
12 Hierarchies
If you think education is expensive, try ignorance.—Derek Bok, former president of Harvard.
A hierarchy is special kind of data structure made up of nodes connected to one another via oneway relationships known as edges. These nodes exist at multiple levels and roughly resemble a tree—in fact, you’ll often hear the terms “hierarchy” and “tree” used interchangeably. Out of the box, Transact-SQL provides only meager support for hierarchies and trees. Other products such as Oracle have decent tree support, but Transact-SQL is strangely lacking here. This isn’t the limitation that it might seem, though, because there are a number of straightforward techniques that make displaying and manipulating hierarchies fairly simple in Transact-SQL.
There are a number of common programming problems that have to do with traversing and manipulating trees. The one that comes immediately to mind is the task of displaying an organizational chart based on a personnel table. Each employee occupies one row in the table and each row contains a pointer to the employee’s manager, which can itself be another row in the table. These types of hierarchies are usually established using just one database table.
By contrast, the Bill of Materials problem (which involves determining all the individual parts that make up an item) is usually a two-table problem. This is because, unlike an organizational chart, the node or leaf level members of a parts explosion can appear multiple times in a tree. For example, a given widget may be a component of several items within a BOM schematic. Using a second table keeps the database normalized and allows a part to appear more than once in the hierarchy.
If you’re interested only in one-level-deep hierarchies, the SQL needed to produce them is fairly straightforward. Here’s some code that lists a single-level organizational chart:
CREATE TABLE staff (employee int PRIMARY KEY, employee_name varchar(10),
supervisor int NULL REFERENCES staff (employee))
INSERT staff VALUES (1,'GROUCHO',1)
INSERT staff VALUES (2,'CHICO',1)

You could order these results a number of ways; the code above takes advantage of the fact that the rows were entered in the desired display order to sort them aesthetically.
A tree that’s only one level deep isn’t really a hierarchy at all. After all, the head pointy-haired boss at a company lords his authority over the entire staff, not just those who immediately report to him. A company’s organizational chart is normally several levels deep for a reason—everyone technically reports to everyone above her in the chart, not just to her immediate supervisor. Getting at this chain of command requires a more sophisticated approach than the simple one presented above. What we need to do is somehow iterate through the base table, collecting not only each employee’s boss but also his boss’s boss, and her boss’s boss, and so on, all the way up to the CEO. Here’s a query that does just that:


This query constructs a temporary table containing the path between every supervisor and every employee under him or her. It does this by requiring that you execute a separate INSERT statement for each level you want to include. Naturally, this requires that you know how many levels your hierarchy has in advance—not an optimal solution. Here’s a better one:
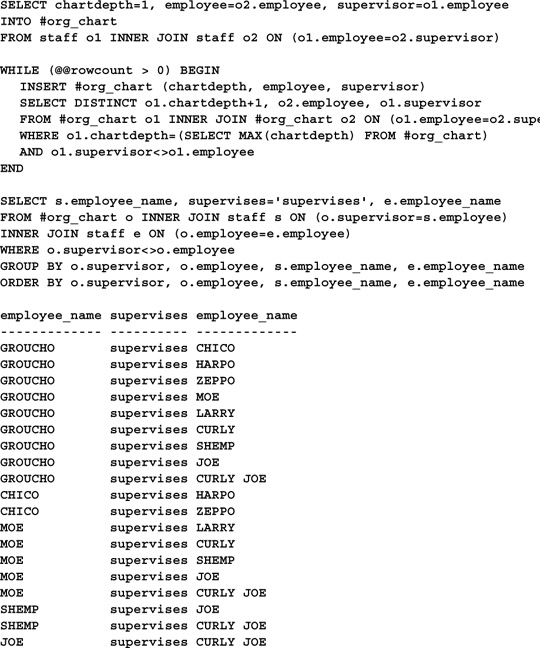
This approach uses a WHILE loop to repeat the INSERT as many times as necessary to process all levels. It works for any number of levels and doesn’t require that you know how many you have in advance.
Like the first query, this approach uses the fact that the employee records were inserted in the desired order to sort them logically. This might not always be possible. The CEO may be employee number 340—obviously you can’t depend on employees being added to the database in order of job level. Here’s a variation on the preceding routine that doesn’t make any assumptions about the initial row insertion order:
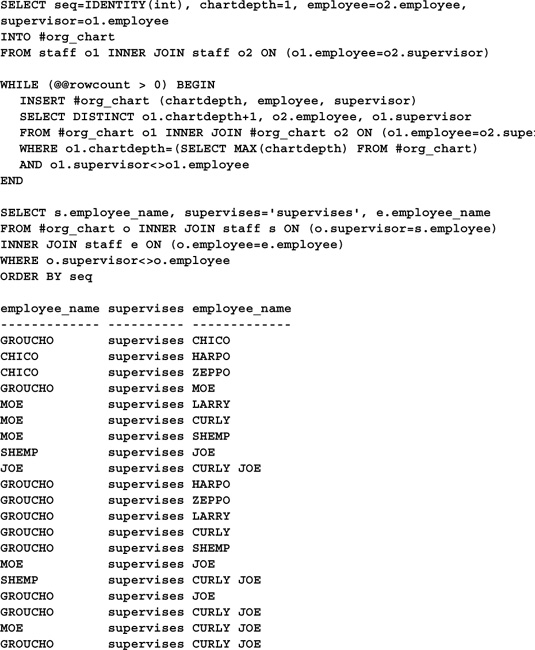
This approach uses the IDENTITY() function with SELECT...INTO to add an identity column to the work table. It then uses this column to sort the result set when returning it.
A common need with hierarchies is to indent them according to level. Since the previous routine already tracks the chart level of each row, indenting the result set is simple. Here’s a variation of the earlier query that indents the result set by level:
SELECT seq=IDENTITY(int),
chartdepth=CASE WHEN o2.employee=o2.supervisor THEN 0 ELSE 1 END,
employee=o2.employee,
supervisor=o1.employee
INTO #org_chart
FROM staff o1 INNER JOIN staff o2 ON (o1.employee=o2.supervisor)
WHILE (@@rowcount > 0) BEGIN
INSERT #org_chart (chartdepth, employee, supervisor)
SELECT DISTINCT o1.chartdepth+1, o2.employee, o1.supervisor
FROM #org_chart o1 INNER JOIN #org_chart o2 ON (o1.employee=o2.supervisor)
WHERE o1.chartdepth=(SELECT MAX(chartdepth) FROM #org_chart)
AND o1.employee<>o1.supervisor
END
SELECT OrgChart=REPLICATE(CHAR(9),chartdepth)+s.employee_name
FROM (SELECT
employee,
seq=MIN(seq),
chartdepth=MAX(chartdepth)
FROM #org_chart
GROUP BY employee) o INNER JOIN staff s ON (o.employee=s.employee)
ORDER BY o.seq
OrgChart
--------------------------------------------------------------------------------
GROUCHO
CHICO
HARPO
ZEPPO
MOE
LARRY
CURLY
SHEMP
JOE
CURLY JOE
This technique uses the REPLICATE() function to generate a string of tab characters corresponding to the chartdepth of each row. It also uses a derived table and some aggregate tricks to remove duplicates from the result set before returning it. The derived table is necessary because we don’t want to have to encapsulate the references to the employee_name and chartdepth columns in aggregate functions in order to GROUP BY the employee column. We need to GROUP BY employee or employee_name in order to remove duplicates from the result set. If we include chartdepth in the GROUP BY clause, some of the duplicates remain, differentiated only by chartdepth.
As they say, there’s more than one way to skin a cat, and there’s certainly more than one way to expand a tree in Transact-SQL. Another way of doing so is to loop through the base table, processing each node separately and using a temporary table to track which nodes have been processed. Here’s a code sample that uses this technique to display a multilevel hierarchy:
CREATE TABLE DINOSAURS (OrderNo int PRIMARY KEY, OrderName varchar(30),
PredecessorNo int NULL REFERENCES DINOSAURS (OrderNo))
INSERT DINOSAURS VALUES (1,'Amphibia',1)
INSERT DINOSAURS VALUES (2,'Cotylosauri',1)
INSERT DINOSAURS VALUES (3,'Pelycosauria',2)
INSERT DINOSAURS VALUES (4,’Therapsida',2)
INSERT DINOSAURS VALUES (5,'Chelonia',3)
INSERT DINOSAURS VALUES (6,’Sauropterygia',3)
INSERT DINOSAURS VALUES (7,'Ichthyosauria',3)
INSERT DINOSAURS VALUES (8,’Squamata',3)
INSERT DINOSAURS VALUES (9,’Thecodontia',3)
INSERT DINOSAURS VALUES (10,'Crocodilia',9)
INSERT DINOSAURS VALUES (11,'Pterosauria',9)
INSERT DINOSAURS VALUES (12,’Saurichia',9)
INSERT DINOSAURS VALUES (13,'Ornithischia',9)
CREATE TABLE #work (lvl int, OrderNo int)
CREATE TABLE #DINOSAURS (seq int identity, lvl int, OrderNo int)
DECLARE @lvl int, @curr int
SELECT TOP 1 @lvl=1, @curr=OrderNo FROM DINOSAURS WHERE OrderNo=PredecessorNo
INSERT INTO #work (lvl, OrderNo) VALUES (@lvl, @curr)
WHILE (@lvl > 0) BEGIN
IF EXISTS(SELECT * FROM #work WHERE lvl=@lvl) BEGIN
SELECT TOP 1 @curr=OrderNo FROM #work
WHERE lvl=@lvl
INSERT #DINOSAURS (lvl, OrderNo) VALUES (@lvl, @curr)
DELETE #work
WHERE lvl=@lvl and OrderNo=@curr
INSERT #work
SELECT @lvl+1, OrderNo
FROM DINOSAURS
WHERE PredecessorNo=@curr
AND PredecessorNo <> OrderNo
IF (@@ROWCOUNT > 0) SET @lvl=@lvl+1
END ELSE
SET @lvl=@lvl-1
END
SELECT ’Dinosaur Orders'=
REPLICATE(CHAR(9),lvl)+i.OrderName
FROM #DINOSAURS d JOIN DINOSAURS i ON (d.OrderNo=i.OrderNo)
ORDER BY seq
Dinosaur Orders:
--------------------------------------------------------------------------------
Amphibia
Cotylosauri
Pelycosauria
Chelonia
Sauropterygia
Ichthyosauria
Squamata
Thecodontia
Crocodilia
Pterosauria
Saurichia
Ornithischia
Therapsida
This technique loops through the rows in the base table, placing each node it encounters into one temporary table and the children of that node into another. When the loop cycles, the first child in this work table is checked to see whether it has children of its own, and the process repeats itself. Each node is removed from the work table once it’s processed. This iteration continues until all nodes have been expanded.
As with the earlier queries, this routine uses an identity column to sequence itself. It also makes use of REPLICATE(CHAR(9)) to format its result set.
I don’t like this approach as much as those earlier in the chapter because, if for no other reason, it requires significantly more code. However, it may be more efficient since it doesn’t require a GROUP BY clause. The base table would have to be much larger than it is in these examples for there to be an appreciable difference in performance between any of the approaches presented here.
Rather than returning an entire hierarchy, you may wish to list its leaf nodes only. A node is a leaf node if it has no children. Given that all you have to do is find the nodes that aren’t listed as the parent of any of the other nodes, locating leaf nodes is easy enough. Here’s an example:
SELECT Grunts=s.employee_name
FROM staff s
WHERE NOT EXISTS
(SELECT * FROM staff t WHERE t.supervisor=s.employee)
Grunts
----------
HARPO
ZEPPO
LARRY
CURLY
CURLY JOE
Though not quite the same thing as a tree or hierarchy, an indented list provides a pseudohierarchy via its formatting. Though its uses are mostly simplistic, understanding the tools available to you for result set formatting is always handy, regardless of whether you end up using all of them. Here’s a code sample that returns an indented list of first and last names from the authors table in the pubs sample database:
SELECT authors=
CASE WHEN au_fname=(SELECT MIN(au_fname) FROM authors WHERE au_lname=a.au_lname)
THEN au_lname
ELSE "
END+CHAR(13)+CHAR(9)+au_fname
FROM authors a
authors
--------------------------------------------------------------
Bennet
Abraham
Blotchet-Halls
Reginald
Carson
Cheryl
DeFrance
Michel
del Castillo
Innes
Dull
Ann
Green
Marjorie
Greene
Morningstar
Gringlesby
Burt
Hunter
Sheryl
Karsen
Livia
Locksley
Charlene
MacFeather
Stearns
McBadden
Heather
O'Leary
Michael
Panteley
Sylvia
Ringer
Albert
Anne
Smith
Meander
Straight
Dean
Stringer
Dirk
White
Johnson
Yokomoto
Akiko
Note the use of the CASE function to limit the inclusion of each last name to one occurrence. For example, the Ringer surname has two corresponding authors—Albert and Anne—but the surname itself is listed just once. Also note the use of both CHAR(13) (carriage return) and CHAR(9) (tab) to create new lines and indent the result set. You can use CHAR() to great effect when formatting result sets. By coupling it with CASE, you can perform the same type of basic formatting that was previously the exclusive domain of report writers and external development tools.