
11
Axiomatic Analysis of Pre-Processing Methodologies Using Machine Learning in Text Mining: A Social Media Perspective in Internet of Things
Tajinder Singh1, Madhu Kumari2, Daya Sagar Gupta3* and Nikolai Siniak4
1 Department of CSE, SLIET Longowal, India
2 Department of CSE, Chandigarh University, India
3 Department of CSE, RGIPT Amethi, India
4 Private Institute of Management and Business, Belarus
Abstract
Despite of the behemoth utilization of social media platforms for various aspects, which provides opportunities to analyze and study the social behavior of users, text mining’s role has been not explored fully. For this, text mining is the way to discover interesting patterns in data. The motive of text mining is to utilize discovered patterns to elucidate contemporary behavior or to predict future outcomes. Multiple disciplines participate in crawling text to discover required textual patterns such as mathematical modeling, computer science, data mining and warehousing to name a few. For this purpose, embeddings are also playing a key role and under the umbrella of machine learning, IoT (Internet of things) are coping up flawlessly at an individual level to predict the behavior in terms of security privacy, analysis, and prediction. Through this chapter, explaining the role of such strategies in social media text analysis for finding knowledgeable patterns. To illustrate and deliberate the areas of social media which are reachable on an amazing variety in the field of text mining using IoT-enabled services in terms of machine learning are also described. Outcomes can provide as a baseline for future of IoT research based on machine learning in emerging applications.
Keywords: Text mining, social media, embeddings, clustering, pre-processing, Internet of Things (IoT)
11.1 Introduction
In these days’ social media is acting as a double edged sword to share information, at its low cost with easy usage and explosive growth. Explosion of live multimedia streams text magnetize online social clients to contribute in real time phenomenon to become an element of gigantic multitude as they want to participate by publishing information in terms of text, video, image or sharing URL. Though, the immense quantity of text available on social media beside with the redundant information demands a momentous venture of collected social text stream. Removing of unwanted information and keywords from the collected text is very common practice. Usually social users do not write a words with correct spellings due to which numerous kind of ambiguities like lexical, semantic and syntactic occurs. Various machine learning approaches are available which helps to remove unwanted information from social text and identify the key theme in extracted social patterns. Therefore online social media and text mining is expanding with a huge degree. In current era a new story of text mining has begun as vast amount of text is posted on a various kind of social media such as Twitter, Facebook, forums, and blogs etc. Numerous types of knowledgeable patterns can be analyzed as it is a knowledge intensive manner. The text is collected over a certain period of time and various analysis tools are used to seek appropriate information from various social media resources through the classification and examination of mes-merizing patterns. Unstructured formats are available as the collected text usually comes in unstructured format and the lack of knowledge to deal with such strange patterns of text forced the researchers to perform scrubbing and normalizing data.
A dynamic and attractive source can change the whole story as it can be a big resource to generate innovative pattern of information. The dynamic nature also helps the users to get updates on time whenever required which not lonely propose a baseline for the social users but also for those who are interested to participate and keep track on daily update with time. With such kind of explosion in social media provides a full freedom to participate and to be a part of current trend. Critical analysis at regular intervals is also to be maintained to keep track on social user’s activities for a variety of perspectives’ plausibility. Numerous methods and training ways are addressed and discussed which are communally used to share and with new users to analyze reappearance of text [1].
These all mechanism diffuses information in vast extent and helps the social media for its rapid growth. Surprising growth and evolution of World Wide Web, online users are also increasing day by day. This exponential growth is never ended and such users participate in various activities of social media and generate a huge corpus of text. Multiple schemes are available which can combine and assemble collected text for analysis such as Leipzig Corpora Collection [2] and many more. The collected text demands for pre-processing [3] from which various features can be extracted and these features can be used for further research areas such as opinion/sentiment mining [4, 5], analysis of polarity disambiguation in sentiment analysis [6], detection, classification and analysis of social media events [7–9], burst analysis and trend forecasting [10], subject/topic tracking [11], recommendation method [12], Machine leaning applications in Internet of Things (IoT) and many more. Bag of Word (BOW) is a very realistic and simple approach which is used to represent text. Semantic information is also carried forward with the text representation so that the correct analysis can be performed. Doing such analysis helps the users to understand the nature of text and also provide a freedom where the large corpus of text can be converted into numeric data. Multiple influential mining mechanisms are available which can perform this task very well to extract required information [13, 14]. Few features which can be available in social text/documents can be described as:
- Tininess: As we know that social media have limit of words and size to post. Therefore we can say that social media text will be usually shorter such as in Twitter there is a 280 character limit to the length of a tweet [15]. With this small length of social post, it is very difficult and challenging task to analyze and extract essential features.
- Multitudinous Languages: Every social media platform facilitates their users to post with different kind of languages as they want. User can use language as per their choice and can participate in multiple social media activities such as blogs, social groups, communities as in FIFA WorldCup, public can watch and participate in any language on Twitter [16]. This kind of nature of social media creates a problem for social users to extract and analyze their meaning as slangs can be out of vocabulary.
- Belief: Social media text contains/holds beliefs which is also known as opinion and it is a quintuple (tobj, objf, sentiscore, oph, ᶵ), where, tobj is a goal object, objf is a feature characteristic of the object, sentiscore is the sentiment cost, oph is opinion container, ᶵ is time [17].
- Suitability: As we know the dynamic nature of social media make it more flexible and users can post in precise time intervals. The summary and the specifications of the posted text changes over time and sometimes the whole scenario of the content can also be changed which is difficult to understand.
Thus, from the above features it is observed that the role of text pre- processing is quite important and it is quite challenging and interesting also to extract the actual meaning of the collected text streams. Therefore, in the next section the role of pre-processing is explained which is proving an information in various domains.
11.2 Text Pre-Processing – Role and Characteristics
Non-standard and out of vocabulary words have their own role in social media and their negative impact on decision making is quite challenging. We have seen and observed from the above discussion how the pre-processing tasks are demanding for emerging methodology. In general form, an ISBN is usually worn to symbolize “International Standard Book Number” [18] and this abbreviation can be used by someone for other purpose also. Such kind of abbreviations, which are changing their sense from one tier to another, make pre-processing task more difficult. Instead of social media, social apps such as mobile phone messaging also contains non-standard or out of vocabulary words. Such words are very common and also handy e.g. hruhow are you, ttyl/talk to you later, cusee you [19], and many more. Therefore, in every social media, such words are increasing in rapid way and this is a very common practice in these days. Typos such as hiy/hey, bey/ bye/c u soon/see you soon and repetition of words like byeeeeee/bye, helllooooo/hello, and many more are the part of social media informal abbreviations. Influence of such words in social media is very critical and needs to be addressed.
- Power of out of vocabulary and non-standard words: In text mining, part of speech tagging [20] and NER (Name Entity Recognition) [21, 22] are very important part to gain high precision. With these two parameters, parsing mechanisms [18] i.e. syntax analysis parsing and machine translation are also to be considered. Because it has been observed that in many cases POS (Part of Speech) is frequently used with the combination of Penn tree bank to gain the information about particular keywords [23].
The performance and accuracy is degraded by non- standard and out of vocabulary words. To increase the performance and accuracy parsing is a best solution which helps to take care about out of vocabulary words [22]. We have seen that many researchers have used parsing on forums [24] and text diversity [25]. The authors have claimed that parsing gives best result but if errors occurs or performance degrades then the major reason behind this are unwanted population, false tokenization and out of vocabulary or non-standard words. Thus, we can say that wrong POS tagging generates error in parsing [19]. Such kind of issues is also available in machine translation in which machine interpretation can be wrong due to negative influence of our of vocabulary words. Let us consider an example of non-standard vocabulary which is pre-processed to gain the actual form of words in a sentence.
Before pre-processing: Finally he got a chance 2 wrk 2gther on a project.
After pre-processing: Finally, he got a chance to work together on a project.
Role of capital words in name entity recognition (NER) cannot be ignored which is also a part of non-standard word. Out is observed that with the increase of slangs, non-standard and out of vocabulary words on social media, segments of non-standards words are also growing. Sometimes slangs don’t have global impact but they contain local impact and cannot be ignored in text mining. In text mining these all act as a part of noise and such influence of words degrades the quality and performance of the text mining task. In Twitter we know that #tag, @tag are also play a significant role which are very important to consider and in [26] authors are working on domain adoption problem which is based on tagging mechanism. So we can say that tagging and its influence on the contextual information is important to consider which leads towards a successful text mining. For this purpose in section 11.3 modern text pre-processing approaches are discussed with their application domains.
11.3 Modern Pre-Processing Methodologies and Their Scope
In text mining research, pre-processing is required and it converts non-standard and out of vocabulary words into actual word. Sometime during pre-processing contextual information lost therefore, it is also very important to understand the contextual information in a suitable form. We have seen that in social media text analytics, contextual information is not considered usually and it leads towards wrong decision. In current era, sentiment analysis, polarity disambiguation in sentiment analysis, event detection, and classification are very common areas of research and everyday new event happened on social media. It is necessary to find the contextual information to count the exact meaning of a particular keyword [19]. In human analysis, it is easy to understand and recognize the contextual information but in machine translation it becomes difficult task. Efforts are required to understand and deal with this situation. From the previous study we can say that its very complex task and such keywords demands additional information also which is usually ignored.
Previous studies related to this text mining problem are designed in which context insensitive lexical approach is commonly used. The main motive of this approach is to reduce or remove the repetitive characters to gain the exact word. It works very well for minimizing the repeated words but it is difficult to analyze the actual sense and exact meaning of the word including the contextual information. Let us consider an example to understand this scenario. “Police will charge rupees 5 thousand fine for not tagging seat ballet in a car” whereas in second example: “I am absolutely fyn, What about you?”.
Now, in these examples, fine have two aspects in which it is representing money and felling/emotions of human concerned. From this example we can say that in re-processing it is necessary to consider the contextual as well as ambiguity in social media text. Many approaches which are handling ambiguity and also taking care of contextual information are explained further. As we know that the machine translation based and spell checking based pre-processing tasks are very communal used from the last many years. Including these two we have also explained the recent approaches which are used in pre-processing and contextual polarity disambiguation.
- Machine learning based text pre-processing approaches: Machine learning translation for social text pre-processing is widely used to convert non-standard and out of vocabulary words into accrual words. Phrase based machine version is used commonly to convert out of vocabulary words into actual words. We have identified that in [27, 28] phrase based machine translation approach is used on SMS texts. Similarly the supervised and unsupervised machine learning approaches are also used to process out of vocabulary words into actual words. In [29] a supervised machine learning approach is used for tweets collected from Twitter. A vast approach is given by the authors who is also performing pre-processing and if any letter/character is repeating then the approach is removing that repeated words to convert into normal form. Effectiveness and accuracy of the supervised machine learning approach is evaluated and the BLEU score is also increased.
- Further, a text processing mechanism based on statistical machine translation (SMT) is explained in [30]. An automatic statistical machine translation (SMT) is explained and developed. For development of the system the authors get information from the various internet users and designed a SMT models including vast knowledge of pre-processing mechanism but lack of deep contextual information of computer knowledge. For comparing and evaluating the effi-ciency of the system, the proposed system is implemented BLEU score and mystification of the language model.
Similarly, a machine learning approach based on character translation is commonly used for text pre-processing [31]. Character based machine translation can handle the sparse easily. We have observed that in social media text mining, due to sparse nature of words and non-standard words availability, it is very difficult to find a particular keyword from the collected data. Therefore, character level machine translation approach is used for informal text nor-malization. It is also found that when we are applying this approach database should be updated time to time when the new words are coming from various users with new abbreviations and types. For example if in the database “whr” is defined as where then it will be recognized otherwise it will be fail to understand the word due to nonexistence of information at character level translation.
- Spell checking based Text pre-processing methodologies: Detecting wrong spelling of various keywords and analyzing errors is a complex task in social text mining. Multiple reasons are associated with spelling mistakes such as typing errors, unintentionally typing wrong character like fair/ fear and peace/piece, principle/principal and many more. Many approaches are given by various authors and in [32], it is defined that 25% and 40% of spelling errors are effective English words. But with this analysis it is also found that with this identification we have to study that either these approaches are capable to convert non-standard words into standard formats or not. If they are detecting and converting words into standard words then accuracy is to be measured for that particular approach. Dictionary based approach is quite easy to use which helps the users to find the correct word from the collected text. We have seen that many authors have used dictionary based approach to correct the spelling of words and similarly in [35], a UNIX based dictionary is used. The main motive of using dictionary based approach is to find the corrected version of the word from the huge number of wrong words.
Usually the dictionaries are designed from large list of unigrams such as Google N-gram text corpus. Likelihood approach is used and depends on the user that how to consider the prior information and then what is the probability to match the words together. Distributional patters of words are also based on probability of matching words. In this approach a query based on misspelled words is matched with the dictionary and then the various patterns of matching are designed. The probability of finding correct pattern is computed and in social media, several non-standard words totally different from their standard word forms, which is away and outside the range of a spell check due to which a standard distribution of matching pattern is to be applied. As we have discussed above the repetition of the character can be corrected and similarly several words are existing in social media text which cannot be detected by spell checkers and not available in dictionary based approach (e.g. f9, b4, str8 etc.).
Various other approaches are also based on same sequences but in [36] a supervised machine learning approach is used. They used the unsupervised approach for text pre-processing and the proposed approach applied on short text messages such as tweets and SMS to find the non-standard words. The performance was computed and analyzed with the standard data sets and in the same way in [37] a special source channel based text processing approach is designed. Four factors are included in this approach such as contextual information, orthographic factor, a phonetic aspect, a contextual aspect, and short form growth. The study proved that the sources which create error to twitter data can be minimized and improved. The authors have practically performed and convert the various abbreviations into actual words such cu/see you”, which is included frequently as one of their model.
- Modern pre-processing approaches: In modern era numerous text mining and text pre-processing approaches have been designed. From last two years the number is increasing in a huge manner. In the above section we have given an overview about spell checking based and machine learning based approaches and without discussing the modern approaches of pre-processing it will be a discrimination. In the modern approaches, conditional random fields (CRF) based approaches are used for text pre-processing. The combination of CRF can be seen with various another modest networks such as RNN (recurrent neural networks), CNN (Convolution neural networks). Similarly in [38] CRF based approach is used for text pre-processing. A Bayesian based approach is implemented to extract the meaning of out of vocabulary words. For implementing modification in the collected text, CRF is also used which helps to update, delete and insert characters in the words. Linear chain models are also available for doing the same job and modest recurrent network can also be used.
- On the other hand Hidden Markov model (HMM) have also a great contribution in the area of text pre-processing. Various authors are using HMM for text mining activities and in [39], authors found its suitability for finding errors in text which are represented cognitive and typos. Cognitive errors are those errors are which are which are primarily initiated and the features of such errors are extracted on the basis of morphological or phonetic approximations. Typing errors are known as typos which occur unintentional/ accidentally during typing.
Unsupervised machine learning methodology is used by authors in [40] to pre-process the text. An approach based on random walk is used on noisy unlabeled text. Contextual information and similarity is also considered from the collected sequence of text.
In this approach a graph called bipartite graph is generated which is represented as G(W, C, E), in which ‘W’, contains all nodes representing pre-processed keywords and noisy out of vocabulary keywords, ‘C’, stands for contextual information and ‘E’, is representing the edges. The weight is updated on the basis of the word frequency. When a same word will occur again and again the analysis stage then the weight will be updated by one every time.
Another way of text pre-processing is parsing strategy. Parsers are widely used to find the meaning of non-standard words and it is used by various researchers whose motive is to find the exact meaning of non-standard words in the collected corpus. Therefore, a parsing based approach is applied in [41] whose main motive is to analyze non-standard words and to convert them into standard words. Performance of the parser is directly associated with the normalization performance and for this purpose evaluation based approaches can be used to measure the performance of various approaches w.r.t. to existing approaches. Numerous parameters are available to compute the performance of pre-processing approaches such as F-measure, precision and recall is widely used and acceptable. A modern sequential text pre-processing approach is given in [42] in which the main focus is drawn on English lexicons. The various strategies are applied to analyze the non-standard words and in first phase these non-standard words are converted into standard words. After analysis phase, domain information of the text is analyzed in next phase which enables further processing of text.
In the modern approaches of text pre-processing an integrated, unsupervised statistical methodology is also very popular and used by various researchers to normalize the text. In [43] same approach is used which is keeping track on converting out of vocabulary words into standard regular words. Random features are selected from the collected text and log- linear method is applied to extract the exact meaning of the words. In case of real time text, usually we deals with text streams and in twitter case, a collected tweet is represented as S={s1,s2,……..sn} when we are dealing with social text streams. The main motive of generating such string is to identify the exact meaning of keywords which is represented as tweet = {t1,t2,…….tn}. Similar kind of approach is used by various social media text analysis approaches to analyze the meaning of words. Finding the real time events based on various time strategy is also a part of social text stream which is dynamic in nature and changing with the change of time. Table 11.1 is showing the summarized version of various text pre-processing techniques.
Table 11.1 Summary of text pre-processing approaches.
| Reference and year | Major contribution | Methodology | Scoring |
|---|---|---|---|
| [28, 47, 55] |
| Open-source toolkit and SMT decoder. | Machine Learning Approach (Supervised) |
| [29, 17] |
| NLP (Natural Language Processing) | Machine Learning Approach (Supervised) |
| [30, 41, 58] |
| LI-rule, LS-rule, SMT. | Numerical Statistical based machine translation (SMT) |
| [10, 19, 33, 40, 49] |
|
Language model (5-gram) Preprocessing based on dictionary Generation | Machine Learning Approach (Unsupervised) |
| [43, 61] |
| log-linear model and UNLOL | Machine Learning Approach (Unsupervised) |
| [44, 52] |
| Language models | Machine Learning Approach (Unsupervised) |
11.4 Text Stream and Role of Clustering in Social Text Stream
Temporal and continuous extraction of social text in social text stream is a power of every kind of textual features. For extracting social text from twitter, API is designed which helps to extract social text pattern based on user’s query. In most of the cases, the process of extraction starts at ‘T’ which can be represented as closed time interval of time, [time1, time2] and it is defined as T = (t1,t2,….ti,… tr….., tn). A steam of social text is a sequence ‘S’ which is collected during various interval, S = {s1,s2,…. si,…..,sr…..sn}. From these collected intervals there may be several element of S such that si, holding a tweets ti. This part of tweet can be connected or linked with other entities in a social network. To analyze the actual connection and linking of tweets, various clustering mechanisms are used. Clustering is an easy way by which a stream of text can be categorized into various similar classes [44]. If in social text stream, S = (s1, s2, ….si, ….sr, ….sn), is distributed among clusters (C′) which is defined as C′ = (C1, C2, ……. Cj) where, C1, C2, ……. Cj ∈ S, such that S = ∪ (c1, c2, …… cj). Each of the object si, belongs to the cluster cj where, cj ⊂ C′.
A similarity based function can also be used which helps to assign a cluster to every incoming text stream on the basis of similarity index. Therefore, if the new keyword is coming then a new cluster is to be created otherwise existing cluster is to be assigned to the incoming textual data which increase its popularity and make it happening.
11.5 Social Text Stream Event Analysis
In social media event is related to anything happening surrounding. If the event will be popular then it will be very active on every kind of social media whereas other events will be ignored. If we consider a simple example as if there will be marriage function of a celebrity then it will act as a big event whereas marriage of a normal citizen will be a very common. Therefore, it is important to know the global context of an event whereas the local events does not contain any equivalent recognition in social media history as global events achieved [45]. From this discussion a social happening can be categorized into two ways:
- Planned events: The events which are pre planned such as IPL, president elections and many more. Various featured tagged with these events are needed to be including such as title, name, time, and place.
- Unplanned events: The events which can occur without any prior information such as earthquake, flood, tsunami and many more. No any information related to the event is associated about their happening but there as some signals which can helps to provide information about the occurrence of event content.
Social text stream: It can be represented as ‘s’ which helps to extract the tweets in ‘T’ in a specific time interval such as, [time1, time2]. The extracted tweets contain chain of text which can be a combination of tweets which is represented as, T = (t1,t2,….ti,… tr….., tn). In other words we can say that social text streams are the combination of continuous and discrete time internal in which various keywords may be linked with each other directly or indirectly. Information of sender and receiver is to be recorded and this scenario may vary from network to network.
From the social text stream it is observed that when the text is extracted, it will be full of noise such as unwanted symbols, abbreviations, short forms of specific words and may be some additional information in terms of tagging and emoticons. Due to this reason a pre-processing approach is required for cleaning the social text stream. We have studied various machine learning based methods which can clean the text in an efficient way. Various methods and techniques are present which classify and detect events from and those methods can be applied to perform pre-processing.
After pre-processing the processed form of text is stored on the basis of their similarity. For this purpose, clustering is used to organize similar text in a single cluster and accordingly others will be managed. Usually in the existing study we have seen that a dynamic clustering is used [46]. In various applications such as topic detection, event classification, event detection, trend analysis and many more are dependent on clustering [47] [48]. In previous study, many authors are applied clustering approach on various applications of text mining and similarly in [48] and [49] clustering is applied on event detection and tracking. The single pass clustering is implemented to analyze the text and to understand the evolving nature of the social events adaptive filtering mechanism is used.
Clustering based on supervised and unsupervised type is also preferred for content analysis. In [50] the authors used the machine learning mechanism whereas in [51] clustering based on machine learning approaches to identify events and their evolving nature is studied. Basically in social media if we want to extract some patterns from the social text stream then usually three steps are performed which are as follows:
- Clustering based on text
- Temporal segments
- Graph analysis of social network
In [52] authors developed an approach for event burst detection based on clustering. A spatial approach is used which helps to analyze the numerous feature of collected text whereas, in [53] a feature based pivot approach based on clustering is studied based on a time window. The time window helps to analyze various kinds of social patterns over time which changes with the change of time window [54]. In [55] a spatial clustering mechanism is applied on flicker text and to extract event from images a k-mean clustering with the combination of DWT is used in [56]. LDA based methods are also very popular in social text analysis and after pre-processing the LDA based methods can also be used. Various author used Bayesian filters for the analysis of social text in extraction of various features such as location and time [57, 58]. It is observed that such applications help to study the unplanned events very well such as earthquake, tsunami, etc. [59, 60]. A language based model called Latent Dirichlet Allocation Category Language Model is designed for topic modeling and also helps to catego-rize text into different classes.
So, we can say that it is very clear from the discussion that the pre- processing a backbone for each and every application of text mining. Without performing the task of pre-processing further analysis is not possible and it is better to understand the role of pre-processing so that an efficient and superior approach can be followed. Here now we are going to give some issues which are analyzed from the discussion and existing in the current study.
- Spam messages, abbreviations, short forms, slangs, irregular use of English words, emoticons using J, L and many more are the part of social media text. For analyzing and to extract knowledgeable patterns, it is important to pre-process the text accurately
- Due to dynamic nature of social media and multiple sources it is also necessary to study its changing behavior with the change of time.
Therefore, in this chapter, we explained a role of text pre-processing task in various application domains of text mining by considering various social text streams. For this purpose, the embeddings are also playing a key role in social media text analysis and they cannot be ignored. Effective vector representations for very short fragments of text in weighted form of word, embedding can be used. In various perspectives embeddings in social media can be used in which weighted embeddings are used widely and effectively. In case of embeddings it will very easy to apply clustering mechanism which helps to combine similar keywords in a group. Thus, we can say that embeddings are faster and efficient to use and for this reason we are explaining the usage of embedding in text mining domain in the next section.
11.6 Embedding
To generate and represent a social text stream or corpus into vector form embeddings are used. Figure 11.1 is describing the general architecture of embedding.
11.6.1 Type of Embeddings
Usually, it is found that there are three main types of classes on the basis of which embeddings can be classified based on the topic. Figure 11.2 is defining a way by which text can be retrieved and ranked with the help of an embeddings.

Figure 11.1 General depiction of embedding.

Figure 11.2 Types of embedding.
Latent semantic indexing (LDA): To identify and analyze hidden concepts and plan in the collected text LDA is widely used. In this method each keyword is represented in the form of vector. Semantic relationships between various documents and terms are analyzed to identify the hidden relationship within the social text. To produce all knowledgeable patterns, pre-processing is also required at initial stage for cleaning the text.
Figure 11.3 is a depiction of LSI (Latent Semantic Indexing). In this representation SVD (Singular Value Decomposition) is computed in in first stage. In Figure 1.3, ‘D’ is a representation of ‘M’ in ‘r’ dimensions, where, ‘T’ is a matric for transforming new documents. ∑, a diagonal matrix provides comparative importance of dimensions [61].

Figure 11.3 Depiction of latent semantic indexing (LSI).
The overall scenario of the model is represented as:

Here, f(q, d) is standing for score between a query q and an individual text d. Weight matric which is to be learnt is ![]() . For training purpose, normalized text stream/corpus
. For training purpose, normalized text stream/corpus ![]() is considered. As per the query, ‘q’ related ‘
is considered. As per the query, ‘q’ related ‘![]() ’ and unrelated ‘
’ and unrelated ‘![]() ’ text is analyzed. We would like to choose ‘S’ such as and it can merge to regain information as given below:
’ text is analyzed. We would like to choose ‘S’ such as and it can merge to regain information as given below:

Recurrent neural network: The popularity of acceptance of RRNs’ is gaining huge interest in the field of text mining. The application of RNN in language modeling is never ended due to their neurons. These neurons can employ to access its internal its internal memory which helps to maintain information associated to preceding state. Due to this property of RNN, contextual information related to every keyword can be preserved. RNNs are recognized as recurrent as they perform the related function for each module of a cycle through the output being inclined on the preceding computations. The distributed hidden feature of RNN helps to store huge information connected or linked with past in smooth manner. On the other hand, the non-linear dynamics feature allows restoring veiled state in multifaceted means. In Figure 11.4, folded RRN is shown and Figure 11.5 describes a complete network.

Figure 11.4 Representation of folded recurrent neural network (RNN).

Figure 11.5 Description of unfolded recurrent neural network (RNN).
In the above Figure 1.4, ‘xt’ is the input, ‘st’ is describing the hidden state at time ‘t’ and ‘ot’ is the output state. In mathematical form, RNN can be described as:
- Word2vec: Word2vec is also used in text mining analysis community. It helps to convert text into vector with very simple way. Many of the researchers have used this approach for various applications of text mining. Another benefit of using vector representation of text is that it gives an accurate and efficient semantic analysis. The vectors can be used for multiple tasks on social media text and we can say that the two models of word2vec such as Continuous Bag of Words (CBOW) and Skip-Gram are also doing a great work. Context information for a given context related to a particular word is easy to predict using CBOW, whereas in skip gram context is envisaged for a specified word. Figure 11.6 is describing the general view of BOW model in which various layers such as input, projection, and output are given and their link between them is also represented whereas in Figure 11.7 a depiction of skip gram is given.
- Clustering: It is an unsupervised process whose main motive is to search frequent features or related patterns. No any pre-defined class value is available in clustering and it collects the common features together and combines them to help the decision maker. Various applications of clustering are available in the field of text mining, machine learning, Sensor network, pattern recognition, image analysis, bioin-formatics and many more. Figure 11.8 is describing the general representation of clustering.
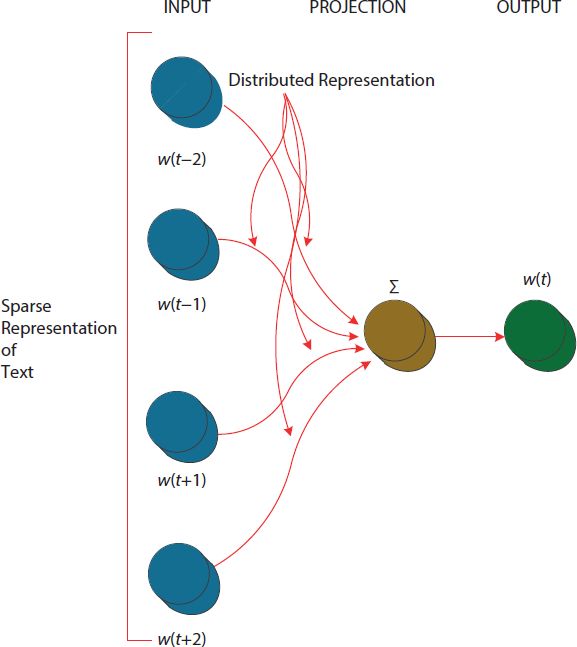
Figure 11.6 General depiction of continuous bag of words (CBOW).
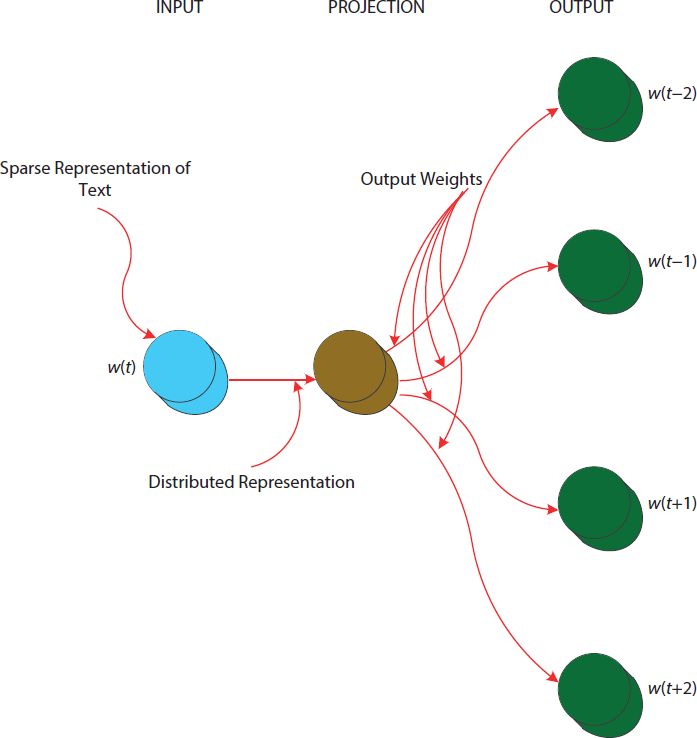
Figure 11.7 General depiction of Skip-Gram.

Figure 11.8 Representation of clustering.
11.7 Description of Twitter Text Stream
As we know that in text mining, for the experiment purpose, we can use existing text corpus or we can extract text from the social media called text stream. Current research is based on real time social text stream which helps to analyze social informative patterns for multiple purposes. Therefore, now in this section we present a twitter text stream. Due to its availability publically accessibility, we used this text stream for the experiment purpose also.
- Twitter Text Stream: For the experiment purpose, we crawled text from Twitter. The experiment is based on various features as described in Table 11.2. Total number of features extracted from the twitter text stream is 3453214 (after pre-processing) and when we perform clustering then on the basis of similarity of features we found 67540 similar features. Features. Various features were connected with each other through direct or indirect link and the connected features are 34398. These features are related with different nodes and these nodes include the information regarding sender and the receivers either in the way of direct indications from senders or their followers in the situation of transmission messages. On the other hand, on the average, each stream object contained about 84 nodes per tweet. Other features associated with this, experiments are described in Table 11.2 given below.
Table 11.2 Summary of collected statistics.
| Statistics | Total values |
|---|---|
| Total feature entities | 3453214 |
| Total types of feature’s categories | 67540 |
| Connected features | 34398 |
| Categories for features | 5430 |
| Average token features | 564 |
| Average predicates associated with features | 432 |
| Average total literals associated with features | 289 |
11.8 Experiment and Result
We performed a series of experiments to answer understand the role of embeddings and its role in social text stream. For this purpose we tried our best to configure model by implementing it on various social text streams. We implemented and analyzed the result for the Skip-Gram-based and word2vec optimization step.
11.9 Applications of Machine Learning in IoT (Internet of Things)
- To decrease the energy cost: Machine learning approaches are widely used to minimize the energy cost in various devices such as vehicles, smart homes, smart vehicle system and many more.
- In traffic routing: By implementing IoT using machine learning, numerous routes can be identified and suggested by a particular node in network traffic. In this way a small route can be identified in a particular network.
- Traffic prediction: This is a very popular application in these days in which machine leaning can embed with IoT to improve the precision of traffic system. Real time traffic analysis and prediction can also be analyzed to identify the traffic situation. IoT based environment embedded with machine learning helps to predict the future in fraction of seconds.
- In human living: For the home utility IoT based services are quite useful. IoT with machine learning is very useful in healthcare and can be used for the light, measuring humidity and temperature.
- In industry: In various industries such as gas, energy water an interface of IoT based devices is used with machine learning to analyze the demand-supply prediction.
- In manufacturing: In remote monitoring, product failure analysis, prediction and production automation IoT with sensor based technology is used for improving the product quality and anomaly detection.
- In retail and insurance: Novel value added services related to customer’s benefits is incorporated with IoT based methodologies under the umbrella of machine learning is used in a dynamic way to increase the value of various plans among customers.
11.10 Conclusion
In this chapter, the standard insights extraction for social text stream is explained for event evaluation. We have also explained how well it applies to a grammatically complex and local slangs of languages. Various processes and embedding mechanism are studied and identified as belonging to the standard structure of social media analysis such as text preprocessing, embeddings, clustering and extraction of event related keywords from collect text. From the above discussing it is observed that embeddings are very useful in social text analysis and from the experimental studies we can say that various features associated with collected text can be distinguished from disjunctively written languages. It is also observed that if we use embeddings in Twitter social text stream they have an optimistic impact on the accuracy. In the future, we are interested in extending the embedding models to ana-lyze the impact using large volume of data sets and social streams for pre-processing and keyword extraction.
References
- 1. Lifna, C.S. and Vijayalakshmi, M., Identifying concept-drift in twitter streams. Proc. - Proc. Comput. Sci., 45, 86–94, 2015.
- 2. Goldhahn, D., Eckart, T., Quasthoff, Q., Building large monolingual dictionaries at the Leipzig Corpora Collection: From 100 to 200 Languages. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC'12), pages 759–765, Istanbul, Turkey, European Language Resources Association (ELRA), 2012.
- 3. Singh, T. and Kumari, M., Role of text pre-processing in twitter sentiment analysis. Proc. - Proc. Comput. Sci., 89, 549–554, 2016.
- 4. Bhadane, C., Dalal, H., Doshi, H., Sentiment analysis: Measuring opinions. Proc. Comput. Sci., 45, C, 808–814, 2015.
- 5. Hamdan, H., Bellot, P., Bechet, F., Lsislif: Feature extraction and label weighting for sentiment analysis in twitter. SemEval, pp. 568–573, 2015.
- 6. Saleiro, P., Rodrigues, E.M., Soares, C., Oliveira, E., FEUP at SemEval-2017 Task 5: Predicting Sentiment Polarity and Intensity with Financial Word Embeddings. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), pages 904–908, Vancouver, Canada, Association for Computational Linguistics, 2017.
- 7. Vavliakis, K.N., Symeonidis, A.L., Mitkas, P.A., Event identification in web social media through named entity recognition and topic modeling. Data Knowl. Eng., 88, 1–24, 2013.
- 8. Zhou, X. and Chen, L., Event detection over twitter social media streams. VLDB J., 23, 3, 381–400, 2014.
- 9. Zhao, Q., and Mitra, P., Event detection and visualization for social text streams, in: ICWSM 2007 - International Conference on Weblogs and Social Media, International Conference on Weblogs and Social Media, ICWSM 2007, Boulder, CO, United States, pp. 1-3, 2007.
- 10. Aiello, L.M. et al., Sensing trending topics in twitter. IEEE Trans. Multimedia, 15, 6, 1268–1282, 2013.
- 11. Lin, J., Snow, R., Morgan, W., Smoothing techniques for adaptive online language models: Topic tracking in tweet streams. Proc. 17th ACM SIGKDD Int. Conf. Knowledge Discovery Data Mining, pp. 422–429, 2011.
- 12. Mart, L., Barranco, M.J., Luis, G.P., A knowledge based recommender system. Int. J. Comput. Intell. Syst., 1, 3, 225–236, 2008.
- 13. Quan, C. and Ren, F., Unsupervised product feature extraction for feature- oriented opinion determination. Inf. Sci. (NY), 272, 16–28, 2014.
- 14. Croft, W.B., Metzler, D., Strohman, T., Information retrieval in practice, pp. 1-542, Pearson Education, Inc., Boston: Addison-Wesley, 2015.
- 15. Ren, Z. and Meij, E., Personalized time-aware tweets summarization. SIGIR’13, Dublin, Ireland, July 28–August 1, 2013, pp. 513–522.
- 16. Ren, Z., Monitoring social media: Summarization, classification and recommendation, ZhaochunRen, Amsterdam, the Netherlands, 2016.
- 17. Pang, B. and Lee, L., Opinion mining and sentiment analysis. Found. Trends Inf. Retr., 2, 1–2, 1–135, 2008.
- 18. Cucerzan, S., and Brill, E.,. Spelling correction as an iterative process that exploits the collective knowledge of web users, in: Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, pages 293– 300, Barcelona, Spain, Association for Computational Linguistics, 2004.
- 19. Han, B., Improving the utility of social media with natural language processing, The University of Melbourne, Melbourne, Australia, February 2014.
- 20. Gimpel, K. et al., Part-of-speech tagging for twitter: Annotation, features, and experiments. Proceedings of the Annual Meeting of the Association for Computational Linguistics, HLT ‘11, vol. 2, pp. 42–47, 2011.
- 21. Liu, X., Zhang, S., Wei, F., Zhou, M., Recognizing named entities in tweets. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Portland, Oregon, pp. 359–367, June 19-24, 2011.
- 22. Owoputi, O., Connor, B.O., Dyer, C., Gimpel, K., Schneider, N., Smith, N.A., Improved part-of-speech tagging for online conversational text with word clusters, in: Proceedings of NAACL, pp. 380–390, June 2013.
- 23. Toutanova,K., Klein, D., Manning, C. D., Singer, Y.,. Feature-rich part-of-speech tagging with a cyclic dependency network, in: Proceedings of the 2003 Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics, pp. 252–259, 2003.
- 24. Foster, J., cba to check the spelling ‘ Investigating Parser Performance on Discussion Forum Posts, Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the ACL, Los Angeles, California, pp. 381–384, June 2010.
- 25. Baldwin, T., Cook, P., Lui, M., MacKinlay, A., and Wang, L.,. How Noisy Social Media Text, How Diffrnt Social Media Sources?. In Proceedings of the Sixth International Joint Conference on Natural Language Processing, pages 356–364, Nagoya, Japan. Asian Federation of Natural Language Processing, 2013.
- 26. Daum, H. and Marcu, D., Domain adaptation for statistical classifiers. J. Artif. Intell. Res., 26, 101–126, 2006.
- 27. Aw, A., Zhang, M., Xiao, J., Su, J., A Phrase-Based Statistical Model for SMS Text Normalization Proceedings of the COLING/ACL 2006 Main Conference Poster Sessions, Sydney, pp. 33–40, July 2006.
- 28. Koehn, P. et al., Moses: Open source toolkit for statistical machine translation. Proceedings of the ACL 2007 Demo and Poster Sessions, Prague, pp. 177–180, June 2007.
- 29. Kaufmann, M., Syntactic normalization of twitter messages. International Conference on Natural Language, pp. 1–7, 2010.
- 30. Schlippe, Tim & Zhu, Chenfei & Gebhardt, Jan & Schultz, Tanja. (2010). Text Normalization based on Statistical Machine Translation and Internet User Support. Proceedings of the 11th Annual Conference of the International Speech Communication Association, INTERSPEECH 2010. 1816-1819.
- 31. Pennell, D.L., A character-level machine translation approach for normalization of SMS abbreviations, in: Proceedings of IJCNLP, 2007, Sasa, pp. 974– 982, 2011.
- 32. Kukich, K., Techniques for automatically correcting words in text. ACM Comput. Surv., 24, 4, 377–439, Dec. 1992. https://doi.org/10.1145/146370.146380
- 33. Whitelaw, C., Hutchinson, B., Chung, G.Y., Ellis, G., Using the web for language independent spellchecking and autocorrection. Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Singapore, pp. 890–899, 6-7 August 2009.
- 34. Hearn, L.A.W. Detection is the central problem in real-word spelling correction. Computation and Language, Cornell University Library, arXiv preprint arXiv:1408.3153, 2014.
- 35. Ahmad, F., Learning a spelling error model from search query logs. Proceedings of Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing (HLT/EMNLP), Vancouver, pp. 955–962, October 2005.
- 36. Cook, P. and Stevenson, S., An unsupervised model for text message nor-malization. Proceedings of the NAACL HLT Workshop on Computational Approaches to Linguistic Creativity, Boulder, Colorado, pp. 71–78, June 2009.
- 37. Zhenzhen, X., Yin, D., Davison, B.D., Normalizing microtext. Workshops at the Twenty-Fifth AAAI Conference on Artificial Intelligence, 10, 74–79, 2011.
- 38. Chrupała, G., Normalizing tweets with edit scripts and recurrent neural embeddings. Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Short Papers), Baltimore, Maryland, USA, pp. 680–686, June 23-25 2014.
- 39. Choudhury, M., Saraf, R., Jain, V., Mukherjee, A., Sarkar, S., Basu. A., Investigation and modeling of the structure of texting language. Int. J. Document Anal. Recognit, 10, 3-4 157–174, 2007.
- 40. Hassan, H., Social text normalization using contextual graph random walks. Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, pp. 1577–1586, August 4-9 2013.
- 41. Zhang, C., Baldwin, T., Kimelfeld, B., Li, Y., Adaptive parser-centric text normalization. Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, August 4-9 2013, pp. 1159–1168.
- 42. Sarker, B., and Gonzalez-Hernandez, G., An unsupervised and customizable misspelling generator for mining noisy health-related text sources, J. Biomed. Inform., 88, 98–107, 2018.
- 43. Yang, Y., and Eisenstein, J., A log-linear model for unsupervised text nor-malization. in: Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pp. 61–72, Seattle, Washington, USA, Association for Computational Linguistics, 2013.
- 44. Aggarwal, C.C., Chapter 10 A survey of stream clustering algorithms, in: Data Clustering. Algorithms Applications, pp. 229–252, 2013.
- 45. Becker, H., Identification and characterization of events in social media Hila Becker, Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate School of Arts and Sciences, Columbia University, New York, NY 10027, US, 1–193, 2011.
- 46. Allan, J. and Papka, R., Search on-line new event detection. Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 37–45, 1998.
- 47. Lee, C.H., Unsupervised and supervised learning to evaluate event relatedness based on content mining from social-media streams. Expert Syst. Appl., 39, 18, 13338–13356, 2012.
- 48. Aggarwal, C.C. and Wang, J., Data streams: Models and algorithms, in: Data Streams, vol. 31, pp. 9–38, Kluwer Academic Publishers, Boston/Dordrecht/ London, 2007.
- 49. Allan, J., Papka, R., Lavrenko, V., On-line new event detection and tracking. SIGIR’98, Melbourne, Australia, ACM, pp. 37–48, 1998.
- 50. Aggarwal, C.C. and Subbian, K., Event detection in social streams. Proceeding. 2012 SIAM International Conference. Data Mining, pp. 624–635, 2012.
- 51. Becker, H. and Gravano, L., Learning similarity metrics for event identification in social media categories and subject descriptors. WSDM’10, New York City, New York, USA, February 4–6, 2010, 2010.
- 52. Chen, W., Chen, C., Zhang, L., Wang, C., Bu, J., Online detection of bursty events and their evolution in news streams. Front. Inf. Technol. Electron. Eng., 11, 5, 340–355, 2010.
- 53. Fung, G.P.C., Yu, J.X., Yu, P.S., Lu, H., Parameter free bursty events detection in text streams. VLDB ‘05 Proc. 31st Int. Conf. Very Large Data Bases, vol. 1, pp. 181–192, 2005.
- 54. He, Q., Chang, K., Lim, E., Zhang, J., Bursty feature representation for clustering text streams. Proceedings of the 2007 SIAM International Conference on Data Mining,(SDM), pp. 491–496, 2007.
- 55. Zeppelzauer, M., Zaharieva, M., Breiteneder, C., A generic approach for social event detection in large photo collections. Work. Notes Proc. Mediaev. 2012 Work, pp. 2011–2012, 2012.
- 56. Ghai, D., Gera, D., Jain, N., A new approach to extract text from images based on DWT and K-means clustering. Int. J. Comput. Intell. Syst., 9, 5, 900–916, 2016.
- 57. Yin, H., Cui, B., Li, J., Yao, J., Chen, C., Challenging the long tail recommendation. Proc. VLDB Endowment, 5, 9, 896–907, 2012.
- 58. Sakaki, T., Okazaki, M., Matsuo, Y., Earthquake shakes twitter users: Real-time event detection by social sensors. Proc. 19th Int. Conf. World Wide Web, pp. 851–860, 2010.
- 59. Singh, T., Kumari, M., Pal, T.L., Chauhan, A., Current trends in text mining for social media. Int. J. Grid Distrib. Comput., 10, 6, 11–28, 2017.
- 60. Zhou, S., Li, K., and Liu, Y., Text categorization based on topic model. International Journal of Computational Intelligence Systems, 2, 4, 398–409, 2009.
- 61. Bai, B. et al., Supervised semantic indexing. Proc. 18th ACM Conf. Inf. Knowl. Manag, pp. 187–196, 2009.
Note
- *Corresponding author: [email protected]