
Chapter 4. Basic Java Distributed Technologies

4.1 Java Distributed Computing Basics
4.2 Java Distributed Technologies and APIs
4.3 XML Standards and Java APIs
4.4 Building Services with Java Components
The Java platform provides the basis for the runtime infrastructure on which many organizations worldwide host their enterprise applications. Java receives strong support for distributed applications and architectures from a number of IT vendors and open-source providers, which has been fundamental to the Java platform from its inception and predates the emergence of Web-based services standards.
This chapter introduces the pre-Web services distributed technologies of the Java platform, focusing on how these technologies can be utilized in support of building service-oriented solutions. Some of the technologies discussed also provide the basic building blocks for Web-based Java services themselves.
Note
If you are a Java professional with a working knowledge of Java distributed technologies, then you can skip this chapter.
4.1 Java Distributed Computing Basics
The Java platform’s three distinct development and runtime platforms are based on the object-oriented Java programming language, with each targeted at a different application environment.
• Java Platform, Standard Edition (Java SE) – Targeted primarily at desktop applications and embedded applications, Java SE provides a range of capabilities delivered as class libraries that include several distributed computing capabilities.
• Java Platform, Micro Edition (Java ME) – Intended for applications running on mobile devices, such as cell phones and PDAs, Java ME aims to address some of the issues inherent in this environment, such as ensuring applications can run successfully with a small memory footprint and without continuous connectivity to external systems.
• Java Platform, Enterprise Edition (Java EE) – Targeted at enterprise applications, Java EE provides a robust and highly scalable runtime environment capable of hosting business-critical applications, such as quality-of-service (QoS) aspects like security and scalability. Java EE is built on Java SE, which provides all of the capabilities of the Java SE platform.
This book focuses on Java EE as the platform most relevant to the exploration of Java-based SOA. However, Java EE depends on Java SE, which in turn depends on some other basic building blocks that require attention before examining Java EE in detail.
Java SE Architecture
Java SE is based on a layered architecture. Java applications run in a Java runtime environment (JRE). The Java Virtual Machine (JVM) included in this runtime environment insulates Java applications from the details of the operating system and provides portability between different hardware and operating system platforms. Included in the runtime environment are a number of Java classes defined within the Java SE specification and grouped as packages. These classes provide the core functionality typically required by applications, such as network access and text/math processing capabilities. Application source code is compiled using a Java Development Kit (JDK) in the bytecode running in the JVM. The JDK provides a compiler (javac) and other useful utilities and toolkits as well as the JRE.
Java EE Architecture
We’ll now introduce the Java EE platform, describing its origins and development from Java SE.
The Beginning of Java EE
Enterprise applications often access one or more back-end systems or enterprise information systems (EISs). These could be relational database-packaged applications, such as SAP, Siebel, or components implemented in other application environments, such as CICS. Java EE applications provide business logic that interacts with these back-end systems and expose this business logic to clients requiring access.
Let’s consider what is involved in starting from scratch and writing an enterprise application without the benefit of an application server. For example, providing for concurrent access by multiple clients and multi-threading capabilities is necessary. Restricting access to only authenticated clients who are authorized to access the services will require work. A solution with transactional integrity across multiple resource managers is required.
The Java EE specification defines the application architecture and runtime infrastructure onto which entire applications are deployed. Each container manages the execution of specific types of components providing a kind of contract between the application and its host runtime infrastructure. The containers also provide standard capabilities to satisfy application QoS requirements, such as multi-threading, transactional behavior, and security.
The Java EE runtime architecture is designed to support multi-tiered enterprise applications executing in different types of containers that each provide runtime support for a variety of Java EE application components. The common infrastructure platform for all containers is the Java SE runtime.
The Applet and Application Client Container (ACC) hosts client applications that execute in environments, such as desktops, browsers, and mobile devices. A Java applet hosted in an applet container, such as a browser with a Java plug-in, can access Web components over HTTP(S). The applet container services force the Java applets to execute in a restricted sandbox on the client machine.
The ACC provides services for persistence (JPA), messaging (JMS), Web services based on SOAP (Java API for XML Web services or JAX-WS, SOAP API for attachments with Java or SAAJ, and Java API for XML Registries or JAXR), REST (Java API for RESTful Services or JAX-RS), and Contexts and Dependency Injection (CDI). These APIs will be discussed in subsequent chapters.
Note
Although client applications executing in an ACC can directly use Enterprise JavaBean (EJB) services to access back-end systems, relying on Web-based services to access service-enabled applications is preferable. ACC components can also use JPA to read and write data from the database.
The Web container manages execution of and provides services for presentation-tier components, which, in a typical Java EE application, are implemented using the Java Server Pages (JSP), Servlets, or Java Server Faces (JSF) technologies. The Web container also provides various supporting services for persistence (JPA), transactions (Java Transaction API or JTA), standards-based connectivity to EIS systems based on the J2EE Connector Architecture (JCA), security, messaging, and Web services. ACC host client applications and Web applications do not need to use EJBs to consume business services. They can be accessed over Web-based services or JPA can be used to access relational databases.
The EJB container provides a hosting environment for stateless and stateful session EJBs and message-driven beans (MDBs). As with the Web container, the EJB container must also provide additional supporting services around persistence, transactions, messaging, security, and Web services.
Starting from Java EE 5, the emphasis has shifted from building business logic in distributable and remotely accessible EJBs to building reusable, testable business logic in Plain Old Java Objects (POJOs). Open-source frameworks like Spring first popularized this model, and Java EE has embraced this philosophy encouraging Java developers to focus on building business logic in POJOs and choosing an appropriate remote protocol for distribution only when application requirements demand.
Java EE 5 first changed the EJB programming model to be based on annotated POJOs that could still benefit from container services, such as concurrency and transaction management. In Java EE 5, by default, EJBs were local components. However, even with Java EE 5, the implementations were monolithic with no way for vendors to choose to implement only a subset of the specifications and still be Java EE-compliant. In contrast with Java EE 6, the specifications emphasize the modularity of the Java EE platform by introducing the concept of a profile that represents a configuration of the platform suited to a particular class of applications.
An entire class of applications can be built leveraging only the services provided by the Web container as Java EE vendors now have the flexibility to implement only a subset of the Java EE specifications conforming to the requirements of a particular profile. One such profile is the Java EE Web Profile, which focuses only on Web components and a set of supporting APIs. The Web Profile leaves out some of the enterprise APIs such as JCA and JMS, which may not be required for building many typical Web applications. However, the Web Profile does include supporting services like persistence, transactions, and a lightweight local EJB-based programming model, which allow developers to build modern Web applications backed by enterprise databases.
Java EE 7 added a number of new and different specifications in each of the container areas. The one of significant interest to this book is an upward revision in the Java API for RESTful Services to version 2.0 (JAX-RS 2.0). Detailed descriptions of how REST services can be built using JAX-RS 2.0 are provided will be covered in subsequent chapters.
Application Packaging and Deployment
Java EE applications are packaged as deployable enterprise archive files (EAR). These include compiled code (Java bytecode packaged as class files), optional source code, and any additional artifacts required by applications, such as properties files. The archive files with an .ear filename suffix are created using the zip file format so that they can be opened and the contents viewed using a compatible zip/unzip utility. EAR files can include EJB modules, Web modules, application client modules, and resource adapter modules, each of which can be packaged as a zip archive with a .war (Web applications), .rar (resource adapters), or .jar (other modules) filename suffix.
Beginning with EJB 3.1 in Java EE 6, local EJB artifacts can be packaged within a .war filename suffix to eliminate the need for a separate EJB jar. This greatly simplifies application development where suitably annotated EJB classes can be directly placed inside the WEB-INF/classes directory or packaged as a .jar file inside the WEB-INf/lib directory.
Deployment Descriptors
The Java EE deployment unit (.war, .jar, .ear, or .rar files) can also contain deployment descriptors including the deployment settings of an application. These XML files located in a subdirectory of each module include runtime configuration settings, such as the context root used by the application server for resources like servlets and JSPs exposed using a URI. Since enterprise applications and their associated modules require access to resources outside of the Java EE environment, a way of referencing these resources is required to allow changes to be made to the external environment without recompiling and redeploying application code. In addition to allowing the occasional changes needing to be made to a production environment, such as changing the host name or IP address of a host, this also allows enterprise application code to be promoted without change through test environments and into production as part of the application lifecycle.
Deployment descriptors help insulate applications from the external environment by providing a layer of indirection through references to resources. Application code is bound to the reference defined in the deployment descriptor, and the binding of the reference to the external environment can be defined and changed at deployment time.
Java EE, from version 5 onwards, greatly simplifies deployment by removing the need for XML-based deployment descriptors with the exception of Web applications requiring a web.xml file. Generally, the EJB and Web service-related deployment descriptor settings can be described through code annotations. However, if required, deployment descriptor settings can be specified in XML files overriding code annotations.
Java EE Architectural Tiers
Java EE is based on a multi-tiered application and runtime architecture. Table 4.1 summarizes the architectural tiers with the APIs and technologies that play a key role in each tier according to the Java EE specification.
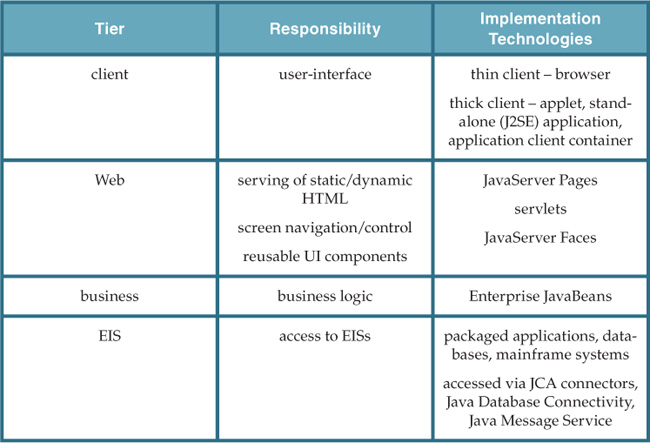
The Java EE platform covers a range of application and runtime architectures, and provides specifications for each of the architectural tiers, components, and implementation technologies. It is entirely possible to build applications using nothing more than the base Java EE platform, such as the Java EE 6 Web Profile platform. Contemporary architectures based on Java EE can diverge from the pure Java EE model in some respects by utilizing frameworks, toolkits, and packages additional to those provided by Java EE.
4.2 Java Distributed Technologies and APIs
The Java language aims to provide built-in capabilities for building distributed applications. As Java has evolved into a complete platform for building distributed enterprise applications, these capabilities have been developed and extended. This section provides an overview of the technologies and APIs of the Java platform, which play an important role in building distributed applications.
Java SE APIs
Before examining the capabilities of the Java EE platform, let’s review some of the important APIs provided by Java SE.
RMI
The Java SE platform offers the ability to communicate with remote Java objects not running within the same JVM in the form of Java Remote Method Invocation (RMI) included in the java.rmi package. RMI allows a Java application running in one JVM (the client) to invoke methods on a Java object running in another (the server), passing parameters as specified on the method signatures.
A number of steps are involved in exposing a Java class for remote communication. First, an interface extending java.rmi.Remote is defined to indicate that the implementation is to be called remotely via RMI. Next, a class that implements the interface and extends the java.rmi.UnicastRemoteObject is written for export via the Java Remote Method Protocol (JRMP). The stub and skeleton classes providing communication between the client and server at runtime are then generated by running rmic, which is the RMI compiler provided with the JDK. Now the stub can be deployed with the client application and the skeleton with the server application. The functionality provided by the Java class can now be accessed remotely via RMI.
Before a client can call methods on an object in the server, the server must create an instance of the object and register it in an RMI registry using a unique name for reference. The RMI registry can run within the server’s JVM or as an external process.
To call a remote object, the client application looks up the reference to the remote object in the RMI registry using its unique name to retrieve the remote interface. The application can then call methods on the remote interface. The Java runtime handles the communications between client and server and the passing of objects as parameters between the client and the server, converting objects to a byte stream for transport via the network (marshaling) at one end and the reverse (unmarshaling) at the other. RMI supports both pass-by-value and pass-by-reference interaction styles. The objects passed must implement the serializable or remote interfaces respectively.
RMI provides a basic remote invocation mechanism. However, RMI does not address non-functional requirements, such as scalability, resilience, transactional integrity, and interoperability with non-Java platforms. Building services using this method is not preferable due to these limitations. RMI can provide the basis for other Java technologies that provide solutions to necessary non-functional requirements.
RMI / IIOP
RMI over IIOP takes the basic model of RMI and attempts to solve the issue of interoperability with non-Java platforms by leveraging the CORBA standards developed by the Object Management Group (OMG). CORBA is based on the approach that object request brokers (ORBs) take to facilitate communication between remote objects and provide basic QoS features, such as the ability to pass transaction and security context.
RMI, as originally developed, uses the JRMP transport protocol restricted to the Java platform. RMI/IIOP allows RMI-based remote calls using CORBA’s IIOP transport protocol, enabling interoperability with CORBA objects running on other platforms. Where cross-platform communication is required, platform-independent interface definitions are specified using CORBA’s Interface Definition Language (IDL). RMI/IIOP facilitates the EJB specification, as discussed later in this chapter.
JNDI
The Java Naming and Directory Interface (JNDI) is an extension to Java SE that provides a standard way of accessing naming and directory services from Java applications. JNDI allows objects to be bound into a hierarchical directory and identified with a name. The name is then used by applications to obtain a reference to the object. The API allows access to a variety of LDAP-based directories as well as CORBA’s COSNaming Service.
All JNDI names exist relative to a context defining where they are stored. When performing a JNDI lookup, an InitialContext object is created, defining the namespace/directory where the lookup will be performed. When a JNDI lookup is performed by a Java EE application running in a container, the environment the application is running in has its own context accessed using the java:comp/env prefix.
Example 4.1 illustrates the retrieval of a Java Database Connectivity (JDBC) data source to establish a connection to a database.
/* set up properties which specify the JNDI provider, security
credentials and other settings required for the lookup */
Properties props = new Properties();
props.put(Context.PROVIDER_URL,"myProviderURL");
// create the initial context
Context ctx = new InitialContext(props);
// name used for lookup
String jndiName = "java:comp/env/jdbc/ds1";
// perform the lookup and cast the retrieved object
DataSource ds = (DataSource)ctx.lookup(jndiName);
// create connection to database
Connection conn = ds.getConnection();
The JNDI is used to locate remote objects exposed using RMI/IIOP and plays an important role in the EJB model. It is also used as a means of retrieving configuration/factory objects in application code.
JDBC
Enterprise applications must generally persist and retrieve data relating to business-relevant entities regardless of the architectural style adopted, and SOA is no exception. In general, relational database management systems (RDBMS) provide the technology for information storage, and the Java Database Connectivity API (JDBC) provides the technology for Java applications to work with the databases.
The JDBC API also provides a standard way of accessing relational databases from Java applications. A JDBC driver deployed on the application server provides connectivity to the database. The JDBC API defines standard interfaces or classes used to execute queries and work with the results returned by the RDBMS. Details of the connection to the database can be kept in a JDBC data source defined at deployment time and retrieved by the application using a JNDI lookup. Environment-specific configuration is left out of application code and instead specified at deployment.
Java EE APIs
The basic distributed computing capabilities provided by Java SE are extended by the Java EE platform, which provides a number of additional APIs. This section provides an overview of the Java EE APIs for distributed applications.
Contexts and Dependency Injection
Contexts and dependency injection build on the dependency injection mechanism introduced in Java EE 5. Dependency injection provides loose coupling. A component implementation can vary independently of the component interface, and a particular implementation for a given interface can be chosen at deployment time without requiring any changes in code. Example 4.1 can be simplified by leveraging the Java EE container’s dependency injection feature as shown in Example 4.2.
...
/* Datasource dependency is injected as a Resource by the container */
@Resource(name="jdbc/ds1")
private javax.sql.DataSource ds;
Connection conn = ds.getConnection();
...
In Java EE 5, only container-managed components, such as EJBs, and Web components, such as servlets and servlet filters, are supported by resource injection. Java EE 6 removed the restriction to allow arbitrary dependencies to be injected like a regular Java object into a component. CDI introduces the concept of managed beans, which can be almost any type of Java class and injected as dependencies in any other object. Java EE 7 provided further enhancements with an incremental release of CDI (CDI 1.1), and makes broader, more extensive use of CDI across the platform.
JTA
Distributed, composition-based solutions must often coordinate the invocation of multiple services within a single atomic unit of work. Java EE provides the Java Transactions API (JTA) as the standard way of handling transactions in a Java EE environment.
JTA provides a means of coordinating transactions involving multiple resource managers. The Java application server acts as a transaction manager, instructing the resource managers to begin, commit, or roll back transactions as required. JTA can achieve distributed two-phase commit across multiple resources controlled by the application server. When the transaction manager is ready to commit the transaction, it tells the resource managers to prepare to commit. The resource managers then respond and, providing no problems and no requests indicate that the transaction be aborted, a commit command is issued. If one or more of the resource managers request that the transaction be aborted, the transaction manager issues a rollback command reversing all of the actions performed within the unit of work.
In addition to allowing programming access to the JTA API to create and control user transactions, the EJB container allows access to define the transactional behavior of components with a deployment descriptor. The transactional behavior required by an operation can be stated, such as if it must be called within the scope of an existing transaction, if a new transaction must be started, or if it must not be called within transactional scope. The container then coordinates transactions based on this configuration, passing transaction context between components as needed.
Employing deployment descriptors with the JTA API has limitations. For example, not all resources provide two-phase commit support, in which case operations involving these resources must be performed outside of transactional scope. If any of these operations fail, compensating operations to reverse the action of the previous operations can be performed. Therefore, a compensation framework is needed to define compensating operations for each of the operations the application performs. The base Java EE platform does not provide a compensation framework, but future sections will explore alternative solutions.
Note
Various XA optimizations can be applied as compensating operations, such as Last Agent Commit, allowing at most one non-XA participant to participate in an XA transaction. In many application servers, the JTA implementations support this and other variants of such optimizations, but a detailed discussion is outside the scope of this book. For details please refer to Java Transaction Processing by Little, Pavlik, Maron et al.
Java EE Connector Architecture
A selection of packaged applications and legacy/bespoke systems can be discovered when examining the IT landscape of any organization. It is possible, and at times preferable, to expose some of the functionality of these systems as services.
The Java EE Connector Architecture provides a standard way for Java EE applications to connect to external EISs. The JCA specification defines how the EIS connects to the Java EE application server through a service interface (SPI). JCA is the base technology for a range of connectors provided by IT vendors, as well as the standard method for integrating JMS providers with the application server.
The specification defines a common way for applications to access an EIS through a common client interface (CCI). The CCI includes a number of interfaces allowing applications to create a connection to the EIS, call functions provided by the EIS, and manipulate the results. The interfaces and programming model of the Java EE Connector Architecture follow a similar approach to other Java APIs, such as JDBC and JMS, which will seem familiar to those who have used these APIs.
EJB
Enterprise JavaBeans (EJBs) are the Java EE components implementing application logic in the business tier of the Java EE model. Java EE 5 introduced EJB 3.0, which included some significant changes from EJB 2.1, the previous version of the specification. EJB 3.0 simplifies EJB programming, resulting in significant changes to the programming model.
The pre-EJB 3.0 versions were less user-friendly, and writing a single EJB required working with three artifacts: a component interface, a home interface, and a bean implementation class. The default choices also forced a remote programming model even with no requirements for remote communication, which resulted in unnecessary performance overhead and increased deployment complexity.
With EJB 3.0, local EJBs became the default. The old home-and-component interface views were dispensed with, and the standard deployment descriptor settings for container-value added services around transactions and security, which were captured in Java code-based annotations. However, EJBs still had to be packaged as separate EJB .jar files, which did not address the deployment complexity. EJB 3.1 and Java EE 6 resolved the deployment complexity with the .war-style packaging of EJBs, which simplified using EJB references in a Web application by distributing the artifacts as part of a packaged .war file. Java EE 7 released an update to the EJB specifications with EJB 3.2.
Session EJBs
Session EJBs provide the implementation of business logic in the Java EE model. Capable of implementing the methods of a business component interface, session EJBs employ instance variables. A bean designed for instance variables required for the lifetime of a single invocation can be implemented as a stateless session bean. However, a stateful session bean is necessary if the design requires conversational state to be maintained across a sequence of invocations.
Using stateful session beans comes at the cost of additional complexity, as the server must store the state at the end of each invocation and ensure availability for subsequent invocations in a conversation. In a clustered environment, the state must be shared across multiple servers, or for server affinity to be honored by the application server, routing all of the invocations that comprise a conversation to the same server.
Stateless session beans are intended to be short-lived objects created as required and destroyed after processing an individual client request. In contrast stateful session beans are used when a client session has completed. For performance reasons, an application server might reuse session bean instances, retrieving them from a pool and returning them when a client has finished with the bean instance. This is opaque to the client. All bean instances are identical and it makes no difference whether a bean instance has been newly created or previously used.
Consider the following guidelines in support of SOA:
• As per the Service Statelessness principle, stateless logic can be implemented using stateless session EJBs to avoid some of the complexities of stateful session EJBs.
• As per the Service Abstraction principle, fine-grained interfaces should be avoided. It is possible to expose methods that accept all of the parameters required to perform some operations as a single set, which means the input and output parameters will be complex structures or objects.
• Services should favor pass-by-value rather than pass-by-reference invocation style, which fits with the EJB model of marshaling/unmarshaling parameters.
Persistence Entities
EJB 3.0 introduced the Java Persistence API, which allows developers to model regular POJOs as lightweight persistent domain objects. The JPA runtime provides applications with a means of accessing data in persistent storage, exposing an object-oriented view of the data. Considering the capabilities offered by a typical database, the JPA provides applications with the ability to read and write data via transactions, map to a data model, and maintain integrity by enforcing constraints defined as part of the database schema.
Like any regular Java object, a persistent entity can encapsulate behavior (methods) and attributes (instance variables). As the Java application works with data by calling methods on persistence entities, the JPA runtime must translate these into calls to the underlying data store. When the data store is a typical relational database, these translated calls take the form of SQL queries that are executed against the database via JDBC. The instance variables of the entity must reflect the data in the data store. Where a relational database is used, think in terms of mapping the persistence entity’s attributes (object instance variable) to columns in one or several data tables. The JPA runtime performs the object, such as relational mapping between Java objects and database tables.
Note
JPA evolved from the popular Hibernate persistence framework.
From the perspective of a Java application, persistent entities should be viewed as long-lived persistent objects. When creating an entity or changing some of its attributes, the changes are persisted to the underlying database once the transaction has committed.
EJB 3.0 introduced changes to the EJB programming model, such as annotations and persistence. Annotations are a tag, indicated with an @ prefix, which can be included in Java code to change the way the code is handled by compilers or toolkits.
A familiar example to most Java developers is the @deprecated annotation picked up during the Javadoc generation to indicate that a class should no longer be used. While Java 5.0 provides the ability to define unique annotations, EJB 3.0 defines some annotations with specific meaning to reduce creating excess boilerplate code when implementing an EJB. Annotations are used instead of implementing the relatively complex interfaces required by previous EJB specifications and as a simpler mechanism to indicate the developer’s intent. As seen in Example 4.3, the @Stateless annotation can be used to implement a stateless session bean in EJB 3.0.
@Stateless
public class HelloWorldBean
public String helloWorld(String name)
{
return ("hello "+name);
}
}
By using the @Stateless annotation, implementing a component interface is unnecessary as was required in previous versions of EJB. Now clients can retrieve a bean instance via a JNDI lookup of the business interface directly or by dependency injection using an @EJB annotation.
EJB 3.0 also changed the way persistent entities are developed, using annotations to remove the requirement to implement interfaces. In JPA, an @Entity annotation indicates that a Java class is a persistent entity, and additional attributes indicate the mapping of attributes to columns in the database. Clients can look up persistent entities by leveraging the JPA EntityManager APIs. The EntityManager class is used to create and remove persistent entity instances, to find entities by their primary key, and to query over entities. A persistent entity is looked up by calling a method on an EntityManager in Example 4.4.
@PersistenceContext
EntityManager em;
Account acc = em.find(Account.class, accountId);
Service-Orientation Principles and the EJB Model
Consider the following guidelines in support of service-orientation:
• As per the Service Façade pattern, session EJBs should act as a coarse-grained service façade, and operations on the session EJB should generally reflect meaningful business use cases, such as looking up a customer’s account information.
• As per the Service Statelessness principle, services should be modeled with stateless session EJBs. Each independent service operation should have a self-contained, complete transaction boundary, and a stateless session EJB operation can enforce appropriate transactional demarcation.
To illustrate this point, consider Example 4.5. An entity is implemented to represent a customer. This customer entity has a number of attributes, which are modeled as instance variables with getters and setters.
Integer customerNumber (primary key)
String firstname
String lastname
String title
String sex
String maritalStatus
java.util.Date birthdate
Suppose Mary Smith calls to change her marital status from Miss to Mrs. With her customer number, the solution must perform the following steps:
1. Find Mary Smith’s details.
2. Change her marital status.
3. Change her title.
Note the problems with carrying Steps 2 and 3 as separate service invocations. First, a stateful interaction is evident in Steps 2 and 3, which include the word “her”, implying that a conversation between service consumer and service ensues. Second, multiple calls made to update each of the changing attributes indicate a fine-grained, API-like interaction.
The Service Abstraction principle states that fine-grained interfaces should be avoided, a requirement met with Java EE and JPA. A stateless session EJB can be built to expose a service operation named updateCustomer (Customer), which takes an updated customer domain entity.
In contrast with previous versions of J2EE, entity beans and their wrapper data transfer objects can work directly with JPA entities and even detach them from a persistence context. In this case, after a customer entity is looked up through another service operation, such as lookupCustomer (customerId), a detached customer entity is received that can then be modified and passed back to the updateCustomer operation. However, for more complex use cases, the use of wrapper data transfer objects can still be preferable to offer a selective view of a complex entity or even avoid exposing the underlying data model details to the service consumers.
JMS
The Java Message Service (JMS) specification defines a set of interfaces that Java applications can use to connect to enterprise messaging systems with asynchronous messaging-based interactions. The messaging system is known as a JMS provider, and delivering one as part of every Java EE application server is mandatory. JMS interfaces are also provided by a number of independent messaging systems, such as IBM’s Web-Sphere MQ.
JMS defines two different styles of messaging known within the specification as messaging domains. These define point-to-point and publish/subscribe models. The point-to-point model is based on the exchange of messages via queues. Sending applications or message producers connect to the messaging provider to create a JMS message and call send() to send the message to the JMS queue. We’ll refer to these applications as “message producers” for the remainder of this book. Either the receiving application or message consumer can poll for messages arriving at a queue. Alternatively, a listener can be created to call user code when a message arrives at the queue, which is similar to the model used by MDBs.
JMS queue objects encapsulate the configuration parameters for a connection to a physical queue provided by the JMS provider, which acts as a route into the distributed messaging infrastructure defined within the JMS provider. Messages being forwarded to a physical queue are defined on a separate server or within a separate heterogeneous messaging infrastructure via a bridge.
The publish/subscribe model involves JMS applications registering subscriptions on particular topics represented by JMS topic destinations. Message consumers register an interest in messages on a particular topic by calling subscribe() on a JMS topic destination. When messages are published on this topic, performed by calling publish() on the corresponding JMS topic destination, each subscriber receives a copy of the message. Requests by applications to subscribe or publish a message to a topic are processed by the JMS provider’s pub-sub broker. The broker is responsible for maintaining a record of subscribers to each topic and sending each publication to the appropriate subscribers.
The publish/subscribe model is well suited to situations where messages must be sent to multiple receiving applications, and/or when frequent changes to the mapping between messaging producers and messaging consumers occur. Configuration changes and having the message producer maintain knowledge of the destinations to which messages must be sent is unnecessary with the publish/subscribe model.
JMS provides for different messaging qualities of service, such as through persistent and non-persistent messages, durable and non-durable subscriptions, and by offering different options for reliable messaging. JMS can ensure messages are passed from JMS provider to application using either a transactional approach where the service supports reliable messaging or acknowledgement from the service consumer to the service.
The JMS model allows for a variety of payloads to be carried within a JMS message, each represented by a Java class inherited from javax.jms.Message. The JMS message types supported include:
• TextMessage string data
• BytesMessage binary data
• ObjectMessage a Java object (which must implement Serializable)
• MapMessage name-value pairs of primitive types identified by a String name
• StreamMessage a stream of primitive types
In addition to the message body, JMS messages also include headers carrying information beyond application data. The JMS specification defines a number of standard headers and allows user-defined headers to be included.
Beyond defining the capabilities that a messaging product must provide, the JMS specification defines the interface between the messaging provider and the Java applications. Therefore, JMS providers are not often interoperable and two heterogeneous JMS providers may not be able to be linked together. Where a messaging product supporting multiple platforms is used, JMS can provide a convenient and robust way of connecting Java applications to other non-Java systems.
Java EE 7 introduced enhancements in the revised version of the JMS specifications (release 2.0) focusing on a simplified programming model, resulting in significantly fewer lines of code required for common application tasks, such as enqueuing/dequeuing messages.
Message-Driven Beans
A message-driven bean is another type of EJB providing a means of exposing application logic with a JMS interface by allowing MDBs to consume messages from a JMS destination. When a message arrives at a JMS destination, the MDB container delivers the message to an MDB instance. Developing an MDB is done by implementing the javax.jms.MessageListener interface and invoking its onMessage(javax.jms.Message) method. The onMessage method triggers when the message delivers to the MDB.
The MDB should extract the required parameters from the JMS message and call appropriate business logic implemented in a session bean to perform the required application logic. Where supported by the JMS provider, this can be performed within the transactional scope provided by JTA so that the message can be backed out onto the JMS destination in the event of a failure.
Security in Java EE
Service functionality should be exposed for reuse in a location-transparent and platform-independent fashion. Services must often create restricted access to only authorized service consumers. Security is of critical importance in any SOA, and Java EE provides a framework for securing Java EE components that can be leveraged when implementing services in Java EE.
Java EE provides a flexible approach to security through the Java Authentication and Authorization Service (JAAS). Resources within a Java EE application can be secured declaratively. The roles authorized to access a resource are defined in deployment descriptors. The Java EE runtime is responsible for authenticating callers and checking authorization. The granularity of Java EE security extends to individual Web resources or methods on an EJB. The application developer does not need to address security concerns through application programming. Additional work, such as restricting access to individual entity instances, is needed if greater granularity is required.
Different methods of authentication, such as basic user id, password, or certificates, are supported with pluggable authentication modules (PAMs) that the runtime is configured to use. Authorization is based on roles mapped at deployment time to users or groups defined in a user registry. Java EE provides support for different user registries used to store information, such as passwords and membership of security groups. Using an LDAP directory is a popular approach to provide a flexible and standards-compliant way of modeling complex organizational structures and associated authentication and authorization information.
Java EE provides control over the identity under which application components delegate, which is used for authenticating to external systems. In the case where Java EE server components access external systems requiring authentication, a level of indirection is provided between the application components and the external system with a JAAS authentication alias. Resources, such as data sources, are bound to an authentication alias, and the user id and password for the alias are defined at deployment time.
4.3 XML Standards and Java APIs
This section provides brief overviews of key XML-based standards and Java APIs relevant to this book.
XML
The Extensible Markup Language, or XML, provides a way of representing structured data in a text-based format, which includes not only a neutral data format for messages but also standards for describing message structures. As well as being one of the fundamental technologies on which Web services standards are based, XML is widely supported across numerous platforms and languages. Many industry-standard messaging formats are based on XML. For these reasons, XML is preferred to pass messages between services.
Before reviewing the Java APIs used in Java EE to work with XML messages, let’s review the basics of the XML standard in Example 4.6 that illustrates how customer name and address details might be specified in XML. All XML instance documents begin with a definition.
<?xml version="1.0" encoding="UTF-8"?>
<customer:CustomerDetails xmlns="http://www.example.org/customer"
xmlns:customer="http://www.example.org/customer"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.example.org/Customer.xsd">
<Name>
<Firstname>John</Firstname>
<Surname>Doe</Surname>
</Name>
<Address addresstype="shipping">
<Line1>1234 High St</Line1>
<Line2>Burnaberry</Line2>
<City>New York</City>
<State>New York</State>
<ZipCode>78930</ZipCode>
</Address>
</customer:CustomerDetails>
The declaration indicates that what follows is an XML document and specifies the encoding style used. UTF-8 is an encoding for Unicode characters commonly used for XML documents. The rest of the document consists of elements and attributes, which represent the data. CustomerDetails is the root element of the XML document shown.
Each element has a type, which can be either simple, such as a string or integer, or complex, such as a structure consisting of a number of nested elements each with its own type. Attributes, such as the addresstype attribute of Address, apply to the element on which they are specified and are always of a simple type. Both elements and attributes can be qualified by a namespace defined as a URI to avoid naming collisions between XML types defined by different organizations.
In Example 4.7, the namespace declaration:
xmlns:customer="http://www.example.org/customerdetails"
...associates a shorthand identifier prefix customer with the namespace http://www.example.org/customerdetails. The CustomerDetails element of this document has been namespace-qualified by prefixing it with customer.
xmlns="http://www.example.org/customer"
...on the CustomerDetails element defines a default namespace for all of the children of CustomerDetails. Unless child elements are explicitly namespace-qualified, they are assumed to belong to the default namespace.
Although a URI is used to identify namespaces, which commonly begin with an http:// prefix, resources do not need to be available at the URI. The URI is used as an identifier, and basing the URI on an organization’s registered domain name provides a way of ensuring uniqueness following a similar convention to that used for naming Java packages.
XML Schema Definition
The XML specification includes certain rules that XML documents must follow, such as all opening tags requiring a closing tag. A document following these rules is considered well formed, and can be successfully parsed by any XML parser. XML schemas are used to specify additional constraints on the structure of an XML document based on the data represented. The schema defines, for example, the names of elements and attributes that can be included in an instance document, the order they appear in, and their possible values. A document is said to be valid if it conforms to the rules specified in its associated schema.
XML schemas themselves are specified as XML documents. The schema describing the CustomerDetails document is shown in Example 4.7.
<?xml version="1.0" encoding="UTF-8"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/customer"
xmlns="http://www.example.org/customer">
<xsd:element name="State" type="xsd:string" />
<xsd:element name="Line1" type="xsd:string" />
<xsd:element name="Line2" type="xsd:string" />
<xsd:element name="Surname" type="xsd:string" />
<xsd:element name="ZipCode" type="xsd:string" />
<xsd:element name="CustomerDetails">
<xsd:complexType>
<xsd:sequence>
<xsd:element ref="Name" />
<xsd:element ref="Address" />
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:element name="Address">
<xsd:complexType>
<xsd:sequence>
<xsd:element ref="Line1" />
<xsd:element ref="Line2" />
<xsd:element ref="City" />
<xsd:element ref="State" />
<xsd:element ref="ZipCode" />
</xsd:sequence>
<xsd:attribute name="addresstype" type="xsd:string" />
</xsd:complexType>
</xsd:element>
<xsd:element name="Firstname" type="xsd:string" />
<xsd:element name="City" type="xsd:string" />
<xsd:element name="Name">
<xsd:complexType>
<xsd:sequence>
<xsd:element ref="Firstname" />
<xsd:element ref="Surname" />
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>
XML documents are processed by a parser, which applies the constraints defined in the XML specification itself to verify if an XML instance document is well formed. If the parser is a validating parser, the XML Schema is used to determine if the XML instance is valid as well as well formed. One validating, namespace-aware parser popular in Java circles is Xerces, an open-source project run by Apache.
Note
Prior to the emergence of XML schemas, the structure of XML documents was specified using XML DTDs. DTDs have been superseded by schemas providing a more flexible and powerful syntax for defining document structures.
XSLT
The Extensible Stylesheet Language Transformations (XSLT) standard provides a means of transforming XML documents to other formats. Transforming an XML document to HTML to be rendered in a browser with appropriate formatting is a common example. For example, an XML document can be transformed to HTML to be rendered in a browser with appropriate formatting. To refer to different parts of an XML document, XSLT uses the XPath standard to define syntax for expressions referencing the different parts of an XML document.
The XSLT standard has several robust implementations, such as Saxon and Xalan, which provide a well-understood and widely used mechanism for specifying XML transformations.
JAXP
The Java API for XML Processing (JAXP) provides a means of working with XML documents programmatically in Java independent of the XML parser or processor being used. Historically there were two different types of XML parser, SAX and DOM, each of which associated with a different programming model.
Simple API for XML (SAX) is an event-driven model. As an XML document is parsed, the parser invokes callback methods with user-provided implementations as each element or attribute is encountered. The application is sent the details of the XML, which include structure and data, and must decide what action to take as each part of the XML document is traversed by the parser.
SAX is stateless, and the application must keep track of the parser’s current location within a document to cache any information from the XML data needed to process business logic. SAX is based on a push model in which documents are parsed in their entirety even if only part of the data is required by the application.
Document Object Model (DOM) parsers convert the entire XML document to an in-memory representation. The object representing the XML document allows applications to navigate the structure and retrieve the values of different elements and attributes.
JAXP provides support for both SAX and DOM parsers and allows XSLT transformations to be performed on XML documents. The interfaces provided can be used to access the underlying parser without using any implementation-specific APIs.
StAX provides a pull parser based on the Sun JSR 173 specification that is used in Java Web services technologies discussed in Chapter 5. The application and not the parser is in control of what part of the XML document is sent to it, as is the case for SAX. This has significant performance advantages over the memory-intensive DOM and SAX. StAX provides a pull parser that is based on the Sun JSR173 specification and used in some of the recent Java Web Services technologies discussed later in Chapter 5.
JAXB
Manipulating XML documents with JAXP can be labor-intensive due to the complexity of the SAX and DOM APIs. The Java API for XML Binding (JAXB) is intended to provide a simpler way to work with XML by building Java classes based on the XML schemas associated with the XML document.
JAXB manages marshaling and unmarshaling between an XML document and Java objects. Default bindings are included for each of the data types defined within the XML Schema specification, although JAXB does allow these to be customized if required. Rather than working with XML APIs, the developer can ignore the conversion to and from XML documents and can focus on the generated Java objects.
4.4 Building Services with Java Components
The following section explores how services can be implemented as components using Java EE APIs and technologies. Service layers can be implemented to build services as components within each of the three distinct service layers, using the technologies and APIs available in the Java EE model.
Components as Services
Various Java technologies can be used to build different types of services. In many instances, these technologies solve problems in areas such as orchestration, and, therefore, have relevance to certain service layers.
Java EE distributed technologies can be used to implement services in the various layers without utilizing any additional technologies, such as Web services, additional frameworks, or toolkits. Technologies introduced later in this book can help solve shortcomings or compromises highlighted in this section.
Application Protocols
There are several common approaches to remove invocation with Java. The first approach is to use RMI in the case of POJOs or RMI/IIOP in the case of EJBs. In practice, choosing to expose POJOs using RMI offers limited quality of service. However, exposing EJBs using RMI/IIOP is a robust approach, which also offers the option of interoperability with CORBA objects.
The second approach is to provide a JMS interface, JMS is not an application protocol like HTTP, but a Java-based abstraction API over proprietary messaging engine protocols. Regardless, use of the basic JMS features of Java EE provides a basic functional implementation without a high quality of service.
With this model, the application would create a JMS MessageConsumer bound to a JMS destination and either call its receive() method to check for messages, or register a MessageListener that has its onMessage triggered when a message is received. In the Java EE model, the service would be exposed with a MDB bound to a destination.
After providing the implementation of the MDB’s onMessage(javax.jms.Message) method, the application server’s EJB container is responsible for calling when a message arrives.
On receipt of a message, the JMS wrapper or façade carries out the following steps:
1. Extract the contents of the JMS Message.
2. Call the service implementation (POJO or EJB) with the required input parameters.
No further steps are required for a one-way interface.
In the Java EE model, implement a servlet to provide an implementation of the doGet() and/or doPost() methods depending on which of the HTTP GET or POST methods are used.
The final approach is to expose the services using HTTP. The client will issue an HTTP request with the input message for the service and wait for the HTTP response containing the output message. On the server-side, implementing a HTTP façade is needed to receive the request and call the POJO or EJB implementation, passing it the parameters extracted from the request. For a one-way interaction, an empty response will be returned as the HTTP protocol requires.
For a request/response interaction, a response message must be constructed based on the return parameters of the POJO or EJB service implementation and returned to the waiting client as an HTTP response. In the Java EE model, implement a servlet to provide an implementation of the doGet() and/or doPost() methods depending on which of the HTTP GET or POST methods is used.
Each of these application protocols or APIs, such as JMS, has different characteristics that influence the decision on which to use when exposing service interfaces. Table 4.2 summarizes some of the key differences.

Before continuing, let’s expand on the interoperability of the application protocols. First, consider RMI/IIOP, which provides interoperability with other CORBA implementations. In practice, achieving this interoperability has proven challenging due to the need to cope with the different ways CORBA providers handle security and transactions.
EJB interoperability when using RMI/IIOP between different Java EE implementations has also proven to be a source of challenges for similar reasons. Although progress has been made in this area during the lifetime of the Java EE/J2EE versions, EJBs/clients deployed in two arbitrary Java EE providers may not always interoperate.
Looking to JMS, the degree of interoperability achieved depends on the JMS provider. Configuring external services allows communication via JMS between applications running on application servers provided by different vendors. Some messaging providers, like IBM’s WebSphere MQ, provide support for additional non-Java platforms accessed using APIs other than JMS. Using these messaging providers allows interoperability with Microsoft .NET applications and other Java implementations and applications running on non-Java platforms, provided the JMS messages use an appropriate format.
Service Contracts
The service contract must define the operations offered by the service, the input and output messages of each operation, the data types that are used in the messages, and the location of the service endpoint. A service contract can also provide additional information to a potential service consumer to judge the suitability and use of the service. These aspects are largely satisfied today with documentation written by, and intended for consumption by, humans rather than machines.
SOAP-based Web services provide a standard way of describing service operations, locations (using WSDL), and messages (SOAP). Alternatively, REST services can have the uniform interface treated as the contract or text-based special contracts, such as WADL (Web Application Description Language), in which resource representations, resource relationships, and applicable HTTP verbs for given service operations are captured in the contract.
The three aspects of the service contract are location, operations, messages, and service data representations, when building services from Java/Java EE components.
Location
The standard way of describing the location of any Web-addressable resource is with a URI to specify the endpoint address for services exposed using any of the protocols discussed. When EJBs are exposed using RMI/IIOP, the CDI mechanism in Java EE and JNDI names facilitate obtaining a handle to the EJBs.
With a JMS interface, the service consumer must be provided with a means of sending messages to the destination to which the service is bound. Where the service consumer is a JMS client, achieve this by binding JMS-administered objects into a directory that the client retrieves with a JNDI lookup similar to retrieving an EJB home. If using JMS as a means of interoperating with non-Java clients by using a JMS provider supporting additional platforms, the details required by the client depend on the messaging product used. It is possible to specify JMS locations using URI syntax, but standards are lacking in this area and defining custom standards limits interoperability with implementations outside of direct control.
With an HTTP interface, specifying the URI of the servlet in the familiar form http://my.host.name:<port>/context/SomeService is necessary.
Operations
Following the object-oriented paradigm and features available in the Java language, the operations on the service are methods of Java classes. With a Java interface, describe the methods of the class and the input and output parameters. Where a service exposes an RMI/IIOP interface, each method of the bean implementation class is defined on the business interface of the EJB.
There is no standard way of exposing multiple operations on the JMS interface where a POJO or EJB via JMS is exposed. It is possible to create a separate destination for each operation with the JMS façade invoking the appropriate Java method based on the destination a message is received. Alternatively, use a single destination for all operations of the service, and include in the service interface a requirement that the service consumer specifies which operation it wishes to invoke in a user-defined JMS header or within the message body. The façade then extracts this property and invokes the appropriate Java method.
For HTTP, it is possible to specify the service and operation at the end of the URI. A Web container can be configured for requests to be routed to a servlet, which extracts the operation name from the URI and invokes the appropriate method on the POJO or EJB.
Messages
The final part of a service contract is a description of the messages supported by each service operation. The implementation of service components as POJOs or EJBs, with operations implemented as Java methods, means that the input or output parameters of the service component are Java objects or primitives. However, the format of data in these messages will depend on how the service is exposed.
When an EJB is exposed directly using RMI/IIOP, the messages act as a conduit of primitive types or, as is more common, serialized Java objects. Alternatively, passing XML data as a Java String type, parsing the XML, and generating objects within the bean, a utility class, or façade is possible.
A range of choices remains in terms of how data is carried in the JMS messages when an API, such as JMS, is used to expose a service. Data can be transmitted in primitive forms, such as strings, streams of primitive types, raw bytes, name-value pairs, or serializable Java objects.
Where services are exposed using HTTP, different media types can be used to specify the type of data being transmitted. However, over the wire the data is shipped as a string or, in the case of attachments potentially containing binary data, MIME multipart messages. There is no standard way of mapping the media types to Java objects, but the benefits of using XML to represent the payload include the ability to:
• describe the message format in a machine-readable way using an XML schema
• use XML utility toolkits available for popular platforms and helpful in achieving interoperability with non-Java applications
• easily pass the messages in HTTP requests/responses because XML is a text-based format
For efficient representation of binary payloads, leveraging standards, such as XML Optimized Packaging (XOP) or Message Transmission Optimization Mechanism (MTOM), to capture embedded binary data in XML messages is possible. Both of these techniques are further described in Part II.
Further Considerations
Exposing services implemented as Java components can be archived with RMI/IIOP, JMS, and HTTP. In each of these cases, various options are available for describing the service location, operations, and messages.
In the case of RMI/IIOP, the Java EE specifications provide a standard way of specifying these aspects of the service contract in the form of an EJB home or business interface. However, in order to enable a client to access an EJB, the classes required to call the EJB must be provided including generated stubs and any utility classes, such as DTOs. This tightly couples the service consumer or EJB client and service. Any changes made to the EJB’s home or remote interface will generally result in having to distribute a new client JAR to service consumers.
However, in the case of JMS and HTTP, no standard way of describing the service contract exists. Custom standards must be defined, diminishing the ability to achieve interoperability with systems which have not followed the same standards, and likely resulting in a different standard for each protocol or transport.
Components as Services and Service-Orientation
Having reviewed the available options for implementing services using basic Java EE technologies, let’s consider how effectively some of the service-orientation principles can be met when implementing services as Java components.
Standardized Service Contract
A service contract needs to specify the aspects of location, operations, and messages. Where services are implemented with EJBs and exposed with RMI/IIOP interfaces, these three aspects are covered by the artifacts that are created for the EJB specification. In the case of HTTP and JMS, custom specifications must be defined for the service contract. The lack of a standard service contract for JMS and HTTP services (as implemented by servlets) is inconvenient, as is the fact that no single standard covers all three of the protocols.
Service Loose Coupling
In the case of EJBs and RMI/IIOP, the service consumer requires a number of specific classes for each EJB it wishes to call. These are generally delivered as an EJB client JAR containing the required classes that must be available at the time of compilation.
Making even a slight change to the EJB business interface will often break any service consumers and require recompilation, which indicates a tightly coupled implementation. However, this represents a contract-to-platform coupling because the service and the service consumer must be implemented on a common technology platform, notwithstanding the interoperability scenario between EJB services and CORBA/IIOP consumers.
In the case of JMS, the service consumer and service are loosely coupled by definitions of message structures and JMS destinations. The implementation technology of the service can change without affecting the service consumer, provided the messaging-based interface remains unchanged. Changes to the interface can also be made, provided backward compatibility with existing service consumers has been ensured, such as by adding operations or optional parameters to an operation. Supporting backward compatibility introduces a degree of technology coupling as the message structures are linked to JMS message types and the destinations are JMS-administered objects.
A loosely coupled implementation also holds true in the case of HTTP, as a location (URI) and message format provide a reasonable level of flexibility in the possibility of making changes without affecting existing service consumers. However, use of HTTP does minimize the extent of platform and technology coupling compared with the options of using RMI/IIOP or JMS.
Service Abstraction
Service abstraction is determined in how the compilation is maintained while hiding the implementation details of a service. In the case of EJBs and RMI/IIOP, the interface indicates that the implementation is an EJB, although the implementation details are hidden behind the EJB remote interface. The EJB could be acting as a façade to any number of additional EJBs, Java classes, or external systems integrated using JCA, JDBC, or one of the other APIs provided by Java EE.
The same is true of JMS and HTTP interfaces, with the additional advantage that similar interfaces could be exposed with a non-Java implementation in the case where a message-oriented middleware (MOM) product with multi-platform support is used as a JMS provider.
Service Discoverability
For services to be discoverable, they must be described by service contracts available within a registry accessible to potential service consumers. The issues of service description and limitations imposed by the lack of widely supported standards have already been reviewed. JNDI comes closest to providing a service registry. However, this is far from an ideal solution due to a lack of interoperability and a number of other limitations.
Ideally, a service directory should include definitions of all of the services within an organization, whereas JNDI usually provides access to a namespace with the scope of a single server or a small administrative grouping of servers. For technical and organizational reasons, deploying a single enterprise-wide group of servers under common administration sharing a single namespace is not usually viable. Typically, a number of distinct, disconnected islands of servers under the control of different groups within an organization are found. If each has its own namespace, this means that multiple JNDI lookups must be performed against different naming servers with knowledge of their location/URI.
4.5 Java Vendor Platforms
This section provides an overview of some of the most popular Java EE application servers, including the open-source GlassFish application server and the commercial offerings from IBM and Oracle. As much of the functionality is dictated by the Java EE specifications, we focus on those areas differentiating the products paying particular attention to resilience, scalability, and administration.
GlassFish Enterprise Server
GlassFish is the reference implementation of Java EE and one of the first application servers to offer a fully compliant Java EE 7 implementation. The GlassFish Open Source Server v4 is built on a modular, flexible runtime that also allows developers to build applications targeted only at a subset of the entire Java EE platform, such as the Web container. The Java EE Web Profile implementation in GlassFish v3 and v4 can be leveraged to build lightweight Web applications without requiring the full Java EE infrastructure.
However, enterprise class applications that must harness the power of advanced Java EE standards including EJB, JMS, legacy system connectivity via JCA, and various XML and Web services-related APIs, such as JAXB and JAX-WS, require the full enterprise version of GlassFish.
GlassFish configuration involves the concept of a domain, which is a logical collection of application server instances treated as one administrative unit. A Domain Administration Server (DAS), also known as the default server, is the central point of control for a single domain and all changes to the domain configuration are made through a Web-based administration console, a Web application deployed out of the box on the DAS itself.
The console also offers runtime monitoring facilities, which can be used by developers to troubleshoot problems. For administering, managing, and monitoring applications running in production, a setup through a command line interface (asadmin) is also offered which lends itself to scripting.
In a production setup, deploying applications on a separate set of instances controlled by the DAS is recommended. However, deploying applications on the DAS itself is sufficient for development purposes.
GlassFish 4 comes pre-installed with a messaging engine, an open-source JMS 2.0-compliant implementation named OpenMQ. GlassFish offers several deployment options for the messaging engine, including an embedded mode in which the messaging engine (message broker) runs embedded inside the application server JVM, a local mode in which the message broker process is started as a separate JVM by the application server itself, and a remote mode in which a standalone broker runs as an external process that an application server can connect to on startup.
GlassFish comes pre-installed with Project Metro, the runtime stack for the implementation of the basic and advanced SOAP-based Web services standards and associated Java Web service-related APIs, such as JAX-WS. Apart from helping developers build basic Web service applications around SOAP and WSDL, Metro also offers support for adding qualities of service to Web services in the areas of reliability, security, transactions, and policy, in compliance with the implementation of the relevant WS-* standards.
GlassFish 4 bundles another popular open-source project named Jersey, which is an implementation of the Java API for RESTful services (JAX-RS 2.0) specifications.
GlassFish is well supported by popular development IDEs, such as Eclipse and Net-Beans. Both of these IDEs allow starting and stopping GlassFish default server, deploying and un-deploying applications, and debugging applications running in the GlassFish server.
IBM WebSphere Application Server
IBM’s WebSphere brand includes a number of Java-based middleware products with WebSphere Application Server (WAS) at its core. WAS is a Java EE application server available for distributed (Linux, Unix, and Windows) and mainframe (IBM zSeries and iSeries) platforms. The 8.5.5 release provides support for Java SE 7 in addition. The codebase is common across platforms, with some differences allowing platform-specific capabilities to be utilized by the application server particularly on the mainframe.
WAS is available in various editions from an entry-level Express Edition intended for small scale use on a single server, a Network Deployment Edition allowing vertical and horizontal scaling across multiple application servers and nodes with high availability features for mission-critical applications, to a Hypervisor Edition designed to run on virtualized infrastructures important for cloud-based environments. The Liberty Profile of the WebSphere Application Server is a lightweight profile intended for Web, mobile, and OSGi applications. The Liberty Profile has a small footprint, fast startup time, and is compliant with the Java EE 6 Web Profile with the 8.5.5 release.
Additionally, WebSphere Application Server for Developers is a fully featured version of the product available for use in an application development environment free of charge, with optional chargeable support offered.
WebSphere Application Server’s Naming Service is based on CORBA CosNaming, providing a distributed implementation that allows objects within a single logical cell-wide federated namespace to be looked up using the name server included with any application server within the cell. Objects can be bound into the namespace with cell, node, or server scope, which defines their visibility to applications performing JNDI lookups.
The application server supports a number of JMS providers, including a Java-based messaging infrastructure called WebSphere Default Messaging Provider. This is a high-performance messaging solution intended for production usage. It can be horizontally scaled and configured for high availability, so that messaging engines can failover to an alternative server with the contents of queues accessible. The JMS provider provides five qualities of service for messages, from best effort to assured persistent.
In order to utilize the scalability and availability features of Network Deployment Edition, servers are grouped together as part of an administrative cell, a group of nodes (physical servers) under the common control of a deployment manager. Each node can host one or more servers (J2EE application servers running in their own JVMs), with the configuration of servers in the cell controlled via the deployment manager through its Web WAS-CE is an open-source product administrative console or via a scripting interface.
All of the administrative tasks required to configure application servers and deploy/manage applications can be performed under centralized control using the deployment manager. Flat files are used as a configuration repository, with the configuration specified as XML.
Individual servers within a cell can be grouped together in clusters, and deploying an application to a cluster allows workload to be shared between the servers (horizontal scaling). As well as scalability, clustering provides high availability for applications. An HA manager monitors resources within the application server environment, which can be configured to failover to alternative servers within a core group. This allows high availability to be achieved without the need for external HA products.
Horizontal scaling across multiple server instances can be achieved in a relatively straightforward manner for the application protocols or the abstraction APIs (HTTP, RMI/IIOP, or JMS).
In the case of HTTP, plugins are provided for a number of popular HTTP servers, allowing HTTP requests to be load balanced across a possibly clustered Web container of multiple application servers. The plugin is a Java-based filter or module that the HTTP server calls each time a request is received, passing it the URI of the resource requested.
The plugin checks to see if the request should be forwarded to an application server or left for the HTTP server to handle based on an XML configuration file generated by the deployment manager. The plugin configuration includes details of clustered servers with load-balancing policies configured, such as for simple round robin-style load balancing, or with configurable server weights to allow for scenarios where servers have unequal capacity. Should a server fail, the plugin detects the failure and stops attempting to send requests until the server has restarted. Included with the WebSphere Application Server is the IBM HTTP Server based on the Apache HTTP Server.
EJB load balancing is performed by the object request broker (ORB), and the behavior is determined by a policy configured by the application deployer. Again, round robin load balancing is the default, with optional configurable server weights. Server failures are detected and requests will not be sent to a failed server. As EJBs commonly call one another, the load-balancing behavior can be configured to “prefer-local” instances, avoiding the overhead of making a call to a remote server where possible.
JMS load balancing is achieved for incoming requests by deploying MDBs in multiple clustered application servers and binding them to a single common destination used for inbound requests. In this case, the distribution of workload between servers is determined by the rate at which each server pulls messages from the destination. Unlike the “push” model used with HTTP and EJBs using RMI/IIOP, where the proportion of the workload sent to each server is set administratively, JMS uses a “pull” model and the workload distribution is dependent on the performance of each application server and the number of MDB instances running within.
Application development tooling for the WebSphere product set is based on the popular open-source Eclipse IDE. WebSphere Developer Tools for Eclipse (WDT) is an Eclipse plugin available for free download from the Eclipse Marketplace. It provides a core set of tools for developing JEE applications for the WebSphere Application Server. Alternatively, Rational Application Developer for WebSphere Software (RAD for WebSphere) can be purchased as an integrated development environment based on the Eclipse platform and designed to offer maximum productivity when developing JEE applications for the WebSphere Application Server. RAD provides a more comprehensive set of capabilities than WDT, including test and analysis tools, and integration with the Rational Collaborative Application Lifecycle Management solution (Rational Team Concert).
IBM WebSphere Application Server Community Edition
WebSphere Application Server Community Edition (WAS-CE) is an open-source Java EE 6 application server based on a number of well-established Apache projects (Tomcat servlet engine, Geronimo Java EE runtime, Derby database), with integration with the Eclipse IDE provided by a Web Tools Platform (WTP) plugin for WAS-CE.
All of the packages comprising the WebSphere Community Edition are available for free through the open-source community, although the additional value the IBM packaging offers to prospective users includes:
• Each release of WAS-CE combines specific releases of the constituent packages. IBM performs the integration of these releases, and the resulting combination undergoes an extensive suite of tests to ensure compatibility between the source packages and to verify the correct behavior of the product.
• Although WAS-CE is provided free of any license charge, formal product support is available for purchase as an optional service. This allows the product to be used by organizations requiring the assurance of formal, contractual support arrangements for products they deploy. Several tiers of support are available, with a range of options providing defect support and developer assistance at different service levels.
As well as providing a lightweight and low-cost entry-level application server, WAS-CE is a true open-source product that allows users access to the source code and provides them with the option of customizing the application server source code to suit their specific needs. WAS-CE includes an enterprise-messaging infrastructure based on the Apache ActiveMQ implementation, which is a JMS 1.1-compliant messaging provider. Apache OpenEJB and OpenJPA provide EJB 3.0 and JPA support respectively.
As part of the WebSphere family, WAS-CE can be administered via a Web-based administration console, via scripting interfaces, and JMX Managed Beans. Another common feature is provision for both horizontal and vertical scaling via clustering support. In addition to providing simple load-balancing capabilities to distribute workload between servers within a cluster, WAS CE uses the Web Application Distributed Infrastructure (WADI) framework to allow session state to be replicated between clustered servers, allowing failover of session state in the event of a server failure.
IBM withdrew WebSphere Application Server Community Edition from marketing in September 2013, with the WebSphere Application Server Liberty Profile offered as the strategic replacement.
Oracle WebLogic Server
WebLogic Server was the flagship Java application server product from BEA Systems, Inc. before they were acquired by Oracle in 2006. WebLogic is an enterprise class application server that offers a fully compliant implementation of the Java EE 6 standards.
From a QoS standpoint, WebLogic deployments can scale vertically and horizontally. In typical large-scale deployments, a clustered setup of WebLogic instances is a more common scenario. A group of WebLogic application server instances functions as a logical unit offering scalability and high availability. Instance failover options are augmented by session failover, where WebLogic server’s clustering mechanism ensures session state held in the HTTP session, or in stateful session beans, is either replicated in memory across chosen peer instances or maintained in a database. In-flight transactions spanning multiple resource managers, such as databases and messaging systems, can also be recovered after server crash and a restart through a robust implementation of an XA-compliant transaction manager.
Web application deployments on WebLogic can also leverage a variety of network deployment topologies featuring a combination of Web servers, load balancers (software and hardware) and WebLogic application servers. Load balancing and failover are supported at the Web tier and EJB tiers, although automated failover is dependent on the idempotency of the operation, which means repeating an action is guaranteed to have the same results as before regardless of the number of repetitions performed.
WebLogic administration also revolves around the concept of an administrative domain. Like GlassFish, WebLogic features a powerful administration console offering role-based access control to WebLogic administration. For example, administrators have full control over domain configuration, deployers have permission to view server configuration, and operators can view configuration and start/stop servers, whereas the monitor roles can only view server configuration. The WebLogic console also offers monitoring capabilities, although production grade troubleshooting and monitoring can be handled through the WebLogic Diagnostics Framework (WLDF) offering features around recording application performance-related information, tracking, and correlating requests through different tiers.
WebLogic JMS is a messaging engine that provides high availability and scalability through features, such as distributed destinations, where a clustered set of JMS destinations offer a logical view to the clients and handle load balancing, failover between destinations on different WebLogic server instances, and automated and manual of stored messages and transactions.
Like most application servers, WebLogic is well supported by popular IDEs, such as Eclipse and NetBeans. Various IDE plug-ins specifically targeted at WebLogic allow developers to build, deploy, and debug applications on WebLogic from their choice of IDE platform.