
CHAPTER FIVE
Deployment
After you have an idea of how much capacity is needed for future growth and have purchased the hardware, you need to deploy it into production. In the case of a cloud setup, this entails configuring autoscaling (this is discussed in depth in Chapter 6). conversely, for a datacenter (which can be a managed service, as well), this also entails physically installing the hardware.

Historically, deployment has been viewed as a headache. Installing the operating system and application software, ensuring that all of the right settings are in place, and loading a website’s data—all of these tedious steps must be done to integrate the new instances in the cloud, or new hardware that’s fresh out of the crate in a datacenter. Fortunately, the pain of repeating these steps over and over has inspired an entire category of software: automated installation and configuration tools such as Vagrant, Chef, Puppet, Pallet, Ansible, and CFEngine.1 This new category of tools is commonly talked about under the umbrella of infrastructure as code, or programmable infrastructure. In essence, infrastructure as code refers to writing code (which you can do using a high-level language or any descriptive language) to manage configurations and automate provisioning of infrastructure in addition to deployments. It differs from infrastructure automation, which just involves replicating steps multiple times and reproducing them on several servers.
Automated Deployment Philosophies
Although various automatic installation and configuration tools differ in their implementation and execution, most of them share the same design philosophy. Just as with monitoring and metric-collection tools, many of these concepts and designs originated in the high-performance computing (HPC) field. Because HPC and web operations have similarities in their infrastructure, the web operations community has adopted many of these tools and approaches. In this section, we briefly outline the key goals and what each entails.
Goal 1: Minimize Time to Provision New Capacity
When you are trying to determine when your capacity is going to run out, you must factor into the calculations the time needed to acquire, install, and provision new hardware. If the capacity will be exhausted in six weeks, and it takes three weeks to add new hardware, you have only three weeks of breathing room. Automated deployment and configuration minimizes the time spent on the phase of the process over which you have the most control—integrating machines onto the network and beginning operations. A key aspect to this end is to have a homogeneous hardware (see the sidebar for further discussion).
Goal 2: All Changes Happen in One Place
When you’re making changes to hosts, it’s preferable to have a central location from which to push changes appropriate to the servers that you are affecting. Having a central location provides a “control tower” from which to manage all aspects of the infrastructure. Unlike server architectures, in which distributed resources help with horizontal scaling, centralized configuration and management environments yield several advantages:
-
You can employ version control for all configurations: operating system (OS), application, or otherwise. You can use Git, Perforce, RCS, CVS, Subversion, and so on to track the “who, what, when, and why” of each change to the infrastructure.
-
Replication and backup of installation and configuration files is easier to manage.
-
An aggregated configuration and management logging system is an ideal troubleshooting resource.
-
This centralized management environment makes an ideal place to keep hardware inventory, particularly if you want to have different configuration settings for different hardware.
This is not to suggest that your configuration, installation, monitoring, and management setup should be kept on a single server. Each of these deployment components demands specific resources. Growth over time would simply overwhelm a single machine, rendering it a potential single point of failure. Separate these components from the rest of the infrastructure. Monitoring and metric collection can reside on one server; configuration management and log aggregation on another. Figure 5-1 presents an example of a typical installation, configuration, and management architecture.

Figure 5-1. Typical cluster management scenario
Goal 3: Never Log in to an Individual Server (for Management)
Restrict logging in to an individual server to troubleshooting or forensic work only. All configuration or management should be done from the centralized management servers. This keeps the production changes in an auditable and controlled environment.
Goal 4: Have New Servers Start Working Automatically
This is the holy grail of all deployment systems. You should be able to order hardware, add it to the inventory-management system, turn it on, have it automatically install all required software and register itself with the monitoring systems, and then get down to work, all without administrator intervention.
Goal 5: Maintain Consistency for Easier Troubleshooting
Coordination of troubleshooting efforts during outages or emergencies is critical. Configuration management tools effectively enable that coordination. Consistent OS and software configuration across a cluster of identically deployed servers eliminates configuration inconsistencies as a source of problems. Troubleshooting in large production environments is difficult enough without needing to isolate configuration discrepancies between a handful of servers. Further, having disparate software configurations across nodes in a given cluster can potentially hinder performance optimization. For instance, having different versions of the gcc compiler can limit application of certain compiler optimizations as a result of certain optimizations not being supported in older versions. In a similar version, having different versions of the Java Development Kit (JDK) might limit the application of certain Just-in-Time (JIT) optimizations by the Java HotSpot compiler.
When tracking down a bug, the ability to quickly view all of the changes that occurred between the last known good state and the present (bad) state can be invaluable. When more than one person is working on an issue, a centralized and consistent overview of all of the changes is crucial. With version control, changes are immediately apparent and tasks aren’t repeated. Nor are they assumed to have been completed or otherwise mixed up with other tasks.
Automated Installation Tools
Before you can begin to even think about configuration management, you need to get the servers to a state in which they can be configured. You want a system that can automatically (and repetitively) install the OS of choice. Many such systems have been developed over the years, all employing similar techniques.
There are two basic approaches to the task of imaging new machines. Most OS vendors offer a package-based installer option, which performs the normal installation process in a noninteractive fashion. It provides the installer with a configuration file that specifies the packages to be installed. Examples include Solaris Jumpstart, Red Hat Kickstart, and Debian FAI.

Many third-party products take a disk-image approach. A gold client image is prepared on one machine and replicated byte-for-byte onto newly imaged hosts. Often, a single image is used for every server in the infrastructure, with hosts differing only in the services that are configured and running. SystemImager is a product that uses this approach.
Each method—package-based versus image-based—has its own advantages. Package-based systems provide accountability; every file installed is guaranteed to belong to a package, and package management tools make it easy to quickly see what’s installed. You can achieve the same result with disk-image systems by installing only packaged files. The temptation to muck about with the gold client filesystem directly can lead to confusion down the road. On the other hand, image-based systems tend to be faster to install. The installer merely has to create a filesystem and dump the image onto it, rather than download many packages, calculate dependencies, and install them one by one. Some products such as SystemImager even support parallel installs to multiple clients by streaming the disk images via multicast or BitTorrent.
On AWS, an Amazon Machine Image (AMI) is specified to launch one or more instances. An AMI includes the following:
-
A template for the root volume for the instance (for example, an OS, an application server, and applications)
-
Launch permissions that control which AWS accounts can use the AMI to launch instances
-
A block device mapping that specifies the volumes to attach to the instance when it’s launched
You can copy an AMI to the same region or to different regions. After launching an instance from an AMI, you can deregister the AMI. In fact, there is a marketplace for AMI where users can buy, share, and sell AMIs. An AMI is categorized as either backed by Amazon Elastic Block Store (EBS) or backed by instance store. The former means that the root device for an instance launched from the AMI is an Amazon EBS volume created from an Amazon EBS snapshot. The latter means that the root device for an instance launched from the AMI is an instance store volume created from a template stored in Amazon S3 (for references to details about AMIs, go to “Resources”). Figure 5-2 illustrates the life cycle of an AMI.

Figure 5-2. Life cycle of an AMI
At Netflix, to minimize the application startup latency, AMIs were designed to be discrete and complete, as demonstrated in Figure 5-3. First, using a standard Linux distribution such as Ubuntu or CentOS, a foundation AMI was created. An empty EBS volume was mounted, a filesystem was then created, a minimal OS was installed, a snapshot of the AMI was taken, and then, finally, the AMI was registered based on the snapshot.

Figure 5-3. An example Base AMI
The base AMI then was constructed by mounting an EBS volume created from the foundation AMI snapshot. Next it was customized with a meta package (RPM or DEB) that, through dependencies, pulled in other packages that comprised the Netflix base AMI. This volume was dismounted, snapshotted, and then registered as a candidate base AMI, which made it available for building application AMIs. In March 2013, Netflix announced the tool called Aminator to create custom machine images on AWS.
NOTE
For a reference to details about Aminator, go to “Resources”.
Linux AMIs use one of two types of virtualization: paravirtual (PV) or hardware VM (HVM). The two main differences between PV and HVM AMIs are the way in which they boot and whether they can take advantage of special hardware extensions (CPU, network, and storage) for better performance. PV AMIs boot with a special boot loader called PV-GRUB, which starts the boot cycle and then chain-loads the kernel specified in the menu.lst file on the image. Paravirtual guests can run on host hardware that does not have explicit support for virtualization, but they cannot take advantage of special hardware extensions such as enhanced networking or GPU processing. Historically, PV guests had better performance than HVM guests in many cases, but because of enhancements in HVM virtualization and the availability of PV drivers for HVM AMIs, this is no longer true. On the other hand, HVM AMIs exploit a fully virtualized set of hardware and boot by executing the master boot record of the root block device of the image. This virtualization type provides the ability to run an operating system directly on top of a VM without any modification, as if it were run on the bare-metal hardware. The Amazon EC2 host system emulates some or all of the underlying hardware that is presented to the guest. Unlike PV guests, HVM guests can take advantage of hardware extensions that provide fast access to the underlying hardware on the host system.
Figure 5-4 depicts the life cyle of an instance on AWS (note that the life cycle is similar on other public clouds).

Figure 5-4. Life cycle of an instance on AWS
Preparing the OS Image
In a cloud context, a rich set of tools are provided by the cloud vendor to install a basic version of the OS of choice and then install the required packages. However, in the on-premises context, most organizations aren’t happy with the OS their vendor installs. Default OS installations are notoriously inappropriate for production environments because they are designed to run on as many different hardware platforms as possible. They usually contain packages that you don’t need and typically are missing those that you do. As a result, most companies create custom OS images suitable for their specific needs.
For a package-based system, the OS image is specified by preparing a configuration file that lists the set of packages to be installed. You can simply dump the package list from an existing server and tweak it as desired. Then, you put the configuration file in the appropriate place on the boot server, and it’s all set. On the other hand, for an image-based system, it’s slightly more involved. Normally, a server is set aside to be the gold client that provides the template for the deployed image. This can be a physical server set aside for the purpose, or even a VM. You perform a normal OS installation and install all the software required in the infrastructure. The client image then is copied to the deployed server.
The Installation Process
If you are installing more than a handful of machines, installations with physical boot media such as CD-ROMs quickly become tedious and require someone to be physically present at the datacenter. You are going to want to set up a network boot server, which in the case of PC hardware usually means a Pre-Boot Execution Environment (PXE), as shown in Figure 5-5.

Figure 5-5. Basic steps of the PXE booting process
PXE-based installations are performed by a number of services working together. PXE firmware on the client requests its environment via Dynamic Host Configuration Protocol (DHCP). A DHCP server provides the information required to fetch the boot image (IP address, boot server, and image name). Finally, the client fetches the boot image from the boot server via TFTP.
For automated installation systems, the boot image consists of a kernel, plus a ramdisk containing the installer program. (This differs from diskless client setups, for which the boot image contains the production kernel the client uses to mount a network volume as its root filesystem.) The installer then determines what type of host is being installed and formats the local filesystems appropriately. There are several methods for mapping hardware profiles to hosts; typically they involve assigning configurations based on a hostname or a MAC address. For example, Kickstart passes the configuration filename as part of the DHCP options and fetches it from the Trivial File Transfer Protocol (TFTP) server, whereas SystemImager has a configuration file stored on the image server that maps image types to hostnames. The installer then installs the OS from the network onto the newly formatted volumes. As it pertains to a package-based installer, this means copying package files from a network repository (for example, apt or yum). For image-based systems, the OS image is dumped directly onto the local volumes, usually via rsync or a similar program.
After the OS image is installed, the PXE server marks the host as installed. Typically, this is done by replacing the host’s bootfile with a stub that instructs the host to boot from the local disk. The machine is restarted and boots normally. As shipped, most automated deployment systems require some manual configuration. You need to create DHCP server configurations and map hostnames to roles. However, inventory management systems should have all the information about a machine required to boot it: MAC address, role, IP address, and hostname. With a bit of clever scripting, you can generate the required configuration automatically from the asset database.
After this is set up, provisioning new servers is as simple as entering their details into inventory management, racking them, and powering them up. Reformatting a machine is as simple as assigning it a new role in the database and rebooting it. (Normally, a reinstallation is required only if the disk layout changes. Otherwise, you simply can reconfigure the server.)
Automated Configuration
Now that the machines are up on the network, it’s time to configure them to do their jobs. Configuration management systems help with this task in the following ways:
-
They let you organize the configuration files into useful subsystems, which you can combine in various ways to build production systems.
-
They put all the information about the running systems in one place, from which it easily can be backed-up or replicated to another site or property of the same site.
-
They extract institutional knowledge out of an administrator’s head and place it into a form that can be documented and reused.
A typical configuration management system consists of a server in which configurations are stored, and a client process, which runs on each host and requests a configuration from the server. In an infrastructure with automated deployment, the client is run as part of the initial installation or immediately after the initial boot into the new OS. After the initial configuration, a scheduled task on the client host periodically polls the server to see if any new configuration is available. Automating these checks ensures that every machine in an infrastructure is always running the latest configuration.
As mentioned earlier, several configuration tools have been developed over the years. Examples include Chef, Puppet, Ansible, CFEngine, SaltStack.
NOTE
For references to books on the subject, go to “Readings”.
Defining Roles and Services
You have a shiny new configuration management system installed. Now, how do you actually use it? The best way to attack the problem is to divide and conquer. Services (collections of related software and configurations) are the atoms, and roles (the types of machines in an infrastructure) are the molecules. Examples of a service and a role are discussed later in this section. After a robust set of services is defined, it is straightforward to shuffle existing services into alternative combinations to serve new roles or to split an existing role into more specialized configurations.
First, go through all of the machines in the infrastructure (or planned infrastructure) and identify the present roles. A role is a particular type of machine that performs a particular task. For a website, a list might include roles such as a “web server” and a “database.” Next, go through each role and determine which services need to be present on each instance of the role for the instance to be able to do its job. A service in this sense is not just an OS-level program like httpd. For example, the HTTP server service would include not only the httpd package and its configuration, but also settings for any metrics, health checks, or associated software that runs on a machine serving web pages.
As you go through the various roles, try to identify services that might be common to multiple roles. For example, every server is likely to require a remote login service such as sshd. By identifying these common services, you can create a single set of configuration routines that you can use over and over for deploying current as well as new roles that might emerge as the site grows.
An Example: Splitting Off Static Web Content
Suppose that you have a cluster of four web servers. Each machine serves a combination of static content and dynamic pages generated by PHP. Apache’s MaxClients setting is tuned down to 80 simultaneous connections to ensure that the machines don’t overrun available memory and initiate swapping. The web server role might look similar to Figure 5-6.

Figure 5-6. The web server role and associated services
You might realize in a flash of insight that more simultaneous clients can be served by splitting the cluster into two roles: one with the current configuration for dynamic content, and one with a stripped-down Apache with a larger MaxClients to serve only static content. To this end, first, you would split out services common to both roles into a separate service called base_http. This service includes settings that any web server should have, such as an HTTP health check and metrics pulled from Apache’s status module. Next, you would create two new services. The dynamic HTTP service contains the original Apache and PHP configurations. The static HTTP service is configured with a simplified httpd.conf with a larger client cap and no PHP module. Then, roles are defined for each server type by combining these services. Figure 5-7 depicts the new roles.
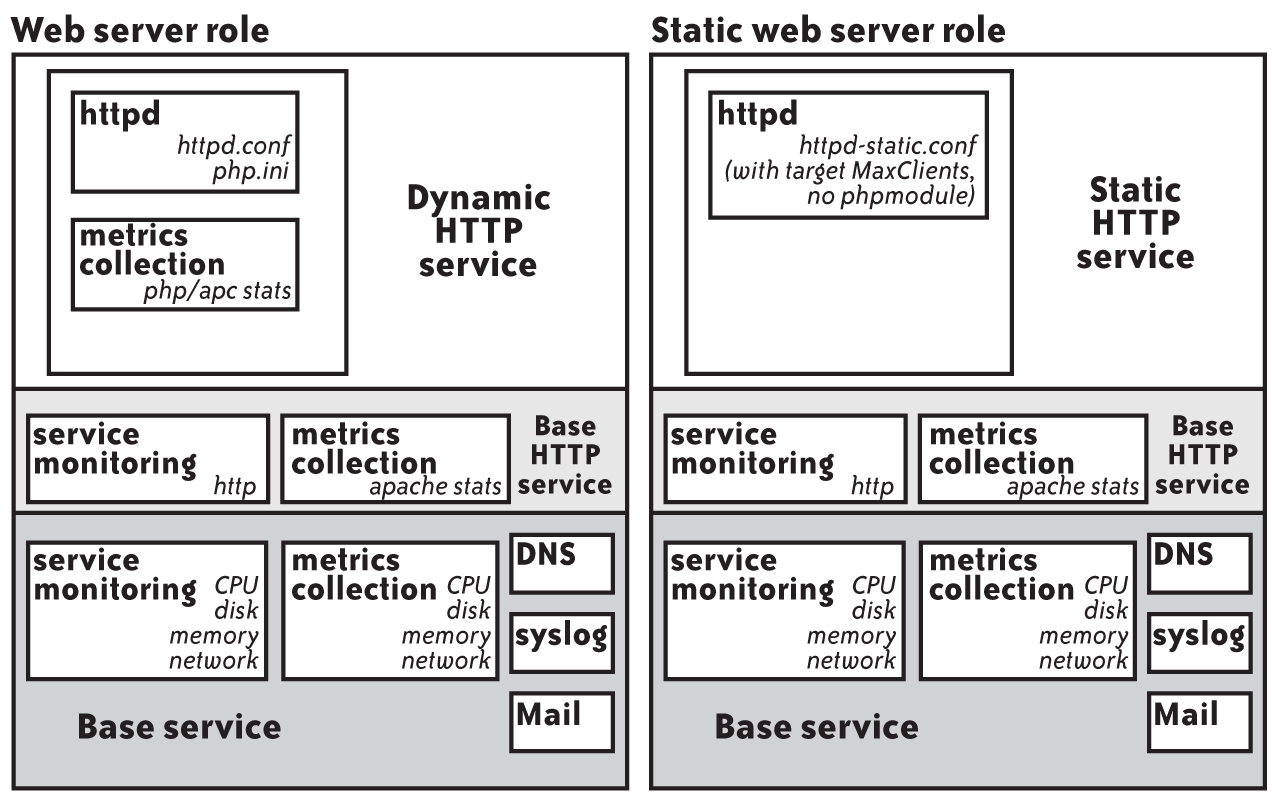
Figure 5-7. Static web server role and associated services
Now that the new role is defined, you can either go into the inventory management system and assign one or more existing web server machines to the static_webserver role, or deploy new hardware with the new role. If you decide to add more metrics or health checks, which are applicable to both roles in the future, you can put them in the base_http service, and both roles will inherit them.
User Management and Access Control
User management and access control require special consideration. How do you control which users have access to which portions of the system In fact, there are several ways. Network-based authentication and authorization services such as Lightweight Directory Access Protocol (LDAP) are popular. Users and groups can be granted access to individual machines or host groups in one place. Permission and password changes are propagated automatically. On the downside, these systems represent yet another service that needs to be provisioned, monitored, and scaled as the infrastructure grows.

Alternatively, it’s possible to use a configuration management system to install user accounts on a host or role basis by defining services that make the appropriate changes to the system authentication databases. This is straightforward if you already have configuration management in place. However, with such a system, password changes and access additions and revocations cannot be applied to all servers simultaneously. Additionally, if automated configuration updates are broken on a host, that host might not receive the latest access configuration at all, which is an obvious security concern.
Both of these setups can be made to work. Which one is most appropriate for the infrastructure depends on the existing authentication systems, the number of users involved, and the frequency with which changes are made. If you are already using LDAP elsewhere in the organization, that might be the natural choice. If you have a small number of users and changes are infrequent, a package-based system might be appropriate.
Ad Hockery
By now, you should have a good grasp about configuration management—an infrastructure full of properly configured servers that you would never need to log in to in order to manage it. But what if you want to? There are times when you might like to log into all of the members of a particular role and run a command. Fortunately, there are tools to make this task easier. These tools run the gamut from simple “run ssh in a for loop” scripts, to sophisticated remote scripting systems, like Capistrano.
Ideally, such a tool should integrate with the configuration management system. Still, you might want to be able to log in to groups of servers by role, or even by service. This might require some scripting to convert the role and service definitions into a format the tool understands. Alternatively, the tool might be provided as a component of the configuration management or monitoring system (such as the gexec utility provided with Ganglia).
You can run commands on multiple servers. But should you? In general, a good use for these utilities is to gather ad hoc data about the systems—perhaps information you’re not measuring with the trending tools. They’re also useful for debugging and forensics. The rule of thumb should be: If it’s not something that you should be collecting as a metric, and it won’t affect server state, it’s OK.
When is it a bad idea? You should hesitate any time it would be more appropriate to use configuration management. There’s always the possibility of forgetting ad hoc changes. You will regret forgetting.
Example 2: Multiple Datacenters
Eventually, you would want to attack the greatest single point of failure of them all—the cloud or the on-premises datacenter. You would want to be able to continue to serve traffic even if the cloud or the datacenter experiences a catastrophic power failure or other calamity. When you expand the infrastructure into multiple physical sites, you begin to realize the gains of automation on an even larger scale. Besides disaster recovery, geographically distributed cloud sites or on-premises datacenters are used to augment the end-user experience by minimizing the “wire time.” Big companies such as Amazon, Google, Facebook, Twitter, and Microsoft have multiple datacenters around the globe. In a similar vein, Netflix has its service set up across different AWS regions around the world.

Bringing up another datacenter can look like a logistical nightmare on paper. It took months or years to get the current systems in place. How would you be able to rebuild them in another location quickly? Automated deployment can make the prospect of bringing up an entire facility from bare metal much less daunting.
Rather than replicate each system in the original site on a host-by-host basis, the process unfolds as such:
-
Set up management hosts in the new datacenter. The base installs might be manual, but the configuration is not—the management host configurations should be in configuration management, as well!
-
Tweak the base configurations to suit the new environment. For example, DNS configuration and routing information will differ.
-
Allocate roles to the new machines on the boot server (or in inventory management).
-
Boot the hosts and allow them to install and configure themselves.
To simplify synchronization of settings between datacenters, it’s best to keep all datacenter-specific configurations in a separate service or set of services. This makes it possible for you to attain maximum reuse out of the service definitions.
Summary
Knowing how much hardware you need does little good if you can’t get that hardware into service quickly. Automating the infrastructure with tools like configuration management and automated installation ensures that the deployment processes are efficient and repeatable. Automation converts system administration tasks from one-off efforts into reusable building blocks.
Readings
-
K. Morris. Infrastructure as Code.
-
M. Taylor and S. Vargo. (2014). Learning Chef: A Guide to Configuration Management and Automation.
-
M. Marschall. (2015). Chef Infrastructure Automation Cookbook.
-
L. Hochstein. (2014). Ansible: Up and Running, Automating Configuration Management and Deployment the Easy Way.
-
P. Duvall et al. Continuous Integration: Improving Software Quality and Reducing Risk.
-
J. Humble and D. Farley. Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation.
-
N. Ford. Engineering Practices for Continuous Delivery: From Metrics and Deployment Pipelines to Integration and Microservices.
Resources
-
“Infrastructure as Code: A Reason to Smile.” (2016) https://www.thoughtworks.com/insights/blog/infrastructure-code-reason-smile.
-
“Google supercharges machine learning tasks with TPU custom chip.” (2016) https://cloudplatform.googleblog.com/2016/05/Google-supercharges-machine-learning-tasks-with-custom-chip.html.
-
https://www.tensorflow.org/ and “Chapter 3. The Java HotSpot Compilers.” http://www.oracle.com/technetwork/java/whitepaper-135217.html#compover.
-
“Amazon Machine Images (AMI).” http://amzn.to/2vapEL1.
-
“AMI Types.” http://amzn.to/2ivjv6a.
-
“Instance Lifecycle.” http://amzn.to/1Fw5S8l.
-
“AMI Creation with Aminator.” (2013) http://techblog.netflix.com/2013/03/ami-creation-with-aminator.html.
-
“Deploying the Netflix API.” (2013) http://techblog.netflix.com/2013/08/deploying-netflix-api.html.
-
Continuous Delivery (2010) https://martinfowler.com/books/continuousDelivery.html.
-
“Global Continuous Delivery with Spinnaker.” (2015) http://techblog.netflix.com/2015/11/global-continuous-delivery-with.html.
1 A part of this chapter was written by John’s former colleague at Flickr, Kevin Murphy.