


Operating the data reservoir
This chapter focuses on the day-to-day operational aspects of the reservoir. It explains how the workflows defined as part of the reservoir ecosystem can combine to provide a self-service model. This model helps ensure that data is governed appropriately, that curation is effective, and that security is managed in a proactive manner. Also covered is how a comprehensive collection of workflows allow you to gain further insight from both the operation of the workflow and the data within it by using monitoring. Insight gained from this can contribute to a significant savings in system burden for data stewards. It discusses how governance rules can significantly lighten the system burden of managing the data reservoir, and how monitoring and reporting can be used to ensure proactive management of the environment.
This chapter includes the following sections:
5.1 Reservoir operations
When examining a data reservoir from an operational perspective, it is important to also look at it from a governance capability perspective. Chapter 1, “Introduction to big data and analytics” on page 1 shows how the data reservoir provides a trusted governed source of data to an enterprise, avoiding the pitfalls of a data lake and minimizing the risk of creating a data swamp. This chapter covers the components of the reservoir supporting the governance of the data and underpinning the operation of the reservoir.
5.2 Operational components
There are a number of key operational components that relate to the operation of the data reservoir. These components are responsible for supporting the governance program associated with the reservoir and are key to self service.
Figure 5-1 describes the governance capabilities that exist within the data reservoir. The following are the governance capabilities:
•Workflow
•Business policies
•Governance rules
•Mobile and user interfaces
•Collaboration
•Monitoring and reporting

Figure 5-1 Logical architecture of the governance capabilities of the reservoir
These capabilities work together to support the underlying reservoir functions and its users. This chapter scrutinizes each of these operational components and discusses how they are applicable to supporting the reservoir functions and the underlying operation of the data reservoir.
The governance capabilities provide a uniform set of features that break down silos between the lines of business users, the governance team, and the data stewards. They provide a mechanism to allow these groups of users to collaborate with each other, and support, contribute to, and extract value from the data that is managed by reservoir functions.
5.3 Operational workflow for the reservoir
Operational workflow defines the actionable steps that should be followed to achieve the wanted results. These steps are either system actionable or human actionable. This section takes a deeper look at the role of workflow in underpinning the operations of the data reservoir.
Workflow is essential to coordinate the computer and human activity that are required to operate and maintain the reservoir, and the data and metadata within it. Workflow not only controls the flow of the data within the reservoir, but also encourages individuals within the reservoir to collaborate to ensure that the data is accurate, useful, and secure.
The use of workflow provides these capabilities:
•Guides a user of the reservoir through a predetermined path to complete a particular action within the reservoir
•Automatically notifies users of the reservoir of actions that need to be taken for others to complete
•Provides a comprehensive set of historical data that can be used for building reports on the operational patterns of the reservoir
All of these capabilities make it a fundamental piece of self service and for the sustainability of the reservoir. At the highest level workflow provides a platform for self service that underpins how information is shared, governed, and used within the reservoir.
Each interaction a user has with the reservoir will typically be as a step within a predefined operational workflow. Workflow plays a role at the point where users share and use data from the reservoir and plays a vital role in ensuring the governance of the data while it is present within the reservoir. The point at which these workflows run fits into one of three groups.
Figure 5-2 showing the flow of a document through the reservoir and how workflow manages it throughout each group.

Figure 5-2 Flow of a document through reservoir with workflow
5.3.1 Share
Workflow can be used at the point at which data is shared with the reservoir:
•Coordination of the human and system actions that are required to prepare data for publishing into the reservoir. This activity ensures that the source is cataloged, the data it contains is properly classified, and all relevant approvals are in place before the data is published and live within the reservoir.
•Enforcing governance rules on the data whose classification requires action at the point of ingestion into the reservoir. Minimizing exposure to risk of the data not having appropriate rules applied.
•Ensuring that the data is classified correctly in the data reservoir repositories at the point of ingestion into the reservoir. This step makes the data immediately more discoverable and usable by reservoir users and assists with the ongoing curation of the data.
5.3.2 Govern
Workflow can be used to manage the data while it sits within the reservoir. Workflow can be used to apply the governance program to the data within the reservoir in an ongoing manner:
•Enforcing appropriate governance rules upon the data that exists within the reservoir such as retention lifecycles.
•Automatically bringing data back into compliance with governance policies or routing tasks to data stewards notifying them of policy exceptions and guiding them through the steps required to remediate or exempt the policy exception.
•Providing notification and automatic prioritization of work items ensuring the most critical policy violations are addressed first.
•Verifying and renewing exemptions to policies.
5.3.3 Use
Workflow also plays an important role at the point at which the data is used by the users of the reservoir by performing these actions:
•Enforcing rules at the point of consumption, for example ensuring that sensitive data is masked for certain users
•Allowing people to identify issues with the data or catalog, notifying a curator that changes should be made, and then supporting the curator in making those changes
5.4 Workflow roles
Each of the workflows that exist within the reservoir has a number of different personas that interact with it in various forms. Roles define the responsibility, management, and execution of the workflow.
5.4.1 Workflow author
A workflow author is a somewhat technical user responsible for the creation of the workflow implementation. This individual will likely be an experienced user of business process management (BPM) software, such as IBM Business Process Manager. They use the tools provided by the BPM software to model the workflow to provide an implementation of the business processes required to operate the reservoir. The workflow author receives requirements from the workflow owner.
5.4.2 Workflow initiator
A workflow initiator can be a human or a system within or outside of the reservoir that starts a new instance of a workflow, resulting in one or more workflow executors being required to complete the workflow. A workflow initializer can manually trigger a new workflow. For example, a user of the reservoir clicks a link or a system triggers a workflow on a schedule. However, it is also possible for a user to trigger a workflow without realizing it. For example, when taking an action against a piece of data that has a trigger assigned to start a workflow if the data is updated.
5.4.3 Workflow executor
A workflow executor can be a human or a system within the reservoir that has a step within a workflow assigned to them for action. A step that is assigned to a human can be referred to as a task. Often tasks are displayed within a task list or an inbox for action.
5.4.4 Workflow owner
The workflow owner is typically an individual or group of individuals responsible for the operation of the workflow. They have intimate knowledge of the intent of the business process and the problem it is solving. They will typically monitor the effectiveness of the workflow in achieving its required objectives and be responsible for the change management of the workflow. The workflow owner will likely be responsible for a number of processes within the reservoir, which is aligned to their area of responsibility or domain expertise. They are responsible for producing reports for their collective workflows up to their stakeholders.
5.5 Workflow lifecycle
The workflows defined within your data reservoir should continue to evolve with the usage of your data reservoir. What seems like a comprehensive workflow supporting the operations of your reservoir during the initial rollout will require continuous iterative improvements. Doing these improvements ensures that the reservoir will continue to provide the benefits required to support the ongoing operations and growth of your environment. For this reason, a lifecycle can be defined for the workflows. The workflow lifecycle defines the phases that each workflow can go through to support the ongoing operations of your environment. Each workflow iterates many times through the lifecycle, each time evolving to suit the changing requirements of the reservoir.
Figure 5-3 shows the workflow lifecycle’s these phases.
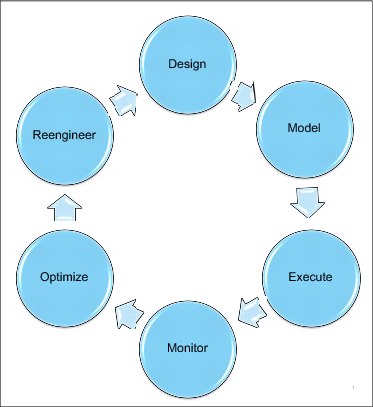
Figure 5-3 Workflow lifecycle phases
The following are the workflow lifecycle phases:
•Design phase
The design phase allows the workflow owner to evaluate the purpose of the workflow and the requirements that need to be satisfied. They will typically use reports that have been generated from the Monitor phase to allow them to determine how the workflow can be fully optimized and determine how the new workflow fits into the existing workflows within the system, while addressing the requirements and how the workflow can best support the operation of the reservoir.
•Improve phase
The improve phase allows the workflow author to translate the requirements from the workflow owner as laid out on the design phase. The workflow author uses a process design tool build the workflow artifacts. After they are built, these artifacts will go through the software development lifecycle steps and receive signoff from the process owner before being deployed.
•Execute phase
The execute phase consists of the deployment of the new workflow to the reservoir and its execution within it. At the point of deployment, the new workflow is enabled within the system. If the workflow is a newer version of an existing workflow, then the new workflow replaces the old workflow. The users and systems of the reservoir become workflow executors, and use the workflow to complete their operations within the reservoir.
•Monitor phase
The monitor phase is perhaps the most important of the phases within the lifecycle. It is in this phase that the workflow owner is able to monitor the effectiveness of their workflow. Each instance of the workflow gathers statistics within its data warehouse or can be added to the reservoir, capturing information about the data that the workflow is operating on and the users that are operating on it. Custom reports can be created to allow a workflow owner to monitor the effectiveness of this workflow, identify potential problems with the workflow or the operation of the reservoir, and provide a platform for analysis. These reports can then be used to improve the workflow in the future. For more information, see “Monitoring and reporting” on page 123.
•Optimization
Optimization is the iterative improvement of a workflow instance while it is live within the system. The workflow author in partnership with the workflow owner identifies improvements that can be made to the process. They do this through changing configuration parameters, optimizing performance characteristics, and using the reports from the monitor phase to identify areas that can be revisited in the reengineering phase.
•Reengineering
After optimization is complete and no further improvements can be identified with the existing workflow implementation, the workflow author works with the workflow owner to further refine the process. At this stage, a significant amount of information is stored within the workflow data warehouse that can be used to improve the components of the workflow. They typically identify human-centric steps that can be streamlined and where possible fully automated through governance rules. As part of the reengineering phase, superseded workflow implementations are versioned and archived.
5.6 Types of workflow
As previously stated, workflow underpins the operations of the data reservoir. A reservoir has many workflows that support the various functions, operations, and users of the reservoir. Typically, these workflows can be categorized into five distinct areas:
•Data quality management
•Data curation
•Data protection
•Data lifecycle management
•Data movement and orchestration
5.6.1 Data quality management
Responsible for the quality of the data and the usage of the data, these workflows play a significant part in the data governance program of the organization and enforcing that program on the data within the reservoir. Typically responsible for the enforcement of the rules defined as part of the data governance program, these workflows are responsible for handling policy exceptions.
These workflows are responsible for enforcing data quality, by capturing that data is in violation of a particular validation rule. The workflows either automatically correct the data quality issue or notify a subject matter expert of the data quality issue prioritizing the issue. The workflows also allow the individual or business unit to correct the issue. These fixes can be on the data within the reservoir or on the data held in the original source.
Governance rules and collaboration are key to ensure that the workflow is efficient at routing tasks to the correct individuals for action and ensuring that the individuals are able to make the correct decisions in minimal time.
Data quality management workflows provide a mechanism to facilitate adherence to regulatory laws. For example, workflows can be built to ensure that right to forget laws are enforced automatically without assigning a team specifically to this task. Reports that are generated from this workflow can record compliance to this legislation on an automatic schedule.
Governance policy violation
An example of a workflow supporting data quality and compliance is one where a rule is tied to a governance policy stating that any customer record under the age of 18 should have a guardian associated to it. Data that violates this rule would trigger a workflow. On validation that the rule had been violated, the workflow tries to correct the data automatically, based on actions taken on similar types of tasks and data. If that does not work, the workflow creates a task for an individual to manually inspect the data and provide them a mechanism to bring the data back into compliance with the policy so that the rule is no longer violated. This activity can either be within the reservoir or at the original source.
Figure 5-4 shows an example of a simple workflow supporting the data quality management of the reservoir. In this example, data is imported into the reservoir and governance rules are used to validate the data of a particular classification. If a rule fails, then a remediation task is created for a data steward, who can then use the remediation user interface to bring the data back into compliance or record an exemption.
After the data has been corrected, it is then revalidated against the governance rules. Finally, after the data is compliant with the rules, the compliant data is saved to the data reservoir.

Figure 5-4 A simple workflow
Data quality management workflows typically run in each of the operational workflow locations. For more information, see “Share” on page 108, “Govern” on page 108, and “Use” on page 108. Multiple workflows are used to test data quality either on the way into the reservoir, from within the reservoir, or at the point the data is used from the reservoir. The specifics of where the governance policy is enforced are down to the specific industry, regulatory compliance requirements, level of information maturity, and type of data within the reservoir.
5.6.2 Data curation
Data curation is the touching of the data by users of the reservoir. Typically data curation manipulates the catalog data rather than the actual reservoir data itself. Data curation is an important activity to maintain the currency of the metadata and make it more findable, descriptive, and relevant to users of the reservoir. Without data curation, as the volumes of data grow, the challenges to find relevant data, the risk that sensitive information might inadvertently be exposed, and the risk of finding data that has now gone stale are significantly heightened.
Workflow can support data curation and encourage effective data curation. A reservoir deployment includes a number of workflows to support the data curation activities that take place by the users of the reservoir. Done correctly, workflows allow data curation to become business as usual, encouraging users to curate information as they go, which results in up-to-date metadata to support the rapid and effective locating of data within the reservoir.
Invalid tagging of data
Workflows supporting data curation are typically started by an individual rather than being started by a system. A typical example would be when a users are searching for data, they might find that some irrelevant results have been returned. Further investigation of the returned data shows that it has been tagged incorrectly. The user can initiate a curation workflow stating that the data has been tagged incorrectly. If permissions allow, the workflow either allows the user to correct the error themselves, or creates a task for an information curator to investigate and correct the issue.
Figure 5-5 shows a simple workflow that supports one curation activity within the reservoir. In this example, a user of the reservoir clicks a link that starts a workflow due to invalid metadata being discovered. This workflow creates a task for an information curator to investigate and notifies that person of this new task. The information curator then makes any required changes to the metadata before saving the changes back into the reservoir. A real world example might bring in rules to determine which information curator a particular curation activity should be routed to or determine whether the user themselves can make the change to the metadata. However, even in this simple example, you can see how the workflow provides the mechanism to notify the curator of a task and provide that person with the mechanisms to correct the metadata.

Figure 5-5 Stepping through a simple workflow
Curation workflows can also provide a level of control over the curation activities. Workflows can be created to enforce a safeguard against curation being performed on particular types of data or curation activities being performed by certain groups of users. For example, governance rules could be used as part of a curation workflow to state that any metadata change performed by a set of novice users on data classified as being sensitive must have the change approved by the data owner. The integration of workflow and governance rules facilitates this capability and underpins the ongoing effective curation and the efficient usage of the data reservoir.
5.6.3 Data protection
Protection workflows support the operation of the reservoir by monitoring the operations of the reservoir and automating the initialization of steps to respond to incidents as they occur, ensuring that security and compliance officers are notified. Data protection workflows are typically started automatically by the system based on user behavior rather than being started directly by a user of the reservoir.
Data protection workflows rely on the collection of information about user interaction with the reservoir, analyzing that data and applying governance rules that provide thresholds as to when certain actions should be investigated by the security team.
Data protection workflows cover a broad spectrum of use cases underpinning the operation of the reservoir, of which these are two different examples:
•Being of potentially non-malicious intent
•Being of potentially malicious intent
Both of these scenarios are important to build trust in users of the reservoir. It is important to have a robust set of workflows to supporting the secure operation of the reservoir so that users know that their sensitive data will be maintained and there are safeguards in place continuing to enforce these rules while the data exists.
Classification violation
In this scenario, new data has been added to the reservoir, and the data has been classified as sensitive, classified, confidential, or private. However, the data does not have any security associated with it. This document has been published to the reservoir and has full public access to all users of the reservoir by mistake. A workflow can be used at the point of ingestion (shared) to the reservoir to recognize that the tags associated with this document indicate that security should be applied. The workflow can temporarily lock down this document so that only the document owner can see this document and notify them that they must validate that the security permissions for this document are correct.
Figure 5-6 shows a simple implementation of this scenario. The workflow handles the import of data into the reservoir and analyzes its metadata to determine whether the document has been classified as sensitive. If it has, the workflow checks to see whether the permissions associated with sensitive data have also been applied. If they have not, the data is locked from view within the reservoir and the information owner is notified about the security exposure that needs to be rectified.

Figure 5-6 Workflow for sensitive data processing
Workflow also allows this security to be enforced on documents that are already within the reservoir. If sensitive information exists within a document, a curator tags the document as sensitive. In this scenario, a workflow could be triggered to recognize that this tag now exists but the document is still available with no security enforced on it. A workflow could notify the document owner and request that they take immediate action to rectify.
Malicious data discovery
In this scenario, a disgruntled employee is searching to see what he can find of interest that he could use for malicious reasons to harm the company. He begins by searching for financial information, looking for employee salary information and budgeting information. Next, he searches for information related to special projects that are due to be worked on by the research department and download large volumes of information about these projects. These searches by themselves could be completely innocent and provide no significant security exposure. However, when looked at as a whole the searches could allow a user to determine the budgets being assigned to an important new project, the individuals working on it, and the remuneration package they are receiving. This information could be taken by the employee to a competitor, exposing the project, the budget, the key people, and how much it might cost them to hire the employees away. This situation provides the potential for unmeasurable damage to the research project and the company's future profitability.
Using a combination of audit mechanisms to track what data users are accessing and downloading, governance rules to capture when certain usage patterns or thresholds are met, and workflow to initialize tasks and notify a security officer to provide further investigation, these events can be investigated quickly.
These events can be investigated quickly by using these capabilities:
•Audit mechanisms to track what data users are accessing and downloading
•Governance rules to capture when certain usage patterns or thresholds are met
•Workflow to initialize tasks and notify a security officer to provide further investigation
In this scenario, a pattern of activity, defined within an analytical model would have been met to state that this individual had been downloading large amounts of new project data and was looking at sensitive-financial data. A task would be sent to a fraud investigation officer immediately identifying that the threshold defined by the business rule had been met. This action allows the fraud investigation officer to begin an investigation and monitor the activity of the user. The speed at which this can take place would mean that the fraud investigation officer would be able to catch the perpetrator in the act and limit the risk of harm to the company. The combination of workflow and rules provides a level of self service to the effective operation of the reservoir. The workflows and rules can be continuously iterated on to tailor the thresholds to match the type of data and threat level associated with it.
5.6.4 Lifecycle management
Workflows supporting lifecycle management typically occur on data within the reservoir rather than at the point of ingestion into or output from the reservoir. They are responsible for managing the lifecycle of all data within the reservoir. This includes the lifecycle of the data and the lifecycle of the governance definitions such as the policies, rules, workflows, and reference data required to support the operation of the reservoir.
|
Note: Lifecycle management workflows manage both the lifecycle of the data and the governance definitions associated with the reservoir. This is important to maintain the artifacts that support the governance program.
|
Lifecycle management workflows are key to maintaining the relevance of the data in the data reservoir repositories. They support the mechanism to request changes, make changes, and approve the results. Data that has expired is removed from the reservoir.
Workflows support the evolution and maturity of the data reservoir definitions. Policies evolve or new ones are required due to various factors:
•Changes in company structure
•Changing regulatory requirements
•Expanding scope of the data reservoir
For these and other factors, workflow provides lifecycle management to ensure that approvals are enforced to manage changes that are made. This scenario applies to all aspects of the governance program, whether they are policies, rules, reference data, or the workflows themselves.
Reference data lifecycle
Imagine a scenario where a large multinational organization has implemented a data reservoir. The data reservoir is accessed by large numbers of users across the entire span of the organization's operating geographies. The data reservoir includes a reference data set specifying country codes. This reference data set is used by other systems and documents that are critical to the financial reporting, organization structure, and budgeting of the organization.
During a period of political unrest, a disputed territory that is claimed by one of the countries that the organization operates in is unofficially renamed by that country. Individuals within that country now refer to it by its new name. Individuals outside of that country refer to it by its original and legal name. An individual resident of the country claiming the disputed territory might choose to update the reference data set to represent the new name for the country, even though this change is not recognized by the organization nor by the United Nations. Making this change could cause a huge amount of disruption to the data. This disruption could result in incorrect financial reporting and potentially damage the brand of the organization should reports be released that name the disputed territory under an unofficial name.
Figure 5-7 describes a simple workflow that could be used to enforce lifecycle management on a piece of reference data. The workflow is initialized when a user requests a change to a piece of reference data. This action creates a task for an approver and notifies them of this new task. The approver starts the task and is presented with a user interface that allows them to determine what the suggested change is and what the reason is for the change. If the approver approves the change, then the reference data is updated within the reservoir. If the change is not approved then the requester is notified that their change has been rejected and the reason for the rejection.
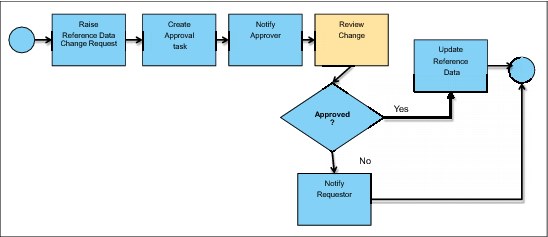
Figure 5-7 Workflow enforcing lifecycle management
Workflow supports the lifecycle management of the reference data. In this scenario, a workflow would have been initiated on the change to the reference data set. This situation would have routed an approval notification to one or more individuals, requiring them to approve the change before the change was implemented, stopping the potential damage to the organization’s brand. This level of management can be applied to data and governance program components through workflows. These workflows allow data custodians to be confident in sharing their data in the reservoir and allowing it to be used in a controlled manner, without putting the company or the data at risk.
5.6.5 Data movement and orchestration
Closely linked to the lifecycle management type workflows, data movement and orchestration workflows support the movement of data as it is fed through the reservoir. Workflow can be used to define and control the various paths that need to be followed to ensure that the data is moved between the various groups within the reservoir. This approach ensures that the data is in the correct format and shape for consumption.
Lifecycle management type workflows typically support the state of the data, such as whether it is published, stale, awaiting approval, or private. Data movement and orchestration workflows define the steps in which the data must flow through as it interacts with other services provided within the reservoir. These services can change the format of the data, change the classification of the data, mask the data, or merge the data with other reservoir data.
Workflows that fall under this category are typically started either by a user, a schedule, or pushed from the data source. They can be started at indigestion to the reservoir or on data that is already within the reservoir. Workflows of this type prepare the data for consumption by users of the reservoir. It is unlikely that workflows falling under this category will be started by the consumption of the data from the reservoir, because the processing should have already been completed.
As with the other workflow types, governance rules add an important layer of intelligence to the operation of these workflows. Governance rules determine the transformation that is required on the data depending on its classification. Through the governance rules, these workflows automatically apply the correct rules to the data and ensure that the data is fit for use by the users of the reservoir.
|
Lifecycle management: Lifecycle management workflows support the state of the data, whereas data movement workflows define the paths that the data should follow to affect the state.
|
Sensitive data ingestion
Imagine a scenario whereby the payroll department of a large organization needs to upload a data set to the reservoir that contains employee payroll information. The information within this data set is considered extremely valuable to select individuals within the organization and therefore would be valuable to be shared. However, to ensure that employee privacy is maintained, elements within the data set such as employee name, employee ID, and bank details are masked when data scientist work with the data. Workflows have been configured within the reservoir to route data through a data masking service at the point of ingestion into the reservoir.
Figure 5-8 shows a simple implementation of such a workflow. As the data is imported into the reservoir, governance rules determine whether the data might be payroll data. If it is, the data is automatically sent on to the masking services, which have been configured to strip out the employee name and ID values. The masked data is then saved into the reservoir.

Figure 5-8 Workflow with data masking
In this scenario, the user importing the data does not even need to know the requirements that need to be enforced on this data. The workflow is responsible for ensuring that the sensitive data masking is an automated process and does not require a human to remember to mask the data. The workflow can be initialized in two ways:
•Under a user initialized implementation, at the point of upload to the reservoir the user can select which elements of the data contains sensitive information. The workflow ensures that these data elements are fed through the masking service.
•System-initiated style, the workflow triggered interrogates the catalog to discover the data's classification. Using the governance rules within the workflow, decision points determine whether the data should be routed through the masking service or not.
Periodic checks can be made on the classifications of data in the data reservoir by surveying workflows that seek out particular types of sensitive data.
5.7 Self service through workflow
“Types of workflow” on page 111 showed how workflow provides the operational underpinnings of the data reservoir. Workflow is the component that ensures these items:
•Data is secure
•Governance program is enforced
•Data is findable, valid, and useful
Without these important elements, the reservoir will become untrusted, not useful, and in the worst case a liability and open to abuse and security violations.
Maintaining these operational aspects of the reservoir can be a time consuming role. This challenge increases as the number of users of the reservoir grows, the skill levels, experiences, and expectations of the users broaden in scope and as the volume of the data increases. Automating these workflows provides a mechanism to manage this challenge as the operational dependencies increase. The number, size, and complexities of these workflows can grow as the number of users and volume and type of data within the reservoir grows. It is typical for a few key workflows to exist in early stages of a data reservoir. These workflows typically include a larger number of human-centric steps to be done as part of the workflow. Over time as the reservoir grows, more workflows will be required, and new and more complex rules can be developed to support a much more automated set of workflows. This capability significantly reduces the maintenance burden of the reservoir.
For users of the reservoir, operation workflows provide the self-service mechanisms that they require to extract value from the data. Business users want information now, they want to be able to accomplish these goals:
•Find data quickly
•Trust that the data is accurate and up-to-date
•Ensure that their data is secure
•Be able to overcome issues quickly and without assistance
Ensuring that workflows are provided to cover these categories is key to providing the self service that is expected by today's savvy users.
5.7.1 The evolution of the data steward
The shift towards the growth in the understanding of the importance of the data reservoir is occurring at a time when the role of a traditional data steward is also shifting (Figure 5-9). These two dramatic shifts are complimentary and are important to each other to aid self service.

Figure 5-9 Data steward
Traditional data stewardship
In some organizations, data stewardship is solely handled by a team of data stewards who belonging to the back-office IT department. In the past, individual data steward roles were called out by an organization, and they managed the data and ensure its accuracy. These operations were performed from a perspective of theoretical accuracy with no real understanding of the customers, products, and accounts that the data was describing. Worse still was that there was little engagement with the lines of business users who understood the customers, products, and accounts that the data was describing.
Data quality decisions were being made by a group of individuals that understood the function of the data rather than the data itself. This situation led to data stewards contributing to the inaccuracies of the data. It also meant that all data quality issues discovered within the data became a bottleneck within an organization. Data quality tasks would be added to a data steward's backlog quicker than they could correct them. In some organizations, it was not uncommon for 10,000 new data quality tasks to be created each day. A team of data stewards with a capacity of completing 500 tasks a day could never be able to address this ever-increasing backlog. It became OK that these tasks were never going to be resolved. This led to significant staff retention issues across the data steward organization, but also created a huge number of data quality issues that were never going to get fixed, leading to low data quality and low trust in the data. Applying this mechanism to stewardship of data within a data reservoir, where the volumes of data and usage of the data is typically very large, causes significant problems when managing the reservoir. This circumstance causes large amounts of maintenance that must be performed and the risk of bad business decisions being made from the inaccurate data.
Imagine a scenario where a data quality issue has arisen on an important piece of master data that is held within the data reservoir. In this scenario, a duplicate customer record has been found for a gold customer. Gold customers are the organization’s top 5% revenue generating clients, and are therefore eligible for special offers and dedicated account management. The data steward notices that the duplicate record does not have the gold customer flag set and includes a new contact listed as chief procurement officer. The data steward collapses the records by moving the new contact into the master record and moves on to the next task. The steward has done the job correctly by correcting the data and removing the duplicate records within the system. However, the data steward has no understanding of the impact of the new contact being added to the customer record. Because this new contact is the chief procurement officer, this new individual could have a significant influence over the future revenue stream from the customer. Traditional data stewardship allows the data quality issue to be corrected, but does allow you to address the underlying business opportunity that might exist.
Line of business engaged stewardship
More recently there has been a shift to increasing avenues of collaboration between data stewards and the line-of-business knowledge workers. Data stewards are typically still involved in managing large volumes of data quality decisions. However, lines of business users are now also expected to actively contribute to or own the data quality decisions within their domain of expertise. In some scenarios, the task will still be routed to a traditional data steward. However, the tools that are used by that data steward allow them to easily identify the line-of-business subject matter experts (SMEs) who are associated with that data. This feature allows them to engage and collaborate with the SMEs in real-time to ensure that the correct decision is made upon that data. In an increasing number of scenarios, the data quality task is routed directly to the SME for that data. Workflow enables the task data to be interrogated and a business rule applied to route the task to the correct SME for processing. After the line-of-business SME has corrected the data, the updated data can either be persisted directly to the data source or can again use the workflow to notify a data steward that this change needs to be approved before it can be applied to the data source.
The ability to use workflow and apply governance rules to determine whom a task should be routed to for processing significantly lightens the workload for a data steward. This action cuts down the number of tasks being routed through the data steward’s bottleneck. It also puts the data quality decision directly into the hands of the subject matter experts for that data, allowing for faster, more informed decisions to be made. Within a data reservoir, the volumes of data and users can become very large. Having a robust mechanism to route the tasks to the subject matter experts for the data and removing the bottlenecks caused by a back-office data stewardship team is extremely important to maintaining control over the data.
Looking back at the data stewardship example about the our customer, using line of business engaged stewardship, rather than adding yet another task to the data stewards backlog, allows you to apply governance rules to the workflow. The workflow interrogates the data and determines that this suspect record relates to a gold customer. The workflow then routes the task directly to the gold account customer service team. The gold account customer service team (as the SMEs) apply their domain knowledge to determine that this new chief procurement officer should be contacted immediately to build a relationship and inform them of the special service and preferential rates they are entitled to as a result of their gold status. It is noted that this new procurement officer is replacing an individual who moved to another company. You can then update the customer record to remove the individual as a contact and contact that individual at their new company and inform them that you would like to continue your relationship and help them achieve gold customer status. By more effectively managing the burden of operating the data reservoir (by engaging the SMEs in the data quality decisions) the company is able to make much more effective business decisions and provide the potential to drive additional revenue.
Enterprise engaged stewardship
An emerging trend in this space is a further shift to fully enterprise-led stewardship. In this scenario, the lines of business are fully engaged in owning the data quality decision. Data quality tasks are automatically routed to the SMEs in the lines of business. Governance rules are heavily used to ensure that data quality decisions are being routed to the correct individuals. It becomes the responsibility of the lines of business to manage the data quality issues. Comprehensive workflows coordinate efforts across individuals and lines of business, ensuring that approvals, escalations, and critical path management are accounted for. The lines of business are responsible for ensuring that data quality service level agreements (SLAs) are met for the tasks that they are accountable for. Reports are provided to help the line-of-business managers monitor the effectiveness of the team in managing their data quality responsibilities. Simple, prescriptive user interfaces provide the capability for the lines of business to manage their tasks and provide the reports on the task resolution statistics to which they can be held accountable.
Under enterprise engaged stewardship and particularly when implemented as part of the operations of a data reservoir, data curation is an important aspect in supporting the shift to enterprise stewardship. It can feel uncomfortable when shifting the responsibility for the data quality away from the traditional stewardship organization and into the hands of the lines of business. Data curation plays an important role in easing this concern. Within a reservoir, information curators are engaged to constantly touch and shape the data to support the enterprise context. Users of the reservoir are constantly updating, tagging, flagging, and rating the data that they are using. These curation activities contribute to the quality and usefulness of the data as an ongoing concern. The expertise that becomes absorbed within the data as a result of this constant curation, coupled with the data quality decisions being made by the SMEs within the lines of business, can result in the level of data quality being good enough. Data stewards will still exist, but they are likely to be focused on a specific set of tasks that require back-office IT involvement rather than subject matter expertise. It is not uncommon that a data steward will still be required to approve certain changes to the data made by a line-of-business user.
5.8 Information governance policies
The information governance policies defined as part of the governance program also describe the manner in which the data reservoir operates. Collectively the policies provide a set of operating principles for the data within the reservoir and the users of the reservoir.
The information governance policies are stored within the catalog and provide a hierarchical view of all of the policies defined for the reservoir. It holds the low level department policies and how they roll up into high level corporation wide policies or industry regulatory policies.
The policies defined within the catalog are owned by the Chief Data Officer or governance leader. They have the responsibility for ensuring that the policies are enforced within the reservoir through the rules and classifications.
The catalog provides the centralized point for housing the various implementation components of the governance program and the operation of the reservoir. From the catalog it is possible to drill down from the policies, into the specific rules that implement those policies for each classification, and then into the operational workflows that execute the rules. The catalog provides the lineage of data throughout the operational components of the reservoir. Operational workflows such as those defined in the section “Lifecycle management” on page 116 provides change request management on artifacts within the catalog.
5.9 Governance rules
Governance rules provide the functional implementation of the policies for each governance classification. It is the information governance policies that provide the logic that needs to be executed when users or systems interact with the data reservoir.
Rules can be implemented in a rules engine such as, IBM Operational Decision Manager. However the rules will be referenced to from the policies that are enforced by these rules from within the catalog. The linkage between the policies and the rules is important as it is typical that policies require multiple rules to be enforced, one for each classification and for each situation where action is appropriate for the classification.
It is the governance rules that provide the intelligence to the operation of the reservoir. The rules are embedded within the operational workflows and are responsible for interrogating the data and catalog, making decisions on which systems or which individuals should be notified about specific types of event. They provide the smart infrastructure required for the efficient operation of the reservoir and are vital to maintaining the quality of governance and quality of service expected of the reservoir.
It is typical for initial deployments of a data reservoir to be somewhat light on governance rules. Overtime as the data volume and veracity increases the rules will be monitored for effectiveness. Using the monitoring components of the reservoir the rule implementations will be iteratively improved and enhanced to meet the changing operational requirements of the reservoir and further aid self service.
5.10 Monitoring and reporting
The monitoring and reporting capabilities of the reservoir are important to the owners of the reservoir who are responsible for its continuing operation and growth. It is also important for the executives within the governance organization who need to know the effect the data reservoir has on the compliance of the policies within the governance program.
This section describes the various aspects to the monitoring and reporting capabilities that are required of the reservoir.
5.10.1 Policy monitoring
Perhaps most important to the operation of the reservoir is the ability to monitor the data against the policies that are defined within the governance program. Monitoring the data against these policies is important for a number of reasons including:
•Regulatory and compliance
•Monitoring financial exposure or risk
•Providing an incremental view on the overall effect of the governance program on the data within the reservoir
Monitoring of the policies is key to proving to the business that the data within the reservoir is accurate, trusted, and compliant with the corporate governance policies that are in place across an organization. The need to ensure that the content of the reservoir is governed to encourage users to release their data into the reservoir is important. It is the ability to monitor the effectiveness of these policies on the data and build reports based on these metrics that proves to the business that the reservoir is able to satisfy these requirements.
5.10.2 Workflow monitoring
“Operational workflow for the reservoir” on page 107 described how workflows can provide the operational underpinnings of the data reservoir. The workflows manage the interaction of users and systems with the data and metadata within the reservoir. They also provide a mechanism to automatically respond to events as they occur, heavily using rules to add the intelligence required for self service.
An important capability of any workflow technology is the ability to monitor the effectiveness of each instance of the workflow that gets initialized. These important statistics, among others, can be extracted from the execution of these workflows:
•Amount of time it takes to complete each workflow
•Overall number of instances of each workflow
•Number of tasks that were not completed within agreed SLAs
•Amount of time that a particular step in a workflow takes to complete
These metrics can be analyzed by the reservoir operations team to identify areas of improvement that can be made to the effectiveness of these workflows, or can be used to identify issues as they arise.
Another important aspect with regards to workflow monitoring concerns critical path management. It is possible for alerts to be associated with particular thresholds. When a metric within the workflow monitoring meets a particular threshold, a reservoir administrator can be notified. Notifications can also be associated when a particular exception path within a workflow instance is initialized. These capabilities significantly lighten the processor burden required to operate the data reservoir.
5.10.3 People monitoring
Closely aligned to workflow monitoring is the ability to monitor the interaction of people with the operational workflows. While a workflow is running, users of the workflow will be interacting with the various steps of the workflow, completing their tasks, and moving the workflow onto the next step.
People monitoring allows you to monitor the interactions that each user is making with the operational workflows. You can monitor how long it takes a user or group of users to complete a step within a workflow, how many tasks are assigned into the inbox of each user or group, and how many tasks a particular user or group has completed over a prescribed time.
Similar to workflow monitoring, alerts can be sent to individuals when specific thresholds are met, such as when a task with a status of high priority must be actioned within one hour. If the one hour time limit is exceeded, an alert is sent to the person responsible for that task. And if there is no action after a further 30 minutes, the task is automatically assigned to their manager or one of their peers.
The ability to monitor and report on the metrics produced by human interaction with the workflows is important when judging the overall efficiency and health of the data reservoir. Large volumes of tasks assigned to an individual might mean that the person is overloaded or out on vacation. What is the impact of that person not being able to act on those tasks within the wanted time frame? Being able to identify these issues through monitoring allows steps to be taken to avoid this situation, perhaps adding to the governance rules to reassign a task if it has not been begun within 24 hours.
5.10.4 Reporting
Reports can be generated from the three types of metrics. Different business units might require reports on one or more aspects of the reservoir. For example, the chief governance officer will be more interested in a monthly report that focuses on the policy metrics. A business line manager might be more interested in monthly reports that highlight inefficiencies in the teams or people that they are responsible for, and could use the information to identify training requirements for the team.
Extracts can be taken from these metrics and custom reports built to provide the information that is wanted by the various lines of business that require this information. Operational workflows can be used to compile and schedule these reports, ensuring that reports are sent to interested individuals as required.
5.10.5 Audit
The data that is required to provide the monitoring and reporting capabilities of the reservoir is automatically captured through a combination of the workflow engine (backed by a data warehouse capturing the workflow information) and the users interactions with the workflows, as well as the changing shape of the data and metadata and its compliance with the governance policies defined within the catalog. This data is built up throughout the lifetime of the reservoir and will become more comprehensive over time as the intelligence, users, and volume of data grows.
This information can be combined to provide a fully audit-able history of the operation of the reservoir, capturing the events, the changes to the data or metadata, and the users’ interaction with the reservoir. This information can be used to satisfy the audit requirements for high regulatory industries and environments.
5.10.6 Iterative improvement
This chapter has repeatedly mentioned the need to allow the reservoir operations to grow and adapt to the changing volumes and veracity of the data within it. As the volume of users increases or the policies within the governance program evolve, the reservoir must be able to shift to adapt to these changing requirements. Ensuring that a robust monitoring capability is implemented as part of the reservoir is key to enabling this.
Bringing together the metrics that are produced by the three types of reporting:
•Policy
•Workflow
•People
It is possible to identify inefficiencies within the operation of the reservoir and take corrective action on the operational components to correct the inefficiency. To assist with the identification of these issues, dashboards (Figure 5-10) can be used to provide visual reports on the operation and health of the reservoir operation. Reservoir administrators can use this information to determine what course of action should be taken to improve the efficiency.

Figure 5-10 Continuous iterative improvement
The metrics that are provided by the dashboards provide the Monitor capability as explained in “Workflow lifecycle” on page 109. It is important that the workflow lifecycle is used to continuously improve the rules and workflows that run the reservoir. Doing so aids automation and self service for the users of the reservoir and drastically improves the operational efficiency of the reservoir.
Taking an iterative approach to improvement of the workflow will quickly identify small areas of improvement that can be made to the workflows and drive an increase in the effectiveness of the governance rules. Over time, this will lead to an increase in the number of automated steps within a workflow and a decrease in the number of human-centric steps, leading to further operational efficiencies.
5.11 Collaboration
This chapter describes the role of the evolving data steward and how a drive to engage the lines of business in the data quality decision is important to ensure that the correct data quality decision are being taken, and to minimize the bottlenecks that can occur from traditional data stewardship. It also describes how information curators hold the key to being able to shift the enforcement of the governance program fully towards the enterprise. Key to making a success of the engagement with lines of business and providing a mechanism to encourage constant curation is collaboration. This section covers various aspects of collaboration that are important to the successful operation of a data reservoir.
5.11.1 Instant collaboration
For collaboration to be fully used, users must be able to collaborate at the click of a button. The means to collaborate need to be easily accessible to the users of the reservoir and encourage the breaking down of organizational silos. Instant messaging provides a means to offer this collaboration. An enterprise’s instant messaging system should be integrated into the data reservoir operations to help break down the organization’s silos and encourage easy, instant collaboration of people around the data and the processes that operate within the data reservoir.
The degree of integration of the corporate instant messaging service varies based on organization policies, lines of ownership, and technical constraints of the instance messaging application adopted by the organization.
At its simplest level, collaboration can be enabled by ensuring that the user interfaces of the data reservoir describe users in a manner that is reflected within the corporate instant messaging system. Authors of artifacts published to the data reservoir should be displayed in the same format as users of the instant messaging system. A search within the reservoir for documents authored by Joe Doe should return the documents that have been authored by the same individual that is returned when searching the corporate instant messaging directory for Joe Doe. Inaccuracies or inconsistencies between the format that users are represented within the reservoir and against other corporate systems can result in miscommunication and become a hurdle to collaboration across an organization.
Moving on from loose integration is a mechanism where the collaboration tools are slightly more integrated with the reservoir. In this scenario, the data reservoir user interfaces are used to embed the corporate instant messaging client within it. In this scenario, the instant messaging tools are always accessible and displayed when a user is accessing reservoir data within the same window.Ensuring that the tools to enable collaboration are on the window and accessible provides a constant cue to encourage users to collaborate. It is still important in this configuration that the identities of users in the reservoir and corporate instance messaging be identical.
Taking the integration a step further, the instant messaging capabilities are enabled directly on the data reservoir components that are displayed in the user interface. In this scenario, the users or department names displayed on the reservoir data become hot links to start an instant messaging conversation with that user. Real-time awareness support is added so that if a user has an instant messaging status of available, then the link is clickable. If the instant messaging status of a user is busy, then a warning can be displayed before the instant messaging conversation begins. Further levels of integration can be included that allow a user to point to the name of a reservoir document author to display a pop-up that shows profile information for the user from the corporate directory. This advanced level of integration with the corporate instant messaging system fully breaks down the organizational barriers that affect the successful engagement of users with the reservoir. Reservoir users can see the availability of other users within the reservoir, and can easily collaborate to curate data for maximum effectiveness and contribute to the quality of the data contributing to the success of an enterprise engaged data stewardship model.
5.11.2 Expertise location
Expertise location is another aspect that provides significant value to users of the data reservoir. The various forms of collaboration above assume that the information about who to collaborate with is known by the users of the reservoir. This can be easy if an artifact has an author associated with it. However, there are frequently scenarios where the author of an artifact is not the best person to comment on its contents or where no author is listed. Ensure that these scenarios are equally as accessible for collaboration on within the reservoir.
Expertise location allows the organization or the system to identify individuals who should be collaborated with for particular types of artifacts. Using expertise location, rather than only displaying the author of an artifact as being available to collaborate with, the experts also appear to the users of the reservoir as being available to contact.
5.11.3 Notifications
Throughout the usage of the reservoir, users should be notified of significant events that are relevant to them. Notifications can occur as part of the workflows that are underpinning the operation of the reservoir. Perhaps a new artifact is published to the reservoir that has a tag of finance and confidential. This publishing can trigger a workflow that notifies the security team of this artifact’s existence within the reservoir so that it can be checked to ensure that it has the correct security permissions applied to it.
Notifications can be surfaced to a user of the reservoir in a number of different styles. More than one style will typically be used within a reservoir, depending on the type of notification and the audience to which it is sent. Users might also be able to configure which notification styles they want to receive for which types of events. The following are some of the most common types of notifications:
•Instant message
A visual notification appears on the window of the recipient through the integration of the corporate instance messaging system. This mechanism is good for informational messages or broadcast messages from the reservoir meant for a wide audience.
•Email
Emails sent to individuals or groups containing relevant information about the reservoir or its contents. Daily digests containing a complete list of all of the day’s events can also be sent.
•Task inbox
Many users of the reservoir have a task inbox available to them. This inbox contains tasks that are awaiting their action. The task inbox provides the user interaction point with the workflows that under underpin the operation of the reservoir. As an operational workflow runs, steps within that workflow can get assigned to a user to take some action. The user is notified of this required action by selecting the task in their inbox.
•Short Message Service (SMS)
Text messages can be sent by the reservoir, typically to a set of key users who need to be notified of important events such as a message to a security officer informing them of a high priority security violation that needs urgent attention or to an account manager who needs to be notified of a change to some critical data.
•Social media
The boom in social media platforms and levels of engagement that they offers their subscribers, means that increasingly users are turning to their social media portals as their platform of entry into their environment. User will turn to their chosen platform and expect to be notified of all the events occurring that are related to their interests. This can be in the form of receiving news bulletins in their social media portal, but also can be events sent from the data reservoir. This also has the added convenience of typically being accessed on a mobile device.
•Log
Notifications can be written to log files within the reservoir. Typically data written to log files is informational and aids the reservoir operators in diagnosing issues as they arise.
It is commonplace for more than one notification type to be used for a single event, such as sending an instant message and an email at the same time.
5.11.4 Gamification in curation
Curation is important when it comes to supporting the ongoing operation of the reservoir and the quality of the data within it. It is vitally important that users of the reservoir are empowered to curate as they go when using the data within the reservoir:
•It should be easy for users to curate, so minimizing the number of clicks and processor burden associated with performing a curation activity is key.
•Give users a reason to want to curate, beyond it just being the right thing to do.
Gamification is a reference mechanism to drive engagement and increase user uptake in particular activities, especially those activities that are deemed to be more mundane.
When applied to data curation, gamification can significantly increase the level of engagement of the reservoir users. Driven by statistics that capture the number, type, and effectiveness of curation activities that a user performs. Simple leaderboards and star ratings can be applied to user profiles and shared across the user community. Providing levels such as power-curator for the top 10% of active curators can radically drive curations activities as users strive to improve their rating and maintain their status after it is achieved.
This mechanism of gamification can further enhance the automatic selection of experts. For more information, see “Expertise location” on page 127.
5.12 Business user interfaces including mobile access
There can be a number of different user interfaces used to interact with the different operational and user aspects of the data reservoir. This section describes some of the key ones.
5.13 Reporting dashboards
The need to monitor the policies, workflows, and people operating against the reservoir is important to satisfy the ongoing regulatory and operational requirements as the data increases in size and veracity and as the users of the reservoir grow. To satisfy this monitoring and reporting requirement, a set of interactive dashboards are used to provide a snapshot of the status of reservoir.
These dashboards report on the three dimensions of reservoir operations (policy compliance, the workflow status, and the person interactions) with the reservoir. Separate dashboards can be provided for each dimension or dashboards can include information from multiple dimensions as required by the reservoir administrators.
The dashboard capability should be configurable allowing custom reports and metrics to be mashed-up allowing new insight to be gained from the metrics that are available.
The dashboards provide a mix of different types of data:
•Live data: Updated in real time as events change
•Static data: Data that is updated on a schedule, such as nightly
•Historic data: Showing trends in the reservoir operations over a period of time
The dashboards include access control that ensures that only authorized users are able to gain access and include tools that allow a user to scroll back in time to display the reservoir status at a particular time in history. Also included is the ability to export reports from the dashboard over prescribed periods of time.
5.13.1 Catalog interface
The catalog interface is used by the governance team to define the policies that should be enforced on the reservoir operations and its content. It contains a number of policy trees that define how policies are related to each other and points to the rules that implement the policies. The governance team uses this interface to manage the governance program and be able to link to reports provided by the reporting dashboards to determine how enforced the policy is against the data. Change request management is supported through workflow to support changes to the data in the catalog.
For more information about using the catalog, see “Information governance policies” on page 122.
5.13.2 Mobile access
For various reasons, employees require access to corporate systems from devices external to the traditional corporate network so that they are able to access systems from anywhere at any time, including these reasons:
•Growth in smartphone ownership over the past decade along with technological leaps forward in the areas of mobile web development technologies
•Increased 3/4G network coverage and acceptance
It has now become a necessity that users can access these systems from their smartphones and tablets, 24 hours a day.
For this reason, each user interface provided by the data reservoir is mobile enabled through a combination of mobile web user interfaces and native and hybrid apps available for download either through commercial app stores or enterprise managed app stores. Using access through a corporate virtual private network (VPN), users can interact with the reservoir, manage catalog content, and monitor and export reports from all of their mobile devices. Recent advancements in enterprise-ready mobile device management technologies take care of the security considerations that occur when opening up your data to mobile users.
5.13.3 Summary
This chapter described the various operational aspects of the reservoir and at the core components that underpin its operation. The chapter discussed the importance of workflow, governance rules, and information governance policies to support various operational aspects and the importance of monitoring the effectiveness of these components overtime.
The key takeaway from this chapter are that combining the capabilities identified in this chapter and supporting their adoption across the users of the reservoir is vital to the success of a reservoir implementation. Policies must be enforced to allow users to trust that they can safely share their data within the reservoir and avoid regulatory noncompliance and risk. Workflows and their rules must be optimized iteratively to support the growth and evolution of the reservoir. Collaboration should be encouraged at each opportunity to engage users with curation, minimizing the requirements for data stewards. The overall system should be monitored through a series of rich reports and dashboards proving compliance to the policies of the governance program and iterative improvements against data quality targets.
These capabilities combine to provide the long-term benefits of the data reservoir to an enterprise and empower business users through efficient self service while reducing operational cost.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.