
Chapter 5 – Join Functions
“I When spider webs unite they can tie up a lion.”
- African Proverb
Teradata Join Quiz
Which Statement is NOT true!
1. Each Table in Teradata has a Primary Index, unless it is a No Primary Index Table (NoPI).
2. The Primary Index is the mechanism that allows Teradata to physically distribute the rows of a table across the AMPs.
3. For two rows to be Joined together Teradata insists that both rows are physically on the same AMP.
4. Teradata a will either Redistribute one or both of the tables or Duplicate the smaller table across all AMPs to ensure matching rows are on the same AMP, even if it is only for the life of the Join.
Do you know which statement above is False?
Teradata Join Quiz Answer

All statements above are TRUE! Two joining rows have to be in the same memory of a single AMP.
Redistribution

SELECT
C.Customer_Number, C.Phone_Number ,C.Customer_Name
,O.Customer_Number, O.Order_Number, O.Order_Date, Order_Total
FROM Customer_Table as C
INNER JOIN
Order_Table as O
ON C.Customer_Number = O.Customer_Number ;
Teradata can redistribute data (temporarily) by re-hashing Customer_Number from the Order_Table. Now, all joining rows will be on the same AMP’s memory. That is one of two way to get matching rows together.
Big Table Small Table Join Strategy
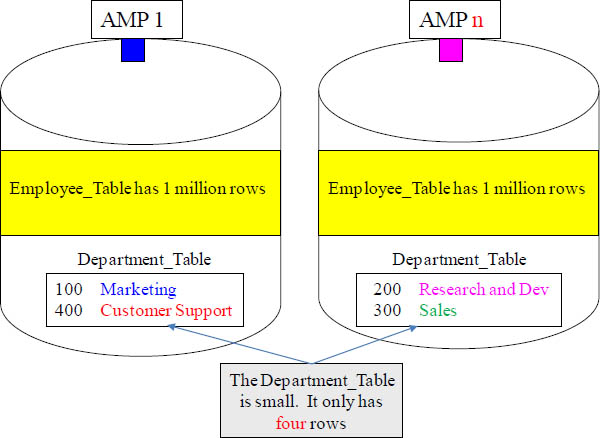
Teradata has a special way of dealing with big table and small table joins. Turn the page and be prepared to be amazed!
Duplication of the Smaller Table across All-AMPs
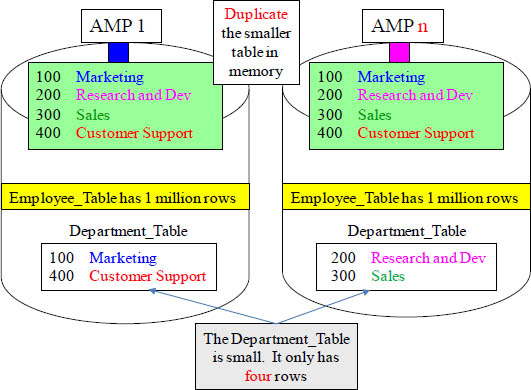
Teradata took the Department_Table and gathered up all 4-rows (temporarily) and in memory Duplicated the entire 4-row Table across all AMPs. Now the joins can happen! This is the second way to get rows together. If one table is much bigger than the other, Teradata will duplicate the smaller table on all AMPs, just for the life of the query.
If the Join Condition is the Distribution Key no Movement
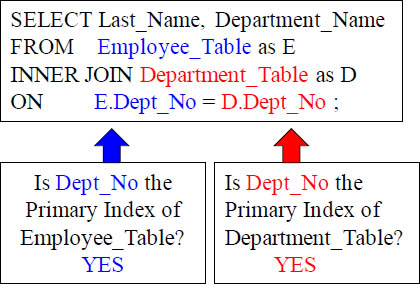
If the above tables (being joined by Dept_No) also had Dept_No as their Primary Index then matching rows would naturally be on the same AMP together. See this visually by turning the page!
Teradata knows that it can only JOIN two rows together if they are physically on the same AMP. This can occur naturally if the join condition columns are the Primary Indexes of their respective tables, but most likely Teradata will have to move data to get the matching rows on the same AMP. What will the Optimizer decide to do next?
Matching Rows That Are On The Same AMP Naturally
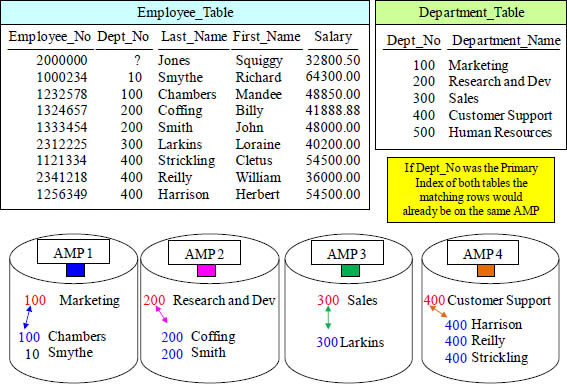
If both the Employee_Table and the Department_table (being joined by Dept_No) have Dept_No as their respective Primary Indexes they are considered co-located. Anytime these two tables are joined, there is no need to redistribute or duplicate because the matching rows are naturally on the same AMP. That is the brilliance of the Teradata Hash Formula.
What if the Join Condition Columns are Not Primary Indexes
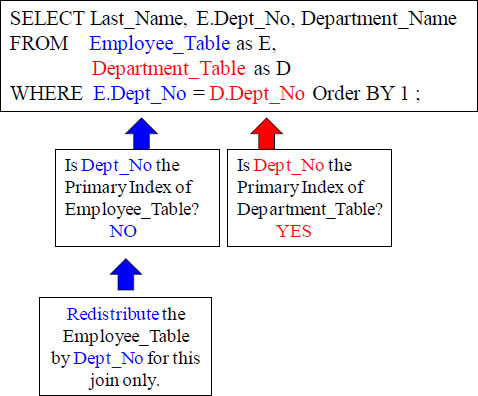
The Optimizer (PE) knows that the Dept_No column is the Primary Index for the Department_Table. It also know s that the Dept_No column is NOT the Primary Index for the Employee_Table, so the Optimizer commands the AMPs to Redistribute the entire Employee_Table by Dept_No temporarily. This is equivalent to loading the Employee_Table with a Primary Index of Dept_No. Now all matching rows can join.
Strategy 1 of 4 – The Merge Join
The rows to be joined have to be located on a common AMP
Both spools have to be sorted by the ROWID calculated over the join column(s)
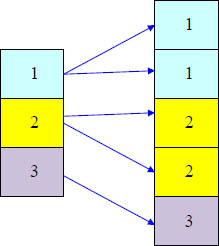
Re-Distribution of one or both spools by ROWHASH or
Duplication of the smaller spool to all AMPs
Sorting of one or both spools by the ROWID
Relocation of rows to the common AMP can be done by redistribution of the rows by the join column(s) ROWHASH or by copying the smaller table as a whole to all AMPs.
Quiz – Redistribute the Employees by their Dept_No
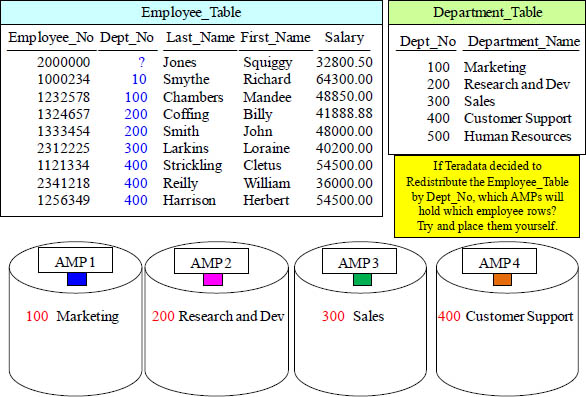
Fill in the quiz above. This is a great opportunity to understand the Teradata engine.
Quiz – Employees' Dept_No landed on AMP with Matches
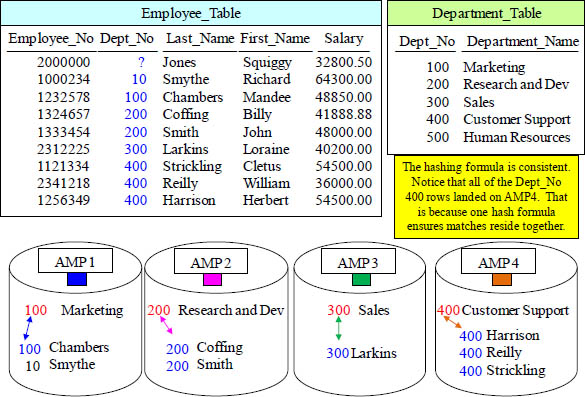
Each redistributed row landed on the same AMP as its matching row. Notice that Squiggy Jones has a NULL department so Teradata will not redistribute that row on an Inner Join. Smythe in Dept_No 10 hashes to SPU 1 but has no match. Turn the page.
Quiz – Redistribute the Orders to the Proper AMP
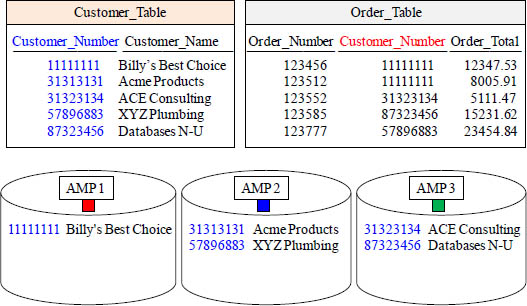
If Teradata decides to Redistribute the Order_Table by Customer_No, which AMPs will hold which Orders? Place their Customer_Number and Order_Total on the AMP after Redistribution.
Fill in the quiz above. This is a great opportunity to understand the Teradata engine.
Answer to Redistribute the Employees by their Dept_No Quiz
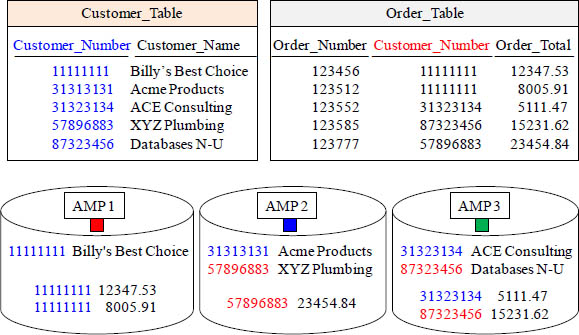
It is no coincidence that when Customer_Number
11111111 was hashed every 11111111 row went to AMP 1.
Each row redistributed to the same AMP as its matching row.
Strategy 2 of 4 – The Hash Join
1) The rows to be joined must be located on a common AMP
2) The smaller spool is sorted by the ROWHASH calculated over the join column(s) and is kept in the FSG cache (memory)
3) The bigger spool stays unsorted
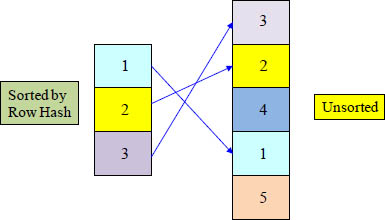
The bigger spool scanned row by row and then
each ROWID from the bigger spool is searched in
the smaller spool (by means of a binary search)
The Hash Join takes advantage of memory and loads the entire smaller spool into FSG Cache memory. Then, each row from the bigger spool is joined one at a time by doing a binary search (on the sorted smaller spool).
Strategy 3 of 4 – The Nested Join
Spool 1 allows a unique ROWHASH access (a unique index is defined)
Spool 2 allows any kind of ROWHASH access
(a unique or non-unique is index defined)
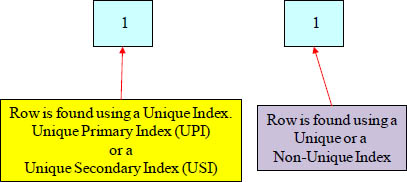
The qualifying row of spool 1 is accessed by
usage of any unique index. The row is relocated to
the AMP owning the rows of spool 2. Spool 2 is
full table scanned and each row is combined with
the one row from Spool 1.
The nested join is the fastest and the most rare. All you need is a Unique Index for the first row and any index for the second row lookup and you have a Nested Join.
Strategy 4 of 4 – The Product Join
The rows to be joined have to be located on the same AMP
No spool needs to be sorted!
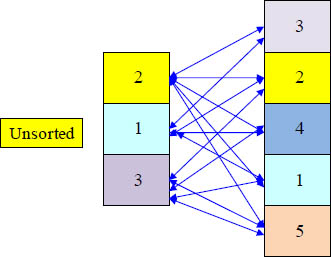
A full table scan is done on the smaller spool and each qualifying row of spool 1 is compared against each row of spool 2
The Product Join takes is not well received. Keep an eye on it. It could be a bad sign.
A Two-Table Join Using Traditional Syntax

A Join combines columns on the report from more than one table. The example above joins the Customer_Table and the Order_Table together. The most complicated part of any join is the JOIN CONDITION. The JOIN CONDITION is which Column from each table is a match. In this case, Customer_Number is a match that establishes the relationship, so this join will happen on matching Customer_Number columns.
A two-table join using Non-ANSI Syntax with Table Alias
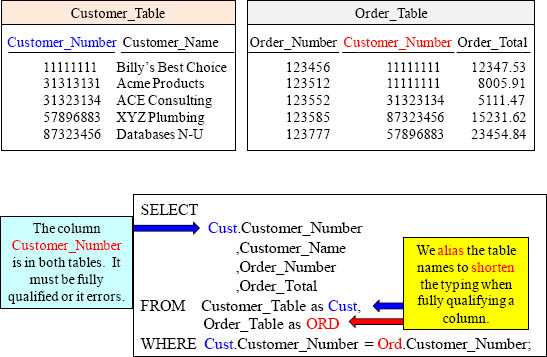
A Join combines columns on the report from more than one table. The example above joins the Customer_Table and the Order_Table together. The most complicated part of any join is the JOIN CONDITION. The JOIN CONDITION means which Column from each table is a match. In this case, Customer_Number is a match that establishes the relationship.
You Can Fully Qualify All Columns
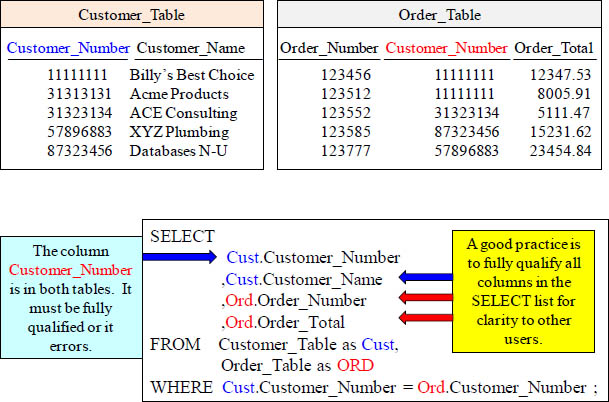
Whenever a column is in both tables, you must fully qualify it when doing a join. You don’t have to fully qualify tables that are only in one of the tables because the system knows which table that particular column is in. You can choose to fully qualify every column if you like. This is a good practice because it is more apparent which columns belong to which tables for anyone else looking at your SQL.
A two-table join using ANSI Syntax
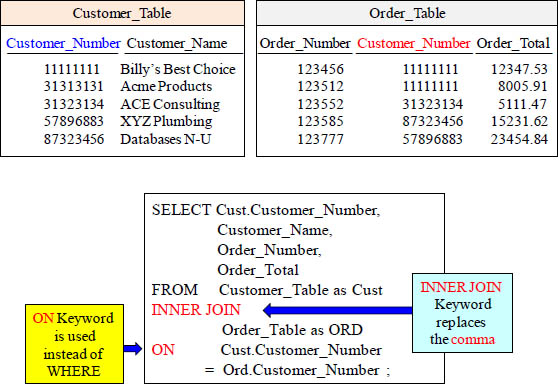
This is the same join as the previous slide except it is using ANSI syntax. Both will return the same rows with the same performance. Rows are joined when the Customer_Number matches on both tables, but non-matches won’t return.
Both Queries have the same Results and Performance
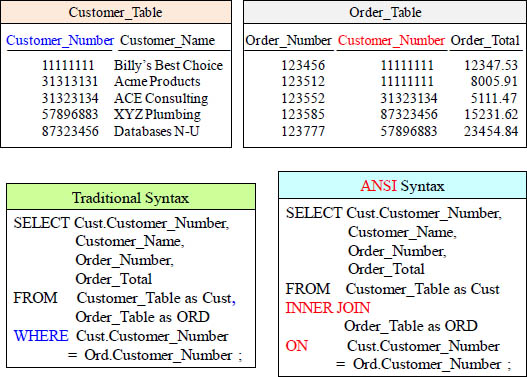
Both of these syntax techniques bring back the same result set and have the same performance. The INNER JOIN is considered ANSI. Which one does Outer Joins?
Quiz – Can You Finish the Join Syntax?
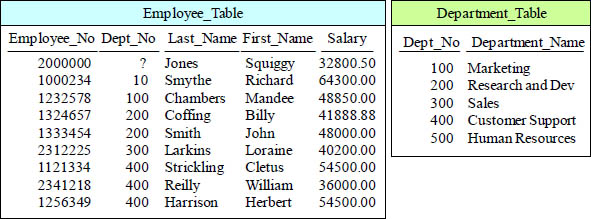
SELECT First_Name, Last_Name, Department_Name
FROM Employee_Table as E
INNER JOIN
Department_Table as D
ON
Finish the Join
Finish this join by placing the missing SQL in the proper place!
Answer to Quiz – Can You Finish the Join Syntax?
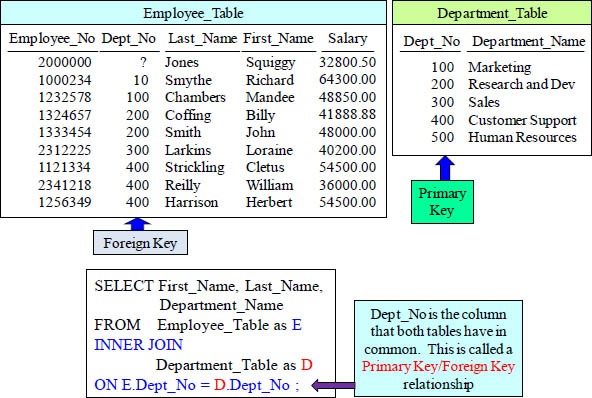
This query is ready to run.
Quiz – Can You Find the Error?
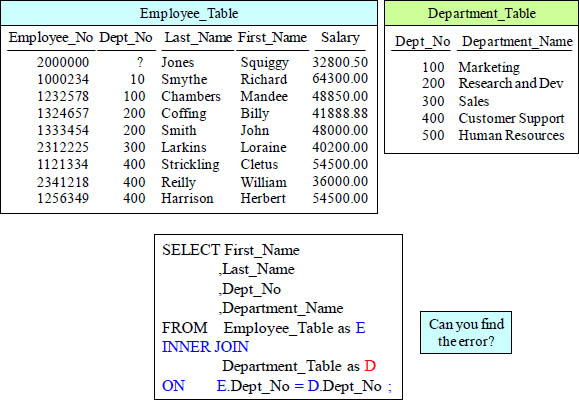
This query has an error! Can you find it?
Answer to Quiz – Can You Find the Error?
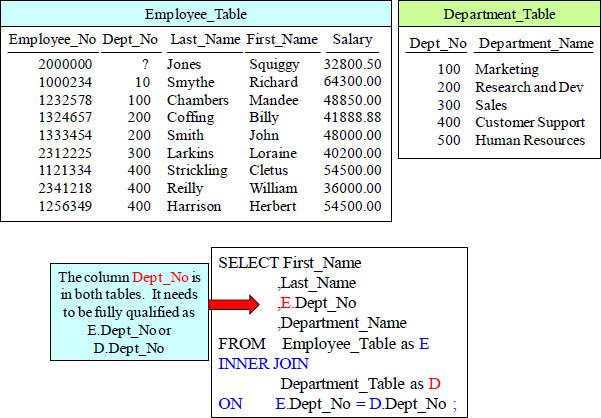
If a column in the SELECT list is in both tables, you must fully qualify it.
Super Quiz – Can You Find the Difficult Error?
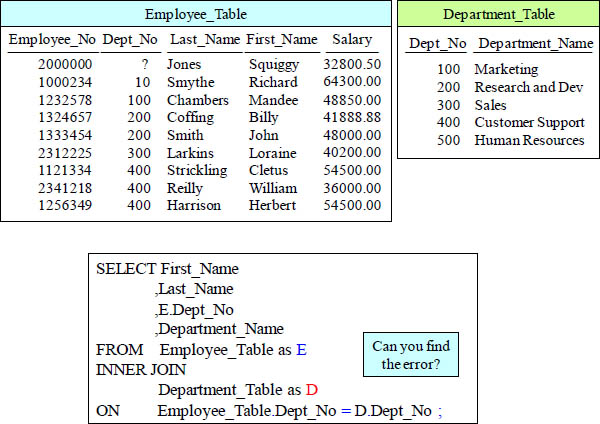
This query has an error! Can you find it?
Answer to Super Quiz – Can You Find the Difficult Error?
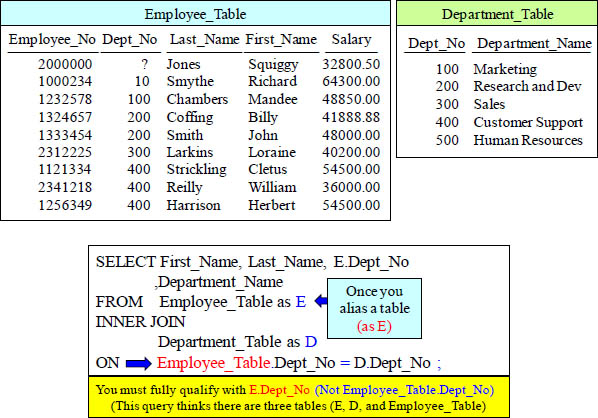
If a column in the SELECT list is in both tables, you must fully qualify it.
Quiz – Which rows from both tables Won’t Return?
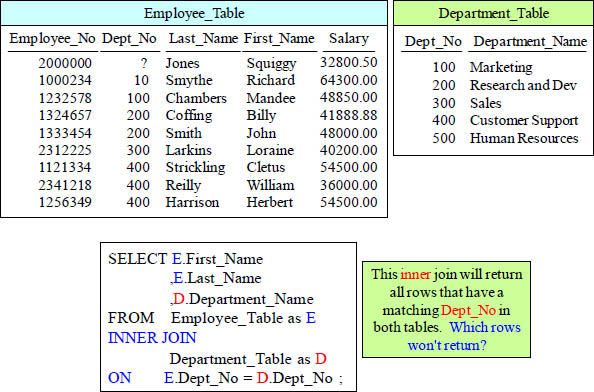
An Inner Join returns matching rows, but did you know an Outer Join returns both matching rows and non-matching rows? You will understand soon!
Answer to Quiz – Which rows from both tables Won’t Return?
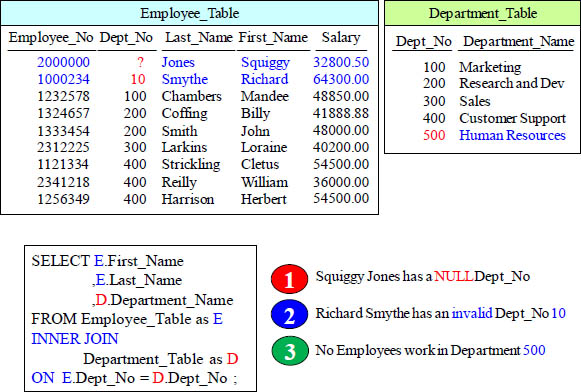
The bottom line is that the three rows excluded did not have a matching Dept_No.
LEFT OUTER JOIN
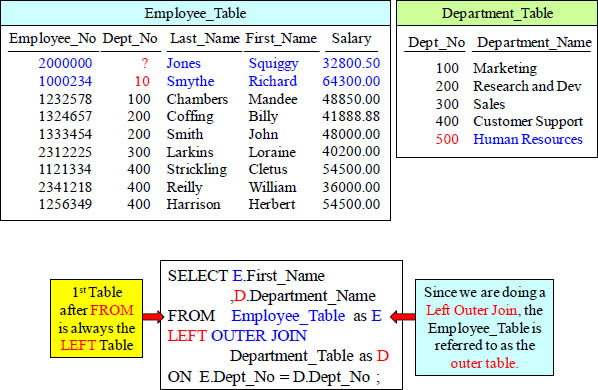
This is a LEFT OUTER JOIN. That means that all rows from the LEFT Table will appear in the report regardless if it finds a match on the right table.
LEFT OUTER JOIN Results
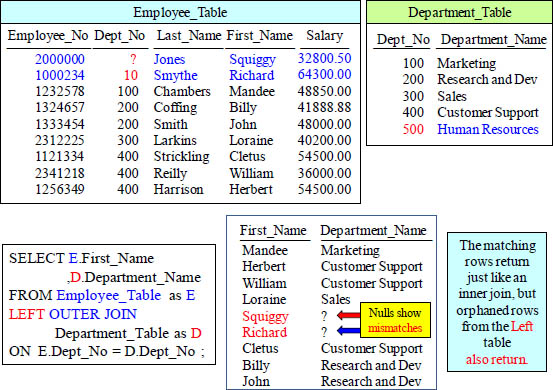
A LEFT Outer Join Returns all rows from the LEFT Table including all Matches. If a LEFT row can’t find a match, a NULL is placed on right columns not found!
RIGHT OUTER JOIN
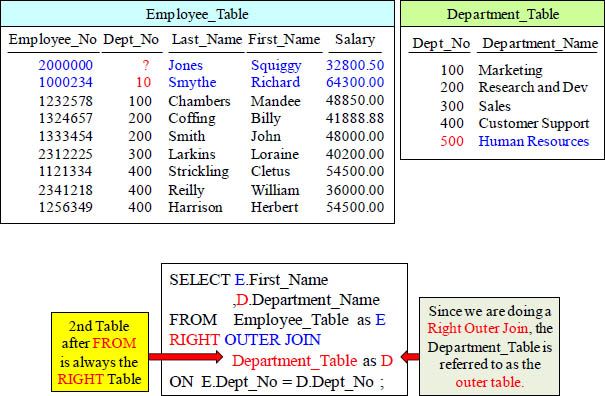
This is a RIGHT OUTER JOIN. That means that all rows from the RIGHT Table will appear in the report regardless if it finds a match with the LEFT Table.
RIGHT OUTER JOIN Example and Results
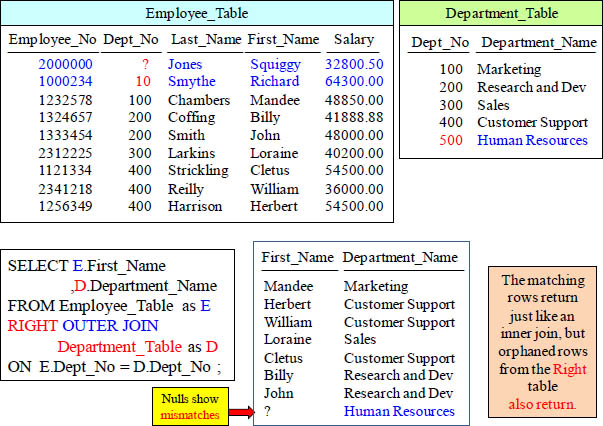
All rows from the Right Table were returned with matches, but since Dept_No 500 didn’t have a match, the system put a NULL Value for Left Column values.
FULL OUTER JOIN
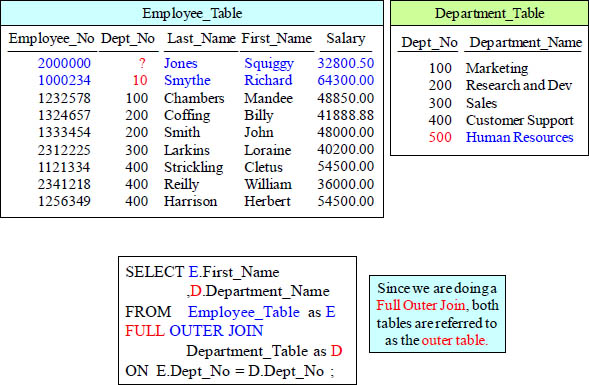
The is a FULL OUTER JOIN. That means that all rows from both the RIGHT and LEFT Table will appear in the report regardless if it finds a match.
FULL OUTER JOIN Results
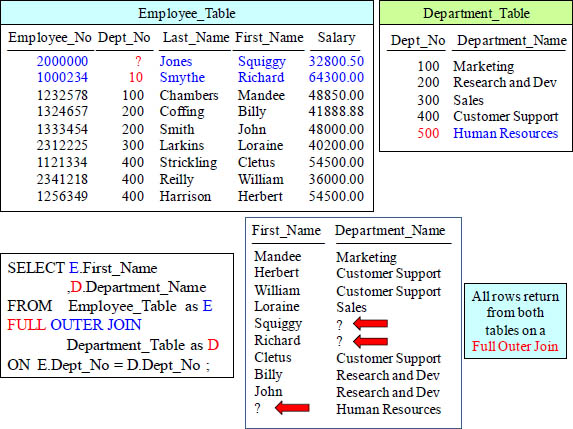
The FULL Outer Join Returns all rows from both Tables. NULLs show the flaws!
Which Tables are the Left and Which are the Right?

Can you list which tables above are left tables and which tables are right tables?
Answer - Which Tables are the Left and Which are the Right?

The first table is always the left table and the rest are right tables. The results from the first two tables being joined becomes the left table.
INNER JOIN with Additional AND Clause
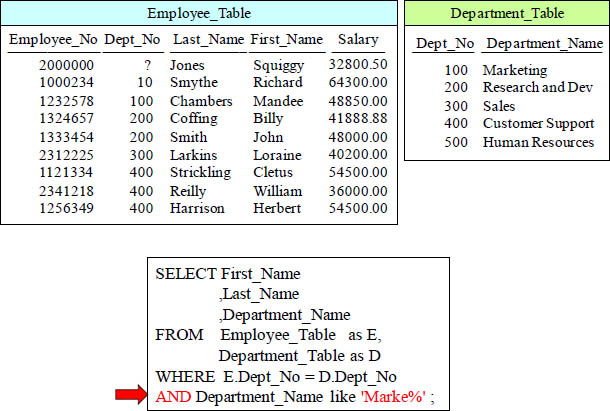
The additional AND is performed first in order to eliminate unwanted data, so the join is less intensive than joining everything first and then eliminating rows that don't qualify.
ANSI INNER JOIN with Additional AND Clause
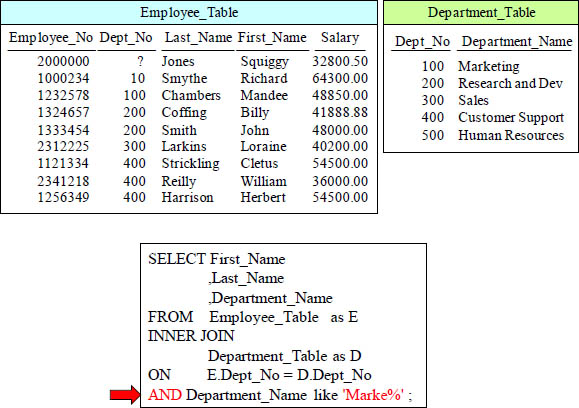
The additional AND is performed first in order to eliminate unwanted data, so the join is less intensive than joining everything first and then eliminating after.
ANSI INNER JOIN with Additional WHERE Clause
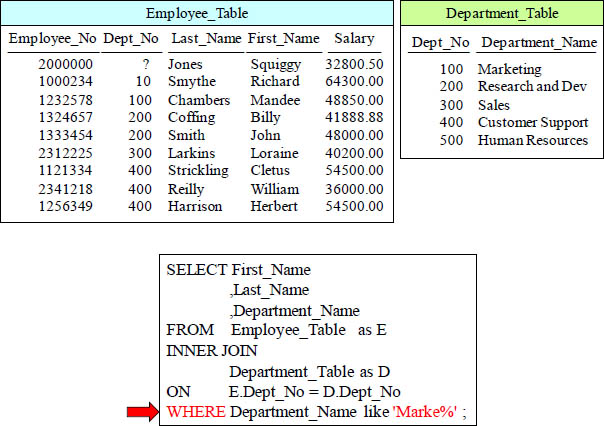
The additional WHERE is performed first in order to eliminate unwanted data, so the join is less intensive than joining everything first and then eliminating.
OUTER JOIN with Additional WHERE Clause
The additional WHERE is performed last on Outer Joins. All rows will be joined first and then the additional WHERE clause filters after the join takes place.
OUTER JOIN with Additional AND Clause
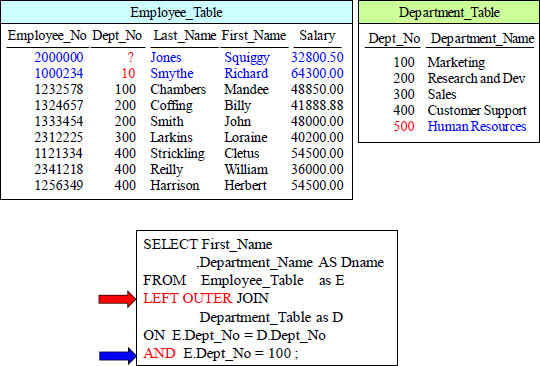
The additional AND is performed in conjunction with the ON statement on Outer Joins. All rows will evaluated with the ON clause and the AND combined.
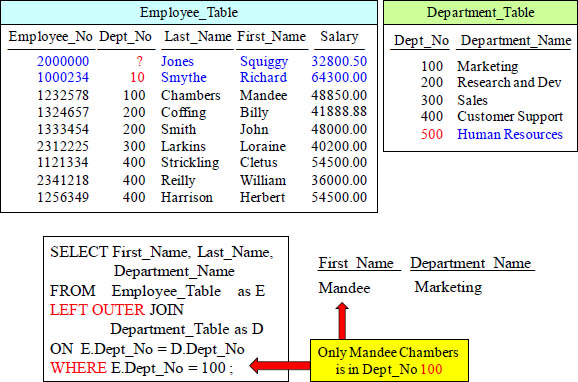
OUTER JOIN with Additional AND Clause Results
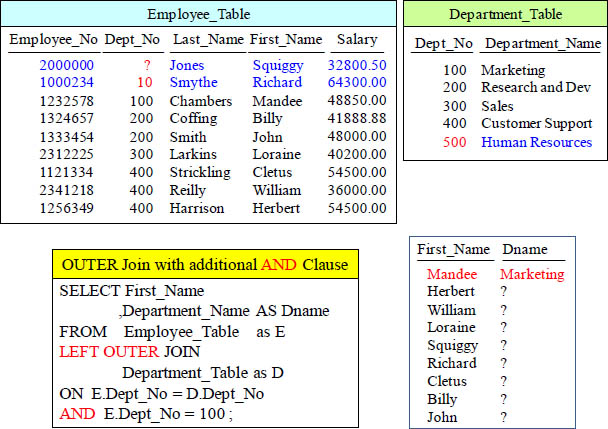
The additional AND is performed in conjunction with the ON statement on Outer Joins. This can surprise you. Only Mandee is in Dept_No 100, so she showed up like expected, but an outer join returns non-matches also. Ouch!!!
Quiz – Why is this Considered an INNER JOIN?
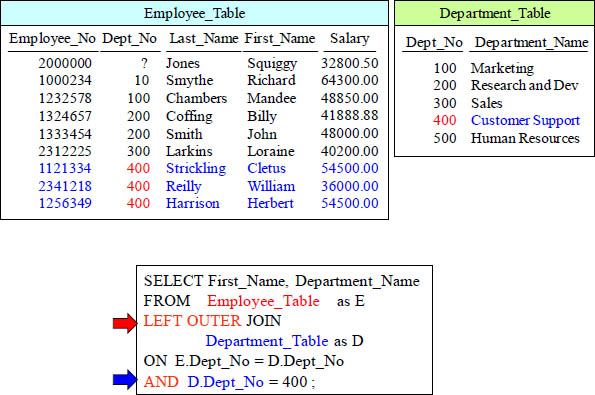
This is considered an INNER JOIN because we are doing a LEFT OUTER JOIN on the Employee_Table and then filtering with the AND for a column in the right table!
Evaluation Order For Outer Queries
SELECT Cou.*, STU1.*
FROM COURSE_TABLE Cou
LEFT OUTER JOIN
STUDENT_COURSE_TABLE STU
ON Cou.Course_Id = STU.Course_Id
LEFT OUTER JOIN STUDENT_TABLE STU1
ON STU.Student_Id = STU1.Student_Id;
| The Order in which Teradata evaluates Outer Queries | |
| The first ON clause in the query (reading from left to right). | |
| Any ON clause applies to its immediately preceding join operation. | |
| Parenthesis can be used to override the natural left to right order. |
When you perform an inner join Teradata considers this to be both commutative and associative. That means that two tables being inner joined will easily come up with the intended answer. This allows the optimizer to select the best join order between tables. This is because the end result will be the same. Outer Joins are different. They will follow the above three rules for evaluation order by the Parsing Engine.
The DREADED Product Join
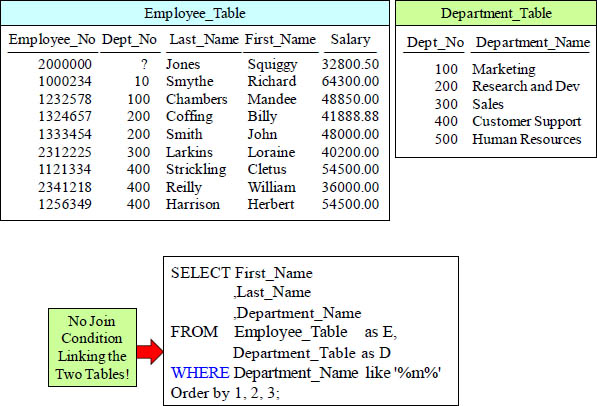
This query becomes a Product Join because it does not possess any JOIN Conditions (Join Keys). Every row from one table is compared to every row of the other table, and quite often, the data is not what you intended to get back.
The DREADED Product Join Results
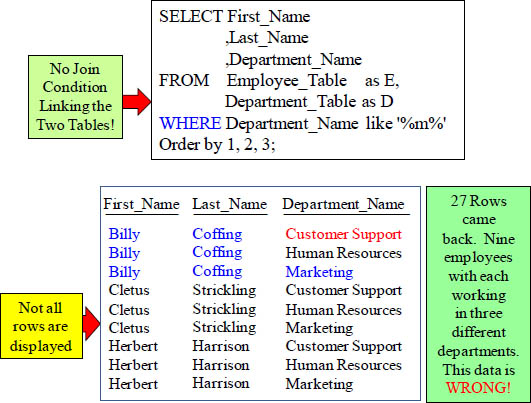
How can Billy Coffing work in 3 different departments?
A Product Join is often a mistake! 3 Department rows had an ‘m’ in their name, so these were joined to every employee, and the information is worthless.
The Horrifying Cartesian Product Join
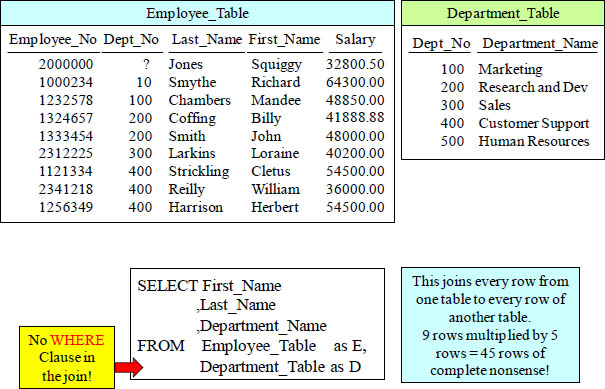
A Cartesian Product Join is usually a big mistake.
The ANSI Cartesian Join will ERROR
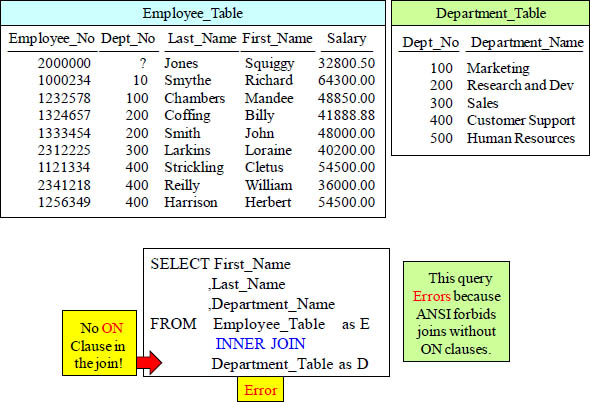
This causes an error. ANSI won’t let this run unless a join condition is present.
Quiz – Do these Joins Return the Same Answer Set?
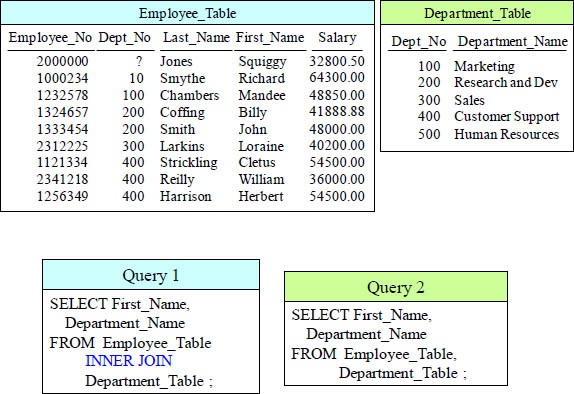
Do these two queries produce the same result?
Answer – Do these Joins Return the Same Answer Set?
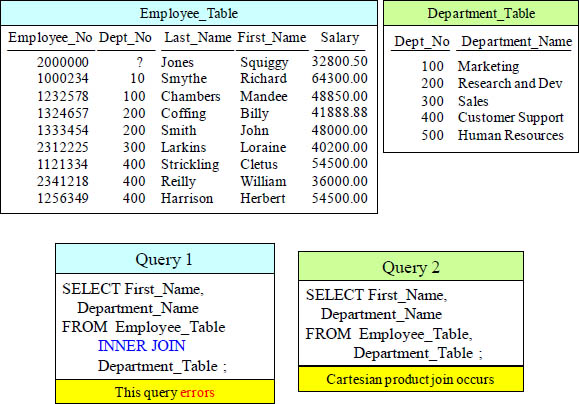
Do these two queries produce the same result? No, Query 1 Errors due to ANSI syntax and no ON Clause, but Query 2 Product Joins to bring back junk!
The CROSS JOIN
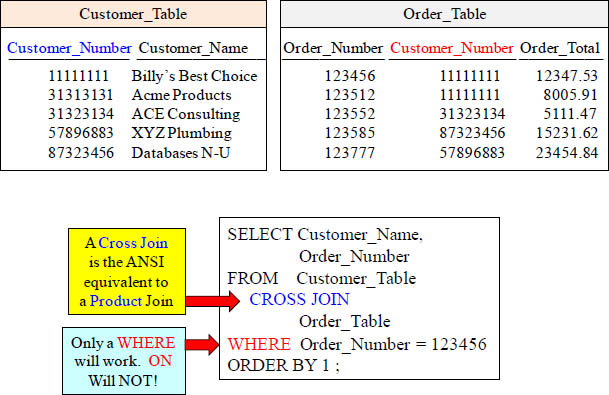
This query becomes a Product Join because a Cross Join is an ANSI Product Join. It will compare every row from the Customer_Table to Order_Number 123456 in the Order_Table. Check out the Answer Set on the next page.
The CROSS JOIN Answer Set
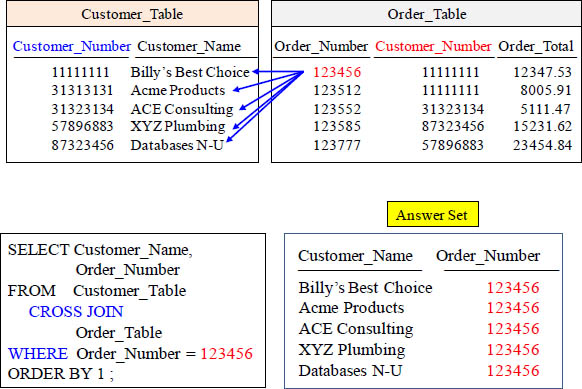
This Cross Join produces information that just isn’t worth anything quite often!
The Self Join
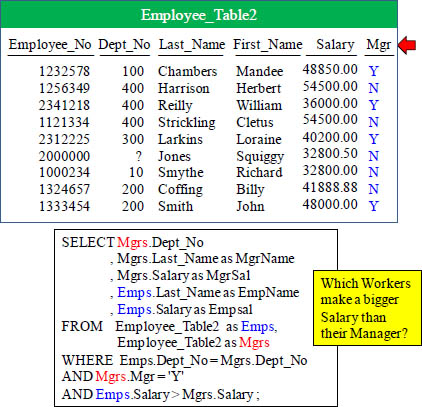
A Self Join gives itself 2 different Aliases, which is then seen as two different tables.
The Self Join with ANSI Syntax
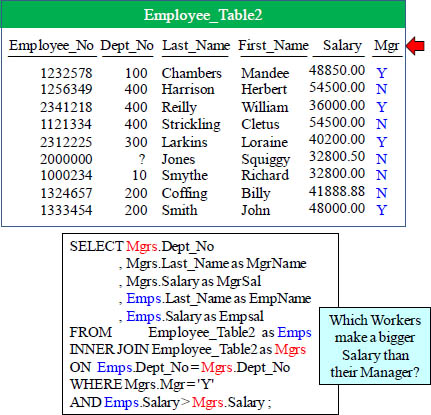
A Self Join gives itself 2 different Aliases, which is then seen as two different tables.
Quiz – Will both queries bring back the same Answer Set?
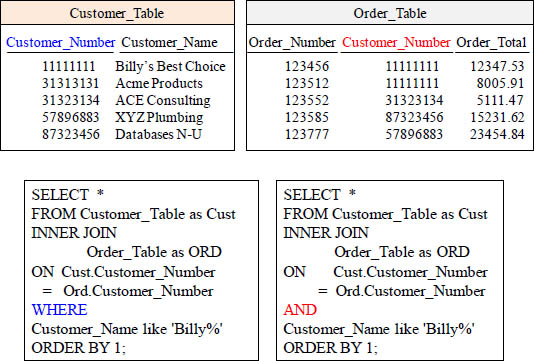
Will both queries bring back the same result set?
Answer – Will both queries bring back the same Answer Set?
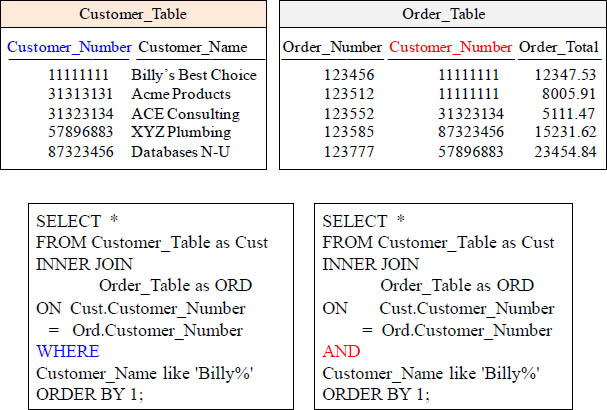
Will both queries bring back the same result set? Yes! Because they’re both inner joins.
Quiz – Will both queries bring back the same Answer Set?
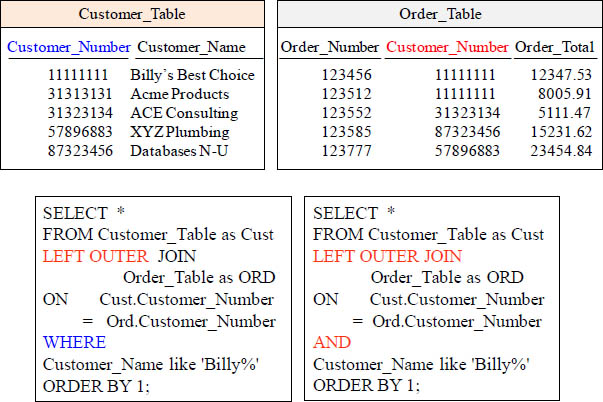
Will both queries bring back the same result set?
Answer – Will both queries bring back the same Answer Set?

Will both queries bring back the same result set? NO! The WHERE is performed last.
How would you Join these two tables?
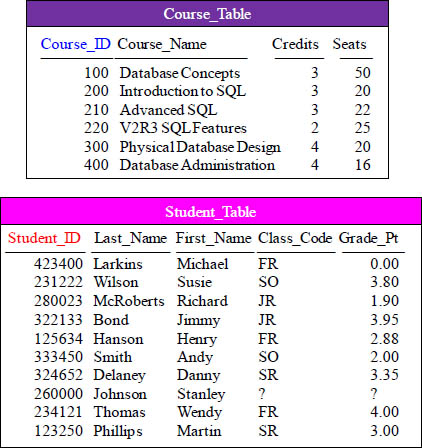
How would you join these two tables together? You can’t do it. There is no matching column with like data. There is no Primary Key/Foreign Key relationship between these two tables. That is why you are about to be introduced to a bridge table. It is formally called an Associative table or a Lookup table.
An Associative Table is a Bridge that Joins Two Tables
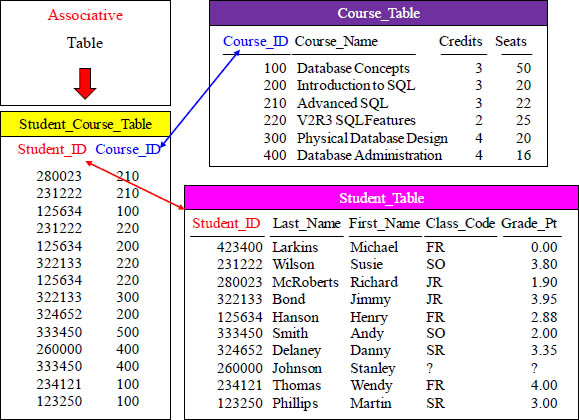
The Associative Table is a bridge between the Course_Table and Student_Table.
Quiz – Can you Write the 3-Table Join?
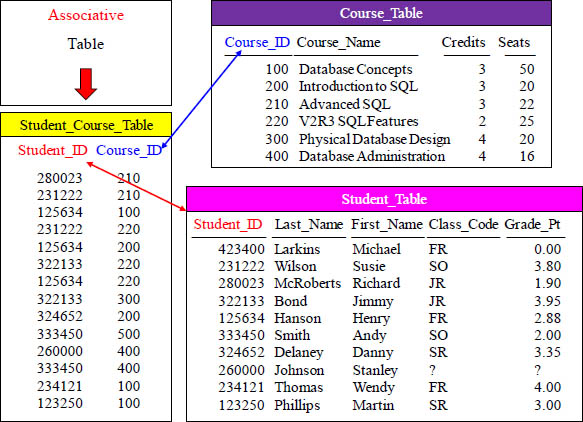
SELECT ALL Columns from the Course_Table and Student_Table and Join them.
Answer to Quiz – Can you Write the 3-Table Join?
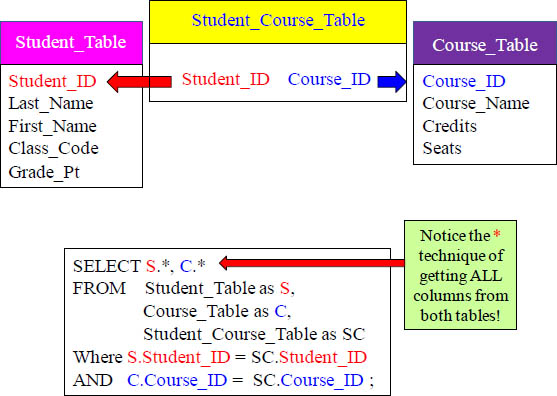
The Associative Table is a bridge between the Course_Table and Student_Table, and its sole purpose is to join these two tables together.
Quiz – Can you Write the 3-Table Join to ANSI Syntax?

SELECT S.*, C.*
FROM Student_Table as S,
Course_Table as C,
Student_Course_Table as SC
Where S.Student_ID = SC.Student_ID
AND C.Course_ID = SC.Course_ID ;
Convert this query to ANSI syntax
Please re-write the above query using ANSI Syntax.
Answer – Can you Write the 3-Table Join to ANSI Syntax?
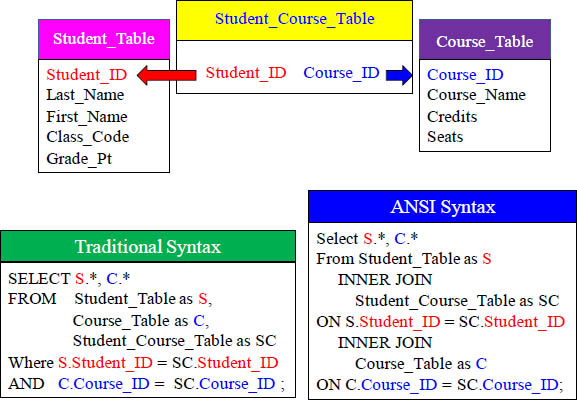
The above queries show both traditional and ANSI form for this three table join.
Quiz – Can you Place the ON Clauses at the End?
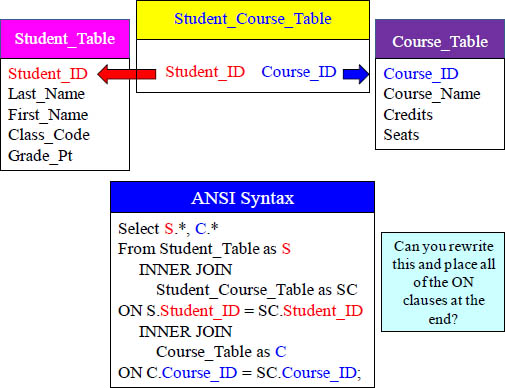
Please re-write the above query and place both ON Clauses at the end.
Answer – Can you Place the ON Clauses at the End?
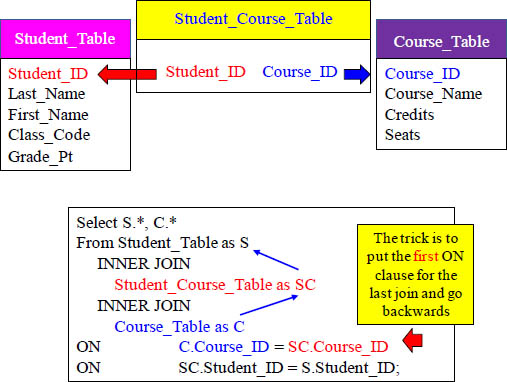
This is tricky. The only way it works is to place the ON clauses backwards. The first ON Clause represents the last INNER JOIN and then moves backwards.
The 5-Table Join – Logical Insurance Model
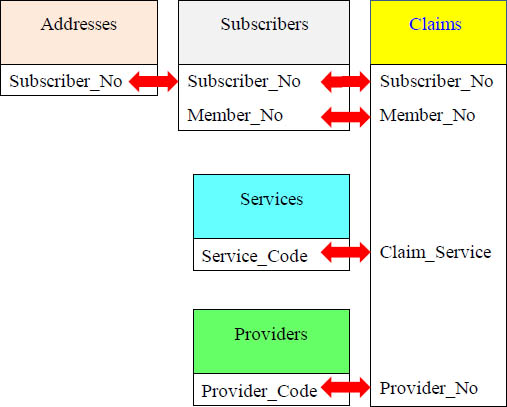
Above is the logical model for the insurance tables showing the Primary Key and Foreign Key relationships (PK/FK).
Quiz - Write a Five Table Join Using ANSI Syntax
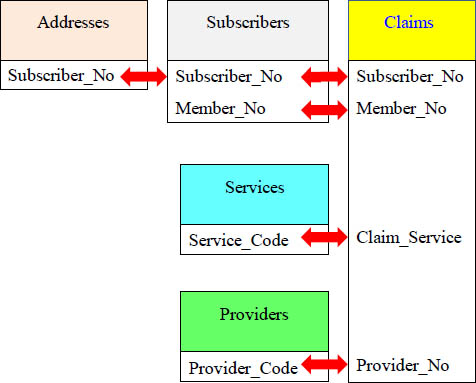
Your mission is to write a five table join selecting all columns using ANSI syntax.
Answer - Write a Five Table Join Using ANSI Syntax
SELECT
cla1.*, sub1.*, add1.* ,pro1.*, ser1.*
FROM CLAIMS AS cla1
INNER JOIN
SUBSCRIBERS AS sub1
ON cla1.Subscriber_No = sub1.Subscriber_No
AND cla1.Member_No = sub1.Member_No
INNER JOIN
ADDRESSES AS add1
ON sub1.Subscriber_No = add1.Subscriber_No
INNER JOIN
PROVIDERS AS pro1
ON cla1.Provider_No = pro1.Provider_Code
INNER JOIN
SERVICES AS ser1
ON cla1.Claim_Service = ser1.Service_Code ;
Above is the example writing this five table join using ANSI syntax.
Quiz - Write a Five Table Join Using Non-ANSI Syntax
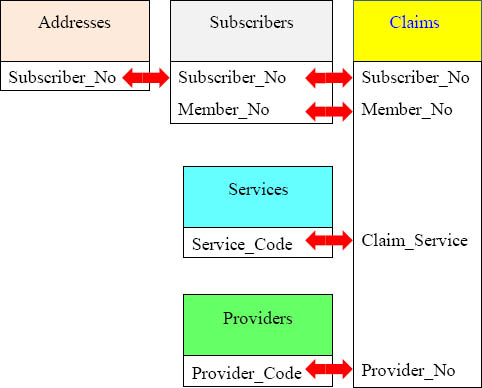
Your mission is to write a five table join selecting all columns using Non-ANSI syntax.
Answer - Write a Five Table Join Using Non-ANSI Syntax
SELECT cla1.*, sub1.*, add1.* ,pro1.*, ser1.*
FROM CLAIMS AS cla1,
SUBSCRIBERS AS sub1,
ADDRESSES AS add1,
PROVIDERS AS pro1,
SERVICES AS ser1
WHERE cla1.Subscriber_No = sub1.Subscriber_No
AND cla1.Member_No = sub1.Member_No
AND sub1.Subscriber_No = add1.Subscriber_No
AND cla1.Provider_No = pro1.Provider_Code
AND cla1.Claim_Service = ser1.Service_Code ;
Above is the example writing this five table join using Non-ANSI syntax.
Quiz –Re-Write this putting the ON clauses at the END
SELECT
cla1.*, sub1.*, add1.* ,pro1.*, ser1.*
FROM CLAIMS AS cla1
INNER JOIN
SUBSCRIBERS AS sub1
ON cla1.Subscriber_No = sub1.Subscriber_No
AND cla1.Member_No = sub1.Member_No
INNER JOIN
ADDRESSES AS add1
ON sub1.Subscriber_No = add1.Subscriber_No
INNER JOIN
PROVIDERS AS pro1
ON cla1.Provider_No = pro1.Provider_Code
INNER JOIN
SERVICES AS ser1
ON cla1.Claim_Service = ser1.Service_Code ;
Above is the example writing this five table join using Non-ANSI syntax.
Answer –Re-Write this putting the ON clauses at the END

Above is the example writing this five table join using ANSI syntax with the ON clauses at the end. We had to move the tables around also to make this happen. Notice that the first ON clause represents the last two tables being joined, and then it works backwards.
The Nexus Query Chameleon Writes the SQL for Users.
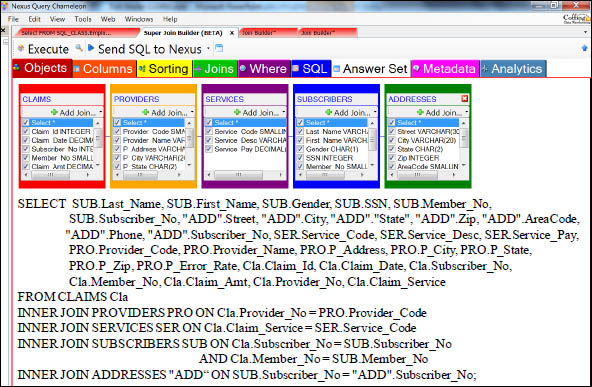
Let Nexus show users the table relationships and then let Nexus build the SQL. Just load the ERwin logical model inside Nexus and then all users can point and click.