
4
STRING PROCESSING AND PATTERN MATCHING
In the previous chapter, we studied the representation of simple data using an array. These representation had the property of storing homogeneous type of data. One of the primary interests of today's computer processing concentrates on string processing, broadly called as text processing. Such processing usually involves some type of pattern matching. Pattern matching is the process of finding a pattern within a string of character text. The answer may be (1) whether a match exists or not, (2) the place of (the first) match, (3) the total number of matches, or (4) the total number of matches and where they occur. We discuss in this chapter fundamentals of string representation, string manipulations, string functions, and pattern-matching algorithms. Three string matching algorithms—straightforward, Kunth-Morris-Pratt, and Boyer-Moore—are examined and their time complexity will be discussed. Algorithms and C programs for different string processing methods will be presented.
4.1 INTRODUCTION TO STRING PROCESSING
A string is a special type of linear one-dimensional array. A book can be thought of as a string of characters. A program can also be looked as a string of characters. String is an important data structure widely used in computer science for storing and manipulating textual data. Thus it is important to study techniques for representing and manipulating strings because of their widespread use.
A number of programming languages provide strings as a virtual data type of the language. Some languages have a special library for handling string operations. String manipulations can also be performed using arrays and lists. A string differs from the one-dimensional array in three basic ways: (i) a string is a one-dimensional array of characters that are usually restricted to the set of printable characters and a few control characters that are useful in text based applications, (ii) a string is a dynamic data structure which grows in size as new characters are added and contracts as characters are removed, in contrast to the static fixed-length of the array structure, and (iii) the length of the string can be obtained through a function.
In some applications, it is necessary to process strings whose length cannot be predicted in advance of the running of a program. It may arise in text-processing systems or information retrieval applications where the size of data to be read is not foreknown. A basic idea for representing strings of varying size is to use a linked list. A pointer can specify the location of the block containing next character in a string, allowing the characters to be stored in noncontiguous blocks of memory. Compared to the array representation of strings, the use of pointer makes string operations considerably easier. Linked representation of text will be discussed in the subsequent chapter.
We now have several questions. What type of data structures can be useful in storing character strings? Which operations on characters are to be considered? What are the performance considerations relating operations to string data structures? How pattern matching operations are performed? In this chapter we will find those answers. This chapter also explores a number of possible representation choices and presents some well-known algorithms for implementing string-manipulation tasks.
4.2 STRING REPRESENTATION
Strings are an important part of any program. We can use them to write messages to the users, to read text files, and generally to make interaction with users smoothly. Computers are frequently used for processing or manipulating non-numeric data, called character data. String manipulating is often a large part of any programming task. Such processing usually involves some type of pattern matching, that is, to see if a particular word S appears in a given text T. So it requires to study string-manipulation routines. In this subsection we will look at how strings are represented and manipulated in C language.
A finite sequence S of zero or more characters is called a string. The number of characters in a string is called its length. The string with zero characters is called the empty string or the null string. Normally specific strings will be denoted by enclosing their characters in double quotation marks. This mark will also act as string delimenter. For example,
“Computer” “It is a programme”
are strings with length 8 and 15 (including blank spaces, if any, since the blank space is also a character).
Before examining the string-manipulation functions, we first review the internal representation of character strings in C.
Character strings in C are stored in contiguous memory locations to hold successive characters. To create a string variable, we must allocate enough space for the number of characters in the string and the characters are terminated by the null character (�). For example, if we want to create a string variable to store the word “hello”, we would need an array of at least six characters. The characters are stored as follows:

The string variable must be declared in the following way:
char String[6]; /*String is the name*/
/* of the string variable */
We can also define string constant for a string variable. The technique for initializing a string is different from the array initialization. For example, if we define the constant vowels,
# define Vowels “aeiouAEIOU”
the constant is stored in memory as
‘a’‘e’‘i’‘o’‘u’‘A’‘E’‘I’‘0’‘U’‘�’
Another way in which we can define the vowels of the english language through an array is
char Vowels[10]={‘a’, ‘e’, ‘i’ ‘o’, ‘u’ ‘A’, ‘E’,
‘I’, ‘0’, ‘U’,};
The C compiler will append the null character to both types of initialization. So it is not required in the initialization.
When creating character strings, however, we must append the null character at the end of the string. It helps to search the end of the string. The following ‘for’ statement illustrates the process for finding the end of the string.
for(i=0; string[ i ] ! =NULL; i++)
or
for(i=0; string[ i ] ! =‘ �’ ;i++)
The word ‘NULL’; can also be used in place of ‘�’.
As we will see later on, the majority of string manipulating functions search for the end of the string in the above manner. These routines can also be implemented with pointers instead of character arrays.
The implementation of arrays in C is strongly tied to pointers. In many ways, array indexing simplifies pointer arithmetic for the program. In C, the name of an array is a pointer to the first element in the array. A pointer references a location in memory and a pointer to a variable is created by the use of the asterisk (*) before the variable. To access the value contained in the location referenced by the pointer, the asterisk is used.
Pointers are convenient for string functions. One advantage of using pointers to character string is that we need not worry about the dimension arrays to contain the characters. When pointers to character strings are used in functions, a pointer to the first character in the string is only to be passed in a similar manner for arrays of characters. Once the pointer is assigned to the locations of the first character in the string, we can move further through the characters contained in the string by incrementing this pointer.
4.3 STRING MANIPULATION
A string is viewed simply as a sequence or linear array of characters. Various string operations have been developed which are not normally used with other kinds of array. The importance of these string manipulation routines will become readily apparent when these routines are used to implement the complex programs. The development of these programs was greatly simplified by using the string functions. This subsection discusses these string functions though some of these functions are available in the standard C library. The next subsection shows how these operations are used in pattern matching.
The number of characters in a string is called its length. We write a function len (String) for the length of a given string. Thus
len(“Program”) = 7, len (“This is”) = 7
len(“”) = 0
The function len(String) is given below:
Example 4.1
/* Returns a count of the number of characters */
/* in the variable string */
len(String)
char string[ ];
{
int i;
for( i=0; string [i]!='�' ; i++)
;
return (i) ; /* Number of characters in the string */
}
The substring of a string returns any length of consecutive characters. A substring function requires three parameters.
(i) The name of the string or the string itself.
(ii) The position of the first character of the substring in the given string.
(iii) The length of the substring or the position of the last character in the substring.
(iv) Copy of substring into another string. We now write the substr (Sl, K, L, S2) function below:
Example 4.2
/* This function copies the substring of a string */
/* SI beginning in a position K and having a length */
/* L into another string S2 */
Substr(S1,K,L,S2)
char S1[ ], S2[ ];
int K,L;
{
int i, Ll,j;
Ll= len(S1) ;
if ( L>0 && L1>L)
L1=L;
else
if(L>0 && Ll< L)
printf(“Original string is too short”);
for( j=0, i=k ; i<Ll ; i++, j++)
S2[j]= S[i];
S2[j]= ‘�’;
}
Let us illustrate the Substr (SI, K, L, S2) function with Table 4.1.
Table 4.1 Example of Substring Function
| Original String (S1) | Substr (S1, K, L, S2) | Content of (S2) |
| ‘Good Morning’ | Substr (‘Good Morning,’ 6,3,S2) | ‘Mor’ |
| ‘To be or not to be’ | Substr (‘To be or not to be 4,7,S2) | ‘be or n’ |
| ‘The end’ | Substr (‘The end’, 4,4,S2) | ‘end’ |
We now present some more useful functions such as Insert ( ), Index ( ), and remove ( ).
Example 4.3
/* Insert the contents of the substring into */
/* another string at the character position specified */
Insert(S1, Sub, Position)
char S1 [ ], Sub[ ];
int position;
{
int i, j, k, flag ;
char temp[80];
/* To check whether the position is valid */
flag = position >= Len(Sl)?l:0 ;
if(flag)
return(-1);
/* Copy characters into temporary string */
/* prior to the position */
for(i=0, j=0; i<position, i++, j++)
temp[j]=S1[i];
/* Append the substring to current contents */
/* of the temporary string */
for(k=0; Sub[k]!=‘�’; ++k, j++)
temp [j] = Sub[i] ;
/* Now append the remainder of the string */
/* to the temporary string */
while(temp[j++]=S1[i++])}
;
/* Copy contents of the temporary string back */
/* into the original string */
strcpy(Sl, temp); /* Use of C-Library function */
/* to copy the string */
/* from temp to S1 */
}
Example 4.4
/* This function returns the position of the first */
/* occurrence of the substring S2 in the string S2 */
Index(S1, S2)
char S1[ ], S2 [ ];
{
int i, j, k ;
for(i=0 ; S1[i]! =‘�' ; i++)
for(j=i, k=o; S2[k] = = sl[j] ; k++, j++)
if(S2 [k+1]==‘�’ )
return(i); /* Substring is found */
/* Substring is not found */
return(-1);
}
We now present two more functions, namely, remove (S), and remove_al l_blanks (S1). The first function removes all trailing blanks and the second function removes all blanks from the given string.
Example 4.5
/* Removes trailing blanks from the string S */
remove(S)
char S[ ];
{
int i=0;
/* Find newline character */
while(S [i++] ! = ‘
’ )
;
while( i> =o&&S[i]!=‘ ’)
i--;
if (i>=0)
{
++i;
S[i] =‘
’; /*Insert new line character */
/* again*/
++i;
S[i]=‘�’; /* Insert null character */
}
return(i);
}
We now consider another string function called append (S1, S2). It appends the contents of S1 to the contents of S2. For example, if S1 contains ‘C’ and S2 contains ‘program in’, then the content of S2 will be program in C after append (S1, S2) was called.
/* Appends the contents of S1 to the contents */
/* of S2 */
append(S1,S2)
char S1[ ]. S2[ ] ;
{
int i, j;
/* Find the end of ↓ S2 */
for(i=0; S2[i]! = *�'; i++)
/* Append S1 to 2 ↑*/
for(j=0; (S2[i]=S1[j])! = ‘�’; ++i, ++j)
;
}
The above function appends the contents of S1 to the contents of S2. We can also utilize the function to append the contents of S2 to the contents of S1 by interchanging the arguments, that is, append (S2, S1) instead of append (S1, S2).
The function Remove_all_blanks ( ) deletes all spaces from a string. Some more examples are also given.
Example 4.7
/* Remove all of the blanks in the character string S */
Remove_all_blanks(S)
char S[ ] ;
{
int i, j ;
char temp [80];
/* Remove all blanks in the string */
for(i = 0, j=0; S[i]!= ‘�'; i++)
if(S[i]!=‘b’)
temp[j++]= S[i];
temp[j] =‘�’;
strcpy(S,temp);
}
Example 4.8
/* Appends blank spaces prior to the first character */
/* in string S */
/* S–String and N – No. of blank spaces to be inserted */
Pad (S,N)
char S[ ] ;
int N;
{
int i, count;
char temp[80];
for(Count =0; Count <N; Count++)
temp[Count] = ” ”;
temp[Count] = ‘�’;
/* Append the contents of the string to the */
/* string S */
append(S, temp);
strcpy(S, temp);
}
/* The program extracts substring from text */
char temp[80];
main ( )
{
char text[80] ;
int i, m; /* i –String, m– end of substring from initial */
gets (text);
scanf(“%d%d”,&i, &m) ;
substr(text, i,m);
printf(“
Substring from i =%d to m=%d is : %s”, i,m, temp);
}
substr(text,i,m)
char text[80] ;
int i, m;
{
int j, k=0 ;
for(j=i; j<=m; j++)
temp[k++]=text[j];
temp[k] = ‘�’;
return;
}
abcdefgh
2 4
Substring from i=2 to m=4 is: cde
Let us now write an algorithm for finding the location where the pattern P is a leftmost substring of string S.
Algorithm
Input: S and P are two strings with lengths n and m, respectively, and are stored in an array. It is assumed that the value of m is less than or equal to n.
Output: If the pattern P is a leftmost substring of string S starting at the kth character of S, this algorithm returns k, otherwise it returns 0.
Stepl: Set k ←1, j ←1 and X ← m–n+1
Step 2: If k > x then return 0 and exit
Step 3: If P[j] = S [ k+j–1] and j=m then return k and exit.
Step 4: Repeat Step 5 while P[j]= s[k+j–l] and j<m
Step 5: Set J <--j+1
End of loop.
Step 6: If P[j] # S [k+j–1] then Set k<--k+1 and Set j<--1
Step 7: Go to Step 2
Step 8: Exit
It is left to the reader as an exercise.
4.4 PATTERN MATCHING
Pattern matching is an important problem that occurs in different areas of computer science and information processing. The basic objective of the problem is to detect the occurrence of a particular string of characters (the pattern) as a substring in a sequence of characters (the input string). For example, the input string ‘computer science’ contains the pattern ‘science’ as a substring. Many text editors and programming languages (such as C, PASCAL, etc.) have facilities for matching strings. Pattern matching is one of the central and most widely studied problems in theoretical computer science.
There are three basic approaches for implementing pattern-matching algorithms. Each of them is conceptually simple but the performance of the third one in many cases is the fastest-known pattern-matching algorithm in both theory and practice.
The first approach, called the brute-force algorithm, is the one that first comes to mind whenever the pattern-matching problem is addressed. The pattern is placed over the input string at its extreme left. The pattern and input characters are then scanned to the right for a mismatch. If a mismatch is found, the pattern is shifted one position to the right and the scan is started again at the new position of pattern. Whenever a partial match fails a backtracking is necessary over the pattern.
In the second approach, initial pattern and input string placement are as in the brute-force algorithm and scanning is done to the right. When a mismatch occurs, however, the pattern is shifted to the right in such a way that the scan can be restarted at the point where a mismatch occurs in the input string. In this case no backtracking is therefore required.
In both approaches the pattern is scanned from left to right and each input character is checked at least once. This approach achieves great speed by skipping over portions of the input string that cannot possibly contribute to a match.
In the next subsections we will present three approaches for pattern-matching problems. For convenience, we will assume P=P1, P2,…, Pm of length m and S= S1 S2,…Sn of length n where P represents the ith character of the pattern and $j the jth character of the input string.
Note that when we will implement algorithms through C programs, we will use pattern as P0 P1,…, Pm−l and input string as S0,S1,…, Sm−l S1nce the index of array starts from 0 in C.
Further, it is straightforward to generalize these algorithms to locate all occurrences of the pattern in the input string.
4.5 THE BRUTE-FORCE ALGORITHM
The initial algorithm is the obvious one. First, the pattern and the input string are stored in two arrays. Next it looks for a match by comparing the patterns p1, p2,…,pm with the m-character substring Sk, Sk+1,…,Sk+m−1 for each successive value of K from 1 to n–m+1. It compares the pattern with the substring of the input from left to right until it either matches all of the pattern or finds that P2#Sd for some l≤i≤m and K≤j≤k+m–l. This is shown in Fig. 4.1.

Fig. 4.1 Illustration of pattern matching
When a mismatch occurs, it slides the pattern one character to the right and starts looking for a match by comparing P1 with Sk+1. The following algorithm illustrates the Brute-Force approach.
4.5.1 Algorithm: Brute-Force Pattern Matching
Input: P and S, arrays of pattern and input string characters. m>0 and n>0 are the number of characters in P and S, respectively.
Output: If P is the leftmost substring of S at the ith character of S, the algorithm returns the location, i, of the pattern in the input string. If P is not a substring of S, the algorithm returns a message ‘pattern not found’.
Step 1: Set i ← 1 /* Current guess where pattern begins in input */
Step 2: Set j ← 1 /* Pointer into the input string */
Step 3: While (i<= m and j<= n)
Step 4: If (P[i] = = S [j] then i ← i+1 and j = j+1
else
i ← 1 and j = j–i+2
Step 5: Wend /*End of while loop */
Step 6: If i>m then
return (‘Pattern is found at', i)
else
return (‘Pattern is not found’)
Step 7: Stop
The worst-case execution time occurs when P=am_1b and S=an, that is, for every possible starting position of the pattern in the input string, all but the last character of the pattern matches the corresponding character in the input string. In this case 0(mn) comparisons are needed to determine that the pattern does not occur in the text. In practical situations, the expected performance of the brute-force algorithm is usually 0(m+n), but a precise characterization depends on the statistical properties of the pattern and input string. The algorithm requires a buffer of size 0(m) to hold the pattern and the m-character substring of the input.
Besides its 0(mn) worst-case execution time, the brute-force algorithm has another property that makes it undesirable in certain applications. It requires backtracking on the input string. This leads to inefficiencies if the entire input string is not available in memory and buffering operations are necessary.
We now present the C program for the Brute-Force algorithm.
Example 4.10
/* Brute-Force algorithm */
# define MAXPATLEN 80
# define MAXTEXLEN 80
# include <stdio.h>
# include <string.h>
main ( )
{
char P[MAXPATLEN], S[MAXTEXLEN] ;
int m, n ; /* m–Length of P, n– Length of S */
printf(“
Enter the text:”);
gets(S);
printf(“
Enter the pattern to be matched:”); gets(P);
m=strlen(P); /* Length of pattern using strlen ( ) */
n= strlen(S); /* Length of text using strlen ( ) */
/* strlen ( ) is a C-Library function */
Brute _ Force (S,P, m,n,) ; /* Function call */
}
/* Brute-Force function */
Brute_Force (S,p,m,n )
char S[ ], P[ ];
int m,n;
{
int i, j, k;
i = 0 ;
j = 0 ;
k = -1 ;
while ( i<m && j<n)
{
k = k+1 ;
if(p[i] == S[j] )
{
i++;
j++;
}
else
{
i = 0 ;
j ++;
}
}
if( i==m)
printf (‘Pattern is found at', k );
else
printf (‘Pattern is not found’);
return ;
}
4.6 KUNTH-MORRIS-PRATT ALGORITHM
The second approach to pattern matching is described by Kunth, Morris, and Pratt (1979). We refer to it as the Kunth, Morris, and Pratt algorithm. It is conceptually a Simple modification of the previous algorithm. This algorithm preprocesses the pattern and constructs a table showing how far to move the pattern after each possible miss. The essence of the algorithm is to shift the patterns to the right bases on the table. To illustrate the algorithm, we will assign specific meaning to the terms match, hit, and miss. A match occurs when a substring of text, S, is same as the pattern, P, itself. A hit happens when a Single character of pattern P is the same as the corresponding character of S. A miss occurs when a character of P is different from a corresponding character of S. It is possible to recognize whether P is a substring of S in time 0( | P | + |S|), where |P| and |S| represent the length of P and S, respectively.
Consider the string (S) and pattern shown in Fig. 4.2. This example is taken from Kunth et al. 1977.

Fig. 4.2 String and pattern
We will assume that the search begins at the left end of S to be searched.
Suppose ![]() and
and ![]() and assume that we are currently determining whether or not there is a match beginning at
and assume that we are currently determining whether or not there is a match beginning at ![]() then we proceed by comparing si+1 and p1. Similarly, if si = p1 and sj+1 # p2 then we may proceed by comparing si+1=P1 In general, after starting it is found that
then we proceed by comparing si+1 and p1. Similarly, if si = p1 and sj+1 # p2 then we may proceed by comparing si+1=P1 In general, after starting it is found that ![]() matches
matches ![]() and
and ![]()
The best possible place to recover from this failure would be to slide P over the right so that as many of its initial characters p1,p2,…,pjmatch as many of the final characters of s1,s2,…si as possible, provided we can continue matching si+1 with pi+1from this position. Thus, we want to find the longest head of P, p,p1,p2,…,pj is equal to the tail of ![]() for which
for which ![]() . So we find that the first j+1 symbols of P have been matched. We continue further pattern matching from this position. To see how the method works, let us consider the following example.
. So we find that the first j+1 symbols of P have been matched. We continue further pattern matching from this position. To see how the method works, let us consider the following example.
Example: Consider the pattern P= abaababaabaab. The algorithm A produces Table 4.2.
Table 4.2 Pattern and Next Function
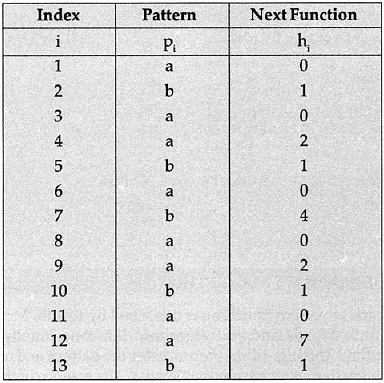
Let us now apply Kunth-Morris-Pratt algorithm (Algorithm B) to look for the pattern P in the input string abaababaabacabaababaabaab. Initially, the first 11 characters of P and S (the input string) align successfully. Let i be the pointer of p and j be the pointer of S. When i=j=12, the algorithm finds a mismatch at the input character C. The first iteration of the inner loop of algorithm B sets i=h12=7 ( from hi of Table 4.2). This has the effect of shifting the pattern five characters to the right, so position 7 of the pattern is now aligned above position 12 of the input string. At this point pi still does not match Sj, so i is set to h7=4. Mismatches continue for i=4,2,1,0. At this point the inner loop is exhausted without finding a match and the outer loop then sets i to 1 and j to 13. It is shown in Fig. 4.3.

Fig. 4.3 A successful match
We now present the algorithm for Kunth-Morris-Pratt pattern matching technique.
4.6.1 Algorithm A: Kunth-Morris-Pratt Pattern Matching
This algorithm needs a tail h, called the next function, for locating a match between pattern and input string. So we describe two algorithms A and B, for next function and pattern matching. The algorithm B utilizes the algorithm A.
Algorithm A: Compute the next function h for pattern P=p1,p2,…,pm.
Input: P, a string of characters; m>0, the length of P.
Output: h, an array representing the next function for p.
Step 1: Set i ← 1, j ← 0 and h[l] ← 0
Step 2: While (i<m)
Step 3: While (j>0 and p[i] # p[j])
Step 4: Set ← h [J]
Step 5: Set i ← i+1 and j ← j+1
Step 6: If (p[i] ← p[j]) then h[i] ← h[j]
else
h[i] ← j
Wend /* End of inner while loop */
Wend /* End of outer while loop * /
Step 7: Stop
4.6.2 Algorithm B: Kunth-Morris-Pratt Pattern Matching
Input: P and S, arrays of pattern and text characters; m>0 and n>0 the number of characters in P and S, respectively; h, the next function computed by algorithm A.
Output: Success or failure indicator and if successful, the location of the pattern in the input string.
Step 1: Set j ← 1 and i ← 1
Step 2: While (i<= m and j<= n)
Step 3: While (i>0 and p [i] # S [j])
Step 4: Set i ← h [i]
Wend / * End of inner while* /
Step 5: Set i ← i+1 and j ← j+1
Wend / * End of outer while* /
Step 6: If (i>m) then
return (‘pattern found’)
else
return (‘pattern is not found’)
Step 7: Stop
We now present the C program for Kunth-Morris-Pratt algorithm.
Example 4.11
/* Kunth-Morris-Pratt */
int h[80], m, n ;
main ( )
{
char pat [80], s[80];
int i,j;
gets (s);
puts (s);
gets (pat);
puts (pat);
m = strlen (pat);
n = strlen (s);
i=1;
j=1;
f (pat);
while (i<=m && j<=n)
{
while (( i>0 && (pat[i-1] ! = s[j-1]))
i = h[i-1];
i++;
j++;
}
if (i > m)
printf("yes
");
else
printf("no");
}
f(pat)
char pat[ ];
{
int i,j;
i=1, j=0 ;h=[0]=0;
while (i<= m)
{
while(( j>0) && (pat[i-1]!=pat[j-1]))
j=h[j-1];
i++;
j++;
if (pat[i-1] = pat[j-1];
h[i-1] = h[j-1];
else
h[i-1] = j;
}
for(i=0 ; i<m ; i++)
printf("%3d", h[i]);
printf("
");
}
Boyer and Moore came up with another string-matching algorithm that finds whether a pattern P is a substring of S. It is based on the ingenious observation that is more efficient to compare characters starting at the right end of the pattern and working to the left. Since this algorithm starts on the right of the pattern, it has the ability to pass more characters than it examines. Kunth has proved that the Boyer-Moore algorithm has linear behaviour in the worst case. This algorithm may be much faster than the previous two algorithms if the pattern length is sufficiently large. The Boyer-Moore algorithm preprocesses the pattern and prepares two tables. The first table stores the distance from the right end of the pattern to the first occurrence of each letter of the alphabet. The second one contains a value for each character in the pattern.
The essential features of the Boyer-Moore algorithm can be summarized as follows.
(A) In this method character comparisons are made starting at the right end of the pattern and moving towards the left. So some characters are never considered.
(B) This method preprocesses the pattern for creating two tables (as stated above). When a miss occurs, the decision about how far to advance the pattern, is based on two possibilities.
(1) The value of the text character at which the miss occurs and the distance to the left at which that value first occurs in the pattern.
(2) The value of all text characters that have been hit, together with the value that is known not to occur because of a miss.
(C) The pattern is moved the distance given by the maximum of (1) and (2) above.
We now explain the essential features of the Boyer-Moore algorithm in terms of S and P.
Suppose that we are checking the characters of P against those of S in right-to-left order. If all characters of P match those of S beneath, we have found a substring of S to match P.
Initially, we compare ![]() with
with ![]() If Sm occurs no-where in the pattern, then there cannot be a match for the pattern beginning at any of the first m characters of the input string. We can safely slide over the pattern m characters to the right and try to match pm with s2m. So we avoid m–1 unnecessary character comparisons.
If Sm occurs no-where in the pattern, then there cannot be a match for the pattern beginning at any of the first m characters of the input string. We can safely slide over the pattern m characters to the right and try to match pm with s2m. So we avoid m–1 unnecessary character comparisons.
Suppose we have just shifted the pattern to the right and are about to compare pm with sk. This is shown in Fig. 4.4.

Fig. 4.4 Shift and compare Pm with sk
We now present cases corresponding to (1) and (2) above.
Case 1: We found that pm and sk do not match. If the rightmost occurrence of sk in the pattern is Pm-g' we can shift the pattern g positions to the right to align pm-g and sk and then resume matching pm with sk+g. The situation is shown in Fig 4.5.

Fig. 4.5 Compare Pm With Sk+g
If sk did not occur in the pattern, we would shift the pattern m positions to the right and start comparing p with sk+m.
Case 2: Suppose that the last m-i characters of the pattern match with the last m-i characters of the input string ending at position k, that is, ![]()
If i=0, we have found a match, otherwise we consider two cases, that is, i>0 and pi=8k-m+i. If the rightmost occurrence of the character sk-m+i. in the pattern is pi-g' then we can simply shift the pattern g positions to the right, so that pi-g and sk-m+i align. The pattern matching starts again by comparing Pm with sk+g, as shown in Fig. 4.5.

Fig. 4.6 Compare sk+gwith Pm
If pi-g is to the right of pi(g<0), then we would instead shift the pattern one position to the right and resume matching by comparing Pm with sk+1. The first covers Case 1 and Case 2 in the discussion above.
The first table, called d1' determines how far to slide the pattern to the right when pi#sj. It is indexed by characters. The table d1 is a function of the text character C for which the mismatch occurred. For every character C1'd1[C] is the largest i such that C=pior C=m if the character C does not occur in the pattern.
Case 3: The second table, called d2' is a function of the position in the pattern at which the mismatch occurred. Suppose suffix ![]() reoccurs at the substring
reoccurs at the substring ![]() in the pattern and P1#Pi-g. If there is more than one such reoccurrence, we take the rightmost one. In this case a longer shift than Case 2 may be possible by aligning
in the pattern and P1#Pi-g. If there is more than one such reoccurrence, we take the rightmost one. In this case a longer shift than Case 2 may be possible by aligning ![]() above
above ![]() and restarting the scan by comparing pm with sk+g (Fig. 4.7).
and restarting the scan by comparing pm with sk+g (Fig. 4.7).

Fig. 4.7 Illustration of table d2
The table d2 is indexed by positions in the pattern. For every 1≤i≤m (m is the length of pattern P), d2[i] gives the minimum shift g such that when we align pm over sk+g the substring ![]() of the pattern matches with substring
of the pattern matches with substring ![]() of the input string, assuming Pi did not match sk-m+i. It is left to the reader as an exercise. Also, write a C program for the algorithm. In this chapter, we have discussed the string-processing and pattern-matching problems. Algorithms are given for solving string-matching problems that have proven useful for text-editing and text-processing applications. In the next chapter, pointers in C will be discussed.
of the input string, assuming Pi did not match sk-m+i. It is left to the reader as an exercise. Also, write a C program for the algorithm. In this chapter, we have discussed the string-processing and pattern-matching problems. Algorithms are given for solving string-matching problems that have proven useful for text-editing and text-processing applications. In the next chapter, pointers in C will be discussed.
E![]() X
X![]() E
E![]() R
R![]() C
C![]() I
I![]() S
S![]() E
E![]() S
S
1. Write a C program to count all occurrences of a particular word from a given text.
2. Write a program that prints the user specified last n lines of its input. If n is more than the number of lines in the input, all the lines should be printed. If n is not specified, a default number of p lines should be printed.
3. Write a function that replaces the first occurrence of a given substring in a source string by the specified substitution string.
4. Write a C program that converts a given string to its equivalent floating-point equivalent.
5. Write a function check (str, c) to print C' if Cis in the string pointed to be Str. The parameter str is a pointer to a char, and the parameter C is a char. If Cis not in the str, return 0.
6. Write a C program to print the word 'Computer' in the following way:
Computer
Compute
Compu
Comp
Com
Co
C
7. Write a C program that copies its input to output, except that it removes trailing blanks, leading blanks, and tabs from the end of lines and prints only one line from each group of adjacent identical lines.
8. Write a function to extract a portion of a character string and print the extracted string. Assume that p characters are extracted, starting with n characters.
9. Write a function that appends a string to a given string. In the resultant string, any upper-case character in the original string needs to be converted into lowercase, and vice-versa.
10. Briefly describe the merits and demerits of all the pattern-matching algorithms that were discussed in this chapter.