
Chapter 1. Introduction
As developers, we certainly face some significant challenges every day, but there is a big one that most of us will have to address sooner or later. As the number of both CPU cores and systems that your code runs on increase, the issue of concurrency rears its head and the approaches that have become common practice show their insufficiency for addressing these issues.
The common technique for coordinating concurrent tasks takes the form of shared, mutable data structures and locking mechanisms to only allow a single caller in a flow of execution to change the shared structure at any one time. If you pick up the typical book on concurrency in Java, C# or C++, this is the approach you will generally see described. Unfortunately, at the point these locks are brought into use, concurrency is no longer possible for any tasks impeded by these locks.
Further, these techniques prove to be difficult to scale. The problem is even more pronounced when multiple, independent machines are involved — locks and shared memory in the form described above are simply not feasible across systems.
The Problems of Concurrency
Generally speaking, we can group approaches used for coordinating concurrent operations in two broad camps: one that uses locks to manage access to shared memory-based data structures or other shared resources; and one that builds on the idea of message passing. We'll walk through a brief description of each of these to make sure our understanding is clear.
The locking approach built around multiple threads accessing shared, mutable data structures is perhaps the most common technique for concurrency coordination. Let's consider the simple example of a system that has two cores and a handful of IO devices attached (the important point being that there are more devices than cores). We'll make an assumption that the combined data throughput of these devices is more than a single core can process, without causing other necessary work to back up. Putting aside the concern that we generally shouldn't make assumptions about the hardware (this is an important concern, though), one possible approach when encountering this issue is to try and spread the load across the cores. But when we're dealing with I/O, we need to manage buffers to hold the data being processed. How do we make those buffers safe for use by both cores? One solution would be locking our data structures.
As the title of this section might suggest (and as pointed out earlier), there are problems with the lock-oriented approach that quickly bring about difficulties. At the least, we'll have to figure out at what scope to place our locks. Locking the whole structure is a bad idea. To be clear, this is due to the bottleneck around this structure anytime a thread needs to interact with it. Unfortunately, making the locks too fine-grained is also not a clear winner - it results in far too much resource consumption, since the system has to manage the locking and unlocking.
And then there's the issue of lock contention and deadlock or, often worse, livelock. Deadlock occurs when two threads are running, trying to access some shared resources and neither can progress because they are both waiting for the other to release the other resource.
Figure 1: Deadlock

We can get a sense of the sequence of events in a deadlock situation by looking at the diagram in Figure 1. There are two threads shown, each of which need to obtain a lock on two different resources. But in this case they are attempting to get the locks in differing orders, so the first thread 1 acquires the lock for A, with thread 2 acquiring the lock on B. Next, thread 1 tries to acquire the lock for object B, but it must wait because thread 2 currently holds it. If, in the meantime, thread 2 then tries to get a lock on object A, we end up with a deadlock. Both threads will sit until they are forcibly destroyed waiting on the other thread to release the lock on the object they need. This assumes that some supervisor or guardian thread or process is watching for these cases and is able to safely do this without severe consequences such as corrupted data.
This may look overly simplistic, but when we are dealing with larger numbers of threads and many shared resources that require locks for safe usage, deadlocks can happen more frequently than we might hope. There are common techniques for reducing the chances of this happening -- for example, by attempting to enforce predefined ordering for any lock acquisitions -- but they usually end up being cumbersome to manage and maintain.
The livelock variation of this pattern occurs when two (or more) threads are competing for some resource, but the state of the lock each thread is trying to acquire changes with respect to the other while trying to determine the state of the lock held by the competing thread. That is, imagine thread 1 has a lock on A, but also needs a lock on B. But the lock on B is currently held by thread 2. In the meantime, thread 2 needs that lock on A, being held by thread 1. Now, with this scenario, we have a slightly different form of deadlock. But consider what happens if each of these threads is running code with retry logic that continually retries the lock acquisition on the second lock and never releases the original lock it has already acquired. This can be even worse than a deadlock, since rather than having our code sitting idle, the threads involved are constantly spinning CPU cycles. This means our system just expells a lot of waste heat. Not the sort of thing our finance department will be very happy about when the utility bill shows up.
What is the Actor Model?
The actor model was first introduced in a paper written in 1973 by Carl Hewitt along with Peter Bishop and Richard Steiger. In very general terms, it describes a method of computation that envolves entities that send messages to each other. Conceptually, this might sound much like object-oriented programming, but there are important differences. In the years since the publication of that first paper, the model has been further refined into a complete model of computation. Understanding this model is important to understanding Akka, as it is the core upon which Akka is built.
The primary entity of this model are these artifacts called actors, as the name implies. An actor is just a single entity (we might think of this as an instance of a class, in OOP terminology), which interacts with other actors entirely via message passing. Each actor has a mailbox, which stores any messages it has not yet processed. The actor is responsible for defining what behavior will be executed when it receives a given message, but it can also, on receipt of a message, choose to change that behavior for subsequent messages. Related closely to this is the idea that an actor is solely responsible for its state and this state cannot be changed directly by anything external to the actor. State changes can happen based upon messages that have been received, but the actor maintains that responsibility.
It's also important to understand that each actor, while it's handling a single message and executing any behavior defined upon receipt of that message, is working in a sequential manner. Further, it processes each message in the order in which they arrive in its mailbox, one message at a time. At any given time; however, a number of different actors can be executing their behaviors. We might even have a number of instances of a single type of actor all working to process messages as they are received.
Another property of actors is that they are never referenced directly. Each actor is given an address that is used to send messages to it. For an actor to send a message to another actor, it must know that other actors address. Actors never reference each other directly, but only through these addresses. Later on in this book, starting with the next chapter, we'll see how Akka uses this trait in an interesting and useful way.
The final characteristic of actors is that they can create other actors. This may be obvious, but it's an important point to understand. This gives you enormous power to create complex systems of actors (We'll discuss more about actor systems in a bit). In fact, it is quite common to have a hierarchy of actors where one top level actor acts as the initial starting point for your system, that is responsible for starting up other actors needed to express the remaining functionality you need. We'll be covering this more in chapter four.
To provide an example of how we might represent something using this model, let's imagine we have an actor, we can call it StoreManager, that monitors access to the door of your bookstore. When the store is closed, we want our security alarm to be triggered if the door opens unexpectedly. We could model the door opened event using a DoorOpened message. To trigger the alarm, the message is TriggerAlarm. When our actor receives the DoorOpened message, its behavior will be to send TriggerAlarm (to some other, currently unspecified actor that somehow interfaces to the physical alarm system).
Now, the key missing piece here is how to handle things during normal business hours. In this case, when the StoreManager actor receives the DoorOpened message, we almost certainly don't want to trigger the alarm. In this case, we would have a scheduled message sent (we'll call it OpeningTime) at the moment when the store is supposed to open (we'll get into scheduling messages later -- it's not explicitly part of the actor model). When StoreManager receives this message, it will switch behavior so that any DoorOpening message it receives will not trigger the alarm. Perhaps we could even have it trigger some other action, such as ringing a chime to let us know someone has entered, or incrementing a counter, so we can see how many unique visitors we had in a given day. At closing time, we would again have a scheduled message, ClosingTime, sent to cause the actor to revert to the previous behavior.
Figure 2: StoreManager states

Are You Distributed?
Up to this point, we've primarily been focusing on a single system, but the problem gets even more interesting when we consider running across multiple independent systems. The simple fact is that most of the standard concurrency toolkits don't offer us a lot of help here as their solutions focus on providing constructs that help the developers work with shared memory systems which for historical reasons, remain the most prevalent. In our example, a scenario would be to count the number of customers entering the store and here you could keep track of the number of times the message RingChime was seen and you would use the constructs provided by the toolkit to implement the tracking process - this problem relates to concurrency. There are of course multiple variations of this problem (we'll see some of these soon) and a common theme that results from this is "just run your code on each system and use defensive coding to address possible issues."
What do we mean by "defensive coding"? Let's look at the most common approaches. Imagine that we have built a system to handle managing users' financial accounts. Periodically we receive data about new transactions from external systems that we don't manage. When that data comes in, we need to add these transactions into our accounting history so we can later report back to the user their full transaction details.
But how do we handle these incoming transactions when we have redundant servers handling the work of pulling the data in? Do we have each system independently pulling in the new data? How do we make sure they don't both see the same item and add it, creating a duplicate record?
One approach would be to have the systems each communicating with each other over some RPC-style mechanism and deciding which is to handle the incoming data. But then we have to get into a whole host of issues around determining which system should be handling the data ingest and what to do when something goes wrong. As an example, there is the unfortunately too frequent case of partial network outages. This will usually be seen by our code as a sudden inability to reach resources on other machines. We can handle this within our business logic using try/catch blocks, but before long, we find ourselves spending more time creating mechanisms to handle the various failure scenarios and possible issues than we are on building your actual application.
The other common approach is to make this an issue of data consistency and push it all the way to some back-end data store. Of course, this assumes we're using a data store that has a facility for handling this, such as a transactional RDBMS and, further, that there are uniquely defining traits on the transaction data that allow us to differentiate two seemingly identical transactions from each other. To understand this better, imagine that we go to the store and buy a soda for $0.99, but then we remember our friend wanted one, too, and, feeling generous, we make another transaction for a $0.99 soda. Depending on how the data shows up in our ingest system, these transactions could look identical, depending upon the granularity of the identifying fields, as shown in Figure 3.
Figure 3: Soda purchases

Of course, the whole point of this approach is to have the database able to handle the case where we end up with actual duplicates. That is, when two (or more) systems attempt to insert the same data. We have now essentially pushed some portion of our application logic, that is, the logic that allows the database to determine whether two records are actual duplicates, to another external system (the database, of course). Again, this would generally be considered ancillary to the actual purpose of the application. But far too many developers now consider this part of their standard operating procedure.
Figure 4: Soda purchase with resend

Both of these approaches clearly have issues and, from our perspective, neither seem very appealing. Why not just use a toolkit that gives us built-in tools to handle these scenarios and make the whole issue of where our code is running independent of (and, to a large degree, invisible to) the application logic itself? Wouldn't it be simpler if our infrastructure code, the libraries and toolkits we build upon already handled this kind of situation for us?
This is where Akka can step in to provide us some help. Akka builds on the actor model (more on this momentarily), which helps us by modelling interaction between components as sequences of message passing, which, as we'll see, allows us to structure behaviors between components in a very fluid manner. Further, it is built on the assumption that failures will occur and therefore presents us with supervisors that help your system to self-heal. Finally, it gives us easy access to flexible routing and dispatching logic to make distributing our application across multiple systems convenient and natural.
By moving concurrency abstractions up to a higher layer, Akka gives us a powerful toolkit for handling the issues that have been discussed. We'll explore the most significant of these in the chapters ahead, but first it might help to provide a bit of background for the most fundamental idea it builds upon.
How does this compare to traditional concurrency?
Now that the actor model has been detailed, it's worth talking a bit more about how this compares to the traditional approach to concurrency used in most other popular languages (in other words, Java, C++, etc.).
As described above, the usual technique used to coordinate concurrent operations, that is the approach considered standard, is the use of locks, semaphores, mutexes, or any of the other variations on this theme within the context of thread-based execution models. This approach relies on some shared state or resources that must be restricted to only be accessed by any one given thread of control at a time. There are a lot of variations on this, such as only locking for write operations, while allowing reads from multiple concurrent callers, but the problems they exhibit fall largely into a single category.
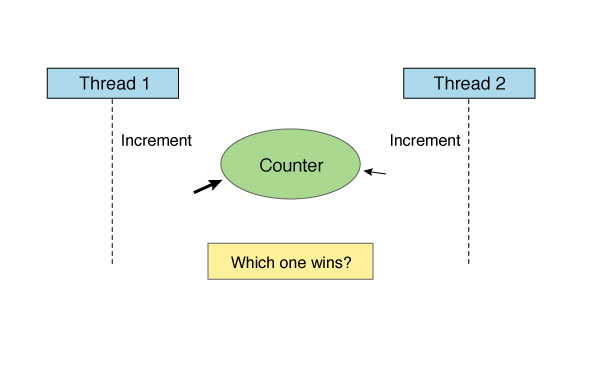
Imagine we have two threads and a single field that needs to be updated whenever one of those threads encounters some event (perhaps it's triggered by someone visiting our website and the field is a counter of total visitors). For some portion of the time, things appear to be just fine, but then two visitors come to our website at the same time, both triggering an update to the counter. Obviously, only one thread can win. So we add a lock around the method that updates this field. That seems to do the trick.
Figure 5: Thread contention
But let's consider what happens when you're no longer dealing with two threads, but with potentially hundreds or thousands. At this stage, you might think everythings just fine, until we open up our profiler and see the how many threads are blocked, waiting to get access to the lock. It's very difficult to reason about these scenarios and figuring out the right strategy to prevent excessive resource consumption as the JVM tries to negotiate this logic. This is not something most developers are going to have the time to do. Thankfully, this is the kind of problem that the actor model and Akka are designed to help.
Figure 6: Heavy thread contention

Since this book is about Akka, and therefore about the JVM, we might wonder what the situation is given the generally positive statements oftened heard about the java.util.concurrent package. This package, originally under the EDU.oswego.cs.dl.util.concurrent namespace and later formalized in JSR 166, started out as a project of Doug Lea's with the goal of adding an efficient implementation of the commomly used utility classes needed for concurrent programming in Java. It contains some very powerful and well tested code, without question. But it's also very low-level and requires very careful coding to use it effectively.
In our opinion, it's best to look at these as the fundamental structures upon which better abstractions can be built. In fact, Doug Lea has made it clear on numerous occasions that he intends these tools to be used as the underlayer of more approachable libraries. Ideally, these abstractions will allow us to more easily reason about the problems which we need to address.
What is Akka and what does it bring to the table?
Akka is a project first begun by Jonas Bonér in 2008, but with roots that go much, much deeper. It pulls ideas from Erlang and Clojure, but also adds a lot of its own innovations and brings in the elegance of Scala. There is a Java API, as well, which we can use if someone forces you to -- but perhaps at that point we should look for other work or make new friends!
Akka is built firmly on the actor model. We've already covered that fairly well, but we'll describe, briefly, how Akka approaches this model and what else it brings along. The model itself is just a framework for modelling problems, but actual implementations are free to implement the specifics however they wish. In our opinion, Akka makes some very good, pragmatic choices here.
Actors in Akka are very lightweight. The memory usage of a single instance is on the order of a few hundred bytes (less than 600). Using Akka's actors for seemingly simple tasks should not be a concern from this perspective unless we're in an extremely memory restricted environment. But even if we are, there's a fair chance any non-actor approach to concurrency could easily use similar memory just trying to manage the locks, mutexes and state juggling needed to keep it "safe".
Akka organizes actors into hierarchies, referred to as actor systems. To begin the life of any actor, you must first obtain a reference to the ActorSystem (we'll show you how to get one in the next chapter) upon which all actors reside. At the top level of the system, we have three actors called guardians. We won't really directly interact with these actors the way we would other actors, but it's important to understand how it forms the top of the hierarchical tree. We can create our own actors from this top-level, which can then create their own child actors, resulting in a tree of of actors, as shown in the following diagram.
Figure 7: Akka's actor hierarchy

There are important reasons Akka structures actors into these hierarchies. The first reason is for fault-tolerance. Akka includes a supervision system that allows each parent actor to determine a course of action when a child actor experiences a failure (that is, throws an exception). The choices, when this happens are: restart the child, resume the child, terminate the child, and escalate the failure to the next parent. We'll go into more details about each of these when we get into implementation details later.
This hierarchy also allows for a simple, file-system like addressing scheme that will be familiar to developers. For instance, an actor called "accountCreditor" (actors can either be given names or the framework will assign one) that was created in an actor system called "accounting" and with a parent called "accountMonitor" might be addressed as "akka://accounting/user/accountMonitor/accountCreditor". We won't dwell on all the specifics of this right now, but it's a useful property that also ties closely into the next feature.
This last feature we want to highlight is the very simple and easily configured remoting that Akka provides. This feature is the core that provides the key to truly scalable concurrency. With Akka remoting, we are able to both create and interact with actors on another distinct Akka instance. This could be on the same machine, running under a different JVM instance, or it could be located on another machine entirely.
And as we mentioned earlier, the remoting capability is very much integrated with the addressing of actors. From the point-of-view of a given actor, if you have the address of another actor, it doesn't matter or need to care whether that actor is local or remote. This is called location transparency and it's a very powerful concept because it allows you to focus on the problem-at-large instead of experiencing an internal hemorrhage tinkering with the mechanics of it. The reason is that remoting can be driven entirely via configuration. WE can have an application that runs entirely in a single JVM, or across a large number of JVMs, with the only change being in the configuration.
Where are we going with this?
Now that we've covered the basic ideas, we can start to look at where this is all headed. At this point we're assuming you have some problem to solve or will likely encounter some problem in the near future that involves the need to build with concurrency in mind. We're hoping to demonstrate how Akka can help solve these problems.
In the next chapter, we'll show how to get started with Akka by way of some simple, but realistic examples. From there, We'll demonstrate how we can take that simple example, make it more resilient, make it distributed and perhaps a few more interesting things that would almost certainly be anything but simple with a thread-based approach.