
Chapter 19
Network Troubleshooting
The Following CompTIA Network+ Exam Objectives Are Covered in This Chapter:
- 1.8 Given a scenario, implement the following network troubleshooting methodology:
- Identify the problem:
- Information gathering
- Identify symptoms
- Question users
- Determine if anything has changed
- Establish a theory of probable cause:
- Question the obvious
- Test the theory to determine cause:
- Once theory is confirmed determine next steps to resolve problem.
- If theory is not confirmed, re-establish new theory or escalate.
- Establish a plan of action to resolve the problem and identify potential effects
- Implement the solution or escalate as necessary
- Verify full system functionality and if applicable implement preventative measures
- Document findings, actions, and outcomes
- 2.4 Given a scenario, troubleshoot common wireless problems.
- Interference
- Signal strength
- Configurations
- Incompatibilities
- Incorrect channel
- Latency
- Encryption type
- Bounce
- SSID mismatch
- Incorrect switch placement
- 2.5 Given a scenario, troubleshoot common router and switch problems.
- Switching loop
- Bad cables/improper cable types
- Port configuration
- VLAN assignment
- Mismatched MTU/MUT black hole
- Power failure
- Bad/missing routes
- Bad modules (SFPs, GBICs)
- Wrong subnet mask
- Wrong gateway
- Duplicate IP address
- Wrong DNS
- 3.6 Given a scenario, troubleshoot common physical connectivity problems.
- Cable problems:
- Bad connectors
- Bad wiring
- Open, short
- Split cables
- DB loss
- TXRX reversed
- Cable placement
- EMI/Interference
- Distance
- Cross-talk
There is no way around it. Troubleshooting computers and networks is a combination of art and science, and the only way to get really good at it is by doing it—a lot! So its practice, practice, and practice with the basic yet vitally important skills you’ll attain in this chapter. Of course, I’m going to cover all the troubleshooting topics you’ll need to sail through the Network+ exam, but I’m also going to add some juicy bits of knowledge that will really help you to tackle the task of troubleshooting successfully in the real world.
First, you’ll learn to check quickly for problems in the “super simple stuff” category, and then we’ll move into a hearty discussion about a common troubleshooting model that you can use like a checklist to go through and solve a surprising number of network problems. We’ll finish the chapter with a good briefing about some common troubleshooting resources, tools, tips, and tricks to keep up your sleeve and equip you even further.
I won’t be covering any new networking information in this chapter because you’ve gotten all the foundational background material you need for troubleshooting in the previous chapters. But no worries. I’ll go through each of the issues described in this chapter’s objectives, one at a time, in detail, so that even if you’ve still got a bit of that previous material to nail down yet, you’ll be good to get going and fix some networks anyway.
To find up-to-the-minute updates for this chapter, please see www.lammle.com/forum or the book’s web site at www.sybex.com/go/netplus.2e.
When initially faced with a network problem in its entirety, it’s easy to get totally overwhelmed. That’s why it’s a great strategy to start by narrowing things down to the source of the problem. To help you achieve that goal, it’s always wise to ask the right questions. You can begin doing just that with this list of questions to ask yourself:
- Did you check the super simple stuff (SSS)?
- Is hardware or software causing the problem?
- Is it a workstation or server problem?
- Which segments of the network are affected?
Are There Any Cabling Issues? Did You Check the Super Simple Stuff?
Yes—it sounds like a snake’s hiss (appropriate for a problem, right?), but exactly what’s on the SSS list that you should be checking first, and why? Well, as the saying goes, “All things being equal, the simplest explanation is probably the correct one,” so you probably won’t be stunned and amazed when I tell you that I’ve had people call me in and act like the sky is falling when all they needed to do was check to make sure their workstation was plugged in or powered on. (I didn’t say “super simple stuff” for nothing!) Your SSS list really does include things that are this obvious—sometimes so obvious, no one thinks to check for them. Even though anyone experienced in networking has their own favorite “DUH” events to tell about, almost everyone can agree on a few things that should definitely be on the SSS list:
- Check to ensure login procedures and rights.
- Look for link lights and collision lights.
- Check all power switches, cords, and adapters.
- Look for user errors.
The Correct Login Procedure and Rights
You know by now that if you’ve set up everything correctly, your network’s users absolutely have to follow the proper login procedure to the letter (or number, or symbol) in order to successfully gain access to the network resources they’re after. If they don’t do that, they will be denied access, and considering that there are truly tons of opportunities to blow it, it’s a miracle, or at least very special, that anyone manages to log in to the network correctly at all.
Think about it. First, a user must enter their username and password flawlessly. Sounds easy, but as they say, “in a perfect world…” In this one, people mess up, don’t realize it, and freak out at you about the “broken network” or the imaginary IT demon that changed their password on them while they went to lunch and now, they can’t log in. (The latter could be true—you may have done exactly that. If you did, just gently remind them about that memo you sent about the upcoming password-change date and time that they must have spaced about due to the tremendous demands on them.)
Anyway, it’s true. By far, the most common problem is bad typing—people accidentally enter the wrong username or password, and they do that a lot. With some operating systems, a slight brush of the Caps Lock key is all it takes: The user’s username and password are case sensitive, and suddenly, they’re trying to log in with what’s now all in uppercase instead—oops.
Plus, if you happen to be running one of the shiny new operating systems around today, you can also restrict the times and conditions under which users can log in, right? So, if your user spent an unusual amount of time in the bathroom upon returning from lunch, or if they got distracted and tried to log in from their BFF’s workstation instead of their own, the network’s operating system would’ve rejected their login request even though they still can type impressively well after two martinis.
And remember—you can also restrict how many times a user can log in to the network simultaneously. If you’ve set that up, and your user tries to establish more connections than you’ve allowed, access will again be denied. Just know that most of the time, if a user is denied access to the network and/or its resources, they’re probably going to interpret that as a network problem even though the network operating system is doing what it should.
Can the Problem Be Reproduced?
The first question to ask anyone who reports a network or computer problem is, “Can you show me what ‘not working’ looks like?” This is because if you can reproduce the problem, you can identify when it happens, which may give you all the information you need to determine the source of the problem and maybe even solve it in a snap. The hardest problems to solve are those of the random variety that occur intermittently and can’t be easily reproduced.
Let’s pause for a minute to outline the steps to take during any user-oriented network problem-solving process:
1. Make sure the username and password is being entered correctly.
2. Check that Caps Lock key.
3. Try to log in yourself from another workstation, assuming that doing this doesn’t violate the security policy. If it works, go back to the user-oriented login problems, and go through them again.
4. If none of this solves the problem, check the network documentation to find out whether any of the aforementioned kinds of restrictions are in place; if so, find out whether the user has violated any of them.

Remember, if intruder detection is enabled on your network, a user will get locked out of their account after a specific number of unsuccessful login attempts. If this happens, either they’ll have to wait until a predetermined time period has elapsed before their account will unlock and give them another chance or you’ll have to go in and manually unlock it for them.
The Link and Collision Lights
The link light is that little light-emitting diode (LED) found on both the Network Interface Card (NIC) and the hub. It’s typically green and labeled Link or some abbreviation of that. If you’re running 10BaseT, a link light indicates that the NIC and hub are making a logical (Data Link layer) connection. If the link lights are lit up on both the workstation’s NIC and the hub port to which the workstation is connected, it’s usually safe to assume that the workstation and hub are communicating just fine.
The link lights on some NICs don’t activate until the driver is loaded. So, if the link light isn’t on when the system is first turned on, you’ll just have to wait until the operating system loads the NIC driver. But don’t wait forever!
The collision light is also a small LED, but it’s typically amber in color, and it can usually be found on both Ethernet NICs and hubs. When lit, it indicates that an Ethernet collision has occurred. If you’ve got a busy Ethernet network on which collisions are somewhat common, understand that this light is likely to blink occasionally; if it stays on continuously, though, it could mean that there are way too many collisions happening for legitimate network traffic to get through. Don’t assume this is really what’s happening without first checking that the NIC, or other network device, is working properly because one or both could simply be malfunctioning.
Don’t confuse the collision light with the network-activity or network-traffic light (which is usually green) because that light just indicates that a device is transmitting. This particular light should be blinking on and off continually as the device transmits and receives data on the network.
The Power Switch
Clearly, to function properly, all computer and network components must be turned on and powered up first. Obvious, yes, but if I had a buck for each time I’ve heard, “My computer is on, but my monitor is all dark,” I’d be rolling in money by now.
When this kind of thing happens, just keep your cool and politely ask, “Is the monitor turned on?” After a little pause, the person calling for help will usually say, “Ohhh…ummmm…thanks,” and then hang up ASAP. The reason I said to be nice is that, embarrassing as it is, this, or something like it, will probably happen to you too eventually.
Most systems include a power indicator (a Power or PWR light). The power switch typically has an On indicator, but the system or device could still be powerless if all the relevant power cables aren’t actually plugged in—including the power strip.
Remember that every cable has two ends, and both must be plugged in to something. If you’re thinking something like, “Sheesh—a four-year-old knows that,” you’re probably right. But again, I can’t count the times this has turned out to be the root cause of a “major system failure.”
The best way to go about troubleshooting power problems is to start with the most obvious device and work your way back to the power-service panel. There could be a number of power issues between the device and the service panel, including a bad power cable, bad outlet, bad electrical wire, tripped circuit breaker, or blown fuse, and any of these things could be the actual cause of the problem that appears to be device-death instead.
Operator Error
Or, the problem may be that you’ve got a user who simply doesn’t know how to be one. Maybe you’re dealing with someone who doesn’t have the tiniest clue about the equipment they’re using or about how to perform a certain task correctly—in other words, the problem may be due to something known as operator error (OE). Here’s a short list of the most common types of OEs and their associated acronyms:
- Equipment exceeds operator capability (EEOC)
- Problem exists between chair and keyboard (PEBCAK)
- ID Ten T error (an ID10T)
A word of caution here, though—assuming that all your problems are user related can quickly make an ID10T error out of you.
Although it can be really tempting to take the easy way out and blow things off, remember that the network’s well-being and security are ultimately your responsibility. So, before you jump to the operator-error conclusion, ask the user in question to reproduce the problem in your presence, and pay close attention to what they do. Understand that doing this can require a great deal of patience, but it’s worth your time and effort if you can prevent someone who doesn’t know what they’re doing from causing serious harm to pricey devices or leaving a gaping hole in your security. You might even save the help desk crew’s sanity from the relentless calls of a user with the bad habit of flipping off the power switch without following proper shutdown procedures. You just wouldn’t know they always do that if you didn’t see it for yourself, right?
And what about finding out that that pesky user was, in fact, trained really badly by someone, and that they aren’t the only one? This is exactly the kind of thing that can turn the best security policy to dust and leave your network and its resources as vulnerable to attack as that goat in Jurassic Park.
The moral here is, always check out the problem thoroughly. If the problem and its solution aren’t immediately clear to you, try the procedure yourself, or ask someone else at another workstation to do so. Don’t just leave the issue unsettled or make the assumption that it is user error or a chance abnormality because that’s exactly what the bad guys out there are hoping you’ll do.
This is only a partial list of super simple stuff. No worries. Rest assured you’ll come up with your own expanded version over time.
Is Hardware or Software Causing the Problem?
A hardware problem often rears its ugly head when some device in your computer skips a beat and/or dies. This one’s pretty easy to discern because when you try to do something requiring that particular piece of hardware, you can’t do it and instead get an error telling you that you can’t do it. Even if your hard disk fails, you’ll probably get warning signs before it actually kicks, like a Disk I/O error or something similar.
Other problems drop out of the sky and hit you like something from the wrong end of a seagull. No warning at all—just splat! Components that were humming along fine a second ago can and do suddenly fail, usually at the worst possible time, leaving you with a mess of lost data, files, everything—you get the idea.
Solutions to hardware problems usually involve one of three things:
- Changing hardware settings
- Updating device drivers
- Replacing dead hardware
If your hardware has truly failed, it’s time to get out your tools and start replacing components. If this isn’t one of your skills, you can either send the device out for repair or replace it. Your mantra here is “backup, backup, backup,” because in either case, a system could be down for a while—anywhere from an hour to several days—so it’s always good to keep backup hardware around. And I know everyone and your momma has told you this, but here it is one more time: Back up all data, files, hard drive, everything, and do so on a regular basis.
Software problems are muddier waters. Sometimes you’ll get General Protection Fault messages, which indicate a Windows or Windows program (or other platform) error of some type, and other times the program you’re working in will suddenly stop responding and hang. At their worst, they’ll cause your machine to randomly lock up on you. When this type of thing happens, I’d recommend visiting the manufacturer’s support website to get software updates and patches or searching for the answer in a knowledge base.
Sometimes you get lucky and the ailing software will tell the truth by giving you a precise message about the source of the problem. Messages saying the software is missing a file or a file has become corrupt are great because you can usually get your problem fixed fast by providing that missing file or by reinstalling the software. Neither solution takes very long, but the downside is that whatever you were doing before the program hosed will probably be at least partially lost; so again, back up your stuff, and save your data often.
Please reread Chapter 17, “Troubleshooting Tools,” and Chapter 18, “Software and Hardware Tools,” and use the software and hardware tools discussed in those two chapters to help you troubleshoot network problems.
Okay—it’s time for you to learn how to troubleshoot your workstations and servers.
Is It a Workstation or a Server Problem?
The first thing you’ve got to determine when troubleshooting these kinds of problems is whether it’s only one person or a whole group that’s been affected. If the answer is only one person, think workstation—more than that, and it’s probably part of the network (a segment) that’s giving you grief.
So what do you do about it? Well, if it’s the single-user situation, your first line of defense is to try to log in from another workstation within the same group of users. If you can do that, the problem is definitely the user’s workstation, so look for things like cabling faults, a bad NIC, power issues, and OSs.
But if a whole department can’t access a specific server, take a good, hard look at that particular server, and start by checking all user connections to it. If everyone is logged in correctly, the problem may have something to do with individual rights or permissions; if no one can log in to that server, including you, the server probably has a communication problem with the rest of the network. And if the server has totally crashed, you’ll either see messages regarding this nasty fact on the server’s monitor, or you’ll find its screen completely blank—screaming indications that the server is no longer running. All good, but it’s important to keep in mind that these symptoms vary among network operating systems.
Which Segments of the Network Are Affected?
Figuring this one out can be a little tough. If multiple segments are affected, you may be dealing with a network-address conflict. If you’re running Transmission Control Protocol/Internet Protocol (TCP/IP), remember that IP addresses must be unique across an entire network. So, if two of your segments have the same static IP subnet addresses assigned, you’ll end up with duplicate IP errors—an ugly situation that can be a real bear to troubleshoot and can make it tough to find the source of the problem.
If all of your network’s users are experiencing the problem, it could be a server everyone accesses. Thank the powers that be if you nail it down to that because if not, other network devices like your main router or hub may be down, making network transmissions impossible and usually meaning a lot more work on your part to fix.
Adding wide area network (WAN) connections to the mix can complicate matters exponentially, and you don’t want to go there if you can avoid it, so start by finding out if stations on both sides of a WAN link can communicate. If so, get the champagne—your problem isn’t related to the WAN—woo hoo! But if those stations can’t communicate, it’s not your lucky day: You’ve got to check everything between the sending station and the receiving one, including the WAN hardware, to find the culprit. The good news is that most of the time, WAN devices have built-in diagnostics that tell you whether a WAN link is working okay, which really helps you determine if the failure has something to do with the WAN link itself or with the hardware involved instead.
Is It Bad Cabling?
Back to hooking up correctly. After you’ve figured out whether your plight is related to one workstation, a network segment, or the whole tamale (network), you must then examine the relevant cabling. Are the cables properly connected to the correct port? More than once, I’ve seen a digital subscriber line (DSL) modem connection to the wall cabled all wrong—it’s an easy mistake to make and an easy one to fix.
And you know that nothing lasts forever, so check those patch cables running between a workstation and a wall jack. Just because they don’t come with expiration dates written on them doesn’t mean they don’t expire. They do go bad—especially if they get moved, trampled, or tripped over a lot. (I did tell you that it’s a bad idea to run cabling across the office floor, didn’t I?) Connection problems are the tell here—if you check the NIC and there is no link light blinking, you may have a bad patch cable to blame.
It gets murkier if your cable in the walls or ceiling is toast or hasn’t been installed correctly. Maybe you’ve got a user or two telling you the place is haunted because they only have problems with their workstations after dark when the lights go on. Haunted? No…Some genius probably ran a network cable over a fluorescent light, which is something that just happens to produce lots of electromagnetic interference (EMI), which can really mess up communications in that cable.
Next on your list is to check the medium dependent interface/medium dependent interface-crossover (MDI/MDI-X) port setting on small, workgroup hubs and switches. This is a potential source of trouble that’s often overlooked, but it’s important because this port is the one that’s used to uplink to a switch on the network’s backbone.
First, understand that the port setting has to be set to either MDI or MDI-X depending on the type of cable used for your hub-to-hub or switch-to-switch connection. For instance, the crossover cables I talked about way back in Chapter 3, “Networking Topologies, Connectors, and Wiring Standards,” require that the port be set to MDI, and a standard network patch cable requires that the port be set to MDI-X. You can usually adjust the setting via a regular switch or a dual inline package (DIP) switch, but to be sure, if you’re still using hubs, check out the hub’s documentation. (You did keep that, right?)
Other Important Cable Issues You Need to Know About
They may be basic, but they’re still vital—understanding the physical issues that can happen on a network when a user is connected via cable (usually Ethernet) is critical information to have in your troubleshooting repertoire.
Because most of today’s networks still consist of large amounts of copper cable, they suffer from the same physical issues that have plagued networking since the very beginning. Newer technologies and protocols have helped to a degree, but they haven’t made these issues a thing of the past yet. Some physical issues that still affect networks are listed and defined next:
Crosstalk Again, harkening back to Chapter 3, remember that crosstalk is what happens when there’s signal bleed between two adjacent wires that are carrying a current. Network designers minimize crosstalk inside network cables by twisting the wire pairs together, putting them at a 90-degree angle to each other. The tighter the wires are twisted, the less the crosstalk you have, and newer cables like Cat 6 cable really make a difference. But like I said, not completely—crosstalk still exists and affects communications, especially in high-speed networks.
Nearing or near-end crosstalk This is a specific type of crosstalk measurement that has to do with the EMI bled from a wire to adjoining wires where the current originates. This particular point has the strongest potential to create crosstalk because the crosstalk signal itself degrades as it moves down the wire; if you have an issue with it, it’s probably going to show up in the first part of wire where it’s connected to a switch or a NIC.
Attenuation/DB loss As a signal moves through any medium, the medium itself will degrade the signal—a phenomenon known as attenuation that’s common in all kinds of networks. True, signals traversing fiber-optic cable don’t attenuate as fast as those on copper cable, but they still do eventually. You know that all copper twisted-pair cables have a maximum segment distance of 100 meters before they’ll need to be amplified or repeated by a hub or a switch, but single-mode fiber-optic cables can sometimes carry signals for miles before they begin to attenuate (degrade). If you need to go big, use fiber, not copper.
Collisions A network collision happens when two devices try to communicate on the same physical segment at the same time. Collisions like this were a big problem in the early Ethernet networks, and a tool known as Carrier Sense Multiple Access with Collision Detection (CSMA/CD) was used to detect and respond to them in Ethernet_II. Nowadays, we use switches in place of hubs because they can separate the network into multiple collision domains, learn the Media Access Control (MAC) addresses of the devices attached to them, create a type of permanent virtual circuit between all network devices, and prevent collisions.
Shorts Basically, a short circuit, or short, happens when the current flows through a different path within a circuit than it’s supposed to; in networks, they’re usually caused by some type of physical fault in the cable. You can find shorts with circuit-testing equipment, but because sooner is better when it comes to getting a network back up and running, replacing the ailing cable until it can be fixed (if it can be) is your best option.
Open impedance mismatch (echo) Open impedance on cable-testing equipment tells you that the cable or wires connect into another cable and there is an impedance mismatch. When that happens, some of the signal will bounce back in the direction it came from, degrading the strength of the signal, which ultimately causes the link to fail.
Interference/cable placement EMI and radio frequency interference (RFI) occur when signals interfere with the normal operation of electronic circuits. Computers happen to be really sensitive to sources of this, such as TV and radio transmitters, which create a specific radio frequency as part of their transmission process. Two other common culprits are two-way radios and cellular phones.
Your only way around this is to use shielded network cables like shielded twisted-pair (STP) and coaxial cable (rare today) or to run EMI/RFI-immune but pricey fiber-optic cable throughout your entire network.
Split pairs A split pair is a wiring error where two connections that are supposed to be connected using the two wires of a twisted pair are instead connected using two wires from different pairs. Such wiring causes errors in high-rate data lines. If you buy your cables precut, you won’t have this problem.
Unbounded Media Issues (Wireless)
Now let’s say your problem-ridden user is telling you they only use a wireless connection. Well, you can definitely take crosstalk and shorts off the list of suspects, but don’t get excited because with wireless, you’ve got a whole new bunch of possible Physical layer problems to sort through.
Wireless networks are really convenient for the user but not so much for administrators. They can require a lot more configuration, and understand that with wireless networks, you don’t just get to substitute one set of challenges for another—you pretty much add all those fresh new issues on top of the wired challenges you already have on your plate.
The following list includes some of those new wireless challenges:
Interference Because wireless networks rely on radio waves to transmit signals, they’re more subject to interference, even from other wireless devices like Bluetooth keyboards, mice, or cell phones that are all close in frequency ranges. Any of these—even microwave ovens!—can cause signal bleed that can slow down or prevent wireless communications. Factors like the distance between a client and a wireless access point (WAP) and the stuff between the two can also affect signal strength and even intensify the interference from other signals. So, careful placement of that WAP is a must.
Configurations Mistakes in the configuration of the wireless access point or wireless router or inconsistencies between the settlings on the AP and the stations can also be the source of problems. This section describes some of the main sources of configuration problems.
Incorrect encryption You know that wireless networks can use encryption to secure their communications and that different encryption flavors are used for wireless networks, like Wired Equivalent Privacy (WEP) and Wi-Fi Protected Access 2 (WPA2) with Advanced Encryption Standard (AES). To ensure the tightest security, configure your wireless networks with the highest encryption protocol that both the WAP and the clients can support. Oh, and make sure the AP and its clients are configured with same type of encryption. This is why it’s a good idea to disable security before troubleshooting client problems, because if the client can connect once you’ve done that, you know you’re dealing with a security configuration error.
Incorrect channel Wireless networks use many different frequencies within the 2.4GHz or 5Ghz band, and I’ll bet you didn’t know that these frequencies are sometimes combined to provide greater bandwidth for the user. You actually do know about this—has anyone heard of something called a channel? Well, that’s exactly what a channel is, and it’s also the reason some radio stations come in better than others—they have more bandwidth because their channel has more combined frequencies. You also know what happens when the AP and the client aren’t quite matching up. Have you ever hit the scan button on your car’s radio and only kind of gotten a station’s static-ridden broadcast? That’s because the AP (radio station) and the client (your car’s radio) aren’t quite on the same channel. Most of the time, wireless networks use channel 1, 6, or 11, and because clients auto-configure themselves to any channel the AP is broadcasting on, it’s not usually a configuration issue unless someone has forced a client onto an incorrect channel.
Incorrect frequency Okay—so setting the channel sets the frequency or frequencies that wireless devices will use. But some devices, such as an AP running 802.11g and a, allow you to tweak those settings and choose a specific frequency such as 2.4Ghz or 5Ghz. As with any relationship, it works best if things are mutual. So if you do this on one device, you’ve got to configure the same setting on all the devices with which you want to communicate, or they won’t—they’ll argue, and you don’t want that. Incorrect-channel and frequency-setting problems on a client are rare, but if you have multiple APs and they’re in close proximity, you need to make sure they’re on different channels/frequencies to avoid potential interference problems.
ESSID mismatch When a wireless device comes up, it scans for Service Set Identifiers (SSIDs) in its immediate area. These can be Basic Service Set Identifiers (BSSIDs) that identify an individual access point or Extended Service Set Identifiers (ESSIDs) that identify a set of APs. In your own wireless LAN, you clearly want the devices to find the ESSID that you’re broadcasting, which isn’t usually a problem: Your broadcast is closer than the neighbor’s, so it should be stronger—unless you’re in an office building or apartment complex that has lots of different APs assigned to lots of different ESSIDs because they belong to lots of different tenants in the building. This can definitely give you some grief because it’s possible that your neighbor’s ESSID broadcast is stronger than yours, depending on where the clients are in the building. So if a user reports that they’re connected to an AP but still can’t access the resources they need or authenticate to the network, you should verify that they are, in fact, connected to your ESSID and not your neighbor’s. This is very typical in an open security wireless network. You can generally just look at the information tool tip on the wireless software icon to find this out. However, you can easily solve this problem today by making the office SSID the preferred network in the client software.
Standard mismatch As you found out in Chapter 12, “Wireless Technologies,” wireless networks have many standards that have evolved over time, like 802.11a, 802.11b, 802.11g, and 802.11n. Standards continue to develop that make wireless networks even faster and more powerful. The catch is that some of these standards are backward compatible and others aren’t. For instance, most devices you buy today can be set to 802.11a/b/g, which means they can be used to communicate with other devices of all three standards. So, make sure the standards on the AP match the standards on the client, or that they’re at least backward compatible. It’s either that or tell all your users to buy new cards for their machines.
Distance/signal strength Location, location, location. You’ve got only two worries with this one: Your clients are either not far enough away or they’re too far from the AP. If your AP doesn’t seem to have enough power to provide a connectivity point for your clients, you can move it closer to them, increase the distance that the AP can transmit by changing the type of antenna it uses, or use multiple APs connected to the same switch or set of switches to solve the problem. If the signal is too strong, and it reaches out into the parking area or further out to other buildings and businesses, place the AP as close as possible to the center of the area it’s providing service for. And don’t forget to verify that you’ve got the latest security features in place to keep bad guys from authenticating to and using your network.
Latency When wireless users complain that the network is slow (latency) or that they are losing their connection to applications during a session, it is usually a capacity or distance issue. Remember, 802.11 is a shared medium, and as more users connect, all user throughput goes down. If this becomes a constant problem as opposed to the occasional issue where 20 guys with laptops gather for an every six-month meeting in the conference room, it may be time to consider placing a second AP in the area. When you do this, place the second AP on a different non-overlapping channel from the first and make sure the second AP uses the same SSID as the first. In the 2.4 Ghz frequency (802.11b and 802.11g), the three non-overlapping channels are 1,6, and 11. Now the traffic can be divided between them and users will get better performance. It is also worth noting that when clients move away from the AP, the data rate drops until at some point it is insufficient to maintain the connection.
Bounce For a wireless network spanning large geographical distances, you can install repeaters and reflectors to bounce a signal and boost it to cover about a mile. This can be a good thing, but if you don’t tightly control signal bounce, you could end up with a much bigger network than you wanted. To determine exactly how far and wide the signal will bounce, make sure you conduct a thorough wireless site survey. However, bounce can also refer to multipath issues, where the signal reflects off objectives and arrives at the client degraded because it is arriving out of phase. The solution is pretty simple. APs use two antennas that both sample the signal and use the strongest signal and ignore the out-of-phase signal. However, 802.11n takes advantage of multipath and can combine the out-of-phase signals to increase the distance hosts can be from the AP.
Incorrect antenna/switch placement Most of the time, the best place to put an AP and/or its antenna is as close to the center of your wireless network as possible. But you can position some antennas a distance from the AP and connect to it with a cable—a method used for a lot of the outdoor installations around today. If you want to use multiple APs, you’ve also got to be a little more sophisticated about deciding where to put them all; you can use third-party tools like the packet sniffers Wireshark and AirMagnet on a laptop to survey the site and establish how far your APs are actually transmitting. You can also hire a consultant to do this for you—there are many companies that specialize in assisting organizations with their wireless networks and the placement of antennas and APs. This is important because poor placement can lead to interference and poor performance, or even no performance at all.
Now that you know all about the possible physical network horrors that can befall you on a typical network, it’s a good time for you to memorize the troubleshooting steps that you’ve got to know to ace the CompTIA Network+ exam.
In the Network+ troubleshooting model, there are seven steps you’ve got to have dialed in:
1. Identify the problem.
2. Establish a theory of probable cause.
3. Test the theory to determine cause.
4. Establish a plan of action to resolve the problem and identify potential effects.
5. Implement the solution or escalate as necessary.
6. Verify full system functionality, and if applicable, implement preventative measures.
7. Document findings, actions, and outcomes.
To get things off to a running start, let’s assume that the user has called you yet again, but now they’re almost in tears because they can’t connect to the server on the intranet and they also can’t get to the Internet. (By the way, this happens a lot, so pay attention—it’s only a matter of time before it happens to you!)
Absolutely, positively make sure you memorize this seven-step troubleshooting process in the right order when studying for the Network+ exam!
Step 1: Identify the Problem
Before you can solve the problem, you’ve got to figure out what it is, right? Again, asking the right questions can get you far along this path and really help clarify the situation. Identifying the problem involves steps that together constitute information gathering.
Question Users
A good way to start is by asking the user the following questions:
- Exactly which part of the Internet can’t you access? A particular website? A certain address? A type of website? None of it at all?
- Can you use your web browser?
- If the hitch has to do with an internal server to the company, ask the user if they can ping the server and talk the them through doing that.
- Ask the user to try to telnet or FTP to an internal server to verify local network connectivity; if they don’t know how, talk them through it.
Here’s another really common trouble ticket that just happens to build on the last scenario: Now let’s say you’ve got a user who’s called you at the help desk. By asking the previous questions, you found out that this user can’t access the corporate intranet or get out to any sites on the Internet. You also established that the user can use their web browser to access the corporate FTP site, but only by IP address, not by the FTP server name. This information tells you two important things: that you can rule out the host and the web browser (application) as the source of the problem and that the physical network is working.
Determine If Anything Has Changed
Moving right along, if you can reproduce the problem, your next step is to verify what has changed and how. Drawing on your knowledge of networking, you ask yourself and your user questions like these:
Were you ever able to do this? If not, then maybe it just isn’t something the hardware or software is designed to do. You should then tell the user exactly that, as well as advise them that they may need additional hardware or software to pull off what they’re trying do.
If so, when did you become unable to do it? If, once upon a time, the computer was able to do the job and then suddenly could not, whatever conditions surrounded and were involved in this turn of events become extremely important. You have a really good shot at unearthing the root of the problem if you know what happened right before things changed. Just know that there’s a high level of probability that the cause of the problem is directly related to the conditions surrounding the change when it occurred.
Has anything changed since the last time you could do this? This question can lead you right to the problem’s cause. Seriously—the thing that changed right before the problem began happening is almost always what caused it. It’s so important that if you ask it, and your user tells you, “Nothing changed…it just happened,” you should rephrase the question and say something like, “Did anyone add anything to your computer?” or “Are you doing anything differently from the way you usually do it?”
Were any error messages displayed? These are basically arrows that point directly at the problem’s origin; error messages are designed by programmers for the purpose of pointing them to exactly what it is that isn’t working properly in computer systems. Sometimes error messages are crystal clear, like Disk Full, or they can be cryptically annoying little puzzles in and of themselves. If you pulled the short straw and got the latter variety, it’s probably best to hit the software or hardware vendor’s support site, where you can usually score a translation from the “programmerese” in which the error message is written into plain English so you can get back to solving your riddle.
Are other people experiencing this problem? You’ve got to ask this one because the answer will definitely help you target the cause of the problem. First, try to duplicate the problem from your own workstation because if you can’t, it’s likely that the issue is related to only one user or group of users—possibly their workstations. (A solid hint that this is the case is if you’re being inundated with calls from a bunch of people from the same workgroup.)
Is the problem always the same? It’s good to know that when problems crop up, they’re almost always the same each time they occur. But their symptoms can change slightly as the conditions surrounding them change. A related question would be, “If you do x, does the problem get better or worse?” For example, ask a user, “If you use a different file, does the problem get better or worse?” If the symptoms lighten up, it’s an indication that the problem is related to the original file that’s being used.
Understand that these are just a few of the questions you can use to get to the source of a problem.
Okay, so let’s get back to our sample scenario. So far, you’ve determined that the problem is unique to one user, which tells you that the problem is specific to this one host. Confirming that is the fact that you haven’t received any other calls from other users on the network.
And when watching the user attempt to reproduce the problem, you note that they’re typing the address correctly. Plus, you’ve got an error message that leads you to believe that the problem has something to with Domain Name Service (DNS) lookups on his host. Time to go deeper…
Identify Symptoms
I probably don’t need to tell you that computers and networks can be really fickle—they can hum along fine for months, suddenly crash, and then continue to work fine again without ever seizing in that way again. That’s why it’s so important to be able to reproduce the problem and identify the affected area to narrow things down so you can cut to the chase and fix the issue fast. This really helps—when something isn’t working, try it again, and write down exactly what is and is not happening.
Most users’ knee-jerk reaction is to straight up call the help desk the minute they have a problem. This is not only annoying but also inefficient, because you’re going to ask them exactly what they were doing when the problem occurred and most users have no idea what they were doing with the computer at the time because they were focused on doing their jobs instead. This is why if you train users to reproduce the problem and jot down some notes about it before calling you, they’ll be much better prepared to give you the information you need to start troubleshooting it and help them.
So with that, here we go. The problem you’ve identified results in coughing out an error message to your user when they try to access the corporate intranet. It looks like this.
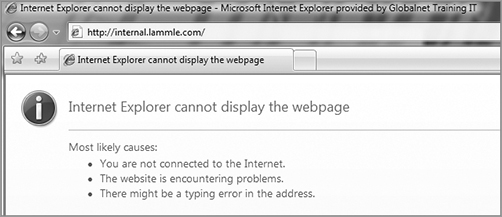
And when this user tries to ping the server using the server’s hierarchical web name, it fails too.

You’re going to respond by checking to see whether the server is up by pinging the server by its IP address.
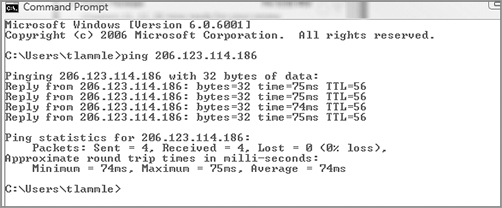
Nice—that worked, so the server is up, but you could still have a server problem. Just because you can ping a host, it doesn’t mean that host is 100 percent up and running, but in this case, it’s a good start.
And you’re in luck because you’ve been able to re-create this problem from this user’s host machine. By doing that, you now know that the URL name is not being resolved from Internet Explorer, and you can’t ping it by the name either. But you can ping the server IP address from your limping host, and when you try this same connection to the internal.lammle.com server from another host nearby, it works fine, meaning the server is working fine. So, you’ve succeeded in isolating the problem to this specific host—yes!
It is a huge advantage if you can watch the user try to reproduce the problem themselves because then you know for sure whether the user is performing the operation correctly. It’s a really bad idea to assume the user is typing in what they say they are.
Great—now you’ve nailed down the problem. This leads us to step 2.
Step 2: Establish a Theory of Probable Cause
After you observe the problem and identify the symptoms, next on the list is to establish its most probable cause. (If you’re stressing about now, don’t, because though you may feel overwhelmed by all this, it truly does get a lot easier with time and experience.)
You must come up with at least one possible cause, even though it may not be completely on the money. And you don’t always have to come up with it yourself. Someone else in the group may have the answer. Also, don’t forget to check online sources and vendor documentation.
Again, let’s get back to our scenario, in which you’ve determined the cause is probably an improperly configured DNS lookup on the workstation. The next thing to do is to verify the configuration and probably reconfigure DNS on the workstation; we’ll get to this solution later, in step 4.
Understand that there are legions of problems that can occur on a network—and I’m sorry to tell you this, but they’re typically not as simple as the example we’ve been using. They can be, but I just don’t want you to expect them to be. Always consider the physical aspects of a network, but look beyond them into the realm of logical factors like the DNS lookup issue we’ve been using.
Question the Obvious
The probable causes that you’ve got to thoroughly understand to meet the Network+ objectives are as follows:
- Port speed
- Port duplex mismatch
- Mismatched MTU
- Incorrect virtual local area network (VLAN)
- Incorrect IP address
- Wrong gateway
- Wrong DNS
- Wrong subnet mask
Let’s talk about these logical issues, which can cause an abundance of network problems. Most of these happen because a device has been improperly configured:
Port speed Because networks have been evolving for many years, there are various levels of speed and sophistication mixed into them—often within the same network. Most of the newest NICs can be used at 10Mbps, 100Mbps, and 1000Mbps. Most switches can support at least 10Mbps and 100Mbps, and an increasing number of switches can also support 1,000Mbps. Plus, many switches can also autosense the speed of the NIC that’s connected and use different speeds on various ports. As long as the switches are allowed to autosense the port speed, it’s rare to have a problem develop that results in a complete lack of communication. But if you decide to set the port speed manually, make positively sure to set the same speed on both sides of a link.
Port duplex mismatch There are generally three duplex settings on each port of a network switch: full, half, and auto. In order for two devices to connect effectively, the duplex setting has to match on both sides of the connection. If one side of a connection is set to full and the other is set to half, they’re mismatched. More elusively, if both sides are set to auto but the devices are different, you can also end up with a mismatch because the device on one side defaults to full and the other one defaults to half.
Duplex mismatches can cause lots of network errors and even the lack of a network connection. This is partially because setting the interfaces to full duplex disables the CSMA/CD protocol. This is definitely not a problem in a network that has no hubs (and therefore no shared segments in which there could be collisions), but it can make things really ugly in a network where hubs are still being used. This means the settings you choose are based on the type of devices you have populating your network. If you have all switches and no hubs, feel free to set all interfaces to full duplex, but if you’ve got hubs in the mix, you have shared networks, so you’re forced to keep the settings at half duplex. With all new switches produced today, leaving the speed and duplex setting to auto (the default on both switches and hosts) is the recommended way to go.
Mismatched MTU Ethernet LANs enforce what is called a maximum transmission unit (MTU). This is the largest size packet that is allowed across a segment. In most cases this is 1,500 bytes. Left alone this is usually not a problem, but it is possible to set the MTU on a router interface, which means it is possible for a mismatch to be present between two router interfaces. This can cause problems with communications between the routers, resulting in the link failing to pass traffic. To check the MTU on an interface, execute the command show interface.
Incorrect VLAN Switches can have multiple VLANs each, and they can be connected to other switches using trunk links. As you now know, VLANs are often used to represent departments or the occupations of a group of users. This makes the configurations of security policies and network access lists much easier to manage and control. On the other hand, if a port is accidentally assigned to the wrong VLAN in a switch, it’s as if that client was magically transported to another place in the network. If that happens, the security policies that should apply to the client won’t anymore, and other policies will be applied to the client that never should have been. The correct VLAN port assignment of a client is as important as air; when I’m troubleshooting a single-host problem, this is the first place I look.
It’s pretty easy to tell if you have a port configured with a wrong VLAN assignment. If this is the case, it won’t be long before you’ll get a call from some user screaming something at you that makes the building shake, like, “I can get to the Internet but I can’t get to the Sales server, and I’m about to lose a huge sale. DO SOMETHING!” When you check the switch, you will invariably see that this user’s port has a membership in another VLAN like Marketing, which has no access to the Sales server.
Incorrect IP address The most common addressing protocol in use today is IPv4, which provides a unique IP address for each host on a network. Client computers usually get their addresses from Dynamic Host Configuration Protocol (DHCP) servers. But sometimes, especially in smaller networks, IP addresses for servers and router interfaces are statically assigned by the network’s administrator. An incorrect address on a client will keep that client from being able to communicate and may even cause a conflict with another client on the network, and a bad address on a server or router interface can be disastrous and affect a multitude of users. This is exactly why you need to be super careful to set up DHCP servers correctly and also when configuring the static IP addresses assigned to servers and router interfaces.
Wrong gateway A gateway, sometimes called a default gateway or an IP default gateway, is a router interface’s address that’s configured to forward traffic with a destination IP address that’s not in the same subnet as the device itself. Let me clarify that one for you: If a device compares where a packet wants to go with the network it’s currently on and finds that the packet needs to go to a remote network, the device will send that packet to the gateway to be forwarded to the remote network. Because every device needs a valid gateway to obtain communication outside of its own network, it’s going to require some careful planning when considering the gateway configuration of devices in your network.
If you’re configuring a static IP address and default gateway, you need to verify the router’s address. Not doing so is a really common “wrong gateway” problem that I see all the time.
Wrong DNS DNS servers are used by networks and their clients to resolve a computer’s hostname to its IP addresses and to enable clients to find the server they need to provide the resources they require, like a domain controller during the login and authentication process. Most of the time, DNS addresses are automatically configured by a DHCP server, but sometimes these addresses are statically configured instead. Because lots of applications rely on hostname resolution, a botched DNS configuration usually causes a computer’s network applications to fail just like the user’s applications in our example scenario.
If you can ping a host using its IP address but not its name, you probably have some type of name-resolution issue. It’s probably lurking somewhere within a DNS configuration.
Wrong subnet mask When network devices look at an IP address configuration, they see a combination of the IP address and the subnet mask. The device uses the subnet mask to establish which part of the address represents the network address and which part represents the host address. So clearly, a subnet mask that is configured wrong has the same nasty effect as a wrong IP address configuration does on communications. Again, a subnet mask is generally configured by the DHCP server; if you’re going to enter it manually, make sure the subnet mask is tight or you’ll end up tangling with the fallout caused by the entire address’s misconfiguration.
With all that in mind, let’s move on with our troubleshooting steps.
Step 3: Test the Theory to Determine Cause
Let’s look into the matter by first checking the IP configuration of the host that just happens to include DNS information. You use the ipconfig /all command to show the IP configuration. The /all switch will give you the DNS information you need.
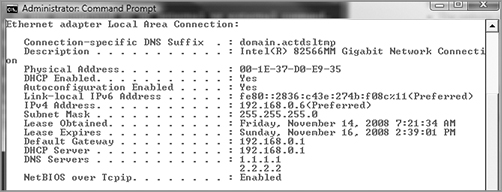
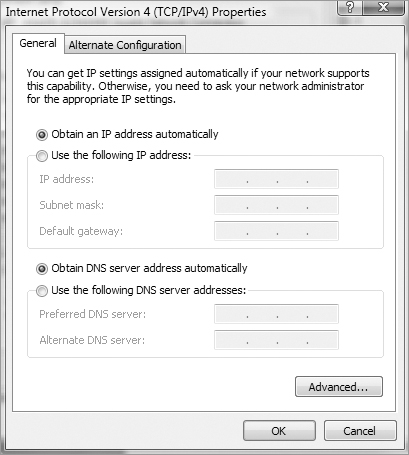
Check out the DNS entries: 1.1.1.1 and 2.2.2.2. Is this right? What are they supposed to be? You can find this out by checking the addresses on a working host, but let’s check the settings on your troubled host’s adapter first. Click Start, then Control Panel, then Network And Sharing Center, and then Manage Network Connections on the left side of the screen, which will take you to this screen.

Now, click the interface in question, and click Properties. You receive this screen.

From here, you highlight Internet Protocol Version 4, and click Properties (or just double-click). From the next screen, do you see what may be causing the problem?
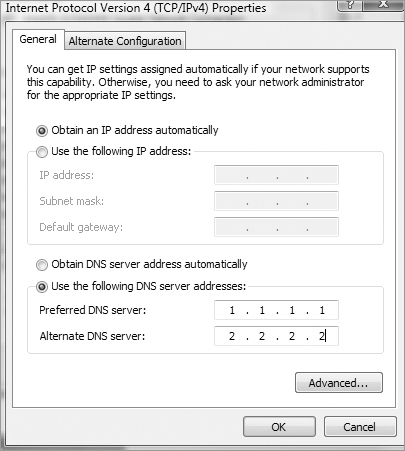
As I said, you’re using DHCP right? But DNS is statically configured on this host. Interesting enough, when you set a static DNS entry on an interface, it will override the DHCP-provided DNS entry.
Step 4: Establish a Plan of Action to Resolve the Problem and Identify Potential Effects
Now that you’ve identified some possible changes, you’ve got to follow through and test your solution to see if you really solved the problem. In this case, you ask the user to try to access the intranet server (because that’s what they called about). Basically, you just ask the user to try doing whatever it was they couldn’t do when they called you in the first place. If it works—sweet—problem solved. If not, try the operation yourself.
Now you can test the proposed solution on the computer of the user who is still waiting for a solution. To do that, you need to check the DNS configuration on your host. But first, let me point out something about the neglected user’s network. All hosts are using DHCP, so it’s really weird that a single user is having a DNS resolution issue.
So, to fix the problem and get your user back in the game, just click Obtain DNS Server Address Automatically, and then click OK. Voilà!
Let’s take a look at the output of ipconfig /all and see if you received new DNS server addresses.

All good; you did. And you can test the host by trying to use HTTP to connect to a web page on the intranet server and even pinging by hostname. Congratulations on solving your first trouble ticket!
If things hadn’t worked out so well, you would go back to step 2, select a new possible cause, and redo step 3. If this happens, keep track of what worked and what didn’t so you don’t make the same mistakes twice.
It’s pretty much common sense that you should change settings like this only when you fully understand the effect your changes will have, or when you’re asked to by someone who does. The incorrect configuration of these settings will disable the normal operation of your workstation, and, well, it seems that someone (the user, maybe?) did something they shouldn’t have or you wouldn’t have had the pleasure of solving this problem.
You have to be super careful when changing settings and always check out a troubled host’s network settings. Don’t just assume that because they’re using DHCP, someone has screwed up the static configuration.
Step 5: Implement the Solution or Escalate as Necessary
Although it’s true that CompTIA doesn’t expect you to fix every single network problem that could possibly happen in the universe, they actually do expect you to get pretty close to determining exactly what the problem is. And if you can’t fix it, you’ll be expected to know how to escalate it and to whom. You are only as good as your resources—be they your own skill set, a book like this one, other more reference-oriented technical books, the Internet, or even a guru at a call center.
I know it seems like I talked to death physical and logical issues that cause problems in a network, but trust me, with what I’ve taught you, you’re just getting started. There’s a galaxy of networking evils that we have not even touched on because they’re far beyond the objectives for Network+ certification and, therefore, the scope of this book. But out there in the real world, you’ll get calls about them anyway, and because you’re not yet equipped to handle them yourself, you need to escalate these nasties to a senior network engineer who has the additional experience and knowledge required to resolve the problems.
Some of the calamities that you should escalate are as follows:
- Switching loops
- Missing routes
- Routing loops
- Routing problems
- MTU black hole
- Bad modules
- Proxy Address Resolution Protocol (ARP)
- Broadcast storms
After you escalated the problem, you are done with the seven-step troubleshooting model and you now need to meet with the emergency response team to determine the next step.
And just as with other problems, you have to be able to identify these events because if you can’t do that, how else will you know that you need to escalate them?
Switching loops Today’s networks often connect switches with redundant links to provide for fault tolerance and load balancing. Protocols such as Spanning Tree Protocol (STP) prevent switching loops and simultaneously maintain fault tolerance. If STP fails, it takes some expertise to reconfigure and repair the network, so you just need to be concerned with being able to identify the problem so you can escalate it. Remember, when you hear users complaining that the network works fine for a while, then unexpectedly goes down for about a minute, and then goes back to being fine, it’s definitely an STP convergence issue that’s pretty tough to find and fix. Escalate this problem ASAP!
Missing routes Routers must have routes either configured or learned to function. There are a number of issues that can prevent a router from learning the routes that it needs. To determine if a router has the route to the network in question, execute the show ip route command and view the routing table. This can save a lot of additional troubleshooting if you can narrow the problem to a missing route.
Routing loops Routing protocols are often used on networks to control traffic efficiently while preventing routing loops that happen when a routing protocol hasn’t been configured properly or network changes didn’t get the attention they deserved. Routing loops can also happen if you or the network admin blew the static configuration and created conflicting routes through the network. This evil event affects the traffic flow for all users, and because it’s pretty complicated to fix, again, it’s up, up, and away with this one. You can expect routing loops to occur if your network is running old routing protocols like Routing Information Protocol (RIP) and RIPv2. Just upgrading your routing protocol to Enhanced Interior Gateway Routing Protocol (EIGRP), Open Shortest Path First (OSPF), or Intermediate System-to-Intermediate System (IS-IS) will usually take care of the problem once and for all. Anyway, escalate this problem to the router group—which hopefully is soon to be you.
Routing problems Routing packets through the many subnets of a large enterprise while still maintaining security can be a tremendous challenge. A router’s configuration can include all kinds of stuff like access lists, Network Address Translation (NAT), Port Address Translation (PAT), and even authentication protocols like Remote Authentication Dial In User Service (RADIUS) and Terminal Access Controller Access-Control System (TACACS). Particularly diabolical, errant configuration changes can trigger a domino effect that can derail traffic down the wrong path or even cause it to come to a grinding halt and stop traversing the network completely. To identify routing problems, check to see if someone has simply set a wrong default route on a router. This can easily create routing loops. I see it all the time. These configurations can be highly complex and specific to a particular device, so they need to be escalated to the top dogs—get the problem to the best sys admin in the router group.
MTU black hole On a WAN connection, communication routes may fail if an intermediate network segment has an MTU that is smaller than the maximum packet size of the communicating hosts—and if the router does not send an appropriate Internet Control Message Protocol (ICMP) response to this condition. If ICMP traffic is allowed, the routers will take care of this problem using ICMP messages. However, as ICMP traffic is increasingly being blocked, this can create what is called a black hole. This will probably be an issue you will escalate.
Bad modules Some multilayer switches and routers have slots available to add new features. The hardware that fits in these slots is called modules. These modules can host fiber connections, wireless connections, and other types as well. A common example is the Cisco Small Form-Factor Pluggable (SFP) Gigabit Interface Ethernet Converter (GBIC). This is an input-output device that plugs into an existing Gigabit Ethernet port or slot providing a variety of additional capabilities to the device hosting the slot or port. Conversion examples include from Ethernet to fiber. Like any piece of hardware made by humans, the modules can fail. It is always worth checking if there are no other reasons a link is not functioning.
Proxy ARP Address Resolution Protocol (ARP) is a service that resolves IP addresses to MAC addresses. Proxy ARP is just wrong to use in today’s networks, but hosts and routers still have it on by default. The idea of Proxy ARP was to solve the problem of a host being able to have only one configured default gateway. To allow redundancy, Proxy ARP running on a router will respond to an ARP broadcast from a host that’s sending a packet to a remote network—but the host doesn’t have a default gateway set. So the router responds by being the proxy for the remote host, which in turn makes the local host think the remote host is really local; as a result, the local host sends the packets to the router, which then forwards the packets to the remote host. Most of the time, in today’s networks, this does not work well, if at all. Disable Proxy ARP on your routers, and make sure you have default gateways set on all your hosts. If you need router redundancy, there are much better solutions available than Proxy ARP! This is another job for the routing group.
Broadcast storms When a switch receives a broadcast, it will normally flood the broadcast out all the ports except for the one the broadcast came in on. If STP fails between switches or is disabled by an administrator, it’s possible that the traffic could continue to be flooded repeatedly throughout the switch topology. When this happens, the network can get so busy that normal traffic can’t traverse it—an event referred to as a broadcast storm. As you can imagine, this is a particularly gruesome thing to have to troubleshoot and fix because you need to find the one bad link that is causing the mess while the network is probably still up and running—but at a heavily congested crawl. Escalate ASAP to experts!
Step 6: Verify Full System Functionality and If Applicable Implement Preventative Measures
A trap that any network technician can fall into is solving one problem and thinking it’s all fixed without stopping to consider the possible consequences of their solution. The cure can be worse than the disease, and it’s possible that your solution falls into this category. So before you fully implement the solution to a problem, make sure you totally understand the ramifications of doing so—clearly, if it causes more problems than it fixes, you should toss it and find a different solution that does no harm.
Many people update a router’s operating system or firmware just because a new version of code is released from the manufacturer. Do not do this on your production routers—just say no! Always test any new code before upgrading your production routers: Like a bad solution, sometimes the new code provides new features but creates more problems, and the cons outweigh the pros.
Step 7: Document Findings, Actions, and Outcomes
I can’t stress enough how vital network documentation is. Always document problems and solutions so that you have the information at hand when a similar problem arises in the future. With documented solutions to documented problems, you can assemble your own database of information that you can use to troubleshoot other problems. Be sure to include information like the following:
- A description of the conditions surrounding the problem
- The OS version, the software version, the type of computer, and the type of NIC
- Whether you were able to reproduce the problem
- The solutions you tried
- The ultimate solution
Network Documentation
I don’t know how many times I’ve gone into a place and asked where their documentation was only to be met with a blank stare. I was recently at a small business that was experiencing network problems. The first question I asked was, “Do you have any kind of network documentation?” I got the blank stare. So, we proceeded to search through lots of receipts and other paperwork—anything we could find to help us understand the network layout and figure out exactly what was on the network. It turned out they had recently bought a WAP, and it was having trouble connecting—something that would’ve taken me five minutes to fix instead of searching through a mess for a couple hours!
Documentation doesn’t have to look like a sleek owner’s manual or anything—it can consist of a simple three-ring binder with an up-to-date network map; receipts for network equipment; a pocket for owner’s manuals; and a stack of loose-leaf paper to record services, changes, network-addressing assignments, access lists, and so on. Just this little bit of documentation can save lots of time and money and prevent grief, especially in the critical first few months of a new network install.
Now that you’ve got the basics of network troubleshooting down pat, I’m going to go over a few really handy troubleshooting tips for you to arm yourself with even further in the quest to conquer the world’s networking evils.
Don’t Overlook the Small Stuff
The super simple stuff (SSS) I referred to at the beginning of this chapter should never be overlooked—ever! Here’s a quick review: Just remember that problems are often caused by little things like a bad power switch; a power switch in the wrong position; a card or port that’s not working, indicated by a link light that’s not lit; or simply operator error (OE). Even the most experienced system administrator has forgotten to turn on the power, left a cable unplugged, or mistyped a username and password—not me, of course, but others…
And make sure that users get solid training for the systems they use. An ounce of prevention is worth a pound of cure, and you’ll experience dramatically fewer ID10T errors this way.
Prioritize Your Problems
Being a network administrator or technician of even a fairly small network can keep you hopping, and it’s pretty rare that you’ll get calls for help one at a time and never be interrupted by more coming in. Closer to reality is receiving yet another call when you already have three people waiting for service. So, you’ve got to prioritize.
You start this process by again asking some basic questions to determine the severity of the problem being reported. Clearly, if the new call is about something little and you already have a huge issue to deal with, you should put the new call on hold or get their info and get back to them later. If you establish a good set of priorities, you’ll make much better use of your time. Here’s an example of the rank you probably want to give to networking problems, from highest priority to lowest:
- Total network failure (affects everyone)
- Partial network failure (affects small groups of users)
- Small network failure (affects a small, single group of users)
- Total workstation failure (single user can’t work at all)
- Partial workstation failure (single user can’t do most tasks)
- Minor issue (single user has problems that crop up now and then)
Mitigating circumstances can, of course, change the order of this list. For example, if the president of the company can’t retrieve email, you’d take the express elevator to their office as soon as you got the call, right? And even a minor issue can move up the ladder if it’s persistent enough.
Don’t fall prey to thinking that simple problems are easier to deal with because even though you may be able to bring up a crashed server in minutes, a user who doesn’t know how to make columns line up in Microsoft Word could take a chunk out of your day. You’d want to put the latter problem toward the bottom of the list because of the time involved—it’s a lot more efficient to solve problems for a big group of people than to fix this one user’s problem immediately.
Some network administrators list all network-service requests on a chalkboard or a whiteboard. They then prioritize them based on the previously discussed criteria. Some larger companies have written support-call tracking software whose only function is to track and prioritize all network and computer problems. Use whatever method makes you comfortable, but prioritize your calls.
Check the Software Configuration
Often, network problems can be traced to software configuration, like our DNS configuration scenario; so when you’re checking for software problems, don’t forget to check types of configurations:
- DNS configuration
- WINS configuration
- HOSTS file
- The Registry
Software-configuration settings love to hide in places like these and can be notoriously hard to find (especially in the Registry).
Also, look for lines that have been commented out either intentionally or accidentally in text-configuration files—another place for clues. A command such as REM or REMARK, or asterisk or semicolon characters, indicates comment lines in a file.
In the HOSTS file, a pound sign (#) is used to indicate a comment line.
Don’t Overlook Physical Conditions
You want to make sure that from a network-design standpoint, the physical environment for a server is optimized for placement, temperature, and humidity. When troubleshooting an obscure network problem, don’t forget to check the physical conditions under which the network device is operating. Check for problems like these:
- Excessive heat
- Excessive humidity (condensation)
- Low humidity (leads to electrostatic discharge [ESD] problems)
- EMI/RFI problems
- ESD problems
- Power problems
- Unplugged cables
Don’t Overlook Cable Problems
Cables, generally speaking, work fine once they are installed properly. If the patch cable isn’t the problem, use a cable tester (not a tone generator and locator) to find the source of the problem.
One of the easiest mistakes to make, especially if cables are not labeled, is to use a crossover cable where a straight through cable should be used or vice-versa. In either case, when you do this it causes TXRX reversal. What’s that? That when the Transmit wire is connected to Transmit and the Receive wire to Receive. That sounds good, but it needs to be Transmit to Receive. See more about this issue in Chapter 3, “Networking Topologies, Connectors, and Wiring Standards.”
Wires that are moved can be prone to breaking or shorting, and a short can happen when the wire conductor comes in contact with another conductive surface, changing the path of the electrical signal. The signal will go someplace else instead of to the intended recipient. You can use cable testers to test for many types of problems:
- Broken cables
- Incorrect connections
- Interference levels
- Total cable length (for length restrictions)
- Cable shorts
- Connector problems
As a matter of fact, cable testers are so sophisticated that they can even indicate the exact location of a cable break, accurate to within 6 inches or better.
Check for Viruses
People overlook scanning for viruses because they assume that the network’s virus-checking software has already picked them off. But to be effective, the software must be kept up-to-date, and updates are made available pretty much daily. You’ve got to run the virus-definition update utility to keep the virus-definition file current.
If you are having strange, unusual, irreproducible problems with a workstation, try scanning it with an up-to-date virus-scan utility. You’d be surprised how many times people have spent hours and hours troubleshooting a strange problem only to run a virus-scan utility, find and clean out one or more viruses, and have the problem disappear like magic.
In this chapter, you learned about all things troubleshooting, and you now know how to sleuth out and solve a lot of network problems. You learned to first check all the SSS and about how to approach problem resolution by eliminating what the problem is not. You learned how to narrow the problem down to its basics and define it.
Next, you learned a systematic approach using a seven-step troubleshooting model to troubleshoot most of the problems you’ll run into in networking. And you also learned about some resources you can use to help you during the troubleshooting process. In addition, you learned how important documentation is to the health of your network.
Finally, I gave you a bunch of cool tips to further equip you, tips about prioritizing issues, checking for configuration issues, environmental factors—even hunting down viruses. As you venture out into the real world, keep these tips in mind; along with your own personal experience, they’ll really help make you into an expert troubleshooter.
Know the seven troubleshooting steps, in order. The steps, in order, are as follows:
1. Identify the problem.
2. Establish a theory of probable cause.
3. Test the theory to determine cause.
4. Establish a plan of action to resolve the problem and identify potential effects.
5. Implement the solution or escalate as necessary.
6. Verify full system functionality, and if applicable, implement preventative measures.
7. Document findings, actions, and outcomes.
Be able to identify a link light. A link light is the small, usually green LED on the back of a network card. This LED is typically found next to the media connector on a NIC and is usually labeled Link.
Understand how proper network use procedures can affect operation of a network. If a user is not following a network use procedure properly (for example, not logging in correctly), that user may report a problem where none exists. A good network troubleshooter should know how to differentiate between a network hardware/software problem and a “lack of user training” problem.
Know how to narrow down a problem to one specific area or cause. Most problems can be traced to one specific area or cause. You must be able to determine if a problem is specific to one user or a bunch of users, specific to one computer or a bunch of computers, and related to hardware or software. The answers to these questions will give you a very specific problem focus.
Know how to detect cabling-related problems. Generally speaking, most cabling-related problems can be traced by plugging the suspect workstation into a known, working network port. If the problem disappears (or at the very least changes significantly), it is related to the cabling for that workstation.
In this section, write the answers to the following questions:
1. What is step 3 of the seven-step troubleshooting model?
2. What is step 7 of the seven-step troubleshooting model?
3. How is crosstalk minimized in twisted-pair cabling?
4. If you plug a host into a switch port and the user cannot get to the server or other services they need to access despite a working link light, what could the problem be?
5. What is it called when a cable has two wires of a twisted pair connected to two wires from a different pair?
6. When a signal moves through any medium, the medium itself will degrade the signal. What is this called?
7. What is step 4 of the seven-step troubleshooting model?
8. What is step 5 of the seven-step troubleshooting model?
9. What are some of the problems that, if determined, should be escalated?
10. What cable issues should you know and understand for network troubleshooting?
You can find the answers in Appendix B.
You can find the answers in Appendix A.
1. Which of the following are not steps in the Network+ troubleshooting model? (Choose all that apply.)
A. Reboot the servers.
B. Identify the problem.
C. Test the theory to determine the cause.
D. Implement the solution or escalate as necessary.
E. Document findings, actions, and outcomes.
F. Reboot all the routers.
2. You have a user who cannot connect to the network. What is the first thing you could check to determine the source of the problem?
A. Workstation configuration
B. Connectivity
C. Patch cable
D. Server configuration
3. When wireless users complain that they are losing their connection to applications during a session, what is the source if the problem?
A. Incorrect SSID
B. Latency
C. Incorrect encryption
D. MAC address filter
4. Several users can’t log in to the server. Which action would help you to narrow the problem down to the workstations, network, or server?
A. Run tracert from a workstation.
B. Check the server console for user connections.
C. Run netstat on all workstations.
D. Check the network diagnostics.
5. A user can’t log in to the network. She can’t even connect to the Internet over the LAN. Other users in the same area aren’t experiencing any problems. You attempt to log in as this user from your workstation with her username and password and don’t experience any problems. However, you cannot log in with either her username or yours from her workstation. What is a likely cause of the problem?
A. Insufficient rights to access the server
B. A bad patch cable
C. Server down
D. Wrong username and password
6. A user is experiencing problems logging in to a Unix server. He can connect to the Internet over the LAN. Other users in the same area aren’t experiencing any problems. You attempt logging in as this user from your workstation with his username and password and don’t experience any problems. However, you cannot log in with either his username or yours from his workstation. What is a likely cause of the problem?
A. The Caps Lock key is pressed.
B. The network hub is malfunctioning.
C. You have a downed server.
D. You have a jabbering NIC.
7. You receive a call from a user who is having issues connecting to a new VPN. Which is the first step you should take?
A. Find out what has changed.
B. Reboot the workstation.
C. Document the solution.
D. Identify the symptoms and potential causes.
8. A workstation presents an error message to a user. The message states that a duplicate IP address has been detected on the network. After establishing what has changed in the network, what should be the next step using the standard troubleshooting model?
A. Test the result.
B. Select the most probable cause.
C. Create an action plan.
D. Identify the results and effects of the solution.
9. You have gathered information on a network issue and determined the affected areas of the network. What is your next step in resolving this issue?
A. You should implement the best solution for the issue.
B. You should test the best solution for the issue.
C. You should check to see if there have been any recent changes to this affected part of the network.
D. You should consider any negative impact to the network that might be caused by a solution.
10. A user calls you, reporting a problem logging in to the corporate intranet. You can access the website without problems using the user’s username and password. At your request, the user has tried logging in from other workstations but has been unsuccessful. What is the most likely cause of the problem?
A. The user is logging in incorrectly.
B. The network is down.
C. The intranet server is locked up.
D. The server is not routing packets correctly to that user’s workstation.
11. You have just implemented a solution and you want to celebrate your success. But what should you do next before you start your celebration?
A. Gather more information about the issue.
B. Document the issue and the solution that was implemented.
C. Test the solution and identify other effects it may have.
D. Escalate the issue.
12. You can ping the local router and web server that a local user is trying to reach, but you cannot reach the web page that resides on that server. From step 2 of the troubleshooting model, what is a possible problem that would lead to this situation?
A. Your network cable is unplugged.
B. There is a problem with your browser.
C. Your NIC has failed.
D. The web server is unplugged.
13. When troubleshooting an obscure network problem, what physical conditions should be reviewed to make sure the network device is operating correctly?
A. Excessive heat
B. Low/excessive humidity
C. ESD problems
D. All of the above
14. Which of the following is not a basic physical issue that can occur on a network when a user is connected via cable?
A. Crosstalk
B. Shorts
C. Open impedance mismatch
D. DNS configurations
15. You are troubleshooting a LAN switch and have identified the symptoms. What is the next step you should take?
A. Escalate the issue.
B. Create an action plan.
C. Implement the solution.
D. Determine the scope of the problem.
16. A user calls you, complaining that he can’t access the corporate intranet web server. You try the same address, and you receive a Host Not Found error. Several minutes later, another user reports the same problem. You can still send email and transfer files to another server. What is the most likely cause of the problem?
A. The hub is unplugged.
B. The server is not routing protocols to your workstation.
C. The user’s workstation is not connected to the network.
D. The web server is down.
17. You have implemented and tested a solution and identified any other effects the solution may have. What is your next step?
A. Create an action plan.
B. Close the case and head home for the day.
C. Reboot the Windows server.
D. Document the solution.
18. Users are reporting that they can access the Internet but not the internal company website. Which of the following is the most likely problem?
A. The DNS entry for the server is non-authoritative.
B. The intranet server is down.
C. The DNS address handed out by DHCP is incorrect.
D. The default gateway is incorrect.
19. Several users have complained about the server’s poor performance as of late. You know that the memory installed in the server is sufficient. What could you check to determine the source of the problem?
A. Server’s NIC link light
B. Protocol analyzer
C. Performance-monitoring tools
D. Server’s system log file
20. You lose power to your computer room and the switches in your network do not come back up when everything is brought online. After you have identified the affected areas, established the cause, and escalated this problem, what do you do next?
A. Start to implement a solution to get those users back online ASAP.
B. Create an action plan and solution.
C. Meet with the emergency response team to determine the next step.
D. Copy all the working routers’ configurations to the nonworking switches.