


Introduction to big data and analytics
This chapter presents a high-level overview of the data reservoir.
This chapter includes the following sections:
1.1 Data is key to success
In the modern world, data is a key element of business success. Over the last few years, IBM has worked with different businesses around the world, from banks to telecommunication companies, retailers to utility companies. These businesses are requesting help in building a sustainable and adaptable big data and analytics environment.
You might ask Why are big data and analytics important to business?
Many of the companies that IBM has worked with have been identified as some of the best in their industry. They have developed advanced processes for dealing with complex situations. But this is not enough. They also need to gather and analyze data from a wide range of sources to understand and act in a changing world.
Big data and analytics shines a light on what is really happening in an organization. It can identify what has changed and identify unexpected obstacles that might cause you or the business to stumble even on a known path.
Expectations are changing.
We are in a world of rapid change and ubiquitous communications. The younger generation does not remember a world without the Internet and mobile phones. Social media such as Twitter and Facebook create an expectation that as an individual, they have a voice and a right to be heard. These people expect service to be personalized and they can mobilize support for change with ease.
Consider the digital trail.
The act of using mobile phones and other mobile devices leaves a digital trail, illuminating where you go and what you do. Supporting this connectivity is an infrastructure so complex that it is too complex for the individual to understand or to control as a system without feedback.
Change has occurred because automation is affordable.
Sensors are becoming so cheap they can be placed anywhere. There is more data and more affordable processing power to collect, correlate, and act on this data.
Consider as an example that an electricity company's revenue stops if the power fails. Scheduled, routine maintenance reduces the chance of failure by replacing potentially worn out components. However, these actions do not eliminate failures. It is only when the whole grid is modeled and monitored does the company identify where components are being overloaded and which components need maintenance sooner. With this information, the company can reduce the number of failures further.
When weather predictions of storms are overlaid on this grid, new vulnerabilities are uncovered. Moving maintenance crews to targeted locations in advance of the storm minimizes outages, and reduces the cost of overtime for the crews.
Collecting, correlating, interpreting, and acting on a wide variety of data through analytics improves the resilience and quality of services. It is not easy to do and takes a disciplined, agile, and open approach. Without it, an organization is stumbling in the dark, unable to see the most obvious obstacles in its path.
1.2 About this publication
This publication describes how to manage information for an analytics and data-driven organization. It expands on the information available inGoverning and Managing Big Data for Analytics and Decision Makers, REDP-5120, which introduced the concept of a data reservoir. This publication provides enterprise architects and information architects with more detail on how to create a data reservoir for their organization. It also presents a high-level overview of the data reservoir architecture.
The data reservoir architecture acts as a blueprint for a generic system of data repositories that are managed under a single information governance program. These repositories together offer a data distribution and self-service data access capability for analytics and other big data use cases.
This publication provides more details about the data reservoir architecture and how to customize it for your organization.
Before delving into the details of how to do this, it is worth exploring the impact that big data and analytics will have on an organization (both in terms of the new capabilities that are enabled and the cultural shift it takes to be data-driven) through a simple case study.
1.3 Case study: Eightbar Pharmaceuticals
Eightbar Pharmaceuticals (EbP) is a fictitious pharmaceutical company.
The company has grown from a small group of researchers working together in a spirit of open communication, collaboration, and trust to a medium-sized successful pharmaceutical company that has a small range of successful drugs in the market and many others in development (three of which look very promising).
Up to this point, their investment in IT has been focused on the automation of the manufacturing process driven by the growth in demand for their most successful drugs. However, the market is shifting to personalized medicine and the company realizes they need a greater investment in data and analytics to embrace this new market.
In recent weeks, they also uncovered some fraudulent activity relating to their manufacturing supply chain and realized that they needed to improve operations security.
The owners of EbP ask Erin Overview to develop an investment proposal for their IT systems to support personalized medicine and help the company become more data-driven.
1.3.1 Introducing Erin Overview
Erin Overview is an enterprise architect working at EbP. In fact, she is the only architect working at EbP. Her speciality is information architecture and she developed the organization's data warehouse. This data warehouse takes feeds from the key manufacturing, sales, and finance systems to create reports on the operational part of the business. She has had minimal interaction with the research team up to this point because they have their own tools and systems.
Erin has a small team that includes:
•Peter Profile is an information analyst who monitors the quality of the data flowing into the data warehouse.
•Gary Geeke is their IT infrastructure administrator who ensures the IT systems are up and running. He is able to perform simple installations and upgrades, and relishes the chance to work with new technologies.
This team (Figure 1-1) is responsible for the support of the core IT systems used by the company. They are not the only people involved, but they each have a potential leadership role in changing the way the company's information is managed.

Figure 1-1 The IT Operations team
1.3.2 Perspectives from the business users at EbP
Erin realizes that enabling EbP to become data-driven and particularly to change their business towards personalized medicine is an enormous challenge that requires sizing and prioritizing if it is ever going to be delivered.
Her first task is to get some clarity on the requirements from various stakeholders in the business. This activity took a number of attempts because the various stakeholders needed help to understand how to develop realistic use cases.
Fraud investigation
Tom Tally is the accounts manager in the EbP's Finance team. He explained how hard it was during the recent fraud investigation to locate, extract, and then piece together the data from various systems to uncover the cause of the fraud.
To become more data-driven, he believes that they need a catalog of all of the data they have, better data consistency between the systems, and a simple way to access the data (Figure 1-2). He was also keen on developing fraud detection rules that can be deployed into the systems.
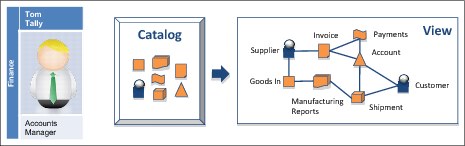
Figure 1-2 Use case for fraud investigation
Sales campaign
Harry Hopeful is a sales specialist for EbP. He has many contacts in various hospitals, and maintains a number of spreadsheets that record the sales visits he makes, who he sees, and the outcome (Figure 1-3). He would like to be able to refresh his spreadsheets with details of the latest customer and product information from EbP's core systems. This would save him time in planning his sales campaigns.
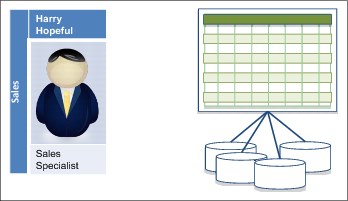
Figure 1-3 Analysis for sales campaigns
Erin asks if Harry would like to receive recommendations on who to visit and what to offer to his clients. He is interested, but skeptical that an IT system could do this.
Erin shared details of different types of customer analytics and the next best action solution, and Harry agreed that this could be useful to work towards. This process is particularly important because he has long-term experience in the industry and it would be useful to capture this knowledge before he retires.
Harry is asking for access to up-to-date operational data about their customers and products that can be used to dynamically update his spreadsheets. This data could also be used for customer analytics that makes recommendations on what to sell to each of Harry's customers.
Clinical trials
Erin then moves on to talk to the research teams. Tessa Tube is the lead researcher for their new range of personalized medicine. She has grand plans for how their personalized medicine will work, creating a close relationship between the patients and medical staff working with the treatments. Tessa describes a system that uses mobile devices to connect medical staff and patients to EbP through a cloud. This solution would capture measurements and dispense information about the drugs being tested and potential side effects.
As a starting point Tessa would like to build a simple version of this solution for her clinical trials (Figure 1-4). This initial solution would collect measurements and notes from the people involved in the clinical trial. This data would then be routed to her team for analysis and further development.

Figure 1-4 Clinical trials mobile-based solution
As Erin sketches out the solution that Tessa is asking for, she concludes that this clinical trials solution is going to require these components:
•Real-time access to information about the drugs being tested.
•Real-time execution of analytics to calculate the optimum mix and dosage for each patient.
•Initiation of requests to the manufacturing supply chain to manufacture the required treatment for each patient.
•The ongoing capture of data from medical staff and patients that describes the activity during a course of treatment.
As the personalized medicine part of this business grows, this solution is going to need to scale to support the needs of all their patients and medical staff. It will be the portal used by medical staff to understand the details of the products that EbP offers. It might well also become the principal sales channel for EbP, supporting advertising for new clinical trials and recommendations on treatments to use.
Clinical record management
Erin is keen to understand what type of information is collected in a clinical trial. She talks to Tanya Tidie, the clinical records clerk who is responsible for managing the clinical trial registrants and the results. Much of her work today is manual, dealing with paper-based records.
Initially the clinical trials are set up. The sales team (including Harry Hopeful) sign up consultants who are interested in participating in the trial. The consultants work with Tessa's team to determine which patients would benefit most from the trial. Next, they need to get the patient's consent. Tanya must ensure that the correct documentation of this phase of the trial is captured, including the patient's consent, plus personal and clinical details of the patient to provide a basis for analyzing the results.
After the clinical trial is running, there is an ongoing collection of information about the treatments given to the patient, observations made by the medical staff, and measurements of the patient made during the treatment.
When the clinical trial is complete, Tanya must assemble the results of the clinical trial for regulatory approval.
Tanya assembles all of the evidence for a clinical trial on her personal computer using a local application. When the clinical trials solution is in place, although she will still need to manage the participant sign-up and permission through the paper-based process, the ongoing collection of evidence, such as treatments given and measurement of the patient's condition, throughout the clinical trial should be much simpler (Figure 1-5).

Figure 1-5 Clinical records management
Advanced analytics processing
Callie Quartile, one of Tessa's data scientists, also provides more details about the data management required to support the Treatment Advice Cloud for personalized medicine (Figure 1-6 on page 8).
Data feeds from the cloud are processed in real time to create a treatment plan based on information about the patient and their condition. This solution also feeds the historical data stores with both the measurements and calculations, and sends instructions to manufacturing to ensure that the correct course of treatment is available for this patient.
An object cache is fed details of the treatment plan to the patient and relevant medical staff from the historical data store. This approach provides a continuously available source of data for the mobile devices connected to the cloud.

Figure 1-6 Analytics process for personalized medicine
Callie demonstrated her advanced analytics tools to Erin, showing how she creates samples of data, transforms each one for the analytics processing, and then creates candidate models and tests them on the different samples. These tools need to be able to connect to the historical data stores to extract samples of data to discover patterns in the data that will be used to configure the analytical models.
1.3.3 Signs of deep change
Erin is thoughtful after her discussion with Callie. Each of the business stakeholders is imagining that they will continue to operate as before, aided by more data. With her experience in information architecture, Erin can see that the real-time analytics driving both patient care and manufacturing is going to change the way that the whole organization operates.
Real-time analytics often causes the boundaries between the traditional silos (such as between research, manufacturing, and sales) to disappear and the way that drugs are sold and paid for is going to become more fine-grained.
Realizing that this is more than an IT project, Erin returns to the owners of EbP with her findings. She summarizes their data management requirements:
•The ability to drive and audit their operations to ensure that the research and manufacturing units are operating effectively together and are free of fraudulent activity.
•The ability to drive their research agenda through on-demand access to a wide variety of data sources. Data from these sources is combined and analyzed from different perspectives to create understanding of the conditions they are treating and the differences between individuals.
•The ability to meet the regulations associated with drug development, manufacturing, and personalized patient care.
•The ability to offer a more social interaction, with real-time insight and data gathering between both medical staff and patients during clinical trials and normal treatment schedules.
Figure 1-7 is a sketch of the systems she is envisioning.

Figure 1-7 The new world?
At the heart of the solution are data stores of harvested data and a set of operational shared operational data hubs. The harvested data stores are fed from the operational systems, the treatment advice cloud, and other external sources that the research teams are using. Between them, they provide a coherent view of the business for daily operation and analytical processing. New data sources can be brought into the harvested data stores to extend the analytics in use by the medical teams.
In addition, she highlights that the culture and skills of the organization need to change:
•Consulting data and analytical results should become a standard practice in all types of decision making. Today, they rely on personal experience and best guess approaches.
•Information should be treated as a key company asset and managed with the same care as their drug development and manufacturing.
•The IT tools that the teams use need to be upgraded so that they are communicating and collaborating more effectively, both within the company and with external parties, while protecting their intellectual property.
These are all essential attributes of a data-driven organization.
The owners of EbP are understandably concerned at the complexity in Erin's sketch and the potential impact of this change. There are two outcomes from the meeting:
•They ask for some external validation of the architecture and a framework/roadmap to enable them to roll out the new capabilities in an iterative manner. This task is the role of the data reservoir architecture from IBM. This architecture was developed using IBM experience in building big data and analytics solutions for organizations that want to be data-driven.
•It covers the integration of both historical and operational data necessary to support real-time analytics and is highly componentized to allow for an incremental rollout.
•It provides self-service access to data for business and analytics teams while protecting and managing the data that the organization depends on.
•They appoint a Chief Data Officer (CDO) named Jules Keeper to manage the business transformation to a data-driven organization.
1.3.4 Governance and compliance perspectives
Jules Keeper is an experienced CDO who has led a number of successful information governance programs in other companies. He sees the role of information governance as an enabler of a data-driven organization. It should deliver these advantages:
•Understanding of the information that an organization has
•Confidence to share and reuse information
•Protection from unauthorized use of information
•Monitoring of activity around the information
•Implementation of key business processes that manage information
•Tracking the provenance of information
•Management of the growth and distribution of their information
Each of these aspects needs an element of skills and training for the people who use the information. The system also needs special procedures when people need to collaborate and agree on a particular course of action, and technology to automate much of the daily management and monitoring of information.
Information governance is important in the personalized medicine business because they must demonstrate proper information management and use at all stages of a product (drug) lifecycle, not just during the clinical trials. This change affects most people in the organization, and requires the systems to gather the evidence that information is being properly managed.
Jules is keen to work with Erin on the changes to the IT systems. He also introduces Erin to two of his colleagues who are involved in the compliance and governance of EbP:
•Ivor Padlock is the security officer. His background is in physical security, but a couple of years ago he branched out into IT security. He wants to understand how they can ensure that the personal data and research IP can be properly protected by the new systems.
•Faith Broker is an auditor focused on EbP's compliance with pharmaceutical industry regulations. She established the current set of standards that the teams work to today, and is an expert in the regulations in each of the countries they sell their treatments to. Personalized medicine is an emerging field in their industry and Faith has been working with the regulators on the safety and compliance requirements that they need to implement.
Together Jules, Ivor, and Faith make up the governance team that Erin will collaborate with during the project (Figure 1-8).

Figure 1-8 The governance team
1.3.5 Positioning the data reservoir in the enterprise architecture
Mindful of the request by the owners of EbP that she should follow established practices in the architecture and build out of the new data driven ecosystem, Erin starts to document and classify these items:
•The existing systems that will integrate with the new ecosystem
•The existing systems that will need major upgrade or change
•The new systems and capabilities that will be required
In particular, Erin wants to document the scope and position of the data reservoir in their existing IT landscape.
Most of the existing IT systems at EbP are referred to as systems of record (SoR). Systems of record are the operational systems that support the day-to-day running of the business. At EbP, these are the manufacturing, finance, sales, and administration systems. They are transactional systems focusing on the efficient operation of the business.
Systems of engagement (SoE) are systems that provide personalized and highly responsive support to individuals. At EbP, the new clinical trials solution is an example of a system of engagement.
The data reservoir is called a system of insight (SoI). The role of a system of insight is to consolidate data from systems of record and systems of engagement to support analytics. The system of insight supports both the creating of analytics and the execution of analytics to generate insight that can be used by both the systems of record and systems of engagement.
Together, the systems of record, systems of engagement and systems of insight provide a complete ecosystem for the modern business enabling responsive mobile applications, with the trusted reliability of the systems of record and added intelligence of the systems of insight.
Figure 1-9 shows that these three groups of systems are linked together and exchange data.
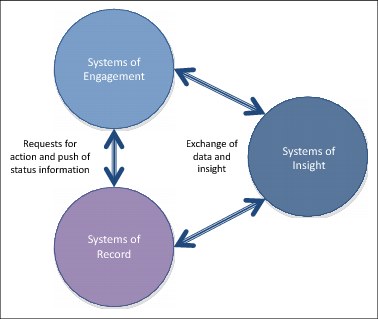
Figure 1-9 Connecting systems of record, systems of engagement and systems of insight
The systems of insight typically receive data from the systems of record and systems of engagement and then distribute both data and analytical insight in return. Between the systems of record and systems of engagement are requests for action and push messages that update status related to the activities in either group of systems.
Systems of record, systems of engagement, and systems of insight each have different architecture and governance requirements. These types of systems have the following differences:
•Systems of engagement support individuals.
They combine functions supported by multiple parts of the business to create a unique and complete experience for the users they support. Their function tends to evolve rapidly and they must to be available whenever the individual needs them. The systems of engagement use caches and queues to provide their services even when the systems of record and systems of insight are not be available.
•Systems of record support the business and focus on efficient processing of transactions.
They are typically long lived and each maintains their own database of information. This information is typically organized around business activity or transactions. This information from the systems of record must be fed into the systems of insight to enable the systems of insight to keep up-to-date with the latest activity in the business.
•Systems of insight need to support a wide variety of data types, sources, and usage patterns.
They must be highly adaptive to the increasing requirements for data and analytics.
From a governance perspective, all systems need to be secure. The systems of insight provide much of the archiving and retention support for the other systems. Data quality is managed in the systems of record and systems of engagement at the point where data enters the systems. The only exception to this is the quality work performed on the feeds of data from external sources. However, this is limited because subsequent updates from the external source will overwrite any data that has been corrected.
Erin overlays the EbP systems on top of the ecosystem (Figure 1-10). The clinical trials application is shown in the systems of engagement. The manufacturing, sales, and other administrative systems are systems of record and the new analytics capability, with its associated data, is sitting in the data reservoir as a system of insight. This gives her a scope for the data reservoir.
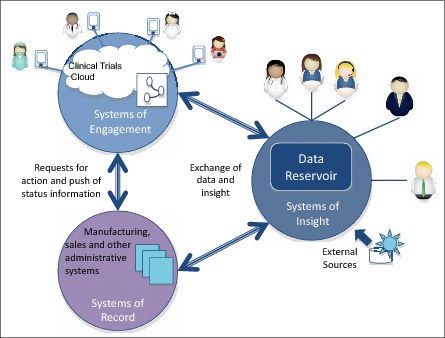
Figure 1-10 EbP systems overlaid on systems or record, systems of engagement, and systems of insight ecosystem
1.3.6 The data reservoir
As a system of insight, the data reservoir is the data and analytics intensive part of the ecosystem that supports all these teams:
•The research team in their daily work
•Providing sales with the latest information about customers and products
•Supports the finance team with ad hoc data queries
Much of the operation of the data reservoir is centered on a catalog of the information that the data reservoir is aware of. The catalog is populated using a process that is called curation (Figure 1-11).

Figure 1-11 Advertising data for the data reservoir
The first type of curation is the advertisement of existing data sources in the catalog (Item 1 in Figure 1-11 on page 13). A description of a data source is created either by the owner of the data source or a trusted curator, and stored in the catalog (Item 2 in Figure 1-11 on page 13). For more information about information curators, see “Role Classifications” on page 41.
The description of the data source includes these details:
•Data source name, short description, and long description
•The type of data that is stored in the data source and its classification
•The structure of the data (if present)
•The location of the data, in terms of its physical location and electronic address
This description of the data source helps someone looking for data to discover and assess the appropriate data sources (Item 3 in Figure 1-12).

Figure 1-12 Data discovery in the data reservoir
After it is clear that data from a particular data source is needed in the data reservoir, it is provisioned into the data reservoir. The provisioning process typically includes an initial copy of data into one or more of the data reservoir repositories, followed by incremental updates to the data as it changes in the original sources.
In special circumstances, a real-time or federated approach can be used to provision the data source for the reservoir.
Real-time interfaces retrieve data from the data source on demand. Federation enables data to be returned in real time from multiple data sources in a single response. These approaches have the advantage that a copy of the data source does not need to be maintained in the data reservoir repositories. However, the data source must have the capacity to handle the unpredictable query load from the data reservoir users.
Real-time provisioning could be an initial approach for some new data sources that can be changed to a copy style of provisioning as the number of users (and hence the load on the original data source) increases.
Whichever way the data source is provisioned into the data reservoir, after the wanted data is located, it is copied into a sandbox for exploration (Item 5 in Figure 1-13)

Figure 1-13 Data exploration and the data reservoir
Data exploration is the process of experimenting with and visualizing data to understand the patterns and trends in that data. It often involves reformatting data and combining values from multiple data sources. This is one of the reasons why data is copied into a sandbox for this work. The other reason is to limit the direct access to the data reservoir repositories to, ideally, just the data reservoir services, so that the use of data can be properly logged and audited.
Data exploration might result in the development of new analytics models and business rules. These new functions might be deployed in the data reservoir or in the connected systems of record or systems of engagement (Item 6 in Figure 1-14).

Figure 1-14 Deploying analytics into production
The deployment of these functions involves some quality checks, potentially some reformatting of the data exchange that the function expects, and then integration into the deployment environment.
Another common role for the data reservoir is to act as a data distribution broker between different systems that are connected to it (Figure 1-15).

Figure 1-15 Data distribution from the data reservoir
The latest values from original data sources are continuously entering the data reservoir (Item 1 in Figure 1-15). Selected values can be distributed to other systems (Item 2 in Figure 1-15). These values can also be accessed on demand through real-time interfaces, providing the latest values when they are needed.
1.3.7 Inside the data reservoir
From the outside, the data reservoir seems to be a simple collection of data sources. Inside the data reservoir is a complex set of components that are actively governing, protecting, and managing the data. The internals of the data reservoir are presented as a series of levels of subsystem and component diagrams of increasing levels of detail.
Figure 1-16 shows level 1, the high-level structure of the data reservoir.
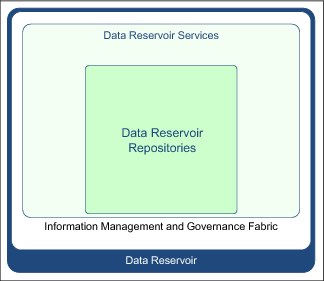
Figure 1-16 Level 1: The data reservoir's high-level structure
Data reservoir repositories
In the center are the data repositories. These repositories provide shared data to the organization. Each repository either supports unique workload capabilities or offers a unique perspective on a collection of data. New repositories can be added and obsolete ones removed during the lifetime of the data reservoir.
The same kind of data can be present in multiple repositories.
Data reservoir services
It is the responsibility of the data reservoir services to keep these copies in synchronization, and to control and support access to the data reservoir repositories. The data reservoir services include a catalog to enable people to locate the data they need and verify that it is suitable for their work.
Information management and governance fabric
Underpinning the data reservoir services is specialist middleware that provides the information management and governance fabric. This middleware includes provisioning engines for moving and transforming data, a workflow engine to enable collaboration between individuals working with the data, and monitoring, access control, and auditing functions.
1.3.8 Initial mapping of the data reservoir architecture
When Erin overlays her initial architecture sketch (Figure 1-7 on page 9) on the data reservoir structure (Figure 1-17), she begins to separate the different concerns of the data-driven ecosystem. This approach clarifies the boundary of the shared data and its management process from the users and feeds interacting with it.

Figure 1-17 EbP's requirements overlaid on the data reservoir's high-level structure
Erin classifies the shared operational data hubs and harvested data stores as data reservoir repositories (Item 1 in Figure 1-17). The real-time analysis of patient needs becomes a data reservoir service (Item 2 in Figure 1-17).
The object cache for the clinical trials cloud is also a data reservoir service rather than a repository, even though it stores data (Item 3 in Figure 1-17). This is because its contents are derived from the harvested data stores, so it is a type of materialized view for the data reservoir. This cache is in the clinical trials cloud. However, logically it sits inside the data reservoir because it is managed and governed by the data reservoir processes.
The next level of detail of the data reservoir architecture gives some structure to the data reservoir services (Figure 1-18).

Figure 1-18 Level 2: The data reservoir's internal subsystems
Level 2 of the data reservoir architecture helps Erin identify that some users, such as Callie Quartile the data scientist, are able to work with raw data. However, others, such as the accounts manager Tom Tally, need simpler views of the data (Figure 1-19).

Figure 1-19 Internal subsystems in EbP's data reservoir
Erin connects the advanced analytical modeling to raw data interaction (Item 1 in Figure 1-19) and the ad hoc analysis to view-based interaction (Item 2 in Figure 1-19). She also added the different enterprise IT interaction subsystems because she knows she needs them to connect to their existing applications and new data feeds from eternal sources (Item 3 in Figure 1-19).
The fine detail architecture picture (Figure 1-20) adds pattern-based components that act as a checklist for any additional detail that Erin wants to highlight at this stage. Chapter 3, “Logical Architecture” on page 53 covers these components in detail. Much of the additional detail describes the kinds of data repositories that could be supported in a data reservoir (an organization rarely deploys all possible types of repositories).
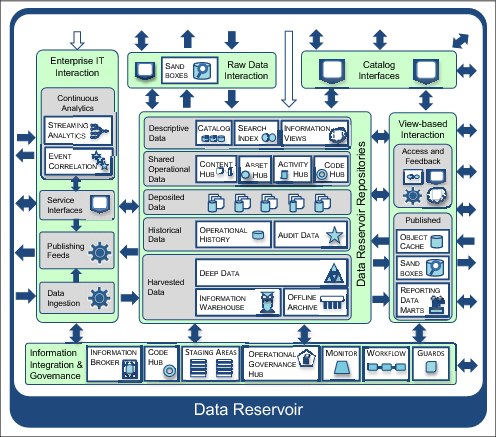
Figure 1-20 Level 3: The data reservoir's internal detail
In the data reservoir architecture, each type of repository characterizes a different kind of information collection, or data set, in terms of the disposition of its content (that is structure, current or historical values, read/write, or read-only). For example, the Operational History repository stores historical data from a single operational system. Except for time stamps, this data is stored in the same format as the original system so it can be used for operational reporting, quality analysis, and archiving for that operational system. There is a different instance of the Operational History repository for each operational system that needs this type of store. Deep Data, however, holds raw detailed data from many sources, along with intermediate and final results from analytics.
The infrastructure that hosts the data reservoir repositories is selected based on the amount of data and the anticipated workload. It is possible that a general-purpose data platform, such as Apache Hadoop, can support all of the selected repositories. However, it is more common to see a mix of infrastructure (including data warehouse and analytics appliances) making up the infrastructure platform of the data reservoir.
Erin decides to focus on selecting the data repositories and usage paths at this stage. She will work with Gary Geeke, their infrastructure expert, after they have a clear view of the volume, variety, and velocity of data for the data reservoir (Figure 1-21).
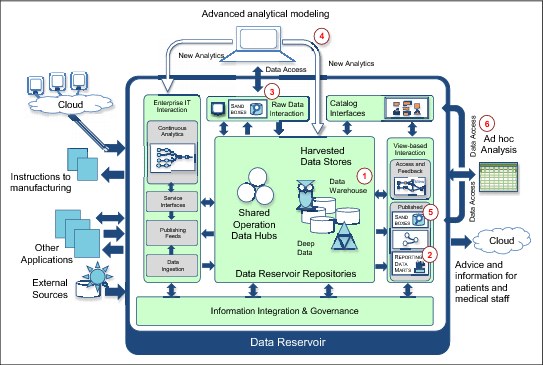
Figure 1-21 Internal detail of EbP's data reservoir
Erin notices that there is an information warehouse in the data reservoir architecture and decides to include their existing data warehouse (Item 1 in Figure 1-21) in the data reservoir. It contains much of the data that will be needed for the data reservoir.
Erin also adds the data marts populated from the data warehouse (Item 2 in Figure 1-21). They are added to the view-based Interaction because they are derived from the data warehouse and are entirely recreatable. They also offer simplified, specialized views of different subsets of the data reservoir, which further confirms their place in the view-based interaction subsystem.
Erin adds a sandbox and data access interface to the raw data interaction (Item 3 in Figure 1-21). The data scientist will not access the data reservoir repositories directly. The raw data interaction subsystem allows them to access and copy any data that they need, ensuring they have access rights to the data they are requesting and monitoring their data use.
Erin adds detail around the advanced analytical modeling, showing it creating analytical models that run both in the data reservoir repositories and the continuous analytics service (Item 4 in Figure 1-21). They must work out a quality assurance process for the deployment of these models because both hosting destinations will be operational production systems when they are supporting the personalized medicine business. The research teams are not used to the discipline associated with working with operational systems.
Erin also added sandboxes to the view-based interaction (Item 5 in Figure 1-21) to allow the business teams to create copies of data they want to manipulate. This means they can view the data descriptions in the catalog, access the data through an API, and copy it into a sandbox (Item 6 in Figure 1-21).
At this stage, Erin’s confidence in the lifecycle of the data in the data reservoir and how it will be accessed increases.
The data reservoir architecture helps to classify and organize the different data repositories, processing engines, and services required for big data and analytics.
1.3.9 Additional use cases enabled by a data reservoir
Looking into the future, the data reservoir can act as the analytics source for the customer care organization in these ways:
•The customer marketing team can request subsets of data for selected marketing campaigns.
•The manufacturing team might want to analyze the demand for different types of treatments so they can plan for improvements to the manufacturing process.
After data is organized, trusted, and accessible, it helps people to understand how their part of the organization is working and improve it.
1.3.10 Security for the data reservoir
As you can imagine, the data reservoir has the potential to hold a copy of all kinds of the valuable data for an organization. In EbP's case, it will contain their valuable pharmaceutical IP that they have built their business on, plus details of their customers, manufacturing activity, and suppliers. In the wrong hands, this data could be leaked to external parties or be used to exploit weakness in their operations, exposing them to further fraud. Security is a key concern.
Security requirements come from various sources:
•An assessment of the key security threats that need to be guarded against, including:
– Deliberate (theft, denial of service, corruption, or removal of information)
– Accidental
– Failures
•Legal, statutory, regulatory, and contractual requirements
•Business requirements and objectives
This section considers how security should be implemented in the data reservoir.
Figure 1-22 shows the stakeholders for data reservoir security and the effect it should achieve.

Figure 1-22 Stakeholders for data reservoir security
The data reservoir must provide a useful service to legitimate users and both source and consuming systems. It must provide evidence to regulators and auditors that information is being properly managed. Finally, it must effectively exclude intruders and unauthorized users.
This protection must extend over the IT infrastructure, data analytics, and the data refineries that manage the data in the data reservoir.
Erin and Ivor Padlock, EbP's security officer, defined these as EbP's core security principles:
•An individual's privacy will be maintained.
•Information is only made available on a need to know basis.
•The organization's information will be protected from misuse and harm.
•Only approved users, devices, and systems can access the organization's data.
These principles should be thought of as the high-level goals of the data reservoir's security. The implementations of these goals are delivered through security controls.
Building the security manual for the data reservoir
The following security control categories list the different aspects of security that need to be considered. These are based on the guidance from the ISO27000-5 set of security standards.
These control categories are the chapters in the data reservoir's security manual. Each focuses on how a particular facet of security will operate.
•Vitality of security governance
Vitality of security ensures that the information security of the data reservoir provides adequate protection despite the changing risk landscape.
Vitality includes processes for raising concerns and new requirements for security of the data reservoir. There should be clear responsibilities on who should review and update the security processes.
•Information classification and handling principles
The information classification and handling principles clarify kinds of information, and the requirements for accessing and using information.
The classification schemes are the key to ensuring that appropriate security is applied to data based on its value, confidentiality, and sensitivity. The classifications are stored in the catalog and linked to the descriptions of the data in the data reservoir. These classifications are used by the data reservoir services to ensure that data is properly protected.
Many organizations have security classification schemes defined already and, if possible, these should be adopted for the data reservoir so they are familiar to its users. Otherwise, there is a default set of classification schemes defined on IBM developerWorks®.
•Information curation
Information curation identifies catalogs, and classifies and describes collections of information to define the scope and ownership of information in the data reservoir and the appropriate protection responsibilities.
Related to classification, curation ensures that the way data is described in the catalog is accurate. A high-quality catalog means that data can be found, understood, and used appropriately. There are three control points where curation occurs and there is a potential to ensure the protection of data or the people who use it:
– When a new data source is advertised in the catalog for the data reservoir. This is a key point where data is classified. Has the correct classification been used?
– When a new project is started and the project leader establishes a list of the data sources that the team will use. Have the most appropriate data sources been selected?
– When a person is searching for data and leaves feedback or ratings. Is this feedback highlighting a valid problem either in the data or in the description of the data?
•Provision of information
Provision of information is used to accomplish these objectives:
– To ensure that information in the data reservoir is appropriately hosted, classified, and protected, while still being made available to authorized users.
– To ensure that users of the reservoir are confident that information will be available whenever it is needed.
Assuming that data has been correctly curated and classified, the data reservoir infrastructure and services should provide appropriate custodianship of the data.
•Maintenance of information trust
Maintenance of information trust ensures that users of information know the pedigree of the information they are using
The data reservoir should maintain lineage for the data that it manages, and that lineage data should be trusted and protected. The data reservoir must ensure that data flowing into the data reservoir comes from verified sources (Figure 1-23).

Figure 1-23 Trusting data flowing into the data reservoir
•User access of information
User access of information ensures only authorized users access information and they use it correctly. An organization must answer several questions around the way that access control is managed. Here is a set of candidate questions to consider:
– Who are the people who have a right to access the information in the reservoir?
• All employees?
• Contractors?
• Business partners?
– Who vouches for (and validates) a user's access rights?
– What are the terms and conditions you want users of the data reservoir to sign up to?
– What are the risks you need to guard against?
– How granular should security access be controlled (collection, entity, attribute)?
– What are the guarantees that the data reservoir offers to information providers and users?
– How deep does the specific user identification penetrate?
• Does the repository know who the user is?
• Are repositories accessed directly?
– What is valid processing in the data reservoir?
• What is the lifecycle that information in the reservoir goes through?
• Does its security requirements change at different stage of its lifecycle?
• What is the analytics lifecycle and what are the security implications?
• What are the software lifecycle processes and how is that process assured?
– How does the context of a request affect access rights?
Typically a data reservoir is set up to ensure that no user accesses the data reservoir repositories directly. Authorized processes access the data reservoir's repositories and people access the data from the data reservoir through the services. In addition, there are the following items to consider:
– Individuals are identified through a common authentication mechanism (for example Lightweight Directory Access Protocol (LDAP)).
– Data is classified in the catalog.
– Access granted by business owners.
– Access controlled by data reservoir services.
– All activity is monitored by probes that store log information in the audit data zone.
After these questions have been answered, a number of end-access services that must be covered by access management. These are covered by Figures 24-27.
Which data is discoverable in the catalog (Figure 1-24)?
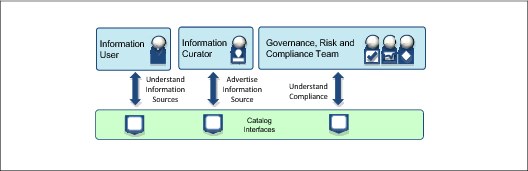
Figure 1-24 What data is discoverable in the catalog?
What data can be extracted from the sandboxes and who can access the sandboxes (Figure 1-25)?
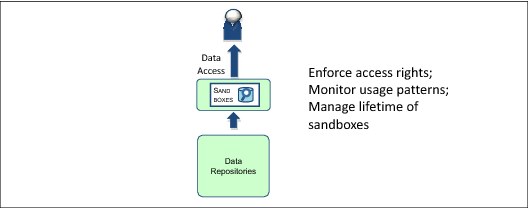
Figure 1-25 What data can be extracted from the data reservoir repositories?
What data values can be located with search technology or accessed by the real-time interfaces (Figure 1-26)?

Figure 1-26 What data values can be located and accessed?
Finally, what access to data is given to the teams managing the data reservoir infrastructure (Figure 1-27)? Can they see the data values?
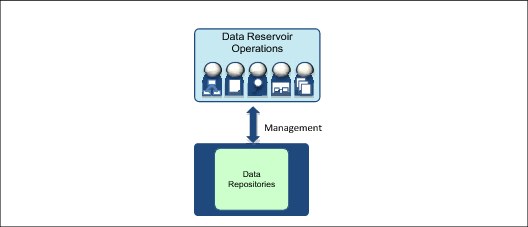
Figure 1-27 What access to data do the data reservoir operations and maintenance teams have?
•Protection of information subject
Protection of information subject ensures the privacy and appropriate use of information about an individual.
Most data reservoirs store personal data. There are laws on how this data must be managed in most countries. The data reservoir must respect these requirements.
•Analytics validation
Analytics validation ensures that the insight generated is meaningful and ethical.
The consolidated and linked data in the data reservoir enables the analytics teams to create detailed insights into individuals. How does the organization decide which analytics are appropriate for its business? The organization needs a framework for deciding on the appropriateness of the analytics they develop and ensuring proper safe-guards are in place.
•Data refinery development
Data refinery development ensures software that is transforming information is properly reviewed, tested, and approved.
The development team building data refinery services need proper checks to ensure erroneous or malicious code cannot be introduced into the data reservoir that could corrupt or leak data.
•Return of information
Return of information to ensure that information is returned or deleted when no longer needed.
Sensitive data represents a risk, so there might be occasions where data is only retained in the data reservoir for short periods to minimize this risk. How do you ensure that all copies of this data are eliminated? Similarly, there are regulations that enable a person to request that information about them is deleted from a company's data stores. How does the data reservoir show that this has happened?
•Maintenance of enterprise memory
Maintenance of enterprise memory ensures that records are correctly managed and retained.
The data reservoir can be used as an online archive for many systems, in which case it must take on the responsibility for the proper retention of this data.
•Incident reporting and management
Incident reporting and management ensures that potential and actual security breaches are reported and resolved in a timely and effective manner.
Incident reporting and management should be a closed loop, ensuring that all incidents are raised, reviewed, and the appropriate action is taken. There should be reporting to highlight the kinds, levels, and severity of incidents that are occurring over time.
•Integrity of information security
Integrity of information security ensures that the information is used to guard the data reservoir is correctly managed.
This might seem obvious, but if anyone can access and change audit information, then it is not possible to trust that it is an accurate record of the activity in the data reservoir.
1.3.11 What does IBM security technology do?
Technology's role in protecting the data reservoir is to provide automation at key points in the processes and services that surrounds the data, including the following items:
•Centralized management of identity authentication of users connecting to the data reservoir
•Classification of data and detection of incorrectly classified data
•Implementation of rules associated with classification
•Auditing, monitoring, and report generation of all activity in the data reservoir
•Encryption, masking, and redaction of data both at rest and in motion
•Authorization of access to data reservoir repositories and services
•Automated choreography of actions to grant/revoke access, resolve issues, investigate suspicious activity, and audit access
Each of these seeks to support the education, manual procedures, and controls that create a culture where the protection of data is a priority.
1.4 Summary and next steps
In the past, analytics has been a back-office function that reported on the past activities of the organization. It enabled a business to understand trends in their operation or market so they could plan for the future.
Real-time analytics and general access to a broader range of data is disruptive, often causing the boundaries between the traditional silos in an organization to break down as people start to see a broader view of the organization and desire more responsive decisions. Mobile applications provide more data and enable real-time insight to be delivered to individuals, further accelerating the demand for a more responsive organization.
Together, the systems of record, systems of engagement, and systems of insight provide a complete ecosystem for the modern business. This system enables responsive mobile applications, with the trusted reliability of the systems of record and added intelligence of the systems of insight.
Systems of record, systems of engagement, and systems of insight each have different architecture and governance requirements. The data reservoir provides a generic architecture for a governed and managed system of insight.
Data Reservoir = Efficient Management, Governance, Protection, and Access.
The data reservoir architecture is presented as a number of levels of increasing detail that helps to classify and organize the different data repositories, processing engines, and services required for big data and analytics. It also acts as a checklist to identify all of the capabilities that are needed to manage a system of insight.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.