
Most applications use a relational database such as Oracle, MySQL, or PostgreSQL; however, there is more to data storage than just SQL databases. There are
Relational databases (Oracle, MySQL, PostgreSQL, etc.)
Document stores (MongoDB, Couchbase)
Key-value stores (Redis, Volgemort)
Column stores (Cassandra)
Graph stores (Neo4j, Giraph)
Each of these technologies (and all of the implementations) works in a different way, so you have to spend time learning each one you want to use. Additionally, it might feel that you have to write a lot of duplicated plumbing code for handling transactions and error translation.
The Spring Data project can help make life easier; it can help configure the different technologies with the plumbing code. Each of the integration modules will have support for exception translation to Spring’s consistent DataAccessException hierarchy and the use of Spring’s templating approach. Spring Data also provides a cross-storage solution for some technologies, which means part of your model can be stored in a relational database with JPA and the other part can be stored in a graph or document store.
Tip
Each section in this chapter describes how to download and install the needed persistence store. However, the bin directory contains scripts that set up Docker containers for each persistence store.
12-1. Use MongoDB
Problem
You want to use MongoDB to store and retrieve documents.
Solution
Download and configure MongoDB.
How It Works
Before you can start using MongoDB you need to have an instance installed and up and running. When you have it running you will need to connect to it to be able to use the datastore for actual storage. You will start with plain MongoDB how to store and retrieve documents and graduatly move to Spring Data MongoDB to close with a reactive version of the repository.
Download and Start MongoDB
Download MongoDB from www.mongodb.org . Select the version that is applicable for the system in use and follow the installation instructions in the manual ( http://docs.mongodb.org/manual/installation/ ). When the installation is complete, MongoDB can be started. To start MongoDB, execute the mongodb command on the command line (see Figure 12-1). This will start a MongoDB server on port 27017. If a different port is required, this can be done by specifying the --port option on the command line when starting the server.

Figure 12-1. Output after initial start of MongoDB
The default location for storing data is datadb (for Windows users, this is from the root of the disk where MongoDB was installed!). To change the path, use the --dbpath option on the command line. Make sure that the directory exists and is writable for MongoDB.
Connect to MongoDB
For a connection to MongoDB, you need an instance of Mongo. You can use this instance to get the database to use and the actual underlying collection (or collections). Let’s create a small system that uses MongoDB to create an object to use for storage.
package com.apress.springrecipes.nosql;public class Vehicle {private String vehicleNo;private String color;private int wheel;private int seat;public Vehicle() {}public Vehicle(String vehicleNo, String color, int wheel, int seat) {this.vehicleNo = vehicleNo;this.color = color;this.wheel = wheel;this.seat = seat;}/// Getters and Setters have been omitted for brevity.}
To work with this object, create a repository interface.
package com.apress.springrecipes.nosql;public interface VehicleRepository {long count();void save(Vehicle vehicle);void delete(Vehicle vehicle);List<Vehicle> findAll()Vehicle findByVehicleNo(String vehicleNo);}
For MongoDB, create the MongoDBVehicleRepository implementation of the VehicleRepository.
package com.apress.springrecipes.nosql;import com.mongodb.*;import java.util.ArrayList;import java.util.List;public class MongoDBVehicleRepository implements VehicleRepository {private final Mongo mongo;private final String collectionName;private final String databaseName;public MongoDBVehicleRepository(Mongo mongo, String databaseName, String collectionName) {this.mongo = mongo;this.databaseName=databaseName;this.collectionName = collectionName;}@Overridepublic long count() {return getCollection().count();}@Overridepublic void save(Vehicle vehicle) {BasicDBObject query = new BasicDBObject("vehicleNo", vehicle.getVehicleNo());DBObject dbVehicle = transform(vehicle);DBObject fromDB = getCollection().findAndModify(query, dbVehicle);if (fromDB == null) {getCollection().insert(dbVehicle);}}@Overridepublic void delete(Vehicle vehicle) {BasicDBObject query = new BasicDBObject("vehicleNo", vehicle.getVehicleNo());getCollection().remove(query);}@Overridepublic List<Vehicle> findAll() {DBCursor cursor = getCollection().find(null);List<Vehicle> vehicles = new ArrayList<>(cursor.size());for (DBObject dbObject : cursor) {vehicles.add(transform(dbObject));}return vehicles;}@Overridepublic Vehicle findByVehicleNo(String vehicleNo) {BasicDBObject query = new BasicDBObject("vehicleNo", vehicleNo);DBObject dbVehicle = getCollection().findOne(query);return transform(dbVehicle);}private DBCollection getCollection() {return mongo.getDB(databaseName).getCollection(collectionName);}private Vehicle transform(DBObject dbVehicle) {return new Vehicle((String) dbVehicle.get("vehicleNo"),(String) dbVehicle.get("color"),(int) dbVehicle.get("wheel"),(int) dbVehicle.get("seat"));}private DBObject transform(Vehicle vehicle) {BasicDBObject dbVehicle = new BasicDBObject("vehicleNo", vehicle.getVehicleNo()).append("color", vehicle.getColor()).append("wheel", vehicle.getWheel()).append("seat", vehicle.getSeat());return dbVehicle;}}
First notice the constructor takes three arguments. The first is the actual MongoDB client, the second is the name of the database that is going to be used, and the last is the name of the collection in which the objects are stored. Documents in MongoDB are stored in collections, and a collection belongs to a database.
For easy access to the DBCollection used, there is the getCollection method that gets a connection to the database and returns the configured DBCollection. This DBCollection can then be used to execute operations such as storing, deleting, or updating documents.
The save method will first try to update an existing document. If this fails, a new document for the given Vehicle will be created. To store objects, start by transforming the domain object Vehicle into a DBObject, in this case a BasicDBObject. The BasicDBObject takes key-value pairs of the different properties of your Vehicle object. When querying for a document, the same DBObject is used, and the key-value pairs that are present on the given object are used to look up documents; you can find an example in the findByVehicleNo method in the repository. Conversion from and to Vehicle objects is done through the two transform methods.
To use this class, create the following Main class:
package com.apress.springrecipes.nosql;import com.mongodb.MongoClient;import java.util.List;public class Main {public static final String DB_NAME = "vehicledb";public static void main(String[] args) throws Exception {// Default monogclient for localhost and port 27017MongoClient mongo = new MongoClient();VehicleRepository repository = new MongoDBVehicleRepository(mongo, DB_NAME, "vehicles");System.out.println("Number of Vehicles: " + repository.count());repository.save(new Vehicle("TEM0001", "RED", 4, 4));repository.save(new Vehicle("TEM0002", "RED", 4, 4));System.out.println("Number of Vehicles: " + repository.count());Vehicle v = repository.findByVehicleNo("TEM0001");System.out.println(v);List<Vehicle> vehicleList = repository.findAll();System.out.println("Number of Vehicles: " + vehicleList.size());vehicleList.forEach(System.out::println);System.out.println("Number of Vehicles: " + repository.count());// Cleanup and closemongo.dropDatabase(DB_NAME);mongo.close();}}
The main class constructs an instance of the MongoClient that will try to connect to port 27017 on localhost for a MongoDB instance. If another port or host is needed, there is also a constructor that takes a host and port as parameters: new MongoClient("mongodb-server.local", 28018). Next an instance of the MongoDBVehicleRepository class is constructed; the earlier constructed MongoClient is passed as well as the name of the database, which is vehicledb, and the name of the collection, which is vehicles.
The next lines of code will insert two vehicles into the database, try to find them, and finally delete them. The last lines in the Main class will close the MongoClient and before doing so will drop the database. The latter is something you don’t want to do when using a production database.
Use Spring for Configuration
The setup and configuration of the MongoClient and MongoDBVehicleRepository can easily be moved to the Spring configuration.
package com.apress.springrecipes.nosql.config;import com.apress.springrecipes.nosql.MongoDBVehicleRepository;import com.apress.springrecipes.nosql.VehicleRepository;import com.mongodb.Mongo;import com.mongodb.MongoClient;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import java.net.UnknownHostException;@Configurationpublic class MongoConfiguration {public static final String DB_NAME = "vehicledb";@Beanpublic Mongo mongo() throws UnknownHostException {return new MongoClient();}@Beanpublic VehicleRepository vehicleRepository(Mongo mongo) {return new MongoDBVehicleRepository(mongo, DB_NAME, " vehicles");}}
The following @PreDestroy annotated method has been added to the MongoDBVehicleRepository to take care of the cleanup of the database.
@PreDestroypublic void cleanUp() {mongo.dropDatabase(databaseName);}
Finally, the Main program needs to be updated to reflect the changes.
package com.apress.springrecipes.nosql;...import org.springframework.context.ApplicationContext;import org.springframework.context.annotation.AnnotationConfigApplicationContext;import org.springframework.context.support.AbstractApplicationContext;import java.util.List;public class Main {public static final String DB_NAME = "vehicledb";public static void main(String[] args) throws Exception {ApplicationContext ctx =new AnnotationConfigApplicationContext(MongoConfiguration.class);VehicleRepository repository = ctx.getBean(VehicleRepository.class);...((AbstractApplicationContext) ctx).close();}}
The configuration is loaded by an AnnotationConfigApplicationContext. From this context, the VehicleRepository bean is retrieved and used to execute the operations. When the code that has run the context is closed, it triggers the cleanUp method in the MongoDBVehicleRepository.
Use a MongoTemplate to Simplify MongoDB Code
At the moment, the MongoDBVehicleRepository class uses the plain MongoDB API. Although it’s not very complex, it still requires knowledge about the API. In addition, there are some repetitive tasks like mapping from and to a Vehicle object. Using a MongoTemplate can simplify the repository considerably.
Note
Before using Spring Data Mongo, the relevant JARs need to be added to the classpath. When using Maven, add the following dependency:
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-mongodb</artifactId>
<version>1.10.1.RELEASE</version>
</dependency>When using Gradle, use the following:
compile 'org.springframework.data:spring-data-mongodb:1.10.1.RELEASE'package com.apress.springrecipes.nosql;import org.springframework.data.mongodb.core.MongoTemplate;import org.springframework.data.mongodb.core.query.Query;import javax.annotation.PreDestroy;import java.util.List;import static org.springframework.data.mongodb.core.query.Criteria.where;public class MongoDBVehicleRepository implements VehicleRepository {private final MongoTemplate mongo;private final String collectionName;public MongoDBVehicleRepository(MongoTemplate mongo, String collectionName) {this.mongo = mongo;this.collectionName = collectionName;}@Overridepublic long count() {return mongo.count(null, collectionName);}@Overridepublic void save(Vehicle vehicle) {mongo.save(vehicle, collectionName);}@Overridepublic void delete(Vehicle vehicle) {mongo.remove(vehicle, collectionName);}@Overridepublic List<Vehicle> findAll() {return mongo.findAll(Vehicle.class, collectionName);}@Overridepublic Vehicle findByVehicleNo(String vehicleNo) {return mongo.findOne(new Query(where("vehicleNo").is(vehicleNo)), Vehicle.class, collectionName);}@PreDestroypublic void cleanUp() {mongo.execute(db -> {db.drop();return null;});}}
The code looks a lot cleaner when using a MongoTemplate. It has convenience methods for almost every operation: save, update, and delete. Additionally, it has a nice query builder approach (see the findByVehicleNo method). There are no more mappings to and from the MongoDB classes, so there is no need to create a DBObject anymore. That burden is now handled by the MongoTemplate. To convert the Vehicle object to the MongoDB classes, a MongoConverter is used. By default a MappingMongoConverter is used. This mapper maps properties to attribute names, and vice versa, and while doing so, also tries to convert from and to the correct data type. If a specific mapping is needed, it is possible to write your own implementation of a MongoConverter and register it with the MongoTemplate.
Because of the use of the MongoTemplate, the configuration needs to be modified.
package com.apress.springrecipes.nosql.config;import com.apress.springrecipes.nosql.MongoDBVehicleRepository;import com.apress.springrecipes.nosql.VehicleRepository;import com.mongodb.Mongo;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.data.mongodb.core.MongoClientFactoryBean;import org.springframework.data.mongodb.core.MongoTemplate;@Configurationpublic class MongoConfiguration {public static final String DB_NAME = "vehicledb";@Beanpublic MongoTemplate mongo(Mongo mongo) throws Exception {return new MongoTemplate(mongo, DB_NAME);}@Beanpublic MongoClientFactoryBean mongoFactoryBean() {return new MongoClientFactoryBean();}@Beanpublic VehicleRepository vehicleRepository(MongoTemplate mongo) {return new MongoDBVehicleRepository(mongo, "vehicles");}}
Notice the use of the MongoClientFactoryBean. It allows for easy setup of the MongoClient. It isn’t a requirement for using the MongoTemplate, but it makes it easier to configure the client. Another benefit is that there is no more java.net.UnknownHostException thrown that is handled internally by the MongoClientFactoryBean.
The Mongo Template has various constructors. The one used here takes a Mongo instance and the name of the database to use. To resolve the database, an instance of a MongoDbFactory is used; by default, it’s the SimpleMongoDbFactory. In most cases, this is sufficient, but if some special case arises, like encrypted connections, it is quite easy to extend the default implementation. Finally, the MongoTemplate is injected, together with the name of the collection, into the MongoDBVehicleRepository.
A final addition needs to be made to the Vehicle object. It is required that a field is available for storing the generated ID. This can be either a field with the name id or a field with the @Id annotation.
public class Vehicle {private String id;...}
Use Annotations to Specify Mapping Information
Currently the MongoDBVehicleRepository needs to know the name of the collection you want to access. It would be easier and more flexible if this could be specified on the Vehicle object, just as with a JPA @Table annotation. With Spring Data Mongo, this is possible using the @Document annotation.
package com.apress.springrecipes.nosql;import org.springframework.data.mongodb.core.mapping.Document;@Document(collection = "vehicles")public class Vehicle { ... }
The @Document annotation can take two attributes: collection and language. The collection property is for specifying the name of the collection to use, and the language property is for specifying the language for this object. Now that the mapping information is on the Vehicle class, the collection name can be removed from the MongoDBVehicleRepository.
public class MongoDBVehicleRepository implements VehicleRepository {private final MongoTemplate mongo;public MongoDBVehicleRepository(MongoTemplate mongo) {this.mongo = mongo;}@Overridepublic long count() {return mongo.count(null, Vehicle.class);}@Overridepublic void save(Vehicle vehicle) {mongo.save(vehicle);}@Overridepublic void delete(Vehicle vehicle) {mongo.remove(vehicle);}@Overridepublic List<Vehicle> findAll() {return mongo.findAll(Vehicle.class);}@Overridepublic Vehicle findByVehicleNo(String vehicleNo) {return mongo.findOne(new Query(where("vehicleNo").is(vehicleNo)), Vehicle.class);}}
Of course, the collection name can be removed from the configuration of the MongoDBVehicleRepository as well.
@Configurationpublic class MongoConfiguration {...@Beanpublic VehicleRepository vehicleRepository(MongoTemplate mongo) {return new MongoDBVehicleRepository(mongo);}}
When running the Main class, the result should still be the same as it was before.
Create a Spring Data MongoDB Repository
Although the code has been reduced a lot in that there is no more mapping from and to MongoDB classes and no more collection names passing around, it can still be reduced even further. Leveraging another feature of Spring Data Mongo, the complete implementation of the MongoDBVehicleRepository could be removed.
First the configuration needs to be modified.
package com.apress.springrecipes.nosql.config;import com.mongodb.Mongo;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.data.mongodb.core.MongoClientFactoryBean;import org.springframework.data.mongodb.core.MongoTemplate;import org.springframework.data.mongodb.repository.config.EnableMongoRepositories;@Configuration@EnableMongoRepositories(basePackages = "com.apress.springrecipes.nosql")public class MongoConfiguration {public static final String DB_NAME = "vehicledb";@Beanpublic MongoTemplate mongoTemplate(Mongo mongo) throws Exception {return new MongoTemplate(mongo, DB_NAME);}@Beanpublic MongoClientFactoryBean mongoFactoryBean() {return new MongoClientFactoryBean();}}
First, notice the removal of the @Bean method that constructed the MongoDBVehicleRepository. Second, notice the addition of the @EnableMongoRepositories annotation. This enables detection of interfaces that extend the Spring Data CrudRepository and are used for domain objects annotated with @Document.
To have your VehicleRepository detected by Spring Data, you need to let it extend CrudRepository or one of its subinterfaces like MongoRepository.
package com.apress.springrecipes.nosql;import org.springframework.data.mongodb.repository.MongoRepository;public interface VehicleRepository extends MongoRepository<Vehicle, String> {public Vehicle findByVehicleNo(String vehicleNo);}
You might wonder where all the methods have gone. They are already defined in the super interfaces and as such can be removed from this interface. The findByVehicleNo method is still there. This method will still be used to look up a Vehicle by its vehicleNo property. All the findBy methods are converted into a MongoDB query. The part after the findBy is interpreted as a property name. It is also possible to write more complex queries using different operators such as and, or, and between.
Now running the Main class again should still result in the same output; however, the actual code written to work with MongoDB has been minimized.
Create a Reactive Spring Data MongoDB Repository
Instead of creating a traditional MongoDB repository, it is possible to create a reactive repository , which is done by extending the ReactiveMongoRepository class (or one of the other reactive repository interfaces). This will change the return types for methods that return a single value into Mono<T> (or Mono<Void> for nonreturning methods) and Flux<T> for zero or more elements.
Note
If you want to use RxJava instead Project Reactor, extend one of the RxJava2*Repository interfaces and use a Single or Observable instead of Mono and Flux.
To be able to use a reactive repository implementation, you first have to use a reactive implementation of the MongoDB driver and configure Spring Data to use that driver. To make it easier, you can extend AbstractReactiveMongoConfiguration and implement the two required methods getDatabaseName and mongoClient.
@Configuration@EnableReactiveMongoRepositories(basePackages = "com.apress.springrecipes.nosql")public class MongoConfiguration extends AbstractReactiveMongoConfiguration {public static final String DB_NAME = "vehicledb";@Bean@Overridepublic MongoClient reactiveMongoClient() {return MongoClients.create();}@Overrideprotected String getDatabaseName() {return DB_NAME;}}
Another thing that has changed is the use of @EnableReactiveMongoRepositories instead of @EnableMongoRepositories. The database name is still needed, and you need to connect with a reactive driver to the MongoDB instance. For this you can use one of the MongoClients.create methods; here you can simply use the default.
Next change VehicleRepository to extend ReactiveMongoRepository so it will become reactive; you also need to change the return type of the findByVehicleNo method to Mono<Vehicle> instead of a plain Vehicle.
package com.apress.springrecipes.nosql;import org.springframework.data.mongodb.repository.ReactiveMongoRepository;import reactor.core.publisher.Mono;public interface VehicleRepository extends ReactiveMongoRepository<Vehicle, String> {Mono<Vehicle> findByVehicleNo(String vehicleNo);}
The final piece that would need to change is the Main class to test all this. Instead of blocking calls, you want to use a stream of methods to be called.
package com.apress.springrecipes.nosql;import com.apress.springrecipes.nosql.config.MongoConfiguration;import org.springframework.context.ApplicationContext;import org.springframework.context.annotation.AnnotationConfigApplicationContext;import org.springframework.context.support.AbstractApplicationContext;import reactor.core.publisher.Flux;import java.util.concurrent.CountDownLatch;public class Main {public static void main(String[] args) throws Exception {ApplicationContext ctx =new AnnotationConfigApplicationContext(MongoConfiguration.class);VehicleRepository repository = ctx.getBean(VehicleRepository.class);CountDownLatch countDownLatch = new CountDownLatch(1);repository.count().doOnSuccess(cnt -> System.out.println("Number of Vehicles: " + cnt)).thenMany(repository.saveAll(Flux.just(new Vehicle("TEM0001", "RED", 4, 4),new Vehicle("TEM0002", "RED", 4, 4)))).last().then(repository.count()).doOnSuccess(cnt -> System.out.println("Number of Vehicles: " + cnt)).then(repository.findByVehicleNo("TEM0001")).doOnSuccess(System.out::println).then(repository.deleteAll()).doOnSuccess(x -> countDownLatch.countDown()).doOnError(t -> countDownLatch.countDown()).then(repository.count()).subscribe(cnt -> System.out.println("Number of Vehicles: " + cnt.longValue()));countDownLatch.await();((AbstractApplicationContext) ctx).close();}}
The flow starts with a count, and when that succeeds, the Vehicle instances are put into MongoDB. When the last() vehicle has been added, a count is done again, followed by a query that in turn is followed by a deleteAll. All these methods are called in a reactive fashion one after the other, triggered by an event. Because you don’t want to block using the block() method, you wait for the code to execute using a CountDownLatch, and the counter is decremented after the deletion of all records, after which the program will continue execution. Granted, this is still blocking. When using this in a full reactive stack, you would probably return the Mono from the last then and do further composition or give the output a Spring WebFlux controller (see Chapter 5).
12-2. Use Redis
Problem
You want to utilize Redis to store data.
Solution
Download and install Redis and use Spring and Spring Data to access the Redis instance.
How It Works
Redis is a key-value cache or store, and it will hold only simple data types such as strings and hashes. When storing more complex data structures, conversion from and to that data structure is needed.
Download and Start Redis
You can download Redis sources from http://redis.io/download . At the time of writing, version 3.2.8 is the most recently released stable version. You can find a compiled version for Windows at https://github.com/MSOpenTech/redis/releases . The official download site only provides Unix binaries. Mac users can use Homebrew ( http://brew.sh ) to install Redis.
After downloading and installing Redis, start it using the redis-server command from the command line. When started, the output should be similar to that in Figure 12-2. It will output the process ID (PID) and the port number (default 6379) it listens on.

Figure 12-2. Output after starting Redis
Connect to Redis
To be able to connect to Redis, a client is needed, much like a JDBC driver to connect to a database. Several clients are available. You can find a full list on the Redis web site ( http://redis.io/clients ). For this recipe, the Jedis client will be used because it is quite active and recommended by the Redis team.
Let’s start with a simple Hello World sample to see whether a connection to Redis can be made.
package com.apress.springrecipes.nosql;import redis.clients.jedis.Jedis;public class Main {public static void main(String[] args) {Jedis jedis = new Jedis("localhost");jedis.set("msg", "Hello World, from Redis!");System.out.println(jedis.get("msg"));}}
A Jedis client is created and passed the name of the host to connect to, in this case simply localhost. The set method on the Jedis client will put a message in the store, and with get the message is retrieved again. Instead of a simple object, you could also have Redis mimic a List or a Map.
package com.apress.springrecipes.nosql;import redis.clients.jedis.Jedis;public class Main {public static void main(String[] args) {Jedis jedis = new Jedis("localhost");jedis.rpush("authors", "Marten Deinum", "Josh Long", "Daniel Rubio", "Gary Mak");System.out.println("Authors: " + jedis.lrange("authors",0,-1));jedis.hset("sr_3", "authors", "Gary Mak, Danial Rubio, Josh Long, Marten Deinum");jedis.hset("sr_3", "published", "2014");jedis.hset("sr_4", "authors", "Josh Long, Marten Deinum");jedis.hset("sr_4", "published", "2017");System.out.println("Spring Recipes 3rd: " + jedis.hgetAll("sr_3"));System.out.println("Spring Recipes 4th: " + jedis.hgetAll("sr_4"));}}
With rpush and lpush, you can add elements to a List. rpush adds the elements to the end of the list, and lpush adds them to the start of the list. To retrieve them, the lrange or rrange method can be used. The lrange starts from the left and takes a start and end index. The sample uses -1, which indicates everything.
To add elements to a Map, use hset. This takes a key and a field and a value. Another option is to use hmset (multiset), which takes a Map<String, String> or Map<byte[], byte[]> as an argument.
Store Objects with Redis
Redis is a key-value store and can handle only String or byte[]. The same goes for the keys. So, storing an object in Redis isn’t as straightforward as with other technologies. The object needs to be serialized to a String or a byte[] before storing.
Let’s reuse the Vehicle class from recipe 12-1 and store and retrieve that using a Jedis client.
package com.apress.springrecipes.nosql;import java.io.Serializable;public class Vehicle implements Serializable{private String vehicleNo;private String color;private int wheel;private int seat;public Vehicle() {}public Vehicle(String vehicleNo, String color, int wheel, int seat) {this.vehicleNo = vehicleNo;this.color = color;this.wheel = wheel;this.seat = seat;}// getters/setters omitted}
Notice the implements Serializable for the Vehicle class. This is needed to make the object serializable for Java. Before storing the object, it needs to be converted into a byte[] in Java. The ObjectOutputStream can write objects, and the ByteArrayOutputStream can write to a byte[]. To transform a byte[] into an object again, ObjectInputStream and ByteArrayInputStream are of help. Spring has a helper class for this called org.springframework.util.SerializationUtils, which provides serialize and deserialize methods.
Now in the Main class, let’s create a Vehicle and store it using Jedis.
package com.apress.springrecipes.nosql;import org.springframework.util.SerializationUtils;import redis.clients.jedis.Jedis;public class Main {public static void main(String[] args) throws Exception {Jedis jedis = new Jedis("localhost");final String vehicleNo = "TEM0001";Vehicle vehicle = new Vehicle(vehicleNo, "RED", 4,4);jedis.set(vehicleNo.getBytes(), SerializationUtils.serialize(vehicle));byte[] vehicleArray = jedis.get(vehicleNo.getBytes());System.out.println("Vehicle: " + SerializationUtils.deserialize(vehicleArray));}}
First, an instance of the Vehicle is created. Next, the earlier mentioned SerializationUtils is used to convert the object into a byte[]. When storing a byte[], the key also needs to be a byte[]; hence, the key, here vehicleNo, is converted too. Finally, the same key is used to read the serialized object from the store again and convert it back into an object again. The drawback of this approach is that every object that is stored needs to implement the Serializable interface. If this isn’t the case, the object might be lost, or an error during serialization might occur. In addition, the byte[] is a representation of the class. Now if this class is changed, there is a great chance that converting it back into an object will fail.
Another option is to use a String representation of the object. Convert the Vehicle object into XML or JSON, which would be more flexible than a byte[]. Let’s take a look at converting the object into JSON using the excellent Jackson JSON library:
package com.apress.springrecipes.nosql;import com.fasterxml.jackson.databind.ObjectMapper;import redis.clients.jedis.Jedis;public class Main {public static void main(String[] args) throws Exception {Jedis jedis = new Jedis("localhost");ObjectMapper mapper = new ObjectMapper();final String vehicleNo = "TEM0001";Vehicle vehicle = new Vehicle(vehicleNo, "RED", 4,4);jedis.set(vehicleNo, mapper.writeValueAsString(vehicle));String vehicleString = jedis.get(vehicleNo);System.out.println("Vehicle: " + mapper.readValue(vehicleString, Vehicle.class));}}
First, an instance of the ObjectMapper is needed. This object is used to convert from and to JSON. When writing, the writeValueAsString method is used as it will transform the object into a JSON String. This String is then stored in Redis. Next, the String is read again and passed to the readValue method of the ObjectMapper. Based on the type argument, Vehicle.class here, an object is constructed, and the JSON is mapped to an instance of the given class.
Storing objects when using Redis isn’t straightforward, and some argue that this isn’t how Redis was intended to be used (storing complex object structures).
Configure and Use the RedisTemplate
Depending on the client library used to connect to Redis, it might be harder to use the Redis API. To unify this, there is the RedisTemplate. It can work with most Redis Java clients out there. Next to providing a unified approach, it also takes care of translating any exceptions into the Spring’s DataAccessException hierarchy. This lets it integrate nicely with any already existing data access and allows it to use Spring’s transactions support.
The RedisTemplate requires a RedisConnectionFactory to be able to get a connection. The RedisConnectionFactory is an interface, and several implementations are available. In this case, the JedisConnectionFactory is needed.
package com.apress.springrecipes.nosql.config;import com.apress.springrecipes.nosql.Vehicle;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.data.redis.connection.RedisConnectionFactory;import org.springframework.data.redis.connection.jedis.JedisConnectionFactory;import org.springframework.data.redis.core.RedisTemplate;@Configurationpublic class RedisConfig {@Beanpublic RedisTemplate<String, Vehicle> redisTemplate(RedisConnectionFactory connectionFactory) {RedisTemplate template = new RedisTemplate();template.setConnectionFactory(connectionFactory);return template;}@Beanpublic RedisConnectionFactory redisConnectionFactory() {return new JedisConnectionFactory();}}
Notice the return type of the redisTemplate bean method. RedisTemplate is a generic class and requires a key and value type to be specified. In this case, String is the type of key, and Vehicle is the type of value. When storing and retrieving objects, RedisTemplate will take care of the conversion. Conversion is done using a RedisSerializer interface, which is an interface for which several implementations exist (see Table 12-1). The default RedisSerializer, JdkSerializationRedisSerializer, uses standard Java serialization to convert objects to byte[] and back.
Table 12-1. Default RedisSerializer Implementations
Name | Description |
|---|---|
GenericToStringSerializer | String to byte[] serializer; uses the Spring ConversionService to convert objects to String before converting to byte[] |
Jackson2JsonRedisRedisSerializer | Reads and writes JSON using a Jackson 2 ObjectMapper |
JacksonJsonRedisRedisSerializer | Reads and writes JSON using a Jackson ObjectMapper |
JdkSerializationRedisSerializer | Uses default Java serialization and deserialization and is the default implementation used |
OxmSerializer | Reads and writes XML using Spring’s Marshaller and Unmarshaller |
StringRedisSerializer | Simple String to byte[] converter |
To be able to use the RedisTemplate, the Main class needs to be modified. The configuration needs to be loaded and the RedisTemplate retrieved from it.
package com.apress.springrecipes.nosql;import com.apress.springrecipes.nosql.config.RedisConfig;import org.springframework.context.ApplicationContext;import org.springframework.context.annotation.AnnotationConfigApplicationContext;import org.springframework.data.redis.core.RedisTemplate;public class Main {public static void main(String[] args) throws Exception {ApplicationContext context = new AnnotationConfigApplicationContext(RedisConfig.class);RedisTemplate<String, Vehicle> template = context.getBean(RedisTemplate.class);final String vehicleNo = "TEM0001";Vehicle vehicle = new Vehicle(vehicleNo, "RED", 4,4);template.opsForValue().set(vehicleNo, vehicle);System.out.println("Vehicle: " + template.opsForValue().get(vehicleNo));}}
When the RedisTemplate template has been retrieved from ApplicationContext, it can be used. The biggest advantage here is that you can use objects, and the template handles the hard work of converting from and to objects. Notice how the set method takes a String and Vehicle as arguments instead of only String or byte[]. This makes code more readable and easier to maintain. By default JDK serialization is used. To use Jackson, a different RedisSerializer needs to be configured.
package com.apress.springrecipes.nosql.config;...import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;@Configurationpublic class RedisConfig {@Beanpublic RedisTemplate<String, Vehicle> redisTemplate() {RedisTemplate template = new RedisTemplate();template.setConnectionFactory(redisConnectionFactory());template.setDefaultSerializer(new Jackson2JsonRedisSerializer(Vehicle.class));return template;}...}
The RedisTemplate template will now use a Jackson ObjectMapper object to perform the serialization and deserialization. The remainder of the code can remain the same. When running the main program again, it still works, and the object will be stored using JSON. When Redis is used inside a transaction, it can also participate in that same transaction. For this, set the enableTransactionSupport property on the RedisTemplate template to true. This will take care of executing the Redis operation inside the transaction when the transaction commits.
12-3. Use Neo4j
Problem
You want to use Neo4j in your application.
Solution
Use the Spring Data Neo4j library to access Neo4j.
How It Works
Before you can start using Neo4J you need to have an instance installed and up and running. When you have it running you will need to connect to it to be able to use the datastore for actual storage. You will start with a plain Neo4J based repository to show how to store and retrieve objects and graduatly move to Spring Data Neo4J based repositories.
Download and Run Neo4J
You can download Neo4J from the Neo4j web site ( http://neo4j.com/download/ ). For this recipe, it is enough to download the community edition; however, it should also work with the commercial version of Neo4j. Windows users can run the installer to install Neo4j. Mac and Linux users can extract the archive and, from inside the directory created, start with bin/neo4j. Mac users can also use Homebrew ( http://brew.sh ) to install Neo4j with brew install neo4j. Starting can then be done with neo4j start on the command line.
After starting on the command line, the output should be similar to that of Figure 12-3.
Figure 12-3. Output after initial start of Neo4j
Start Neo4j
Let’s start by creating a simple Hello World program with an embedded Neo4j server. Create a Main class that starts an embedded server, adds some data to Neo4j, and retrieves it again.
package com.apress.springrecipes.nosql;import org.neo4j.graphdb.GraphDatabaseService;import org.neo4j.graphdb.Node;import org.neo4j.graphdb.Transaction;import org.neo4j.graphdb.factory.GraphDatabaseFactory;import java.nio.file.Paths;public class Main {public static void main(String[] args) {final String DB_PATH = System.getProperty("user.home") + "/friends";GraphDatabaseService db = new GraphDatabaseFactory().newEmbeddedDatabase(Paths.get(DB_PATH).toFile());Transaction tx1 = db.beginTx();Node hello = db.createNode();hello.setProperty("msg", "Hello");Node world = db.createNode();world.setProperty("msg", "World");tx1.success();db.getAllNodes().stream().map(n -> n.getProperty("msg")).forEach(m -> System.out.println("Msg: " + m));db.shutdown();}}
This Main class will start an embedded Neo4j server. Next it will start a transaction and create two nodes . Next all nodes are retrieved, and the value of the msg property is printed to the console. Neo4j is good at traversing relations between nodes. It is especially optimized for that (just like other Graph data stores).
Let’s create some nodes that have a relationship between them.
package com.apress.springrecipes.nosql;import org.neo4j.graphdb.*;import org.neo4j.graphdb.factory.GraphDatabaseFactory;import java.nio.file.Paths;import static com.apress.springrecipes.nosql.Main.RelationshipTypes.*;public class Main {enum RelationshipTypes implements RelationshipType {FRIENDS_WITH, MASTER_OF, SIBLING, LOCATION}public static void main(String[] args) {final String DB_PATH = System.getProperty("user.home") + "/friends";final GraphDatabaseService db = new GraphDatabaseFactory() .newEmbeddedDatabase(Paths.get(DB_PATH).toFile());final Label character = Label.label("character");final Label planet = Label.label("planet");try (Transaction tx1 = db.beginTx()) {// PlanetsNode dagobah = db.createNode(planet);dagobah.setProperty("name", "Dagobah");Node tatooine = db.createNode(planet);tatooine.setProperty("name", "Tatooine");Node alderaan = db.createNode(planet);alderaan.setProperty("name", "Alderaan");// CharactersNode yoda = db.createNode(character);yoda.setProperty("name", "Yoda");Node luke = db.createNode(character);luke.setProperty("name", "Luke Skywalker");Node leia = db.createNode(character);leia.setProperty("name", "Leia Organa");Node han = db.createNode(character);han.setProperty("name", "Han Solo");// Relationsyoda.createRelationshipTo(luke, MASTER_OF);yoda.createRelationshipTo(dagobah, LOCATION);luke.createRelationshipTo(leia, SIBLING);luke.createRelationshipTo(tatooine, LOCATION);luke.createRelationshipTo(han, FRIENDS_WITH);leia.createRelationshipTo(han, FRIENDS_WITH);leia.createRelationshipTo(alderaan, LOCATION);tx1.success();}Result result = db.execute("MATCH (n) RETURN n.name as name");result.stream().flatMap(m -> m.entrySet().stream()).map(row -> row.getKey() + " : " + row.getValue() + ";").forEach(System.out::println);db.shutdown();}}
The code reflects a tiny part of the Star Wars universe. It has characters and their locations, which are actually planets. There are also relations between people (see Figure 12-4 for the relationship diagram ).
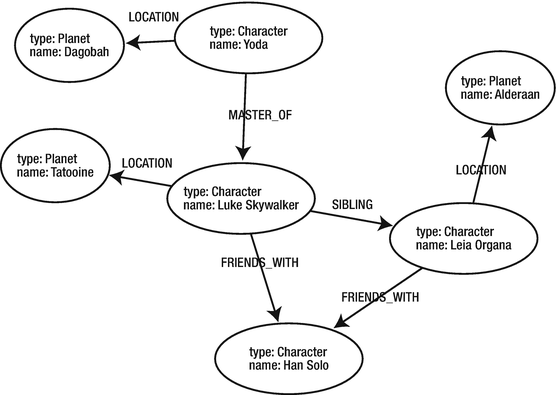
Figure 12-4. Relationship sample
The relationships in the code are enabled by using an enum that implements a Neo4j interface called RelationshipType. This is, as the name suggests, needed to differentiate between the different types of relationships. The type of node is differentiated by putting a label on the node. The name is set as a basic property on the node. When running the code, it will execute the cypher query MATCH (n) RETURN n.name as name. This selects all nodes and returns the name property of all the nodes.
Map Objects with Neo4j
The code until now is quite low level and bound to plain Neo4j. Creating and manipulating nodes is cumbersome. Ideally, you would use a Planet class and a Character class and have them stored/retrieved from Neo4j. First create the Planet and Character classes .
package com.apress.springrecipes.nosql;public class Planet {private long id = -1;private String name;// Getters and Setters omitted}package com.apress.springrecipes.nosql;import java.util.ArrayList;import java.util.Collections;import java.util.List;public class Character {private long id = -1;private String name;private Planet location;private final List<Character> friends = new ArrayList<>();private Character apprentice;public void addFriend(Character friend) {friends.add(friend);}// Getters and Setters omitted}
The Planet class is quite straightforward. It has id and name properties. The Character class is a bit more complicated. It also has the id and name properties along with some additional properties for the relationships. There is the location value for the LOCATION relationship, a collection of Characters for the FRIENDS_WITH relationship, and also an apprentice for the MASTER_OF relationship.
To be able to store these classes, let’s create a StarwarsRepository interface to hold the save operations.
package com.apress.springrecipes.nosql;public interface StarwarsRepository {Planet save(Planet planet);Character save(Character character);}
Here’s the implementation for Neo4j:
package com.apress.springrecipes.nosql;import org.neo4j.graphdb.GraphDatabaseService;import org.neo4j.graphdb.Label;import org.neo4j.graphdb.Node;import org.neo4j.graphdb.Transaction;import static com.apress.springrecipes.nosql.RelationshipTypes.*;public class Neo4jStarwarsRepository implements StarwarsRepository {private final GraphDatabaseService db;public Neo4jStarwarsRepository(GraphDatabaseService db) {this.db = db;}@Overridepublic Planet save(Planet planet) {if (planet.getId() != null) {return planet;}try (Transaction tx = db.beginTx()) {Label label = Label.label("planet");Node node = db.createNode(label);node.setProperty("name", planet.getName());tx.success();planet.setId(node.getId());return planet;}}@Overridepublic Character save(Character character) {if (character.getId() != null) {return character;}try (Transaction tx = db.beginTx()) {Label label = Label.label("character");Node node = db.createNode(label);node.setProperty("name", character.getName());if (character.getLocation() != null) {Planet planet = character.getLocation();planet = save(planet);node.createRelationshipTo(db.getNodeById(planet.getId()), LOCATION);}for (Character friend : character.getFriends()) {friend = save(friend);node.createRelationshipTo(db.getNodeById(friend.getId()), FRIENDS_WITH);}if (character.getApprentice() != null) {save(character.getApprentice());node.createRelationshipTo(db.getNodeById(character.getApprentice().getId()), MASTER_OF);}tx.success();character.setId(node.getId());return character;}}}
There is a whole lot going on here to convert the objects into a Node object. For the Planet object, it is pretty easy. First check whether it has already been persisted (the ID is greater than -1 in that case); if not, start a transaction, create a node, set the name property, and transfer the id value to the Planet object . However, for the Character class, it is a bit more complicated as all the relationships need to be taken into account.
The Main class needs to be modified to reflect the changes to the classes.
package com.apress.springrecipes.nosql;import org.neo4j.graphdb.GraphDatabaseService;import org.neo4j.graphdb.Result;import org.neo4j.graphdb.Transaction;import org.neo4j.graphdb.factory.GraphDatabaseFactory;import java.nio.file.Paths;public class Main {public static void main(String[] args) {final String DB_PATH = System.getProperty("user.home") + "/starwars";final GraphDatabaseService db = new GraphDatabaseFactory().newEmbeddedDatabase(Paths.get(DB_PATH).toFile());StarwarsRepository repository = new Neo4jStarwarsRepository(db);try (Transaction tx = db.beginTx()) {// PlanetsPlanet dagobah = new Planet();dagobah.setName("Dagobah");Planet alderaan = new Planet();alderaan.setName("Alderaan");Planet tatooine = new Planet();tatooine.setName("Tatooine");dagobah = repository.save(dagobah);repository.save(alderaan);repository.save(tatooine);// CharactersCharacter han = new Character();han.setName("Han Solo");Character leia = new Character();leia.setName("Leia Organa");leia.setLocation(alderaan);leia.addFriend(han);Character luke = new Character();luke.setName("Luke Skywalker");luke.setLocation(tatooine);luke.addFriend(han);luke.addFriend(leia);Character yoda = new Character();yoda.setName("Yoda");yoda.setLocation(dagobah);yoda.setApprentice(luke);repository.save(han);repository.save(luke);repository.save(leia);repository.save(yoda);tx.success();}Result result = db.execute("MATCH (n) RETURN n.name as name");result.stream().flatMap(m -> m.entrySet().stream()).map(row -> row.getKey() + " : " + row.getValue() + ";").forEach(System.out::println);db.shutdown();}}
When executing, the result should still be the same as before. However, the main difference is now that the code is using domain objects instead of working directly with nodes. Storing the objects as nodes in Neo4j is quite cumbersome. Luckily, Spring Data Neo4j can help to make it a lot easier.
Map Objects Using Neo4j OGM
In the conversion to nodes and relationships, properties can be quite cumbersome. Wouldn’t it be nice if you could simply specify what to store where using annotations, just as is done using JPA? Neo4j OGM offers those annotations. To make an object a Neo4j mapped entity, use the @NodeEntity annotation on the type. Relationships can be modeled with the @Relationship annotation. To identify the field used for the ID, add the @GraphId annotation. Applying these to the Planet and Character classes would make them look like the following:
package com.apress.springrecipes.nosql;import org.neo4j.ogm.annotation.GraphId;import org.neo4j.ogm.annotation.NodeEntity;@NodeEntitypublic class Planet {@GraphIdprivate Long id;private String name;// Getters/setters omitted}
Here’s the Character class:
package com.apress.springrecipes.nosql;import org.neo4j.ogm.annotation.GraphId;import org.neo4j.ogm.annotation.NodeEntity;import org.neo4j.ogm.annotation.Relationship;import java.util.Collections;import java.util.HashSet;import java.util.Objects;import java.util.Set;@NodeEntitypublic class Character {@GraphIdprivate Long id;private String name;@Relationship(type = "LOCATION")private Planet location;@Relationship(type="FRIENDS_WITH")private final Set<Character> friends = new HashSet<>();@Relationship(type="MASTER_OF")private Character apprentice;// Getters / Setters omitted}
Now that the entities are annotated, the repository can be rewritten to use SessionFactory and Session for easier access.
package com.apress.springrecipes.nosql;import org.neo4j.ogm.model.Result;import org.neo4j.ogm.session.Session;import org.neo4j.ogm.session.SessionFactory;import org.neo4j.ogm.transaction.Transaction;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Repository;import javax.annotation.PreDestroy;import java.util.Collections;@Repositorypublic class Neo4jStarwarsRepository implements StarwarsRepository {private final SessionFactory sessionFactory;@Autowiredpublic Neo4jStarwarsRepository(SessionFactory sessionFactory) {this.sessionFactory = sessionFactory;}@Overridepublic Planet save(Planet planet) {Session session = sessionFactory.openSession();try (Transaction tx = session.beginTransaction()) {session.save(planet);return planet;}}@Overridepublic Character save(Character character) {Session session = sessionFactory.openSession();try (Transaction tx = session.beginTransaction()) {session.save(character);return character;}}@Overridepublic void printAll() {Session session = sessionFactory.openSession();Result result = session.query("MATCH (n) RETURN n.name as name", Collections.emptyMap(), true);result.forEach(m -> m.entrySet().stream().map(row -> row.getKey() + " : " + row.getValue() + ";").forEach(System.out::println));}}
There are a couple of things to notice: the code is a lot cleaner when using SessionFactory and Session as a lot of the plumping is done for you, especially mapping from and to nodes. The final thing to note is the addition of the printAll method. It has been added to move the code from the Main class to the repository.
The next class to modify is the Main class as it now needs to construct a SessionFactory. To construct a SessionFactory, you need to specify which packages it needs to scan for @NodeEntity annotated classes.
package com.apress.springrecipes.nosql;import org.neo4j.ogm.session.SessionFactory;public class Main {public static void main(String[] args) {SessionFactory sessionFactory = new SessionFactory("com.apress.springrecipes.nosql");StarwarsRepository repository = new Neo4jStarwarsRepository(sessionFactory);// PlanetsPlanet dagobah = new Planet();dagobah.setName("Dagobah");Planet alderaan = new Planet();alderaan.setName("Alderaan");Planet tatooine = new Planet();tatooine.setName("Tatooine");dagobah = repository.save(dagobah);repository.save(alderaan);repository.save(tatooine);// CharactersCharacter han = new Character();han.setName("Han Solo");Character leia = new Character();leia.setName("Leia Organa");leia.setLocation(alderaan);leia.addFriend(han);Character luke = new Character();luke.setName("Luke Skywalker");luke.setLocation(tatooine);luke.addFriend(han);luke.addFriend(leia);Character yoda = new Character();yoda.setName("Yoda");yoda.setLocation(dagobah);yoda.setApprentice(luke);repository.save(han);repository.save(luke);repository.save(leia);repository.save(yoda);repository.printAll();sessionFactory.close();}}
A SessionFactory is created and used to construct a Neo4jStarwarsRepository. Next the data is being set up, and the printAll method is called. The code that was there initially is now in that method. The end result should still be similar to what you got until now.
Use Spring for Configuration
Up until now everything was manually configured and wired. Let’s create a Spring configuration class .
package com.apress.springrecipes.nosql;import org.neo4j.ogm.session.SessionFactory;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;@Configurationpublic class StarwarsConfig {@Beanpublic SessionFactory sessionFactory() {return new SessionFactory("com.apress.springrecipes.nosql");}@Beanpublic Neo4jStarwarsRepository starwarsRepository(SessionFactory sessionFactory) {return new Neo4jStarwarsRepository(sessionFactory);}}
Both SessionFactory and Neo4jStarwarsRepository are Spring managed beans now. You can now let the Main class use this configuration to bootstrap an ApplicationContext and retrieve the StarwarsRepository from it.
package com.apress.springrecipes.nosql;import org.springframework.context.annotation.AnnotationConfigApplicationContext;public class Main {public static void main(String[] args) {AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(StarwarsConfig.class);StarwarsRepository repository = context.getBean(StarwarsRepository.class);// PlanetsPlanet dagobah = new Planet();dagobah.setName("Dagobah");Planet alderaan = new Planet();alderaan.setName("Alderaan");Planet tatooine = new Planet();tatooine.setName("Tatooine");dagobah = repository.save(dagobah);repository.save(alderaan);repository.save(tatooine);// CharactersCharacter han = new Character();han.setName("Han Solo");Character leia = new Character();leia.setName("Leia Organa");leia.setLocation(alderaan);leia.addFriend(han);Character luke = new Character();luke.setName("Luke Skywalker");luke.setLocation(tatooine);luke.addFriend(han);luke.addFriend(leia);Character yoda = new Character();yoda.setName("Yoda");yoda.setLocation(dagobah);yoda.setApprentice(luke);repository.save(han);repository.save(luke);repository.save(leia);repository.save(yoda);repository.printAll();context.close();}}
It is still largely the same. The main difference is that now Spring is in control of the life cycle of the beans.
Spring Data Neo4j also provides a Neo4jTransactionManager implementation , which takes care of starting and stopping a transaction for you, just like the other PlatformTransactionManager implementations do. First let’s modify the configuration to include it and to add @EnableTransactionManagement.
package com.apress.springrecipes.nosql;import org.neo4j.ogm.session.SessionFactory;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.data.neo4j.transaction.Neo4jTransactionManager;import org.springframework.transaction.annotation.EnableTransactionManagement;@Configuration@EnableTransactionManagementpublic class StarwarsConfig {@Beanpublic SessionFactory sessionFactory() {return new SessionFactory("com.apress.springrecipes.nosql");}@Beanpublic Neo4jStarwarsRepository starwarsRepository(SessionFactory sessionFactory) {return new Neo4jStarwarsRepository(sessionFactory);}@Beanpublic Neo4jTransactionManager transactionManager(SessionFactory sessionFactory) {return new Neo4jTransactionManager(sessionFactory);}}
With this in place, you can now further clean up the Neo4jStarwarsRepository class .
package com.apress.springrecipes.nosql;import org.neo4j.ogm.model.Result;import org.neo4j.ogm.session.Session;import org.neo4j.ogm.session.SessionFactory;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Repository;import org.springframework.transaction.annotation.Transactional;import javax.annotation.PreDestroy;import java.util.Collections;@Repository@Transactionalpublic class Neo4jStarwarsRepository implements StarwarsRepository {private final SessionFactory sessionFactory;@Autowiredpublic Neo4jStarwarsRepository(SessionFactory sessionFactory) {this.sessionFactory = sessionFactory;}@Overridepublic Planet save(Planet planet) {Session session = sessionFactory.openSession();session.save(planet);return planet;}@Overridepublic Character save(Character character) {Session session = sessionFactory.openSession();session.save(character);return character;}@Overridepublic void printAll() {Session session = sessionFactory.openSession();Result result = session.query("MATCH (n) RETURN n.name as name", Collections.emptyMap(), true);result.forEach(m -> m.entrySet().stream().map(row -> row.getKey() + " : " + row.getValue() + ";").forEach(System.out::println));}@PreDestroypublic void cleanUp() {Session session = sessionFactory.openSession();session.query("MATCH (n) OPTIONAL MATCH (n)-[r]-() DELETE n,r", null);}}
The Main class can remain as is, and storing and querying should still work as before.
Use Spring Data Neo4j Repositories
The code has been simplified considerably. The usage of the SessionFactory and Session made it a lot easier to work with entities with Neo4j. It can be even easier. As with the JPA or Mongo version of Spring Data, it can generate repositories for you. The only thing you need to do is write an interface. Let’s create PlanetRepository and CharacterRepository classes to operate on the entities.
package com.apress.springrecipes.nosql;import org.springframework.data.repository.CrudRepository;public interface CharacterRepository extends CrudRepository<Character, Long> {}
Here’s PlanetRepository:
package com.apress.springrecipes.nosql;import org.springframework.data.repository.CrudRepository;public interface PlanetRepository extends CrudRepository<Planet, Long> {}
The repositories all extend CrudRepository, but it could also have been PagingAndSortingRepository or the special Neo4jRepository interface. For the recipe, CrudRepository is sufficient.
Next, rename StarwarsRepository and its implementation to StarwarsService because it isn’t really a repository anymore; the implementation also needs to change to operate on the repositories instead of the SessionFactory.
package com.apress.springrecipes.nosql;import org.springframework.stereotype.Service;import org.springframework.transaction.annotation.Transactional;import javax.annotation.PreDestroy;@Service@Transactionalpublic class Neo4jStarwarsService implements StarwarsService {private final PlanetRepository planetRepository;private final CharacterRepository characterRepository;Neo4jStarwarsService(PlanetRepository planetRepository, CharacterRepository characterRepository) {this.planetRepository=planetRepository;this.characterRepository=characterRepository;}@Overridepublic Planet save(Planet planet) {return planetRepository.save(planet);}@Overridepublic Character save(Character character) {return characterRepository.save(character);}@Overridepublic void printAll() {planetRepository.findAll().forEach(System.out::println);characterRepository.findAll().forEach(System.out::println);}@PreDestroypublic void cleanUp() {characterRepository.deleteAll();planetRepository.deleteAll();}}
Now all operations are done on the specific repository interfaces. Those interfaces don’t create instances themselves. To enable the creation, the @EnableNeo4jRepositories annotations need to be added to the configuration class. Also, add an @ComponentScan to have StarwarsService detected and autowired.
@Configuration@EnableTransactionManagement@EnableNeo4jRepositories@ComponentScanpublic class StarwarsConfig { ... }
Notice the @EnableNeo4jRepositories annotation. This annotation will scan the configured base packages for repositories. When one is found, a dynamic implementation is created, and this implementation eventually delegates to SessionFactory.
Finally, modify the Main class to use the refactored StarwarsService.
package com.apress.springrecipes.nosql;import com.apress.springrecipes.nosql.config.StarwarsConfig;import org.springframework.context.annotation.AnnotationConfigApplicationContext;public class Main {public static void main(String[] args) {AnnotationConfigApplicationContext context =new AnnotationConfigApplicationContext(StarwarsConfig.class);StarwarsService service = context.getBean(StarwarsService.class);...}}
Now all the components have been changed to use the dynamically created Spring Data Neo4j repositories.
Connect to a Remote Neo4j Database
Until now all the coding for Neo4j has been done to an embedded Neo4j instance; however, at the beginning, you downloaded and installed Neo4j. Let’s change the configuration to connect to that remote Neo4j instance.
package com.apress.springrecipes.nosql;import org.neo4j.ogm.session.SessionFactory;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.ComponentScan;import org.springframework.context.annotation.Configuration;import org.springframework.data.neo4j.repository.config.EnableNeo4jRepositories;import org.springframework.data.neo4j.transaction.Neo4jTransactionManager;import org.springframework.transaction.annotation.EnableTransactionManagement;@Configuration@EnableTransactionManagement@EnableNeo4jRepositories@ComponentScanpublic class StarwarsConfig {@Beanpublic org.neo4j.ogm.config.Configuration configuration() {return new org.neo4j.ogm.config.Configuration.Builder().uri("bolt://localhost").build();}@Beanpublic SessionFactory sessionFactory() {return new SessionFactory(configuration(),"com.apress.springrecipes.nosql");}@Beanpublic Neo4jTransactionManager transactionManager(SessionFactory sessionFactory) {return new Neo4jTransactionManager(sessionFactory);}}
There is now a Configuration object that is used by SessionFactory; you can either use new Configuration or use a Builder to construct the Configuration object. You need to specify the URI of the Neo4j server. In this case, that is localhost. The default driver is the Bolt driver, which uses a binary protocol to transfer data. HTTP(S) could also be used, but another dependency is needed for that. The created Configuration object is used by SessionFactory to configure itself.
12-4. Use Couchbase
Problem
You want to use Couchbase in your application to store documents.
Solution
First download, install, and set up Couchbase; then use the Spring Data Couchbase project to store and retrieve documents from the data store.
How It Works
Before you can start using Couchbase you need to have an instance installed and up and running. When you have it running you will need to connect to it to be able to use the datastore for actual storage. You will start with a plain Couchbase based repository to show how to store and retrieve documents and graduatly move to Spring Data Couchbase and to close with a reactive version of the repository.
Download, Install, and Set Up Couchbase
After downloading and starting Couchbase, open your browser and go to http://localhost:8091. You should be greeted with a page similar to Figure 12-5. On that page, simply click the Setup button.

Figure 12-5. Installing Couchbase
On the next screen (see Figure 12-6), you can configure the cluster. You can either start a new one or join an existing cluster. For this recipe you will start a new cluster. Specify the memory limits and optionally the paths for the disk storage. For this recipe, it is enough to leave them to the defaults. Then click Next.

Figure 12-6. Installing Couchbase, cluster settings
Note
If you are running the Dockerized Couchbase, you need to reduce the data RAM quota as that is limited.
The next screen (Figure 12-7) allows you to select sample data to work with the default samples from Couchbase. As you aren’t needing it for this recipe, leave all unselected and click Next.

Figure 12-7. Installing Couchbase, sample buckets
The screen shown in Figure 12-8 allows you to create the default bucket. For this recipe just leave the settings as is and click Next.

Figure 12-8. Installing Couchbase, creating a default bucket
If you want to register the product, fill out the form and decide whether you want to be notified of software updates. You need to at least select the box to agree with the terms and conditions (Figure 12-9). Then for almost the last time, click Next.

Figure 12-9. Installing Couchbase, notifications and registration
Finally, you need to pick a username and password for the administrator account for the server. This recipe is using admin with a password of sr4-admin, but feel free to choose your own. See Figure 12-10.

Figure 12-10. Installing Couchbase, setting up an admin user
Store and Retrieve Documents with Couchbase
To store an object in Couchbase, you need to create a Document that can hold various types of content, like serializable objects, JSON, strings, dates, or binary data in the form of a Netty ByteBuf. However, the primary type of content is JSON. This way you can use it with other technologies as well. When using a SerializableDocument, you are restricting yourself to the usage of Java-based solutions.
However, before storing an object in Couchbase, you need to make a connection to the cluster. To connect to Couchbase, you need a Cluster to be able to access the Bucket you created while doing the setup for Couchbase. You can use the CouchbaseCluster class to create a connection to the earlier setup cluster. The resulting Cluster can be used to open a Bucket with the openBucket() method . For this recipe, you are going to use the default bucket and simplest cluster setup.
First, create a Vehicle class (or reuse the one from recipe 12-1), which you are going to store in Couchbase.
package com.apress.springrecipes.nosql;import java.io.Serializable;public class Vehicle implements Serializable {private String vehicleNo;private String color;private int wheel;private int seat;public Vehicle() {}public Vehicle(String vehicleNo, String color, int wheel, int seat) {this.vehicleNo = vehicleNo;this.color = color;this.wheel = wheel;this.seat = seat;}public String getColor() {return color;}public int getSeat() {return seat;}public String getVehicleNo() {return vehicleNo;}public int getWheel() {return wheel;}public void setColor(String color) {this.color = color;}public void setSeat(int seat) {this.seat = seat;}public void setVehicleNo(String vehicleNo) {this.vehicleNo = vehicleNo;}public void setWheel(int wheel) {this.wheel = wheel;}@Overridepublic String toString() {return "Vehicle [" +"vehicleNo='" + vehicleNo + ''' +", color='" + color + ''' +", wheel=" + wheel +", seat=" + seat +']';}}
Notice this part: implements Serializable. This is needed because you will use, at first, the SerializableDocument class from Couchbase to store the object.
To communicate with Couchbase, you will create a repository. First define the interface.
package com.apress.springrecipes.nosql;public interface VehicleRepository {void save(Vehicle vehicle);void delete(Vehicle vehicle);Vehicle findByVehicleNo(String vehicleNo);}
Here’s the implementation, which will store the Vehicle value using SerializableDocument:
package com.apress.springrecipes.nosql;import com.couchbase.client.java.Bucket;import com.couchbase.client.java.document.SerializableDocument;class CouchBaseVehicleRepository implements VehicleRepository {private final Bucket bucket;public CouchBaseVehicleRepository(Bucket bucket) {this.bucket=bucket;}@Overridepublic void save(Vehicle vehicle) {SerializableDocument vehicleDoc = SerializableDocument .create(vehicle.getVehicleNo(), vehicle);bucket.upsert(vehicleDoc);}@Overridepublic void delete(Vehicle vehicle) {bucket.remove(vehicle.getVehicleNo());}@Overridepublic Vehicle findByVehicleNo(String vehicleNo) {SerializableDocument doc = bucket.get(vehicleNo, SerializableDocument.class);if (doc != null) {return (Vehicle) doc.content();}return null;}}
The repository needs a Bucket for storing the documents; it is like the table of a database (a Bucket is like the table, and the Cluster more like the whole database). When storing the Vehicle, it is wrapped in a SerializableDocument, and the vehicleNo value is used as the ID; after that, the upsert method is called. This will either update or insert the document depending on whether it already exists.
Let’s create a Main class that stores and retrieves the data for a Vehicle in the bucket.
package com.apress.springrecipes.nosql;import com.couchbase.client.java.Bucket;import com.couchbase.client.java.Cluster;import com.couchbase.client.java.CouchbaseCluster;public class Main {public static void main(String[] args) {Cluster cluster = CouchbaseCluster.create();Bucket bucket = cluster.openBucket();CouchBaseVehicleRepository vehicleRepository = new CouchBaseVehicleRepository(bucket);vehicleRepository.save(new Vehicle("TEM0001", "GREEN", 3, 1));vehicleRepository.save(new Vehicle("TEM0004", "RED", 4, 2));System.out.println("Vehicle: " + vehicleRepository.findByVehicleNo("TEM0001"));System.out.println("Vehicle: " + vehicleRepository.findByVehicleNo("TEM0004"));bucket.remove("TEM0001");bucket.remove("TEM0004");bucket.close();cluster.disconnect();}}
First, a connection is made to the Cluster using the CouchbaseCluster.create() method . This will, by default, connect to the cluster on localhost. When using Couchbase in a production environment, you probably want to use one of the other create methods and pass in a list of hosts to connect to or to set even more properties using a CouchbaseEnvironment (to set things like queryTimeout, searchTimeout, etc.). For this recipe, it is enough to use the default Cluster. Next you need to specify the Bucket to use for storing and retrieving documents. As you will use the defaults, using cluster.openBucket() is enough. There are several other overloaded methods to specify a specific Bucket to use and to specify properties for the connection to the bucket (such as timeout settings, username/password, etc.).
The Bucket is used to create an instance of CouchbaseVehicleRepository. After that, two Vehicles are stored, retrieved, and removed again (as to leave no clutter from this recipe). Finally, the connections are closed.
Although you are now storing documents in CouchBase, there is one drawback: you are doing that using SerializableDocument, which is something CouchBase cannot use for indexing. In addition, it will only be readable from other Java-based clients and not using different languages (like JavaScript). Instead, it is recommended to use JsonDocument instead. Let’s rewrite CouchbaseVehicleRepository to reflect this.
package com.apress.springrecipes.nosql;import com.couchbase.client.java.Bucket;import com.couchbase.client.java.document.JsonDocument;import com.couchbase.client.java.document.json.JsonObject;class CouchbaseVehicleRepository implements VehicleRepository {private final Bucket bucket;public CouchbaseVehicleRepository(Bucket bucket) {this.bucket=bucket;}@Overridepublic void save(Vehicle vehicle) {JsonObject vehicleJson = JsonObject.empty().put("vehicleNo", vehicle.getVehicleNo()).put("color", vehicle.getColor()).put("wheels", vehicle.getWheel()).put("seat", vehicle.getSeat());JsonDocument vehicleDoc = JsonDocument.create(vehicle.getVehicleNo(), vehicleJson);bucket.upsert(vehicleDoc);}@Overridepublic void delete(Vehicle vehicle) {bucket.remove(vehicle.getVehicleNo());}@Overridepublic Vehicle findByVehicleNo(String vehicleNo) {JsonDocument doc = bucket.get(vehicleNo, JsonDocument.class);if (doc != null) {JsonObject result = doc.content();return new Vehicle(result.getString("vehicleNo"), result.getString("color"), result.getInt("wheels"), result.getInt("seat"));}return null;}}
Notice this code uses a JsonObject object and converts Vehicle to a JsonObject object, and vice versa. Running the Main class again should store, retrieve, and remove two documents from Couchbase again.
Converting to/from JSON can become quite cumbersome for larger object graphs, so instead of doing things manually, you could use a JSON library, like Jackson, to convert to/from JSON.
package com.apress.springrecipes.nosql;import com.couchbase.client.java.Bucket;import com.couchbase.client.java.document.JsonDocument;import com.couchbase.client.java.document.json.JsonObject;import com.fasterxml.jackson.core.JsonProcessingException;import com.fasterxml.jackson.databind.ObjectMapper;import java.io.IOException;class CouchbaseVehicleRepository implements VehicleRepository {private final Bucket bucket;private final ObjectMapper mapper;public CouchbaseVehicleRepository(Bucket bucket, ObjectMapper mapper) {this.bucket=bucket;this.mapper=mapper;}@Overridepublic void save(Vehicle vehicle) {String json = null;try {json = mapper.writeValueAsString(vehicle);} catch (JsonProcessingException e) {throw new RuntimeException("Error encoding JSON.", e);}JsonObject vehicleJson = JsonObject.fromJson(json);JsonDocument vehicleDoc = JsonDocument.create(vehicle.getVehicleNo(), vehicleJson);bucket.upsert(vehicleDoc);}@Overridepublic void delete(Vehicle vehicle) {bucket.remove(vehicle.getVehicleNo());}@Overridepublic Vehicle findByVehicleNo(String vehicleNo) {JsonDocument doc = bucket.get(vehicleNo, JsonDocument.class);if (doc != null) {JsonObject result = doc.content();try {return mapper.readValue(result.toString(), Vehicle.class);} catch (IOException e) {throw new RuntimeException("Error decoding JSON.", e);}}return null;}}
Now you use the powerful Jackson library for converting from/to JSON.
Use Spring
At the moment, everything is configured in the Main class. Let’s move the configuration parts to a CouchbaseConfiguration class and use it to bootstrap an application.
package com.apress.springrecipes.nosql;import com.couchbase.client.java.Bucket;import com.couchbase.client.java.Cluster;import com.couchbase.client.java.CouchbaseCluster;import com.fasterxml.jackson.databind.ObjectMapper;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;@Configurationpublic class CouchbaseConfiguration {@Bean(destroyMethod = "disconnect")public Cluster cluster() {return CouchbaseCluster.create();}@Beanpublic Bucket bucket(Cluster cluster) {return cluster.openBucket();}@Beanpublic ObjectMapper mapper() {return new ObjectMapper();}@Beanpublic CouchbaseVehicleRepository vehicleRepository(Bucket bucket, ObjectMapper mapper) {return new CouchbaseVehicleRepository(bucket, mapper);}}
Notice the destroyMethod method on the Cluster bean. This method will be invoked when the application shuts down. The close method on the Bucket will be called automatically as that is one of the predefined methods that is automatically detected. The construction of the CouchbaseVehicleRepository is still the same, but you now pass two Spring managed beans to it.
Modify the Main class to use CouchbaseConfiguration.
package com.apress.springrecipes.nosql;import org.springframework.context.ApplicationContext;import org.springframework.context.annotation.AnnotationConfigApplicationContext;public class Main {public static void main(String[] args) {ApplicationContext context = new AnnotationConfigApplicationContext(CouchbaseConfiguration.class);VehicleRepository vehicleRepository =context.getBean(VehicleRepository.class);vehicleRepository.save(new Vehicle("TEM0001", "GREEN", 3, 1));vehicleRepository.save(new Vehicle("TEM0004", "RED", 4, 2));System.out.println("Vehicle: " + vehicleRepository.findByVehicleNo("TEM0001"));System.out.println("Vehicle: " + vehicleRepository.findByVehicleNo("TEM0004"));vehicleRepository.delete(vehicleRepository.findByVehicleNo("TEM0001"));vehicleRepository.delete(vehicleRepository.findByVehicleNo("TEM0004"));}}
VehicleRepository is retrieved from the constructed ApplicationContext, and still there are Vehicle instances stored, retrieved, and removed from the Couchbase cluster.
Use Spring Data’s CouchbaseTemplate
Although using Couchbase from Java with Jackson for mapping JSON is pretty straightforward, it can become quite cumbersome with larger repositories or when using specific indexes and N1QL queries, not to mention if you want to integrate this in an application that has other means of storing data. The Spring Data Couchbase project contains a CouchbaseTemplate template, which takes away part of the plumping you are now doing in the repository, such as mapping to/from JSON but also converting exceptions into a DataAccessException. This makes it easier to integrate it with other data access technologies that are utilized with Spring.
First rewrite the repository to use CouchbaseTemplate.
package com.apress.springrecipes.nosql;import org.springframework.data.couchbase.core.CouchbaseTemplate;public class CouchbaseVehicleRepository implements VehicleRepository {private final CouchbaseTemplate couchbase;public CouchbaseVehicleRepository(CouchbaseTemplate couchbase) {this.couchbase = couchbase;}@Overridepublic void save(Vehicle vehicle) {couchbase.save(vehicle);}@Overridepublic void delete(Vehicle vehicle) {couchbase.remove(vehicle);}@Overridepublic Vehicle findByVehicleNo(String vehicleNo) {return couchbase.findById(vehicleNo, Vehicle.class);}}
Now the repository is reduced to just a couple of lines of code. To be able to store the Vehicle object, you need to annotate Vehicle; it needs to know which field to use for the ID.
package com.apress.springrecipes.nosql;import com.couchbase.client.java.repository.annotation.Field;import com.couchbase.client.java.repository.annotation.Id;import java.io.Serializable;public class Vehicle implements Serializable{@Idprivate String vehicleNo;@Fieldprivate String color;@Fieldprivate int wheel;@Fieldprivate int seat;// getters/setters omitted.}
The field vehicleNo has been annotated with the @Id annotation and the other fields with @Field. Although the latter isn’t required to do, it is recommended to specify it. You can also use the @Field annotation to specify a different name for the name of the JSON property, which can be nice if you need to map existing documents to Java objects.
Finally, you need to configure a CouchbaseTemplate template in the configuration class.
package com.apress.springrecipes.nosql;import com.couchbase.client.java.Bucket;import com.couchbase.client.java.Cluster;import com.couchbase.client.java.CouchbaseCluster;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.data.couchbase.core.CouchbaseTemplate;@Configurationpublic class CouchbaseConfiguration {@Bean(destroyMethod = "disconnect")public Cluster cluster() {return CouchbaseCluster.create();}@Beanpublic Bucket bucket(Cluster cluster) {return cluster.openBucket();}@Beanpublic CouchbaseVehicleRepository vehicleRepository(CouchbaseTemplate couchbaseTemplate) {return new CouchbaseVehicleRepository(couchbaseTemplate);}@Beanpublic CouchbaseTemplate couchbaseTemplate(Cluster cluster, Bucket bucket) {return new CouchbaseTemplate(cluster.clusterManager("default","").info(), bucket);}}
A CouchbaseTemplate object needs a Bucket, and it needs access to ClusterInfo, which can be obtained through ClusterManager; here you pass the name of the Bucket, which is default, and no password. Instead, you could have passed admin/sr4-admin as the username/password combination. Finally, the configured CouchbaseVehicleRepository instance is created with this configured template.
When running the Main class , access is still provided, and storing, retrieving, and removing still work.
To make configuration a little easier, Spring Data Couchbase provides a base configuration class, AbstractCouchbaseConfiguration, which you can extend so you don’t need to configure the Cluster, Bucket, or CouchbaseTemplate objects anymore.
package com.apress.springrecipes.nosql;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.data.couchbase.config.AbstractCouchbaseConfiguration;import org.springframework.data.couchbase.core.CouchbaseTemplate;import java.util.Collections;import java.util.List;@Configurationpublic class CouchbaseConfiguration extends AbstractCouchbaseConfiguration {@Overrideprotected List<String> getBootstrapHosts() {return Collections.singletonList("localhost");}@Overrideprotected String getBucketName() {return "default";}@Overrideprotected String getBucketPassword() {return "";}@Beanpublic CouchbaseVehicleRepository vehicleRepository(CouchbaseTemplate couchbaseTemplate) {return new CouchbaseVehicleRepository(couchbaseTemplate);}}
The configuration now extends the AbstractCouchbaseConfiguration base class, and you only need to provide the name of the bucket, an optional password, and the list of hosts. The base configuration class provides CouchbaseTemplate and all the objects it needs.
Use Spring Data’s Couchbase Repositories
As with other technologies, Spring Data Couchbase provides the option to specify an interface and have an actual repository implementation available at runtime. This way, you only need to create an interface and not the concrete implementation. For this, like with other Spring Data projects, you need to extend CrudRepository. Note you could also extend CouchbaseRepository or CouchbasePagingAndSortingRepository if you need that functionality. For this recipe, you are going to use CrudRepository.
package com.apress.springrecipes.nosql;import org.springframework.data.repository.CrudRepository;public interface VehicleRepository extends CrudRepository<Vehicle, String> {}
As you can see, the interface has no more methods, as all the CRUD methods are provided already.
Next, an @EnableCouchbaseRepositories annotation is needed on the configuration class.
package com.apress.springrecipes.nosql;import org.springframework.context.annotation.Configuration;import org.springframework.data.couchbase.config.AbstractCouchbaseConfiguration;import org.springframework.data.couchbase.repository.config.EnableCouchbaseRepositories;import java.util.Collections;import java.util.List;@Configuration@EnableCouchbaseRepositories(public class CouchbaseConfiguration extends AbstractCouchbaseConfiguration { ... }
Finally, the Main class needs a minor modification because instead of findByVehicleNo, you need to use the findById method.
package com.apress.springrecipes.nosql;import org.springframework.context.ApplicationContext;import org.springframework.context.annotation.AnnotationConfigApplicationContext;public class Main {public static void main(String[] args) {ApplicationContext context = new AnnotationConfigApplicationContext(CouchbaseConfiguration.class);VehicleRepository vehicleRepository =context.getBean(VehicleRepository.class);vehicleRepository.save(new Vehicle("TEM0001", "GREEN", 3, 1));vehicleRepository.save(new Vehicle("TEM0004", "RED", 4, 2));vehicleRepository.findById("TEM0001").ifPresent(System.out::println);vehicleRepository.findById("TEM0004").ifPresent(System.out::println);vehicleRepository.deleteById("TEM0001");vehicleRepository.deleteById("TEM0004");}}
The findById method returns a java.util.Optional object, and as such you can use the ifPresent method to print it to the console.
Use Spring Data’s Reactive Couchbase Repositories
In addition to the blocking repositories, it is possible to utilize ReactiveCouchbaseRepository to get a reactive repository. It will now return a Mono for zero or one returning methods such as findById, and it will return a Flux for methods returning zero or more elements, such as findAll. The default Couchbase driver already has reactive support built in. To be able to use this, you need to have the RxJava and RxJava reactive streams on your classpath. To be able to use the reactive types from ReactiveCouchbaseRepository, you also need Pivotal Reactor on your classpath.
To configure reactive repositories for Couchbase, modify CouchbaseConfiguration. Let it extend AbstractReactiveCouchbaseConfiguration, and instead of @EnableCouchbaseRepositories, use @EnableReactiveCouchbaseRepositories.
package com.apress.springrecipes.nosql;import org.springframework.context.annotation.Configuration;import org.springframework.data.couchbase.config.AbstractReactiveCouchbaseConfiguration;import org.springframework.data.couchbase.repository.config.EnableReactiveCouchbaseRepositories;import java.util.Collections;import java.util.List;@Configuration@EnableReactiveCouchbaseRepositoriespublic class CouchbaseConfiguration extends AbstractReactiveCouchbaseConfiguration {@Overrideprotected List<String> getBootstrapHosts() {return Collections.singletonList("localhost");}@Overrideprotected String getBucketName() {return "default";}@Overrideprotected String getBucketPassword() {return "";}}
The remainder of the configuration remains the same as compared to the regular Couchbase configuration; you still need to connect to the same Couchbase server and use the same Bucket.
Next, the VehicleRepository should extend ReactiveCrudRepository instead of CrudRepository.
package com.apress.springrecipes.nosql;import org.springframework.data.repository.reactive.ReactiveCrudRepository;public interface VehicleRepository extends ReactiveCrudRepository<Vehicle, String> {}
This is basically all that is needed to get a reactive repository. To be able to test this, you also need to modify the Main class.
package com.apress.springrecipes.nosql;import org.springframework.context.ApplicationContext;import org.springframework.context.annotation.AnnotationConfigApplicationContext;import reactor.core.publisher.Flux;import reactor.core.publisher.Mono;import java.util.Arrays;import java.util.concurrent.CountDownLatch;public class Main {public static void main(String[] args) throws InterruptedException {ApplicationContext context = new AnnotationConfigApplicationContext(CouchbaseConfiguration.class);VehicleRepository repository =context.getBean(VehicleRepository.class);CountDownLatch countDownLatch = new CountDownLatch(1);repository.saveAll(Flux.just(new Vehicle("TEM0001", "GREEN", 3, 1), //new Vehicle("TEM0004", "RED", 4, 2))).last().log().then(repository.findById("TEM0001")).doOnSuccess(System.out::println).then(repository.findById("TEM0004")).doOnSuccess(System.out::println).then(repository.deleteById(Flux.just("TEM0001", "TEM00004"))).doOnSuccess(x -> countDownLatch.countDown()).doOnError(t -> countDownLatch.countDown()).subscribe();countDownLatch.await();}}
Creating the ApplicationContext and obtaining the VehicleRepository isn’t any different. However, after that, you have a chain of method calls, one following the other. First you add two Vehicle instances to the data store. When the last one has been saved, you will query the repository for each instance. When that is done, everything is deleted again. For everything to be able to complete, you could either block with block() or wait yourself. Generally, using block() in a reactive system is something you want to avoid. That is why you are using CountDownLatch; when the deleteById method completes, the CountDownLatch value is decremented. The countDownLatch.await() method waits until the counter reaches zero and then finishes the program.
Summary
In this recipe, you took an introductory journey into different types of data stores, including how to use them and how to make using them easier with different modules of the Spring Data family. You started out by looking at document-driven stores in the form of MongoDB and the usage of the Spring Data MongoDB module. Next the journey took you to key-value stores; you used Redis as an implementation and used the Spring Data Redis module. The final data store was a graph-based one called Neo4j, for which you explored the embedded Neo4j, how to use it, and how to build a repository for storing entities.
For two of the data stores, you also explored the reactive features by extending the reactive version of the interface as well as configuring the reactive drivers for those data stores.