
14 Transactions
I think I am motivated mostly by dread, by fear of a miserable life. Certainly I am troubled by worries of obsolescence, of incompetence, of unemployability. I would probably be happier if I were motivated by positives, by goals to be attained and rewards to be enjoyed.—Thomas L. Holaday
An in-depth discussion of transaction management is outside the scope of this book. There are a number of books out there that cover the internals of SQL Server transaction management in detail. The Books Online is also a good source of information for exploring the mechanics of SQL Server transactions.
SQL Server’s transaction management facilities help ensure the integrity and recoverability of the data stored in its databases. A transaction is a set of one or more database operations that are treated as a single unit—either they all occur or none of them do. As such, a transaction is a database’s basic operational metric—its fundamental unit of work.
SQL Server transactions ensure data recoverability and consistency in spite of any hardware, operating system, application, or SQL Server errors that may occur. They ensure that multiple commands performed within a transaction are performed either completely or not at all and that a single command that alters multiple rows changes either all of them or none of them.
SQL Server transactions are often described as having the ACID properties or “passing the ACID test,” where ACID is an acronym for atomic, consistent, isolated, and durable. Transactional adherence to the ACID tenets is commonplace in modern DBMSs and is a prerequisite for ensuring the safety and reliability of data.
A transaction is atomic if it’s an all-or-nothing proposition. When the transaction succeeds, all of its changes are stored permanently; when it fails, they’re completely reversed. So, for example, if a transaction includes ten DELETE commands and the last one fails, rolling back the transaction will reverse the previous nine. Likewise, if a single command attempts ten row deletions and one of them fails, the entire operation fails.
A transaction is consistent if it ensures that its underlying data never appears in an interim or illogical state—that is, if it never appears to be inconsistent. So, the data affected by an UPDATE command that changes ten rows will never appear to the outside world in an intermediate state—all rows will appear in either their initial state or their final state. This prevents one user from inadvertently interfering with another user’s work in progress. Consistency is usually implied by the other ACID properties.
A transaction is isolated if it is not affected by, nor affects, other concurrent transactions on the same data. The extent to which a transaction is isolated from other transactions is controlled by its transaction isolation level (specified via the SET TRANSACTION ISOLATION LEVEL command). These TILs range from no isolation at all—during which transactions can read uncommitted data and cannot exclusively lock resources—to serializable isolation—which locks the entire data set and prevents users from modifying it in any way until the transaction completes. (See the following section, “Transaction Isolation Levels,” for more information.) The trade-off with each isolation level is one of concurrency (concurrent access and modification of a data set by multiple users) vs. consistency. The more airtight the isolation, the higher the degree of data consistency. The higher the consistency, the lower the concurrency. This is because SQL Server locks resources to ensure data consistency. More locks means fewer simultaneous data modifications and reduced accessibility overall.
Isolation prevents a transaction from retrieving illogical or incomplete snapshots of data currently under modification by another transaction. For example, if a transaction is inserting a number of rows into a table, isolation prevents other transactions from seeing those rows until the transaction is committed. SQL Server’s TILs allow you to balance your data accessibility needs with your data integrity requirements.
A transaction is considered durable if it can complete despite a system failure or, in the case of uncommitted transactions, if it can be completely reversed following a system failure. SQL Server’s write-ahead logging and the database recovery process ensure that transactions committed but not yet stored in the database are written to the database following a system failure (rolled forward) and that transactions in progress are reversed (rolled back).
SQL Server transactions are similar to command batches in that they usually consist of multiple Transact-SQL statements that are executed as a group. They differ in that a command batch is a client-side concept—it’s a mechanism for sending groups of commands to the server—while a transaction is a server-side concept—it controls what SQL Server considers completed and in-progress work.
There’s a many-to-many relationship between command batches and transactions. Command batches can contain multiple transactions, and a single transaction can span multiple batches. As a rule, you want to avoid transactions that span lengthy command batches because of the concurrency and performance problems that such transactions can cause.
Any time a data modification occurs, SQL Server writes a record of the change to the transaction log. This occurs before the change itself is performed and is the reason SQL Server is described as having a “write-ahead” log—log records are written ahead of their corresponding data changes. Failing to do this could result in data changes that would not be rolled back if the server failed before the log record was written.
Modifications are never made directly to disk. Instead, SQL Server reads data pages into a buffer area as they’re needed and changes them in memory. Before it changes a page in memory, the server ensures that the change is recorded in the transaction log. Since the transaction log is also cached, these changes are initially made in memory as well. Write-ahead logging ensures that the lazywriter process does not write modified data pages ("dirty" pages) to disk before their corresponding log records.
No permanent changes are made to a database until a transaction is committed. The exact timing of this varies based on the type of transaction. Once a transaction is committed, its changes are written to the database and cannot be rolled back.
Regardless of whether an operation is logged or nonlogged, terminating it before it’s been committed results in the operation being rolled back completely. This is possible with nonlogged operations because page allocations are recorded in the transaction log.
SQL Server supports four basic types of transactions: automatic, implicit, user-defined, and distributed. Each has its own nuances, so I’ll discuss each one separately.
By default, each Transact-SQL command is its own transaction. These are known as automatic (or autocommit) transactions. They are begun and committed by the server automatically. A DML command that’s executed outside a transaction (and while implicit transactions are disabled) is an example of an automatic transaction. You can think of an automatic transaction as a Transact-SQL statement that’s ensconced between a BEGIN TRAN and a COMMIT TRAN. If the statement succeeds, it’s committed. If not, it’s rolled back.
Implicit transactions are ANSI SQL-92–compliant automatic transactions. They’re initiated automatically when any of numerous DDL or DML commands is executed. They continue until explicitly committed by the user. To toggle implicit transaction support, use the SET IMPLICIT_TRANSACTIONS command. By default, OLEDB and ODBC connections enable the ANSI_DEFAULTS switch, which, in turn, enables implicit transactions. However, they then immediately disable implicit transactions because of the grief mismanaged transactions can cause applications. Enabling implicit transactions is like rigging your car doors to lock automatically every time you shut them. It costs more time than it saves, and, sooner or later, you’re going to leave your keys in the ignition.
User-defined transactions are the chief means of managing transactions in SQL Server applications. A user-defined transaction is user-defined in that you control when it begins and when it ends. The BEGIN TRAN, COMMIT TRAN, and ROLLBACK TRAN commands are used to control user-defined transactions. Here’s an example:
SELECT TOP 5 title_id, stor_id FROM sales ORDER BY title_id, stor_id
BEGIN TRAN
DELETE sales
SELECT TOP 5 title_id, stor_id FROM sales ORDER BY title_id, stor_id
GO
ROLLBACK TRAN
SELECT TOP 5 title_id, stor_id FROM sales ORDER BY title_id, stor_id
title_id stor_id
-------- -------
BU1032 6380
BU1032 8042
BU1032 8042
BU1111 8042
BU2075 7896
(5 row(s) affected)
(25 row(s) affected)
title_id stor_id
-------- -------
(0 row(s) affected)
title_id stor_id
-------- -------
BU1032 6380
BU1032 8042
BU1032 8042
BU1111 8042
BU2075 7896
(5 row(s) affected)
Transactions that span multiple servers are known as distributed transactions. These transactions are administered by a central manager application that coordinates the activities of the involved servers. SQL Server can participate in distributed transactions coordinated by manager applications that support the X/Open XA specification for Distributed Transaction Processing, such as the Microsoft Distributed Transaction Coordinator (DTC). You can initiate a distributed transaction in Transact-SQL using the BEGIN DISTRIBUTED TRANSACTION command.
Other than avoiding making database modifications, there’s really no way to disable transaction logging completely. Some operations generate a minimum of log information, but there’s no configuration option that turns off logging altogether.
The BULK INSERT, TRUNCATE TABLE, SELECT...INTO, and WRITETEXT/ UPDATETEXT commands minimize transaction logging by causing only page operations to be logged (BULK INSERT can, depending on the circumstances, create regular detail log records). Contrary to a popular misconception, these operations are logged—it’s just that they don’t generate detail transaction log information. That’s why the Books Online refers to them as nonlogged operations—they’re nonlogged in that they don’t generate row-level log records.
Nonlogged operations tend to be much faster than fully logged operations. And since they generate page allocation log records, they can be rolled back (but not forward) just like other operations. The price you pay for using them is transaction log recovery. Once you’ve executed a nonlogged command in a database, you can no longer back up the database’s transaction log—you must perform a full or differential database backup instead.
One obvious way of avoiding logging as well as resource blocks and deadlocks in a database is by making the database read-only. Naturally, if the database can’t be changed, there’s no need for transaction logging or resource blocks. Making the database single-user even alleviates the need for read locks, avoiding the possibility of an application blocking itself.
Though reducing a database’s accessibility in order to minimize transaction management issues might sound a little like not driving your car in order to keep it from breaking down, you sometimes see this in real applications. For example, it’s fairly common for DSS (Decision Support System) applications to make use of read-only databases. These databases can be updated off-hours (e.g., overnight or on weekends), then returned to read-only status for use during normal working hours. Obviously, transaction management issues are greatly simplified when a database is modifiable only by one user at a time, is changed only en masse, or can’t be changed at all.
Read-only databases can also be very functional as members of partitioned data banks. Sometimes an application can be spread across multiple databases—one containing static data that doesn’t change much (and can therefore be set to read-only) and one containing more dynamic data that must submit to at least nominal transaction management.
SQL Server provides a number of facilities for automating transaction management. The most prominent example of these is the automatic transaction (autocommit) facility. As mentioned earlier, an automatic transaction is begun and committed or rolled back implicitly by the server. There’s no need for explicit BEGIN TRAN or COMMIT/ ROLLBACK TRAN statements. The server initiates a transaction when a modification command begins and, depending on the command’s success, commits or rolls it back afterward. Automatic transaction mode is SQL Server’s default mode but is disabled when implicit or user-defined transactions are enabled.
Implicit transactions offer another type of automated transaction management. Whenever certain commands (ALTER TABLE, FETCH, REVOKE, CREATE, GRANT, SELECT, DELETE, INSERT, TRUNCATE TABLE, DROP, OPEN, UPDATE) are executed, a transaction is automatically started. In a sense, implicit transactions offer an automated alternative to explicit transactions—a facility falling somewhere between autocommit transactions and user-defined transactions in terms of functionality. These transactions are only semiautomated, though, since an explicit ROLLBACK TRAN or COMMIT TRAN is required to close them. Only the first part of the process is automated—the initiation of the transaction. Its termination must still be performed explicitly. Transact-SQL’s SET IMPLICIT_TRANSACTIONS command is used to toggle implicit transaction mode.
SET XACT_ABORT toggles whether a transaction is aborted when a command raises a runtime error. The error can be a system-generated error condition or a user-generated one. It’s essentially equivalent to checking @@ERROR after every statement and rolling back the transaction if an error is detected. Note that the command is a bit of misnomer. When XACT_ABORT is enabled and a runtime error occurs, not only is the current transaction aborted, but the entire batch is as well. For example, consider this code:
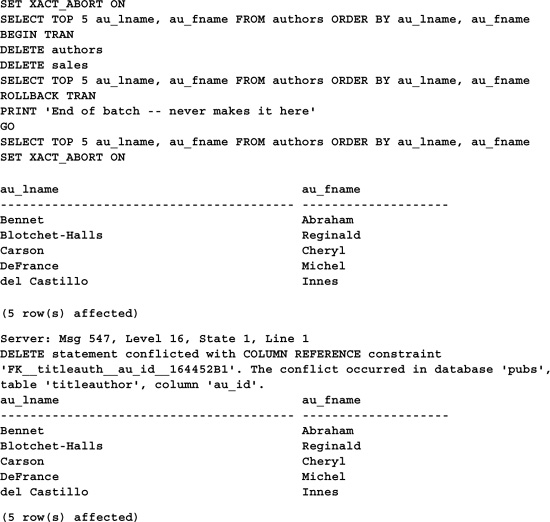
Execution never reaches the PRINT statement because the constraint violation generated by attempting to empty the authors table aborts the entire command batch (the statements before the GO). This is in spite of the fact that a ROLLBACK TRAN immediately precedes the PRINT.
The fact that the entire command batch is aborted is what makes checking @@ERROR after each data modification preferable to enabling SET XACT_ABORT. This is particularly true when calling a stored procedure within a transaction. If the procedure causes a runtime error, the statements following it in the command batch are aborted, affording no opportunity to handle the error condition.
SQL Server supports four transaction isolation levels. As mentioned earlier, a transaction’s isolation level controls how it affects, and is affected by, other transactions. The trade-off is always one of data consistency vs. concurrency. Selecting a more restrictive TIL increases data consistency at the expense of accessibility. Selecting a less restrictive TIL increases concurrency at the expense of data consistency. The trick is to balance these opposing interests so that the needs of your application are met.
Use the SET TRANSACTION ISOLATION LEVEL command to set a transaction’s isolation level. Valid TILs include READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, and SERIALIZABLE.
Specifying READ UNCOMMITTED is essentially the same as using the NOLOCK hint with every table referenced in a transaction. It is the least restrictive of SQL Server’s four TILs. It permits dirty reads (reads of uncommitted changes by other transactions) and nonrepeatable reads (data that changes between reads during a transaction). To see how READ UNCOMMITTED permits dirty and nonrepeatable reads, run the following queries simultaneously:

While the first query is running (you have five seconds), fire off the second one, and you’ll see that it’s able to access the uncommitted data modifications of the first query. It then waits for the first transaction to finish and attempts to read the same data again. Since the modifications were rolled back, the data has vanished, leaving the second query with a nonrepeatable read.
READ COMMITTED is SQL Server’s default TIL, so if you don’t specify otherwise, you’ll get READ COMMITTED. READ COMMITTED avoids dirty reads by initiating share locks on accessed data but permits changes to underlying data during the transaction, possibly resulting in nonrepeatable reads and/or phantom data. To see how this works, run the following queries simultaneously:

As in the previous example, start the first query, then quickly run the second one simultaneously (you have five seconds).
In this example, the value of the qty column in the first row of the sales table changes between reads during the first query—a classic nonrepeatable read.
REPEATABLE READ initiates locks to prevent other users from changing the data a transaction accesses but doesn’t prevent new rows from being inserted, possibly resulting in phantom rows appearing between reads during the transaction. Here’s an example (as with the other examples, start the first query; then run the second one simultaneously—you have five seconds to start the second query):
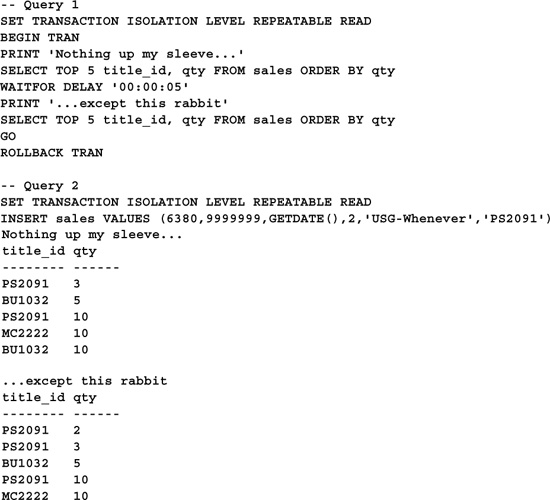
As you can see, a new row appears between the first and second reads of the sales table, even though REPEATABLE READ has been specified. Though REPEATABLE READ prevents changes to data it has already accessed, it doesn’t prevent the addition of new data, thus introducing the possibility of phantom rows.
SERIALIZABLE prevents dirty reads and phantom rows by placing a range lock on the data it accesses. It is the most restrictive of SQL Server’s four TILs. It’s equivalent to using the HOLDLOCK hint with every table a transaction references. Here’s an example (delete the row you added in the previous example before running this code):
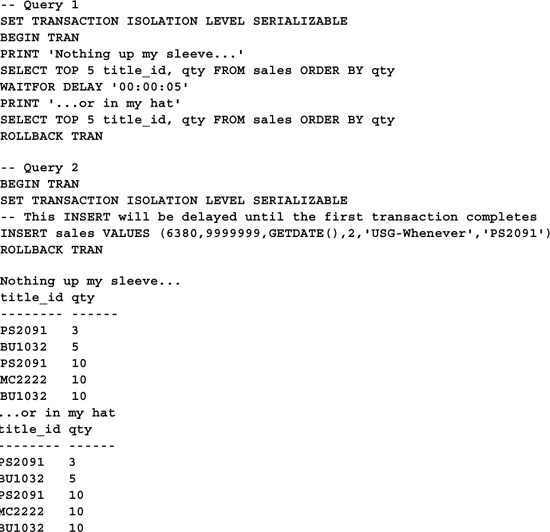
In this example, the locks initiated by the SERIALIZABLE isolation level prevent the second query from running until after the first one finishes. While this provides airtight data consistency, it does so at a cost of greatly reduced concurrency.
As I said earlier, the BEGIN TRAN, COMMIT TRAN, and ROLLBACK TRAN commands are used to manage transactions in Transact-SQL (the sp_xxxx_xact system stored procedures are legacy code that was used in the past with DB-Library two-phase commit applications, and you should not use them). The exact syntax used to begin a transaction is:
BEGIN TRAN[SACTION] [name|@TranNameVar]
To commit a transaction, use:
COMMIT TRAN[SACTION] [name|@TranNameVar]
And to roll back a transaction, use:
ROLLBACK TRAN[SACTION] [name|@TranNameVar]
You can also use the COMMIT WORK and ROLLBACK WORK commands in lieu of COMMIT TRANSACTION and ROLLBACK TRANSACTION, though you cannot use transaction names with them.
Transact-SQL allows you to nest transaction operations by issuing nested BEGIN TRAN commands. The @@TRANCOUNT automatic variable can be queried to determine the level of nesting—0 indicates no nesting, 1 indicates nesting one level deep, and so forth. Batches and stored procedures that are nesting sensitive should query @@TRANCOUNT when first executed and respond accordingly.
Though on the surface it appears otherwise, SQL Server doesn’t support truly nested transactions. A COMMIT issued against any transaction except the outermost one doesn’t commit any changes to disk—it merely decrements the @@TRANCOUNT automatic variable. A ROLLBACK, on the other hand, works regardless of the level at which it is issued but rolls back all transactions, regardless of the nesting level. Though this is counterintuitive, there’s a very good reason for it. If a nested COMMIT actually wrote changes permanently to disk, an outer ROLLBACK wouldn’t be able to reverse those changes since they would already be recorded permanently. Likewise, if ROLLBACK didn’t reverse all changes at all levels, calling it from within stored procedures and triggers would be vastly more complicated since the caller would have to check return values and the transaction nesting level when the routine returned in order to determine whether it needed to roll back pending transactions. Here’s an example that illustrates some of the nuances of nested transactions:
SELECT 'Before BEGIN TRAN',@@TRANCOUNT
BEGIN TRAN
SELECT 'After BEGIN TRAN',@@TRANCOUNT
DELETE sales
BEGIN TRAN nested
SELECT 'After BEGIN TRAN nested',@@TRANCOUNT
DELETE titleauthor
COMMIT TRAN nested -- Does nothing except decrement @@TRANCOUNT
SELECT 'After COMMIT TRAN nested',@@TRANCOUNT
GO -- When possible, it’s a good idea to place ROLLBACK TRAN in a separate batch
-- to prevent batch errors from leaving open transactions
ROLLBACK TRAN
SELECT 'After ROLLBACK TRAN',@@TRANCOUNT
SELECT TOP 5 au_id FROM titleauthor
---------------------------- ----------
Before BEGIN TRAN 0
--------------------------- ----------
After BEGIN TRAN 1
-------------------------------------- ----------
After BEGIN TRAN nested 2
----------------------------------------- ----------
After COMMIT TRAN nested 1
---------------------------------- ----------
After ROLLBACK TRAN 0
au_id
----------------
213-46-8915
409-56-7008
267-41-2394
724-80-9391
213-46-8915
In this example, we see that despite the nested COMMIT TRAN, the outer ROLLBACK still reverses the effects of the DELETE titleauthor command. Here’s another nested transaction example:
SELECT 'Before BEGIN TRAN',@@TRANCOUNT
BEGIN TRAN
SELECT 'After BEGIN TRAN',@@TRANCOUNT
DELETE sales
BEGIN TRAN nested
SELECT 'After BEGIN TRAN nested',@@TRANCOUNT
DELETE titleauthor
ROLLBACK TRAN
SELECT 'After ROLLBACK TRAN',@@TRANCOUNT
IF @@TRANCOUNT>0 BEGIN
COMMIT TRAN -- Never makes it here because of the ROLLBACK
SELECT 'After COMMIT TRAN',@@TRANCOUNT
END
SELECT TOP 5 au_id FROM titleauthor
---------------------------- ----------
Before BEGIN TRAN 0
--------------------------- ----------
After BEGIN TRAN 1
------------------------------------ ----------
After BEGIN TRAN nested 2
--------------------------------- ----------
After ROLLBACK TRAN 0
au_id
---------------
213-46-8915
409-56-7008
267-41-2394
724-80-9391
213-46-8915
In this example, execution never reaches the outer COMMIT TRAN because the ROLLBACK TRAN reverses all transactions currently in progress and sets @@TRANCOUNT to zero.
Note that we can’t ROLLBACK the nested transaction. ROLLBACK can reverse a named transaction only when it’s the outermost transaction. Attempting to roll back our nested transaction yields the message:
Server: Msg 6401, Level 16, State 1, Line 10
Cannot roll back nested. No transaction or savepoint of that name was found.
The error message notwithstanding, the problem isn’t that no transaction exists with the specified name. It’s that ROLLBACK can reference a transaction by name only when it is also the outermost transaction. Here’s an example that illustrates using ROLLBACK TRAN with transaction names:
SELECT 'Before BEGIN TRAN main',@@TRANCOUNT
BEGIN TRAN main
SELECT 'After BEGIN TRAN main',@@TRANCOUNT
DELETE sales
BEGIN TRAN nested
SELECT 'After BEGIN TRAN nested',@@TRANCOUNT
DELETE titleauthor
ROLLBACK TRAN main
SELECT 'After ROLLBACK TRAN main',@@TRANCOUNT
IF @@TRANCOUNT>0 BEGIN
ROLLBACK TRAN -- Never makes it here because of the earlier ROLLBACK
SELECT 'After ROLLBACK TRAN',@@TRANCOUNT
END
SELECT TOP 5 au_id FROM titleauthor
----------------------------------- ----------
Before BEGIN TRAN main 0
--------------------------------- ----------
After BEGIN TRAN main 1
------------------------------------- ----------
After BEGIN TRAN nested 2
----------------------------------------- ----------
After ROLLBACK TRAN main 0
au_id
---------------
213-46-8915
409-56-7008
267-41-2394
724-80-9391
213-46-8915
Here, we named the outermost transaction “main” and then referenced it by name with ROLLBACK TRAN. Note that a transaction name is never required by ROLLBACK TRAN, regardless of whether the transaction is initiated with a name. For this reason, many developers avoid using transaction names with ROLLBACK altogether, since they serve no real purpose. This is largely a matter of personal choice and works acceptably well either way as long as you understand it. Unless called with a save point (see below), ROLLBACK TRAN always rolls back all transactions and sets @@TRANCOUNT to zero, regardless of the context in which it’s called.
You can control how much work ROLLBACK reverses via the SAVE TRAN command. SAVE TRAN creates a save point to which you can roll back if you wish. Syntactically, you just pass the name of the save point to the ROLLBACK TRAN command. Here’s an example:
SELECT 'Before BEGIN TRAN main',@@TRANCOUNT
BEGIN TRAN main
SELECT 'After BEGIN TRAN main',@@TRANCOUNT
DELETE sales
SAVE TRAN sales -- Mark a save point
SELECT 'After SAVE TRAN sales',@@TRANCOUNT -- @@TRANCOUNT is unchanged
BEGIN TRAN nested
SELECT 'After BEGIN TRAN nested',@@TRANCOUNT
DELETE titleauthor
SAVE TRAN titleauthor -- Mark a save point
SELECT 'After SAVE TRAN titleauthor',@@TRANCOUNT -- @@TRANCOUNT is unchanged
ROLLBACK TRAN sales
SELECT 'After ROLLBACK TRAN sales',@@TRANCOUNT -- @@TRANCOUNT is unchanged
SELECT TOP 5 au_id FROM titleauthor
IF @@TRANCOUNT>0 BEGIN
ROLLBACK TRAN
SELECT 'After ROLLBACK TRAN',@@TRANCOUNT
END
SELECT TOP 5 au_id FROM titleauthor
---------------------------------- ------
Before BEGIN TRAN main 0
--------------------------------- -----
After BEGIN TRAN main 1
--------------------------------- -----
After SAVE TRAN sales 1
------------------------------------ ----
After BEGIN TRAN nested 2
----------------------------------------- ----------
After SAVE TRAN titleauthor 2
----------------------------------------- ----------
After ROLLBACK TRAN sales 2
au_id
----------------
213-46-8915
409-56-7008
267-41-2394
724-80-9391
213-46-8915
--------------------------------- ----------
After ROLLBACK TRAN 0
au_id
---------------
213-46-8915
409-56-7008
267-41-2394
724-80-9391
213-46-8915
As with version 6.5, SQL Server 7.0 allows you to reuse a save point name if you wish, but if you do so, only the last save point is retained. Rolling back using the save point name will roll the transaction back to the save point’s last reference.
Since ROLLBACK TRAN reverses all transactions in progress, it’s important not to inadvertently nest calls to it. Once it’s been called a single time, there’s no need (nor are you allowed) to call it again until a new transaction is initiated. For example, consider this code:
SELECT 'Before BEGIN TRAN',@@TRANCOUNT
BEGIN TRAN
SELECT 'After BEGIN TRAN',@@TRANCOUNT
DELETE sales
BEGIN TRAN nested
SELECT 'After BEGIN TRAN nested',@@TRANCOUNT
DELETE titleauthor
IF @@ROWCOUNT > 1000
COMMIT TRAN nested
ELSE BEGIN
ROLLBACK TRAN -- Completely rolls back both transactions
SELECT 'After ROLLBACK TRAN',@@TRANCOUNT
END
SELECT TOP 5 au_id FROM titleauthor
ROLLBACK TRAN -- This is an error -- there’s no transaction to rollback
SELECT 'After ROLLBACK TRAN',@@TRANCOUNT
SELECT TOP 5 au_id FROM titleauthor
---------------------------- ------------
Before BEGIN TRAN 0
--------------------------- --------
After BEGIN TRAN 1
------------------------------------- ----------
After BEGIN TRAN nested 2
---------------------------------- ----------
After ROLLBACK TRAN 0
au_id
----------------
213-46-8915
409-56-7008
267-41-2394
724-80-9391
213-46-8915
Server: Msg 3903, Level 16, State 1, Line 17
The ROLLBACK TRANSACTION request has no corresponding BEGIN TRANSACTION.
---------------------------------- ----------
After ROLLBACK TRAN 0
au_id
----------------
213-46-8915
409-56-7008
267-41-2394
724-80-9391
213-46-8915
Note the error message that’s generated by the second ROLLBACK TRAN. Since the first ROLLBACK TRAN reverses both transactions, there’s no transaction for the second to reverse. This situation is best handled by querying @@TRANCOUNT first, like this:
Some normally valid Transact-SQL syntax is prohibited while a transaction is active. For example, you can’t use sp_dboption to change database options or call any other stored procedure that modifies the master database from within a transaction. Also, a number of Transact-SQL commands are illegal inside transactions: ALTER DATABASE, DROP DATABASE, RECONFIGURE, BACKUP LOG, DUMP TRANSACTION, RESTORE DATABASE, CREATE DATABASE, LOAD DATABASE, RESTORE LOG, DISK INIT, LOAD TRANSACTION, and UPDATE STATISTICS.
Two DBCC (database consistency checker) commands come in very handy when debugging transaction-related problems. The first is DBCC OPENTRAN(). It allows you to retrieve the oldest active transaction in a database. Since only the inactive portion of a log is backed up and truncated, a malevolent or zombie transaction can cause the log to fill prematurely. You can use DBCC OPENTRAN()to identify the offending process so that it may be terminated if necessary. Here’s an example:
DBCC OPENTRAN(pubs)
Transaction information for database 'pubs'.
Oldest active transaction:
SPID (server process ID) : 15
UID (user ID) : 1
Name : user_transaction
LSN : (57:376:596)
Start time : Aug 5 1999 5:54:46:713AM
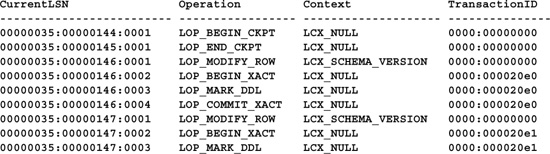
Another handy command for tracking down transaction-related problems is the DBCC LOG command. DBCC LOG lists the database transaction log. You can use it to look under the hood and see what operations are being carried out on your data. Here’s an example:
CREATE TABLE #logrecs
(CurrentLSN varchar(30),
Operation varchar(20),
Context varchar(20),
TransactionID varchar(20))
INSERT #logrecs
EXEC(’DBCC LOG(''pubs'')')
SELECT * FROM #logrecs
GO
DROP TABLE #logrecs
No discussion of SQL Server transaction debugging would be complete without mentioning the @@TRANCOUNT automatic variable. Though we’ve already covered it elsewhere in this chapter, @@TRANCOUNT is a frequent target of PRINT statements and debugger watches because it reports the current transaction nesting level. When debugging complex nested transactions, it’s common to insert SELECT or PRINT statements throughout the code to determine the current nesting level at various procedural junctures.
Finally, don’t forget about the Windows NT Performance Monitor. It sports numerous objects and counters related to transaction management and performance. In particular, the SQL Server:Databases object provides a wealth of transaction- and transaction log–related counters.
There are a number of general guidelines for writing efficient transaction-oriented T-SQL. Here are a few of them:
• Keep transactions as short as possible. Once you’ve determined what data modifications need to be made, initiate your transaction, perform those modifications, and then end the transaction as soon as possible. Try not to initiate transactions prematurely.
• Limit transactions to data modification statements when practical. Don’t initiate a transaction while scanning data if you can avoid it. Though transactions certainly affect reading data as well as writing it (e.g., dirty and nonrepeatable reads, phantom rows, etc.), it’s often possible to limit them to just those statements that modify data, especially if you do not need to reread data within a transaction.
• Don’t require user input during a transaction. Doing so could allow a slow user to tie up server resources indefinitely. It could also cause the transaction log to fill prematurely since active transactions cannot be cleared from it.
• Try to use optimistic concurrency control when possible. That is, rather than explicitly locking every object your application may change, allow the server to determine when a row has been changed by another user. You may find that this occurs so little in practice (perhaps the app is naturally partitioned, or, once entered, rows are rarely updated, etc.) as to be worth the risk in order to improve concurrency.
• Use nonlogged operations wisely. As I’ve pointed out, nonlogged operations preclude normal transaction log backups. This may or may not be a showstopper, but, when allowable, nonlogged operations can turbocharge an application. They can often reduce processing time for large amounts of data by orders of magnitude and virtually eliminate a number of common transaction management headaches. Keep in mind that this increase in performance sometimes comes at a cost. SELECT...INTO, for example, locks system tables until it completes.
• Try to use lower (less restrictive) TILs when possible. READ COMMITTED, the default, is suitable for most applications and will provide better concurrency than REPEATABLE READ or SERIALIZABLE.
• Attempt to keep the amount of data you change within a transaction to a minimum. Don’t indiscriminately attempt to change millions of rows in a table and expect concurrency and resource utilization to take care of themselves magically. Database modifications require resources and locks, and these locks by definition affect other users. Unless your app is a single-user app, it pays to be mindful of operations that could negatively affect concurrency.
• Don’t use implicit transactions unless you really need them, and, even then, watch them very closely. Because implicit transactions are initiated by nearly any primary Transact-SQL command (including SELECT), they can be started when you least expect them, potentially lowering concurrency and causing transaction log problems. It’s nearly always better to manage transactions explicitly with BEGIN TRAN, COMMIT TRAN, and ROLLBACK TRAN than to use implicit transactions. When you manage transactions yourself, you know exactly when they’re started and stopped—you have full control over what happens.
Transactions are SQL Server’s basic unit of work. They ensure that a data modification operation is carried out either completely or not at all. Atomicity, consistency, isolation, and durability—the so-called ACID properties—characterize SQL Server transactions and help guard your data against incomplete or lost updates.
The current transaction isolation level (TIL) governs transaction isolation. You set the TIL via the SET TRANSACTION ISOLATION LEVEL command. Each TIL represents a trade-off between concurrency and consistency.
In this chapter, you became acquainted with SQL Server transactions and explored the various Transact-SQL commands that relate to transaction management. You learned about auto-commit and implicit transactions, as well as user-defined and distributed transactions. You also explored some common transaction-related pitfalls, and you learned methods for avoiding them.