


GDPS/PPRC HyperSwap Manager
In this chapter we discuss the capabilities and prerequisites of the GDPS/PPRC HyperSwap Manager (GDPS/PPRC HM) offering.
GDPS/PPRC HM is designed to extend the availability attributes of a Parallel Sysplex to disk subsystems, whether the Parallel Sysplex and disk subsystems are in a single site, or whether the Parallel Sysplex and the primary/secondary disk subsystems span across two sites.
It provides the ability to transparently switch primary disk subsystems with the secondary disk subsystems for either a planned or unplanned disk reconfiguration. It also supports disaster recovery capability across two sites by enabling the creation of a consistent set of secondary disks in case of a disaster or potential disaster.
However, unlike the full GDPS/PPRC offering, GDPS/PPRC HM does not provide any resource management or recovery management capabilities.
The functions for protecting data provided by GDPS/PPRC HM include the following functions:
•Ensuring the consistency of the secondary data in the event of a disaster or suspected disaster, including the option to also ensure zero data loss
•Transparent switching to the secondary disk using HyperSwap
•Management of the remote copy configuration for System z and non-System z platform data
Because GDPS/PPRC HM is a subset of the GDPS/PPRC offering, you might want to skip to the comparison presented in Table 4-1 on page 124 if you have already read Chapter 3, “GDPS/PPRC” on page 51.
4.1 Introduction to GDPS/PPRC HM
GDPS/PPRC HM provides a subset of GDPS/PPRC capability with the emphasis being more on the remote copy and disk management aspects. At its most basic, GDPS/PPRC HM extends Parallel Sysplex availability to disk subsystems by delivering the HyperSwap capability to mask disk outages caused by planned disk maintenance or unplanned disk failures. It also provides monitoring and management of the data replication environment, including the freeze capability.
In the multisite environment, GDPS/PPRC HM provides an entry-level disaster recovery offering. Because GDPS/PPRC HM does not include the systems management and automation capabilities of GDPS/PPRC, it cannot provide in and of itself the short RTO that is achievable with GDPS/PPRC. However, GDPS/PPRC HM does provide a cost-effective route into full GDPS/PPRC at a later time if your Recovery Time Objectives change.
4.1.1 Protecting data integrity and data availability with GDPS/PPRC HM
In 2.2, “Data consistency” on page 17, we point out that data integrity across primary and secondary volumes of data is essential to perform a database restart and accomplish an RTO of less than an hour. This section provides details of how GDPS automation in GDPS/PPRC HM is designed to provide both data consistency in the event of mirroring problems, and data availability in the event of disk problems.
There are two types of disk problems that trigger a GDPS automated reaction:
•PPRC Mirroring problems (FREEZE triggers)
There is no problem with writing to the primary disk subsystem, but there is a problem mirroring the data to the secondary disk subsystem. This is discussed in “GDPS Freeze function for mirroring failures” on page 96.”
•Primary disk problems (HyperSwap triggers)
There is a problem writing to the primary disk: either a hard failure, or the disk subsystem is not accessible or not responsive. This is discussed in “GDPS HyperSwap function” on page 100.
GDPS Freeze function for mirroring failures
GDPS uses automation, keyed off events or messages, to stop all mirroring when a remote copy failure occurs. In particular, the GDPS automation uses the IBM PPRC FREEZE and RUN architecture, which have been implemented as part of Metro Mirror on IBM disk subsystems and also by other enterprise disk vendors. In this way, if the disk hardware supports the FREEZE/RUN architecture, GDPS can ensure consistency across all data in the sysplex (consistency group) irrespective of disk hardware type. This preferred approach differs from proprietary hardware approaches that only work for one type of disk hardware. For an introduction to data consistency with synchronous disk mirroring, see “PPRC data consistency” on page 24.
When a mirroring failure occurs, this problem is classified as a FREEZE trigger and GDPS stops activity across all disk subsystems at the time the initial failure is detected, thus ensuring that the dependant write consistency of the remote disks is maintained. This is what happens when a GDPS performs a FREEZE:
•Remote copy is suspended for all device pairs in the configuration.
•While the suspend command is being processed for each LSS, each device goes into a long busy state. When the suspend completes for each device, z/OS marks the device unit control block (UCB) in all connected operating systems to indicate an Extended Long Busy (ELB) state.
•No I/Os can be issued to the affected devices until the ELB is thawed with the PPRC RUN or until it times out (the consistency group timer setting commonly defaults to 120 seconds, although for most configurations a longer ELB is recommended).
•All paths between the PPRCed disks are removed, preventing further I/O to the secondary disks if PPRC is accidentally restarted.
Because no I/Os are processed for a remote-copied volume during the ELB, dependent write logic ensures the consistency of the remote disks. GDPS performs FREEZE for all LSS pairs that contain GDPS-managed mirrored devices.
It is important to note that because of the dependent write logic, it is not necessary for all LSSs to be frozen at the same instant. In a large configuration with many thousands of remote copy pairs, it is not unusual to see short gaps between the times when the FREEZE command is issued to each disk subsystem. Because of the ELB, however, such gaps are not a problem.
After GDPS performs the Freeze and the consistency of the remote disks is protected, what GDPS does depends on the client’s PPRCFAILURE policy (also known as Freeze policy). The policy as described in “Freeze policy (PPRCFAILURE policy) options” on page 98 will tell GDPS to take one of these three possible actions:
•Perform a RUN against all LSSs. This will remove the ELB and allow production systems to continue using these devices. The devices will be in remote copy-suspended mode, meaning that any further writes to these devices are no longer being mirrored. However, the changes are being tracked by the hardware such that at a later time, only the changed data will be resynchronized to the secondary disks. Refer to “FREEZE and GO” on page 99 for more detail about this policy option.
•System-RESET all production systems. This ensures that no more updates can occur to the primary disks, because such updates would not be mirrored and it would not be possible to achieve RPO zero (zero data loss) if a failure occurs (or if the original trigger was an indication of a catastrophic failure). Refer to “FREEZE and STOP” on page 98 for more detail about this option.
•Try to determine if the cause of the PPRC suspension event was a permanent or temporary problem with any of the secondary disk subsystems in the GDPS configuration. If GDPS can determine that the PPRC failure was caused by the secondary disk subsystem, this would not be a potential indicator of a disaster in the primary site. In this case, GDPS would perform a RUN and allow production to continue using the suspended primary devices. If, however, the cause cannot be determined to be a secondary disk problem, GDPS would system-RESET all systems, guaranteeing zero data loss. Refer to “FREEZE and STOP CONDitionally” on page 99 for further details.
GDPS/PPRC HM uses a combination of storage subsystem and sysplex triggers to automatically secure, at the first indication of a potential disaster, a data-consistent secondary site copy of your data using the FREEZE function. In this way, the secondary copy of the data is preserved in a consistent state, perhaps even before production applications are aware of any issues. Ensuring the data consistency of the secondary copy ensures that a normal system restart can be performed, instead of having to perform DBMS forward recovery actions. This is an essential design element of GDPS to minimize the time to recover the critical workloads in the event of a disaster in the primary site.
You will appreciate why such a process must be automated. When a device suspends, there is simply not enough time to launch a manual investigation process. The entire mirror must be frozen by stopping further I/O to it, and then letting production run with mirroring temporarily suspended, or stopping all systems to guarantee zero data loss based on the policy.
In summary, freeze is triggered as a result of a PPRC suspension event for any primary disk in the GDPS configuration, that is, at the first sign of a duplex mirror that is going out of duplex state. When a device suspends, all attached systems are sent a “State Change Interrupt” (SCI). A message is issued in all of those systems and then each system must issue multiple I/Os to investigate the reason for the suspension event.
When GDPS performs a freeze, all primary devices in the PPRC configuration suspend. This will result in significant SCI traffic and many messages in all of the systems. GDPS, in conjunction with z/OS 1.13 and microcode on the DS8700/DS8800 disk subsystems, supports reporting suspensions in a summary message per LSS instead of at the individual device level. When compared to reporting suspensions on a per device basis, the Summary Event Notification for PPRC Suspends (PPRCSUM) dramatically reduces the message traffic and extraneous processing associated with PPRC suspension events and freeze processing.
Freeze policy (PPRCFAILURE policy) options
As described, when a mirroring failure is detected, GDPS automatically and unconditionally performs a Freeze to secure a consistent set of secondary volumes in case the mirroring failure could be the first indication of a site failure. Because the primary disks are in an Extended Long Busy state as a result of the freeze and the production systems are locked out, GDPS must take some action. There is no time to interact with the operator on an event-by-event basis. The action must be taken immediately and is determined by a customer policy setting, namely the PPRCFAILURE policy option (also known as the Freeze policy option). GDPS will use this same policy setting after every Freeze event to determine what its next action should be. The options are listed here:
•PPRCFAILURE=GO (Freeze&GO) - GDPS allows production systems to continue operation after mirroring has been suspended.
•PPRCFAILURE=STOP (Freeze&STOP) GDPS resets production systems while I/O is suspended.
•PPRCFAILURE=COND (Freeze & STOP conditionally) - GDPS tries to determine if a secondary disk caused the mirroring failure. If so, GDPS performs a GO. If not, GDPS performs a STOP.
FREEZE and STOP
If your RPO is zero (that is, you cannot tolerate any data loss), you must select the FREEZE and STOP policy to reset all production systems. With this setting you can be assured that no updates are made to the primary volumes after the FREEZE because all systems that can update the primary volumes are reset. You can choose to restart them when you see fit. For example, if this was a false freeze (that is, a false alarm), then you can quickly resynchronize the mirror and restart the systems only after the mirror is duplex.
If you are using duplexed Coupling Facility (CF) structures along with a FREEZE and STOP policy, it might seem that you are guaranteed to be able to use the duplexed instance of your structures in the event you have to recover and restart your workload with the frozen secondary copy of your disks. However, this is not always the case. There can be rolling disaster scenarios where prior to, following, or during the freeze event, there is an interruption (perhaps a failure of CF duplexing links) that forces CFRM to drop out of duplexing. There is no guarantee that the structure instance in the surviving site is the one that is kept. It is possible that CFRM keeps the instance in the site that is about to totally fail. In this case, there will not be an instance of the structure in the site that survives the failure.
To summarize, with a FREEZE and STOP policy, if there is a surviving, accessible instance of application-related CF structures, that instance will be consistent with the frozen secondary disks. However, depending on the circumstances of the failure, even with structures duplexed across two sites you are not 100% guaranteed to have a surviving, accessible instance of the application structures and therefore you must have the procedures in place to restart your workloads without the structures.
A STOP policy ensures no data loss. However, if this was a false freeze event, that is, it was a transient failure that did not necessitate recovering using the frozen disks, then it will result in unnecessarily stopping the systems.
FREEZE and GO
If you can accept an RPO that is not necessarily zero, you might decide to let the production systems continue operation after the secondary volumes have been protected by the Freeze. In this case you would use a FREEZE and GO policy. With this policy you avoid an unnecessary outage for a false freeze event, that is, if the trigger is simply a transient event.
However, if the trigger turns out to be the first sign of an actual disaster, you might continue operating for an amount of time before all systems actually fail. Any updates made to the primary volumes during this time will not have been replicated to the secondary disk, and therefore are lost. In addition, because the CF structures were updated after the secondary disks were frozen, the CF structure content is not consistent with the secondary disks. Therefore, the CF structures in either site cannot be used to restart workloads and log-based restart must be used when restarting applications. Note this is not full forward recovery. It is forward recovery of any data such as DB2 Group Buffer Pools that might have existed in a CF but might not have been written to disk yet. This results in elongated recovery times. The extent of this elongation will depend on how much such data existed in the CFs at that time. With a FREEZE and GO policy you may consider tuning applications such as DB2 to harden such data on disk more frequently than otherwise.
FREEZE and GO is a high availability option that avoids production outage for false freeze events. However, it carries a potential for data loss.
FREEZE and STOP CONDitionally
Field experience has shown that most occurrences of Freeze triggers are not necessarily the start of a rolling disaster, but are “false freeze” events, which do not necessitate recovery on the secondary disk. Examples of such events include connectivity problems to the secondary disks and secondary disk subsystem failure conditions.
With a COND specification, the action that GDPS takes after it performs the Freeze is conditional. GDPS tries to determine if the mirroring problem was as a result of a permanent or temporary secondary disk subsystem problem:
•If GDPS can determine that the freeze was triggered as a result of a secondary disk subsystem problem, then GDPS performs a GO. That is, it allows production systems to continue to run using the primary disks. However, updates will not be mirrored until the secondary disk can be fixed and PPRC can be resynchronized.
•If GDPS cannot ascertain that the cause of the freeze was a secondary disk subsystem, then GDPS deduces that this could be the beginning of a rolling disaster in the primary site and therefore it performs a STOP, resetting all the production systems to guarantee zero data loss. Note that GDPS cannot always detect that a particular freeze trigger was caused by a secondary disk, and some freeze events that are in fact caused by a secondary disk could still result in a STOP.
For GDPS to determine whether a freeze trigger could have been caused by the secondary disk subsystem, the IBM DS8700/DS8800 disk subsystems provide a special query capability known as the Query Storage Controller Status microcode function. If all disk subsystems in the GDPS-managed configuration support this feature, GDPS uses this special function to query the secondary disk subsystems in the configuration to understand the state of the secondaries and whether one of those secondaries could have caused the freeze. If you use the COND policy setting but all disks your configuration do not support this function, then GDPS cannot query the secondary disk subsystems and the resulting action will be a STOP.
This option could provide a useful compromise wherein you can minimize the chance that systems would be stopped for a false freeze event, and increase the chance of achieving zero data loss for a real disaster event.
PPRCFAILURE policy selection considerations
As described, the PPRCFAILURE policy option specification directly relates to Recovery Time and Recovery Point Objectives, which are business objectives. Hence, the policy option selection is really a business decision, rather than an IT decision. If data associated with your transactions are high value, it might be more important to ensure that no data associated with your transactions is ever lost, so you might decide on a FREEZE and STOP policy. If you have huge volumes of relatively low value transactions, you might be willing to risk some lost data in return for avoiding unneeded outages with a FREEZE and GO policy. The FREEZE and STOP CONDitional policy attempts to minimize the chance of unnecessary outages and the chance of data loss; however, there is still a risk of either, however small.
Most installations start out with a FREEZE and GO policy. Companies that have an RPO of zero will typically then move on and implement a FREEZE and STOP CONDitional or FREEZE and STOP policy after the implementation is proven stable.
GDPS HyperSwap function
If there is a problem writing or accessing the primary disk due to a failing, failed, or non-responsive primary disk, there is a need to swap from the primary disks to the secondary disks.
GDPS/PPRC HM delivers a powerful function known as “HyperSwap.” HyperSwap provides the ability to swap from using the primary devices in a mirrored configuration to using what had been the secondary devices, transparent to the production systems and applications using these devices. Prior to the availability of HyperSwap, a transparent disk swap was not possible. All systems using the primary disk would have been shut down (or could have failed, depending on the nature and scope of the failure) and would have been re-IPLed using the secondary disks. Disk failures were often a single point of failure for the entire sysplex.
With HyperSwap, such a switch can be accomplished without IPL and with simply a brief hold on application I/O. The HyperSwap function is designed to be completely controlled by automation, thus allowing all aspects of the disk configuration switch to be controlled through GDPS.
There are two ways that HyperSwap can be invoked:
•Planned HyperSwap
A planned HyperSwap is invoked by operator action using GDPS facilities. One example of a planned HyperSwap is where a HyperSwap is initiated in advance of planned disruptive maintenance to a disk subsystem.
•Unplanned HyperSwap
An unplanned HyperSwap is invoked automatically by GDPS, triggered by events that indicate a primary disk problem.
Primary disk problems can be detected as a direct result of an I/O operation to a specific device that fails due to a reason that indicates a primary disk problem such as:
– No paths available to the device
– Permanent error
– I/O timeout
In addition to a disk problem being detected as a result of an I/O operation, it is also possible for a primary disk subsystem to proactively report that it is experiencing an acute problem. The IBM DS8700/DS8000 models have a special microcode function known as the Storage Controller Health Message Alert capability. Problems of different severity are reported by disk subsystems that support this capability. Those problems classified as acute are also treated as HyperSwap triggers. Once systems are swapped to use the secondary disks, the disk subsystem and operating system can try to perform recovery actions on the former primary without impacting the applications using those disks.
Planned and unplanned HyperSwap have requirements in terms of the physical configuration, such as having a symmetrically configured configuration. If a client’s environment meets these requirements, there is no special enablement required to perform planned swaps. Unplanned swaps are not enabled by default and must be enabled explicitly as a policy option. This is described in detail in “HyperSwap policy (PRIMARYFAILURE policy) options” on page 103.
When a swap is initiated, GDPS will always validate various conditions to ensure that it is safe to swap. For example, if the mirror is not fully duplex, that is, not all volume pairs are in a duplex state, then a swap cannot be performed. The way that GDPS reacts to such conditions will change depending on the condition detected and whether the swap is a planned or unplanned swap.
Assuming that there are no show-stoppers and the swap proceeds, for both planned and unplanned HyperSwap, the systems that are using the primary volumes will experience a temporary pause in I/O processing. GDPS will block I/O both at the channel subsystem level by performing a Freeze, which will result in all disks going into Extended Long Busy, and also in all systems I/O being quiesced at the operating system (UCB) level. This is to ensure that no systems will use the disks until the switch is complete. During this time when I/O is paused:
•The PPRC configuration is physically switched - this involves physically changing the secondary disk status to primary. Secondary disks are protected and cannot be used by applications. Changing their status to primary allows them to come online to systems and be used.
•The disks will be logically switched in each of the systems in the GDPS configuration. This involves switching the internal pointers in the operating system control blocks (UCBs). The operating system will point to the former secondary devices instead of the current primary devices.
•For planned swaps, optionally, the mirroring direction can be reversed.
•Finally, the systems resume operation using the new, swapped-to primary devices even though applications are not aware of the fact that different devices are now being used.
This brief pause during which systems are locked out of performing I/O is known as the User Impact Time. In benchmark measurements at IBM using currently supported releases of GDPS and IBM DS8700/8800 disk subsystems, the User Impact Time to swap 10,000 pairs across 16 systems during an unplanned HyperSwap was less than 10 seconds. Most implementations are actually much smaller than this and typical impact times using the most current storage and server hardware are measured in seconds. Although results will depend on your configuration, these numbers give you a high-level idea of what to expect.
GDPS/PPRC HM HyperSwaps all devices in the managed configuration. Just as the Freeze function applies to the entire consistency group, HyperSwap is similarly for the entire consistency group. For example, if a single mirrored volume fails and HyperSwap is invoked, processing is swapped to the secondary copy of all mirrored volumes in the configuration, including those in other, unaffected, subsystems. This is because, to maintain disaster readiness, all primary volumes must be in the same site. If HyperSwap were to only swap the failed LSS, you would then have several primaries in one site, and the remainder in the other site. This would also make for a complex environment to operate and administer I/O configurations.
Why is this necessary? Consider the configuration shown in Figure 4-1. This is what might happen if only the volumes of a single LSS or subsystem were hyperswapped without swapping the whole consistency group. What happens if there is a remote copy failure at 15:00? The secondary disks in both sites are frozen at 15:00 and the primary disks (in the case of a FREEZE and GO policy) continue to receive updates.
Now assume that either site is hit by another failure at 15:10. What do you have? Half the disks are now at 15:00 and the other half are at 15:10 and neither site has consistent data. In other words, the volumes are of virtually no value to you.
If you had all the secondaries in Site2, all volumes in that site would be consistent. If you had the disaster at 15:10, you would lose 10 minutes of data with the GO policy, but at least all the data in Site2 would be usable. Using a FREEZE and STOP policy is no better for this partial swap scenario because with a mix of primary disks in either site, you have to maintain I/O configurations that can match every possible combination simply to IPL any systems.
More likely, you first have to restore mirroring across the entire consistency group before recovering systems, and this is not really practical. Therefore, for disaster recovery readiness, it is necessary that all the primary volumes are in one site, and all the secondaries in the other site.

Figure 4-1 Unworkable Metro Mirror disk configuration
HyperSwap with less than full channel bandwidth
You may consider enabling unplanned HyperSwap even if you do not have sufficient cross-site channel bandwidth to sustain the full production workload for normal operations. Assuming that a disk failure is likely to cause an outage and you will need to switch to using disk in the other site, the unplanned HyperSwap might at least present you with the opportunity to perform an orderly shutdown of your systems first. Shutting down your systems cleanly avoids the complications and restart time elongation associated with a crash-restart of application subsystems.
HyperSwap policy (PRIMARYFAILURE policy) options
Clients might prefer not to immediately enable their environment for unplanned HyperSwap when they first implement GDPS. For this reason, HyperSwap is not enabled by default. However, we strongly recommend that all GDPS/PPRC HM clients enable their environment for unplanned HyperSwap.
An unplanned swap is the action that makes most sense when a primary disk problem is encountered. However, other policy specifications that will not result in a swap are available. When GDPS detects a primary disk problem trigger, the first thing it will do will be a Freeze (the same as it performs when a mirroring problem trigger is detected). GDPS then uses the selected PRIMARYFAILURE policy option to determine what action it will take next:
•PRIMARYFAILURE=GO
No swap is performed. The action GDPS takes is the same as for a freeze event with policy option PPRCFAILURE = GO. A RUN is performed, which allows systems to continue using the original primary disks. PPRC is suspended and therefore updates are not replicated to the secondary. Note, however, that depending on the scope of the primary disk problem, it might be that all or some production workloads simply cannot run or cannot sustain required service levels. Such a situation might necessitate restarting the systems on the secondary disks. Due to the freeze, the secondary disks are in a consistent state and can be used for restart. However, any transactions that ran after the GO action will be lost.
•PRIMARYFAILURE=STOP
No swap is performed. The action GDPS takes is the same as for a freeze event with policy option PPRCFAILURE=STOP. GDPS system-RESETs all the production systems. This ensures that no further I/O occurs. After performing situation analysis, if it is determined that this was not a transient issue and that the secondaries should be used to re-IPL the systems, no data will be lost.
•PRIMARYFAILURE=SWAP,swap_disabled_action
The first parameter, SWAP, indicates that after performing the Freeze, GDPS will proceed with an unplanned HyperSwap. When the swap is complete, the systems will be running on the new, swapped-to primary disks (the former secondaries). PPRC will be in a suspended state; because the primary disks are known to be in a problematic state, there is no attempt to reverse mirroring. After the problem with the primary disks is fixed, you can instruct GDPS to resynchronize PPRC from the current primaries to the former ones (which are now considered to be secondaries).
The second part of this policy, swap_disabled_action, indicates what GDPS should do if HyperSwap had been temporarily disabled by operator action at the time the trigger was encountered. Effectively, an operator action has instructed GDPS not to perform a HyperSwap, even if there is a swap trigger. GDPS has already done a freeze. So the second part of the policy says what GDPS should do next.
The following options are available for the second parameter, which only comes into play if HyperSwap was disabled by the operator (remember, disk is already frozen):
GO This is the same action as GDPS would have performed if the policy option had been specified as PRIMARYFAILURE=GO.
STOP This is the same action as GDPS would have performed if the policy option had been specified as PRIMARYFAILURE=STOP.
PRIMARYFAILURE policy specification considerations
As indicated previously, the action that best serves RTO/RPO objectives when there is a primary disk problem is to perform an unplanned HyperSwap. Hence, the SWAP policy option is the recommended policy option.
For the STOP or GO choice, either as the second part of the SWAP specification or if you will not be using SWAP, similar considerations apply as discussed for the PPRCFAILURE policy options to STOP or GO. GO carries the risk of data loss if it becomes necessary to abandon the primary disk and restart systems on the secondary. STOP carries the risk of taking an unnecessary outage if the problem was transient. The key difference is that with a mirroring failure, the primary disks are not broken. When you allow the systems to continue to run on the primary disk with the GO option, other than a disaster which is low probability, the systems are likely to run with no problems. With a primary disk problem, with the GO option, you are allowing the systems to continue running on what are known to be disks that experienced a problem just seconds ago. If this was a serious problem with widespread impact, such as an entire disk subsystem failure, the applications are going to experience severe problems. Some transactions might continue to commit data to those disks that are not broken. Other transactions might be failing or experiencing serious service time issues. Finally, if there is a decision to restart systems on the secondaries because the primary disks are simply not able to support the workloads, there will be data loss. The probability that a primary disk problem is a real problem that will necessitate restart on the secondary disks is much higher when compared to a mirroring problem. A GO specification in the PRIMARYFAILURE policy increases your overall risk for data loss.
If the primary failure was of a transient nature, a STOP specification results in an unnecessary outage. However, with primary disk problems it is likely that the problem could necessitate restart on the secondary disks. Therefore, a STOP specification in the PRIMARYFAILURE policy avoids data loss and facilitates faster restart.
The considerations relating to CF structures with a PRIMARYFAILURE event are similar to a PPRCFAILURE event. If there is an actual swap, the systems continue to run and continue to use the same structures as they did prior to the swap; the swap is transparent, With a GO action, you continue to update the CF structures along with the primary disks after the GO. If you need to abandon the primary disks and restart on the secondary, the structures are inconsistent with the secondary disks and are not usable for restart purposes. This will elongate the restart, and therefore your recovery time. With STOP, if you decide to restart the systems using the secondary disks, there is no consistency issue with the CF structures because no further updates occurred on either set of disks after the trigger was detected.
Failover/Failback support
When a primary disk failure occurs and the disks are switched to the secondary devices, PPRC Failover/Failback (FO/FB) support eliminates the need to do a full copy when reestablishing replication in the opposite direction. Because the primary and secondary volumes are often in the same state when the freeze occurred, the only difference between the volumes are the updates that occur to the secondary devices after the switch. Failover processing sets the secondary devices to primary suspended status and starts change recording for any subsequent changes made. When the mirror is reestablished with failback processing, the original primary devices become secondary devices and a resynchronization of changed tracks takes place.
GDPS/PPRC HM transparently exploits the PPRC FO/FB capability if it is installed on the disk subsystems. This support mitigates RPO exposures by reducing the amount of time needed to resynchronize mirroring after a HyperSwap. The resync time will depend on how long mirroring was suspended and the number of changed tracks that must be transferred.
All disk subsystems in your GDPS configuration, in both Site1 and Site2, must support PPRC Failover/Failback for GDPS to exploit this capability.
Protection during IPL
A system cannot be IPLed using a disk that is physically a PPRC secondary disk because PPRC secondary disks cannot be brought online to any systems. However, a disk can be secondary from a GDPS (and application usage) perspective but physically from a PPRC perspective have simplex or primary status.
For both planned and unplanned HyperSwap, and a disk recovery, GDPS changes former secondary disks to primary or simplex state. However, these actions do not modify the state of the former primary devices, which remain in the primary state. Therefore, the former primary devices remain accessible and usable even though they are considered to be the secondary disks from a GDPS perspective. This makes it is possible to accidentally IPL from the wrong set of disks. Accidentally using the wrong set of disks can result in a potential data integrity or data loss problem.
GDPS/PPRC HM provides IPL protection early in the IPL process. During initialization of GDPS, if GDPS detects that the system coming up has just been IPLed using the wrong set of disks, GDPS will quiesce that system, preventing any data integrity problems that could be experienced had the applications been started.
4.1.2 Protecting distributed (FBA) data
|
Terminology note: The introduction of Open LUN support in GDPS has caused several changes in the terminology we use when referring to disks in this book, as explained here.
•System z or CKD disks
GDPS can manage disks used by System z systems, including z/VM, VSE, or Linux on System z disks. All these disks are formatted as Count-Key-Data (CKD) disks, the traditional mainframe format.
In most places, we refer to the disks used by a system running on the mainframe as “System z disks” or “CKD disks”; both terms are used interchangeably.
•Open LUN or FB disks
Disks that are used by systems other than those running on System z are traditionally formatted as Fixed Block Architecture (FBA or FB). In this book, we generally use the term “Open LUN disks,” “FBA disks,” or “FB disks”; these terms are used interchangeably.
|
GDPS/PPRC HM can manage the mirroring of FB devices used by non-mainframe operating systems; this also includes SCSI disks written by Linux for System z. The FBA devices can be part of the same consistency group as the mainframe CKD devices, or they can be managed separately in their own consistency group.
For a more detailed discussion of Open LUN management, see 8.1, “Open LUN Management function” on page 214.
4.1.3 Protecting other CKD data
Systems that are fully managed by GDPS are known as GDPS-managed systems or GDPS systems. These are the z/OS systems in the GDPS sysplex.
GDPS/PPRC HM can also manage the disk mirroring of CKD disks used by systems outside the sysplex: other z/OS systems, Linux on System z, VM, and VSE systems that are not running any GDPS/PPRC or xDR automation. These are known as “foreign systems”.
Because GDPS manages PPRC for the disks used by these systems, these disks must be attached to the GDPS controlling systems. With this setup, GDPS is able to capture mirroring problems and will perform a freeze. All GDPS-managed disks belonging to the GDPS systems and these foreign systems are frozen together, regardless of whether the mirroring problem is encountered on the GDPS systems’ disks or the foreign systems’ disks.
GDPS/PPRC HM is not able to directly communicate with these foreign systems. For this reason, GDPS automation will not be aware of certain other conditions such as a primary disk problem that is detected by these systems. Because GDPS will not be aware of such conditions that would have otherwise driven autonomic actions such as HyperSwap, GDPS cannot react to these events.
If an unplanned HyperSwap occurs (because it triggered on a GDPS-managed system), the foreign systems cannot and will not swap to using the secondaries. A setup is prescribed to set a long Extended Long Busy time-out (the maximum is 18 hours) for these systems such that when the GDPS-managed systems swap, these systems hang. The ELB prevents these systems from continuing to use the former primary devices. You can then use GDPS automation facilities to reset these systems and re-IPL them using the swapped-to primary disks.
4.2 GDPS/PPRC HM configurations
A basic GDPS/PPRC HM configuration consists of at least one production system, at least one controlling system, primary disks, and secondary disks. The entire configuration can be located in either a single site to provide protection from disk outages with HyperSwap, or it can be spread across two data centers within metropolitan distances as the foundation for a disaster recovery solution. The actual configuration depends on your business and availability requirements.
4.2.1 Controlling system
Why does a GDPS/PPRC HM configuration need a Controlling system? At first, you might think this is an additional infrastructure overhead. However, when you have an unplanned outage that affects production systems or the disk subsystems, it is crucial to have a system such as the Controlling system that can survive failures that might have impacted other portions of your infrastructure. The Controlling system allows you to perform situation analysis after the unplanned event to determine the status of the production systems or the disks. The Controlling system plays a vital role in a GDPS/PPRC HM configuration.
The Controlling system must be in the same sysplex as the production system (or systems) so it can see all the messages from those systems and communicate with those systems. However, it shares an absolute minimum number of resources with the production systems (typically only the sysplex couple data sets). By being configured to be as self-contained as possible, the Controlling system will be unaffected by errors that might stop the production systems (for example, an ELB event on a primary volume).
The Controlling system must have connectivity to all the Site1 and Site2 primary and secondary devices that it will manage. If available, it is preferable to isolate the Controlling system infrastructure on a disk subsystem that is not housing mirrored disks that are managed by GDPS.
The Controlling system is responsible for carrying out all PPRC and STP-related recovery actions following a disaster or potential disaster; for managing the disk mirroring configuration; for initiating a HyperSwap; and for initiating a freeze and implementing the freeze policy actions following a freeze event; reassigning STP roles, and so on.
The availability of the dedicated GDPS controlling system (or systems) in all configurations is a fundamental requirement of GDPS. It is not possible to merge the function of the controlling system with any other system that accesses or uses the primary volumes.
Improved Controlling system availability - enhanced timer support
GDPS improves recovery times for events that impact the primary time source for the sysplex, whether the time source is Server Time Protocol (STP-based) or External Time Reference (ETR-based).
These enhancements allow the GDPS Controlling system to continue processing even when the server it is running on loses its time source and becomes unsynchronized. The Controlling system is therefore able to complete any freeze or HyperSwap processing it might have started, instead of being in a disabled WTOR state. Normally, a loss of synchronization with the sysplex timing source will generate a disabled console WTOR that suspends all processing on the LPAR until a response is made to the WTOR. The WTOR message is IEA015A if the CPC that z/OS is running on is in ETR timing mode (either in an ETR network or in an STP Mixed Coordinated Timing Network (CTN)), and it is IEA394A if the CPC is in STP timing mode (either in an STP Mixed CTN or STP-only CTN).
In addition, because the Controlling system is operational, it can be used to help in problem determination and situation analysis during the outage, thus reducing further the recovery time needed to restart applications.
The Controlling system is required to perform GDPS automation in the event of a failure. Actions might include:
•Performing the freeze processing to guarantee secondary data consistency
•Coordinating HyperSwap processing
•Executing a takeover script
•Aiding with situation analysis
Because the Controlling system only needs to run with a degree of time synchronization that allows it to correctly participate in heartbeat processing with respect to the other systems in the sysplex, this system should be able to run unsynchronized for a period of time (80 minutes) using the local TOD clock of the server (referred to as local timing mode), instead of generating a WTOR.
Automated response to ETR or STP sync WTORs
GDPS on the Controlling systems, using the BCP Internal Interface, provides automation to reply to WTORs IEA015A or IEA394A when the Controlling systems are running in local timing mode. Refer to “Improved Controlling system availability - enhanced timer support” on page 107. A server in an ETR or STP network might have recovered from an unsynchronized to a synchronized timing state without client intervention. By automating the response to the WTORs, potential time outs of subsystems and applications in the client’s enterprise might be averted, thus potentially preventing a production outage.
If either WTOR IEA015A or IEA394A is posted for production systems, GDPS uses the BCP Internal Interface to automatically reply RETRY to the WTOR. If z/OS determines that the CPC is in a synchronized state, either because STP recovered or the CTN was reconfigured, it will no longer spin and continue processing. If the CPC is still in an unsynchronized state when GDPS automation responded with RETRY to the WTOR, however, the WTOR will be reposted.
The automated reply for any given system is retried for 60 minutes. After 60 minutes, you will need to manually respond to the WTOR.
4.2.2 GDPS/PPRC HM in a single site
In the single-site configuration, the Controlling systems, primary disks, and secondary disks are all in the same site, as shown in Figure 4-2. This configuration allows you to benefit from the capabilities of GDPS/PPRC HM to manage the mirroring environment, and HyperSwap across planned and unplanned disk reconfigurations. Note that a single site configuration does not provide disaster recovery capabilities, because all the resources are in the same site, and if that site suffers a disaster, then the systems and disk are all gone.
|
Note: We will continue to refer to Site1 and Site2 in this section, although this terminology here refers to the two copies of the production data in the same site.
|
Even though having a single Controlling system might be acceptable, we recommend having two Controlling systems to provide the best availability and protection. The K1 Controlling system can use “Site2” disks, and K2 can use the “Site1” disks. In this manner, a single failure will not affect availability of at least one of the Controlling systems, and it will be available to perform GDPS processing.

Figure 4-2 GDPS/PPRC HM single-site configuration
4.2.3 GDPS/PPRC HM in a two-site configuration
Another option is to use GDPS/PPRC HM with the primary disk in one site, and the secondaries in a second site, as shown in Figure 4-3. This configuration does provide the foundation for disaster recovery because the secondary copy of disk is in a separate site protected from a disaster in Site1. Additionally, GDPS/PPRC HM delivers the freeze capability, thus ensuring a consistent set of secondary disk in case of a disaster.
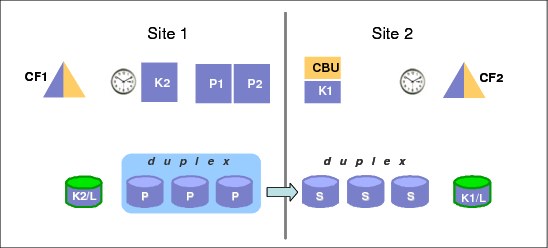
Figure 4-3 GDPS/PPRC HM two-site configuration
If you have a two-site configuration, and chose to implement only one Controlling system, it is highly recommended that you place the Controlling system in the recovery site. The advantage of this is that the Controlling system will continue to be available even if a disaster takes down the whole production site. Placing the Controlling system in the second site creates a multisite sysplex, meaning that you must have the appropriate connectivity between the sites. To avoid cross-site sysplex connections you might also consider the BRS configuration described in more detail in 3.2.4, “Business Recovery Services (BRS) configuration” on page 67.
To get the full benefit of HyperSwap and the second site, ensure that there is sufficient bandwidth for the cross-site connectivity from the primary site servers to the secondary site disk. Otherwise, although you might be able to successfully perform the HyperSwap to the second site, the I/O performance following the swap might not be acceptable.
4.2.4 GDPS/PPRC HM in a three-site configuration
GDPS/PPRC HM can be combined with GDPS/XRC or GDPS/GM in a three-site configuration. In this configuration, GDPS/PPRC HM provides protection from disk outages across a metropolitan area or within the same local site, and GDPS/XRC or GDPS/GM provides disaster recovery capability in a remote site.
We call these combinations GDPS/Metro Global Mirror (GDPS/MGM) or GDPS/Metro z/OS Global Mirror (GDPS/MzGM). In these configurations, GDPS/PPRC, GDPS/XRC, and GDPS/GM provide additional automation capabilities.
Refer to Chapter 9, “Combining Local/Metro continuous availability with out-of-region disaster recovery” on page 245 for a more detailed discussion about the capabilities and limitations of using GDPS/PPRC HM in a GDPS/MGM and GDPS/MzGM solution.
4.2.5 Other considerations
The availability of the dedicated GDPS Controlling system (or systems) in all scenarios is a fundamental requirement in GDPS. It is not possible to merge the function of the Controlling system with any other system that accesses or uses the primary volumes.
4.3 Managing the GDPS environment
The bulk of the functionality delivered with GDPS/PPRC HM relates to maintaining the integrity of the secondary disks, and being able to non-disruptively switch to the secondary volume of the Metro Mirror pair.
However, there is an additional aspect of remote copy management that is available with GDPS/PPRC HM, namely the ability to query and manage the remote copy environment using the GDPS panels.
In this section, we describe this other aspect of GDPS/PPRC HM. Specifically, GDPS/PPRC HM provides facilities to let you:
•Be alerted to any changes in the remote copy environment
•Display the remote copy configuration
•Stop, start, and change the direction of remote copy
•Stop and start FlashCopy
Note that GDPS/PPRC HM does not provide script support, so all these functions are only available through the GDPS NetView interfaces.
4.3.1 NetView interface
There are two primary user interface options available for GDPS/PPRC: the NetView 3270 panels and a browser-based graphical user interface (also referred to as the “web interface” in this document).
An example of the main GDPS/PPRC 3270-based panel is shown in Figure 4-4 on page 111.
Notice that a number of the option choices are dimmed to the color blue instead of black; these blue options are supported by the GDPS/PPRC offering but are not part of GDPS/PPRC HM.

Figure 4-4 GDPS/PPRC HyperSwap Manager main GDPS panel
This panel is relatively simple to use, with a summary of configuration status at the top of the panel and a menu of choices that a user can select from. As an example, to view the disk mirroring (Dasd Remote Copy) panels a user simply types 1 at the Selection ===> prompt and presses Enter.
GDPS web interface
The web interface is a browser-based interface alternative to the traditional 3270 panels designed to improve operator productivity. The web interface provides the same functional capability as the 3270-based panels, such as providing management capabilities for Remote Copy Management and SDF Monitoring. In addition, users can open multiple windows to allow for continuous status monitoring, while performing other GDPS/PPRC management functions.
The web interface display has three sections:
•A menu bar on the left with links to the main GDPS options
•A window list on top allowing switching between multiple open frames
•An active task frame where the relevant information is displayed and activities are performed for a selected option
The main panel of the GDPS/PPRC HM web interface is shown in Figure 4-5 on page 112. The left frame, shown under GDPS HM links, allows you to select the menu options. These options can be displayed at all times, or you can optionally collapse the frame.
|
Note: For the remainder of this section only the web interface is shown to illustrate the various GDPS management functions. The equivalent traditional 3270 panels are not shown here.
|
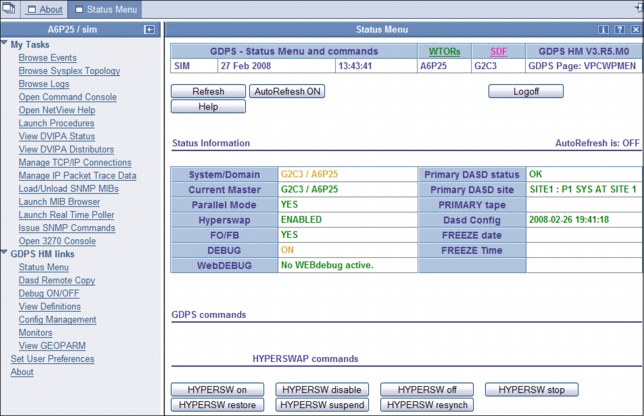
Figure 4-5 Full view of GDPS main panel with task bar and status information
Main Status panel
The GDPS Web Interface status panel shown in Figure 4-6 is the equivalent of the main GDPS panel. The information shown on this frame is what is found on the top portion of the 3270 GDPS Main panel. Additionally, this panel includes the HYPERSW commands that can be entered at a 3270 prompt in buttons at the bottom of the panel.
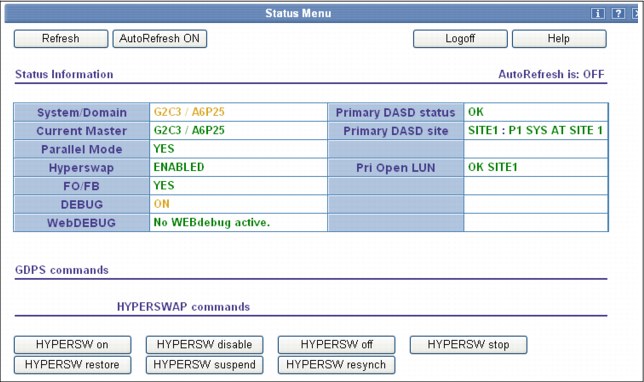
Figure 4-6 GDPS web interface - Main Status panel
Monitoring function - Status Display Facility (SDF)
GDPS also provides many monitors to check the status of disks, sysplex resources, and so on. Any time there is a configuration change or something in GDPS that requires manual intervention, GDPS will raise an alert. GDPS uses the Status Display Facility (SDF) provided by System Automation as the primary status feedback mechanism for GDPS. It is the only dynamically updated status display available for GDPS.
SDF provides a dynamically-updated color-coded panel, as shown in Figure 4-7 on page 114. If something changes in the environment that requires attention, the color of the associated field on the panel will change. At all times, the operators are to have an SDF panel within view so they will immediately become aware of anything requiring intervention or action.
The web interface can be set up to automatically refresh every 30 seconds. As with the 3270 panel, if there is a configuration change or a condition that requires special attention, the color of the fields will change based on the severity of the alert. By pointing and clicking any of the highlighted fields, you can obtain detailed information regarding the alert.

Figure 4-7 NetView SDF web interface
Remote copy panels
The z/OS Advanced Copy Services capabilities are powerful, but the native CLI and z/OS TSO and ICKDSF interfaces are not user friendly. To make it easier for operators to check and manage the remote copy environment, use the “Dasd Remote Copy” panels provided by GDPS.
For GDPS to manage the remote copy environment, you must first define the configuration (primary and secondary LSSs, primary and secondary devices, and PPRC links) to GDPS in a file called the GEOPARM file.
After the configuration is known to GDPS, you can use the panels to check that the current configuration matches the desired one. You can start, stop, suspend, and resynchronize mirroring at the volume or LSS level. You can initiate a FlashCopy, and you can reverse the direction of mirroring. These actions can be carried out at the device or LSS level, or both, as appropriate. Figure 4-8 shows the mirroring panel for CKD devices.
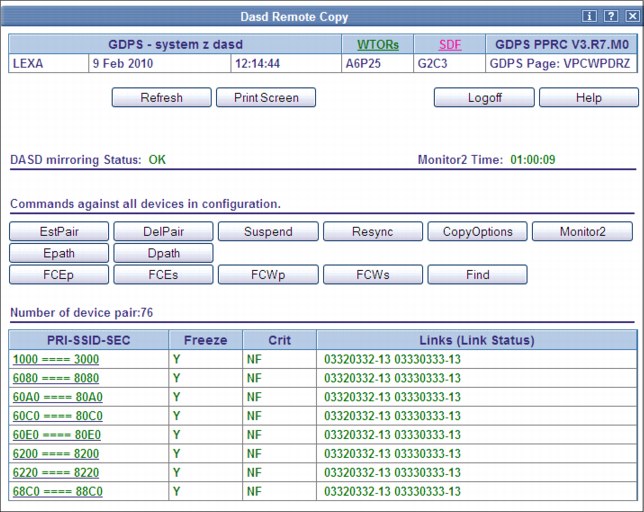
Figure 4-8 DASD Remote Copy SSID web interface
The Dasd Remote Copy frame is organized into three sections:
•A top section displays the mirroring status, and buttons for Return, Refresh and Help.
•A middle section displays actions against all the panel-displayed SSID-pairs (similar to the bottom section of the equivalent 3270 panel).
•A bottom section displays the list of all the SSID-pairs.
To perform an action on a single SSID-pair, click the pair. This brings you to a panel where you can perform the same actions as those available as line commands on the top section of the 3270 panel.
After an individual SSID-pair has been selected, the frame shown in Figure 4-9 on page 116 is displayed. The bottom of this frame shows each of the mirrored device pairs within a single SSID-pair, along with the current status of each pair. In this example, all the pairs are fully synchronized and in duplex status (indicated as DUP on the panel). Also note that the secondary devices for some of these pairs are in an alternate subchannel set (MSS1 in this case). Additional details can be viewed for each pair by clicking the button for the primary device in the pair.

Figure 4-9 Web interface DASD Remote Copy “View Devices” detail frame
If you are familiar with using the TSO or ICKDSF interfaces, you will appreciate how much more user friendly the panel is.
Remember that these GDPS-provided panels are not intended to be a remote copy monitoring tool. Because of the overhead involved in gathering the information to populate the NetView panels, GDPS only gathers this information about a timed basis, or on demand following an operator instruction. The normal interface for finding out about remote copy status or problems is the Status Display Facility (SDF).
Similar panels are provided for controlling the Open LUN devices.
4.3.2 NetView commands
Even though GDPS/PPRC HM does not support using scripts as GDPS/PPRC does, certain GDPS operations are initiated through the use of NetView commands that perform similar actions to the equivalent script command. These commands are entered at a NetView command prompt.
There are commands to perform the following types of actions (not an all inclusive list). One command would accomplish the entire action:
•Temporarily disable HyperSwap and subsequently re-enable Hyperswap.
•List systems in the GDPS and identify which are Controlling systems.
•Perform a planned HyperSwap disk switch.
•Perform a planned freeze of the disk mirror.
•Make the secondary disks usable through a PPRC failover or recover action.
•Restore PPRC mirroring to a duplex state.
•Take a point-in-time copy of the current set of secondary CKD devices. FlashCopy using COPY or NOCOPY options and the NOCOPY2COPY option to convert an existing FlashCopy taken with NOCOPY to COPY are supported. The CONSISTENT option (FlashCopy Freeze) is supported in conjunction with the COPY. and NOCOPY options.
•Reconfigure an STP-only CTN by reassigning the Preferred Time Server (PTS) and Current Time Server (CTS) roles and the Backup Time Server (BTS) and Arbiter (ARB) roles to one or more CPCs.
4.4 GDPS/PPRC HM monitoring and alerting
The GDPS SDF panel, discussed in “Monitoring function - Status Display Facility (SDF)” on page 113, is where GDPS dynamically displays color-coded alerts.
Alerts can be posted as a result of an unsolicited error situation that GDPS listens for. For example, if one of the multiple PPRC links that provide the path over which PPRC operations take place is broken, there is an unsolicited error message issued. GDPS listens for this condition and will raise an alert on the SDF panel notifying the operator of the fact that a PPRC link is not operational.
Clients run with multiple PPRC links and if one is broken, PPRC still continues over any remaining links. However, it is important for the operations staff to be aware of the fact that a link is broken and fix this situation, because a reduced number of links results in reduced PPRC bandwidth and reduced redundancy. If this problem is not fixed in a timely manner, and more links have a failure, it can result in production impact due to insufficient mirroring bandwidth or total loss of PPRC connectivity (which results in a freeze).
Alerts can also be posted as a result of GDPS periodically monitoring key resources and indicators that relate to the GDPS/PPRC HM environment. If any of these monitoring items are found to be in a state deemed to be not normal by GDPS, an alert is posted on SDF.
Various GDPS monitoring functions are executed not only on the GDPS Controlling systems, but also on the production systems. This is because, from a software perspective, it is possible that different production systems have a different view of some of the resources in the environment and although status can be normal in one production system, it might be not normal in another. All GDPS alerts generated on one system in the GDPS sysplex are propagated to all other systems in the GDPS. This propagation of alerts provides for a single, focal point of control. It is sufficient for operators to monitor SDF on the master Controlling system to be aware of all alerts generated in the entire GDPS complex.
When an alert is posted, the operator will have to investigate (or escalate, as appropriate) and corrective action will need to be taken for the reported problem as soon as possible. After the problem is corrected, this is detected during the next monitoring cycle and the alert is cleared by GDPS automatically.
GDPS/PPRC HM monitoring and alerting capability is intended to ensure that operations are notified of and can take corrective action for any problems in their environment that can impact the ability of GDPS/PPRC HM to carry out recovery operations. This will maximize the chance of achieving your IT resilience commitments.
4.4.1 GDPS/PPRC HM health checks
In addition to the GDPS/PPRC HM monitoring described, GDPS provides health checks. These health checks are provided as a plug-in to the z/OS Health Checker infrastructure to check that certain GDPS-related settings adhere to best practices.
The z/OS Health Checker infrastructure is intended to check a variety of settings to see whether these settings adhere to z/OS best practices values. For settings found to be not in line with best practices, exceptions are raised in the Spool Display and Search Facility (SDSF). If these settings do not adhere to recommendations, this can hamper the ability of GDPS to perform critical functions in a timely manner.
Often, if there are changes in the client environment, this might necessitate adjustment of various parameter settings associated with z/OS, GDPS, and other products. It is possible that you can miss making these adjustments, which might affect GDPS. The GDPS health checks are intended to detect such situations and avoid incidents where GDPS is unable to perform its job due to a setting that is perhaps less than ideal.
For example, GDPS/PPRC HM requires that the Controlling systems’ data sets are allocated on non-mirrored disks in the same site where the Controlling system runs. The Site1 Controlling systems’ data sets must be on non-mirrored disk in Site1 and the Site2 Controlling systems’ data sets must be on non-mirrored disk in Site2. One of the health checks provided by GDPS/PPRC HM checks that each Controlling system’s data sets are allocated in line with the GDPS best practices recommendations.
Similar to z/OS and other products that provide health checks, GDPS health checks are optional. Additionally, a number of the best practices values that are checked, and the frequency of the checks, are client-customizable to cater to unique client environments and requirements.
There are a few z/OS best practices that conflict with GDPS best practices. The z/OS and GDPS health checks for these result in conflicting exceptions being raised. For such health check items, to avoid conflicting exceptions, z/OS provides the capability to define a coexistence policy where you can indicate which best practice is to take precedence; GDPS or z/OS. GDPS ships sample coexistence policy definitions for the GDPS checks that are known to be conflicting with those for z/OS.
GDPS also provides a useful interface for managing the health checks using the GDPS panels. You can perform actions such as activate/deactivate or run any selected health check, view the customer overrides in effect for any best practices values, and so on. Figure 4-10 shows a sample of the GDPS Health Check management panel. In this example you see that all the health checks are enabled. The status of the last run is also shown indicating that some were successful and some resulted in a medium exception. The exceptions can also be viewed using other options on the panel.

Figure 4-10 GDPS/PPRC HM Health Check management panel .
4.5 Other facilities related to GDPS
In this section we describe miscellaneous facilities provided by GDPS/PPRC that can assist in various ways, such as reducing the window during which disaster recovery capability is not available.
4.5.1 HyperSwap coexistence
In the following sections we discuss the GDPS enhancements that remove various restrictions that had existed regarding HyperSwap coexistence with products such as Softek Transparent Data Migration Facility (TDMF) and IMS Extended Recovery Facility (XRF).
HyperSwap and TDMF coexistence
To minimize disruption to production workloads and service levels, many enterprises use TDMF for storage subsystem migrations and other disk relocation activities. The migration process is transparent to the application, and the data is continuously available for read and write activities throughout the migration process.
However, the HyperSwap function is mutually exclusive with software that moves volumes around by switching UCB pointers. The good news is that currently supported versions of TDMF and GDPS allow operational coexistence. With this support, TDMF automatically temporarily disables HyperSwap as part of the disk migration process only during the short time where it switches UCB pointers. Manual operator interaction is not required. Without this support, through operator intervention, HyperSwap is disabled for the entire disk migration, including the lengthy data copy phase.
HyperSwap and IMS XRF coexistence
HyperSwap also has a technical requirement that RESERVEs cannot be allowed in the hardware because the status cannot be reliably propagated by z/OS during the HyperSwap to the new primary volumes. For HyperSwap, all RESERVEs need to be converted to GRS global enqueue through the GRS RNL lists.
IMS/XRF is a facility by which IMS can provide one active subsystem for transaction processing, and a backup subsystem that is ready to take over the workload. IMS/XRF issues hardware RESERVE commands during takeover processing and these cannot be converting to global enqueues through GRS RNL processing. This coexistence problem has also been resolved so that GDPS is informed prior to IMS issuing the hardware RESERVE, allowing it to automatically disable HyperSwap. After IMS has finished processing and releases the hardware RESERVE, GDPS is again informed and will reenable HyperSwap.
4.5.2 GDPS/PPRC HM reduced impact initial copy and resynchronization
Performing PPRC copy of a large amount of data across a large number of devices while the same devices are used in production by application workloads can potentially impact production I/O service times when those copy operations are performed synchronously. Your disk subsystems and PPRC link capacity are typically sized for steady state update activity but not for bulk, synchronous replication. Initial copy of disks and resynchronization of disks are examples of bulk copy operations that can impact production if performed synchronously.
There is no need to perform initial copy or resynchronizations using synchronous copy, because the secondary disks cannot be made consistent until all disks in the configuration have reached duplex state.
GDPS supports initial copy and resynchronization using asynchronous PPRC-XD (also known as Global Copy). When GDPS initiates copy operations in asynchronous copy mode, GDPS monitors progress of the copy operation. When the volumes are near full duplex state, GDPS converts the replication from the asynchronous copy mode to synchronous PPRC. Performing the initial copy or resynchronization using PPRC-XD eliminates the performance impact of synchronous mirroring on production workloads.
Without asynchronous copy it might be necessary to defer these operations or reduce the number of volumes copied at any given time. This would delay the mirror from reaching a duplex state, impacting a client’s ability to recovery. Exploitation of the XD-mode asynchronous copy allows clients to establish or resynchronize mirroring during periods of high production workload, and can potentially reduce the time during which the configuration is exposed.
This function requires that all disk subsystems in the GDPS configuration support PPRC-XD.
4.5.3 Reserve Storage Pool
Reserve Storage Pool (RSP) is a type of resource introduced with z/OS 1.13 zOSMF that can simplify the management of defined but unused volumes. GDPS provides support for including RSP volumes in the PPRC configuration that is managed by GDPS. PPRC primary volumes are expected to be online in Controlling systems, and GDPS monitoring on the GDPS Controlling systems results in an alert being raised for any PPRC primary device that is found to be offline. However, because z/OS does not allow RSP volumes to be brought online to any system, GDPS monitoring recognizes that an offline primary device is an RSP volume and suppresses alerting for these volumes.
4.5.4 GDPS/PPRC HM Query Services
GDPS maintains configuration information and status information in NetView variables for the various elements of the configuration that it manages. Query Services is a capability that allows client-written NetView REXX programs to query the value of numerous GDPS internal variables. The variables that can be queried pertain to the PPRC configuration, the system and sysplex resources managed by GDPS, and other GDPS facilities such as HyperSwap and GDPS Monitors.
Query Services allows clients to complement GDPS automation with their own automation code. In addition to the Query Services function that is part of the base GDPS product, GDPS provides a number of samples in the GDPS SAMPLIB library to demonstrate how Query Services can be used in client-written code.
GDPS also makes available to clients a sample tool called the Preserve Mirror Tool (PMT), which facilitates adding new disks to the GDPS PPRC HM configuration and bringing these disks to duplex. The PMT tool, which is provided in source format, makes extensive use of GDPS Query Services and thereby provides clients with an excellent example of how to write programs to benefit from Query Services.
4.5.5 Concurrent Copy cleanup
The DFSMS Concurrent Copy (CC) function uses a “sidefile” that is kept in the disk subsystem cache to maintain a copy of changed tracks that have not yet been copied. For a PPRCed disk, this sidefile is not mirrored to the secondary subsystem. If you perform a HyperSwap while a Concurrent Copy operation is in progress, this will yield unpredictable results. GDPS will not allow a planned swap when a Concurrent Copy session exists against your primary PPRC devices. However, unplanned swaps will still be allowed. If you plan to use HyperSwap for primary disk subsystem failures (unplanned HyperSwap), try to eliminate any use of Concurrent Copy because you cannot plan when a failure will occur. If you choose to run Concurrent Copy operations while enabled for unplanned HyperSwaps, and a swap occurs when a Concurrent Copy operation is in progress, the result will be unpredictable. In the best case scenario, your copy will be invalid and must be recreated. However, because results are unpredictable, there might be other, unforeseen repercussions.
Checking for CC is performed by GDPS immediately prior to performing a planned HyperSwap. SDF trace entries are generated if one or more CC session exists, and the swap command will end with no PPRC device pairs being swapped. You must identify and terminate any CC and XRC sessions against the PPRC primary devices prior to the swap.
When attempting to resynchronize your disks, checking is performed to ensure that the secondary devices do not retain CC status from the time when they were primary devices. These are not supported as PPRC secondary devices. Therefore, GDPS will not attempt to establish a duplex pair with secondary devices if it detects a CC session.
GDPS can discover and terminate Concurrent Copy sessions that could otherwise cause errors. The function is controlled by a keyword that provides options to disable, to conditionally enable, or to unconditionally enable the cleanup of Concurrent Copy sessions on the target disks. This capability eliminates the manual task of identifying and cleaning up orphaned Concurrent Copy sessions.
4.6 GDPS/PPRC HM flexible testing and resync protection
Configuring point-in-time copy (FlashCopy) capacity in your PPRC environment provides two main benefits:
•It enables you to conduct regular DR drills or other tests using a copy of production data while production continues to run.
•It lets you save a consistent, “golden” copy of the PPRC secondary data which can be used in the event the primary disk or site is lost during a PPRC resynchronization operation.
FlashCopy and the various options related to FlashCopy are discussed in 2.6, “FlashCopy” on page 37. GDPS/PPRC HM supports taking a FlashCopy of the current secondary CKD disks. The COPY, NOCOPY and NOCOPY2COPY options are supported. Additionally, CONSISTENT FlashCopy is supported in conjunction with COPY and NOCOPY FlashCopy.
In addition, FlashCopy can be used to provide a consistent point-in-time copy of production data to be used for nondisruptive testing of your system and application recovery procedures. FlashCopy can also be used, for example, to back up data without the need for extended outages to production systems; to provide data for data mining applications; and for batch reporting and other uses.
4.6.1 Use of FlashCopy Space Efficient volumes
As discussed in “FlashCopy Space Efficient (FlashCopy SE)” on page 39, by using Space Efficient (SE) volumes, you might be able to lower the amount of physical storage needed and thereby reduce the cost associated with providing a tertiary copy of the data. GDPS provides support for FlashCopy Space Efficient volumes to be used as FlashCopy target disk volumes. Whether a target device is Space Efficient or not is transparent to GDPS; if any of the FlashCopy target devices defined to GDPS are Space Efficient volumes, GDPS will simply use them. All GDPS FlashCopy operations with the NOCOPY option, through panels or using the FLSHCOPY command or FlashCopies automatically taken by GDPS can use Space Efficient targets.
Space Efficient volumes are ideally suited to FlashCopy taken for resync protection. The FlashCopy is taken prior to the resync and can be withdrawn just as soon as the resync operation is complete. As changed tracks are sent to the secondary for resync, the time zero (T0) copy of this data is moved from the secondary to the FlashCopy target device. This means that the total space requirement for the targets is equal to the number of tracks that were out of sync, which is typically going to be significantly less than a full set of fully provisioned disks.
Another potential use of Space Efficient volumes is if you want to use the data for limited disaster recovery testing.
You must understand the characteristics of Space Efficient FlashCopy to determine whether this method of creating a point-in-time copy will satisfy your business requirements. For example, will it be acceptable to your business if, due to some unexpected workload condition, the repository on the disk subsystem for the Space Efficient devices gets full and your FlashCopy is invalidated such that you are unable to use it? If your business requirements dictate that the copy must always be guaranteed to be usable, Space Efficient might not be the best option and you can consider using standard FlashCopy instead.
4.7 GDPS tools for GDPS/PPRC HM
GDPS/PPRC also ships tools which provide function that is complementary to GDPS function. The tools represent the kind of function that all or many clients are likely to develop themselves to complement GDPS. Using tools eliminates the necessity for you to develop similar function yourself. The tools are provided in source code format, which means that if the tool does not meet your requirements completely, you can modify the code to tailor it to your needs.
The following tools are available with GDPS/PPRC HM:
•Preserve Mirror Tool (PMT) is intended to simplify and automate to a great extent the process of bringing new devices to PPRC duplex state. It also adds these devices to your running GDPS environment, while keeping the time during which the GDPS-managed PPRC mirror is not full duplex (and therefore not protected by Freeze and HyperSwap) to a minimum.
Additionally, PMT provides facilities to aid with migration procedures when using Global Copy (PPRC-XD) and PPRC to migrate data to new disk subsystems.
•Configuration Checker Tool (GEOCHECK) checks whether all devices that are online to a GDPS production system are PPRCed under GDPS control, and raises alerts if violations are encountered. It provides identification and facilitates correction for any production devices that are inadvertently left out of the GDPS-managed PPRC configuration. Not replicating some devices can prevent HyperSwap as well as recovery from catastrophic disk or site failures.
•GDPS Configuration Assistant (GeoAssistant) Tool helps you to manage the GDPS/PPRC configuration definition file (GEOPARM file). It allows you to create a graphical view of your GEOPARM that can be easily shared and displayed on a variety of devices (such as a workstation, tablet, smart phone and so on). It can analyze and extract various statistics about your configuration. GeoAssistant can also provide step-by-step guidance for coding the GEOPARM statements when adding new devices to an existing configuration.
4.8 Services component
As explained, GDPS touches on much more than simply remote copy. It also includes automation, testing processes, disaster recovery processes, and others areas.
Most installations do not have skills in all these areas readily available. And it is extremely rare to find a team that has this range of skills across many implementations. However, the GDPS/PPRC HM offering includes exactly that: access to a global team of specialists in all the disciplines you need to ensure a successful GDPS/PPRC HM implementation.
Specifically, the Services component includes some or all of the following services:
•Planning to determine availability requirements, configuration recommendations, implementation and testing plans
•Assistance in defining Recovery Point Objectives
•Installation and necessary customization of the special GDPS/PPRC HM versions of NetView and System Automation
•Remote copy implementation
•GDPS/PPRC HM automation code installation and policy customization
•Education and training on GDPS/PPRC HM setup and operations
•Onsite implementation assistance
•Project management and support throughout the engagement
GDPS/PPRC HM projects are typically much smaller than those for the other GDPS offerings. Nevertheless, the sizing of the services component of each project can be tailored for that project based on many factors including what automation is already in place, whether remote copy is already in place, whether the two centers are already in place with a multisite sysplex if required, and so on. This means that the skills provided are tailored to the specific needs of each particular implementation.
4.9 GDPS/PPRC HM prerequisites
Refer to the following web site for the latest GDPS/PPRC HM prerequisite information:
4.10 Comparison of GDPS/PPRC HM versus other GDPS offerings
There are so many features and functions in the various members of the GDPS family that it is sometimes difficult to recall them all and to remember which offerings support them. To position the offerings, Table 4-1 lists the key features and functions and indicates which ones are delivered by the various GDPS offerings.
Table 4-1 Supported features matrix
|
Feature
|
GDPS/PPRC
|
GDPS/PPRC HM
|
GDPS/XRC
|
GDPS/GM
|
|
Continuous availability
|
Yes
|
Yes
|
No
|
No
|
|
Disaster recovery
|
Yes
|
Yes
|
Yes
|
Yes
|
|
Supported distance
|
200 km
300 km (BRS configuration)
|
200 km
300 km (BRS configuration)
|
Virtually unlimited
|
Virtually unlimited
|
|
FlashCopy support
|
Yes
|
Yes
(NOCOPY only)
|
Yes
(Zero Suspend)
|
Yes (No UCB)
|
|
Reduced impact initial copy/resync
|
Yes
|
Yes
|
N/A
|
N/A
|
|
PtP VTS support
|
Yes
|
No
|
Yes
|
No
|
|
Production sysplex automation
|
Yes
|
No
|
No
|
No
|
|
Span of control
|
Both sites
|
Both sites
(disk only)
|
Recovery site
|
Disk at both sites.
Recovery Site (CBU / LPARs)
|
|
GDPS scripting
|
Yes
|
No
|
Yes
|
Yes
|
|
Monitoring, alerting, and health checks
|
Yes
|
Yes
|
Yes
|
Yes
|
|
Query Services
|
Yes
|
Yes
|
Yes
|
Yes
|
|
MGM
|
Yes
(IR or non-IR)
|
Yes
(Non-IR only)
|
N/A
|
Yes
(IR or non-IR)
|
|
MzGM
|
Yes
|
Yes
|
Yes
|
N/A
|
|
Open LUN
|
Yes
|
Yes
|
No
|
Yes
|
|
z/OS equivalent functionality for Linux for System z
|
Yes
|
No
|
Yes
|
Yes
|
|
Heterogeneous support through DCM
|
Yes (VCS and SA AppMan)
|
No
|
Yes (VCS only)
|
Yes (VCS only)
|
|
Web interface
|
Yes
|
Yes
|
No
|
Yes
|
4.11 Summary
GDPS/PPRC HM is a powerful offering that can extend Parallel Sysplex availability to disk subsystems by delivering the HyperSwap capability to mask planned and unplanned disk outages. It also provides monitoring and management of the data replication environment, including the freeze capability. It can provide these capabilities either in a single site, or when the systems and disks are spread across two data centers within metropolitan distances.
In a multisite configuration, GDPS/PPRC HM can also be an entry-level offering, capable of providing zero data loss. The RTO is typically longer than what can be obtained with a full GDPS/PPRC offering. As time goes by, if your business needs to migrate from GDPS/PPRC HM to the full GDPS/PPRC offering, this can be achieved as well.
In addition to disaster recovery and continuous availability capabilities, GDPS/PPRC HM also provides a user-friendly interface for monitoring and managing the remote copy configuration.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.