
The vast majority of computers running Linux are connected to the Internet, and many of them are used by multiple people. Keeping a computer and its software secure from anonymous threats that arrive over its network connection, as well as from local users who are trying to gain unauthorized levels of access, requires careful programming in both the core operating system and many of its applications.
This chapter gives an overview of some of the things to think about when you are writing C programs that need to be secure. We discuss what types of programs need to think carefully about their security and how to minimize the risks, and mention some of the most common security pitfalls. This is meant to be an introduction to writing secure programs; for more information look at David A. Wheeler’s Secure Programming for Linux and UNIX HOWTO at http://www.dwheeler.com/secure-programs/. It includes an excellent bibliography as well.
Computer programs are complicated things. Even the most simple “Hello World” program is surprisingly involved. Ignoring everything that happens in the kernel, the C library has to find the right shared libraries, load them into the system, and initialize the standard I/O routines. On the computer used to write this chapter, the full program took 25 system calls, only one of which was the write() call used to print the words “Hello World.”
As programs get larger, complexity grows quite rapidly. Most real-world programs accept input from multiple locations (such as the command line, configuration files, and the terminal) and manipulate that input in complicated ways. Any mistakes in this process provide for unexpected behavior, and those surprises can often be manipulated by a savvy programmer with undesirable consequences. Add a few complicated libraries into this mix, and it is very difficult for any programmer (let alone a team of programmers) to fully understand just how a program will react to any particular set of inputs.
While most programs are carefully tested to make sure they give the proper results for correct input sequences, most are poorly tested for unexpected ones.[1] While the kernel has been carefully designed to prevent failures in user-space programs from compromising the system, mistakes in some types of programs can affect the system’s integrity.
There are three main types of programs whose programmers need to constantly think about security.
Programs that handle data that could come from an untrustworthy source are very prone to vulnerabilities. That data can have attacks hidden in it that exploit bugs in programs, causing those programs to behave unexpectedly; they can often be manipulated into allowing anonymous users full access to the machine. Any program that accesses data across a network (both clients and servers) is an obvious candidate for attacks, but programs as innocuous as word processors can also be attacked through corrupted data files.[2]
Any program that switches user or group context when it is run (via the setuid or setgid bits on the executable) has the potential of being tricked into doing things as the other (privileged) user, things that the unpriviliged user is probably not allowed to do.
Any program that runs as a system daemon can be a security problem. Those programs are running as a privileged user on the system (quite often they are run as root), and any interaction they have with normal users provides the opportunity for system compromises.
Security bugs in programs lead to four broad categories of attacks: remote exploits, local exploits, remote denial-of-service attacks, and local denial-of-service attacks. Remote exploits let users who can access the machine’s network services run arbitrary code on that machine. For a remote exploit to occur, there must be a failure in a program that accesses the network. Traditionally, these mistakes have been in network servers, allowing a remote attacker to trick that server into giving him access to the system. More recently, bugs in network clients have been exploited. For example, if a web browser had a flaw in how it parsed HTML data, a web page loaded by that browser could cause the browser to run an arbitrary code sequence.
Local exploits let users perform action they do not normally have permission to perform (and are commonly referred to as allowing local privilege escalation, such as masquerading as other users on the system. This type of exploit typically targets local daemons (such as the cron or sendmail server) and setuid programs (such as mount or passwd).
Denial-of-service attacks do not let the attacker gain control of a system, but they allow them to prevent legitimate uses of that system. These are the most insidious bugs, and many of these can be very difficult to eliminate. Many programs that use lock files are subject to these, for example, as an attacker can create the lock file by hand and no program will ever remove it. One of the simplest denial-of-service attacks is for users to fill their home directories with unnecessary files, preventing other users on that file system from creating new files.[3] As a general rule, there are many more opportunities for local denial-of-service attacks than remote denial-of-service attacks. We do not talk much about denial-of-service attacks here, as they are often the result of program architecture rather than any single flaw.
One of the best strategies for making a program secure against attempts to exploit their privileges is to make the parts of a program that can be attacked as simple as possible. While this strategy can be difficult to employ for network programs and system daemons, programs that must be run with special permissions (via the setuid or setgid bits, or run by the root user) can usually use a few common mechanisms to limit their areas of vulnerability.
Many programs that need special privileges use those privileges only at startup time. For example, many networking daemons need to be run by the root user so they can listen() on a reserved port, but they do not need any special permissions after that. Most web servers use this technique to limit their exposure to attack by switching to a different user (normally a user called nobody or apache) right after they open TCP/IP port 80. While the server may still be subject to remote exploits, at least those exploits will no longer give the attacker access to a process running as root. Network clients who need reserved ports, such as rsh, can employ a similar strategy. They are run as setuid to root, which allows them to open the proper port. Once the port is open, there is no longer any need for root privileges, so they can drop those special abilities.
One or more of setuid(), setgid(), and setgroups() need to be used to reset the processes permissions. This technique is effective only if the real, effective, file system, and saved uids (or gids) are all set to their proper values. If the program is running setuid (or setgid), the process probably wants to set those uids to its saved uid. System daemons that are changing to a different user after being run by root need to change their user and group ids, and should also clear their supplemental group list. For more information on how a process can change its credentials, see page 108.
If a program needs special permissions during more than just its initial startup, helper programs may provide a good solution. Rather than making the entire application run with elevated privileges, the main program runs as the normal user who invoked it, and runs another, very small program that has the proper credentials to perform the task that requires them. By architecting the application in this way, the complexity of the code that can be attacked is dramatically reduced. This reduction makes the code much easier to get correct and to audit for any mistakes. If there are problems in the main application that allow the user to perform arbitrary actions, those actions can be performed only with the user’s normal credentials, rendering any attack useful only against that user, not the user with elevated capabilities.
Using small helper programs in this way has become quite popular in the Linux community. The utempter library, discussed on page 340, uses a setgid helper program to update the utmp database. The helper is very careful to validate its command-line arguments and to ensure that the application calling it is allowed to update the utmp database. By providing this service through a helper application, programs that use utempter do not need to have any special permissions themselves; before this library was written, any program that used pseudo ttys needed to be setgid to the group that owned the utmp database.
Another example of a helper program is the unix_chkpwd program used by PAM (PAM, or Pluggable Authentication Modules, is discussed in detail starting on page 635). Passwords on most Linux systems are stored in a file that is readable only by the root user; this prevents dictionary attacks on the users’ encrypted passwords.[4] Some programs want to make sure the person currently at the computer is the one who is logged in (xscreensaver, which can be used to lock a system’s screen until the user returns, is a common program that does this), but do not normally run as root. Rather than make those programs setuid root so they can validate the user’s password, PAM’s normal Unix-style authentication calls unix_chkpwd to validate the password for it, so that only unix_chkpwd needs to be setuid root. Not only does this remove the need for xscreensaver to be written as a privileged program, but it also means that any vulnerabilities in the X11 libraries it depends on do not allow local exploits.
Using helper programs in this way is a very good way of eliminating the possibility of security problems in applications. Writing these helpers is normally quite straightforward, and their correctness is relatively simple to determine. There are a couple of things to watch out for in their design, however.
Quite often, confidential data is passed between the main application and the helper program. For unix_chkpwd, the user’s unencrypted password must be supplied for the helper program to validate. Some care needs to be taken in how that information is passed; while it is tempting to use a command-line argument, that would allow any user who runs ps at just the right time to see a user’s unencrypted passwords. If a pipe is used to transmit the data instead (normally set as the helper program’s stdin), then the data is transmitted without other programs being able to see it.
The helper program also needs to carefully ensure that the program calling it is allowed to perform the action it is requesting. The unx_chkpwd helper does not let a program validate the passwords of any user other than the one running it. It uses its own real uid to validate that the program that calls it is allowed to check the password of the user it has requested. The utempter helper does similar checks to make sure that programs cannot remove terminals from the utmp database unless it is appropriate to do so.
One more way of keeping coding mistakes from providing the potential for an attack is to limit the set of files to which a program has access by using the chroot() system call. As discussed on page 296, chroot() followed by a chdir() call changes the root directory of the process, limiting the set of files that process is able to access. This does not prevent an exploit, but it can sometimes contain the damage. If a network server running as a user other than root is remotely exploited, it becomes much more difficult for that remote user to use that server as the base of a local exploit if it cannot access any setuid files (the most common programs local exploits can take advantage of).
Anonymous ftp servers are the most common programs that take advantage of the chroot() mechanism. In recent years it has become more popular in other programs, and many system administrators have used the chroot command to force system daemons into running in a restricted environment as a precaution against intruders.
Now that we have looked at ways of reducing the potential impact of insecure code, we go over some of the most common programming mistakes that lead to security problems. While the rest of this chapter highlights some of the things to look out for, it is by no means a definitive list. Anyone writing programs that need to be secure needs to look beyond just this chapter for guidance.
By far the most common programming mistake that leads to local and remote exploits is a buffer overflow. Here is an example of a program with an exploitable buffer overflow:
1: /* bufferoverflow.c */
2:
3: #include <limits.h>
4: #include <stdio.h>
5: #include <string.h>
6:
7: int main(int argc, char ** argv) {
8: char path[_POSIX_PATH_MAX];
9:
10: printf("copying string of length %d
", strlen(argv[1]));
11:
12: strcpy(path, argv[1]);
13:
14: return 0;
15: }
16:
This looks pretty innocuous at first glance; after all, the program does not even really do anything. It does, however, copy a string provided by the user into a fixed space on the stack without making sure there is room on the stack for it. Try running this program with a single, long command-line argument (say, 300 characters). It causes a segmentation fault when the strcpy() writes beyond the space allocated for the path array.
To better understand how a program’s stack space is allocated, take a look at Figure 22.1. On most systems, the processor stack grows down; that is, the earlier something is placed on the stack, the higher the logical memory address it gets. Above the first item on the stack is a protected region of memory; any attempt to access it is an error and causes a segmentation fault.
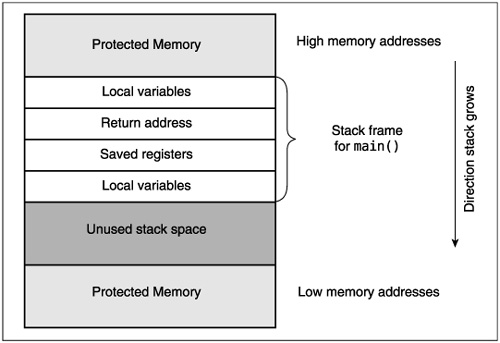
The next area on the stack contains local variables used by the code that starts the rest of the program. Here, we have called that function _main(), although it may actually get quite complex as it involves things like dynamic loading. When this startup code calls the main() routine for a program, it stores the address that the main() routine should return to after it is finished on the stack. When main() begins, it may need to store some of the microprocessor’s registers on the stack so it can reuse those registers, and then it allocates space for its local variables.
Returning to our buffer overflow example, this means that the path variable gets allocated at the bottom of the stack. The byte path[0] is at the very bottom, the next byte is path[1], and so on. When our sample program writes more than _POSIX_PATH_MAX bytes into path, it starts to overwrite other items on the stack. If it keeps going, it tries to write past the top of the stack and causes the segmentation fault we saw.
The real problem occurs if the program writes past the return address on the stack, but does not cause a segmentation fault. That lets it change the return address from the function that is running to any arbitrary address in memory; when the function returns, it will go to this arbitrary address and continue execution at that point.
Exploits that take advantage of buffer overflows typically include some code in the array that is written to the stack, and they set the return address to that code. This technique allows the attacker to execute any arbitrary code with the permissions of the program being attacked. If that program is a network daemon running as root, it allows any remote user root access on the local system!
String handling is not the only place where buffer overflows occur (al-though it is probably the most common). Reading files is another common location. File formats often store the size of a data element followed by the data item itself. If the store size is used to allocate a buffer, but the end of the data field is determined by some other means, then a buffer overflow could occur. This type of error has made it possible for Web sites to refer to files that have been corrupted in such a way that reading them causes a remote exploit.
Reading data over a network connection provides one more opportunity for buffer overflows. Many network protocols specify a maximum size for data fields. The BOOTP protocol,[5] for example, fixes all packet sizes at 300 bytes. However, there is nothing stopping another machine from sending a 350-byte BOOTP packet to the network. If some programs on the network are not written properly, they could try and copy that rogue 350-byte packet into space intended for a valid 300-byte BOOTP packet and cause a buffer overflow.
Localization and translation are two other instigators of buffer overflows. When a program is written for the English language, there is no doubt that a string of 10 characters is long enough to hold the name of a month loaded from a table. When that program gets translated into Spanish, “September” becomes “Septiembre” and a buffer overflow could result. Whenever a program supports different languages and locations, most of the formerly static strings become dynamic, and internal string buffers need to take this into account.
It should be obvious by now that buffer overflows are critical security problems. They are easy to overlook when you are programming (after all, who must worry about file names that are longer than _POSIX_PATH_MAX?) and easy to exploit.
There are a number of techniques to eliminate buffer overflows from code. Well-written programs use many of them to carefully allocate buffers of the right size.
The best way of allocating memory for objects is through malloc(), which avoids the problems incurred by overwriting the return address since malloc() does not allocate memory from the stack. Carefully using strlen() to calculate how large a buffer needs to be and dynamically allocating it on the program’s heap provides good protection against overflows. Unfortunately, it also provides a good source of memory leaks as every malloc() needs a free(). Some good ways of tracking down memory leaks are discussed in Chapter 7, but even with these tools it can be difficult to know when to free the memory used by an object, especially if dynamic object allocation is being retrofitted into existing code. The alloca() function provides an alternative to malloc():
#include <alloca.h> void * alloca(size_t size);
Like malloc(), alloca() allocates a region of memory size bytes long, and returns a pointer to the beginning of that region. Rather than using memory from the program’s heap, it instead allocates memory from the bottom of the program’s stack, the same place local variables are stored. Its primary advantage over local variables is that the number of bytes needed can be calculated programmatically rather than guessed; its advantage over malloc() is that the memory is automatically freed when the function returns. This makes alloca() an easy way to allocate memory that is needed only temporarily. As long as the size is calculated properly (do not forget the '�' at the end of every C language string!), there will not be any buffer overflows.[6]
There are a couple of other functions that can make avoiding buffer over-flows easier. The strncpy() and strncat() library routines can make it easier to avoid buffer overruns when copying strings around.
#include <string.h> char * strncpy(char * dest, const char * src, size_t max); char * strncat(char * dest, const char * src, size_t max);
Both functions behave like their similarly named cousins, strcpy() and strcat(), but the functions return once max bytes have been copied to the destination string. If that limit is hit, the resulting string will not be '�' terminated, so normal string functions will no longer work. For this reason, it is normally a good idea to explicitly end the string after calling one of these functions like this:
strncpy(dest, src, sizeof(dest)); dest[sizeof(dest) - 1] = '�';
It is a very common mistake when using strncat() to pass the total size of dest as the max parameter. This leads to a potential buffer overflow as strncat() appends up to max bytes onto dest; it does not stop copying bytes when the total length of dest reaches max bytes.
While using these functions may make the program perform incorrectly if long strings are present (by making those strings get truncated), this technique prevents buffer overflows in static-sized buffers. In many cases, this is an acceptable trade-off (and does not make the program perform any worse than it would if the buffer overflow were allowed to occur).
While strncpy() solves the problem of copying a string into a static buffer without overflowing the buffer, the strdup() functions automatically allocate a buffer large enough to hold a string before copying the original string into it.
#include <string.h> char * strdup(const char * src); char * strdupa(const char * src); char * strndup(const char * src, int max); char * strndupa(const char * src, int max);
The first of these, strdup(), copies the src string into a buffer allocated by malloc(), and returns the buffer to the caller while the second, strdupa() allocated the buffer with alloca(). Both functions allocate a buffer just long enough to hold the string and the trailing '�'.
The other two functions, strndup() and strndupa() copy at most max bytes from str into the buffer (and allocated at most max + 1 bytes) along with a trailing '�'. strndup() allocates the buffer with malloc() while strndupa() uses alloca().
Another function that often causes buffer overflows is sprintf(). Like strcat() and strcpy(), sprintf() has a variant that makes it easier to protect against overflows.
#include <stdio.h> int snprintf(char * str, size_t max, char * format, ...);
Trying to determine the size of a buffer required by sprintf() can be tricky, as it depends on items such as the magnitude of any numbers that are formatted (which may or may not need number signs), the formatting arguments that are used, and the length of any strings that are being used by the format. To make it easier to avoid buffer overflows, snprintf() fills in no more than max characters in str, including the terminating '�'. Unlike strcat() and strncat(), snprintf() also terminates the string properly, omitting a character from the formatted string if necessary. It returns the number of characters that would be used by the final string if enough space were available, whether or not the string had to be truncated to max (not including the final '�').[7] If the return value is less than max, then the function completed successfully; if it is the same or greater, then the max limit was encountered.
The vsprintf() function has similar problems, and vsnprintf() provides a way to overcome them.
It is quite common for privileged applications to provide access to files to untrusted users and let those users provide the filenames they would like to access. A web server is a good example of this; an HTTP URL contains a filename that the web server is requested to send to the remote (untrusted) user. The web server needs to make sure that the file it returns is one that it has been configured to send, and checking filenames for validity must be done carefully.
Imagine a web server that serves files from home/httpd/html, and it does this by simply adding the filename from the URL it is asked to provide to the end of /home/httpd/html. This will serve up the right file, but it also allows remote users to see any file on the system the web server has access to by requesting a file like ../../../etc/passwd. Those .. directories need to be checked for explicitly and disallowed. The chroot() system call is a good way to make filename handling in programs simpler.
If those filenames are passed to other programs, even more checking needs to be done. For example, if a leading - is used in the filename, it is quite likely that the other program will interpret that filename as a command-line option.
Programs run with setuid or setgid capabilities need to be extremely careful with their environment settings as those variables are set by the person running the program, allowing an avenue for attack. The most obvious attack is through the PATH environment variable, which changes what directories execlp() and execvp() look for programs. If a privileged program runs other programs, it needs to make sure it runs the right ones! A user who can override a program’s search path can easily compromise that program.
There are other environment variables that could be very dangerous; the LD_PRELOAD environment variable lets the user specify a library to load before the standard C library. This can be useful, but is very dangerous in privileged applications (the environment variable is ignored if the real and effective uids are the same for exactly this reason).
If a program is localized, NLSPATH is also problematic. It lets a user switch the language catalog a program uses, which specifies how strings are translated. This means that, in translated programs, the user can specify the value for any translated string. The string can be made arbitrarily long, necessitating extreme vigilance in buffer allocation. Even more dangerously, if a format string for a function like printf() is translated, the format can change. This means that a string like Hello World, today is %s could become Hello World, today is %c%d%s. It is hard to tell what effect this type of change would have on a program’s operation!
All of this means that the best solution for a setuid or setgid program’s environment variables is to eliminate them. The clearenv()[8] function erases all values from the environment, leaving it empty. The program can then add back any environment variables it has to have with known values.
Running the system shell from any program where security is a concern is a bad idea. It makes a couple of the problems that already have been discussed more difficult to protect against.
Every string passed to a shell needs to be very carefully validated. A '
' or ; embedded in a string could cause the shell to see two commands instead of one, for example. If the string contains back tick characters (') or the $() sequence, the shell runs another program to build the full command-line argument. Normal shell expansion also takes place, making environment variables and globbing available to attackers. The IFS environment variable lets characters other than space and tab separate fields when command lines are parsed by the string, opening up new avenues of attack. Other special characters, like <, >, and |, provide even more ways to build up command lines that do not behave as a program intended.
Checking all of these possibilities is very difficult to get right. The best way, by far, of avoiding all of the possible attacks against a shell is to avoid running one in the first place. Functions like pipe(), fork(), exec(), and glob() make it reasonably easy to perform most tasks the shell is normally used for without opening the Pandora’s box of shell command-line expansion.
It is quite common for programs to use temporary files; Linux even provides special directories (/tmp and /var/tmp) for this purpose. Unfortunately, using temporary files in a secure manner can be very tricky. The best way to use temporary files is to create them in a directory that can be accessed only by the program’s effective uid; the home directory of that user would be a good choice. This approach makes using temporary files safe and easy; most programmers do not like this approach as it clutters directories and those files will probably never get erased if the program fails unexpectedly.
Imagine a program that is run by the root user that creates a shell script in a temporary file and then runs that script. To let multiple copies of the program run at the same time, perhaps it includes the program’s pid as part of the filename, and creates the file with code like this:
char fn[200];
int fd;
sprintf(fn, "/tmp/myprogram.%d", getpid());
fd = open(fn, O_CREAT | O_RDWR | O_TRUNC, 0600);
The program creates a unique filename and truncates whatever file used to be there before writing to it. While it may look reasonable at first glance, it is actually trivial to exploit. If the file the program tries to create already exists as a symbolic link, the open call follows that symbolic link and opens whatever file it points to. One exploit is to create symbolic links in /tmp using many (or all) possible pids that point to a file like /etc/passwd, which would cause the system’s password file to be overwritten when this program is run, resulting in a denial-of-service attack.
A more dangerous attack is for those symbolic links to be pointed at a file the attacker owns (or, equivalently, for the attacker to create regular files in /tmp with all of the possible names). When the file is opened, the targeted file will be truncated, but between the time the file is opened and the time the program gets executed, the attacker (who still owns the file) can write anything they like into it (adding a line like chmod u+s /bin/sh would certainly be advantageous in a shell script running as root!), creating an easy attack. While this may seem difficult to time properly, these types of race conditions are often exploited, leading to security compromises. If the program was setuid instead of run as root, the exploit actually becomes much easier as the user can send SIGSTOP to the program right after it opens the file, and then send SIGCONT after exploiting this race condition.
Adding O_EXCL to the open() call prevents open() from opening a file that is a symbolic link as well as a file that already exists. In this particular case, a simple denial-of-service attack also exists, as the code will fail if the first filename tried exists, but this is easily remedied by placing the open() in a loop that tries different filenames until one works.
A better way to create temporary files is by using POSIX’s mkstemp() library function, which ensures that the file was created properly.[9]
int mkstemp(char * template);
The template is a filename whose last six characters must be "XXXXXX”. The last part is replaced with a number that allows the filename to be unique in the file system; this approach allows mkstemp() to try different filenames until one is found that works. The template is updated to contain the filename that was used (allowing the program to remove the file) and a file descriptor referring to the temporary file is returned. If the function fails, -1 is returned.
Older versions of Linux’s C library created the file with mode 0666 (world read/write), and depended on the program’s umask to get the proper permissions on the file. More recent versions allow only the user to read and write from the file, but as POSIX does not specify either behavior, it is a good idea to explicitly set the process’s umask (077 would be a good choice!) before calling mkstemp().
Linux, and a few other operating systems, provide mkdtemp() for creating temporary directories.
char * mkdtemp(char * template);
The template works the same as it does for mkstemp(), but the function returns a pointer to template on success and NULL if it fails.
Most operating systems that provide mkdtemp() also provide a mktemp program that allows shell scripts to create both temporary files and directories in a secure manner.
There are other problems with temporary files that have not been covered here. They include race conditions added by temporary directories residing on networked (especially NFS) file systems as well as by programs that regularly remove old files from those directories, and the extreme care that needs to be taken to reopen temporary files after they have been created.
For details on these and other problems with temporary files, take a look at David A. Wheeler’s HOWTO mentioned on page 531. If you need to do any of these things, it is probably a better idea just to figure out how to create the files in the effective user’s home directory instead.
Any time an attacker can cause a program to behave in an incorrect manner there is the potential for an exploit. Mistakes that seem as innocuous as freeing the same portion of memory twice have been successfully exploited in the past, highlighting the need for privileged programs to be very carefully written.
Race conditions, and the signal handlers that can easily cause race conditions, are a rich source of program bugs. Common mistakes in writing signal handlers include:
Performing dynamic memory allocation. Memory allocation functions are not reentrant, and should not be used from a signal handler.
Using functions other than those appearing in Table 12.2 is always a mistake. Programs that call functions such as
printf()from a signal handler have race conditions, asprintf()has internal buffers and is not reentrant.Not properly blocking other signals. Most signal handlers are not meant to be reentrant, but it is quite common for a signal handler that handles multiple signals to not automatically block those other signals. Using
sigaction()makes it easy to get this right as long as the programmer is diligent.Not blocking signals around areas of code that modify variables that a signal handler also accesses. (These code regions are often called critical regions.)
While signal-induced race conditions may not seem dangerous, networking code, setuid, and setgid programs can all have signals sent by untrusted users. Sending out-of-band data to a program can cause a SIGURG to be sent, while setuid and setgid programs can be sent signals by the user who runs them as the real uid of those processes does not change. Even if those programs change their real uids to prevent signals from being sent, when the user closes a terminal, all programs using that terminal are sent a SIGHUP.
On Linux and Unix systems, file descriptors are normally inherited across exec() system calls (and are always inherited across fork() and vfork()). In most cases, this behavior is not particularly desirable, as it is only stdin, stdout, and stderr that ought to be shared. To prevent programs that a privileged process runs from having access to files they should not have via an inherited file descriptor, it is important that programs carefully close all of the file descriptors to which the new program should not have access, which can be problematic if your program calls library functions which open files without closing them. One way of closing these file descriptors is to blindly close all of the file descriptors from descriptor number 3 (the one just after stderr) to an arbitrary, large value (say, 100 or 1024).[10] For most programs, this ensures that all of the proper file descriptors have been closed.[11]
A better approach is for programs to set the close-on-exec flag for every file it leaves open for an extended period of time (including sockets and device files), which prevents any new programs that are run from having access to those files. For details on the close-on-exec flag, see page 196.
Programs that are designed to run as system daemons need to be a little careful how they become daemons to get all of the details right. Here is a list of things that should be done:
Most of the initialization work should be done before the program becomes an actual daemon. This allows any errors to be reported to the user starting the program and a meaningful exit code to be returned. This type of work includes parsing configuration files and opening sockets.
The current directory should be changed to whatever is appropriate. This is often the root directory, but it is never the directory from which the program was run. If the daemon does not do this, it may work properly, but it is preventing the directory from which it was started from being removed, as it is still a program’s current directory. It is a good idea to
chroot()to a directory if it is possible to do so for the reasons discussed earlier in this chapter.Any unneeded file descriptors should be closed. This may seem obvious, but it can be easy to neglect to close file descriptors that have been inherited instead of opened by the program itself. See page 549 for information on how to do this.
The program should then call
fork()and the parent process should callexit(), allowing the program that ran the daemon (often a shell) to continue.The child process, which is continuing, should close stdin, stdout, and stderr, as it will no longer use the terminal. Rather than reuse file descriptors 0, 1, or 2, it is a good idea to open those files as
/dev/null. This ensures that any library functions that report error conditions to stdout or stderr do not write those errors into other files the daemon has opened, and it allows the daemon to run external programs without worrying about their output.To completely disassociate from the terminal from which the daemon was run, it should call
setsid()to place it in its own process group. This prevents it from getting signals when the terminal is closed, as well as job-control signals.
The C library provides a daemon() function that handles some of these tasks.
int daemon(int nochdir, int noclose);
This function forks immediately, and if the fork succeeds, the parent process calls _exit() with an exit code of 0. The child process then changes to the root directory unless nochdir is nonzero and redirects stdin, stdout, and stderr to /dev/null unless noclose is nonzero. It also calls setsid() before returning to the child. This could still leave open inherited file descriptors, so programs that use daemon() should check for that. If possible, the programs should also use chroot().
[1] A popular way of testing early Linux kernels was to generate a sequence of completely random bytes and start executing them as a program. While this would never do anything particularly useful (let alone write Hamlet), it would quite often cause the kernel to completely lock up. While trying to execute completely random code sequences is not in the kernel’s job description, user-space programs should never cause the kernel to stop running properly, so this technique found a large number of bugs that needed to be fixed.
[2] Attacking application software is now the primary method viruses use to spread.
[3] System quotas prevent this attack from working.
[4] A dictionary attack is a brute force method of discovering passwords where an automated program runs through a large list of common passwords, such as words in a dictionary, until one works.
[5] BOOTP is the predecessor to DHCP, which allows machines to learn their IP addresses automatically when they enable their network interfaces.
[6] alloca() is not a standard feature of the C language, but the gcc compiler provides alloca() on most operating systems it supports. In older versions of the gcc compiler (before version 3.3), alloca() did not always interact properly with dynamically sized arrays (another GNU extension), so consider using only one of the two.
[7] On some obsolete versions of the C library, it will instead return -1 if the string does not fit; the old version of the C library is no longer maintained and secure programs will not use it, but the snprintf() man page demonstrates code that can handle both variants.
[8] Unfortunately, clearenv() has not been well standardized. It is included in recent versions of POSIX but was left out of the Single Unix Standard, and is not available on all Unix-type systems. If you need to support an operating system that does not include it, environ = NULL; should work just as well.
[9] There are a few other library functions that deal with temporary files, such as tmpnam(), tempnam(), mktemp(),and tmpfile(). Unfortunately, using any of them is little help as they leave exploitable race conditions in programs that are not carefully implemented.
[10] Linux allows programs to open a very large number of files. Processes that are run as root can open millions of files simultaneously, but most distributions set a resource limit on the number of files a user process can open. This resource limit also limits the maximum file descriptor that can be used with dup2(), providing a usable upper limit for closing file descriptor.
[11] Another way of closing all of the files a program has open is to walk through the process’s /proc file system directory that lists all of the files it has open and close each of them. The directory /proc/PID/fd (where PID is the pid of the running process) contains a symbolic link for each file descriptor the process has open, and the name of each symbolic link is the file descriptor to which it corresponds. By reading the contents of the directory, the program can easily close all of the file descriptors it no longer needs.