

THIS CHAPTER IS WHERE IT ALL COMES TOGETHER. we’ll describe and implement a complete GNU/Linux program that incorporates many of the techniques described in this book. The program provides information about the system it’s running on via a Web interface.
The program is a complete demonstration of some of the methods we’ve described for GNU/Linux programming and illustrated in shorter programs. This program is written more like “real-world” code, unlike most of the code listings that we presented in previous chapters. It can serve as a jumping-off point for your own GNU/Linux programs.
The example program is part of a system for monitoring a running GNU/Linux system. It includes these features:
• The program incorporates a minimal Web server. Local or remote clients access system information by requesting Web pages from the server via HTTP.
• The program does not serve static HTML pages. Instead, the pages are generated on the fly by modules, each of which provides a page summarizing one aspect of the system’s state.
• Modules are not linked statically into the server executable. Instead, they are loaded dynamically from shared libraries. Modules can be added, removed, or replaced while the server is running.
• The server services each connection in a child process. This enables the server to remain responsive even when individual requests take a while to complete, and it shields the server from failures in modules.
• The server does not require superuser privilege to run (as long as it is not run on a privileged port). However, this limits the system information that it can collect.
We provide four sample modules that demonstrate how modules might be written. They further illustrate some of the techniques for gathering system information presented previously in this book. The time module demonstrates using the gettimeofday system call. The issue module demonstrates low-level I/O and the sendfile system call. The diskfree module demonstrates the use of fork, exec, and dup2 by running a command in a child process. The processes module demonstrates the use of the /proc file system and various system calls.
This program has many of the features you’d expect in an application program, such as command-line parsing and error checking. At the same time, we’ve made some simplifications to improve readability and to focus on the GNU/Linux-specific topics discussed in this book. Bear in mind these caveats as you examine the code.
• We don’t attempt to provide a full implementation of HTTP. Instead, we implement just enough for the server to interact with Web clients. A real-world program either would provide a more complete HTTP implementation or would interface with one of the various excellent Web server implementations[1] available instead of providing HTTP services directly.
[1] The most popular open source Web server for GNU/Linux is the Apache server, available from http://www.apache.org.
• Similarly, we don’t aim for full compliance with HTML specifications (see http://www.w3.org/MarkUp/). We generate simple HTML output that can be handled by popular Web browsers.
• The server is not tuned for high performance or minimum resource usage. In particular, we intentionally omit some of the network configuration code that you would expect in a Web server. This topic is outside the scope of this book. See one of the many excellent references on network application development, such as UNIX Network Programming, Volume 1: Networking APIs—Sockets and XTI, by W. Richard Stevens (Prentice Hall, 1997), for more information.
• We make no attempt to regulate the resources (number of processes, memory use, and so on) consumed by the server or its modules. Many multiprocess Web server implementations service connections using a fixed pool of processes rather than creating a new child process for each connection.
• The server loads the shared library for a server module each time it is requested and then immediately unloads it when the request has been completed. A more efficient implementation would probably cache loaded modules.
All but the very smallest programs written in C require careful organization to preserve the modularity and maintainability of the source code. This program is divided into four main source files.
Each source file exports functions or variables that may be accessed by the other parts of the program. For simplicity, all exported functions and variables are declared in a single header file, server.h (see Listing 11.1), which is included by the other files. Functions that are intended for use within a single compilation unit only are declared static and are not declared in server.h.



common.c (see Listing 11.2) contains functions of general utility that are used throughout the program.



You could use these functions in other programs as well; the contents of this file might be included in a common code library that is shared among many projects:
• xmalloc, xrealloc, and xstrdup are error-checking versions of the C library functions malloc, realloc, and strdup, respectively. Unlike the standard versions, which return a null pointer if the allocation fails, these functions immediately abort the program when insufficient memory is available.
Early detection of memory allocation failure is a good idea. Otherwise, failed allocations introduce null pointers at unexpected places into the program. Because allocation failures are not easy to reproduce, debugging such problems can be difficult. Allocation failures are usually catastrophic, so aborting the program is often an acceptable course of action.
• The error function is for reporting a fatal program error. It prints a message to stderr and ends the program. For errors caused by failed system calls or library calls, system_error generates part of the error message from the value of errno (see Section 2.2.3, “Error Codes from System Calls,” in Chapter 2, “Writing Good GNU/Linux Software”).
• get_self_executable_directory determines the directory containing the executable file being run in the current process. The directory path can be used to locate other components of the program, which are installed in the same place at runtime. This function works by examining the symbolic link /proc/self/exe in the /proc file system (see Section 7.2.1, “proc/self,” in Chapter 7, “The /proc File System”).
In addition, common.c defines two useful global variables:
• The value of program_name is the name of the program being run, as specified in its argument list (see Section 2.1.1, “The Argument List,” in Chapter 2). When the program is invoked from the shell, this is the path and name of the program as the user entered it.
• The variable verbose is nonzero if the program is running in verbose mode. In this case, various parts of the program print progress messages to stdout.
module.c (see Listing 11.3) provides the implementation of dynamically loadable server modules. A loaded server module is represented by an instance of struct server_module, which is defined in server.h.


Each module is a shared library file (see Section 2.3.2, “Shared Libraries,” in Chapter 2) and must define and export a function named module_generate. This function generates an HTML Web page and writes it to the client socket file descriptor passed as its argument.
module.c contains two functions:
• module_open attempts to load a server module with a given name. The name normally ends with the .so extension because server modules are implemented as shared libraries. This function opens the shared library with dlopen and resolves a symbol named module_generate from the library with dlsym (see Section 2.3.6, “Dynamic Loading and Unloading,” in Chapter 2). If the library can’t be opened, or if module_generate isn’t a name exported by the library, the call fails and module_open returns a null pointer. Otherwise, it allocates and returns a module object.
• module_close closes the shared library corresponding to the server module and deallocates the struct server_module object.
module.c also defines a global variable module_dir. This is the path of the directory in which module_open attempts to find shared libraries corresponding to server modules.
server.c (see Listing 11.4) is the implementation of the minimal HTTP server.








These are the functions in server.c:
• server_run is the main entry point for running the server. This function starts the server and begins accepting connections, and does not return unless a serious error occurs. The server uses a TCP stream server socket (see Section 5.5.3, “Servers,” in Chapter 5, “Interprocess Communication”).
The first argument to server_run specifies the local address at which connections are accepted. A GNU/Linux computer may have multiple network addresses, and each address may be bound to a different network interface.[2] To restrict the server to accept connections from a particular interface, specify the corresponding network address. Specify the local address INADDR_ANY to accept connections for any local address.
[2] Your computer might be configured to include such interfaces as eth0, an Ethernet card; lo, the local (loopback) network; or ppp0, a dial-up network connection.
The second argument to server_run is the port number on which to accept connections. If the port number is already in use, or if it corresponds to a privileged port and the server is not being run with superuser privilege, the server fails. The special value 0 instructs Linux to select an unused port automatically. See the inet man page for more information about Internet-domain addresses and port numbers.
The server handles each client connection in a child process created with fork (see Section 3.2.2, “Using fork and exec,” in Chapter 3, “Processes”). The main (parent) process continues accepting new connections while existing ones are being serviced. The child process invokes handle_connection and then closes the connection socket and exits.
• handle_connection processes a single client connection, using the socket file descriptor passed as its argument. This function reads data from the socket and attempts to interpret this as an HTTP page request.
The server processes only HTTP version 1.0 and version 1.1 requests. When faced with a different protocol or version, it responds by sending the HTTP result code 400 and the message bad_request_response. The server understands only the HTTP GET method. If the client requests any other method, the server responds by sending the HTTP result code 501 and the message bad_method_response_template.
• If the client sends a well-formed GET request, handle_connection calls handle_get to service it. This function attempts to load a server module with a name generated from the requested page. For example, if the client requests the page named information, it attempts to load a server module named information.so. If the module can’t be loaded, handle_get sends the client the HTTP result code 404 and the message not_found_response_template.
If the client sends a page request that corresponds to a server module, handle_get sends a result code 200 header to the client, which indicates that the request was processed successfully and invokes the module’s module_generate function. This function generates the HTML source for a Web page and sends it to the Web client.
• server_run installs clean_up_child_process as the signal handler for SIGCHLD. This function simply cleans up terminated child processes (see Section 3.4.4, “Cleaning Up Children Asynchronously,” in Chapter 3).
main.c (see Listing 11.5) provides the main function for the server program. Its responsibility is to parse command-line options, detect and report command-line errors, and configure and run the server.
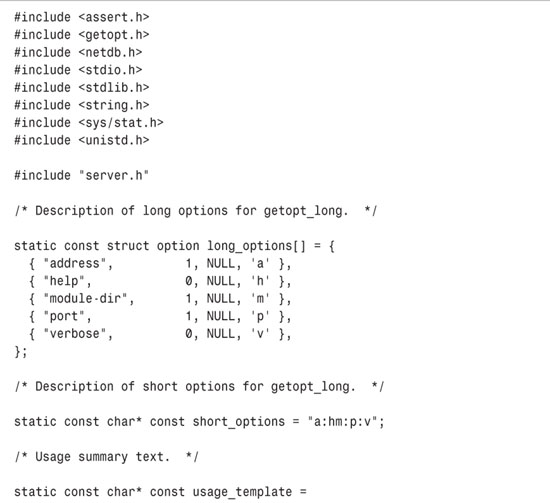




main.c contains these functions:
• main invokes getopt_long (see Section 2.1.3, “Using getopt_long,” in Chapter 2) to parse command-line options. It provides both long and short option forms, the former in the long_options array and the latter in the short_options string.
The default value for the server port is 0 and for a local address is INADDR_ANY. These can be overridden by the --port (-p) and --address (-a) options, respectively. If the user specifies an address, main calls the library function gethostbyname to convert it to a numerical Internet address.[3]
[3] gethostbyname performs name resolution using DNS, if necessary.
The default value for the directory from which to load server modules is the directory containing the server executable, as determined by get_self_executable_directory. The user may override this with the --module-dir (-m) option; main makes sure that the specified directory is accessible.
By default, verbose messages are not printed. The user may enable them by specifying the --verbose (-v) option.
• If the user specifies the --help (-h) option or specifies invalid options, main invokes print_usage, which prints a usage summary and exits.
We provide four modules to demonstrate the kind of functionality you could implement using this server implementation. Implementing your own server module is as simple as defining a module_generate function to return the appropriate HTML text.
The time.so module (see Listing 11.6) generates a simple page containing the server’s local wall-clock time. This module’s module_generate calls gettimeofday to obtain the current time (see Section 8.7, “gettimeofday: Wall-Clock Time,” in Chapter 8, “Linux System Calls”) and uses localtime and strftime to generate a text representation of it. This representation is embedded in the HTML template page_template.


This module uses standard C library I/O routines for convenience. The fdopen call generates a stream pointer (FILE*) corresponding to the client socket file descriptor (see Section B.4, “Relation to Standard C Library I/O Functions,” in Appendix B, “Low-Level I/O”). The module writes to it using fprintf and flushes it using fflush to prevent the loss of buffered data when the socket is closed.
The HTML page returned by the time.so module includes a <meta> element in the page header that instructs clients to reload the page every 5 seconds. This way the client displays the current time.
The issue.so module (see Listing 11.7) displays information about the GNU/Linux distribution running on the server. This information is traditionally stored in the file /etc/issue. This module sends the contents of this file, wrapped in a <pre> element of an HTML page.



The module first tries to open /etc/issue. If that file can’t be opened, the module sends an error page to the client. Otherwise, the module sends the start of the HTML page, contained in page_start. Then it sends the contents of /etc/issue using sendfile (see Section 8.12, “sendfile: Fast Data Transfers,” in Chapter 8). Finally, it sends the end of the HTML page, contained in page_end.
You can easily adapt this module to send the contents of another file. If the file contains a complete HTML page, simply omit the code that sends the contents of page_start and page_end. You could also adapt the main server implementation to serve static files, in the manner of a traditional Web server. Using sendfile provides an extra degree of efficiency.
The diskfree.so module (see Listing 11.8) generates a page displaying information about free disk space on the file systems mounted on the server computer. This generated information is simply the output of invoking the df -h command. Like issue.so, this module wraps the output in a <pre> element of an HTML page.


While issue.so sends the contents of a file using sendfile, this module must invoke a command and redirect its output to the client. To do this, the module follows these steps:
- First, the module creates a child process using
fork(see Section 3.2.2, “Using fork and exec,” in Chapter 3) - The child process copies the client socket file descriptor to file descriptors
STDOUT_FILENOandSTDERR_FILENO, which correspond to standard output and standard error (see Section 2.1.4, “Standard I/O,” in Chapter 2). The file descriptors are copied using thedup2call (see Section 5.4.3, “Redirecting the Standard Input,” in Chapter 5). All further output from the process to either of these streams is sent to the client socket. - The child process invokes the
dfcommand with the-hoption by callingexecv(see Section 3.2.2, “Using fork and exec,” in Chapter 3) - The parent process waits for the child process to exit by calling
waitpid(see Section 3.4.2, “The wait System Calls,” in Chapter 3).
You could easily adapt this module to invoke a different command and redirect its output to the client.
The processes.so module (see Listing 11.9) is a more extensive server module implementation. It generates a page containing a table that summarizes the processes currently running on the server system. Each process is represented by a row in the table that lists the PID, the executable program name, the owning user and group names, and the resident set size.










Gathering process data and formatting it as an HTML table is broken down into several simpler operations:
• get_uid_gid extracts the IDs of the owning user and group of a process. To do this, the function invokes stat (see Section B.2, “stat,” in Appendix B) on the process’s subdirectory in /proc (see Section 7.2, “Process Entries,” in Chapter 7). The user and group that own this directory are identical to the process’s owning user and group.
• get_user_name returns the username corresponding to a UID. This function simply calls the C library function getpwuid, which consults the system’s /etc/passwd file and returns a copy of the result. get_group_name returns the group name corresponding to a GID. It uses the getgrgid call.
• get_program_name returns the name of the program running in a specified process. This information is extracted from the stat entry in the process’s directory under /proc (see Section 7.2, “Process Entries,” in Chapter 7). We use this entry rather than examining the exe symbolic link (see Section 7.2.4, “Process Executable,” in Chapter 7) or cmdline entry (see Section 7.2.2, “Process Argument List,” in Chapter 7) because the latter two are inaccessible if the process running the server isn’t owned by the same user as the process being examined. Also, reading from stat doesn’t force Linux to page the process under examination back into memory, if it happens to be swapped out.
• get_rss returns the resident set size of a process. This information is available as the second element in the contents of the process’s statm entry (see Section 7.2.6, “Process Memory Statistics,” in Chapter 7) in its /proc subdirectory.
• format_process_info generates a string containing HTML elements for a single table row, representing a single process. After calling the functions listed previously to obtain this information, it allocates a buffer and generates HTML using snprintf.
• module_generate generates the entire HTML page, including the table. The output consists of one string containing the start of the page and the table (in page_start), one string for each table row (generated by format_process_info), and one string containing the end of the table and the page (in page_end).
module_generate determines the PIDs of the processes running on the system by examining the contents of /proc. It obtains a listing of this directory using opendir and readdir (see Section B.6, “Reading Directory Contents,” in Appendix B). It scans the contents, looking for entries whose names are composed entirely of digits; these are taken to be process entries.
Potentially a large number of strings must be written to the client socket—one each for the page start and end, plus one for each process. If we were to write each string to the client socket file descriptor with a separate call to write, this would generate unnecessary network traffic because each string may be sent in a separate network packet.
To optimize packing of data into packets, we use a single call to writev instead (see Section B.3, “Vector Reads and Writes,” in Appendix B). To do this, we must construct an array of struct iovec objects, vec. However, because we do not know the number of processes beforehand, we must start with a small array and expand it as new processes are added. The variable vec_length contains the number of elements of vec that are used, while vec_size contains the allocated size of vec. When vec_length is about to exceed vec_size, we expand vec to twice its size by calling xrealloc. When we’re done with the vector write, we must deallocate all of the dynamically allocated strings pointed to by vec, and then vec itself.
If we were planning to distribute this program in source form, maintain it on an ongoing basis, or port it to other platforms, we probably would want to package it using GNU Automake and GNU Autoconf, or a similar configuration automation system. Such tools are outside the scope of this book; for more information about them, consult GNU Autoconf, Automake, and Libtool (by Vaughan, Elliston, Tromey, and Taylor, published by New Riders, 2000).
Instead of using Autoconf or a similar tool, we provide a simple Makefile compatible with GNU Make[4] so that it’s easy to compile and link the server and its modules. The Makefile is shown in Listing 11.10. See the info page for GNU Make for details of the file’s syntax.
[4] GNU Make comes installed on GNU/Linux systems.
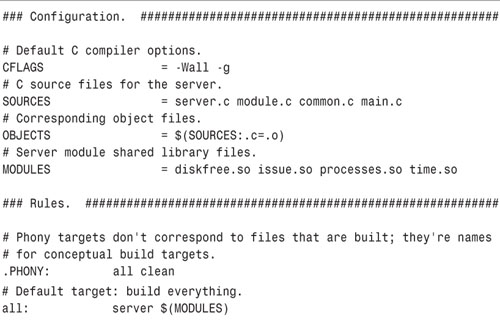

The Makefile provides these targets:
• all (the default if you invoke make without arguments because it’s the first target in the Makefile) includes the server executable and all the modules. The modules are listed in the variable MODULES.
• clean deletes any build products that are produced by the Makefile.
• server links the server executable. The source files listed in the variable SOURCES are compiled and linked in.
• The last rule is a generic pattern for compiling shared object files for server modules from the corresponding source files.
Note that source files for server modules are compiled with the -fPIC option because they are linked into shared libraries (see Section 2.3.2, “Shared Libraries,” in Chapter 2).
Also observe that the server executable is linked with the -Wl, -export-dynamic compiler option. With this option, GCC passes the -export-dynamic option to the linker, which creates an executable file that also exports its external symbols as a shared library. This allows modules, which are dynamically loaded as shared libraries, to reference functions from common.c that are linked statically into the server executable.
Building the program is easy. From the directory containing the sources, simply invoke make:

This builds the server program and the server module shared libraries.

To run the server, simply invoke the server executable.
If you do not specify the server port number with the --port (-p) option, Linux will choose one for you; in this case, specify --verbose (-v) to make the server print out the port number in use.
If you do not specify an address with --address (-a), the server runs on all your computer’s network addresses. If your computer is attached to a network, that means that others will be capable of accessing the server, provided that they know the correct port number to use and page to request. For security reasons, it’s a good idea to specify the localhost address until you’re confident that the server works correctly and is not releasing any information that you prefer to not make public. Binding to the localhost causes the server to bind to the local network device (designated “lo”)—only programs running on the same computer can connect to it. If you specify a different address, it must be an address that corresponds to your computer:
% ./server --address localhost --port 4000
The server is now running. Open a browser window, and attempt to contact the server at this port number. Request a page whose name matches one of the modules. For instance, to invoke the diskfree.so module, use this URL:
http://localhost:4000/diskfree
Instead of 4000, enter the port number you specified (or the port number that Linux chose for you). Press Ctrl+C to kill the server when you’re done.
If you didn’t specify localhost as the server address, you can also connect to the server with a Web browser running on another computer by using your computer’s hostname in the URL—for example:
http://host.domain.com:4000/diskfree
If you specify the --verbose (-v) option, the server prints some information at startup and displays the numerical Internet address of each client that connects to it. If you connect via the localhost address, the client address will always be 127.0.0.1.
If you experiment with writing your own server modules, you may place them in a different directory than the one containing the server module. In this case, specify that directory with the --module-dir (-m) option. The server will look in this directory for server modules instead.
If you forget the syntax of the command-line options, invoke server with the --help (-h) option.

If you were really planning on releasing this program for general use, you’d need to write documentation for it as well. Many people don’t realize that writing good documentation is just as difficult and time-consuming—and just as important—as writing good software. However, software documentation is a subject for another book, so we’ll leave you with a few references of where to learn more about documenting GNU/Linux software.
You’d probably want to write a man page for the server program, for instance. This is the first place many users will look for information about a program. Man pages are formatted using a classic UNIX formatting system troff. To view the man page for troff, which describes the format of troff files, invoke the following:
% man troff
To learn about how GNU/Linux locates man pages, consult the man page for the man command itself by invoking this:
% man man
You might also want to write info pages, using the GNU Info system, for the server and its modules. Naturally, documentation about the info system comes in info format; to view it, invoke this line:
% info info
Many GNU/Linux programs come with documentation in plain text or HTML formats as well.
Happy GNU/Linux programming!