can find a lot more information about partitioned tables and indexes later in this chapter.
- Online index operations: Online index operations were added as an availability feature in SQL Server 2005. They enable users to continue to query against a table while indexes are built or rebuilt. The main scenario for using this new feature is when you need to make index changes during normal operating hours. The new syntax for using online index operations is the addition of the ONLINE = ON option with the CREATE INDEX, ALTER INDEX, DROP INDEX, and ALTER TABLE operations.
- Parallel index operations: Parallel index operations are another useful feature from SQL Server 2005. They are available only in Enterprise Edition and only apply to systems running on multiprocessor machines. The key scenario for using this feature is when you need to restrict the amount of CPU resources that index operations consume. This might be either for multiple index operations to coexist, or more likely when you need to allow other tasks to complete while performing index operations. They enable a DBA to specify the MAXDOP for an index operation. This is useful on large systems, enabling you to limit the maximum number of processors used in index operations. It’s effectively a MAXDOP specifically for index operations, and it works with the server-configured MAXDOP setting. The new syntax for parallel index operations is the MAXDOP = n option, which can be specified on CREATE INDEX, ALTER INDEX, DROP INDEX (for clustered indexes only), ALTER TABLE ADD (constraint), ALTER TABLE DROP (clustered index), and CONSTRAINT operations.
- Asynchronous statistics update: This is a performance SET option -AUTO UPDATE STATISTICS_ASYNC. When this option is set, outdated statistics are placed on a queue and are automatically updated by a worker thread later. The query that generated the autoupdate request continues before the stats are updated. Asynchronous statistics updates cannot occur if any data definition language (DDL) statements such as CREATE, ALTER, or DROP occur in the same transaction.
- Full-text indexes: Beginning with SQL Server 2005, Full-Text Search supports the creation of indexes on XML columns. It was also upgraded to use MSSearch 3.0, which includes additional performance improvements for full-text index population. It also means that there is now one instance of MSSearch for each SQL Server instance.
- Nonkey columns in non-clustered indexes: With SQL Server 2005 and SQL Server 2008, nonkey columns can be added to a non-clustered index. This has several advantages. It enables queries to retrieve data faster because the query can now retrieve everything it needs from the index pages without having to do a bookmark lookup into the table to read the data row. The nonkey columns are not counted in the limits for the non-clustered index number of columns (16 columns) or key length (900 bytes). The new syntax for this option is INCLUDE (column Name, ... ), which is used with the CREATE INDEX statement.
- Index lock granularity changes: In SQL Server 2005, the CREATE INDEX and ALTER INDEX T-SQL statements were enhanced by the addition of new options to control the locking that occurs during the index operation. ALLOW _ROW_LOCKS and ALLOW_PAGE_LOCKS specify the granularity of the lock to be taken during the index operation.
- Indexes on XML columns: This type of index on the XML data in a column enables the Database Engine to find elements within the XML data without having to shred the XML each time.
- Dropping and rebuilding large indexes: The Database Engine was modified in SQL Server 2005 to treat indexes occupying more than 128 extents in a new, more scalable way. If a drop or rebuild is required on an index larger than 128 extents, the process is broken down into logical and physical stages. In the logical phase, the pages are simply marked as deallocated. After the transaction commits, the physical phase of deallocating the pages occurs. The deallocation takes place in batches, occurring in the background, thereby avoiding taking locks for a long period of time.
- Indexed view enhancements: Indexed views have been enhanced in several ways. They can now contain scalar aggregates and some user-defined functions (with restrictions). In addition, the query optimizer can now match more queries to indexed views if the query uses scalar expressions, scalar aggregates, user-defined functions, interval expressions, and equivalency conditions.
- Version Store: Version Store provides the basis for the row-versioning framework used by Online Indexing, Multiple Active Result Sets (MARS), triggers, and the new row-versioning-based isolation levels.
- Database Tuning Advisor: The Database Tuning Advisor (DTA) replaced SQL Server 2000’s Index Tuning Wizard (ITW). DTA offers the following new features:
- Time-bound tuning
- Tune across multiple databases
- Tune a broader class of events and triggers
- Tuning log
- What-if analysis
- More control over tuning options XML file support
- Partitioning support
- Offloading tuning load to lower-spec hardware
- Execution by Database_owners
This chapter uses the sample database AdventureWorks available to download from Codeplex.com at http://msftdbprodsamples.codeplex.com/.
PARTITIONED TABLES AND INDEXES
This section offers an overview of the process that goes into creating indexes and partitioning tables and how they can be combined to manage large tables and to scale.
Understanding Indexes
Good index design starts with a good understanding of the benefits indexes provide. In books, table of contents help readers locate a section, chapter, or page of interest. SQL Server indexes serve the same function as a table of contents in a book. It enables SQL Server to locate and retrieve the data requested in a query as fast as possible.
Consider a 500-page book with dozens of sections and chapters and no table of contents. To locate a section of a book, readers would need to flip and read through every page until they locate the section of interest. Imagine if you have to do this for multiple sections of the book. It would be a time-consuming task.
This analogy also applies to SQL Server database tables. Without proper indexes, SQL Server has to scan through all the data pages that contain the data in a table. For tables with large amounts of data, this becomes time-consuming and resource-intensive. This is the reason why indexes are so important.
Indexes can be classified in several ways depending on the way they store data, their internal structure, their purpose, and the way they are defined. The following sections briefly describe these types of indexes.
Row-based Indexes
A row-based index is a traditional index in which data is stored as rows in data pages. These indexes include the following:
Clustered Indexes
Clustered indexes store and sort data based on the key column(s). There can only be one clustered index per table because data can be sorted in only one order. A clustered index is created by default when a table definition includes a primary key constraint.
Non-clustered Indexes
Non-clustered indexes contain index key values and row locators that point to the actual data row. If there is no clustered index, the row locator is a pointer to the row. When there is a clustered index present, the row locator is the clustered index key for the row.
Non-clustered indexes can be optimized to satisfy more queries, improve query response times, and reduce index size. The two most important of these optimized non-clustered indexes are described in the next two sections.
Covering Indexes
Covering indexes are non-clustered indexes that include nonkey columns in the leaf level. These types of indexes improve query performance, cover more queries, and reduce IO operations as the columns necessary to satisfy a query are included in the index itself either as key or nonkey columns. Covering indexes can greatly reduce bookmark lookups.
The ability to include nonkey columns enables indexes to be more flexible by including columns with data types not supported as index key columns Nonkey columns also enable indexes to extend beyond the 16 key column limitation. Nonkey columns do not count towards the 900 byte index key size limit.
Filtered Indexes
Filtered indexes can take a WHERE clause to indicate which rows are to be indexed. Since you index only a portion of rows in a table, you can create only a non-clustered filtered index. If you try to create a filtered clustered index, SQL Server returns a syntax error.
Why do you need a non-clustered index with a subset of data in a table? A well-designed filtered index can offer the following advantages over full-table indexes:
- Improved query performance and plan quality: If the index is deep (more pages because of more data), traversing an index takes more I/O and results in slow query performance. If you have a large table and you know that there are more user queries on a well-defined subset of data, creating a filtered index makes queries run faster because less I/O will be performed since the number of pages is less for the smaller amount of data in that filtered index. Moreover, stats on the full table may be less accurate compared to filtered stats with less data, which also helps improve query performance.
- Reduced index maintenance costs: Maintaining a filtered index is less costly than maintaining a full index because of smaller data size. Obviously, it also reduces the cost of updating statistics because of the smaller size of the filtered index. As mentioned earlier, you must know your user queries and what kind of data they query often to create a well-defined filtered index with a subset of that data. If the data outside of the filtered index is modified frequently, it won’t cost anything to maintain the filtered index. That enables you to create many filtered indexes when the data in those indexes is not modified frequently.
- Reduced index storage costs: Less data, less space. If you don’t need a full-table non-clustered index, creating a smaller dataset for a non-clustered filtered index takes less disk space.
Column-based Indexes
Column-based indexes are a new type of index introduced in SQL Server 2012 in which only column data is stored in the data pages. These indexes are based on the Vertipaq engine implementation, which is capable of high compression ratios and handles large data sets in memory.
How Indexes are Used by SQL Server?
A good understanding of how indexes are used by SQL Server is also important in a good index design. In SQL Server, the Query Optimizer component determines the most cost-effective option to execute a query. The Query Optimizer evaluates a number of query execution plans and selects the execution plan with the lowest cost.
The execution plan selected by the Query Optimizer may or may not make efficient use of indexes, or it may not use indexes at all. The following sections describe how execution plans can use indexes.
Table Scan
Indexes are not required by SQL Server to retrieve data requested by a query. In the absence of indexes or if determined to be least cost effective, SQL server scans every row of a table until the query is satisfied. This is known as a table scan. As you may suspect, table scans can bring forth expensive IO operations for large tables. SQL Server has to read every single data page until it finds the data that satisfies the query. A table scan can take from a couple of seconds to several minutes. Some users may even experience time-outs by applications with short response-time thresholds.
Table scans generally occur when there is no clustered indexed available; in other words, when the table is a heap.
Index Scan and Index Seek
An index scan is similar to a table scan in that SQL Server has to read every single data page in the index until it finds the data that satisfies the query. Index scans can be both IO and memory intensive operations.
An index seek on the other hand, is a more efficient way of retrieving data because only data pages and rows that satisfy the query are read. Index seeks result in less data pages read, hence reducing IO and memory consumption.
Depending on how selective a query is, meaning what percentage of the total number of rows in a table is requested, SQL Server Query Optimizer can choose to do an index scan rather than an index seek. The tipping point at which an index scan is preferred by the SQL Server Query Optimizer is not always a definitive percentage. There are many factors such as parallelism settings, memory availability, and number of rows that contribute in the decision for the more cost-effective option.
Bookmark Lookup
It is quite common to see queries that require additional columns than the ones included in a non-clustered index. To retrieve these additional columns, SQL Server needs to retrieve additional data pages to cover all requested columns. Bookmark lookups can become expensive operations when dealing with a large number of rows because more data pages need to be retrieved from disk and loaded into memory.
To avoid excessive bookmark lookup operations, the required columns that need to be covered by the query can be included in the index definition. These types of indexes are known as covering indexes.
Creating Indexes
At this point you should be familiar with the different types of indexes and how they are used in execution plans. This understanding is crucial to design and fine tune indexes to improve query performance.
Indexes are created manually using T-SQL commands or by using a graphical user interface such as SQL Server Management Studio. SQL Server 2012 also includes a tool called the Database Engine Tuning Advisor (DTA) that suggests and generates missing indexes for you. This tool is discussed later in this chapter.
To create an index using T-SQL commands, perform the following steps:
1. Open SQL Server Management Studio and connect to the SQL server instance.
2. Open a new query window and follow one of the sample syntaxes provided in the following list:
- To create a clustered index you use the CREATE CLUSTERED INDEX T-SQL command as follows:
CREATE CLUSTERED INDEX idx_EmployeeID ON EmployeeTable (EmployeeID)
- To create a non-clustered index you use the CREATE NONCLUSTERED INDEX T-SQL command. NONCLUSTERED is the default index type and can be omitted:
CREATE NONCLUSTERED INDEX idx_LastName ON EmployeeTable (LastName) Or CREATE INDEX idx_LastName ON EmployeeTable (LastName)
- To create a covering index you use the CREATE NONCLUSTERED INDEX T-SQL command along with the INCLUDE keyword as follows:
CREATE NONCLUSTERED INDEX idx_LastName ON EmployeeTable (LastName) INCLUDE (FirstName, HireDate)
- To create a filtered index you use the CREATE NONCLUSTERED INDEX T-SQL command along with the WHERE keyword as follows:
CREATE NONCLUSTERED INDEX idx_GenderFemale ON EmployeeTable (Gender) WHERE Gender = 'Female'
Why Use Both Partitioned Tables and Indexes?
Partitioned tables are a way to spread a single table over multiple partitions, and while doing so each partition can be on a separate filegroup. Following are several reasons for doing this:
- Faster and easier data loading: If your database has a large amount of data to load, you might want to consider using a partitioned table. “A large amount of data,” doesn’t mean a specific amount of data, but any case in which the load operation takes longer than is acceptable in the production cycle. A partitioned table enables you to load the data to an empty table that’s not in use by the “live” data, so it has less impact on concurrent live operations. Clearly, there will be an impact on the I/O subsystem, but if you also have separate filegroups on different physical disks, even this has a minimal impact on overall system performance. After the data is loaded to the new table, you can perform a switch to add the new table to the live data. This switch is a simple metadata change that quickly executes, which is why partitioned tables are a great way to load large amounts of data with limited impact to users who touch the rest of the data in the table.
- Faster and easier data deletion or archival: For the same reasons, partitioned tables also help you to delete or archive data. If your data is partitioned on boundaries that are also the natural boundaries on which you add or remove data, the data is considered to be aligned. When your data is aligned, deleting or archiving data is as simple as switching a table out of the current partition, after which you can unload or archive it at your leisure. There is a bit of a catch to this part: With archiving, you often want to move the old data to slower or different storage. The switch operation is so fast because all it does is change metadata. It doesn’t move any data around, so to actually move the data from the filegroup where it lived to the old, slow disk archival filegroup, you need to move the data, but you move it when the partition isn’t attached to the existing partitioned table. Therefore, although this may take quite some time, it can have a minimal impact on any queries executing against the live data.
- Faster queries: You are probably interested in an opportunity to get faster queries. When querying a partitioned table, the query optimizer can eliminate searching through partitions that it knows won’t hold any results. This is referred to as partition elimination. This works only if the data in the partitioned table or index is aligned with the query. That is, the data must be distributed among the partitions in a way that matches the search clause on the query. You learn more details about this as you consider how to create a partitioned table. SQL Server 2008 offers some improvements for parallel query processing enhancements on partitioned tables and indexes. Refer to the section “Query Processing Enhancements on Partitioned Tables and Indexes” in Chapter 13 for details on this topic.
- Sliding windows: A sliding window is basically what was referred to earlier in the discussion about adding new data and then deleting or archiving old data. What you did was fill a new table, switch it into the live table, and then switch an existing partition out of the live table for archival or deletion. It’s kind of like sliding a window of new data into the current partitioned table, and then sliding an old window of data out of the partitioned table.
Creating Partitioned Tables
Table partitioning requires SQL Server 2012 Enterprise Edition. There are also some expectations about the hardware in use, in particular the storage system; although these are implicit expectations, and you can store the data anywhere you want. You just won’t get the same performance benefits you would get if you had a larger enterprise storage system with multiple disk groups dedicated to different partitions.
SQL Server 2012 supports up to 15,000 partitions by default and is fully supported in 64-bit systems. In 32-bit systems, it is possible to create more than 1,000 table or index partitions, but it is not fully supported.
To create a partitioned table or index, perform the following steps:
1. Specify how the table or index is partitioned by the partitioning column, and the range of values included for each partition. Only one partitioning column can be specified. For example, to create four partitions based on a DateKey column, you execute the following command:
CREATE PARTITION FUNCTION DateKeyRange_PF (int) AS RANGE LEFT FOR VALUES (20021231, 20031231, 20041231);
Either LEFT or RIGHT boundaries can be specified in the partition function. If no partition boundary is specified LEFT is used as default. Table 14-3 describes the partitions created by the preceding partition function.
TABLE 14-3: Partition Results for DateKeyRange Function.
| PARTITION NO. | DESCRIPTION |
| 1 | All records with DateKey <= 20021231 |
| 2 | Records between Datekey>20021231 and Datekey<=20031231 |
| 3 | Records between Datekey>20031231 and Datekey<=20041231 |
| 4 | All records with DateKey > 20041231 |
2. To determine the partition number where a record will be placed based on the DateKey column value, use the $PARTITION function as follows:
SELECT '20010601' DateKey, $PARTITION.DateKeyRange_PF(20010601) PartitionNumber UNION SELECT '20030601' DateKey, $PARTITION.DateKeyeRange_PF(20030601) PartitionNumber UNION SELECT '20040601' DateKey, $PARTITION.DateKeyRange_PF(20040601) PartitionNumber UNION SELECT '20050601' DateKey, $PARTITION.DateKeyeRange_PF(20050601)
The results of the $PARTITION function are shown in Figure 14-3.

3. Now create a partition scheme. For example, create a partition scheme with four filegroups that can be used to hold the four partitions defined in the DateKeyRange_PF partition function as follows:
CREATE PARTITION SCHEME DateKeyRange_ps AS PARTITION DateKeyRange_PF TO (FileGroup1, FileGroup2, FileGroup3, FileGroup4, FileGroup5)
Another important task of database administrators is to monitor existing index health and identify where new indexes are needed. Every time data is inserted, updated, or deleted in SQL Server tables, indexes are accordingly updated.
Over time, the distribution of data in data pages can become unbalanced. Some data pages become loosely filled, whereas others are filled to the maximum. Too many loosely filled data pages create performance issues as more data pages need to be read to retrieve the requested data.
On the other hand, pages filled close to their maximum may create page splits when new data is inserted or updated. When page splits occur, about half of the data is moved to a newly created data page. This constant reorganization consumes resources and creates data page fragmentation.
The goal is to store as much data into the smallest number of data pages with room for growth to prevent excessive page splits. This delicate balance can be achieved by fine-tuning the index fill factor. For more information on fine-tuning the index fill factor, refer to Books Online at http://msdn.microsoft.com/en-us/library/ms177459(v=SQL.110).aspx.
Monitoring Index Fragmentation
You can monitor index fragmentation through the provided Data Management Views (DMVs) available in SQL Server 2012. One of the most useful DMVs is sys.dm_db_index_physical_stats, which provides average fragmentation information for each index.
For example, you can query the sys.dm_db_index_physical_stats DMV as follows:
SELECT index_id,avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats
(
DB_ID('AdventureWorks'),
OBJECT_ID('AdventureWorks'),
NULL, NULL, 'DETAILED'
)
Figure 14-4 shows the results of this query.

From execution results of this DMV, you can observe indexes with high fragmentation. Indexes with high defragmentation percentages need to be defragmented to avoid performance issues. Heavily fragmented indexes are stored and accessed inefficiently by SQL Server depending on the type of fragmentation, internal or external. External fragmentation means that data pages are not stored in logical order. Internal fragmentation means that pages store much less data then they can hold. Both types of fragmentation cause query execution to take longer.
Cleaning Up Indexes
Index cleanup should always be part of all database maintenance operations. You need to perform these index cleanup tasks on a regular basis, depending on how fragmented indexes become due to changes to the data. If your indexes become highly fragmented, you can defragment it through one of the operations described here:
- Reorganize an index:
- Reorders and compacts leaf level pages
- Performs index reordering online, no long-term locks
- Good for indexes with low fragmentation percentages
- Rebuild an index:
- Drops and re-creates the index
- Reclaims disk space
- Reorders and compacts rows in contiguous pages
- Online index rebuilt option available in Enterprise Edition
- Better for highly fragmented indexes
Table 14-2 lists the general syntax for index operations for the DimCustomer table.
TABLE 14-2: Index /operations Syntax for DimCustomer Table
| OPERATION | SYNTAX |
| Create Index | CREATE INDEX IX_CustomerAlternateKey ON DimCustomer_CustomerAlternateKey |
| Reorganize Index | ALTER INDEX IX_DimCustomer_CustomerAlternateKey ON DimCustomer REORGANIZE |
| Rebuild Index | ALTER INDEX IX_DimCustomer_CustomerAlternateKey ON DimCustomer REBUILD |
| Drop Index | DROP INDEX IX_DimCustomer_CustomerAlternateKey FROM DIMCustomer |
Indexes may become heavily fragmented over time. Deciding whether to reorganize or rebuild indexes depends in part on their level of fragmentation and your maintenance window. Generally accepted fragmentation thresholds to perform an index rebuild range between 20 percent and 30 percent. If your index fragmentation level is below this threshold, performing a reorganize index operation may be good enough.
But, why not just rebuild indexes every time? You can, if your maintenance window enables you to do so. Keep in mind that index rebuild operations take longer to complete, time during which locks are placed and all inserts, updates, and deletions have to wait. If you are running SQL Server 2012 Enterprise Edition, you can take advantage of online index rebuild operations. Unlike standard rebuild operations, online index operations allow for inserts, updates, and deletions during the time the index is being rebuilt.
IMPROVING QUERY PERFORMANCE WITH INDEXES
SQL Server 2012 includes several Dynamic Management Views (DMVs) that enable you to fine-tune queries. DMVs are useful to surface execution statistics for a particular query such as the number of times it has been executed, number of reads and writes performed, amount of CPU time consumed, index query usage statistics, and so on.
You can use the execution statistics obtained through DMVs to fine-tune a query by refactoring the T-SQL code to take advantage of parallelism and existing indexes, for example. You can also use them to identify missing indexes, indexes not utilized, and identify indexes that require defragmentation.
For example, explore the existing indexes in the FactInternetSales table from the AdventureWorks database. As shown in Figure 14-5, the FactInternetSales table has been indexed fairly well.
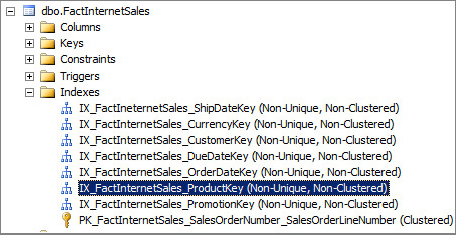
To illustrate the query tuning process, run through a series of steps to generate execution statistics that can surface through DMVS:
1. Drop the existing ProductKey and OrderDateKey indexes from the FactInternet Sales table as follows:
USE [AdventureWorks] GO -- Drop ProductKey index IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[dbo].[FactInternetSales]') AND name = N'IX_FactInternetSales_ProductKey') DROP INDEX [IX_FactInternetSales_ProductKey] ON [dbo].[FactInternetSales] GO -- Drop OrderDateKeyIndex IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[dbo].[FactInternetSales]') AND name = N'IX_FactInternetSales_OrderDateKey') DROP INDEX [IX_FactInternetSales_OrderDateKey] ON [dbo].[FactInternetSales] GO
2. Execute the following script three times, like so:
/*** Internet_ResellerProductSales ***/ SELECT D.[ProductKey], D.EnglishProductName, Color, Size, Style, ProductAlternateKey, sum(FI.[OrderQuantity]) InternetOrderQuantity, sum(FR.[OrderQuantity]) ResellerOrderQuantity, sum(FI.[SalesAmount]) InternetSalesAmount, sum(FR.[SalesAmount]) ResellerSalesAmount FROM [FactInternetSales] FI INNER JOIN DimProduct D ON FI.ProductKey = D.ProductKey INNER JOIN FactResellerSales FR ON FR.ProductKey = D.ProductKey WHERE FI.OrderDateKey BETWEEN 20000101 AND 20041231 AND FR.OrderDateKey BETWEEN 20000101 AND 20041231 GROUP BY D.[ProductKey], D.EnglishProductName, Color, Size, Style, ProductAlternateKey
Figure 14-6 displays T-SQL script executed along with results and an execution time of 11 seconds. Your execution results may vary depending on the resources available to your machine.

3. Run the following script to analyze the execution statistics of the previous query.
SELECT TOP 10 SUBSTRING(qt.TEXT, (qs.statement_start_offset/2)+1, ((CASE qs.statement_end_offset WHEN -1 THEN DATALENGTH(qt.TEXT) ELSE qs.statement_end_offset END - qs.statement_start_offset)/2)+1) QueryText, qs.last_execution_time, qs.execution_count , qs.last_logical_reads, qs.last_logical_writes, qs.last_worker_time, qs.total_logical_reads, qs.total_logical_writes, qs.total_worker_time, qs.last_elapsed_time/1000000 last_elapsed_time_in_S, qs.total_elapsed_time/1000000 total_elapsed_time_in_S, qp.query_plan FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp ORDER BY qs.last_execution_time DESC, qs.total_logical_reads DESC
Figure 14-7 shows the execution statistics reported mainly by the sys.dm_exec_query_stats DMV.
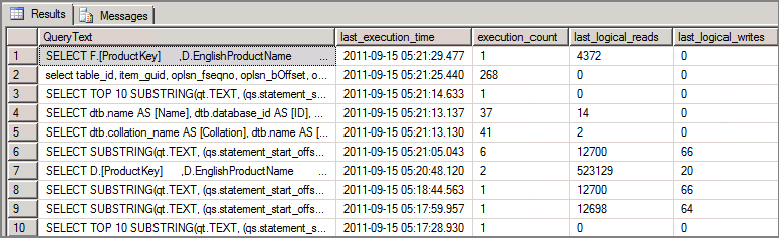
From this DMV you can observe that there was a large number of reads and long period of time the processor was busy executing the query. Keep these baseline numbers in mind. At the end of this example, you can reduce these numbers.
4. Query the sys.dm_db_missing_index_details DMV to check if missing indexes are reported like so:
SELECT DatabaseName = DB_NAME(database_id,) [Number Indexes Missing] = count(*) FROM sys.dm_db_missing_index_details GROUP BY DB_NAME(database_id) ORDER BY 2 DESC;
Figure 14-8 shows the results of the sys.dm_db_missing_index_details DMV. The sys.dm_db_missing_index_details DMV is a great way to quickly identify if you need indexes. If you have a substantial number of missing indexes, you may want to run the Database Tuning Advisor to let the Query Optimizer recommend which indexes to implement.
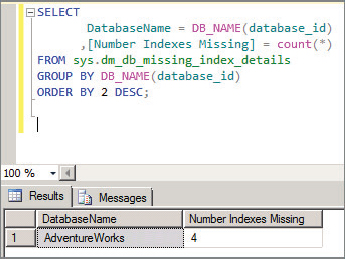
You could also try to identify which indexes are needed by analyzing the query text captured by the sys.dm_exec_sql_text (refer to Figure 14-7).
5. Continuing with your query tuning endeavor, create the ProductKey and OrderDateKey indexes on the FactInternetSales table as follows:
USE [AdventureWorks] GO IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'FactInternetSales') AND name = N'IX_FactInternetSales_OrderDateKey') DROP INDEX IX_FactInternetSales_OrderDateKey ON FactInternetSales GO IF NOT EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[dbo].[FactInternetSales]') AND name = N'IX_FactInternetSales_ProductKey') CREATE NON-CLUSTERED INDEX IX_FactInternetSales_ProductKey ON FactInternetSales (ProductKey ASC) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY] GO
6. Execute the Internet_ResellerProductSales query defined in step 2 three more times. Figure 14-9 shows that execution time went down to 8 seconds! That is a 28% improvement in query execution simply by adding the appropriate index.

One of the more useful tools available for database administrators since SQL Server 2005 is the Microsoft Database Engine Tuning Advisor (DTA). DTA enables you to analyze a database for missing indexes and other performance-tuning recommendations such as partitions and indexed views. DTA accepts the following types of workloads:
- SQL script files (*.sql)
- Trace files (*.trc)
- XML files (*.xml)
- Trace table
- Plan Cache (new)
Figure 14-10 displays the Database Engine Tuning Advisor’s workload selection screen, including the new Plan Cache option. One of the great benefits of the Database Tuning Advisor to database administrators and SQL Server developers is the ability to rapidly generate database performance improvement recommendations without knowing the underlying database schema, data structure, usage patterns, or even the inner workings of the SQL Server Optimizer.

In addition, new in SQL Server 2012, the plan cache can also be used as part of a DTA workload. This new workload option eliminates the need to manually generate a workload for analysis, such as trace files.
The saying “Too much of a good thing is not always good” holds true when discussing indexes. Too many indexes create additional overhead associated with the extra amount of data pages that the Query Optimizer needs to go through. Also, too many indexes require too much space and add to the time it takes to accomplish maintenance tasks.
Still, the Data Tuning Wizard typically recommends a large number of indexes, especially when analyzing a workload with many queries. The reason behind this is because queries are analyzed on an individual basis. It is a good practice to incrementally apply indexes as needed, always keeping a baseline to compare if the new index improves query performance.
SQL Server 2012 provides several Dynamic Management Views (DMV) to obtain index usage information. Some of these DMVs include:
- sys.dm_db_missing_index_details: Returns detailed information about a missing index.
- sys.dm_db_missing_index_columns: Returns information about the table columns that are missing an index.
- sys.dm_db_missing_index_groups: Returns information about a specific group of missing indexes.
- sys.dm_db_missing_index_group_stats: Returns summary information about missing index groups.
- sys.dm_db_index_usage_stats: Returns counts of different types of index operations and the time each type of operation was last performed.
- sys.dm_db_index_operational_stats: Returns current low-level I/O, locking, latching, and access method activity for each partition of a table or index in the database.
- sys.dm_db_index_physical_stats: Returns size and fragmentation information for the data and indexes of the specified table or view.
For example, to obtain a list of indexes that have been used and those that have not been used by user queries, query the sys.dm_db_index_usage_stats DMV. From the list of indexes that have been used you can obtain important statistics that help you fine tune your indexes. Some of this information includes index access patterns such index scans, index seeks, and index bookmark lookups.
To obtain a list of indexes that have been used by user queries, execute the following script:
SELECT
SO.name Object_Name,
SCHEMA_NAME(SO.schema_id) Schema_name,
SI.name Index_name,
SI.Type_Desc,
US.user_seeks,
US.user_scans,
US.user_lookups,
US.user_updates
FROM sys.objects AS SO
JOIN sys.indexes AS SI
ON SO.object_id = SI.object_id
INNER JOIN sys.dm_db_index_usage_stats AS US
ON SI.object_id = SI.object_id
AND SI.index_id = SI.index_id
WHERE
database_id=DB_ID('AdventureWorks')
SO.type = 'u'
AND SI.type IN (1, 2)
AND (US.user_seeks > 0 OR US.user_scans > 0 OR US.user_lookups > 0 );
To obtain a list of indexes that have not been used by user queries, execute the following script:
SELECT
SO.Name TableName,
SI.name IndexName,
SI.Type_Desc IndexType
US.user_updates
FROM sys.objects AS SO
INNER JOIN sys.indexes AS SI
ON SO.object_id = SI.object_id
LEFT OUTER JOIN sys.dm_db_index_usage_stats AS US
ON SI.object_id = US.object_id
AND SI.index_id = US.index_id
WHERE
database_id=DB_ID('AdventureWorks')
SO.type = 'u'
AND SI.type IN (1, 2)
AND (US.index_id IS NULL)
OR (US.user_seeks = 0 AND US.user_scans = 0 AND US.user_lookups = 0 );
Indexes that are not used by user queries should be dropped, unless they have been added to support mission critical work that occurs at specific points in time, such as monthly or quarterly data extracts and reports. Unused indexes add overhead to insert, delete, and update operations as well as index maintenance operations. Index usage statistics are initialized to empty when the SQL Server service restarts. The database is detached or shutdown when the AUTO_CLOSE property is turned on.
The newest index type introduced in SQL Server 2012 is the columnstore index. Columnstore indexes are column-based, non-clustered indexes that store data based on discrete values found in a column. This new type of index has greater advantages over regular row-based indexes. These advantages include smaller-sized indexes and faster retrieval of data.
An important part of indexing your database includes creating partitions and indexes, along with advanced indexing techniques such as filtered indexes using the WHERE keyword and covering indexes using the INCLUDED keyword. Reorganizing and rebuilding indexes is an important maintenance operation to reduce and eliminate index fragmentation. SQL Server 2012 Database Tuning Advisor has been enhanced and can now help you tune your databases based on the plan cache.
You can put the finishing touches on your indexed database by tuning a query, which you can accomplish by utilizing the data from Data Management Views (DMVs). It is also important to remember the benefits of finding indexes that are not used by user queries and removing them.