
Let's look at how we can code the k-means algorithm in Python:
- First, let's import the packages that we will need to code for the k-means algorithm. Note that we are importing the sklearn package for k-means clustering:
from sklearn import cluster
import pandas as pd
import numpy as np
- To use k-means clustering, let's create 20 data points in a two-dimensional problem space that we will be using for k-means clustering:
dataset = pd.DataFrame({
'x': [11, 21, 28, 17, 29, 33, 24, 45, 45, 52, 51, 52, 55, 53, 55, 61, 62, 70, 72, 10],
'y': [39, 36, 30, 52, 53, 46, 55, 59, 63, 70, 66, 63, 58, 23, 14, 8, 18, 7, 24, 10]
})
- Let's have two clusters (k = 2) and then create the cluster by calling the fit functions:
myKmeans = cluster.KMeans(n_clusters=2)
myKmeans.fit(dataset)
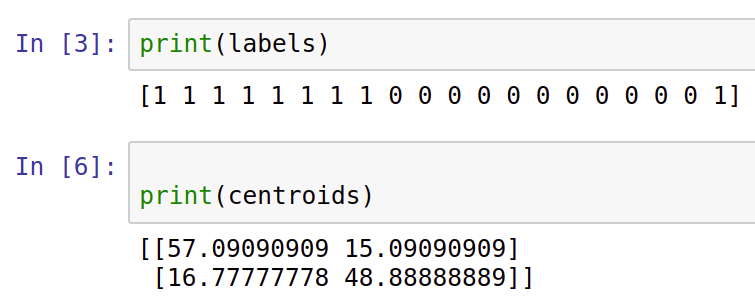
- Let's create a variable named centroid that is an array that holds the location of the center of the clusters formed. In our case, as k = 2, the array will have a size of 2. Let's also create another variable named label that represents the assignment of each data point to one of the two clusters. As there are 20 data points, this array will have a size of 20:
centroids = myKmeans.cluster_centers_
labels = myKmeans.labels_
- Now let's print these two arrays, centroids and labels:
- Let's plot and look at the clusters using matplotlib:

Note that the bigger dots in the plot are the centroids as determined by the k-means algorithm.