
Chapter 14. Implementing Cybercrime Detection Techniques
Introduction
In the preceding chapter, we turned our focus from an analysis and explanation of cybercrime, who's involved in perpetrating such crimes, and underlying computer and networking security basics to an investigation of what's involved in countering potential threats—namely, we covered various aspects and areas in which it's essential to implement system, network, and communication security. Unfortunately, our security measures won't always work. Another important part of preparing for potential threats and related risks of criminal mischief, intrusion, or attack is being prepared to deal with the aftermath of a cybercrime and to start gathering the information that will be necessary to build a case for prosecution.
Once an attack has occurred or a system or network has been compromised, it's essential to be able to sift through the evidence of what's happened. From a technical information technology (IT) perspective, this means knowing how to find, recognize, and locate the visible evidence of a cybercrime. From a law enforcement perspective, this means knowing how to handle such evidence to make sure it will be admissible in court if necessary. However, these roles overlap somewhat. A good investigator also needs to know the technicalities of where and how evidence can be located, to properly put together the offense report and help the prosecutor formulate questions for witnesses. Likewise, the IT professional needs an understanding of how evidence must be treated to preserve its integrity in the eyes of the law.
In this chapter, we focus primarily on the former activity; we introduce various sources and potential types of evidence that investigators can gather to provide evidence of attempts to perpetrate cybercrimes. In some cases, this evidence may be collected whether the attempted crime succeeds or fails; in other cases, such evidence may be available only as a byproduct of a successful attack.
To some extent, computers and other network devices are capable of recording information about activity that occurs within them or passes through them. When evidence of cybercrime is needed, this kind of data can be an essential element in making a successful case or in making a decision to prosecute the people responsible. But as with so many other aspects of system and network security, it's necessary to understand the underlying technologies and software that must be put to work to make it possible to produce such evidence. It's also necessary to understand what this evidence looks like, how it may be interpreted, and what kinds of telltale signs or data to look for that could not only help document that a cybercrime was committed, but also help identify the responsible party or parties involved and prove to the satisfaction of a jury that they did it.
As we've noted elsewhere in this book, a lack of due diligence in protecting IT assets and information is very often involved in exposing companies and organizations to loss or harm. This loss or harm may occur as a result of either an insider attack (from an employee, consultant, or other person “in the know”) or of an attack mounted from outside the network boundary. We've also mentioned that there is no such thing as perfect security, so it's also necessary to concede that even a remote chance of successful attack, penetration, or compromise means that it's necessary to be able to monitor, detect, and react to security incidents if and when they occur.
Thus, an important part of the due diligence necessary in dealing with security matters is to be ready to perform subsequent analysis and investigations to determine causes and to identify perpetrators whenever possible. Whether or not an organization decides to prosecute a security incident is almost beside the point. To the organization and its IT professionals, the real value of understanding how to gather and interpret evidence of cybercrimes comes from the ability it confers to improve or harden security after the fact, to prevent any recurrence of the attacks or circumstances that permitted such crimes to occur in the first place.
Even if the company or organization never actually decides to pursue legal remedies for attempted or successful attacks, the ability to gather, interpret, and respond to the information inherent in the tracks and traces of such events is an essential part of a proper security regime. Finally, it's important to realize that maintaining proper system and network security requires active checks on how security policy is implemented and how well it's working to determine whether potential or actual vulnerabilities exist.
Think of this as a “how are we doing?” kind of check, security-wise, that acts not only to make sure that whatever security controls have been implemented match what a security policy requires, but also to repeatedly assess vulnerabilities to new security exploits and attack techniques as they occur. This is not unlike the continuous training and preparation for a violent confrontation that most police officers undergo on a regular basis. Even if there is no reason to expect violence, officers are always prepared for a situation to turn bad, and during and after any contact related to a call, officers are constantly monitoring the situation. Likewise, a savvy security professional knows that he or she must check the status of the network on a regular basis, if only to be sure nothing untoward or unexpected is in progress or has already happened. This empirical form of assessing security posture is a key ingredient in maintaining strong security at all times and is the first step in incident response.
Security Auditing and Log Files
An important concept in system and network security is what's often called the AAA, or “triple-A” model of security. In this case, the acronym is subject to several interpretations, including:
▪ Administration, authorization, and authentication
▪ Authentication, authorization, and accounting
Although both expansions of the acronym are pretty widespread, the second is the one that we use in this chapter.
The idea behind AAA is that strong security rests on a three-legged foundation in which:
▪ Authentication, as discussed in detail in Chapter 11, ensures that users, processes, and services that seek to consume system resources or access their contents provide sufficient proof of identity to enter systems and networks before any such requests may be issued.
▪ Authorization (sometimes also called access control) ensures that requests for resources will not be granted unless requesters have the permissions necessary not only to read or otherwise inspect the contents of the resources they want to access, but also that they have explicit permissions to perform the kind of operation they seek to perform on the resource. Some individuals may be granted read-only access to information to which they have no permissions to make changes (or to delete such information altogether), whereas other individuals may be granted the ability to modify or delete such information at will.
▪ Accounting relates to monitoring and tracking system activity. Some companies or organizations put a monetary value on computer resources, usage, and access. In this situation, accounting tracks such activity to assess so-called “chargebacks” for use of computer or network services based on actual consumption. But from a security standpoint, the other form of monitoring or tracking involved under the general heading of accounting is called auditing. As in its formal meaning in financial accounting, auditing means tracking access and use of resources—in this case, communication links, systems, networks, and related resources, so that activity may be logged. This auditing deposits tangible data into various kinds of computerized records so that they may be analyzed for all kinds of purposes after the fact. Such logs provide a key source of evidence in detecting and analyzing cybercrimes, whether only attempted or successfully completed.
Note that both authentication and authorization put various kinds of barriers or checks between users (or consumers) and the resources they seek to utilize. Only accounting tracks what actually happens on the networks and systems it monitors. Thus, accounting—or, more properly, auditing—is the essential activity that closes the loop between what is supposed to happen from a security standpoint and what actually occurs on the systems and networks to which authentication and authorization controls apply.
Auditing is a capability that's built into most computer operating systems and network devices. But because creating audit trails means generating files in which activity records may be stored, auditing is generally viewed as a discretionary form of tracking and monitoring, rather than something to be applied to all user activity and resource access across the board. A good general principle to apply when deciding whether to audit certain kinds of activity or access to specific resources is based on a careful assessment of the risks involved. In other words, it's wise to audit for potentially harmful or dangerous activities and for access to sensitive files and other resources. But it's also important to recognize that auditing everything is just as impractical as auditing nothing. These general exhortations will make more sense if we look at how certain operating systems handle auditing and what kinds of activities and accesses they can track and monitor. Following that discussion, we can generalize further about auditing and the trails that auditing leaves behind (usually called logs or log files) with a little more specificity and precision.
Auditing for Windows Platforms
Starting with the earliest versions of Windows NT, all installations of the Windows operating systems (with the exception of Windows 9x/Me) maintain three audit logs to track user and system activity. You can view these logs through the built-in Event Viewer utility:
▪ Application log Shows messages, status information, and events reported from applications and nonessential services on the Windows computer. (Note that some system services write to this log rather than to the System log.)
▪ System log Records errors, warnings, and information events generated by the Windows operating system itself and related core system services.
▪ Security log Displays success and failure records from audited activities. When you enable auditing and set specific auditing policies or settings in Windows, this is the log in which such items appear.
The last log is, of course, the one that is most obviously important for our purposes, although investigators should not ignore the other two. Relevant information, such as the starting or stopping of a service or abnormal behavior of an application, can be obtained from the Application and System logs as well.
Launching the Event Viewer varies by platform, but you can usually fins it under the Administrative Tools menu, as in Windows NT and 2000, or through the Microsoft Management Console (MMC) in Windows 2000, XP, and Vista, Windows Server 2003, and Windows Server 2008. The Event Viewer is a good starting point when investigating abnormal or unusual system activity and for monitoring system activity in general.
In Windows, Group Policy Objects, or GPOs, control the level of auditing performed by the operating system. Only someone logged on with an account with administrative-level permissions can enable auditing or establish audit policies. To enable auditing, you simply create a GPO and configure it to monitor success and failure for one or more of various classes of defined events. As shown in Figure 14.1, by using the Local Security Settings, you can edit the Audit Policy of the computer. In looking at this figure, you'll notice that by default, the audit policies are disabled, meaning that if you initially viewed the Security Log in the Event Viewer, it would be empty. To enable the policy, you would double-click on the event(s) you wanted to audit, and then choose whether to audit the success and/or failure of that event.
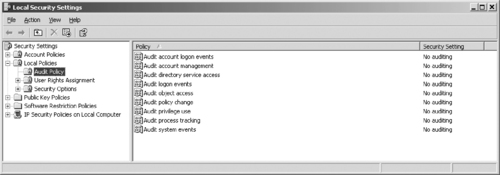 |
| Figure 14.1 Audit Policy on a Windows XP Computer |
Previous to Windows Vista and Windows Server 2008, nine classes of events or activities could be audited:
▪ Account logon events Use this to monitor user account logon activity.
▪ Account management Use this to monitor administrative account management activities (creating, deleting, disabling, or changing account settings).
▪ Directory service access Use this to monitor use of Active Directory services and objects.
▪ Logon events Use this to monitor all logon events for system accounts, service accounts, and user accounts (a superset of account logon events, in other words).
▪ Object access Use this to enable auditing of individual files, folders, printers, or other computer resources (which must also be configured for auditing individually and separately).
▪ Policy change Use this to monitor GPO creation, deletion, or modification. This tracks important administrative activities on Windows systems.
▪ Privilege use Use this to monitor use of user and administrative privileges on a Windows system. This also tracks important administrative activities on Windows systems, as well as object owner/creator and user use of privileges.
▪ Process tracking Use this to monitor process creation, threads, and deletion. This is seldom used for security purposes (but may sometimes be helpful).
▪ System events Use this to monitor operating system activities. This is also seldom used for security purposes.
In Windows Vista and Windows Server 2008, the number of audit policies increased from nine to 50. Each of the original nine has subcategories that allow you to audit events on a more granular level. Table 14.1 lists the policies and their subcategories.
Once audit policies have been enabled, the information captured from the audit is stored in the security log for viewing with the Event Viewer. Figure 14.2 shows a security log open in the Event Viewer. Note that successful and failed logon events are audited.
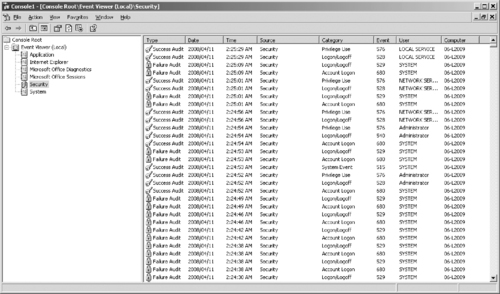 |
| Figure 14.2 The Security Log Showing Event Types for Which Auditing Is Enabled |
The profound trade-offs between auditing and system performance are manifested in at least two ways:
▪ The more objects and activities that are audited, the more impact that the collection and recording of such data will have on system performance and consumption of disk space (because all of those logged activities are written to files on disk).
▪ The more objects and activities that are audited, the more data administrators and investigators will have to dig through to find items of interest among the routine or benign events or activities that will also be recorded.
If a large amount of data is collected, however, all is not lost. You can configure the Event Viewer to filter logged events so that only certain event types (for example, only failures) or only events that originate with specific sources, users, or computers are displayed in the log. Other options include displaying only events that occurred on a specified date and/or time or within a specified period, or events in a certain category or that are marked with a specific event ID. Figure 14.3 shows the dialog box that is used to configure display filtering.
Designing Effective Audit Strategies
Ultimately, what the IT administrator chooses to audit depends on the kinds of activity that occur on the server or device in question, the kinds of attacks or intrusions that are anticipated, and the kinds of information or other assets the organization seeks to monitor (and protect). Thus, it might make sense to audit specific intrusion signatures at the periphery of the network (on firewalls, screening routers, application gateways, and so forth). But on those servers where sensitive files reside, it probably makes sense to audit access to such files, including attempted and successful accesses. In general, it's also a good idea to monitor administrative activities on all such devices (and to advertise that policy) so that IT professionals know they will be held accountable for all official (and unsanctioned) administrative activities they perform.
In some situations—perhaps when an account may be compromised—it may make sense to disable that account (and set up a new account for the old account's user), and then audit subsequent attempts to use the old account. This practice permits administrators to determine whether such activity originates inside or outside the local network boundary and can help to establish an intruder's identity.
The general principle at work here is to audit for suspicious activities, to track administrative activity, and to monitor information or assets of known value or interest. By combining these activities into the auditing strategy, it's easier to strike the right balance between audit data volume and the amount of useful information that can be discerned from that data.
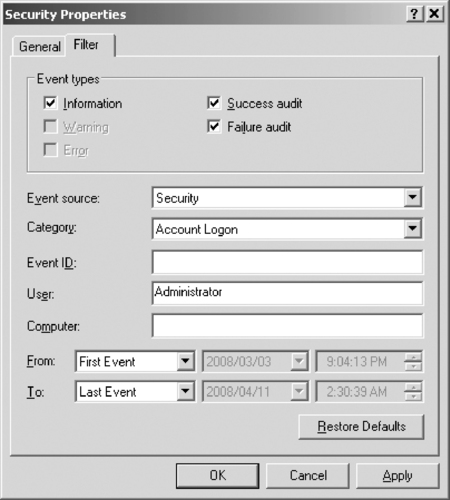 |
| Figure 14.3 Configuring Display Filtering to Display Only Specified Logged Events |
Auditing for UNIX and Linux Platforms
Every different distribution and version of UNIX and Linux logs critical audit information in its own unique way and stores the resultant log files in particular locations using specific platform-dependent formats. Nevertheless, most UNIX and Linux operating systems support extensive logging capabilities and share numerous common features.
The Syslog daemon (syslogd) is a clearinghouse for all kinds of log information on UNIX and Linux systems. The daemon is a process that diverts different system messages to different log files, depending on the type of message and how urgent or severe it is. For example, on a FreeBSD system, successful and failed File Transfer Protocol (FTP) logons are shown in the ftp.log file, information about access to Apache Web sites is stored in access_log, and information about failed logons resides in secure.log.
Most networks that incorporate UNIX or Linux systems also set up special network drives to record logging data, so it can all reside in a single centralized location. In addition, the Syslog daemon receives event data from various operating system and user applications (listed in Table 14.2); it also stores all log data using a single standardized format for easy interpretation and analysis. (The same consistency, alas, is not found for all logs on Windows systems, where the Event Viewer uses one format for its logs, but other applications and services use other formats.)
In fact, Syslog even prioritizes event or error messages according to a predefined scheme (listed in Table 14.3). Higher-priority messages appear at the top of this table, and lower-priority messages appear at the bottom of this table.
As mentioned previously, various specific UNIX or Linux log files store particular types of events or information. Thus, the loginlog records failed logon attempts, and the sulog records su (superuser) command activity on a specific system and identifies the user account where the activity originated. The utmp log identifies all users who are currently logged on to a system, and the wtmp log stores snapshots of utmp information at regular intervals. These are only some of the many log files you'll find on most Linux and UNIX systems; please consult your system documentation and man pages to obtain a complete listing of logging facilities, formats used, and (default) storage locations.
Firewall Logs, Reports, Alarms, and Alerts
In Chapter 12, we discussed the function of firewalls and the part they play in a network security plan. Because firewalls sit on the boundary between internal and external networks, they're ideally positioned to observe incoming (and outgoing) traffic. Thus, it should come as no surprise that firewalls not only represent a first and important line of defense to foil or deflect attack, but also that you can configure them to monitor and track activity that can point to incipient attacks as they commence. Unless attackers are savvy enough to erase log files (and alas, many are indeed smart enough to do this), firewall logs can also help you document successful or attempted attacks after the fact. Most boundary devices, which include not only firewalls but also screening routers, application gateways, proxy servers, and so forth, can—and indeed should—log various kinds of activity routinely. Given that such logs can be very important sources of evidence in cases where strong evidence is needed, most such devices log a wide range of traffic and various types of activity.
Because so many such devices run in UNIX-based or UNIX-like environments, the good news here is that the same information covered in the preceding section about the Syslog facility and general Linux or UNIX logging techniques often applies to firewalls, routers, and other devices. For example, even though Cisco devices run a Cisco proprietary operating system, known as the Internet Operating System or IOS, this software environment uses a reasonably standard Syslog implementation to support its logging capabilities. With the proviso in mind that low-level details vary from system to system and implementation to implementation, our general coverage of logging facilities and operation remains applicable to many (if not most) boundary devices in wide use.
Note
Add-on software products that can monitor and analyze firewall logs are available. For example, firelogd is a daemon that monitors Linux firewall logs. Fwanalog is a shell script that parses and summarizes firewall log files on UNIX and Linux systems. Stonylake Firewall Reporter is a server application that runs on Windows and Linux, and provides more than 150 reports to help in data analysis. ZoneLog Analyzer imports the logs from the ZoneAlarm firewalls into an easily queried database. Web Trends makes a Firewall Suite that processes log files from Check Point, Cisco, Microsoft ISA Server firewalls, and others.
Logging is only one of the ways in which firewalls and other boundary devices can provide information about the activity and traffic they handle. Firewalls (and other boundary devices) do indeed create log files, where all kinds of data may be written and stored for the long term. But these devices also support various types of other outputs, some of which can be quite important:
▪ Alarms These systems can be instructed to issue high-priority messages in various formats should particularly suspicious activities or events occur. Many such systems can send e-mail messages to specific respondents and even page designated telephone numbers, in addition to logging information when specified events occur. This functionality permits these systems to provoke immediate responses from responsible individuals. Because routers, firewalls, and other boundary devices may be subjected to ping floods or other denial-of-service (DoS) attacks, and because they may witness repeated failed logon attempts that can likewise signal that attacks have commenced, immediate action is sometimes essential in responding to such events.
▪ Alerts Some types of traffic activity are less obviously symptomatic of attack but should be looked into nonetheless. This explains why many boundary systems can also issue alerts when particular conditions occur. Although these alerts may also result in e-mail or pager calls, they are usually less urgent than outright alarms.
▪ Reports Although reportable events fall into the more mundane category of cataloging and categorizing traffic, activity, errors, and failed logon or other access attempts, most boundary devices can also report aggregate behavior and statistics over some specific period of time (daily, weekly, monthly, and so forth). Such reports are important indicators of overall system health and security and should be consulted regularly as part of the security monitoring and maintenance process.
In fact, most operating systems have some kind of alarm or alert facility as well. For example, Windows NT, 2000, XP, Vista, Server 2003, and Server 2008 support system alerts to alert administrators of system performance- or error-related events. Although the Event Viewer provides no way to configure alerts when security events occur, some third-party software packages such as IPSentry (www.ipsentry.com) monitor the Windows event logs and send alerts when triggering events occur.
When it comes to working with firewall logs (or responding to related alarms or alerts), some of the most common types of information you'll encounter relate directly to attacks and exploits documented elsewhere in this book. Thus, it should come as no surprise that the following types of activities or traffic might be noteworthy from both an attack detection and a post-attack perspective:
▪ Internet Control Message Protocol (ICMP) traffic Excessive pinging, ping scans, echo requests to broadcast address, ICMP time exceeded packets, distributed ICMP echo reply hits
▪ Regular, systematic scanning behavior Internet Protocol (IP) address range scanning, Transmission Control Protocol/User Datagram Protocol (TCP/UDP) port scans, NetBIOS name scans
▪ Attempts to access specific well-known port addresses Addresses associated with remote access software (pcAnywhere, Back Orifice [BO2K], and so forth), instant messaging (IM), or specific Trojan horse applications
In fact, any type of traffic or activity pattern—otherwise known as an attack signature, or more simply as a signature—that can be directly associated with a specific type or method of attack represents events that should be logged if at all possible. Sometimes recognizing a signature can involve more intelligence than a typical boundary device such as a firewall or screening router might possess, however. For that reason, we return to this subject later in this chapter when we discuss a class of systems known as intrusion detection systems, or IDSes, that are expressly built with this very kind of capability.
As to what kind of information occurs in a firewall log, it usually consists of fairly simple text records that document various aspects of network traffic underway. Though here again the details will vary to some extent, no log record is complete without including at least the following information (and usually more than appears in this deliberately brief list of common log entry fields):
▪ Timestamp Date and time at which the event, activity, or communication occurred
▪ Source address Reported IP address for traffic source
▪ Source domain name (if available) Reported domain name for traffic source
▪ Destination address Target delivery address for traffic
▪ Protocol Name of IP protocol or service in use
▪ Port address (where applicable) TCP or UDP port to which the message is directed
▪ Socket address (where applicable) Socket address to which the message is directed
In some cases, log entries also include what's called a reverse DNS lookup or a backtrace. You can configure some boundary devices to double-check the official IP address associated with domain names reported for inbound traffic against the actual IP address included in incoming traffic. When these two values differ, it can be a definite indicator of spoofing, which in turn may mean that suspicious activity (if not an outright attack) has ensued. This type of detection usually triggers an alert or alarm for that reason.
Commercial Intrusion Detection Systems
Earlier, we mentioned that firewalls and other simple boundary devices lack some degree of intelligence when it comes to observing, recognizing, and identifying attack signatures that may be present in the traffic they monitor and the log files they collect. Without sounding critical of such systems’ capabilities, this deficiency explains why intrusion detection systems (often abbreviated as IDSes) are becoming increasingly important in helping to maintain proper network security. Whereas other boundary devices may collect all the information necessary to detect (and often, to foil) attacks that may be getting started or may already be underway, they haven't been programmed to inspect for and detect the kinds of traffic or network behavior patterns that match known attack signatures or that suggest that potential unrecognized attacks may be incipient or in progress.
In a nutshell, the simplest way to define an IDS might be to describe it as a specialized tool that knows how to read and interpret the contents of log files from routers, firewalls, servers, and other network devices. Furthermore, an IDS often stores a database of known attack signatures and can compare patterns of activity, traffic, or behavior it sees in the logs it's monitoring against those signatures to recognize when a close match between a signature and current or recent behavior occurs. At that point, the IDS can issue alarms or alerts, take various kinds of automatic action ranging from shutting down Internet links or specific servers to launching backtraces, and make other active attempts to identify attackers and actively collect evidence of their nefarious activities.
By analogy, an IDS does for a network what an antivirus (AV) software package does for files that enter a system: It inspects the contents of network traffic to look for and deflect possible attacks, just as an AV software package inspects the contents of incoming files, e-mail attachments, active Web content, and so forth to look for virus signatures (patterns that match known malware) or for possible malicious actions (patterns of behavior that are at least suspicious, if not downright unacceptable).
To be more specific, intrusion detection means detecting unauthorized use of or attacks on a system or network. An IDS is designed and used to detect and then to deflect or deter (if possible) such attacks or unauthorized use of systems, networks, and related resources. Like firewalls, IDSes may be software-based or may combine hardware and software (in the form of preinstalled and preconfigured stand-alone IDS devices). Often, IDS software runs on the same devices or servers where firewalls, proxies, or other boundary services operate; an IDS not running on the same device or server where the firewall or other services are installed will monitor those devices closely and carefully. Although such devices tend to operate at network peripheries, IDS systems can detect and deal with insider attacks as well as external attacks.
Characterizing Intrusion Detection Systems
IDSes vary according to a number of criteria. By explaining those criteria, we can explain what kinds of IDSes you're likely to encounter and how they do their jobs. First and foremost, it's possible to distinguish IDSes on the basis of the kinds of activities, traffic, transactions, or systems they monitor. In this case, IDSes may be divided into network-based, host-based, and application-based IDS types. IDSes that monitor network backbones and look for attack signatures are called network-based IDSes, whereas those that operate on hosts to defend and monitor the operating and file systems for signs of intrusion are called host-based IDSes. Some IDSes monitor only specific applications and are called application-based IDSes. (This type of treatment is usually reserved for important applications such as database management systems, content management systems, accounting systems, and so forth.) Read on to learn more about these various types of IDS monitoring approaches:
▪ Network-based IDS characteristics
Pros: Network-based IDSes can monitor an entire, large network with only a few well-situated nodes or devices and impose little overhead on a network. Network-based IDSes are mostly passive devices that monitor ongoing network activity without adding significant overhead or interfering with network operation. They are easy to secure against attack and may even be undetectable to attackers; they also require little effort to install and use on existing networks.
Cons: Network-based IDSes may not be able to monitor and analyze all traffic on large, busy networks and may therefore overlook attacks launched during peak traffic periods. Network-based IDSes may not be able to monitor switch-based (high-speed) networks effectively, either. Typically, network-based IDSes cannot analyze encrypted data, nor do they report whether attempted attacks succeed or fail. Thus, network-based IDSes require a certain amount of active, manual involvement from network administrators to gauge the effects of reported attacks.
▪ Host-based IDS characteristics
Pros: A host-based IDS can analyze activities on the host it monitors at a high level of detail; it can often determine which processes and/or users are involved in malicious activities. Though they may each focus on a single host, many host-based IDSes use an agent-console model where agents run on (and monitor) individual hosts but report to a single centralized console (so that a single console can configure, manage, and consolidate data from numerous hosts). Host-based IDSes can detect attacks undetectable to the network-based IDS and can gauge attack effects quite accurately. Host-based IDSes can use host-based encryption services to examine encrypted traffic, data, storage, and activity. Host-based IDSes have no difficulties operating on switch-based networks, either.
Cons: Data collection occurs on a per-host basis; writing to logs or reporting activity requires network traffic and can decrease network performance. Clever attackers who compromise a host can also attack and disable host-based IDSes. Host-based IDSes can be foiled by DoS attacks (because they may prevent any traffic from reaching the host where they're running or prevent reporting on such attacks to a console elsewhere on a network). Most significantly, a host-based IDS does consume processing time, storage, memory, and other resources on the hosts where such systems operate.
▪ Application-based IDS characteristics
Pros: An application-based IDS concentrates on events occurring within some specific application. They often detect attacks through analysis of application log files and can usually identify many types of attacks or suspicious activity. Sometimes application-based IDSes can even track unauthorized activity from individual users. They can also work with encrypted data, using application-based encryption/decryption services.
Cons: Application-based IDSes are sometimes more vulnerable to attack than host-based IDSes. They can also consume significant application (and host) resources.
In practice, most commercial environments use some combination of network- and host- and/or application-based IDSes to observe what's happening on the network while also monitoring key hosts and applications more closely.
IDSes may also be distinguished by their differing approaches to event analysis. Some IDSes primarily use a technique called signature detection. This resembles the way many AV programs use virus signatures to recognize and block infected files, programs, or active Web content from entering a computer system, except that it uses a database of traffic or activity patterns related to known attacks, called attack signatures. Indeed, signature detection is the most widely used approach in commercial IDS technology today. Another approach is called anomaly detection. It uses rules or predefined concepts about “normal” and “abnormal” system activity (called heuristics) to distinguish anomalies from normal system behavior, and to monitor, report on, or block anomalies as they occur. Some IDSes support limited types of anomaly detection; most experts believe this kind of capability will become part of how more IDSes operate in the future. Read on for more information about these two kinds of event analysis techniques:
▪ Signature-based IDS characteristics
Pros: A signature-based IDS examines ongoing traffic, activity, transactions, or behavior for matches with known patterns of events specific to known attacks. As with AV software, a signature-based IDS requires access to a current database of attack signatures and some way to actively compare and match current behavior against a large collection of signatures. Except when entirely new, uncataloged attacks occur, this technique works extremely well.
Cons: Signature databases must be constantly updated, and IDSes must be able to compare and match activities against large collections of attack signatures. If signature definitions are too specific, a signature-based IDS may miss variations on known attacks. (A common technique for creating new attacks is to change existing, known attacks rather than to create entirely new ones from scratch.) Signature-based IDSes can also impose noticeable performance drags on systems when current behavior matches multiple (or numerous) attack signatures, either in whole or in part.
▪ Anomaly-based IDS characteristics
Pros: An anomaly-based IDS examines ongoing traffic, activity, transactions, or behavior for anomalies on networks or systems that may indicate attack. The underlying principle is the notion that “attack behavior” differs enough from “normal user behavior” that it can be detected by cataloging and identifying the differences involved. By creating baselines of normal behavior, anomaly-based IDSes can observe when current behavior deviates statistically from the norm. This capability theoretically gives anomaly-based IDSes capabilities to detect new attacks that are neither known nor for which signatures have been created.
Cons: Because normal behavior can change easily and readily, anomaly-based IDSes are prone to false positives where attacks may be reported based on changes to the norm that are “normal,” rather than representing real attacks. Their intensely analytical behavior can also impose sometimes-heavy processing overheads on systems where they're running. Furthermore, anomaly-based systems take awhile to create statistically significant baselines (to separate normal behavior from anomalies); they're relatively open to attack during this period.
Today, many AV packages include both signature-based and anomaly-based detection characteristics, but not all IDSes incorporate both approaches.
Finally, some IDSes are capable of responding to attacks when they occur. This behavior is desirable from two points of view. For one thing, a computer system can track behavior and activity in near-real time and respond much more quickly and decisively during early stages of an attack. Because automation helps hackers mount attacks, it stands to reason that it should also help security professionals fend them off as they occur. For another thing, IDSes run 24/7, but network administrators may not be able to respond as quickly during off hours as they can during peak hours (even if the IDS can page them with an alarm that an attack has begun). By automating a response to block incoming traffic from one or more addresses from which an attack originates, the IDS can halt an attack in process and block future attacks from the same address.
By implementing the following techniques, IDSes can fend off expert and novice hackers alike. Although experts are more difficult to block entirely, these techniques can slow them down considerably:
▪ Breaking TCP connections by injecting reset packets into attacker connections causes attacks to fall apart.
▪ Deploying automated packet filters to block routers or firewalls from forwarding attack packets to servers or hosts under attack stops most attacks cold—even DoS or distributed denial-of-service (DDoS) attacks. This works for attacker addresses and for protocols or services under attack (by blocking traffic at different layers of the Advanced Research Projects Agency [ARPA] networking model, so to speak).
▪ Deploying automated disconnects for routers, firewalls, or servers can halt all activity when other measures fail to stop attackers (as in extreme DDoS attack situations, where filtering would work effectively on only the Internet service provider [ISP] side of an Internet link, if not higher up the ISP chain, as close to Internet backbones as possible).
▪ Actively pursuing reverse DNS lookups or other ways of attempting to establish hacker identity is a technique used by some IDSes, generating reports of malicious activity to all ISPs in the routes used between the attacker and the attackee. Because such responses may themselves raise legal issues, experts recommend obtaining legal advice before repaying hackers in kind.
Note
For access to a great set of articles and resources on IDS technology, visit http://searchsecurity.techtarget.com and use the site's search engine to produce results on intrusion detection as a search string.
Commercial IDS Players
Literally hundreds of vendors offer various forms of commercial IDS implementations. Most effective solutions combine network- and host-based IDS implementations. Likewise, most such implementations are primarily signature-based, with only limited anomaly-based detection capabilities present in certain specific products or solutions. Finally, most modern IDSes include some limited automatic response capabilities, but these usually concentrate on automated traffic filtering, blocking, or disconnects as a last resort. Although some systems claim to be able to launch counterstrikes against attacks, best practices indicate that automated identification and backtrace facilities are the most useful aspects that such facilities provide and are therefore those most likely to be used.
A huge number of potential vendors can provide IDS products to companies and organizations. Without specifically endorsing any particular vendor, the following offer some of the most widely used and best-known solutions in this product space:
▪ Cisco Systems is perhaps best known for its switches and routers, but Cisco offers significant firewall and intrusion detection products as well (www.cisco.com).
▪ GFI LANguard is a family of monitoring, scanning, and file-integrity-check products that offer broad intrusion detection and response capabilities (www.gfi.com/languard).
▪ Network-1 Security Solutions offers various families of desktop and server (host-based) intrusion detection products, along with centralized security management facilities and firewalls (www.network-1.com).
▪ Tripwire is perhaps the best known of all vendors of file integrity and signature-checking utilities (which are also known as Tripwire). But Tripwire also offers integrity check products for routers, switches, and servers, along with a centralized management console for its various products (www.tripwire.com).
Weighing IDS Options
In addition to the various IDS vendors mentioned in the preceding list, judicious use of a good Internet search engine can help network administrators identify more potential IDS suppliers than they would ever have the time or inclination to investigate in detail. That's why we also urge administrators to consider an additional alternative: deferring some or all of the organization's network security technology decisions to a special type of outsourcing company. Known as managed security service providers, or MSSPs, these organizations can help their customers select, install, and maintain state-of-the-art security policies and technical infrastructures to match. Law enforcement professionals may find these organizations to be particularly knowledgeable sources for information, help, and support when tackling technology questions or teasing apart IT security puzzles.
IP Spoofing and Other Antidetection Tactics
Despite your best efforts to backtrace unwanted e-mail or attack traffic, sometimes you will still be unable to determine its real source or conclusively identify the person or persons behind that activity. The primary reason for the phenomenon is that hackers typically generate network traffic or messages that contain fabricated data for the source address, port numbers, protocol IDs, and other information that normally permits such information to be conclusively associated with an originating IP address, if not also an originating process identifier (and by extension, the user or service responsible for creating that process). This is a deliberate and calculated technique to prevent identification of attackers and to deflect interest from the real source of such traffic to unwitting or uninvolved third parties.
The most common form of spoofing occurs when attackers try to insert fabricated traffic or messages that purport to originate inside a local network through an outside interface. That explains why the most common antispoofing rule enforced at most screening routers and firewalls is to drop any packets that arrive on an external interface that report an originating address that should appear only on an internal interface. Other forms of spoofing may be detected by using a backtrace or reverse DNS lookup to compare domain names and associated IP addresses (when that data is available) and dropping all packets where these two information items show no correlation (as when the reported IP address originates outside the range of addresses assigned to the organization from within which it claims to originate).
The real problem with spoofed traffic occurs when IDS or human administrators try to follow the traffic back to its source and hit various types of dead ends. Recall, for example, that various types of DoS or DDoS attacks rely on compromised intermediate computers, sometimes called zombies or agents, and you'll quickly understand why tracing attacks back to their source can't always identify attackers. When you determine where certain attacks originate, you may only be able to identify other victims rather than finding a “smoking gun” which points to an attacker. The savvier and more sophisticated the hacker who perpetrates an attack, the less likely it is that he or she will provide direct clues that lead directly to his or her primary presence on the Internet. Rather, you'll find your identification efforts will lead you down a trail of intermediaries, cut-outs, and anonymizer services, each of which you must then investigate to look for clues to the identity of the mastermind behind the cybercrimes you are pursuing.
This also explains why contacting service providers who may be forwarding attacks—and working with them not only to trace back the origination of attack traffic, but also to block it from going through unwitting intermediaries—is an important part of the process of handling security incidents and fending off future attacks. In addition, numerous Web sites and Internet services maintain lists of known IP addresses, domain names, and e-mail addresses from which attacks have originated in the past. By subscribing to such services and using them to configure packet and e-mail filters, administrators can fend off many potential sources of attack preemptively—as many ISPs themselves do—and avoid interacting with known sources of trouble.
Numerous sources for information about spammers and attackers are available online; we mention only a couple of examples here. To find more, use a good Internet search engine to search on strings such as spam database, attacker database, spam prevention, and so forth:
▪ List of all known DNS-based spam databases: www.declude.com/junkmail/support/ip4r.htm
▪ Lists of spammers, harassers, mail bombers, and other e-mail abusers: www.ram.org/ramblings/philosophy/spam/spammers.html and www.spamhaus.org
Honeypots, Honeynets, and Other “Cyberstings”
Although the strategy involved in luring hackers to spend time investigating attractive network devices or servers can cause its own problems, finding ways to lure intruders into a system or network improves the odds that you might be able to identify those intruders and pursue them more effectively. A honeypot is a computer system that is deliberately exposed to public access—usually on the Internet—for the express purpose of attracting and distracting attackers. Likewise, a honeynet is a network set up for the same purpose, where attackers will find not only vulnerable services or servers, but also vulnerable routers, firewalls, and other network boundary devices, security applications, and so forth. In other words, these are the technical equivalent of the familiar police “sting” operation.
Walking the Line between Opportunity and Entrapment
Most law enforcement officers are aware of the fine line that they must walk when setting up a “sting”—an operation in which police officers pretend to be victims or participants in crime with the goal of getting criminal suspects to commit an illegal act in their presence. Most states have laws that prohibit entrapment; that is, law enforcement officers are not allowed to cause a person to commit a crime and then arrest him or her for doing it. Entrapment is a defense to prosecution; if the accused person can show at trial that he or she was entrapped, the result must be an acquittal.
Courts have traditionally held, however, that providing a mere opportunity for a criminal to commit a crime does not constitute entrapment. To entrap involves using persuasion, duress, or other undue pressure to force someone to commit a crime that the person would not otherwise have committed. Under this holding, setting up a honeypot or honeynet would be like the (perfectly legitimate) police tactic of placing an abandoned automobile by the side of the road and watching it to see whether anyone attempts to burglarize, vandalize, or steal it. It should also be noted that entrapment applies only to the actions of law enforcement or government personnel. A civilian cannot entrap, regardless of how much pressure is exerted on the target to commit the crime. (However, a civilian could be subject to other charges, such as criminal solicitation or criminal conspiracy, for causing someone else to commit a crime.)
The following characteristics are typical of honeypots or honeynets:
▪ Systems or devices used as lures are set up with only “out of the box” default installations so that they are deliberately made subject to all known vulnerabilities, exploits, and attacks.
▪ The systems or devices used as lures include no real sensitive information—such as passwords, data, applications, or services on which an organization must really depend or which it must absolutely protect—so these lures can be compromised, or even destroyed, without causing real damage, loss, or harm to the organization that presents them to be attacked.
▪ Systems or devices used as lures often also contain deliberately tantalizing objects or resources, such as files named password.db, folders named Top Secret, and so forth—often consisting only of encrypted garbage data or log files of no real significance or value—to attract and hold an attacker's interest long enough to give a backtrace a chance of identifying the attack's point of origin.
▪ Systems or devices used as lures also include or are monitored by passive applications that can detect and report on attacks or intrusions as soon as they start, so the process of backtracing and identification can begin as soon as possible.
Although this technique can certainly help identify the unwary or unsophisticated attacker, it also runs the risk of attracting additional attention or ire from savvier attackers. Honeypots or honeynets, once identified, are often publicized on hacker message boards or mailing lists and thus become more subject to attacks and hacker activity than they otherwise might. Likewise, if the organization that sets up a honeypot or honeynet is itself identified, its production systems and networks may also be subjected to more attacks than might otherwise be the case.
The honeypot technique is best reserved for use when a company or organization employs full-time IT security professionals who can monitor and deal with these lures on a regular basis, or when law enforcement operations seek to target specific suspects in a “virtual sting” operation. In such situations, the risks are sure to be well understood, and proper security precautions, processes, and procedures are far more likely to already be in place (and properly practiced). Nevertheless, for organizations that seek to identify and pursue attackers more proactively, honeypots and honeynets can provide valuable tools to aid in such activities.
Numerous quality resources on honeypots and honeynets are available on the Internet by searching on either term at http://searchsecurity.techtarget.com or www.techrepublic.com. The Honeynet Project at www.honeynet.org is probably the best overall resource on the topic online; it not only provides copious information on the project's work to define and document standard honeypots and honeynets, but it also does a great job of exploring hacker mindsets, motivations, tools, and attack techniques.
Summary
Why is cybercrime detection important to investigators? Only by detecting that cybercrimes have occurred (or are occurring) will investigators be able to get a step ahead of the criminals and start the investigation while the trail is still “hot.” Furthermore, only when suspicious activity is detected or observed do investigators know that they must take the steps necessary to obtain, secure, and prepare the evidence that will be necessary if any kind of legal charges are to stick. By following attack traffic from its targets back to its sources—even if those sources point only to other victims and not to the real attacker, as may often be the case—investigators can work with intermediate service providers to inform them about attacks and to help administrators and security personnel prevent such attacks from recurring. Even when prosecution isn't possible, or when those who have been attacked decide not to pursue legal remedies, the information obtained and shared during the investigation can still have an overall positive impact on the security posture and awareness of the various parties investigators contact in the process.
One key element in obtaining evidence of cybercrimes may be found by enabling auditing of suspicious events in the boundary devices and operating systems that are likely to be subject to attack. IT professionals should understand how to instruct these systems and devices to log such data and should also be aware of what kinds and classes of events are most worth logging. These events include logon attempts, access to sensitive resources, use of administrative privileges, and monitoring of key system and data files. Likewise, law enforcement professionals should be aware not only that these logs exist, but also that they often provide the most salient evidence of attempted or successful cybercrimes, and they must be aware of how to make appropriate efforts to secure and protect these logs before and during the investigation. Firewalls, routers, proxy servers, network servers, and IDSes can all contribute logs (plus related reports, alarms, and alerts) to substantiate allegations that unauthorized access, alteration, destruction, or denial of service occurred for information assets or services and, in some cases, to help track down the origin of the activity.
In the security model known as triple-A (authentication, authorization, and accounting), accounting is what makes auditing and logging of suspicious or illicit activity possible. IT and law enforcement professionals alike must understand this concept. Administrators must practice proper auditing and logging techniques to make sure they can detect cybercrimes (preferably before they succeed at compromising or damaging an organization's IT assets or infrastructure), obtain evidence that can help document illicit or unwanted activity, and assist in identifying the parties involved. Note also that boundary devices, Windows, and UNIX/Linux systems all have their own methods for enabling and recording such data, but that evidence is readily obtainable to those who know what to ask for and where to find what they seek.
On the proactive, preventive side of system and network security, boundary systems and servers should be configured to prevent or deflect common known attacks while also auditing and logging any evidence that related activities may be occurring. Log data usually includes timestamps, putative source addresses and domain names, and other information that can be used to trace attacks to their systems of origin. E-mail messages include similar information so that unwanted e-mail can be tracked back through the systems that forwarded it from its sender to its ultimate receiver. All too often, however, such trails lead only to additional victims or to unwitting participants in cybercrimes rather than to the actual perpetrators.
When tracing the origin of cybercrimes and the paths their network activity takes from the point of origin to the point of attack, investigators will find numerous tools and utilities useful in obtaining information. Firewalls, screening routers, and IDSes can often seek out and obtain such information automatically, and numerous Windows and Linux or UNIX tools and commands also exist to reacquire or confirm such information manually. Both IT and law enforcement professionals should understand how to use such commands and utilities, particularly those that help map IP addresses to domain names, and vice versa, to help identify points along the path of attack as well as its ultimate origin.
IDSes not only help detect and actively foil cybercrimes, but they also often help gather evidence about their patterns of attack, specific details about related activities, and so forth. Many IDSes operate on so-called attack signatures, which provide specific patterns of activity, network traffic, or behavior against which ongoing network activity may be compared to identify (and sometimes even foil) attacks as they occur. Like AV software and its signature databases, the IDS must also be constantly updated to keep its attack signatures up-to-date. Some IDSes also seek to identify anomalous behavior on systems or networks as a way to detect potential attacks for which signatures may not yet have been defined. In addition, IDSes can focus on individual hosts, applications, or networks to look for evidence of attacks or suspicious activity.
Despite investigators’ real abilities to trace attacks and identify their points of origin, spoofing techniques can often foil their efforts to identify the real perpetrators of cybercrimes. Often, initial suspects in cybercrimes turn out to be themselves victims of cybercrimes that make them only intermediaries for real perpetrators, or they may only be unwitting participants in activities that originate elsewhere. That's why antispoofing techniques are important components when configuring firewalls, screening routers, and so forth to avoid potential attack and why investigators must be prepared to follow trails of attack further, rather than rely on what the initial available evidence reveals.
Some companies and organizations may choose to expose deliberate lures to attackers—sometimes known as honeypots (for individual systems that act as lures) or honeynets (for entire networks that act as lures)—as a way of attracting their attention, then distract them long enough to increase the odds of identifying the perpetrators involved. Although this strategy does incur some additional risks (much like those associated with what insurance professionals call an “attractive nuisance” or what law enforcement professionals can readily identify as “sting operations”), when properly implemented and practiced, it can produce definite, usable results.
In the final analysis, the proper practice of security includes planning for potential intrusion or compromise, with attendant tools and settings in place to gather evidence of the existence and operation of illicit or unwanted activities. Because such evidence is essential to detecting cybercrimes, preventing recurrence, and enabling successful prosecution, it's a key element of any proper security policy. This also explains why tracking and monitoring represents an essential “reality check” to make sure security is working properly and to be able to deal with unforeseen or unexpected attacks or vulnerabilities if and when they occur.
Frequently Asked Questions
A The short answer to this question is inventory, inspect, filter, document, and preserve. Let's expand on that a bit:
▪ Inventory Take stock of all firewalls, screening routers, IDSes, systems, and servers in use through which attack traffic may have passed or at which attack traffic or activity may have focused. Examine each element to identify related log files or audit trails, and take note of their names and locations.
▪ Inspect Examine the various log files or audit trails to determine whether they contain records or entries that contain any traces of or evidence related to the incident under investigation. If so, add the name and location of each such audit trail to your list of evidence files.
▪ Filter Mathematics professionals call this step data reduction because it consists of ignoring entries that have no bearing on the incident you're investigating and collecting only those that are relevant to the matter at hand. Most log or event viewers include powerful data filtering tools; those that do not can usually be imported into a spreadsheet or database where those applications’ built-in search tools can help you separate what's important from what's not. Make sure your notes include the name and location of the original source file and that you (or an expert witness) can attest that (a) data filtering is a common practice in log and event trace analysis and (b) you can demonstrate a direct relationship between the original file and the filtered file.
▪ Document Explain how the captured log entries, event listings, and so forth provide evidence of a cybercrime. In addition, document extensively the original sources for such data, including their locations; original filenames; current locations of original, unaltered files or drives; and how the data was handled since initial detection of the incident occurred.
▪ Preserve Take all steps necessary to preserve the original source of the log files or event data. This may require removing a hard drive from a system or even taking a system out of service so as to preserve the evidence in its most pristine possible state.
Q Given the need to interpret and explain the contents of some specific log file or event trace, how can an investigator obtain the information necessary to perform this task?
A We've noted repeatedly that although the kinds of information recorded in logs and event traces are similar across multiple operating systems and boundary devices, the details vary according to each system and implementation. To document the layout and interpret the significance of log files and event traces, you will need to contact the vendor of the operating system, application, or device in question and ask the company to provide you with its documentation for those log files or event traces. In many cases, you'll be able to find this information for yourself if you use the vendor's search engine on its Web site or consult its technical support database or other information resources the vendor makes available online. If this doesn't produce the desired results, you may need to call the vendor's technical support operation and ask for assistance in identifying and obtaining the right information. In most cases, this should be an entirely routine matter and relatively easy to handle.
Q How can an organization be sure that its IDS and other boundary devices are completely up-to-date and that they include the latest attack signatures, patches, fixes, and so forth?
A In most cases, the system or software vendor that provides the IDS or other boundary device will also offer a notification service, online update information, and perhaps even tools you can use to assess the status of databases, patches, and fixes for such systems or services. Usually, a search on the vendor's Web site for the product in question will provide direct pointers to such information because the vendor understands the importance and urgency of that information as much as its customers do. When in doubt, contact the vendor's technical support operation. Here again, obtaining this information (or pointers to it) should be an entirely routine matter and easy to complete.
Q If an organization becomes subject to an attack that appears to be unknown or for which no signatures appear to be available, how and to whom should this kind of information be reported?
A The odds against falling prey to the first (or an early instance of an) attack are pretty low, but one unlucky organization must inevitably be the first victim of new vulnerabilities or be subjected to as-yet-undocumented attacks, as they occur. When this happens, it's important to notify all parties that might be concerned, including the following:
▪ Notify your upstream ISP and any other upstream ISPs that might sit between your network and the Internet.
▪ Contact any vendors whose products handle traffic related to such an attack, including firewall, proxy server, screening router, IDS, application, AV (where applicable), and operating system vendors. Most companies have formal reporting mechanisms they provide to customers who want to report security incidents. It will help if you can identify these companies in advance so that your response during an incident isn't slowed by researching this information.
▪ All the big general-incident clearinghouses should also be notified, including www.cert.org and other more-focused security organizations that focus on your particular industry or market niche.
▪ In the United States, if your state has criminal laws that cover network attacks (such as unauthorized access or denial/disruption of network services) contact your local police or sheriff's office.
▪ In the United States, the FBI and Secret Service have developed guidelines intended to encourage companies to report cyberattacks. See CIO Cyberthreat Response & Reporting Guidelines (in PDF format) at www.cio.com/research/security/incident_response.pdf for detailed information.
▪ Outside the United States, contact the national or regional agency responsible for making and enforcing cybercrime laws.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.